
Что представляет собой сжатый файл
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики

Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F =
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.

Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.

Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.

Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:

Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
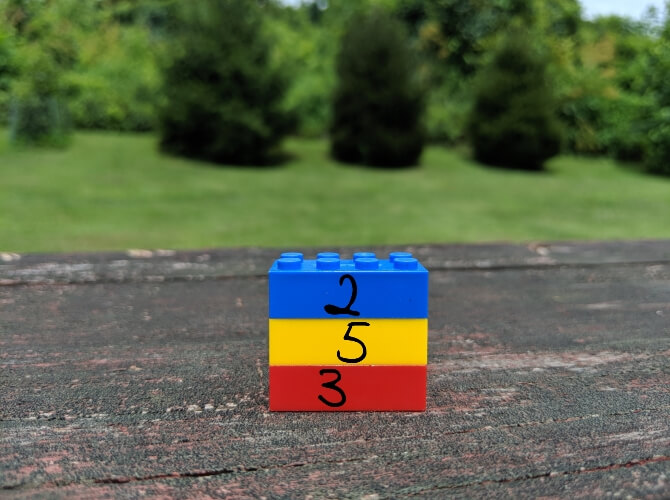
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Дополнительная информация о сжатии файлов
Хотя это, вероятно, неудивительно, для сжатия больших файлов потребуется больше времени, чем для более мелких. Если весь объем файлов сжимается, его завершение может занять некоторое время, причем общее время зависит от количества файлов в томе, размера файлов и общей скорости компьютера.
Некоторые файлы сжимаются не очень хорошо, в то время как другие могут сжиматься до 10% или меньше от их первоначального размера. Это связано с тем, что некоторые файлы уже сжимаются в некоторой степени даже перед использованием инструмента сжатия Windows.
Один из примеров этого можно увидеть, если вы попытаетесь сжать файл ISO. Большинство ISO-файлов сжимаются при первой сборке, поэтому повторное сжатие с использованием сжатия Windows, скорее всего, не повлияет на общий размер файла.
При просмотре свойств файла указывается размер файла для фактического размера файла (так называемый размер ), а другой – для размера файла на жестком диске (размер ). на диске ).
Первое число не изменится, независимо от того, сжат ли файл или нет, потому что он говорит вам истинный, несжатый размер файла. Второе число, однако, показывает, сколько места занимает файл на жестком диске прямо сейчас. Поэтому, если файл сжат, число рядом с Размер на диске , конечно, обычно будет меньше, чем другое число.
Копирование файла на другой жесткий диск очистит атрибут сжатия. Например, если видеофайл на вашем основном жестком диске сжимается, но затем вы копируете его на внешний жесткий диск, файл больше не будет сжиматься на этом новом диске, если вы снова не сожмете его вручную.
Сжатие файлов может увеличить фрагментацию тома. Из-за этого инструментам дефрагментации может потребоваться больше времени для дефрагментации жесткого диска, который содержит много сжатых файлов.
История

Иерархия алгоритмов:
Хотя сжатие данных получило широкое распространение вместе с интернетом и после изобретения алгоритмов Лемпелем и Зивом (алгоритмы LZ), можно привести несколько более ранних примеров сжатия. Морзе, изобретая свой код в 1838 году, разумно назначил самым часто используемым буквам в английском языке, “e” и “t”, самые короткие последовательности (точка и тире соотв.). Вскоре после появления мейнфреймов в 1949 году был придуман алгоритм Шеннона — Фано, который назначал символам в блоке данных коды, основываясь на вероятности их появления в блоке. Вероятность появления символа в блоке была обратно пропорциональна длине кода, что позволяло сжать представление данных.
Дэвид Хаффман был студентом в классе у Роберта Фано и в качестве учебной работы выбрал поиск улучшенного метода бинарного кодирования данных. В результате ему удалось улучшить алгоритм Шеннона-Фано.
Ранние версии алгоритмов Шеннона-Фано и Хаффмана использовали заранее определённые коды. Позже для этого стали использовать коды, созданные динамически на основе данных, предназначаемых для сжатия. В 1977 году Лемпель и Зив опубликовали свой алгоритм LZ77, основанный на использования динамически создаваемого словаря (его ещё называют «скользящим окном»). В 78 году они опубликовали алгоритм LZ78, который сначала парсит данные и создаёт словарь, вместо того, чтобы создавать его динамически.
Проблемы с правами
Алгоритмы LZ77 и LZ78 получили большую популярность и вызвали волну улучшателей, из которых до наших дней дожили DEFLATE, LZMA и LZX. Большинство популярных алгоритмов основаны на LZ77, потому что производный от LZ78 алгоритм LZW был запатентован компанией Unisys в 1984 году, после чего они начали троллить всех и каждого, включая даже случаи использования изображений в формате GIF. В это время на UNIX использовали вариацию алгоритма LZW под названием LZC, и из-за проблем с правами их использование пришлось сворачивать. Предпочтение отдали алгоритму DEFLATE (gzip) и преобразованию Барроуза — Уилера, BWT (bzip2). Что было и к лучшему, так как эти алгоритмы почти всегда превосходят по сжатию LZW.
К 2003 году срок патента истёк, но поезд уже ушёл и алгоритм LZW сохранился, пожалуй, только в файлах GIF. Доминирующими являются алгоритмы на основе LZ77.
В 1993 году была ещё одна битва патентов – когда компания Stac Electronics обнаружила, что разработанный ею алгоритм LZS используется компанией Microsoft в программе для сжатия дисков, поставлявшейся с MS-DOS 6.0. Stac Electronics подала в суд и им удалось выиграть дело, в результате чего они получили более $100 миллионов.
Рост популярности Deflate
К сожалению Фил Катц не дожил до триумфа DEFLATE, он умер от алкоголизма в 2000 году в возрасте 37 лет. Граждане – чрезмерное употребление алкоголя опасно для вашего здоровья! Вы можете не дожить до своего триумфа!
Современные архиваторы
ZIP царствовал безраздельно до середины 90-х, однако в 1993 году простой русский гений Евгений Рошал придумал свой формат и алгоритм RAR. Последние его версии основаны на алгоритмах PPM и LZSS. Сейчас ZIP, пожалуй, самый распространённый из форматов, RAR – до недавнего времени был стандартом для распространения различного малолегального контента через интернет (благодаря увеличению пропускной способности всё чаще файлы распространяются без архивации), а 7zip используется как формат с наилучшим сжатием при приемлемом времени работы. В мире UNIX используется связка tar + gzip (gzip — архиватор, а tar объединяет несколько файлов в один, т.к. gzip этого не умеет).
Прим. перев. Лично я, кроме перечисленных, сталкивался ещё с архиватором ARJ (Archived by Robert Jung), который был популярен в 90-х в эру BBS. Он поддерживал многотомные архивы, и так же, как после него RAR, использовался для распространения игр и прочего вареза. Ещё был архиватор HA от Harri Hirvola, который использовал сжатие HSC (не нашёл внятных объяснений — только «модель ограниченного контекста и арифметическое кодирование»), который хорошо справлялся со сжатием длинных текстовых файлов.
В 1996 году появился вариант алгоритма BWT с открытыми исходниками bzip2, и быстро приобрёл популярность. В 1999 году появилась программа 7-zip с форматом 7z. По сжатию она соперничает с RAR, её преимуществом является открытость, а также возможность выбора между алгоритмами bzip2, LZMA, LZMA2 и PPMd.
В 2002 году появился ещё один архиватор, PAQ. Автор Мэтт Махоуни использовал улучшенную версию алгоритма PPM с использованием техники под названием «контекстное смешивание». Она позволяет использовать больше одной статистической модели, чтобы улучшить предсказание по частоте появления символов.
Будущее алгоритмов сжатия
Конечно, бог его знает, но судя по всему, алгоритм PAQ набирает популярность благодаря очень хорошей степени сжатия (хотя и работает он очень медленно). Но благодаря увеличению быстродействия компьютеров скорость работы становится менее критичной.
С другой стороны, алгоритм Лемпеля-Зива –Маркова LZMA представляет собой компромисс между скоростью и степенью сжатия и может породить много интересных ответвлений.
Ещё одна интересная технология «substring enumeration» или CSE, которая пока мало используется в программах.
В следующей части мы рассмотрим техническую сторону упомянутых алгоритмов и принципы их работы.
Ограничения атрибута сжатого файла
Файловая система NTFS является единственной файловой системой Windows, которая поддерживает сжатые файлы.Это означает, что разделы, отформатированные в файловой системе FAT, не могут использовать сжатие файлов.
Некоторые жесткие диски могут быть отформатированы для использования кластеров с размерами, превышающими размер по умолчанию 4 КБ (подробнее об этом здесь). Любая файловая система, использующая размер кластера, превышающий этот размер по умолчанию, не сможет использовать функции атрибута сжатого файла.
Несколько файлов не могут быть сжаты одновременно, если они не содержатся в папке, а затем вы выбираете вариант для сжатия содержимого папки. В противном случае при выборе отдельных файлов за раз (например, выделение двух или более файлов изображений) опция включения атрибута сжатия будет недоступна.
Некоторые файлы в Windows могут вызвать проблемы, если они сжаты, потому что они необходимы для запуска Windows. BOOTMGR и NTLDR – два примера файлов, которые не должны быть сжаты. Более новые версии Windows даже не позволят сжать файлы этих типов.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.

Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Что такое сжатый атрибут и стоит ли его включать в Windows?
Сжатый файл – это любой файл с включенным атрибутом сжатия.
Использование сжатого атрибута – это один из способов сжатия файла до меньшего размера для экономии места на жестком диске, и его можно применять несколькими различными способами (о которых я говорю ниже).
Большинство компьютеров Windows по умолчанию настроены на отображение сжатых файлов синим текстом при обычном поиске файлов и просмотре папок.
Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Как сжать файлы и папки в Windows
Как проводник, так и команда командной строки compact можно использовать для сжатия файлов и папок в Windows, включив атрибут сжатого.
У Microsoft есть это руководство, которое объясняет сжатие файлов с помощью метода File/Windows Explorer, а также примеры того, как сжимать файлы из командной строки, и правильный синтаксис для этой команды командной строки.
Сжатие одного файла, конечно, применяет сжатие только к этому файлу. При сжатии папки (или целого раздела) вам предоставляется возможность сжать только эту папку или папку plus , ее подпапки и все файлы, которые находятся в них.
Как вы видите ниже, сжатие папки с помощью Explorer дает вам две опции: Применить изменения только к этой папке и Применить изменения к этой папке, подпапкам и файлам .
Первый вариант применения изменений к одной папке, в которой вы находитесь, устанавливает атрибут сжатия только для новых файлов, которые вы помещаете в папку. Это означает, что любой файл, находящийся в папке прямо сейчас, не будет включен, но любые новые файлы, которые вы добавите в будущем, будут сжаты. Это верно только для одной папки, к которой вы применяете его, а не для любых подпапок, которые у него могут быть.
Второй вариант – применить изменения к папке, подпапкам и всем их файлам – работает так, как звучит. Все файлы в текущей папке, а также все файлы в любой из ее подпапок, будут иметь включенный атрибут сжатия. Это означает не только то, что текущие файлы будут сжаты, но также и то, что сжатый атрибут применяется ко всем новым файлам, которые вы добавляете в текущую папку , а также ко всем подпапкам , в этом и заключается разница между этот вариант и другой.
При сжатии диска C или любого другого жесткого диска вы получаете те же параметры, что и при сжатии папки, но шаги несколько иные. Откройте свойства диска в проводнике и установите флажок Сжать этот диск, чтобы сэкономить место на диске . Затем вам предоставляется возможность применить сжатие только к корню диска или ко всем его подпапкам и файлам.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
12. Программное управление работой компьютера предполагает:
1.необходимость использования операционной системы для синхронной работы аппаратных средств;
2.выполнение компьютером серии команд без уча-стия пользователя;
3.двоичное кодирование данных в компьютере;
4.использование специальных формул для реали-зации команд в компьютере.
13. Файл - это:
1.элементарная информационная единица, содер-жащая последовательность байтов и имеющая уникальное имя;
2.объект, характеризующихся именем, значением и типом;
3.совокупность индексированных переменных;
4.совокупность фактов и правил.
14. Расширение файла, как правило, характеризует:
1.время создания файла;
2.объем файла;
3.место, занимаемое файлом на диске;
4.тип информации, содержащейся в файле;
5.место создания файла.
15. Полный путь файлу: c:\books\raskaz.txt. Каково имя файла?
1.books\raskaz;.
2.raskaz.txt;
3.books\raskaz.txt;
4.txt.
16. Операционная система это -
1.совокупность основных устройств компьютера;
2.система программирования на языке низкого уровня;
3.программная среда, определяющая интерфейс пользователя;
4.совокупность программ, используемых для опе-раций с документами;
5.программ для уничтожения компьютерных виру-сов.
17. Программы сопряжения устройств компьютера называются:
1.загрузчиками;
2.драйверами;
3.трансляторами;
4.интерпретаторами;
5.компиляторами.
18. Системная дискета необходима для:
1.для аварийной загрузки операционной системы;
2.систематизации файлов;
3.хранения важных файлов;
4.лечения компьютера от вирусов.
19. Какое устройство обладает наибольшей скоро-стью обмена информацией:
1.CD-ROM дисковод;
2.жесткий диск;
3.дисковод для гибких магнитных дисков;
4.оперативная память;
5.регистры процессора?
20. Программой архиватором называют:
1.программу для уплотнения информационного объема (сжатия) файлов;
2.программу резервного копирования файлов;
3.интерпретатор;
4.транслятор;
5.систему управления базами данных.
21. Сжатый файл представляет собой:
1.файл, которым долго не пользовались;
2.файл, защищенный от копирования;
3.файл, упакованный с помощью архиватора;
4.файл, защищенный от несанкционированного доступа;
5.файл, зараженный компьютерным вирусом.
22. Какое из названных действий можно произвести со сжатым файлом:
1.переформатировать;
2.распаковать;
3.просмотреть;
4.запустить на выполнение;
5.отредактировать.
23. Сжатый файл отличается от исходного тем, что:
1.доступ к нему занимает меньше времени;
2.он в большей степени удобен для редактирова-ния;
3.он легче защищается от вирусов;
4.он легче защищается от несанкционированного доступа;
5.он занимает меньше места.
24. Компьютерные вирусы:
1.возникают в связи сбоев в аппаратной части компьютера;
2.создаются людьми специально для нанесения ущерба ПК;
3.зарождаются при работе неверно написанных программных продуктов;
4.являются следствием ошибок в операционной системе;
5.имеют биологическое происхождение.
25. Отличительными особенностями компьютерного вируса являются:
1.значительный объем программного кода;
2.необходимость запуска со стороны пользовате-ля;
3.способность к повышению помехоустойчивости операционной системы;
4.маленький объем; способность к самостоятель-ному запуску и к созданию помех корректной ра-боте компьютера;
5.легкость распознавания.
26. Загрузочные вирусы характеризуются тем, что:
1.поражают загрузочные сектора дисков;
2.поражают программы в начале их работы;
3.запускаются при запуске компьютера;
4.изменяют весь код заражаемого файла;
5.всегда меняют начало и длину файла.
27. Файловый вирус:
1.поражают загрузочные сектора дисков;
2.поражают программы в начале их работы;
3.запускаются при запуске компьютера;
4.изменяют весь код заражаемого файла;
5.всегда меняют начало и длину файла.
12ать- либо 1 либо 4 хз
тринадцать: 1
14ать - 4
15ать-2
16ать-3
17ать-2
18ать-1
19ать-5
20ать-1
21н-3
22а-2345
23й-5
24й-2
25-ть-4
26-3
27-1
Как работает компрессия?
Итак, что же на самом деле делает сжатие файла? Включение атрибута сжатого файла для файла уменьшит размер файла, но все равно позволит Windows использовать его так же, как и любой другой файл.
Сжатие и распаковка происходит на лету. Когда сжатый файл открывается, Windows автоматически распаковывает его для вас. Когда он закрывается, он снова сжимается. Это происходит снова и снова столько раз, сколько вы открываете и закрываете сжатый файл.
Я включил атрибут сжатия для файла TXT размером 25 МБ, чтобы проверить эффективность алгоритма, используемого Windows. После сжатия файл занимал всего 5 МБ дискового пространства.
Даже с помощью этого примера вы можете увидеть, сколько дискового пространства можно сэкономить, если бы оно было применено ко многим файлам одновременно.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Должен ли я сжать весь жесткий диск?
Как вы видели в примере файла TXT, установка атрибута сжатого файла для файла может существенно уменьшить его размер. Однако работа со сжатым файлом будет занимать больше процессорного времени, чем работа с несжатым файлом, потому что Windows должна распаковать и повторно сжать файл во время его использования.
Поскольку на большинстве компьютеров достаточно места на жестком диске, сжатие обычно не рекомендуется, тем более что компромиссный компьютер в целом медленнее благодаря дополнительной загрузке процессора.
Все это говорит о том, что может быть полезно сжать определенные файлы или группы файлов, если вы их почти не используете. Если вы не планируете открывать их часто или даже вообще, то тот факт, что для их открытия потребуется вычислительная мощность, вероятно, очень мало заботит изо дня в день.
Сжатие отдельных файлов в Windows довольно легко благодаря атрибуту сжатых, но использование сторонней программы сжатия файлов лучше всего подходит для архивирования или совместного использования. Посмотрите этот список бесплатных инструментов извлечения файлов, если вы заинтересованы в этом.
Читайте также: