
Что такое двойное хеширование
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу посвятить запуску нового потока курса «Алгоритмы для разработчиков».

Безопасное использование MD5
MD5 – до сих пор является одним из самых распространенных способов защитить информацию в сфере прикладных исследований, а также в области разработки веб-приложений. Хеш необходимо обезопасить от всевозможных хакерских атак.
Атаки переборного типа

Перебор по словарю — атака на систему защиты, применяющая метод полного перебора предполагаемых паролей, используемых для аутентификации, осуществляемого путём последовательного пересмотра всех слов (паролей в чистом виде) определённого вида и длины из словаря с целью последующего взлома системы и получения доступа к секретной информации.
Как видно из определения, атаки по словарю являются атаками полного перебора. Единственное отличие состоит в том, что данные атаки обычно более эффективны так как становится не нужным перебирать все комбинации символов, чтобы добиться успеха. Злоумышленники используют обширные списки наиболее часто используемых паролей таких как, имена домашних животных, вымышленных персонажей или конкретно характерных слов из словаря – отсюда и название атаки. Однако если пароль действительно уникален (не является комбинацией слов), атака по словарю не сработает. В этом случае использование атаки полного перебора единственный вариант.
Для полного перебора или перебора по словарю можно использовать программы PasswordsPro, MD5BFCPF, John the Ripper. Для перебора по словарю существуют готовые словари.
Проблема коллизии
Естественно, возникает вопрос, почему невозможно такое, что мы попадем дважды в одну ячейку массива, ведь представить функцию, которая ставит в сравнение каждому элементу совершенно различные натуральные числа просто невозможно. Именно так возникает проблема коллизии, или проблемы, когда хеш-функция выдает одинаковое натуральное число для разных элементов.
Существует несколько решений данной проблемы: метод цепочек и метод двойного хеширования. В данной статье я постараюсь рассказать о втором методе, как о более красивом и, возможно, более сложном.
Коллизии MD5

MD5 был тщательно изучен криптографическим сообществом с момента его первоначального выпуска и до 2004 года демонстрировал лишь незначительные недостатки. Однако летом 2004 года криптографы Ван Сяоюнь и Фэн Дэнго продемонстрировали алгоритм способный генерировать MD5-коллизии с использованием стандартного вектора инициализации.
Заключение
К сожалению, выяснилось, что алгоритм MD5 не способен отвечать данным требованиям. IETF (Internet Engineering Task Force) рекомендовала новым проектам протоколов не использовать MD5, так как исследовательские атаки предоставили достаточные основания для исключения использования алгоритма в приложениях, которым требуется устойчивость к различного рода коллизиям.
Хеши MD5 больше не считаются безопасными, и их не рекомендовано использовать для криптографической аутентификации.
Что такое Столкновение?
Поскольку хэш-функция получает нам небольшое число для ключа, который представляет собой большое целое число или строку, существует вероятность того, что два ключа приведут к одному и тому же значению. Ситуация, когда вновь вставленный ключ отображается на уже занятый слот в хэш-таблице, называется коллизией и должна обрабатываться с использованием некоторой техники обработки коллизий.
Каковы шансы столкновения с большим столом?
Столкновения очень вероятны, даже если у нас есть большой стол для хранения ключей. Важное наблюдение — парадокс дня рождения . При наличии только 23 человек вероятность того, что два человека имеют одинаковый день рождения, составляет 50%.
Отдельная цепочка:
Идея состоит в том, чтобы каждая ячейка хеш-таблицы указывала на связанный список записей, имеющих одинаковое значение хеш-функции.

Давайте рассмотрим простую хеш-функцию как « ключ мод 7 », а последовательность ключей — 50, 700, 76, 85, 92, 73, 101.
Преимущества:
1) Простота реализации.
2) Хеш-таблица никогда не заполняется, мы всегда можем добавить больше элементов в цепочку.
3) Менее чувствителен к хеш-функции или коэффициентам загрузки.
4) Он в основном используется, когда неизвестно, сколько и как часто ключей можно вставлять или удалять.
Недостатки:
1) Производительность кэширования цепочки не очень хорошая, поскольку ключи хранятся с использованием связанного списка. Открытая адресация обеспечивает лучшую производительность кэша, поскольку все хранится в одной таблице.
2) Потеря пространства (некоторые части хеш-таблицы никогда не используются)
3) Если цепочка становится длинной, то время поиска в худшем случае может стать O (n).
4) Использует дополнительное пространство для ссылок.
Производительность цепочки:
Эффективность хеширования может быть оценена в предположении, что каждый ключ одинаково вероятен для хеширования в любой слот таблицы (простое равномерное хеширование).
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по обсуждаемой теме
Постановка задачи
Давайте зададимся целью создать структуру данных, которая позволяет:
- contains(Element element) проверять, находится в ней некоторый элемент или нет, за О(1)
- add(Element element) добавлять элемент за О(1)
- delete(Element element) удалять элемент за О(1)
Содержание

Каждая ячейка [math]i[/math] массива [math]H[/math] содержит указатель на начало списка всех элементов, хеш-код которых равен [math]i[/math] , либо указывает на их отсутствие. Коллизии приводят к тому, что появляются списки размером больше одного элемента.
В зависимости от того нужна ли нам уникальность значений операции вставки у нас будет работать за разное время. Если не важна, то мы используем список, время вставки в который будет в худшем случае равна [math]O(1)[/math] . Иначе мы проверяем есть ли в списке данный элемент, а потом в случае его отсутствия мы его добавляем. В таком случае вставка элемента в худшем случае будет выполнена за [math]O(n)[/math]
Время работы поиска в наихудшем случае пропорционально длине списка, а если все [math]n[/math] ключей захешировались в одну и ту же ячейку (создав список длиной [math]n[/math] ) время поиска будет равно [math]\Theta(n)[/math] плюс время вычисления хеш-функции, что ничуть не лучше, чем использование связного списка для хранения всех [math]n[/math] элементов.
Удаления элемента может быть выполнено за [math]O(1)[/math] , как и вставка, при использовании двухсвязного списка.

Все элементы хранятся непосредственно в хеш-таблице, без использования связных списков. В отличие от хеширования с цепочками, при использовании этого метода может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, следовательно, будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Последовательный поиск
При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+1, i+2, i+3[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.

Линейный поиск
Выбираем шаг [math]q[/math] . При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+(1 \cdot q), i+(2 \cdot q), i+(3 \cdot q)[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент. По сути последовательный поиск - частный случай линейного, где [math]q=1[/math] .
Квадратичный поиск
Шаг [math]q[/math] не фиксирован, а изменяется квадратично: [math]q = 1,4,9,16. [/math] . Соответственно при попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math] i+1, i+4, i+9[/math] и так далее, пока не найдём свободную ячейку.

Проверка осуществляется аналогично добавлению: мы проверяем ячейку [math]i[/math] и другие, в соответствии с выбранной стратегией, пока не найдём искомый элемент или свободную ячейку.
При поиске элемента может получится так, что мы дойдём до конца таблицы. Обычно поиск продолжается, начиная с другого конца, пока мы не придём в ту ячейку, откуда начинался поиск.
Проблем две — крайне нетривиальное удаление элемента из таблицы и образование кластеров — последовательностей занятых ячеек.
Кластеризация замедляет все операции с хеш-таблицей: при добавлении требуется перебирать всё больше элементов, при проверке тоже. Чем больше в таблице элементов, тем больше в ней кластеры и тем выше вероятность того, что добавляемый элемент попадёт в кластер. Для защиты от кластеризации используется двойное хеширование и хеширование кукушки.
Рассуждение будет описывать случай с линейным поиском хеша. Будем при удалении элемента сдвигать всё последующие на [math]q[/math] позиций назад. При этом:
- если в цепочке встречается элемент с другим хешем, то он должен остаться на своём месте (такая ситуация может возникнуть если оставшаяся часть цепочки была добавлена позже этого элемента)
- в цепочке не должно оставаться "дырок", тогда любой элемент с данным хешем будет доступен из начала цепи
Учитывая это будем действовать следующим образом: при поиске следующего элемента цепочки будем пропускать все ячейки с другим значением хеша, первый найденный элемент копировать в текущую ячейку, и затем рекурсивно его удалять. Если такой следующей ячейки нет, то текущий элемент можно просто удалить, сторонние цепочки при этом не разрушатся (чего нельзя сказать про случай квадратичного поиска).
Хеш-таблицу считаем зацикленной
Вариант с зацикливанием мы не рассматриваем, поскольку если [math]q[/math] взаимнопросто с размером хеш-таблицы, то для зацикливания в ней вообще не должно быть свободных позиций
Теперь докажем почему этот алгоритм работает. Собственно нам требуется сохранение трёх условий.
Докажем по индукции. Если на данной итерации мы просто удаляем элемент (база), то после него ничего нет, всё верно. Если же нет, то вызванный в конце [math]\mathrm[/math] (см. псевдокод) заметёт созданную дыру (скопированный элемент), и сам, по предположению, новых не создаст.
- Элементы, которые уже на своих местах, не должны быть сдвинуты.
Противное возможно только в том случае, если какой-то элемент был действительно удалён. Удаляем мы только последнюю ячейку в цепи, и если бы на её месте возникла дыра для сторонней цепочки, это бы означало что элемент, стоящий на [math]q[/math] позиций назад, одновременно принадлежал нашей и другой цепочкам, что невозможно.
Двойное хеширование (англ. double hashing) — метод борьбы с коллизиями, возникающими при открытой адресации, основанный на использовании двух хеш-функций для построения различных последовательностей исследования хеш-таблицы.
При двойном хешировании используются две независимые хеш-функции [math] h_1(k) [/math] и [math] h_2(k) [/math] . Пусть [math] k [/math] — это наш ключ, [math] m [/math] — размер нашей таблицы, [math]n \bmod m [/math] — остаток от деления [math] n [/math] на [math] m [/math] , тогда сначала исследуется ячейка с адресом [math] h_1(k) [/math] , если она уже занята, то рассматривается [math] (h_1(k) + h_2(k)) \bmod m [/math] , затем [math] (h_1(k) + 2 \cdot h_2(k)) \bmod m [/math] и так далее. В общем случае идёт проверка последовательности ячеек [math] (h_1(k) + i \cdot h_2(k)) \bmod m [/math] где [math] i = (0, 1, \; . \;, m - 1) [/math]
Таким образом, операции вставки, удаления и поиска в лучшем случае выполняются за [math]O(1)[/math] , в худшем — за [math]O(m)[/math] , что не отличается от обычного линейного разрешения коллизий. Однако в среднем, при грамотном выборе хеш-функций, двойное хеширование будет выдавать лучшие результаты, за счёт того, что вероятность совпадения значений сразу двух независимых хеш-функций ниже, чем одной.
[math]\forall x \neq y \; \exists h_1,h_2 : p(h_1(x)=h_1(y))\gt p((h_1(x)=h_1(y)) \land (h_2(x)=h_2(y)))[/math]
[math] h_1 [/math] может быть обычной хеш-функцией. Однако чтобы последовательность исследования могла охватить всю таблицу, [math] h_2 [/math] должна возвращать значения:
- не равные [math] 0 [/math]
- независимые от [math] h_1 [/math]
- взаимно простые с величиной хеш-таблицы
Есть два удобных способа это сделать. Первый состоит в том, что в качестве размера таблицы используется простое число, а [math] h_2 [/math] возвращает натуральные числа, меньшие [math] m [/math] . Второй — размер таблицы является степенью двойки, а [math] h_2 [/math] возвращает нечетные значения.
Например, если размер таблицы равен [math] m [/math] , то в качестве [math] h_2 [/math] можно использовать функцию вида [math] h_2(k) = k \bmod (m-1) + 1 [/math]
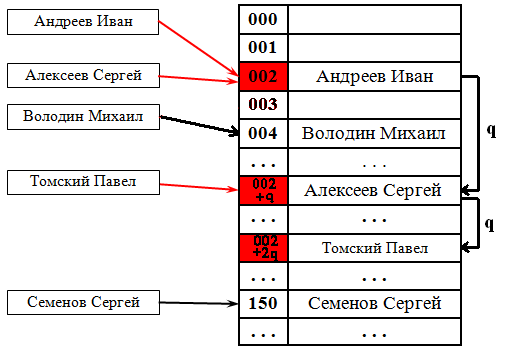
Показана хеш-таблица размером 13 ячеек, в которой используются вспомогательные функции:
[math] h(k,i) = (h_1(k) + i \cdot h_2(k)) \bmod 13 [/math]
[math] h_1(k) = k \bmod 13 [/math]
[math] h_2(k) = 1 + k \bmod 11 [/math]
Мы хотим вставить ключ 14. Изначально [math] i = 0 [/math] . Тогда [math] h(14,0) = (h_1(14) + 0\cdot h_2(14)) \bmod 13 = 1 [/math] . Но ячейка с индексом 1 занята, поэтому увеличиваем [math] i [/math] на 1 и пересчитываем значение хеш-функции. Делаем так, пока не дойдем до пустой ячейки. При [math] i = 2 [/math] получаем [math] h(14,2) = (h_1(14) + 2\cdot h_2(14)) \bmod 13 = 9 [/math] . Ячейка с номером 9 свободна, значит записываем туда наш ключ.
Таким образом, основная особенность двойного хеширования состоит в том, что при различных [math] k [/math] пара [math] (h_1(k),h_2(k)) [/math] дает различные последовательности ячеек для исследования.
Пусть у нас есть некоторый объект [math] item [/math] , в котором определено поле [math] key [/math] , от которого можно вычислить хеш-функции [math] h_1(key)[/math] и [math] h_2(key) [/math]
Так же у нас есть таблица [math] table [/math] величиной [math] m [/math] , состоящая из объектов типа [math] item [/math] .
Чтобы наша хеш-таблица поддерживала удаление, требуется добавить массив [math]deleted[/math] типов [math]bool[/math] , равный по величине массиву [math]table[/math] . Теперь при удалении мы просто будем помечать наш объект как удалённый, а при добавлении как не удалённый и замещать новым добавляемым объектом. При поиске, помимо равенства ключей, мы смотрим, удалён ли элемент, если да, то идём дальше.
В Java 8 для разрешения коллизий используется модифицированный метод цепочек. Суть его заключается в том, что когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. То есть при использовании данныx типа [math]\mathbf[/math] или [math]\mathbf[/math] имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, так как они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с [math]O(n)[/math] до [math]O(\log(n))[/math] . Данный способ используется в таких коллекциях как HashMap, LinkedHashMap и ConcurrentHashMap.

Хеш-функция — функция, осуществляющая преобразование массива входных данных произвольной длины в выходную битовую строку установленной длины, выполняемое определенным алгоритмом. Преобразование, производимое хеш-функцией, называется хешированием. Результат преобразования называется хешем.
Хеш-функции применяются в следующих случаях:
При поиске дубликатов в последовательностях наборов данных.
При построении уникальных идентификаторов для наборов данных.
При вычислении контрольных сумм от данных для последующего обнаружения в них ошибок, возникающих при хранении и передаче данных.
При сохранении паролей в системах защиты в виде хеш-кода (для восстановления пароля по хеш-коду требуется функция, являющаяся обратной по отношению к использованной хеш-функции).
С точки зрения математики, контрольная сумма является результатом хеш-функции, используемой для вычисления контрольного кода — небольшого количества бит внутри большого блока данных, например, сетевого пакета или блока компьютерного файла, применяемого для обнаружения ошибок при передаче или хранении информации. Значение контрольной суммы добавляется в конец блока данных непосредственно перед началом передачи или записи данных на какой-либо носитель информации. Впоследствии оно проверяется для подтверждения целостности данных. Популярность использования контрольных сумм для проверки целостности данных обусловлена тем, что подобная проверка просто реализуема в двоичном цифровом оборудовании, легко анализируется и хорошо подходит для обнаружения общих ошибок, вызванных наличием шума в каналах передачи данных.
Как работает протокол?

Утилита md5sum, предназначенная для хеширования данных заданного файла по алгоритму MD5, возвращает строку. Она состоит из 32 цифр в шестнадцатеричной системе счисления (016f8e458c8f89ef75fa7a78265a0025).
То есть хеш, полученный от функции, работа которой основана на этом алгоритме, выдает строку в 16 байт (128) бит. И эта строка включает в себя 16 шестнадцатеричных чисел. При этом изменение хотя бы одного ее символа приведет к последующему бесповоротному изменению значений всех остальных битов строки.
В данном алгоритме предполагается наличие 5 шагов, а именно:
Вычисление в цикле
На втором шаге в оставшиеся 64 бита дописывают 64-битное представление длины данных до выравнивания. Сначала записывают младшие 4 байта. Если длина превосходит то дописывают только младшие биты. После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
На третьем для вычислений используются четыре переменные размером 32 бита и задаются начальные значения в 16-ричном виде. В этих переменных будут храниться результаты промежуточных вычислений.
В итоге на 5-ом шаге мы получим результат вычислений, который находится в буфере это и есть хеш. Если выводить побайтово, начиная с младшего байта первой переменной и закончив старшим байтом последней, то мы получим MD5-хеш.
От хеш-множества к хеш-таблице (HashMap)
Давайте создадим структуру данных, которая позволяет так же быстро, как и хеш-множество (то есть за O(1)), добавлять, удалять, искать элементы, но уже по некоторому ключу.
Воспользуемся той же структурой данных, что у хеш-множества, но хранить будем не элементы, а пары элементов.
Таким образом, вставка (put(Key key, Value value)) будет осуществляться так: мы посчитаем ячейку массива по объекту типа Key, получим номер bucket'а. Пройдемся по списку в bucket'е, сравнивая ключ с ключом в хранимых парах. Если нашли такой же ключ — просто вытесняем старое значение, если не нашли — добавляем пару.
Как осуществляется получение элемента по ключу? Да по похожему принципу: получаем bucket по ключу, проходимся по парам и возвращаем значение в паре, ключ в которой равен ключу в запросе, если такая пара есть, и null в противном случае.
Данная структура данных и называется хеш-таблицей.
Решения проблемы коллизии методом двойного хеширования
Мы будем (как несложно догадаться из названия) использовать две хеш-функции, возвращающие взаимопростые натуральные числа.
Одна хеш-функция (при входе g) будет возвращать натуральное число s, которое будет для нас начальным. То есть первое, что мы сделаем, попробуем поставить элемент g на позицию s в нашем массиве. Но что, если это место уже занято? Именно здесь нам пригодится вторая хеш-функция, которая будет возвращать t — шаг, с которым мы будем в дальнейшем искать место, куда бы поставить элемент g.
Мы будем рассматривать сначала элемент s, потом s + t, затем s + 2*t и т.д. Естественно, чтобы не выйти за границы массива, мы обязаны смотреть на номер элемента по модулю (остатку от деления на размер массива).
Наконец мы объяснили все самые важные моменты, можно перейти к непосредственному написанию кода, где уже можно будет рассмотреть все оставшиеся нюансы. Ну а строгое математическое доказательство корректности использования двойного хеширования можно найти тут.
Для наглядности будем реализовывать хеш-таблицу, хранящую строки.
Начнем с определения самих хеш-функций, реализуем их методом Горнера. Важным параметром корректности хеш-функции является то, что возвращаемое значение должно быть взаимопросто с размером таблицы. Для уменьшения дублирования кода, будем использовать две структуры, ссылающиеся на реализацию самой хеш-функции.
Чтобы идти дальше, нам необходимо разобраться с проблемой: что же будет, если мы удалим элемент из таблицы? Так вот, его нужно пометить флагом deleted, но просто удалять его безвозвратно нельзя. Ведь если мы так сделаем, то при попытке найти элемент (значение хеш-функции которого совпадет с ее значением у нашего удаленного элемента) мы сразу наткнемся на пустую ячейку. А это значит, что такого элемента и не было никогда, хотя, он лежит, просто где-то дальше в массиве. Это основная сложность использования данного метода решения коллизий.
Помня о данной проблеме построим наш класс.
На данном этапе мы уже более-менее поняли, что у нас будет храниться в таблице. Переходим к реализации служебных методов.
Из необходимых методов осталось еще реализовать динамическое увеличение, расширение массива — метод Resize.
Увеличиваем размер мы стандартно вдвое.
Немаловажным является поддержание асимптотики O(1) стандартных операций. Но что же может повлиять на скорость работы? Наши удаленные элементы (deleted). Ведь, как мы помним, мы ничего не можем с ними сделать, но и окончательно обнулить их не можем. Так что они тянутся за нами огромным балластом. Для ускорения работы нашей хеш-таблицы воспользуемся рехешом (как мы помним, мы уже выделяли под это очень странные переменные).
Теперь воспользуемся ими, если процент реальных элементов массива стал меньше 50, мы производим Rehash, а именно делаем то же самое, что и при увеличении таблицы (resize), но не увеличиваем. Возможно, это звучит глуповато, но попробую сейчас объяснить. Мы вызовем наши хеш-функции от всех элементов, переместим их в новых массив. Но с deleted-элементами это не произойдет, мы не будем их перемещать, и они удалятся вместе со старой таблицей.
Но к чему слова, код все разъяснит:
Ну теперь мы уже точно на финальной, хоть и длинной, и полной колючих кустарников, прямой. Нам необходимо реализовать вставку (Add), удаление (Remove) и поиск (Find) элемента.
Начнем с самого простого — метод Find элемент по значению.
Далее мы реализуем удаление элемента — Remove. Как мы это делаем? Находим элемент (как в методе Find), а затем удаляем, то есть просто меняем значение state на false, но сам Node мы не удаляем.
Ну и последним мы реализуем метод Add. В нем есть несколько очень важных нюансов. Именно здесь мы будем проверять на необходимость рехеша.
Помимо этого в данном методе есть еще одна часть, поддерживающая правильную асимптотику. Это запоминание первого подходящего для вставки элемента (даже если он deleted). Именно туда мы вставим элемент, если в нашей хеш-таблицы нет такого же. Если ни одного deleted-элемента на нашем пути нет, мы создаем новый Node с нашим вставляемым значением.
Разрешение коллизий (англ. collision resolution) в хеш-таблице, задача, решаемая несколькими способами: метод цепочек, открытая адресация и т.д. Очень важно сводить количество коллизий к минимуму, так как это увеличивает время работы с хеш-таблицами.
Проверка наличия
Необходимо сделать линейный поиск по массиву, ведь элемент потенциально может находиться в любой ячейке. Асимптотически это можно осуществить за O(n), где n — размер массива.
Метод открытой адресации
В данном методе в ячейках хранятся сами элементы, а в случае коллизии происходит последовательность проб, то есть мы начинаем по некоторому алгоритму перебирать ячейки в надежде найти свободную. Это можно делать разными алгоритмами (линейная / квадратичная последовательности проб, двойное хеширование), каждый из которых обладает своими проблемами (например, возникновение первичных или вторичных кластеров).
Введение
Хеш-таблицы (HashMap) наравне с динамическими массивами являются самыми популярными структурами данных, применяемыми в production'е. Очень часто можно услышать вопросы на собеседованиях касаемо их предназначения, особенностей их внутреннего устройства, а также связанных с ними алгоритмов. Данная структура данных является классической и встречается не только в Java, но и во многих других языках программирования.
Метод цепочек
Метод цепочек является наиболее простым методом разрешения коллизий. В ячейке массива мы будем хранить не элементы, а связанный список данных элементов. Потому как добавление в начало списка (а нам все равно в какую часть списка добавлять элемент) обладает асимптотикой О(1), мы не испортим общую асимптотику, и она останется равной О(1).
У данной реализации есть проблема: если списки будут очень сильно вырастать (в качестве крайнего случая можно рассмотреть хеш-функцию, которая возвращает константу для любого объекта), то мы получим асимптотику O(m), где m — число элементов во множестве, если размер массива фиксирован. Для избежания таких неприятностей вводится понятие коэффициент заполнения (он может быть равен, например, 1.5). Если при добавлении элемента оказывается, что доля числа элементов, находящихся в структуре данных по отношению к размеру массива, превосходит коэффициент заполнения, то происходит следующее: выделяется новый массив, размер которого превосходит размер старого массива (например в 2 раза), и структура данных перестраивается на новом массиве.
Данный метод разрешения коллизий и применяется в Java, а структура данных называется HashSet.
Декодирование кода MD5
Иногда при работе с компьютером или поврежденными базами данных требуется декодировать зашифрованное с помощью MD5 значение хеша.
Удобнее всего использовать специализированные ресурсы, предоставляющие возможность сделать это online:
md5.web-max.ca данный сервис обладает простым и понятным интерфейсом. Для получения декодированного значения нужно ввести хеш и заполнить поле проверочной капчи;
Если присмотреться к значениям декодинга, то становится понятно, что процесс расшифровки почти не дает результатов. Эти ресурсы представляют собой одну или несколько объединенных между собой баз данных, в которые занесены расшифровки самых простых слов.
При этом данные декодирования хеша MD5 даже такой распространенной части пароля, как «админ», нашлись лишь в одной базе. Поэтому хеши паролей, состоящих из более сложных и длинных комбинаций символов, практически невозможно расшифровать.
Создание хеша MD5 является односторонним процессом. Поэтому не подразумевает обратного декодирования первоначального значения.
Мотивация использовать хеш-таблицы
Для наглядности рассмотрим стандартные контейнеры и асимптотику их наиболее часто используемых методов.
| Контейнер \ операция | insert | remove | find |
|---|---|---|---|
| Array | O(N) | O(N) | O(N) |
| List | O(1) | O(1) | O(N) |
| Sorted array | O(N) | O(N) | O(logN) |
| Бинарное дерево поиска | O(logN) | O(logN) | O(logN) |
| Хеш-таблица | O(1) | O(1) | O(1) |
Все данные при условии хорошо выполненных контейнерах, хорошо подобранных хеш-функциях
Из этой таблицы очень хорошо понятно, почему же стоит использовать хеш-таблицы. Но тогда возникает противоположный вопрос: почему же тогда ими не пользуются постоянно?
Ответ очень прост: как и всегда, невозможно получить все сразу, а именно: и скорость, и память. Хеш-таблицы тяжеловесные, и, хоть они и быстро отвечают на вопросы основных операций, пользоваться ими все время очень затратно.
Проблемы простейшей реализации хеш-множества
Как бы ни была написана хеш-функция, число ячеек массива всегда ограничено, тогда как множество элементов, которые мы хотим хранить в структуре данных, неограничено. Ведь мы бы не стали заморачиваться со структурой данных, если бы была потребность в сохранении всего лишь десяти заранее известных элементов, верно? Такое положение дел приводит к неизбежным коллизиям. Под коллизией понимается ситуация, когда при добавлении разных объектов мы попадаем в одну и ту же ячейку массива.
Для разрешения коллизий придумано 2 метода: метод цепочек и метод открытой адресации.
Типичные вопросы на собеседовании
Q: Как устроены HashSet и HashMap? Как осуществляются основные операциии в данных коллекциях? Как применяются методы equals() и hashCode()?
A: Ответы на данные вопросы можно найти выше.
Q: Каков контракт на equals() и hashCode()? Чем он обусловлен?
A: Если объекты равны, то у них должны быть равны hashCode. Таким образом, hashCode должен определяться по подможноству полей, учавствующих в equals. Нарушение данного контракта может приводить к весьма интересным эффектам. Если объекты равны, но hashCode у них разный, то вы можете не достать значение, соответствующее ключу, по которому вы только что добавили объект в HashSet или в HashMap.
Добавление “соли” к паролю

Одна из наиболее распространенных причин успешных атак заключается в том, что компании не используют добавление соли к исходному паролю. Это значительно облегчает хакерам взлом системы с помощью атак типа радужных таблиц, особенно учитывая тот факт, что многие пользователи используют очень распространенные, простые пароли, имеющие одинаковые хеши.
Сольэто вторичный фрагмент информации, состоящий из строки символов, которые добавляются к открытому тексту (исходному паролю пользователя), а затем хешируется. Соление делает пароли более устойчивыми к атакам типа радужных таблиц, так как подобный пароль будет иметь более высокую информационную энтропию и, следовательно, менее вероятное существование в предварительно вычисленных радужных таблицах. Как правило, соль должна быть не менее 48 бит.
Массив
Попробуем сделать эти операции поверх массива, который является самой простой структурой данных. Договоримся, что будем считать ячейку пустой, если в ней содержится null.
Понятие хеш-таблицы
Хеш-таблица — это контейнер, который используют, если хотят быстро выполнять операции вставки/удаления/нахождения. В языке C++ хеш-таблицы скрываются под флагом unoredered_set и unordered_map. В Python вы можете использовать стандартную коллекцию set — это тоже хеш-таблица.
Реализация у нее, возможно, и не очевидная, но довольно простая, а главное — как же круто использовать хеш-таблицы, а для этого лучше научиться, как они устроены.
Для начала объяснение в нескольких словах. Мы определяем функцию хеширования, которая по каждому входящему элементу будет определять натуральное число. А уже дальше по этому натуральному числу мы будем класть элемент в (допустим) массив. Тогда имея такую функцию мы можем за O(1) обработать элемент.
Теперь стало понятно, почему же это именно хеш-таблица.
Информационная энтропия

Энтропия
Надежность и сложность пароля в сфере информационных технологий обычно измеряется в терминах теории информации. Чем выше информационная энтропия, тем надежнее пароль и, следовательно, тем труднее его взломать.
Чем длиннее пароль и чем больше набор символов, из которого он получен, тем он надежнее. Правда вместо количества попыток, которые необходимо предпринять для угадывания пароля, принято вычислять логарифм по основанию 2 от этого числа, и полученное значение называется количеством «битов энтропии» в пароле. При увеличении длины пароля на один бит количество возможных паролей удвоится, что сделает задачу атакующего в два раза сложнее. В среднем, атакующий должен будет проверить половину из всех возможных паролей до того, как найдет правильный. В качестве наилучшей практики должно выполняться предварительное требование: приложение настаивает на том, чтобы пользователь использовал надежный пароль в процессе регистрации.
Добавление
Если нам надо добавить элемент абы куда, то вначале мы должны найти пустую ячейку, а затем записать в нее элемент. Таким образом, мы опять осуществим линейный поиск и получим асимптотику O(n).
Вывод
На собеседованиях очень любят задавать различные кейсы, связанные с этими структурами данных. При этом решение любого из них может быть выведено из понимания принципов их работы без всякой «зубрежки».
На этом все. Если вы дочитали материал до конца, приглашаю на бесплатный урок по теме «Секреты динамического программирования» в рамках урока мой коллега — Евгений Волосатов покажет как решить олимпиадную задачу используя идеи динамического программирования.
Я много раз заглядывал на просторы интернета, нашел много интересных статей о хеш-таблицах, но вразумительного и полного описания того, как они реализованы, так и не нашел. В связи с этим мне просто нетерпелось написать пост на данную, столь интересную, тему.
Возможно, она не столь полезна для опытных программистов, но будет интересна для студентов технических ВУЗов и начинающих программистов-самоучек.

RainbowCrack

Это ещё один метод взлома хеша. Он основан на генерировании большого количества хешей из набора символов, чтобы по получившейся базе вести поиск заданного хеша.
Радужные таблицы состоят из хеш-цепочек и более эффективны, чем предыдущий упомянутый тип атак, поскольку они оптимизируют требования к хранению, хотя поиск выполняется немного медленнее. Радужные таблицы отличаются от хеш-таблиц тем, что они создаются с использованием как хеш-функций, так и функций редукции.
Цепочки хешей — метод для уменьшения требования к объёму памяти. Главная идея — определение функции редукции R, которая сопоставляет значениям хеша значения из таблицы. Стоит отметить, что R не является обращением хеш-функции.
Радужные таблицы являются развитием идеи таблицы хеш-цепочек. Функции редукции применяются по очереди, перемежаясь с функцией хеширования.
Использование последовательностей функций редукции изменяет способ поиска по таблице. Поскольку хеш может быть найден в любом месте цепочки, необходимо сгенерировать несколько различных цепочек.
Существует множество систем взлома паролей и веб-сайтов, которые используют подобные таблицы. Основная идея данного метода — достижение компромисса между временем поиска по таблице и занимаемой памятью. Конечно, использование радужных таблиц не гарантирует 100% успеха взлома систем паролей. Но чем больше набор символов, используемый для создания радужной таблицы, и чем продолжительнее хеш-цепочки, тем больше будет шансов получить доступ к базе данных исходных паролей.
Уязвимости MD5

Перебор по словарю
При этом методы перебора по словарю и brute-force могут использоваться для взлома хеша других хеш-функций (с небольшими изменениями алгоритма). RainbowCrack требует предварительной подготовки радужных таблиц, которые создаются для заранее определённой хеш-функции. Поиск коллизий специфичен для каждого алгоритма. Рассмотрим каждый вид «взлома» по отдельности.
Простейшее хеш-множество
Обратите внимание, что при каждой операции, мы сначала искали индекс нужной ячейки, а затем осуществляли операцию, и именно поиск портит нам асимптотику! Если бы мы научились получать данный индекс за O(1), то исходная задача была бы решена.
Давайте теперь заменим линейный поиск на следующий алгоритм: будем вычислять значение некоторой фунции — хеш-функции, ставящей в соответствие объекту класса некоторое целое число. После этого будем сопоставлять полученное целое число индексу ячейки массива (это достаточно легко сделать, например, взяв остаток от деления этого числа на размер массива). Если хеш-функция написана так, что она считается за O(1) (а она так обычно и написана), то мы получили самую простейшую реализацию хеш-множества. Ячейка массива в терминах хеш-множества может называться bucket'ом.
Удаление
Чтобы удалить элемент, его нужно сначала найти, а затем в найденную ячейку записать null. Опять линейный поиск приводит нас к O(n).
Читайте также: