Что означает в названии файла бд решетка
Имя объекта базы данных называется его идентификатором. Идентификаторы в Microsoft SQL Server могут присваиваться любым сущностям: серверам, базам данных и их объектам, например таблицам, представлениям, столбцам, индексам, триггерам, процедурам, ограничениям и правилам. Для большинства объектов идентификаторы необходимы, а для некоторых, например ограничений, необязательны.
Идентификатор объекта создается при определении объекта. Затем идентификатор используется для обращения к объекту. Например, следующая инструкция создает таблицу с идентификатором TableX и двумя столбцами с идентификаторами KeyCol и Description :
Эта таблица также содержит безымянное ограничение. Ограничение PRIMARY KEY не имеет идентификатора.
Параметры сортировки идентификатора зависят от уровня, для которого определен этот идентификатор. К идентификаторам объектов на уровне экземпляров, таких как имена входа и имена базы данных, применяются параметры сортировки по умолчанию для экземпляра. Идентификаторам объектов в пределах базы данных, например таблиц, представлений или имен столбцов, назначаются параметры сортировки, установленные по умолчанию для базы данных. Например, две таблицы с именами, отличающимися только регистром, могут быть созданы в базе данных с параметрами сортировки c учетом регистра, но не могут быть созданы в базе данных с параметрами сортировки без учета регистра.
Имена переменных или параметров функций и хранимых процедур должны соответствовать правилам для идентификаторов Transact-SQL .
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Целостность базы данных
На текущий момент развития СУБД Caché возможные случаи и ошибки, которые могли бы привести к деградации БД, сведены к минимуму, и необходимость ремонта базы данных возникает всё реже. Но проверку целостности в любом случае рекомендуется проводить регулярно на автоматической основе. Для этого есть утилита ^Integrity, которую можно запустить через терминал из области %SYS, через портал управления, на странице Базы данных, а также через менеджер задач. Кстати, задача по автоматической проверке целостности уже настроена по умолчанию, но отключена – её достаточно только активировать:


В процессе проверки целостности, проверяется правильность указания нижних ссылок, правильность типов блоков, выполняется проверка правых связей. Сравниваются также и узлы глобалов, чтобы они соответствовали порядку сортировки. Если в результате проверки целостности всё-таки были обнаружены ошибки, то можно воспользоваться утилитой ^REPAIR, которую можно запустить в области %SYS. Эта утилита позволяет как просмотреть любой блок, так и подредактировать при необходимости, т.е. отремонтировать БД.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Теория
База данных Caché представляет собой каталог с названием базы, в котором содержится файл CACHE.DAT. На *nix-системах, в качестве базы данных может выступать раздел на диске.
Данные в Caché хранятся в блоках, а те, в свою очередь, организованы в виде сбалансированного B*-дерева. Если вспомнить, что мы храним глобалы в виде дерева в упрощённом понимании, ветками в таком дереве будут сами индексы глобала, а листьями – значения индекса глобала. Отличие сбалансированного B*-дерева от обычного B-дерева в том, что ветви имеют правые связи, помогающие (в нашем случае с глобалами) обходить индексы достаточно быстро с помощью функций $Order и $Query, без необходимости подниматься к стволу дерева.
Размер блока в файле БД фиксированный, по умолчанию он составляет 8192Б, но есть возможность разрешить создавать БД с размерами блоков 16кБ, 32кБ и 64кБ. Разработчик системы может выбрать необходимый размер блока в зависимости от характера данных, которые он планирует хранить. Но всегда нужно учитывать, что чтение данных производится поблочно – даже если запрошено одно значение размером 1 байт, будет прочитано несколько блоков, и только последним в этой цепочке будет блок с данными. Caché также имеет разные буферы глобалов – нельзя смонтировать или создать новую БД, если в системе не настроен буфер глобалов с соответствующим размером блока – это приведёт к ошибке.


На картинке как раз выделена память для буфера глобалов для баз с 8кБ блоками – только такие базы с 8кБ блоками и будут работать в этой системе. Блоки в БД сгруппированы в карты, одна карта в случае с 8кБ блоком описывает 62464 блока, и хранится в блоке карты, который идёт первым в карте.
Классы идентификаторов
Существует два класса идентификаторов.
Обычные идентификаторы
Соответствуют правилам форматирования идентификаторов. Обычные идентификаторы не разделяются при использовании в инструкциях языка Transact-SQL .
Идентификаторы с разделителем
Заключаются в двойные кавычки (") или квадратные скобки ([ ]). Идентификаторы, которые соответствуют правилам форматирования идентификаторов, могут быть не разделяемыми. Пример:
Идентификаторы, которые не соответствуют всем правилам для идентификаторов, в инструкции языка Transact-SQL должны быть разделены. Пример:
И обычные идентификаторы, и идентификаторы с разделителями должны содержать от 1 до 128 символов. Для локальных временных таблиц идентификатор может содержать не более 116 символов.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Типы файлов в SQL Server
- Файлы данных – это файлы, в которых хранятся сами данные. Такие файлы бывают двух типов:
- Первичный файл данных – имеет расширение .mdf (Master Data File). Данный файл присутствует в любой базе данных. Кроме данных, он еще содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных;
- Вторичный файл данных – имеет расширение .ndf (Not Master Data File). Данные типы файлов база данных может и не содержать, они создаются дополнительно к первичному файлу. С помощью именно таких файлов мы можем распределять данные на несколько дисков.
![Скриншот 1]()
По умолчанию файлы базы данных располагаются в каталоге, который Вы указали в момент установки SQL Server на этапе настройки ядра в поле «Каталог пользовательской базы данных» для файлов данных, и в поле «Каталог журналов пользовательской базы данных» для журнала транзакций.
Однако при создании базы данных, или добавлении файла к базе данных, Вы можете указать свой путь к каталогу, в котором хранить создаваемый файл.
Практика
Но всё это теория. Как выглядит глобал и его блоки на самом деле – судить пока довольно сложно. Единственный сейчас доступный способ просмотра блоков – это упомянутая выше утилита ^REPAIR. Вывод этой программы выглядит примерно так:
![]()
Я не так давно начал работать над проектом, который позволяет пройтись по дереву блоков, без риска повредить БД, и удобно просматривать в браузере, с возможностью сохранить эту визуализацию в SVG или PNG-формате. Проект называется CacheBlocksExplorer, исходники проекта выложены на Github.
![]()
Из реализованных возможностей:
- Возможность просмотреть любую настроенную или просто смонтированную БД в системе;
- Возможность просматривать информацию по блоку, тип блока, правый указатель, список узлов с их ссылками;
- При клике на любой узел, имеющий ссылку на нижний блок, информацию по данному блоку загрузится и отобразится, так же как и ссылка на загруженный блок;
- Есть возможность удалить из отображения некоторые блоки, просто удалив ссылку, к изменениям в данных это не приведет.
- Отображение правой ссылки: на данный момент отображается как информация по блоку, хотелось бы показать в виде стрелочки;
- Поддержка отображения блоков больших строк: сейчас они просто не отображаются;
- Отображение всех блоков каталога глобалов, а не только третьего.
В следующей статье я расскажу подробнее на примерах, как всё работает и что можно узнать о наших глобалах и блоках, если у вас есть такой инструмент, как разработанный мной Cache Block Explorer.
![Архитектура хранения данных в Microsoft SQL Server]()
Файловые группы
В Microsoft SQL Server есть возможность объединять файлы данных в файловые группы.
Файловая группа в SQL Server – это логический контейнер, который объединяет несколько файлов данных.
Файловые группы нужны нам в основном для более гибкого управления хранением данных в SQL Server. Дело в том, что с помощью файловых групп мы можем одни таблицы хранить в одних файлах, а другие в других, иными словами, благодаря файловым группам мы можем распределять таблицы по разных файлам и по разным дискам.
Например, мы знаем, что одна таблица у нас будет очень большой и на ее хранение потребуется несколько дисков, поэтому ее (т.е. только одну эту таблицу), мы можем поместить в отдельную файловую группу, в которую добавить несколько файлов, каждый из которых будет храниться на отдельном диске. Все остальные таблицы мы будем хранить в другой файловой группе, т.е. уже в других файлах и, соответственно, на других дисках.
Без файловых групп мы этого сделать не можем, т.е. мы можем, конечно же, создать дополнительные файлы данных, но распределять данные по этим файлам будет сам SQL Server, т.е. на это мы уже не можем повлиять.
Таким образом, при создании таблиц мы можем указать, в какой файловой группе создавать эту таблицу. Если в базе данных создавать объекты без указания файловой группы (в большинстве случаев так и делается), к которой они относятся, они создаются в файловой группе по умолчанию.
По умолчанию в SQL сервере создана файловая группа PRIMARY, и если Вы не создавали дополнительных файловых групп, то все объекты базы данных будут храниться именно в этой файловой группе.
Файловую группу по умолчанию можно переопределить инструкцией ALTER DATABASE, т.е. можно создать файловую группу и назначить ее файловой группой по умолчанию, при этом стоит отметить, что все системные объекты хранятся в файловой группе PRIMARY, а не в новой файловой группе по умолчанию. Иными словами, файловая группа PRIMARY – это особенная файловая группа, в которой хранятся системные объекты и которую нельзя удалить.
Также стоит отметить, что один файл данных может входить в состав только одной файловой группы.
Примечание! Файлы журнала транзакций не могут входить в файловые группы.
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Устройство файлов базы данных SQL Server
Мы с Вами поговорили о том, как на верхнем уровне хранятся данные в SQL Server, теперь давайте немного поговорим о том, как хранятся данные на более низком уровне, т.е. как организовано внутреннее хранение данных в тех самых файлах данных.
В файлах данных в SQL Server все данные хранятся на страницах, которые группируются в экстенты.
Поэтому давайте чуть более подробно поговорим о страницах и экстентах.
Дисковое пространство, выделенное для размещения файлов базы данных (MDF или NDF), логически разделяется на страницы. Иными словами, внутреннее пространство файлов данных разделено на страницы и именно в этих страницах хранятся наши данные.
Все дисковые операции ввода-вывода в SQL Server выполняются на уровне страницы и это означает, что SQL Server считывает или записывает целые страницы данных.
Например, в процессе оптимизации запросов мы очень часто говорим о количестве логических чтений, которые выполняются на уровне запроса, так вот – это количество как раз и представляет собой количество считанных страниц данных.
Если провести аналогию, то файл базы данных в SQL Server (MDF или NDF) представляет собой бумажную книгу, содержимое которой написано на страницах. Иными словами, в SQL Server все строки данных точно так же, как и в бумажной книге, записываются на страницы, которые имеют одинаковый физический размер 8 килобайт.
Основную часть файла данных занимают страницы с данными, как и у книги страницы с содержимым, а на некоторых страницах могут находиться метаданные об этом содержимом, например, как оглавление или алфавитный указатель в бумажной книге.
Как уже было отмечено размер страницы в SQL Server составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц.
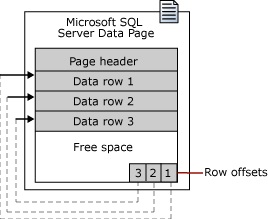
Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Строки данных заносятся на страницу последовательно, сразу же после заголовка. В конце страницы располагается таблица смещения строк.
Таблица смещения строк содержит одну запись для каждой строки на странице. Каждая запись смещения строк регистрирует, насколько далеко от начала страницы находится первый байт строки. Таким образом, таблицы смещения строк помогает SQL Server быстро находить строки на странице. Записи в таблице смещения строк находятся в обратном порядке относительно последовательности строк на странице.
![Скриншот 2]()
В следующей таблице представлены типы страниц, которые используются в файлах данных базы данных SQL Server.
Тип страницы Описание Data page Строки с данными, за исключением типов text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и xml. Index page Содержимое индекса. Text/Image Текст/изображение. Типы данных больших объектов: text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и данные xml.
Столбцы переменной длины, когда размер строки данных превышает 8 КБ: varchar, nvarchar, varbinary и sql_variant.Global Allocation Map (GAM) Глобальная карта распределения. На GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен, если бит равен 0, то экстент размещен. Shared Global Allocation Map (SGAM) Общая глобальная карта распределения. На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются. Page Free Space (PFS) Сведения о размещении страниц и доступном на них свободном месте. Index Allocation Map (IAM) Карта распределения индекса. Сведения об экстентах, используемых таблицей или индексом для единицы распределения. Bulk Changed Map (BCM) Карта массовых изменений данных. Сведения об экстентах, измененных массовыми операциями со времени последнего выполнения инструкции BACKUP LOG для единицы распределения. Differential Changed Map (DCM) Карта изменений для разностной резервной копии. Сведения об экстентах, измененных с момента последнего выполнения инструкции BACKUP DATABASE для единицы распределения. Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
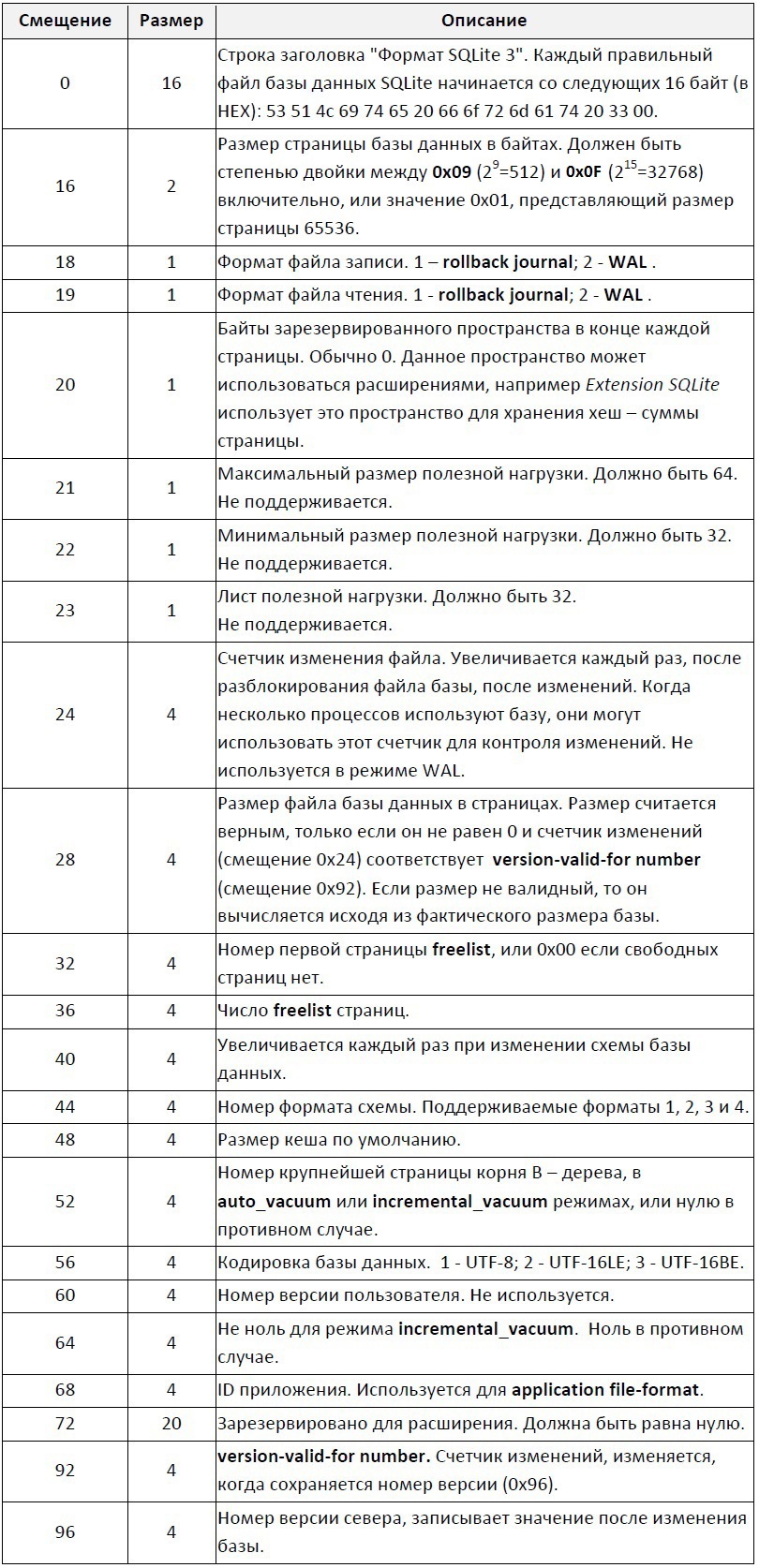
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (~140 Тбайт).Заголовок
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
![]()
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.
![]()
B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.
![]()
Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
Не так давно на хабре в блоге InterSystems были выложены статьи о том, что собой представляет глобал в Caché, с чем его готовят и как подают (часть 1 и часть 2). Это всё, конечно, интересно, удобство работы с любыми моделями данных, какие только пожелает разработчик. Но что обеспечивает хорошую скорость обращения с этими глобалами?
![]()
Общая архитектура хранения
Данные в базе данных Microsoft SQL Server, как и в любой другой базе данных, физически хранятся в виде обычных файлов операционной системы, при этом в SQL Server внешне это выглядит, на самом деле, достаточно понятно.
Дело в том, что существует всего 3 типа файлов, которые могут существовать у базы данных в SQL Server. При этом, конечно же, каждый файл относится к какой-то конкретной базе данных, иными словами, у каждой базы данных есть свои индивидуальные файлы.
Стоит отметить, что в простейшем виде большинство баз данных, реализованных в SQL Server, будет состоять всего из двух файлов (mdf и ldf), именно это и создаёт понятную внешнюю картину физического хранения данных в Microsoft SQL Server.
По мере увеличения данных, увеличения нагрузки на базу данных, безусловно потребуется оптимизация хранения данных, за счёт их распределения по нескольким дискам, поэтому в крупных базах данных появляются дополнительные файлы данных (ndf), благодаря которым мы можем распределить данные одной базы данных на несколько дисков.
Файлы базы данных
SQL Server имеют три типа файлов.
Файл Описание Первичная Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. Вторичная Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. Журнал транзакций Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Экстенты
Экстент — это набор из 8 физически непрерывных страниц.
Экстенты являются основными единицами организации пространства. Как было отмечено, экстент состоит из восьми непрерывных страниц или 64 КБ. Это означает, что в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Экстенты используются для эффективного управления страницами.
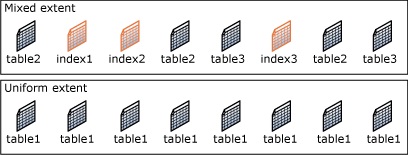
В SQL Server есть два типа экстентов:
- Однородные экстенты (Uniform) – это экстенты, которые принадлежат одному объекту, и все восемь страниц экстента может использовать только этот владеющий объект;
- Смешанные экстенты (Mixed) – это экстенты, которые могут находиться в общем пользовании максимум у восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
![Скриншот 3]()
SQL Server до 2016 версии не выделяет целые экстенты для таблиц с небольшими объемами данных. Под новую таблицу или индекс обычно выделяются страницы из смешанных экстентов. Когда таблица или индекс вырастают до восьми страниц, они переключаются на использование однородных экстентов для последующих распределений. Если Вы создаете индекс для существующей таблицы, в которой достаточно строк для создания восьми страниц в индексе, все выделения для индекса будут в однородных экстентах.
Начиная с SQL Server 2016 по умолчанию для большей части распределений в пользовательской базе данных и базе данных tempdb используются однородные экстенты. Это не касается распределений, принадлежащих первым восьми страницам цепочки IAM. Для распределений баз данных master и msdb, и model сохраняется предыдущее поведение.
SQL Server использует два типа карт распределения для выделения экстентов:
- Глобальная карта распределения (GAM) – на GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент размещен.
- Общая глобальная карта распределения (SGAM) – на SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Каждый экстент обладает следующими наборами битовых шаблонов в картах GAM и SGAM, основанными на его текущем использовании.
Текущее использование экстента Настройка битов карты GAM Настройка битов карты SGAM Свободно, в текущий момент не используется 1 0 Однородный экстент или заполненный смешанный экстент 0 0 Смешанный экстент со свободными страницами 0 1 Таким образом, упрощенный алгоритм управления экстентами страниц следующий:
- Для выделения однородного экстента SQL Server производит на карте GAM поиск бита 1 и заменяет его на бит 0;
- Для поиска смешанного экстента со свободными страницами SQL Server производит поиск на карте SGAM бита 1;
- Для выделения смешанного экстента SQL Server производит на карте GAM поиск бита 1, заменяет его на бит 0, а затем устанавливает значение соответствующего бита на карте SGAM равным 1;
- Для освобождения экстента SQL Server устанавливает бит GAM равным 1, а соответствующий бит SGAM равным 0.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Правила для обычных идентификаторов
Имена переменных, функций и хранимых процедур должны соответствовать этим правилам для идентификаторов Transact-SQL .
Первым символом должен быть один из следующих.
Буква в соответствии со стандартом Unicode Standard 3,2. Определения букв в стандарте Юникод включают латинские символы от «a» до «z», от «A» до «Z», а также буквенные символы других языков;
Некоторые функции языка Transact-SQL имеют имена, начинающиеся с двойного символа «@» (@@). Во избежание путаницы с этими функциями не следует использовать имена, начинающиеся символами @@.
Последующие символы могут включать:
Буквы в соответствии со стандартом Unicode Standard 3,2.
Десятичные цифры из набора символов Basic Latin или другого набора символов национального языка.
Идентификатор не должен быть зарезервированным словом Transact-SQL . SQL Server резервирует версии зарезервированных слов как в верхнем, так и в нижнем регистре. Если идентификаторы используются в инструкциях языка Transact-SQL , идентификаторы, которые не соответствуют этим правилам, должны быть заключены в двойные кавычки или квадратные скобки. Состав зарезервированных слов зависит от уровня совместимости базы данных. Этот уровень можно установить с помощью инструкции ALTER DATABASE .
Внутри идентификаторов запрещается использовать символы пробела или специальные символы.
Если идентификаторы используются в инструкциях языка Transact-SQL , идентификаторы, которые не соответствуют этим правилам, должны быть заключены в двойные кавычки или квадратные скобки.
Некоторые правила форматирования обычных идентификаторов зависят от уровня совместимости базы данных. Этот уровень можно установить с помощью процедуры ALTER DATABASE.
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Файлы базы данных SQL Server
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
Файловая группа Описание Первичная Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. Данные, оптимизированные для памяти В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. Файловый поток Определяемые пользователем маршруты Любая файловая группа, созданная пользователем при создании или изменении базы данных. Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Рекомендации по работе с файлами и файловыми группами
- Для всех баз данных рекомендуется создать дополнительную файловую группу и сделать ее файловой группой по умолчанию, чтобы в файловой группе PRIMARY и в первичном файле хранились только системные таблицы и объекты;
- Чтобы увеличить производительность, разносите файлы и файловые группы по нескольким физическим дискам, при этом объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы;
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках, например, размещайте большие и быстрорастущие таблицы на отдельных дисках;
- Если несколько таблиц очень часто используются в одних и тех же запросах с соединениями, можно поместить эти таблицы в разные файловые группы и тем самым увеличить производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод;
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, можно помещать в разные файловые группы и на разные диски, что также увеличит производительность за счет параллельного ввода-вывода;
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы. Иными словами, файл журнала транзакций по возможности помещайте на отдельный, достаточно быстрый диск.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Типы блоков
Существует несколько типов блоков. На каждом уровне блоков правая связь должна указывать на блок того же типа, либо на нулевой блок, что может означать, что дальше данных нет.
-
тип 9: блок каталога глобалов. Используется для описания всех имеющихся глобалов и их параметров. Для каждого глобала в этом блоке определена сортировка (collation) индексов глобала — очень важный параметр, отвечающий за сортировку данных. Этот параметр не может быть изменен после создания глобала;
![]()
Там же можно создать новый глобал – в таком случае можно задать сразу любую доступную сортировку и выбрать её отличной от той, что установлена по умолчанию в базе данных.
![]()
![]()
В общем виде дерево блоков можно представить как на картинке ниже. Красным цветом отмечены ссылки на блоки.
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Читайте также: