
Что такое инфинити кэш
Но над трассировкой лучей и программными улучшениями производительности AMD ещё стоит поработать.
DTF в числе первых в России получил экземпляр AMD Radeon RX 6700 XT — видеокарты средне-высокого ценового диапазона, которую производитель заявляет как «лучше всего приспособленную к играм в разрешении 1440p»
- 40 вычислительных блоков RDNA 2
- 40 блоков Ray Accelerator (по одному на каждый вычислительный блок)
- Частоты: базовая 2,3 ГГц, «игровая» 2,4 ГГЦ, авторазгон до 2,74 ГГц
- 12 ГБ DDR6 с шиной 192 бита + 96 МБ Infinity Cache
- Частота видеопамяти 1,98 МГц, авторазгон до 2,15 ГГц
- Энергопотребление 230 Вт
- Рекомендованная цена в России: 42 499 рублей
Видеокарта в референсном дизайне AMD изготовлена преимущественно из алюминия и занимает ровно два слота по высоте — она значительно компактнее и легче, чем RX 6800 XT, которую мы тестировали ранее. Охлаждение обеспечивают два кулера и сравнительно небольшой радиатор с боковым выдувом. Часть тепла также помогает рассеивать металлический корпус, соединённый с платой термопрокладками.
В наших тестах RX 6700 XT система охлаждения видеокарты отдавала приоритет акустическому комфорту, поэтому в играх чип «прогревался» от 75 до 87 градусов, но при этом шум вентиляторов было едва слышно даже в открытом стенде (его перекрывал процессорный кулер).
За питание отвечают два стандартных коннектора на 8+6 контактов — AMD рекомендует использовать БП не менее чем на 650 Вт.
Для подключения экранов предусмотрено три Displayport 1.4 и один HDMI 2.1, совместимый 4К и 8К телевизорами.
Подсистема памяти Radeon RX 6700 XT на первый взгляд напоминает более дешёвую GeForce RTX 3060: 12 ГБ GDDR6 c уменьшенной 192-битной шиной (шесть каналов по 32 бита). При такой шине можно использовать либо 6, либо 12 ГБ памяти (шесть модулей по 1 или 2 ГБ), так как применение разных модулей в рамках одной карты считается далёким от оптимального решения.
Однако видеокарты AMD кардинально отличаются от NVIDIA — подсистема памяти в RDNA2 усилена отдельным кэшем Infinity Cache на 96 МБ. Производитель заявляет, что реальная скорость обращения к памяти в 2,5 раза выше, чем у видеокарт с 256-битной шиной, поэтому эффективность RX 6700 XT выше, чем у схожей по спецификации RTX 3060.
AMD заявляет, что Radeon RX 6700 XT спроектирована для игры в разрешении 1440p — поэтому большинство тестов мы проводили именно в нём и при максимально возможных настройках графики.
В большинстве игр из нашего регулярного тестового пакета видеокарта выдаёт средний фреймрейт порядка 60 fps или выше без критических просадок. При использовании монитора с FreeSync (его поддерживают почти все игровые мониторы и даже некоторые телевизоры), геймплей выглядит достаточно плавным уже начиная с 40-45 fps, поэтому даже в немного «не добирающий» Cyberpunk 2077 играть вполне комфортно.
Результаты тестов других видеокарт можно посмотреть в соответствующих обзорах: Geforce RTX 3070, RTX 3060 Ti, Radeon RX 6800 XT.
Это, впрочем, не касается игр с трассировкой лучей — в Watch Dogs: Legion средняя частота кадров в 1440p не добирается даже до 30 fps. Для сравнения, GeForce RTX 3060 Ti, которая (в теории) стоит дешевле и в целом заявляется как карта более низкого класса, справляется с RTX-играми значительно лучше, и это даже без учёта DLSS 2.0. При этом в «обычных» играх RX 6700 XT значительно более производительна.
Для Full HD производительность Radeon RX 6700 XT можно назвать избыточной — если не учитывать игры с трассировкой лучей и аномально низкую производительность Cyberpunk 2077. Большинство требовательных игр стабильно работают с частотой кадров выше 100 fps, позволяя воспользоваться преимуществами игровых мониторов с быстрой матрицей.
Radeon RX 6700 XT мы тестировали с процессором AMD Ryzen 3600 и материнской платой Aorus B550i PRO AX, предоставленными Gigabyte.
Материнская плата имеет формат mini-ITX, и одной из главных её особенностей стала система охлаждения SSD. M.2-cлот на лицевой стороне платы предназначен для NVMe-накопителей с интерфейсом PCIe 4.0, которые при работе могут нагреваться до 80 градусов и выше. У Aorus B550i PRO AX накопитель сверху и снизу зажимается алюминиевыми радиаторами (хотя термопрокладка предусмотрена на верхнем). Радиатор SSD соединён тепловой трубкой с большим радиатором чипсета и подсистемы питания для более эффективного отвода тепла.
Также у материнской платы предусмотрен Wi-Fi 6, LAN-порт на 2,5 Гбит/с и полная поддержка процессоров Ryzen 5000. Однако для нас ключевым моментом стало то, что к моменту написания обзора Gigabyte уже выпустила обновление BIOS, которое разблокировало функцию Resizable BAR (и Smart Access Memory) для чипов Ryzen 3000.
AMD Smart Access Memory (SAM) позволяет процессору напрямую обращаться к быстрой памяти видеокарты — раньше эта функция была доступна только для Radeon RX 6000 и Ryzen 5000, но с выходом RX 6700 XT производитель добавил поддержку и для более старых чипов. Справедливости ради, с выходом NVIDIA GeForce RTX 3060 функция Re-BAR заработала с Ryzen 3000, 5000 и даже чипами Intel, но, для AMD это всё равно важный шаг навстречу пользователям.
По данным «Яндекс.Маркета», AMD Ryzen 3600 был самым востребованным процессоров в России на протяжении всего 2020 года. Именно на него пришлось почти 10% от продаж процессоров в феврале 2021-го, поэтому расширенная совместимость именно с этим кристаллом представляет больше всего реальной ценности для пользователей.
Со временем список тайтлов с поддержкой Resizable BAR и SAM будет расти — её поддерживают все актуальные видеокарты, процессоры и игровые консоли, поэтому у разработчиков нет повода её игнорировать.
Прирост производительности от SAM очень сильно колеблется от игры к игре. В хорошо оптимизированной под железо AMD Assassin's Creed Valhalla средний fps вырос на 13,5%, а в Borderlands 3 — на 10%. При этом в большинстве других игр прирост составляет 2-3% или 1-2 fps.
AMD анонсировала собственный аналог NVIDIA DLSS для «бесплатного» повышения производительности вместе с видеокартами Radeon RX 6000, но до сих пор не раскрыла никаких подробностей о технологии. На недавнем брифинге для журналистов представитель компании отметил, что работа идёт, но пока никакой конкретики нет.
Мы продолжаем налаживать сотрудничество с разработчиками игр, чтобы обеспечить поддержку апскейлинга на видеокртах Radeon в большом выборе тайтлов. Мы подробнее расскажем о AMD FidelityFX Super Resolution, когда наступит подходящее время.
Судя по всему, апскейлинг Radeon потребует добавления поддержки со стороны разработчиков, как это происходит с DLSS, однако здесь это может стать проблемой — современные (и дорогие) видеокарты AMD значительно менее распространены и популярны, чем NVIDIA GeForce. С другой стороны, графические ускорители AMD, родственные RDNA 2, используются в Xbox Series и PlayStation 5, так что крест на заинтересованности разработчиков ставить пока рано.
Сейчас же улучшать производительность в играх остаётся при помощи фирменной технологии Radeon Boost на основе технологии Variable Rate Shading из пакета DirectX 12 Ultimate.
Суть проста: драйвер анализирует действия игрока и состав игровой сцены и определяет, где важные объекты, а где фон, на который никто не смотрит. Разрешение и детализация «ненужных» объектов снижается, чтобы освободить ресурсы системы для других задач.
Но на практике всё не так уж хорошо — в играх с видом от первого лица «важной» считается только небольшая область вокруг перекрестья прицела, поэтому при движении всё окружение выглядит нечётким.
И если в Borderlands 3 фильтр резкости Fidelity FX неплохо маскирует работу технологии, то в Cyberpunk 2077 нечёткие и покрытые «лесенками» объекты и персонажи в поле видимости отвлекают и раздражают. Иногда алгоритм «убивает» детализацию даже на руках о оружии персонажа, что совсем никуда не годится.
При этом производительность улучшается не всегда — в Borderlands 3 у меня получилось выгадать 5-8 fps в геймплее, а вот в Cyberpunk, где эти улучшения нужны больше всего, средняя частота кадров упала на 1-2 fps.
AMD Radeon RX 6700 XT делает ровно то, для чего её создавали — позволяет комфортно играть в современные AAA в разрешении 1440p. В соревновательных играх частота держится выше 144 fps даже в высоком разрешении, а в некоторых и вовсе превышает 200 кадров в секунду.
Smart Access Memory теперь работает с распространёнными процессорами и реально даёт хоть сколько-нибудь заметный прирост производительности, но пока далеко не везде. К тому же, технология больше не эксклюзивна для AMD — у NVIDIA и Intel тоже есть Resizable BAR.
А вот трассировка лучей и хитрые программные способы повышения производительности в сделку пока не входят: блоки для аппаратной трассировки справляются ощутимо хуже, чем RT-ядра NVIDIA, от Radeon Boost больше вреда, чем пользы, а апскейлинг Fidelity FX пока где-то далеко.
Но главными врагами Radeon RX 6700 XT, скорее всего, окажутся не конкуренты, а возможности AMD и ситуация на рынке. В период дефицита чипов и перегрузки мощностей TSMC производитель едва ли сможет обеспечить достаточное количество видеокарт для обеспечения спроса и геймеров, и майнеров, поэтому в первые месяцы после релиза едва ли стоит рассчитывать на неограниченную доступность по рекомендуемой цене.
Читаю обзор видюхи, которую я ни разу вживую не увижу
Рейтрейсинг? Он нам и нахуй не нужон энтот ваш рейтрейсинг!
Без рофлов, он реально нахуй не нужен. Побегал в 5-6 играх у кореша, с каменным еблом. А я человек которого легко удивить)
Куртки в красный цвет покрасить)
Реальная цена в России: 142 499 рублей
А вот и инсайды от перекупов
Окей, чекну как с производительностью в других обзорах. Совершенно не информативная статья с минимумом тестов, зачем?
UPD: на 3dnews нормальные тесты со сравнениями, в 1440р RX6700 обходит 3060ti только в думе и на грани погрешности в WD Legion. Я не фанат куртки если что, я фанат нормальных обзоров железа. Без сравнения с конкурентом в графиках, а так же с собственными старшими решениями красных (хотя бы с 6800), статья больше напоминает ситуацию "ммм, AMD выслали карточку, надо сделать обзор так, чтобы их не обидеть". Ну а "вот ссылки на тесты других карт" это нелепость и какое-то неуважение к читателям, сейчас я буду бегать по вкладкам и запоминать, сколько фпс в какой игре у разных моделей, или в мобильном приложении взад-вперед по ссылкам скакать.
Тут ещё стоит учитывать, что тесты должны быть сделаны на одной системе в одно время. Завтра на игру патч выпустят с +20% ФПС, а послезавтра в Винду устроят какую-нибудь фигню, которая ФПС будет жрать. И ещё много подобного
Эм
Сравнение с другими видеокартами (одной, лол) только в трех играх? Причем только одна из игр без лучей? В чем смысл такого теста? Допустим, у тебя нет карт, кроме 6700XT и 3060 Ti, окей, но сравни их хотя бы в большем количестве игр, чем три.
Infinity Cache - это наиболее заметное различие между недавно представленными видеокартами серии RX 6000 (RX 6800, RX 6800 XT и RX 6900) с Xbox SoC серии X GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР, также основанный на RDNA 2. ¿Но что такое Infinity Cache, для чего он нужен и как он работает? Мы расскажем вам все его секреты.
За несколько недель до презентации RX 6000 мы узнали о существовании этого огромного пула памяти внутри графического процессора, огромного, потому что мы говорим о самом большом кэше в истории графических процессоров с примерно 128 МБ емкости . Но AMD не дал много информации о нем, он просто рассказал нам о его существовании.

Вот почему необходимо подробное объяснение, чтобы понять, почему AMD поместила кэш такого размера в версию своей RDNA 2 для ПК.
Поиск бесконечного кэша

Первый момент, который необходимо понять, чтобы понять, какова функция компонента в аппаратном обеспечении, - это определить его функцию из его местоположения в системе.
С RDNA 2 - это эволюция RDNA Прежде всего, мы должны взглянуть на первое поколение текущей графической архитектуры AMD, из которой нам известны два чипа: Navi 10 и Navi 14.
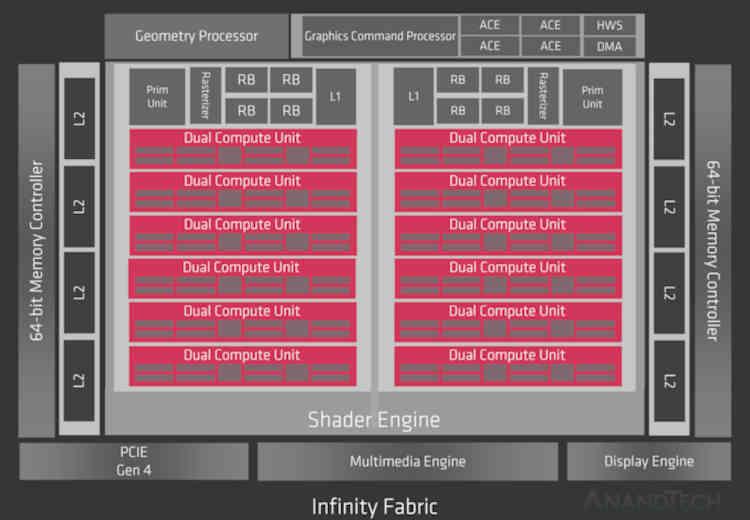
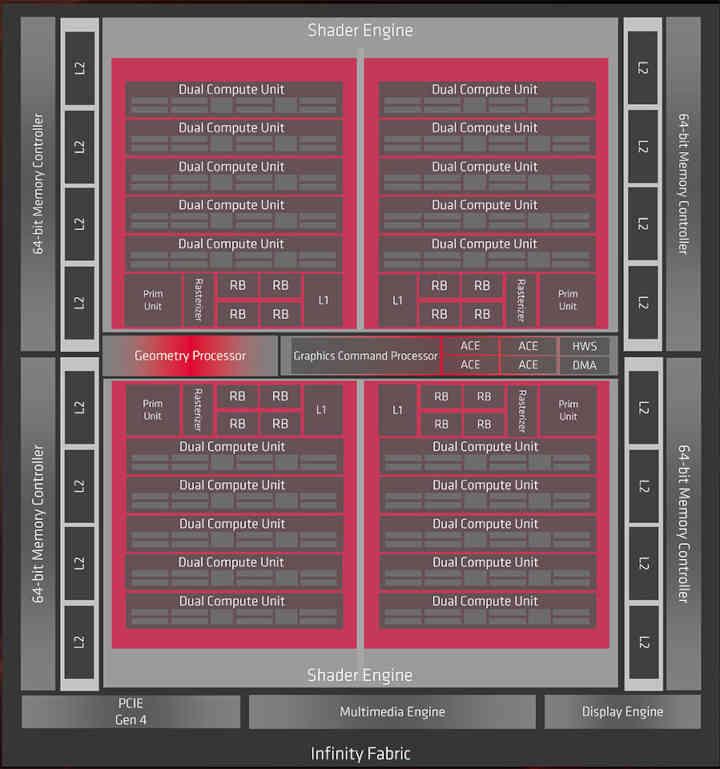
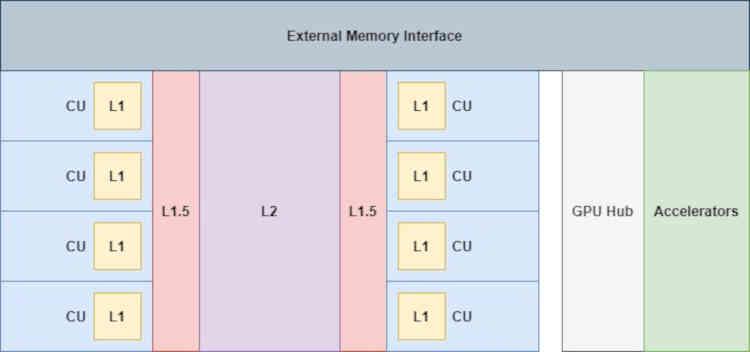
Что ж, если бы Infinity Cache был реализован в RDNA, он был бы в той части диаграммы, которая говорит о Infinity Fabric, поэтому на уровне организации кеша мы бы пошли от этого:
Если ускорители, подключенные к концентратору графического процессора (видеокодек, контроллер дисплея, диски DMA и т. Д.), Не имеют прямого доступа к кешам, даже к кеш-памяти L2.
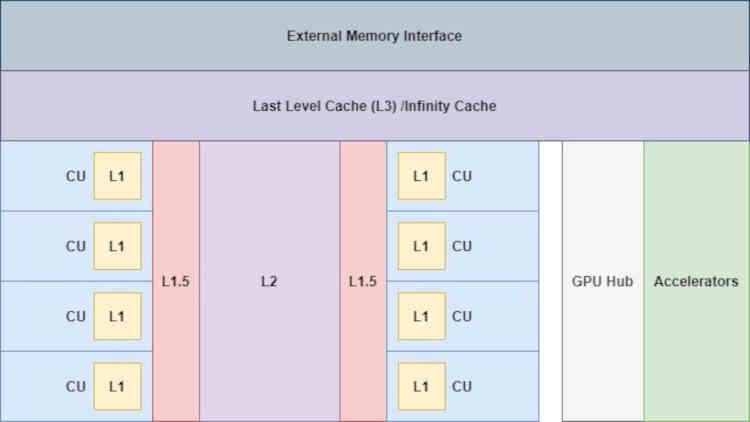
С добавлением Infinity Cache все уже «немного» меняется, так как теперь у ускорителей есть доступ к этой памяти,
Это очень важно, особенно для Display Core Next, которое отвечает за чтение итогового буфера изображения и передачу его на соответствующий порт дисплея или интерфейс HDMI, чтобы изображение отображалось на экране, это важно для уменьшения доступа во VRAM этими устройствами.
A new level of cache: the Infinity Cache

Since it is an additional level of cache, the Infinity Cache has to be connected to the L2 cache directly, which is the previous level in the cache hierarchy, this is confirmed to us by AMD itself in a footer:
Measurement calculated by AMD engineers, on a Radeon RX 6000 series card with 128MB AMD Infinity Cache and 256-bit GDDR6. Measuring the average AMD Infinity Cache success rates in 4k games of 58% across major game titles, multiplied by the theoretical maximum bandwidth of the 16 64B AMD Infinity Fabric channels connecting the cache to the graphics engine at a boost frequency up to 1.94 GHz.
The GPU used in the RX 6800, RX 6800 XT and RX 6900 is Navi 21 which has a 256-bit GDDR6 bus, ergo it has 16 channels and hence the 16 partitions of Caché L2 being each connected to a partition of the Infinity Cache.
As for the issue of “hit rates” of 58%, it is more complicated and is what we will try to explain below.
Вспоминая систему кеширования RDNA
В RDNA кэши связаны друг с другом следующим образом:

Кэш L2 подключен снаружи к 16 каналам по 32 байта / цикл каждый, если мы посмотрим на диаграмму Navi 10, то вы увидите, как этот графический процессор имеет примерно 16 разделов кэша L2 и 256-битная шина GDDR6 к которому они подключены.
Имейте в виду, что GDDR6 использует 2 канала на чип которые работают параллельно, каждый из 16 бит.
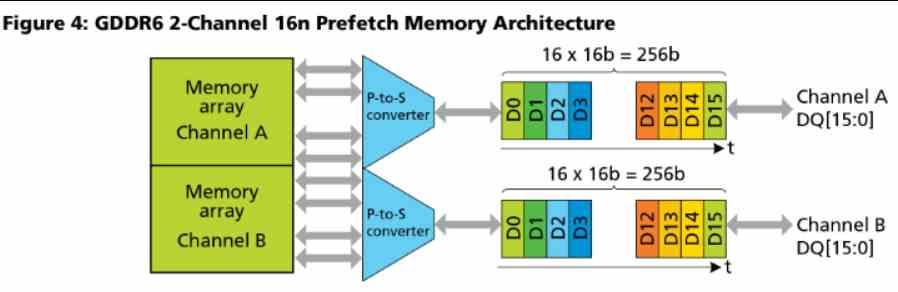
Другими словами, количество разделов кэша L2 в архитектурах RDNA равно количеству 16-битных каналов GDDR6, подключенных к графическому процессору. В RDNA и RDNA 2 размер каждого раздела составляет 256 КБ, поэтому Xbox Series X с 320-битной шиной и, следовательно, с 20 каналами GDDR6 имеет около 5 МБ кэша L2.
DSBR, the Tile Caching on AMD GPUs
AMD, on the other hand, during all generations of the GCN architecture prior to Vega, connected the Render Backends (RB) directly to the memory controller.

But starting with the AMD Vega, he made two changes in the architecture to add Tile Caching to his GPUs, the first of them was to renew the raster unit, which he renamed DSBR, Draw Stream Binning Rasterizer.

The second change was that they connected the raster unit and ROPS to the L2 cache, a change that still exists in RDNA and RDNA 2.
Tile Caching on NVIDIA GPUs

Before continuing with the Infinity Cache we have to understand the reasons for its existence and for this we have to look at how GPUs have evolved in recent years.
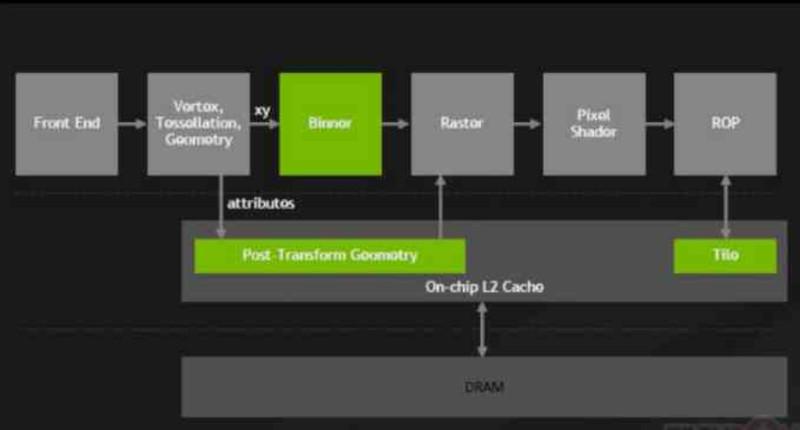
Starting with the NVIDIA Maxwell, GeForce 900 Series, NVIDIA made a major change in their GPUs that they called Tile Caching, whose change involved connecting the ROPS and the raster unit to the L2 cache.
With this change, the ROPS stopped writing to the VRAM directly, the ROPS are common in all GPUs and are responsible for creating the image buffers in memory.
Thanks to this change, NVIDIA was able to reduce the energy impact on the memory bus by reducing the amount of transfers that were made to and from the VRAM and with this, NVIDIA managed to gain energy efficiency from AMD with the Maxwell and Pascal architectures.
Locating the Infinity Cache
The first point that is necessary to understand what the function of a piece is within the hardware is to deduce its function from its location within the system.
Since RDNA 2 is an evolution of RDNA , first of all, we have to take a look at the first generation of the current AMD graphics architecture, of which we know two chips that are Navi 10 and Navi 14.
Well, if the Infinity Cache had been implemented in RDNA, it would be in the part that says Infinity Fabric of the diagram, so at the cache organization level we would go from this:
Where the accelerators connected to the GPU Hub (the video codec, the display controller, the DMA drives, etc.) have no direct access to the caches, not even the L2 cache.
With the addition of the Infinity Cache things already change “a little”, since now the accelerators have access to this memory,
This is very important, especially for the Display Core Next, which is responsible for reading the final image buffer and transmitting it to the corresponding Display Port or HDMI interface so that the image is displayed on the screen, this is important in order to reduce accesses to VRAM by these units.
Конфликт утилит Infinity Cache и L3 Cache ядер Zen
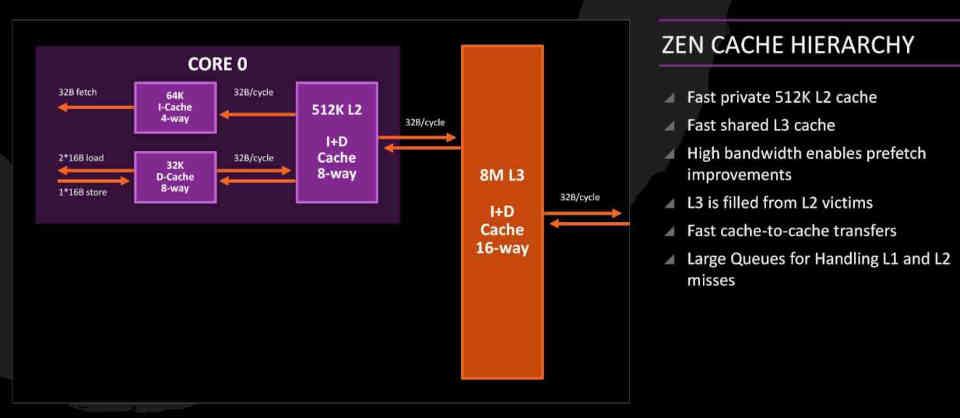
И кэш L3 ядер Zen, и кэш Infinity в архитектуре RDNA 2 выполняют одну и ту же функцию, поскольку оба являются кешами жертв и, следовательно, имеют одинаковую функциональность. Это означает, что когда дело доходит до сбора данных и инструкций для каждого из соответствующих процессоров, они отвечают за сбор строк кэша, отброшенных предыдущим уровнем кэша.
В чем проблема? Чтобы понять это, мы должны принять во внимание, куда бы пошел Infinity Cache, если бы он был реализован как в SoC, так и в AMD. ЦП, непосредственно перед контроллером памяти и, следовательно, в северном мосту, как предполагаемый кэш L4.
В чем конфликт? Нет смысла в том, что существует кэш жертвы другого кеша жертвы, поскольку в этом случае бесконечный кэш будет подключен к кешу L3 ядер Zen, что вызывает конфликт функций между обеими сторонами.
Утилита DSBR или Tile Caching
Кэширование плиток или DSBR эффективно, потому что оно упорядочивает геометрию сцены в соответствии с ее положением на экране перед ее растрированием, это было важным изменением, поскольку графические процессоры до реализации этого метода заказывал уже текстурированные фрагменты непосредственно перед отправкой их в буфер изображения.
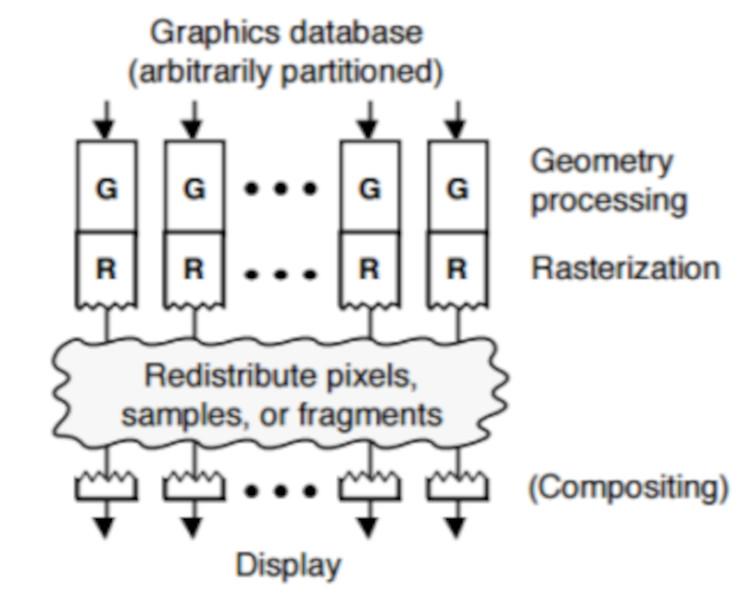
В тайловом кэшировании / DSBR делается следующее: упорядочить полигоны сцены до того, как они будут преобразованы во фрагменты блоком растеризации.
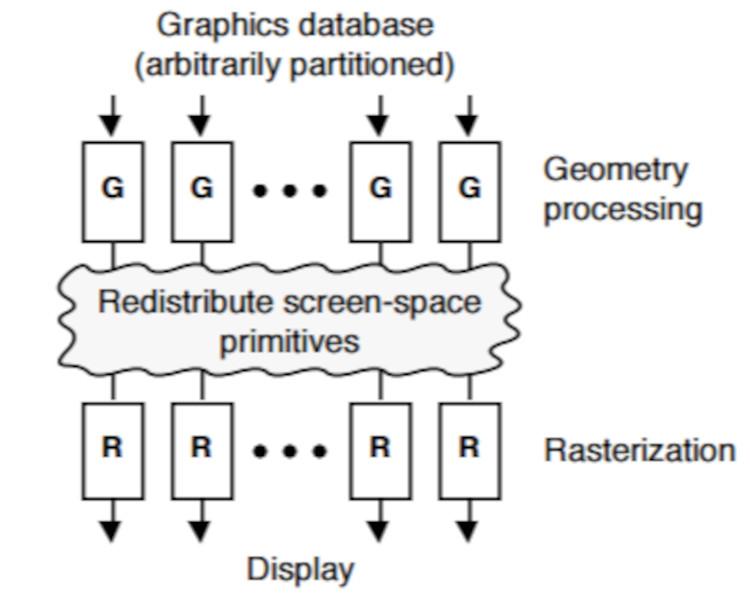
В кэшировании листов многоугольники упорядочиваются в соответствии с их положением на экране в плитках, где каждая плитка представляет собой фрагмент размером n * n пикселей.
Одним из преимуществ этого является то, что он позволяет заранее удалить невидимые пиксели фрагментов, которые непрозрачны при нахождении в одной и той же ситуации. То, что нельзя сделать, если элементы, составляющие сцену, упорядочены после текстурирования.
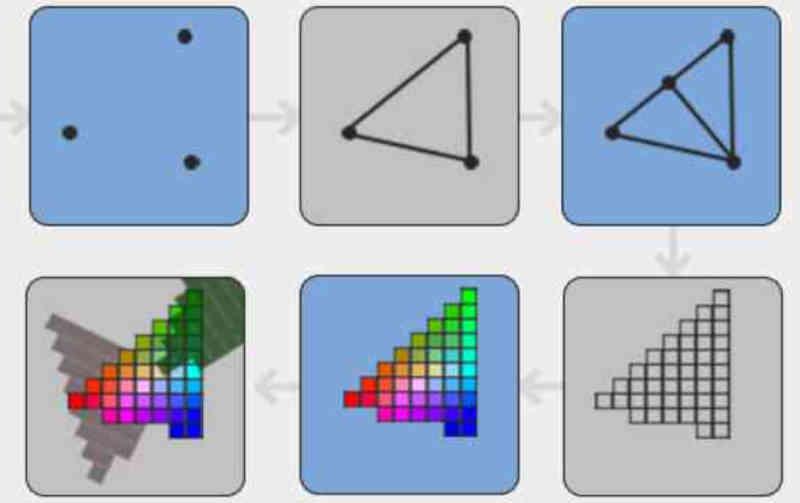
Это избавляет GPU от траты времени на лишние пиксели и повышает эффективность GPU. Если вас это сбивает с толку, достаточно просто вспомнить, что на протяжении всего графического конвейера различные примитивы, составляющие сцену, принимают разные формы на разных ее этапах.
Кэширование плитки на графических процессорах NVIDIA
Прежде чем продолжить работу с Infinity Cache, мы должны понять причины его существования, и для этого мы должны посмотреть, как развивались графические процессоры в последние годы.
Начиная с NVIDIA Maxwell, GeForce 900 Series, NVIDIA внесли серьезные изменения в свои графические процессоры, которые они назвали Tile Caching, изменение которых включало подключение ROPS и растрового блока к кеш-памяти L2.
С этим изменением ROPS перестали писать во VRAM напрямую, ROPS являются общими для всех графических процессоров и отвечают за создание буферов изображений в памяти.
Благодаря этому изменению NVIDIA смогла снизить энергетическое воздействие на шину памяти за счет уменьшения количества передач, которые выполнялись в и из VRAM, и благодаря этому NVIDIA смогла добиться от AMD энергоэффективности с архитектурами Maxwell и Pascal.
The utility of DSBR or Tile Caching
The Tile Caching or DSBR is efficient because it orders the geometry of the scene according to its position on the screen before it is rasterized, this was an important change since the GPUs before the implementation of this technique ordered the already textured fragments just before sending them to the image buffer.
In Tile Caching / DSBR what is done is to order the polygons of the scene before they are converted into fragments by the rasterization unit.
In Tile Caching, polygons are ordered according to their screen position in tiles, where each tile is a fragment of n * n pixels.
One of the advantages of this is that it allows to eliminate beforehand the non-visible pixels of the fragments that are opaque when being in the same situation. Something that cannot be done if the elements that make up the scene are ordered after texturing.
This saves the GPU from wasting time on superfluous pixels and improves the efficiency of the GPU. In case you find this confusing, it is as simple as remembering that throughout the graphical pipeline the different primitives that make up the scene take different forms during the different stages of it.
Infinity Cache - это кэш жертвы
Жертва Каше idea - это наследие процессоров под архитектурой Zen, адаптированное к RDNA 2.
В ядрах Zen кэш L3 - это то, что мы называем Victim Caché, они отвечают за сбор сброшенных строк кеша из L2 вместо того, чтобы быть частью обычного кэш иерархия. То есть в ядрах Zen данные, поступающие из Оперативная память не следует по пути RAM → L3 → L2 → L1 или наоборот, а вместо этого следует по пути RAM → L2 → L1, поскольку кеш L3 действует как Victim Caché.
В случае с Infinity Cache идея состоит в том, чтобы спасти линии L2 Cache GPU без доступа к VRAM , что позволяет значительно снизить потребление энергии на инструкцию и, следовательно, достичь более высоких скоростей. Часы.
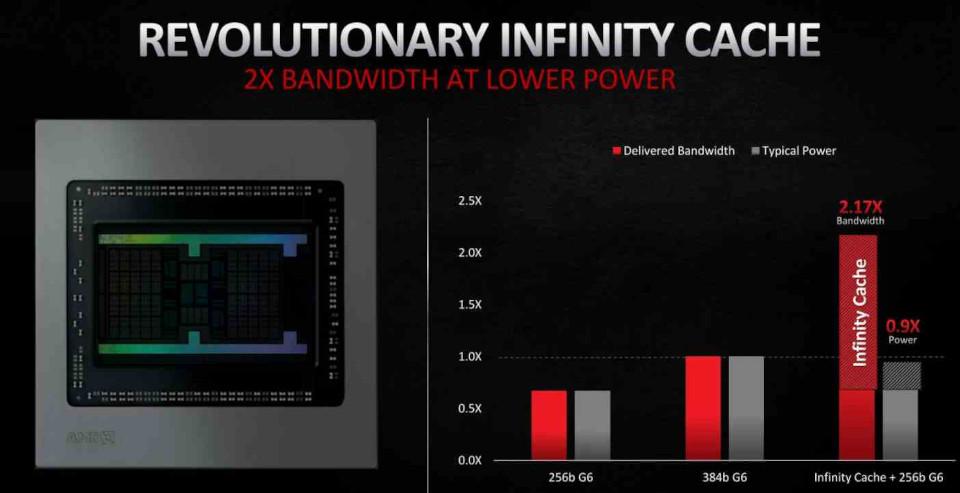
Однако, хотя емкость 128 МБ может показаться очень высокой, ее недостаточно, чтобы избежать попадания всех отброшенных строк во VRAM, поскольку в лучшем случае она удается спасти только 58% . Это означает, что в будущих итерациях его архитектуры RDNA весьма вероятно, что AMD увеличит емкость этого Infinity Cache .
The Infinity Cache is the most notable difference between the recently introduced RX 6000 series graphics cards (RX 6800, RX 6800 XT and RX 6900) with the Xbox Series X SoC GPU, also based on RDNA 2. ¿ But what exactly is the Infinity Cache, what is its use and how does it work? We are going to tell you all its secrets.
Since the weeks before the presentation of the RX 6000 we have known of the existence of this huge memory pool inside the GPU, huge because we are talking about the largest cache in the history of GPUs with about 128 MB of capacity . But AMD has not given much information about it, it has simply told us about its existence.
That is why a detailed explanation is necessary to understand why AMD has placed a cache of such size in the version of its RDNA 2 for PC.
А как насчет встроенных графических процессоров?
Поскольку мы видели, что Infinity Cache не может использоваться в качестве дополнительного кеша ядер Zen, единственный ответ, который остается, - это Infinity Cache ядер RDNA 2, интегрированных в SoC, на данный момент AMD не выпустила ни одной SoC с интегрированный графический процессор с архитектурой RDNA, из-за сроков запуска мы не думаем, что увидим первое поколение RDNA.
В случае iGPU имеет смысл интегрировать Infinity Cache, который расположен между контроллером памяти и графическим процессором, но это будет исключительно для использования графического процессора в SoC.
В этой небольшой обзорной статье я бы хотел кратко рассмотреть основные особенности этой новой архитектуры и посмотреть на консоли через призму этой архитектуры. В этих статьях я просто сгруппирую известную информацию и разбавлю ее своими комментариями.
Для начала хочу сразу убрать холиварную часть о том полная ли поддержка архитектуры RDNA 2 в консолях Sony. Без какой либо официальной документации, заявлений и тестов сложно об этом говорить поэтому этот вопрос оставим на потом. Также на самом сайте AMD нет четкой формулировки. Формулировка сделана максимально нейтрально для обейих консолей чтобы избежать какого-либо сравнения
Теперь когда мы с этим покончили я хочу сказать что мне неинтересны консольные войны, каждый выберет то что емубольше нравится и то что ему более удобно и я буду рад за любой выбор. Я просто хочу разобраться в этом так как мне это интересно и я люблю технологии. Теперь пойдем по порядку:
Одна из важных особенностей архитектуры RDNA2 это увеличение производительности на ватт, в целом удалось на в среднем 52% увеличить производительность на ватт. Что это может значить для нас как для игроков? В целом…мало что. Потому что эта характеристика говорит только о внутреннем относительном улучшении а не о реальной производительности в играх. Для этого нужны конкретные тесты. Текущие тесты в играх пока еще мало о чем нам говорят так как все мы прекрасно знаем о тестах на презентациях и сколько там могут умалчивать. Также тесты были проведены на избранном количестве игр, что также дает ограниченную картину, также в тестах использовались разные версии DirectX(не то чтобы это что-то значило на самом деле по большому счету, но в определенных играх это может иметь значение).
Прежде чем приступить к этому пункту я думаю следует сначала рассказать а что же такое вообще кэш процессора и зачем он нужен? Кэш для процессора нужен для того чтобы уменьшить время доступа к памяти. Кэш процессора обычно небольшой и имеет несколько уровней чем выше уровень тем больше его объем и тем меньше скорость. В кэш помещаются копии часто используемых участков памяти чтобы процессор обрабатывая информация брал ее из него и только если что-то пошло не так и данных не оказалось делать запрос в оперативную/видео память(это называется промахом кэша, когда кеш найдет это хит или попадание) таким образом мы сохраняем большое количество времени на запрос количества данных, так как какой бы быстрой не была ваша оперативная или видео память, кэш всегда будет быстрее.
Но кэш это достаточно дорогое удовольствие:
- Во первых он занимает драгоценное место на кристале. Чем больше кристал тем больше вероятность брака и тем дороже выходит производство
- Во вторых у центрального процессора очень много задач которые он может выполнять и чтобы ядра эффективно работали параллельно на кристале самый быстрый кэш дают каждому ядру свой. Обычно только кэш третьего уровня является общим для всех ядер но он и самый медленный.
Но вернемся к видеокартам. У видеокарт обычно достаточно простые задачи(естественно сравнивая с центральными процессорами которые делают все и сразу) и их операции крайне легко могут быть распараллелены. собственно для этого они созданы, чтобы обрабатывать математику стоящую за отрисовкой параллельно и за счет этого быстро.
Обычно кеш видеокарт не большой так как процессоров очень много и им не нужен большой запас. Даже L2(кэш второго уровня) кеш у последних видеокарт RTX 3080 всего 5 мегабайт а у предыдущих топовых потребительских видеокарт AMD всего 4 мегабайта.
AMD Infinity Cache передлагает 128 мегабайт кэш памяти. Достоверно пока неизвестно второго ли это уровня кэш или же AMD сделала кэш третьего уровня(обычно в видеокартах сейчас он не используется). Но судя по размеру маловероятно что это кэш второго уровня.
Так что же он все таки может нам дать? Такой большой кэш третьего уровня может использоваться одновременно всеми ядрами GPU и кэшировать уже нечто большее что может крайне положительно сказаться на операциях операциях с крайне часто используемыми данными от кадра к кадру.
Но тут всплывают очень странные маркетинговые данные. AMD утверждает что это делает пропускную способность память более эффективной в 3.25 раза. Всегда когда видите слово «эффективность» спрашивайте себя "В чем она измеряется. В данном случае за маленькой припиской скрывается очень странная формула:
Измерения произведены компанией AMD, на видеокартах Radeon RX 6000 серии с 128MB AMD Infinity Cache и видеопамятью GDDR6 с 256-битнной шиной памяти. Измерялся игровой процесс в разрешении 4к, где хитрейт(частота попаданий в кэше) составляла 58% среди топовых игровых тайтлов. Это значение умноженное на теоретический пик пропускной способности 16 64B каналов AMD Infinity Fabric соединяющий кэш к графическому движку на разогнанной частоте до 1.94 ГГц
Выходит очень странная картина. На разогнанной частое при пиковой теоретической пропускной способности в избранных играх. И хитрейт умноженный на пропускную способность плюс пропускная способность видеопамять почему-то сравнивается просто с пропускной способностью памяти. Что лично мне кажется крайне странным.
Не поймите меня неправильно, безусловно это даст прирост производительности и возможности. Но маркетинг очень странный.
Вывод: Нужно больше тестов в разных играх при разной нагрузке и разном разрешении чтобы решать на сколько это больше даст для текущего поколения а также я бы послушал экспертное мнение о том на сколько важен будет такой кэш в современных тайтлах.
Да, были споры о том будет ли аппаратная поддержка ускорения рейтрейсинга. Более того были споры будет ли у компании Sony аппаратная реализация (да действительно были и такие)
Крайне маловероятно что у Sony нет аппаратной поддержки лучей, так как сложно представить даже то что показали сейчас эти отражения сделаны на голом GPU это была бы очень большая потеря производительности ради маркетинга.
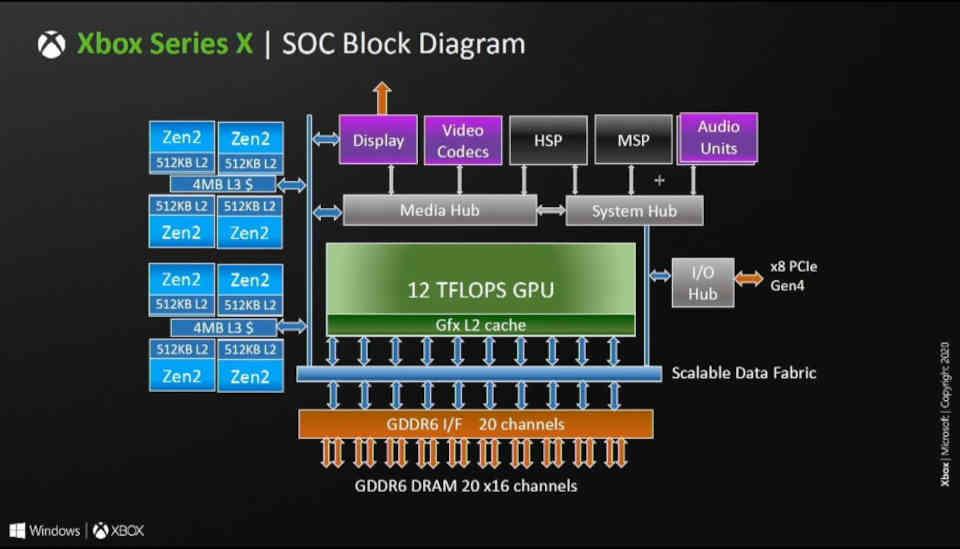
Но важнее вот что на сайте AMD (на скриншоте выше) сказано что будет один ускоритель лучей на один вычислительный блок. И вспоминаем что у Sony их всего 36 против 56 у Microsoft( 52 активных, 4 отключено по пока неизвестным причинам зарезервированы ли они или же это защита от брака)
Таким образом можно предположить что рейтрейсинг на консоли XBox будет гораздо лучше. Но опять же это всего-лишь предположение и следует делать тесты. Также есть новость о том что Сони разрабатывала свой некоторые особые алгоритмы для рейтрейсинга.
Tile Caching or DSBR is not equivalent to Tile Rendering
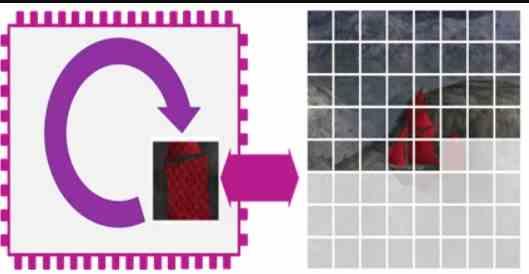
- Tile renderers store scene geometry in memory, order it, and create screen lists for each tile. This process does not occur in the case of Tile Caching or DSBR.
- In Tile Rendering, the ROPS are connected to scratchpad memories outside the cache hierarchy and do not empty their content into the VRAM until that tile has been 100% finished, so the hit rates are 100%.
- In the Tile Caching / DSBR, since the ROPS / RBs are connected to the L2 Cache, at any time the cache lines from L2 to RAM may be discarded, so there is no guarantee that 100% of the data is in the L2 cache.
Since there is a high probability of cache lines ending up in VRAM, what AMD has done with the Infinity Cache is to add an additional cache layer that collects the discarded data from the GPU’s L2 cache.
Кэширование листов или DSBR не эквивалентно рендерингу листов
- Рендереры листов хранят геометрию сцены в памяти, упорядочивают ее и создают списки экранов для каждой плитки. Этот процесс не происходит в случае тайлового кэширования или DSBR.
- В рендеринге плитки ROPS подключаются к блокам памяти вне иерархии кеша и не сбрасывают свое содержимое во VRAM, пока эта плитка не будет завершена на 100%, поэтому процент попаданий составляет 100%.
- В тайловом кэшировании / DSBR, поскольку ROPS / RB подключены к кэшу L2, в любой момент строки кэша из L2 в RAM могут быть отброшены, поэтому нет гарантии, что 100% данных находятся в кэше L2.
Поскольку высока вероятность того, что строки кэша окажутся в VRAM, то, что AMD сделала с Infinity Cache, - это добавление дополнительного уровня кеша, который собирает отброшенные данные из кеша второго уровня графического процессора.
The Infinity Cache is a Victim Cache
The Victim Caché idea is a legacy of CPUs under Zen architectures that has been adapted to RDNA 2.
In the Zen cores the L3 Cache is what we call a Victim Caché, these are in charge of collecting the cache lines discarded from the L2 instead of being part of the usual cache hierarchy. That is to say, in Zen cores the data that comes from RAM does not follow the path RAM → L3 → L2 → L1 or vice versa, but instead follows the path RAM → L2 → L1 since the L3 cache acts as Victim Caché.
In the case of the Infinity Cache, the idea is to rescue the lines of the L2 Cache of the GPU without having to access the VRAM , which allows the energy consumed per instruction to be much lower and therefore higher speeds can be achieved. clock.
However, although the capacity of 128 MB may seem very high, it does not seem enough to avoid that all the discarded lines end up in the VRAM, since in the best of cases it only manages to rescue 58% . This means that in future iterations of its RDNA architecture it is very likely that AMD will increase the capacity of this Infinity Cache .

Реализация Бесконечный кэш в графических процессорах с архитектурой RDNA 2 - одна из новинок нового AMD GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР Архитектура, но возникает вопрос: это что-то эксклюзивное для графических процессоров AMD или мы собираемся увидеть процессоры Ryzen, как в процессорах, так и в SoC?
Несколько месяцев назад просочилась диаграмма патента AMD, которая соответствовала процессору семейства AMD Ryzen, по крайней мере, мы предполагаем, но с особенностями отображения кэша четвертого уровня на диаграмме, что-то беспрецедентное для процессоров AMD на основе такой архитектуры.
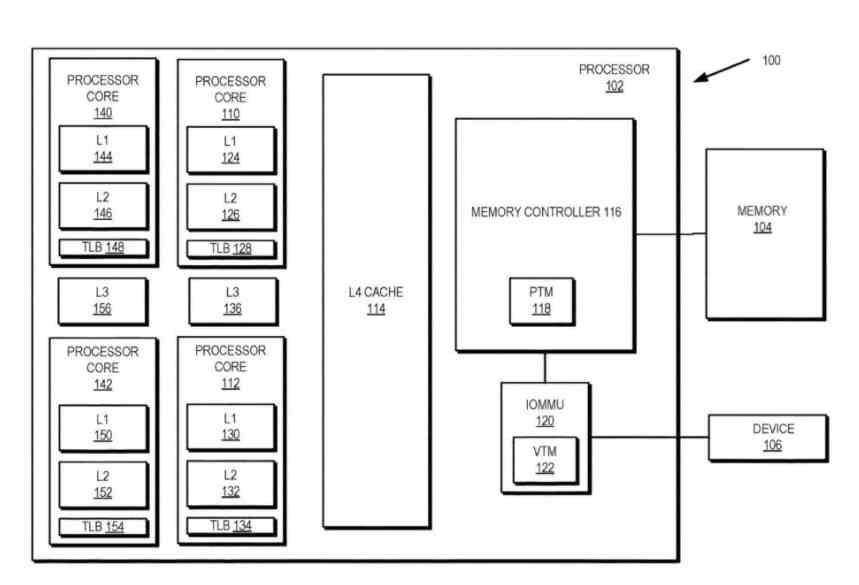
В то же время появление Infinity Cache в графических процессорах AMD вызывает два вопроса: увидим ли мы Infinity Cache, реализованную в процессорах AMD Ryzen от AMD, будет ли он использоваться в качестве кеша L4 или каким-либо другим образом?
Remembering the RDNA cache system
In RDNA, the caches are connected to each other in the following way:
The L2 cache is connected to the outside to 16 channels of 32 Bytes / cycle each, if we look at the Navi 10 diagram then you will see how this GPU has about 16 L2 Cache partitions and a 256-bit GDDR6 bus to which they are connected.
Keep in mind that GDDR6 uses 2 channels per chip that operate in parallel, each of 16 bits.
In other words, the number of L2 cache partitions in RDNA architectures is equal to the number of 16-bit GDDR6 channels that are connected to the graphics processor. In RDNA and RDNA 2 each partition is 256 KB, this is the reason why the Xbox Series X that has a 320-bit bus and therefore 20 GDDR6 channels has about 5 MB of L2 Cache.
DSBR, тайловое кэширование на графических процессорах AMD
AMD, с другой стороны, на протяжении всех поколений архитектуры GCN до Vega подключала серверные модули рендеринга (RB) напрямую к контроллеру памяти.
Но, начиная с AMD Vega, он внес два изменения в архитектуру, чтобы добавить тайловое кэширование в свои графические процессоры, первое из них заключалось в обновлении растрового блока, который он переименовал в DSBR, Draw Stream Binning Rasterizer.
Второе изменение заключалось в том, что они подключили растровый блок и ROPS к кэш-памяти L2, изменение, которое все еще существует в RDNA и RDNA 2.
Новый уровень кеширования: Infinity Cache
Поскольку это дополнительный уровень кеша, Infinity Cache должен быть подключен напрямую к кеш-памяти L2, который является предыдущим уровнем в иерархии кеша, это подтверждается нам самой AMD в нижнем колонтитуле:
Измерения рассчитаны инженерами AMD на карте серии Radeon RX 6000 с 128MB AMD Infinity Cache и 256-битный GDDR6. Измерение среднего показателя успешности AMD Infinity Cache в играх 4K, равного 58% для основных игр, умноженного на теоретическую максимальную пропускную способность 16 64-битных каналов AMD Infinity Fabric подключение кэша к графическому движку с частотой разгона до 1.94 ГГц.
В RX 6800, RX 6800 XT и RX 6900 используется графический процессор Navi 21, который имеет 256-битную шину GDDR6, следовательно, он имеет 16 каналов и, следовательно, 16 разделов Caché L2, каждый из которых подключен к разделу Infinity Cache.
Что касается вопроса о «процентных ставках» 58%, то он более сложный, и мы постараемся объяснить его ниже.
Конфликт подключения Infinity Cache с ядрами Zen
Если мы посмотрим на Infinity Cache графического процессора Navi 21, мы обнаружим, что всего имеется 16 разделов, подключенных на одном конце к 16 разделам кэша L2 под 64-байтовой / тактовой шиной для каждого раздела, а на другом конце - к 16. каналы GDDR6.
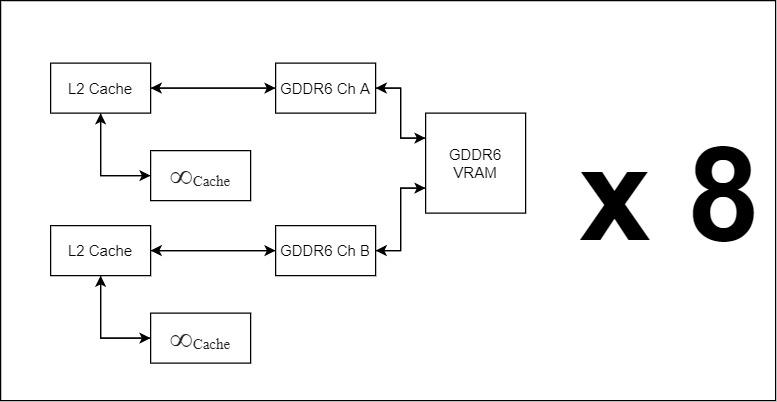

Таким образом, в конфигурации с CCD у вас будет только один раздел, один с двумя разделами и 2 CCD, а в крайнем случае будет что-то вроде AMD Epyc с 8 CCD, которые будут иметь 8 разделов. Как правило, размер кэша увеличивается с каждым дополнительным уровнем, и он всегда в два раза превышает сумму предыдущего уровня кэша.
Емкость одной ПЗС-матрицы Zen 3 составляет 32 МБ кэш-памяти третьего уровня, размер отдельного раздела кэша бесконечности составляет 3 МБ, что намного меньше, чем то, что потребуется для работы в качестве кэша четвертого уровня процессора Zen, поэтому при подключении доказано, что Infinity Cache не может функционировать как L8 Cache процессора с процессором Zen.
Читайте также: