
Что такое файл prophet
Почти каждая компания хочет ответить, где они будут через неделю / месяц / год.
Ответы на эти вопросы могут быть полезны при планировании инфраструктуры компании, ключевых показателей эффективности (ключевых показателей эффективности) и рабочих целей.
Следовательно, использование инструментов прогнозирования данных является одной из наиболее распространенных задач, которые задаются профессионалами в области данных.
Одним из инструментов, который недавно был выпущен в качестве открытого источника, является пакет прогнозирования временных рядов Facebookпророк, Доступная как для R, так и для Python, это относительно простая в реализации модель с некоторыми необходимыми опциями настройки.
В этом посте я рассмотрю Prophet и последую за ним простым примером кода R. Этот поток кода сильно вдохновленофициальное руководство пользователя пакета,
Мы будем использовать открытый набор данных, извлеченный из викишарка, содержащего ежедневные входы данных на страницу статьи LeBron James Wikipedia. Далее мы будем строить ежедневные прогнозы на основе исторических данных.
* Викишарк был закрыт после выхода статьи. Вы можете использовать другой полезный сайт дляполучить данные,
Этап 5 - Проверка компонентов модели
не отставая от простоты, легко взглянуть на компоненты модели. Отображение общей тенденции, недельной и годовой сезонности.

Этап 2 - загрузка набора данных

Для нашего примера кода мы преобразуем данные и используем журнал входов. Это поможет нам понять визуализации прогноза.
Использование пророка для обнаружения аномалий
Следующим шагом, который, я надеюсь, разработчики сделают, будет использование этого пакета и его использование для обнаружения аномалий для данных временных рядов.Предыдущие пакетыпредлагают такую функциональность, но сильно зависят от структуры данных и строгой сезонности.
Давайте используем существующую модель для отображения аномалий в данных. Мы сравним исходные значения (y) с предсказанными значениями модели (yhat) и создадим новый столбец с именемdiff_values.
Чтобы лучше обобщить обнаружение аномалий, мы также добавим нормализованные значения diff, представляющие процентное отличие от фактических значений.
Давайте продолжим и визуализируем нормализованные значения различий во времени.

Большинство прогнозов довольно близки к фактическим значениям, поскольку график имеет тенденцию перемещаться вокруг значения 0. Мы также можем спросить, какой процент точек данных являются аномалиями, отфильтровав абсолютные значения столбца.diff_values_normalized.Установка порога, с которого точка данных считается аномалией, является одним из способов ее рассмотрения. В этом примере его 10%
Мы получаем 0,02, что указывает на то, что 2% точек данных являются аномалиями на основе данного порога.
Что представляет собой стандартный NFO-файл?
Вообще, стандартные файлы этого типа являются объектами, содержащими информацию о системе и метаданные, закодированные в формат XML.

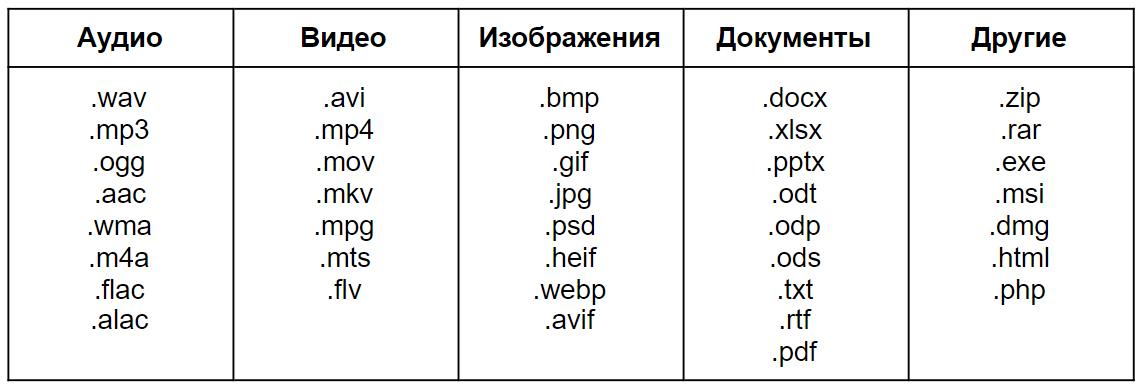
Программа, открывающая NFO-файлы, также является системным инструментом, который обычные юзеры вряд ли будут использовать. Это утилита msinfo32.exe, обеспечивающая доступ к описательной части «железных» и программных компонентов.
Этап 8 - Больше функциональности
На данный момент мы видим простоту и надежность, которые разработчики имели в виду при создании этого пакета. Некоторые дополнительные функции, которые я не показывал, но их следует использовать:
- Изменение масштаба сезонности и эффекта праздников
- Картирование критических точек изменения тренда
- Редактирование интервалов неопределенности
Пример PyInstaller
Не всегда подобный подход работает для приложений, которые используют более сложную структуру исполняемого файла. Рассмотрим файл, который был создан с помощью PyInstaller — пакет, который позволяет преобразовать Python скрипт в исполняемый файл. При генерации исполняемого файла создается архив, который содержит виртуальную машину Python и все необходимые библиотеки. Сам исходный код приложения при этом преобразуется в байт код и его нельзя дезассемблировать.
Попробуем все же получить что-то читаемое. Создадим простое приложение на Python и упакуем с помощью PyInstaller. Исходный код приложения:
Установим пакет pyInstaller и создадим exe файл:
Итак, проведем сбор информации о том, что в итоге получилось. У нас есть архив, который должен запустить виртуальную машину, и код, который мы записали в виде скрипта. Попробуем восстановить исходник и просто его прочесть даже без запуска.
После выполнения команд выше, у вас должна создаться директория ./dist/test.exe . Откроем последовательно файл с помощью pyinstallerextractor и uncompile3 :

Наш скрипт находится в директории, которая создается в результате распаковки. Наименование файла должно соответствовать названию exe файла. В нашем случае это test.pyc . Откроем его в hiew :

Декомпиляция стандартными средствами невозможна, так как инструменты просто не умеют работать с байткодом Python. Применим специализированный инструмент — uncompile6 .
Наверняка многие пользователи компьютерных программ, работающих под Windows, могли видеть специфичные объекты в виде файлов с расширением .nfo. Посмотрим, что собой представляет NFO-файл, чем открыть его и для чего он нужен. Как правило, основными являются всего два варианта, о которых далее и пойдет речь.
Этап 3 - Изучение данных

Мы можем видеть, что данные за 2014–01–01 гг. И до 2016–12–31 гг. С некоторыми годовыми пиками сезонности с апреля по июнь.
Инструментарий и настройка ОС
Для тестов будем использовать виртуальную машину под управлением ОС Windows. Инструментарий будет содержать следующие приложения:
установленный по умолчанию плагин x64dbg Scylla;
Самый быстрый и простой способ провести распаковку любого исполняемого файла — применить отладчик. Но так как мы будем также рассматривать язык программирования Python, то может понадобится проект:
uncompile6 проект, который позволяет разобрать байткод виртуальной машины Python;
pyinstallerExtractor инструмент для распаковки архива pyInstaller.
Вместо итога
Как видно из всего вышесказанного, проблема открытия файлов NFO решается достаточно просто. В самом простом случае, даже если пользователь не знает, как поступить, просмотр содержимого проще всего произвести с помощью обычного «Блокнота». Если по каким-то причинам файл все равно не открывается, можно попытаться выбрать приложение из списка наиболее подходящих вручную, а в Windows 10 - обратиться к разделу магазина, где можно будет подыскать что-то наиболее приемлемое.
Об особенностях разреженных файлов, их преимуществах и ограничениях мы расскажем более подробно в данном обзоре.
По умолчанию, разреженные файлы являются специальным форматом представления, в котором часть цифровой последовательности заменена сведениями о ней (сформирован перечень дыр), что в свою очередь позволяет гораздо эффективнее задействовать возможности файловой системы. Информация об отсутствующих последовательностях располагается напрямую в метаданных файловой системы, а не занятый высвободившийся объем запоминающего устройства будет использоваться для записи по мере надобности. Такой подход значительно сокращает объем исходного файла и экономит пространство накопителя.
Разреженные файлы распознаются многими основными файловыми системами, задействованными при работе в Windows, Linux и MacOS.
Как и многие типы файловой организации, разреженные файлы обладают отличительными особенностями, предлагающими пользователям как выгоду, так и отдельные неудобства. К приоритетным выгодам безусловно относится эффективное использование дискового пространства. Любой, даже очень большой, файл может занимать на диске минимальный объем. И только по мере записи дополнительных данных область для хранения будет дополнительно увеличиваться. Процесс создания разреженных файлов также выгодно отличается от обычных, ведь системе требуется существенно меньше времени по причине пропуска последовательности нулевых байт. Дополнительно, меньший объем записи меньше нагружает диск и увеличивает срок его безотказной службы.
Помимо преимуществ, есть и недостатки. Система выполняет дополнительные операции с метаданными при записи информации о пропуске нулевых последовательностей. Не все ФС поддерживают разреженные файлы, и при переносе файла в такую систему, объем его может значительно возрасти по сравнению с исходником. А при ограниченном объеме конечного носителя операция копирования может быть полностью заблокирована или привести к непредсказуемым последствиям, ошибкам, логическим конфликтам, в том числе частичной перезаписи выделенной разреженной области. Также принудительная фрагментация при записи может сказаться на производительности, особенно при частой записи.
Поэтому выбирать, использовать или нет, разреженные файлы пользователи должны исходя из персональных потребностей и существующих задач.
Для создания разреженных файлов требуется использовать возможности командной строки в ОС Windows или терминала в Linux и MacOS.
Все операции с разряженными файлами осуществляет инструмент ФС «fsutil». В Windows запустите командную строку с привилегиями администратора. На первом этапе перейдите в требуемую папку, а потом наберите команду следующего вида, опустив граничные кавычки, для создания простого файла: «fsutil file createnew sparse-file 1000000000».
Атрибуты «sparse-file» и «1000000000» соответственно означают наименование файла и объем (единица измерения – байт).
Затем задайте новому файлу формат «разреженный», для чего следом введите в консоли команду (также без кавычек): «fsutil sparse setflag sparse-file».
Примечание. Если возникла потребность сменить атрибут файла и удалить присвоенное значение «разреженный», то внесите изменения в его формат посредством набора команды «fsutil sparse setflag sparse-file 0» (кавычки не использовать).
Дополнительно. Пользователи всегда могут проверить состояние формата файла и его заданную характеристику при помощи команды «fsutil sparse queryflag sparse-file». Сведения об атрибуте будут непосредственно сразу указаны в следующей строке после запроса.
На следующем этапе необходимо произвести разметку дисковой области, высвобождаемой внутри, чтобы экономично использовать накопитель. Наберите в консоли команду (без кавычек): «fsutil sparse setrange sparse-file 0 1000000000».
Примечание. Цифровые значения означают смещение. Единица измерения – байт. В нашем примере диапазон от 0 до одного гигабайта. Можно указать как полный объем, так и задать превышающее установленное значение.
Проверить факт присвоения атрибута можно командой «fsutil file layout sparse-file» (ограничивающие кавычки не использовать).
Данный атрибут может быть применен для любого по выбору файла и требует только указания в команде соответствующего наименования с востребованным размером. В нашем примере в расшифровке свойств отображается утверждение, что расширенный файл емкостью один гигабайт потребляет пространства накопителя ноль байт.
Создать разреженный файл в данной ОС несколько легче и можно воспользоваться двумя разными инструментами. Откройте терминал и введите указание к действию с командами «dd» или «truncate». Форма команды для создания разреженного файла в первом случае будет иметь вид (не использовать кавычки): «dd if=/dev/zero of=file-sparse bs=1 count=0 seek=2G».
Примечание. Атрибут «file-sparse» означает наименование файла. Заключительная цифра – готовый объем. Единица измерения – по выбору пользователя (мы указали в гигабайтах).
Второй вариант создания разреженного файла предполагает следующий вид команды (без обрамляющих кавычек): «truncate –s1G file-sparse2».
Примечание. Порядок записи атрибутов, по сравнению с первым способом, изменен, после характеристики «s» сначала задан объем файла, а потом указано его наименование.
Каждый способ непосредственно сразу напрямую создает разреженный файл и не требует последовательного двух шагового исполнения разных команд, как в операционной системе Windows.
Если же требуется привести к разреженному формату представления другой простой файл, то в Linux следует использовать следующую команду (кавычки опустить): «cp --sparse=always ./025.jpg ./0251.jpg».
Примечание. В представленной команде замените значения «025.jpg» и «0251.jpg» именами простого обычного файла и нового разреженного соответственно.
Для увеличения исходного готового файла задействуйте команду (кавычки не учитывать): «dd if=/dev/zero of=025.jpg bs=1 count=0 seek=2G».
Примечание. В нашем примере значение «025.jpg» указывает на имя увеличиваемого файла, а параметр в конце команды «2G» устанавливает его новый объем в два гигабайта.
Чтобы убедиться, какой размер выделен, введите без кавычек команду с именем проверяемого файла (в нашем примере имя файла «025.jpg») следующего вида: «du -h --apparent-size 025.jpg».
Файловая система ApFS, эксклюзивно используемая Apple, также поддерживает разреженные файлы, управлять которыми пользователи могут посредством команд для операционной системы Linux, представленными в предыдущем разделе, с отдельными уточнениями.
Например, для MacOS Catalina возможно использование только команды на основе утилиты формата «dd» с обязательным указанием объема разреженного файла только в одной единице измерения – байт. В противном случае система просигнализирует об ошибке. Вид команды в терминале выглядит следующим образом (без кавычек): «sudo dd if=/dev/zero of=sparse_APFS bs=1 count=0 seek=1000000000».
Указание для увеличения объема файла также требует задавать новый размер в байтах. Так, для увеличения объема до 400Мб команда примет вид (исключить кавычки): «dd if=/dev/zero of=025.jpg bs=1 count=0 seek=400000000».
Лучший способ восстановить разреженные файлы, как и для всех основных типов существующих файлов, - это воспользоваться готовой резервной копией, предварительно ранее созданной и хранящейся отдельно в защищенном месте. Однако данный способ не гарантирует полную сохранность данных и стопроцентный возврат файлов в случае их утраты или повреждения. Поэтому всегда следует иметь дополнительный вариант, а именно, программу для восстановления данных. Следует лишь убедиться, что такое решение обеспечивает восстановление разреженных файлов, поддерживает различные операционные и файловые системы, обладает мощным алгоритмом, оснащено дополнительными инструментами, повышающими степень удачного исхода, выполнено в понятном и удобном интерфейсе. Общение на тематических площадках и советы профессиональных специалистов по восстановлению помогут выбрать в Интернете подходящее решение.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике. А также зайдите на наш Youtube канал, там собраны более 400 обучающих видео.
Заключительные слова
Прогнозирование - важный навык для профессионалов в области данных. Спасибо за проекты с открытым исходным кодом, такие как Prophet, это не должно быть слишком сложным. Этот пакет обеспечивает баланс между простотой, скоростью вычислений и нужным количеством настроек, чтобы его могли использовать как начинающие, так и опытные пользователи.
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Привет, хабровчане. В рамках курса "Reverse-Engineering. Basic" Александр Колесников (специалист по комплексной защите объектов информатизации) подготовил авторскую статью.
Также приглашаем всех желающих на открытый вебинар по теме «Эксплуатация уязвимостей в драйвере. Часть 1». Участники вебинара вместе с экспертом разберут уязвимости переполнения в драйверах и особенности разработки эксплойтов в режиме ядра.
Статья расскажет о подходах к анализу запакованных исполняемых файлов с помощью простых средств для обратной разработки. Будут рассмотрены некоторые пакеры, которые применяются для упаковки исполняемых файлов. Все примеры будут проведены в ОС Windows, однако изучаемые подходы можно легко портировать на любую ОС.
Этап 6 - Настройка праздников и событий
Последний график компонентов показал растущий интерес к Леброну Джеймсу во время плей-офф НБА и во время финалов НБА. Модель в этом пункте признает ежегодную сезонность, которая возвращается каждый год. С другой стороны, Леброн Джеймс в настоящее время удерживает рекорд6 лет подряд в плей-офф НБАначиная с Майами и продолжая с кавалерами. Таким образом, мы должны ожидать одну и ту же сезонность год за годом.
Добавление праздников и событий является основным преимуществом пакета. Во-первых, делая прогнозы более точными и позволяя пользователю принимать во внимание известные будущие события. Разработчики сделали эту настройку намного проще, чем предыдущие пакеты временных рядов, в которых события и праздники должны были быть изменены вручную или проигнорированы, чтобы делать прогнозы. Подумайте о веб-сайте электронной коммерции, который может добавлять все повторяющиеся кампании и рекламные акции и устанавливать цели получения доходов на основе известных дат будущих кампаний.
Добавление событий и праздников осуществляется путем создания нового кадра данных, в котором мы передаем даты начала или окончания событий и продолжительность дней. В этом примере мы добавим плей-офф NBA и финалы NBA в качестве событий.
Используя параметры нижнего и верхнего окна, пользователь может установить продолжительность праздника. Эти сопоставления будут привязаны к одному объекту и переданы в параметре праздничных дней.

Обратите внимание, что модель лучше предсказывает значения во время пиков. Повторная распечатка компонентов покажет добавленную строку влияния выходных дней на прогноз. Теоретически вы можете отобразить многие события, которые имеют решающее значение для бизнеса, и получить более точные прогнозы.

NFO-файл: чем открыть?
Исходя из описания стандартного типа, нетрудно понять, каким образом можно его использовать. Если пользователь видит перед собой NFO-файл, чем открыть его, становится понятно.
В принципе, даже системную утилиту вызывать не нужно. Обычный двойной клик сделает свое дело, и пользователь увидит информацию, содержащуюся в файле.
Этап 4 - Основные прогнозы
Как и модели машинного обучения, первая команда соответствует модели на фрейме данных, а следующая развернет модель с помощью команды предиката для получения прогнозов на требуемую продолжительность дней.
Стандартные визуализации пакета пророка довольно хороши с предопределенными отметками, точками данных и интервалами неопределенности. Это одно из преимуществ этого пакета с открытым исходным кодом, нет необходимости в дополнительной настройке, и первый результат является быстрым и достаточно хорошим для большинства потребностей.

Используя этот график, мы более четко определяем годовой тренд и сезонность и то, как они используются для прогнозирования.
Объект прогноза содержит необработанные данные с прогнозируемым значением по дням и интервалам неопределенности. Также возможно получить доступ к прогнозным тенденциям и компонентам сезонности с помощью:
Пример UPX
Попробуем с помощью отладчика найти оригинальную точку входа для приложения. Запечатлим оригинальную точку входа до упаковки UPX:

Как та же точка входа выглядит после упаковки:

Запустим отладчик и попробуем найти место сохранения контекста:

Ждем первого использования ESP — в отладчике при этом значение регистра подсветится красным цветом. Затем устанавливаем точку останова на адрес и просто запускаем приложение:

В результате попадаем на оригинальную точку входа:

Вот так просто, теперь используя плагин Scylla Hide можно сохранить результирующий файл на жесткий диск и продолжить его анализ.
Подобный метод можно применять для любого упаковщика, который сохраняет контекст на стек.
Этап 7 - Устранение выбросов
При построении прогнозов важно удалить выбросы из исторических данных. Точки данных используются моделью, которая добавляет их эффект к прогнозам, хотя они представляют собой единичные события времени или просто ложные журналы событий. В отличие от других пакетов, которые будут повреждены при передаче значения NA с историческими данными, Prophet будет игнорировать эти даты.
В этом примере мы удалим серию одиночных событий, в которых игрок НБА объявил, что покидает Майами в пользу Кливленда, что, вероятно, привлечет внимание к его странице в Википедии.
Как открыть NFO-файл (Windows 7 или любая другая ОС), если файл стандартным способом не открывается или не читается?
Однако не всегда такие объекты можно открыть для просмотра обычным способом. Очень часто при загрузке пиратского программного обеспечения такие файлы можно встретить в качестве описательных компонентов при выполнении действий, связанных с установкой, взломом, патчингом, генерированием ключей или обходом регистрации официального ПО.

Чаще всего такие объекты можно встретить у хакеров из команд TEAM R2R, Core, Oxygen, Warez Group и других. Поскольку объект не содержит системной информации, соответственно, двойной клик не открывает NFO-файл. Чем открыть его в таком случае?
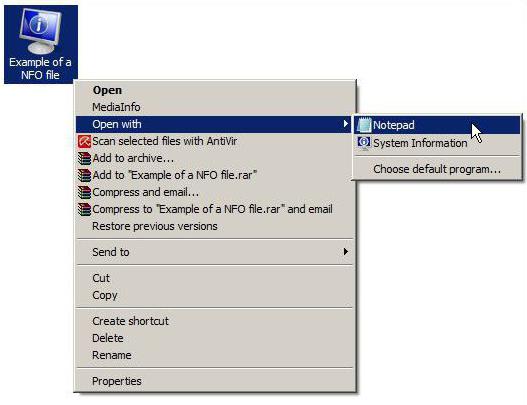
Все просто! Если вызвать правым кликом на файле контекстное меню, там отобразится строка открытия при помощи стандартного «Блокнота». Вот его-то и нужно использовать, ведь сам файл изначально имеет текстовый DOS-формат.
В принципе, можно использовать любой другой текстовый редактор такого типа. Пригодится и еще один вариант, позволяющий просмотреть NFO-файл. Чем открыть? Да хоть стандартным приложением Word, входящим в состав офисного пакета от Microsoft. Правда, в отличие от «Блокнота», здесь придется указать кодировку, если она по каким-либо причинам не будет распознана автоматически.
Кстати сказать, текстовые редакторы подойдут и для тех случаев, когда стандартный файл с системной информацией оказывается поврежденным. Однако есть еще масса специализированных утилит для просмотра содержимого. Например, довольно неплохо ведут себя приложения DAMN NFO Viewer, Bred3, GetDiz и другие.
Этап 1 - Установка и импорт пророка
Общие методы снятия паковки
Разберемся, что же такое паковка. В большинстве случаев исполняемые файлы современных языков программирования имеют довольно большой размер при минимальном наборе функций. Чтобы оптимизировать данную величину, можно применить паковку или сжатие. Наиболее распространенный на сегодняшний день пакер — UPX. Ниже приведен пример того, как пакер проводит сжатие исполняемого файла.

На картинке может показаться, что файл стал по размеру больше, однако это не всегда так. Большинство файлов за счет такой модификации могут уменьшить свой размер до 1.5 раз от исходного объема.
Что же от этого реверс-инженеру? Почему надо знать и уметь определять, что файл упакован? Приведу наглядный пример. Ниже приведен снимок файла, который не запакован:

И файл, который был пропущен через алгоритм UPX:

Изменения коснулись в этом случае двух основных точек исполняемого файла:
Точка входа — в случае с упакованным файлом это начало алгоритма распаковки, настоящий алгоритм программы будет работать только после того, как будет распакован оригинальный файл;
Код оригинального файла: теперь не найти паттернов, которые можно сразу разбирать как команды.
Итак, чтобы снова анализировать оригинальный файл, нужно найти настоящую или оригинальную точку входа. Для этого нужно разбить алгоритм на основные этапы:
Этап подготовки исполнения файла — загрузчик ОС настраивает окружение, загружает файл в оперативную память;
Сохранение контекста — упаковщик сохраняет контекст исполнения файла (набор значений регистров общего назначения, которые были установлены загрузчиком ОС);
Распаковка оригинального файла;
Передача управления оригинальному файлу.
Все описанные выше этапы можно легко отследить в отладчике. Особенно может выделяться процедура сохранения контекста. Для нее в разных архитектурах могут быть использованы команды pushad/popad или множественное использование команды push . Поэтому всегда приложение трассируют до первого изменения регистра ESP/RSP, и ставят "Hardware Breakpoint" на адрес, который был помещен в регистр в первый раз. Второе обращение этому адресу будет в момент восстановления контекста, который заполнил загрузчик ОС. Без него приложение завершится с ошибкой.
Читайте также: