
Что такое избыточность lan
Ну, разве вас не бесит это также как и меня, когда посреди полета, пилот вдруг заявляет по громкой связи, что в связи с прискорбным отказом второго двигателя, мы скоро все разобьемся, и любезно советует, знаете ли, попробовать найти духовное единение со своим создателем или «что-то типа того»?
Но постойте-ка, обычно так не бывает.
Что, в общем-то, забавно, потому что двигатели у самолетов отказывают постоянно. Серьезно, это случается так часто, что Федеральное авиационное агентство США даже не ведет статистику отказов — это такая же обыденность, как и временная недоступность какого-то сайта в интернете.
Страховка рисков и жизней
Вот тут пилоты прикидывают, что отказы авиадвигателей происходят с частотой от одного раза на каждую тысячу летных часов, до одного раза на каждые десять тысяч часов. Вроде как нечасто. Но так кажется до тех пор, пока вы не примете во внимание, что в любой день, в воздухе над США выполняется около 30 000 коммерческих рейсов.
Только вы про это не узнаете,
никто не обязан вам о таком рассказывать
В этом нет большой проблемы, потому что все самолеты, кроме самых маленьких, имеют несколько двигателей. Даже с отказавшим двигателем, самолет летит, как ни в чем не бывало.
Некоторое время назад, авиакомпании обнаружили интересную закономерность. По прихоти статистики, удвоение количества двигателей на самолете ведет к удвоению проблем с ними. Что вполне логично: вы же не улучаете сами двигатели, добавляя их, вы просто увеличиваете вероятность, что один из них откажет. Но, что важно, вы вместе с тем уменьшаете вероятность того, что все двигатели откажут одновременно.
Если бы двигатели переставали работать раз в сто полетов (цифра с потолка и сильно завышенная) и на самолете был только один двигатель, то, понятно, один раз из ста полетов он бы отказывал.
А вот уже при двух установленных двигателях, хотя отказы двигателей происходили бы каждые 50 полетов, в среднем только один из 10 000 полетов, заканчивался бы трагически.
Именно поэтому, большие и тяжелые самолеты, которым для полета требуются два работающих двигателя, имеют целых четыре. Это еще больше уменьшает вероятность возникновения настоящих проблем.

Но, как я уже говорил, рейсов-то очень много и, в конце-концов, статистика берёт свое.
Если вы посмотрите эту ссылку, то узнаете, что в одном из рейсов над Индийским океаном произошло целых пять отказов двигателей. И тем не менее, этот рейс успешно приземлился, благодаря разным бортовым системам безопасности.
Ребята, мы все в IT можем очень многому поучиться у авиационной отрасли. Нет, честно. Это одна из немногих областей, где требования к безотказной работе выше, чем у нас. Кроме того, они в деле-то подольше нашего будут. За время своего существования, они кое-чему научились, в том числе тому, что у вас должен быть порядочный запас прочности (читай: избыточность), если вы хотите, чтобы ваш сервис имел действительно высокую доступность.
Избыточность — как синоним надежности
На самом деле, IT инфраструктура — это набор систем, работающих вместе для предоставления каких-то услуг. Каждая из систем относится к определенной категории, например физической, сетевой или хостовой. Для того, чтобы построить действительно отказоустойчивую инфраструктуру, каждая из категорий должна быть избыточна.
К физической категории относятся такие вещи, как местоположение, серверная комната, стойки, электричество. Если вы обратите внимание на последовательность в этом списке, то заметите, что перечисление начинается с самых общих вещей (местоположение) и движется в сторону частного (электричество). Это должно быть отражено в вашем планировании избыточности.
К сожалению, этот полет был бы очень захватывающим,
не в лучшем значении этого слова для пассажиров
Одного источника питания явно не достаточно. Любое оборудование зависит от питания, и если происходит отключение — тогда оопс, мы приплыли. Для борьбы с этим дата-центры имеют два независимых входа с электричеством от разных подстанций. Каждый сервер имеет по два блока питания, что и обеспечивает избыточность.
Сами дата-центры предоставляют питание от двух отдельных электросистем, каждая со своими аккумуляторными батареями и генераторами. Высококачественные дата-центры для обеспечения надежности используют схемы N+1 и N+2 . Это означает, что на каждые N-единиц оборудования, необходимого для нормальной работы, у них есть одна (или две) запасная. Самолеты с двигателями используют схему N+1 , с двигателями — N+2 .
Если наши системы размещены не в таком дата-центре, нам нужно как-то сымитировать два независимых входа питания. Для этого мы используем источники бесперебойного питания (UPS), которые питаются от обычной электросети и обеспечивают резервное питание от своих батарей в случае отключения электричества в электросети.
Это не так хорошо, как два независимых входа питания, но лучше чем ничего.

Сетевая инфраструктура обеспечивает удаленный доступ к нашим ресурсам. Через нее предоставляются сервисы наших организаций, и если сеть вдруг ложится, они перестают быть доступны вне зависимости, работают ли сами сервера.
Итак, мы используем многоуровневую защиту, чтобы обеспечить надежное функционирование сети.
Всегда, когда это возможно, нужно использовать два аплинка. В дата-центре это означает дублирование сетевого подключения. В небольших средах это означает, что нужно продублировать минимально необходимые подключения. По возможности, нужно использовать разных провайдеров, чтобы сбой одного из них не влиял на доступность ваших сервисов.
Подключение серверов в локальной сети одним кабелем очень рискованно. Всегда есть риск зацепить и выдернуть провода. Сетевые карты сбоят, а порты на свичах умирают. Сервер станет недоступен в любом из таких случаев. Чтобы избежать возникновения подобных проблем, современные сервера выпускаются с двумя встроенными сетевыми картами. Раньше я не понимал зачем, но потом узнал об объединении интерфейсов (interface bonding).
Конечно, подключить машину двумя кабелями к одному свичу — недостаточно. Свичи тоже не слишком надежны. Они иногда сбоят и тихо умирают, а кроме того, все свичи, которые я видел, из низкой и средней ценовой категории, имели только один блок питания, то есть если он умрет (см. выше), — то доступ к вашей сети или серверам, тоже исчезнет.
Так что покупайте сразу два свича как парни и подключайте сетевые карты одного сервера всегда к разным свичам.

Понятно, что эти советы не ограничиваются ethernet-сетями. Сети хранения данных подвержены тем же проблемам, возможно, даже с более тяжелыми последствиями для ваших данных. Все, известные мне технологии сетей хранения данных поддерживают multipath-функциональность, которая работает аналогично связыванию интерфейсов.
Получив отказоустойчивую инфраструктуру, обеспечивающую функционирование и связывающую наши серверы, нужно задуматься о самих серверах. Как я уже говорил, современные серверы для надежности производятся с дублирующимися частями. Многие BIOS-ы поддерживают зеркалирование ОЗУ, практически любой сервер имеет зеркалирование системного диска. Но, не смотря на все эти предосторожности, сбои все равно происходят.
Взрываются конденсаторы на материнских платах, ошибаются люди, а зазеркалированные диски стираются ошибочно введенной командой, не выдерживают нагрузочного тестирования.
Для защиты от таких происшествий мы дублируем целые системы. Используя подходящее программное обеспечение, можно объединить серверы в кластер так, что они будут работать, как один логический. Это обеспечивает дополнительный уровень избыточности, недоступный для отдельного сервера.
Но даже кластер серверов не поможет в случае катастрофического происшествия.

На картинке выше изображен естественный враг сетевых администраторов. Это специальный самонаводящийся оптико-искательный экскаватор, и одного такого достаточно (и в нашей стране они, управляемые красноносыми Операторами, встречаются целыми пачками), чтобы разрушить все ваши тщательно продуманные планы, которые мы перечислили выше.
Одним легким движением рычага, его зияющая пасть разрывает самые тяжело бронированные оптические кабеля и лишает интернета целые кварталы города. Пощады не будет ни для какого провайдера. В таком случае заранее мыльте веревку.
Хорошая новость: к счастью, обезопасить себя от этого можно. Плохая — к несчастью, это непросто и недешево
Ответом, конечно же, будет второй дата-центр, где-нибудь подальше от вашего основного, с повторением всей вышеописанной инфраструктуры. Похоже на полет в самолете, но с дополнительным самолетом рядом, — так, на всякий случай.
Чтобы построить избыточную и надежную инфраструктуру требуется время и тщательное планирование. Естественно, далеко не каждая организация нуждается в такой инфраструктуре, но если ваша организация в ней нуждается, — то ваш долг перед самим собой и вашей компании построить ее правильно. Потратьте время на то, чтобы изучить варианты, попробовать и поиграться с ними.

И это единственный способ стать лучше в том, что вы делаете каждый день.
Трехуровневая иерархическая модель сети, которая использует уровни ядра, распределения и доступа с избыточностью, призвана устранить единую точку отказа в сети. Использование нескольких физически подключенных каналов между коммутаторами обеспечивает физическую избыточность в коммутируемой сети. Это повышает надёжность и доступность сети. Наличие альтернативных физических каналов для передачи данных по сети позволяет пользователям получить доступ к сетевым ресурсам даже в случае сбоя одного из каналов.
1. PC1 взаимодействует с PC4 через избыточную топологию сети.
2. Когда в сетевом канале между S1 и S2 происходит сбой, путь между PC1 и PC4 автоматически корректируется, чтобы компенсировать сбой.
3. Если сетевое соединение между S1 и S2 восстановлено, путь повторно корректируется для маршрутизации трафика непосредственно от S2 к S1 для его доставки на PC4.
Для многих организаций доступность сети является важнейшим фактором обеспечения соответствия требованиям бизнеса. Таким образом, модель инфраструктуры сети является критически важным для бизнеса компонентом. Избыточность маршрута предоставляет решение, обеспечивающее необходимую доступность нескольких сетевых служб за счёт устранения потенциальной единой точки отказа.
Примечание. Избыточность на 1 уровне модели OSI демонстрируется с использованием нескольких каналов и устройств, однако для настройки сети требуется нечто большее, чем просто физическое планирование. Для систематической работы избыточности также необходимо использовать протоколы 2 уровня OSI (например STP).
Важной частью иерархической архитектуры является избыточность, использование которой позволяет предотвратить перебои в обслуживании оконечных пользователей. Для работы избыточных сетей требуются физические маршруты, однако и логическая избыточность также должна быть частью архитектуры. Тем не менее, избыточные маршруты в коммутируемой сети Ethernet могут привести к возникновению физических и логических петель 2 уровня.
Вследствие работы коммутаторов, особенно в процессе получения данных и пересылки, могут возникать логические петли 2 уровня. При наличии нескольких путей между двумя устройствами и отсутствии реализации протокола spanning-tree возникает петля 2 уровня. Как показано на рис. 2, петля 2 уровня, как правило, приводит к трем проблемам.
Нужны новые клиенты? Тогда Вам рекомендуем посмотреть этот раздел нашего сайта
_____
Когда в одной сети используется множество коммутаторов, это приводит к появлению преднамеренных или случайных физических петель. Когда образуются петли, может быть создан широковещательный шторм, распространяющий фреймы в сети. В этом разделе описывается, как петли влияют на производительность в коммутируемой сети.
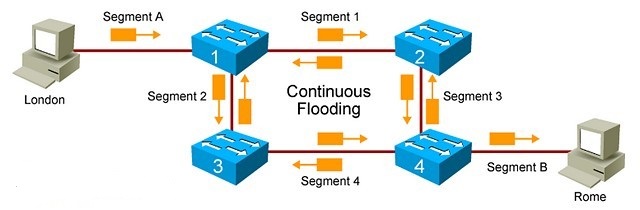
Ethernet сети и избыточность соединений в них
Добавление коммутаторов в сеть может так же добавить избыточность соединений; это происходит, когда два коммутатора подсоединяются к одному сегменту сети, для того чтобы при выходе одного из сегментов быть уверенным, что соединение осталось. Избыточность позволяет быть уверенным в доступности сети в любое время, что являетеся важным преимуществом для пользователей. Однако в эгом кроется возможная проблема в сети: когда коммутатор испольтуется для избыточности, возможно появление петель. Когда хост в одном сетевом сегменте передает данные хосту в другом сетевом сегменте, и возможно два или более пути через коммутаторы, то каждый коммутатор при получении фрейма ищет положение принимающего устройства и пересылает фрейм. Из-за того, что каждый коммутатор передает фрейм, появляются дубликаты фрейма. Этот процесс приводит к появлению петель между двумя путями без удаления из сети. Таблица MAC адресов может быть тоже обновлена неправильной информацией об адресе, в результате происходит неправильная пересылка.
Пример: Петли в коммутируемой сети
Предположим, тго хост London отправляет фрейм к хосту Rome London находится в сетевом сегменте A, a Rome находится в сетевом сегменте В. Оба хоста соединены с сегментом А и сегментом В для надежности, если даже сегмент будет поврежден. Коммутатор 1 и коммутатор 2 предоставляет избыточные соединения между двумя сегментами сети. Оба коммутатора, коммутатор 1 и коммутатор 2, получают фрейм от London и запоминают, что London находится в сегменте 2. Каждый коммутатор передает фрейм в сегмент 1.
Rome получает две копии фрейма от London через коммутатор 1 и коммутатор 2. Однако два этих коммутатора также получают фрейм на интерфейсы, находящиеся в сегменте В. Коммутаторы меняют их внутреннюю таблицу, отмечая, что London теперь в сегменте В. Если Rome посылает ответ к London, два коммутатора получат, а затем выбросят фрейм с ответом, потому что в таблице MAC адресов каждого коммутатора присутствует запись, что London в том же сегменте сети, что и Rome.
Если от London изначально пришел широковещательный фрейм, то оба коммутатора будут пересылать этот фрейм бесконечно, используя всю доступную пропускную способность и блокируя передачу всех остальных фреймов в двух сегментах.
C появлением высокоскоростных каналов, предоставляемых провайдерами Internet (Internet Service Provider, ISP), пользователям стало намного проще размещать различные службы на своих домашних компьютерах. Но что если связь прервется? Очевидное решение в такой ситуации — использовать резервное соединение с Internet от другого провайдера. В данной статье рассказывается о наиболее важных моментах, которые следует учитывать при настройке хоста Linux с избыточными соединениями Internet:
- о конфигурации хоста таким образом, чтобы он корректно поддерживал входящие сетевые соединения от нескольких провайдеров Internet;
- о балансировке трафика между исходящими сетевыми соединениями;
- o конфигурации различных служб для поддержания избыточности;
- о настройке защиты межсетевого экрана с помощью сценариев ipchains или iptables.
На Рисунке 1 приведена конфигурация домашней компьютерной сети, на которую мы будем ссылаться по мере повествования. Хост Linux действует как межсетевой экран между Internet и внутренней локальной сетью. Интерфейс Ethernet eth1 использует DSL, а интерфейс Ethernet eth2 — кабельный модем. Хост Linux выполняет балансировку нагрузки между исходящими сетевыми соединениями с двумя провайдерами Internet. Такой подход не ограничивается только высокоскоростными сетевыми каналами — подобные методы могут применяться и для распределения нагрузки между двумя коммутируемыми соединениями.
Хост в тестовой конфигурации представлял собой компьютер с двумя процессорами Intel Celeron с тактовой частотой 533 МГц, на котором работала операционная система Red Hat 6.2 с ядром Linux 2.2.18. Испытания проводились также с версией Red Hat 7.1 и ядром Linux 2.4.13. Представленная конфигурация не требует наличия ни двухпроцессорной системы, ни процессоров с тактовой частотой 533 МГц. В качестве межсетевого экрана можно приспособить старую систему с процессором Pentium/100 МГц и оперативной памятью емкостью 32 Мбайт. Некоторые примеры, приведенные в статье, рассчитаны на Red Hat, но их можно легко изменить таким образом, чтобы они будут приложимы к другим распространенным вариантам Linux.
КОНФИГУРИРОВАНИЕ ЯДРА
Ядро Linux 2.2 и более поздних версий поддерживает усовершенствованные методы маршрутизации, которые необходимы для выполнения балансировки нагрузки и предоставления нескольких маршрутов по умолчанию на хосте Linux. Для поддержки нескольких соединений с Internet при компиляции ядра следует задать следующие сетевые опции:
МАРШРУТИЗАЦИЯ IP ПО ИСТОЧНИКУ
По умолчанию, маршрутизация пакетов TCP/IP выполняется путем анализа IP-адресов назначения и поиска маршрута к указанной сети в таблице маршрутизации, просмотреть которую можно с помощью команды netstat -r. Если маршрут найден, пакет передается на этот сетевой интерфейс, в противном случае пересылается на шлюз, заданный по умолчанию. Для большинства систем, напрямую подключенных к Internet, по умолчанию в качестве шлюза выступает провайдер Internet. В нашем случае это означает, что все исходящие соединения Internet выходят из интерфейса DSL — не очень желательное явление в среде с избыточными соединениями. При добавлении в систему кабельного модема совсем не хочется, чтобы его соединения при ответе переходили на DSL.
Для решения этой проблемы с помощью команды ip создается несколько таблиц маршрутизации, а конкретная таблица выбирается в зависимости от IP-адреса отправителя исходящего пакета. Конфигурирование осуществляется посредством следующих команд.
Если исходящий пакет передается с адреса источника 63.89.102.157 (DSL), то поиск маршрута выполняется в Таблице маршрутизации 1, где имеются две записи:
С помощью первой строки локальный трафик маршрутизируется во внутреннюю сеть, а благодаря второй все оставшиеся пакеты пересылаются провайдеру Internet через интерфейс DSL. Таблица маршрутизации 2 для интерфейса кабельного модема используется таким же образом.
БАЛАНСИРОВКА НАГРУЗКИ
Балансировка нагрузки между исходящими из внутренней сети соединениями осуществляется с помощью опции ядра CONFIG_IP_ROUTE_MULTIPATH, которая позволяет определить несколько шлюзов по умолчанию. Для этого необходимо удалить шлюз по умолчанию из файла /etc/sysconfig/network и задать шлюз по умолчанию с помощью расширенных функций маршрутизации посредством следующей команды:
Следующая команда позволяет просмотреть усовершенствованную таблицу маршрутизации:
Опция ядра CONFIG_IP_ROUTE_MULTIPATH заставляет Linux, как сказано в документации /usr/src/linux/Documentation/ Configure.help, «рассматривать все эти пути (маршруты, заданные по умолчанию) как имеющие равную «стоимость» и выбирать один из них произвольным образом». Опция equalize в команде ip route указывает ядру Linux на необходимость балансировки нагрузки между исходящими соединениями на основе IP-адреса. Для конкретного IP-адреса ядро выбирает интерфейс, куда будут передаваться исходящие пакеты; затем ядро сохраняет это решение как запись в кэше маршрутизации для данного IP-адреса. Последующие соединения с указанным IP-адресом будут осуществляться через тот же самый интерфейс до тех пор, пока не истечет срок действия записи в кэше маршрутизации, просмотреть который можно с помощью команды ip route list cache.
КОНФИГУРАЦИЯ СЕРвисОВ
Проверить конфигурацию DNS можно с помощью команды dig (модификация команды nslookup):
позволяют организовать несколько именованных виртуальных хостов для Apache.
СЦЕНАРИИ НАЧАЛЬНОЙ ЗАГРУЗКИ
Для поддержки нашей сетевой конфигурации необходимо изменить несколько сценариев начальной загрузки. Они созданы для Red Hat, но легко модифицируются для любого другого варианта Linux. Команды ip rule нужно выполнять только после загрузки системы. Для этого в раздел начальной загрузки сценария /etc/rc.d/init.d/network следует добавить следующие строки:
Файл /etc/sysconfig/static-rules содержит:
Команды ip route должны выполняться каждый раз, когда инициируется ifup для соответствующего интерфейса. Добавьте следующие строки в /etc/sysconfig/ network-scripts/ifup-routes:
Файл /etc/sysconfig/static-routes содержит:
МЕЖСЕТЕВЫЕ ЭКРАНЫ
Если ваш хост подключен к Internet, то для блокировки нежелательного трафика понадобится установить межсетевой экран. Выбрав, каким службам будет разрешен доступ к хосту через Internet, использование соединений всеми остальными службами следует запретить. Помните, что установка межсетевого экрана не означает, что ваша система защищена. Любая служба, которой разрешен доступ через межсетевой экран, имеет собственные изъяны в защите, чем не преминут воспользоваться хакеры, поэтому очень важно следить за тем, чтобы в приложениях были установлены все новейшие заплаты.
Большинство сценариев межсетевого экрана рассчитано только на одно внешнее сетевое соединение. Поддержку множества внешних сетевых интерфейсов можно реализовать с помощью нескольких специально разработанных сценариев. Первый использует поставляемый вместе с ядрами Linux 2.2 межсетевой экран под названием ipchains. Второй — поставляемый вместе с ядрами Linux 2.4 межсетевой экран под названием iptables. (Ядро Linux 2.4 позволяет установить межсетевой экран ipchains, но одновременная работа ipchains и iptables невозможна.)
По существу, iptables — это преемник ipchains, только более мощный, поскольку поддерживает контроль соединений, благодаря чему Linux получает межсетевой экран с контекстной проверкой. Кроме того, iptables является расширяемым, т. е. к нему можно добавлять новые функции (например, поиск соответствия строк), не изменяя при этом базовый исходный текст для iptables. Новые функции iptables описаны во врезке «Новые функции сценария межсетевого экрана iptables». И ipchains, и iptables разделяют трафик на несколько различных цепочек правил, которые определяют, нужно ли принять или отвергнуть пакет. В iptables для фильтрации пакетов применяются три таблицы цепочек, называемые filter, nat и mangle. При передаче пакета по цепочке последовательно проверяется каждое правило, пока не будет найдено соответствие.
Три стандартные цепочки в ipchains получили название INPUT, FORWARD и OUTPUT. Эти цепочки представлены в iptables в таблице фильтров: INPUT анализирует пакеты сразу же, как только они поступают на сетевой интерфейс; FORWARD исследует замаскированные пакеты; OUTPUT проверяет их до передачи на сетевой интерфейс. На Рисунке 2 представлен путь, который пакеты проходят при разделении на различные цепочки на межсетевом экране ipchains.
У межсетевого экрана iptables в таблице nat имеются две дополнительные цепочки — PREROUTING и POSTROUTING. Они служат для выполнения маскировки пакетов, или, иначе, преобразования сетевых адресов. После поступления на сетевой интерфейс все пакеты проходят эти цепочки перед дальнейшей отправкой.
В iptables цепочки INPUT и OUTPUT обрабатывают пакеты, предназначенные для межсетевого экрана, а цепочка FORWARD обрабатывает только замаскированные пакеты. На Рисунке 3 представлен путь, по которому следуют пакеты, проходя по различным цепочкам в межсетевом экране iptables.
Таблица mangle в iptables использует цепочки PREROUTING и OUTPUT для того, чтобы можно было изменять в пакетах такие флаги IP, как TTL (срок действия) и TOS (тип обслуживания).
КОНФИГУРАЦИЯ ЯДРА МЕЖСЕТЕВОГО ЭКРАНА
Чтобы создать межсетевой экран ipchains в ядре Linux 2.2, необходимо указать ниже перечисленные опции в файле конфигурации ядра:
Межсетевой экран iptables в ядре Linux 2.2 создается с помощью следующих опций в файле конфигурации ядра:
Добавить к своему ядру экспериментальные заплаты iptables можно, выполнив указанные инструкции.
Ответьте yes («да») на вопрос об установке следующих заплат:
Поскольку не все заплаты совместимы, выбирайте только те из них, которые намереваетесь использовать.
Укажите в качестве ответа m для опций CONFIG_IP_NF_ MATCH, которые вы добавили к ядру.
Обратите внимание, что приведенные команды написаны именно для ядра Linux 2.4.13 и заплат iptables 1.2.4. Предполагается, что эти экспериментальные функции войдут в состав основного ядра уже в ближайшем будущем.
СЦЕНАРИИ МЕЖСЕТЕВОГО ЭКРАНА
Чтобы установить сценарий межсетевого экрана в своей системе Red Hat 7.1, его следует поместить в /etc/init.d/firewall и выполнить команду:
Для конфигурации сценария межсетевого экрана в своей системе нужно отредактировать следующие две строки, чтобы определить имеющиеся внутренний и внешний интерфейсы:
Цепочка INPUT также допускает любые ответы (возвраты), инициированные локально для соединений в соответствии со следующими правилами в сценарии межсетевого экрана ipchains.
Это единственный способ разрешить обратный трафик TCP, поскольку ipchains не является межсетевым экраном с контекстной проверкой. iptables значительно улучшает защиту за счет поддержки работы межсетевого экрана с такой функциональностью. Он называется также «контроль соединения», т. е. пакет принимается только при соответствии активному соединению, инициатор которого находится во внутренней сети. Эта обработка оформляется в сценарии межсетевого экрана iptables соответствующим образом:
UDP — это протокол, не сохраняющий состояние, но контроль соединений iptables поддерживает таблицу состояний и допускает через порты UDP ответы для трафика, инициатор которого находится во внутренней сети.
Сценарий межсетевого экрана iptables принимает входящие соединения и размещает информацию о новых в базе данных контроля соединений в соответствии со следующими правилами:
Базу данных контроля соединений можно посмотреть, открыв файл /proc/net/ip_conntrack.
Приводимое ниже правило для iptables разрешает входящие активные соединения ftp на межсетевом экране с порта TCP 20 только для уже открытого сеанса ftp.
Следующее правило разрешает входящие запросы DNS к BIND:
Перечисленные ниже правила разрешают входящий трафик NTP из военно-морской обсерватории Соединенных Штатов:
Цепочка FORWARD просто маскирует соединения для систем во внутренней сети, используя преобразование сетевых адресов (Network Addresss Translation, NAT). Большинство протоколов работает с NAT, но некоторым необходима небольшая помощь со стороны специального модуля, который переписывает IP-адреса. Активным соединениям ftp требуется программа-помощник для преодоления межсетевого экрана; их можно замаскировать, загружая модули ip_masq_ftp (ipchains) или ip_nat_ftp (iptables) с командой modprobe (если они уже не скомпилированы в ядре). Удаленная машина на другой стороне активного соединения ftp пытается подключиться обратно к локальной машине через межсетевой экран для передачи данных. Модуль ip_masq_ftp перезаписывает пакеты соединения ftp так, что внутренняя машина кажется подключенной напрямую к Internet. В пассивном режиме ftp эта проблема решается за счет передачи всех данных через порт TCP 21. Если вы решите поддерживать ftp, помните, что он передает пароли по сети в виде обычного текста и не считается защищенным. Защищенная альтернатива ftp — это sftp; метод организации соединений он использует в качестве защищенного сокета. Сейчас sftp предлагается вместе с клиентскими инструментальными средствами OpenSSH.
Другие маскирующие модули для различных приложений можно найти в каталогах /lib/modules/?uname -r?/ipv4 (ipchains) или /lib/modules/?uname -r?/kernel/net/ipv4/netfilter/ (iptables).
Цепочка FORWARD использует следующие правила iptables при прохождении замаскированных пакетов через межсетевой экран:
Цепочка OUTPUT допускает только сетевой трафик (если он направляется через корректный интерфейс), а также выявляет приоритеты для определенного трафика, устанавливая флаги TOS. Так, с помощью флагов TOS можно указать, что интерактивный (SSH) трафик имеет приоритет перед трафиком ftp. К флагам TOS относятся минимизация задержки (Minimize-Delay), максимизация пропускной способности (Maximize-Throughput), максимизация надежности (Maximize-Reliability) и минимизация затрат (Minimize-Cost).
Многие провайдеры Internet игнорируют флаги TOS в пакетах, но их полезность очевидна, поскольку именно благодаря им опция ядра CONFIG_IP_ROUTE_TOS определяет приоритеты исходящего трафика. Это значит, что приложения с высокими требованиями к пропускной способности (например, крупный сервер ftp) могут выполняться с флагом «максимальная пропускная способность», а интерактивные приложения (такие, как SSH) — «с минимальной задержкой». Таким образом, ftp не будет негативно влиять на производительность вашего соединения SSH.
Флаги TOS устанавливаются в сценарии межсетевого экрана iptables в цепочках PREROUTING и OUTPUT таблицы mangle. Цепочка PREROUTING определяет приоритеты входящих, а OUTPUT — исходящих пакетов. Для минимизации задержки пакетов SSH используются следующие правила:
ПОДДЕРЖКА МЕЖСЕТЕВОГО ЭКРАНА
Чтобы проверить эффективность правил межсетевого экрана, сценарий межсетевого экрана следует выполнить, применив следующую команду:
Проанализируйте данные в первых двух столбцах полученного результата. Нули свидетельствуют о том, что ни один пакет не соответствует данному правилу. Это не всегда плохо — нули в поле правил DENY или DROP свидетельствуют, что никто не пытался проникнуть на ваш хост с помощью указанного правила. Нули в поле правила ACCEPT означают, что соответствующий трафик не был принят, однако трафик может соответствовать к правилу, находящемуся раньше в цепочке.
Эти сценарии межсетевого экрана разрешают обратный трафик только через непривилегированные порты, поэтому, чтобы разрешить обслуживание непривилегированных портов, конфигурацию SSH придется обновить, отредактировав файл ssh_config и добавив строку:
ВЫВОДЫ
Я использовал эту конфигурацию почти целый год и остался доволен ее производительностью. Однако исходящие соединения ставят несколько вопросов в тех случаях, когда канал перестает функционировать. Если один канал станет недоступен, то на этот случай избыточность для исходящих соединений обеспечивается с помощью второго канала на уровне приложений. Исходящие соединения, инициируемые локально, будут поддерживаться в единичных случаях до тех пор, пока не будет выполнена команда ifdown для интерфейса с провайдером Internet, на котором возник сбой. Если перерыв в работе окажется достаточно долгим, вы можете обновить DNS. Проблема возникает, когда выполняется ifup для интерфейса, поскольку во вторичную таблицу необходимо добавить записи о маршрутизации (например, ip route add 0/0 via 63.89.102.1 table 1). Сценарий ifup-routes был изменен для того, чтобы эти нетривиальные маршруты добавлялись автоматически. Если команда ifdown запускается на обоих интерфейсах, необходимо снова добавить маршрут по умолчанию в основную таблицу маршрутизации (например, ip route add default equalize nexthop via. ). Сценарии для выполнения различных алгоритмов восстановления после сбоя читателю предлагается написать самостоятельно в качестве упражнения.
Ресурсы Internet
Новые функции сценария межсетевого экрана iptables
Следует отметить, что iptables не только обеспечивает полноценную работу межсетевого экрана с контекстной проверкой, но и способен к расширению. Кроме того, iptables поддерживает более совершенные функции межсетевого экрана, чем ipchains. Некоторые из них требуют поддержки ядра, как описано выше в разделе «Конфигурация ядра межсетевого экрана».
iptables можно использовать для установки ограничений на новые входящие пакеты TCP, чтобы предотвратить атаки по типу «отказ в обслуживании». Это достигается с помощью следующих правил:
Эти правила ограничивают количество новых входящих соединений TCP (пакеты с установленным битом SYN) до 12 соединений в секунду после того, как окажется достигнут предел в 24 соединения в секунду.
Теперь можно установить соответствие любым флагам TCP, т. е. блокировать дерево XMAS (все флаги установлены) и пакеты NULL по следующим правилам:
Благодаря экспериментальной заплате netfilter psd межсетевой экран iptables может выявлять и блокировать сканирование входящих портов с помощью другого правила:
Экспериментальная заплата netfilter iplimit позволит межсетевому экрану iptables ограничить число соединений с конкретного IP-адреса посредством следующего правила:
Одна из наиболее мощных заплат netfilter предназначена для определения соответствия пакетов на основе их информационного наполнения. Экспериментальная заплата соответствия строк позволяет отфильтровать пакеты, если они относятся к определенной строке. Она дает возможность выявлять вирусы CodeRed или Nimda до их проникновения на сервер Web. Это можно сделать с помощью нескольких правил.
Вы можете также перенаправлять с порта пакеты UDP. Если трафик перенаправляется на конкретный порт, то для разрешения входящих соединений соответствующее правило в цепочке INPUT указывать не нужно.
Новые функции iptables появляются регулярно. Один из таких экспериментальных модулей — ip_nat_h323. Он позволит перенаправлять с порта входящие соединения NetMeeting через межсетевой экран. В момент написания данной статьи это решение находилось на стадии разработки.
B последние годы специалисты в области локальных сетей все чаще склоняются к тому, что сети с сотнями, тысячами или даже десятками тысяч узлов должны быть структурированы в соответствии с иерархической моделью, превосходство которой перед плоской, неиерархической, моделью кажется убедительным.
Казалось бы, после замены медленных маршрутизаторов на более производительные коммутаторы третьего уровня ничто больше не сможет помешать распространению этой модели. Однако удешевление коммутаторов способствует выбору в пользу решений полностью на базе второго уровня. Преимущества структурированных сетей при этом игнорируются.
ПРЕИМУЩЕСТВА ИЕРАРХИЧЕСКОЙ МОДЕЛИ
В иерархической модели вся сеть делится на несколько уровней, работа с которыми производится по отдельности. Это весьма облегчает постановку задач при проектировании, поскольку каждый отдельный уровень можно реализовать в соответствии со специфическими требованиями определенной области охвата. Уменьшение размеров подсетей позволяет добиться снижения числа коммуникационных связей каждого конечного устройства. Так, например, широковещательные «штормы» быстро растут вместе с увеличением числа систем в плоской сети.
Ответственность за обслуживание отдельных подобластей сетевого дерева в иерархической модели легко делегируется без каких-либо серьезных проблем с интерфейсом, что невозможно в случае плоской сети. Кроме того, наглядность сетевой структуры в случае иерархической модели также оправдывает себя при поиске ошибок. При иерархическом построении сети различного рода изменения реализовать гораздо проще, поскольку, как правило, они затрагивают лишь часть системы. В плоской же модели они способны повлиять на всю сеть. Это обстоятельство значительно упрощает наращивание иерархических сетей: оно реализуется добавлением новой сетевой области к существующему уровню или следующего уровня без необходимости перекройки всей структуры.
ОТ МАРШРУТИЗАЦИИ К КОММУТАЦИИ НА ТРЕТЬЕМ УРОВНЕ
Долгое время успешному распространению иерархической схемы построения сети мешали высокая стоимость и низкая производительность имеющихся устройств. Классические маршрутизаторы не могли соперничать с коммутаторами второго уровня ни по скорости передачи пакетов, ни по стоимости портов. Реализация необходимой комбинации маршрутизации и коммутации второго уровня на практике оказалась проблематичной. Поэтому на многих предприятиях выбор для коммуникаций в пределах подсетей IP или виртуальных локальных сетей (Virtual Local Area Network, VLAN) был сделан в пользу комбинированной коммутации кадров второго уровня и АТМ. Между тем высокопроизводительного оборудования для коммуникаций по IP между виртуальными сетями не было. Оно наконец-то стало доступным с появлением коммутации на третьем уровне (с исправлением первоначальных недостатков ее можно теперь считать вполне зрелой).
Коммутаторы третьего уровня осуществляют маршрутизацию каждого пакета в отдельности с помощью специализированных интегральных схем (Applications Specific Integrated Circuit, ASIC), при этом они анализируют содержимое пакетов и принимают решения о выборе пути на основе информации с более высоких уровней. Коммуникация между VLAN происходит так же быстро, как и внутри, т. е. с максимальной пропускной способностью сети. На рынке уже появились продукты со скоростью передачи до 100 млн пакетов в секунду.
Замена имеющихся маршрутизаторов на коммутаторы третьего уровня осуществляется очень просто: заменить требуется только соответствующие устройства. Все навыки и потенциал ноу-хау, накопленный за годы эксплуатации маршрутизаторов, могут быть использованы в дальнейшей работе.
Коммутаторы второго и третьего уровней в настоящее время мало чем отличаются друг от друга в плане производительности, поэтому вопрос выбора типа устройства зависит — наряду с функциональностью — от стоимости портов. Вместе с тем, даже несмотря на заметное удешевление коммутаторов третьего уровня, простые коммутаторы второго уровня по-прежнему стоят намного меньше. Тем самым область применения первых — главным образом сетевые магистрали, а последних — рабочие группы.
ЧЕТКОЕ ЛОКАЛЬНОЕ ПОДЧИНЕНИЕ
Связанная с коммутацией второго уровня технология виртуальных локальных сетей появилась вследствие стремления свести к минимуму коммуникации между подсетями IP, поскольку они осуществляются по медленным соединениям с маршрутизаторами. Увеличить долю коммуникаций внутри VLAN и снизить таковую между VLAN можно путем отображения на виртуальные локальные сети подсетей IP и выделенных организационных структур. При этом одна и та же подсеть может распространяться на несколько зданий — как правило, для виртуальных локальных сетей география не имеет никакого значения.
Коммутация третьего уровня все же дает шанс на последовательное претворение в жизнь иерархических принципов построения сети. Тем самым особое значение снова приобретает вопрос о так называемом плоском или иерархическом подходе. Логическая структура плоской неструктурированной сети соответствует представленной на Рисунке 1 схеме. Связь между местоположением конечных устройств и их IP-адресами отсутствует. Третий октет IP-адреса (на рисунке: «1», «2» или «3») не дает никакой информации о расположении конечного устройства.
Альтернативой может быть инфраструктура третьего уровня в ядре сети с подключенными коммутаторами второго уровня, возможно, так, как это представлено на Рисунке 2. Структурированная сеть соответствует изображенной на Рисунке 3 логической схеме, в которой отчетливо прослеживается зависимость между местоположением конечных устройств и их IP-адресами. Третий октет IP-адреса дает точную информацию о том, где находится конечное устройство. В четвертом и последнем октете указываются конкретные конечные устройства.
СТРУКТУРИРОВАННЫЕ СЕТИ ВТОРОГО/ТРЕТЬЕГО УРОВНЕЙ
При исследовании достоинств и недостатков рассматриваемых топологий все-таки можно найти один значительный позитивный аспект плоских сетей второго уровня: при перемещениях оборудования не требуется менять IP-адреса и не надо перенастраивать приложения, в которых IP-адреса используются в качестве идентификационных признаков.
Однако этому можно противопоставить целый ряд преимуществ структурированных сетей второго/третьего уровня:
- отсутствие отрицательных последствий потенциального дублирования IP-адресов для всей сети в целом;
- разделение доменов широковещательной рассылки и, тем самым, значительное снижение нагрузки на конечные устройства;
- повсеместное соответствие адресов сетевого уровня зданиям и коммутаторам: «говорящие» адреса облегчают локализацию возникающих ошибок;
- возможность реализации функций безопасности на границах между подсетями;
- обеспечение нужного качества сервиса на сетевом и транспортном уровнях, например путем определения приоритета для некоторых приложений;
- более эффективное управление широковещательными рассылками благодаря применению маршрутизации широковещательного трафика в коммутаторах третьего уровня;
- значительное сокращение времени, необходимого для обеспечения сходимости при реализации избыточных соединений. К примеру, при первоочередном выборе кратчайшего маршрута (Open Shortest Path First, OSPF) для этого понадобится всего несколько секунд, в то время как протоколу Spanning Tree — от 40 до 50 с. На уровне подсетей IP в качестве механизма избыточности для маршрутизатора по умолчанию можно применять протокол маршрутизатора «горячего» резерва/виртуальный протокол избыточной маршрутизации (Hot Standby Router Protocol/Virtual Router Redundancy Protocol, HSRP/VRRP).
КОНКУРИРУЮЩИЕ ПОДХОДЫ К ДИЗАЙНУ
Структурированная сеть второго/третьего уровня, по-видимому, лучше всего подходит для обеспечения безопасной и стабильной работы даже в крупных сетях. К таким выводам приходят практически все архитекторы сетей, однако в последнее время немало приверженцев получают новый подход к дизайну сети, в основу которого положены исключительно коммутаторы второго уровня. Это связано с тем, что многие предприятия вынуждены искать возможности для уменьшения инвестиций, в том числе и в локальные сети.
Подобные концепции базируются преимущественно на применении недорогих коммутаторов второго уровня и заключаются в составлении из них, к примеру, кольцевой структуры. Механизм реализации избыточности в кольцевых структурах опирается на протокол Rapid Spanning Tree. Этот подход поддерживается стандартом IEEE 802.1w, где определена быстрая реконфигурация покрывающего дерева, целью разработки которого было сокращение до нескольких секунд времени сходимости протокола Spanning Tree, пользующегося за свою медлительность дурной славой.
Подобные «недорогие» схемы, где модель иерархической сетевой структуры остается за бортом, на первый взгляд выглядят привлекательными: экономия исчисляется в десятках процентов. Однако умеренный скепсис не повредит. Дешевые коммутаторы второго уровня должны иметь стабильные коды для поддержки Rapid Spanning Tree. Однако это кажется очень смелым предположением с учетом того, сколько времени потребовалось, чтобы исходный алгоритм стал работать более-менее стабильно. К тому же нельзя забывать, что малое значение времени сходимости при наличии избыточных соединений — всего лишь одна из причин, по которым применяется инфраструктура третьего уровня. А как же тогда «говорящие» IP-адреса, защита от ошибочно заданных адресов, сокращение широковещательного трафика и более эффективное управление широковещательным трафиком в сетях на третьем уровне?
При такой точке зрения ценовый аспект приобретает относительный характер, ведь, в конце концов, эти два подхода к сетевому дизайну нельзя сравнивать. Конечно же, полностью избыточный дизайн с топологией «двойная звезда» стоит гораздо больше каскадной структуры с недорогими компонентами. Впрочем, проект сети с применением устройств третьего уровня тоже можно несколько удешевить: вовсе не обязательно брать за основу аппаратное обеспечение «с избытком». Это поможет построить сеть третьего уровня и сэкономить при этом порядка 35% ее стоимости.
Читайте также: