
Что хранится в файле базы данных хранится
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Общие сведения
База данных представляет собой набор сведений, связанных с определенной темой или функцией, например отслеживанием заказов покупателей или обработкой музыкальной коллекции. Если база данных полностью или частично хранится не на компьютере, данные могут быть собираться из нескольких источников, которые необходимо координировать.
Предположим, что номера телефонов поставщиков хранятся в различных местах: в файле виртуальной визитной карточки, файлах со сведениями о продукте в картотеке и в электронной таблице со сведениями о заказах. В случае изменения телефона поставщика необходимо обновить соответствующие данные во всех трех местах. В грамотно спроектированной базе данных Access номер телефона сохраняется всего один раз, поэтому обновить данные придется лишь однажды. При обновлении номера телефона он автоматически будет обновлен в любом месте базы данных, где он используется.
Отчеты
1. Создание почтовых наклеек с помощью отчета.
2. Отображение итоговых значений на диаграмме с помощью отчета.
3. Использование отчета для отображения рассчитанных итоговых данных.
После того как вы ознакомились с базовой структурой баз данных Access, ознакомьтесь со сведениями об использовании встроенных инструментов для изучения конкретной базы данных Access.
Рекомендации по работе с файлами и файловыми группами
- Для всех баз данных рекомендуется создать дополнительную файловую группу и сделать ее файловой группой по умолчанию, чтобы в файловой группе PRIMARY и в первичном файле хранились только системные таблицы и объекты;
- Чтобы увеличить производительность, разносите файлы и файловые группы по нескольким физическим дискам, при этом объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы;
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках, например, размещайте большие и быстрорастущие таблицы на отдельных дисках;
- Если несколько таблиц очень часто используются в одних и тех же запросах с соединениями, можно поместить эти таблицы в разные файловые группы и тем самым увеличить производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод;
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, можно помещать в разные файловые группы и на разные диски, что также увеличит производительность за счет параллельного ввода-вывода;
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы. Иными словами, файл журнала транзакций по возможности помещайте на отдельный, достаточно быстрый диск.
Файл и документ — это одно и то же?
Файлами называют вообще любые последовательности байтов на диске, у которых есть имя и адрес. Если файл зашифрован, не открывается, внутри него сбои или пустота — это всё равно файл.
Документом называют файл, в котором лежит что-то полезное для пользователя, что он может открыть и с чем может осмысленно взаимодействовать. Например, ваша курсовая работа в формате Word — для вас это документ, а для компьютера — файл.
Для сравнения, системная библиотека программы Microsoft Word — это не документ, а просто файл. Вы не можете его открыть, но его использует программа Word для работы.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Просмотр таблицы в режиме конструктора
Примечание: Режим конструктора недоступен для таблиц в веб-базах данных.
Открытие таблицы в Конструкторе позволяет подробно изучить ее структуру. Например, можно найти параметры типа данных для каждого поля и любые маски ввода или узнать, используются ли в таблице поля подстановок — поля, которые с помощью запросов извлекают данные из других таблиц. Эти сведения полезны потому, что типы данных или маски ввода могут влиять на возможность искать данные и выполнять запросы на обновление. Предположим, что необходимо использовать запрос на обновление для обновления некоторых полей в таблице путем копирования данных из таких же полей другой таблицы. Запрос не удастся выполнить, если типы данных каждого поля в исходной и целевой таблицах не совпадают.
Откройте базу данных, которую необходимо проанализировать.
В области навигации щелкните правой кнопкой мыши таблицу, которую нужно изучить, и выберите в контекстном меню пункт Режим конструктора.
При необходимости запишите имя каждого поля таблицы и его тип данных.
Тип данных поля может ограничивать размер и тип данных, которые можно ввести в поле. Например, размер текстового поля может быть ограничен 20 знаками, а поле с типом данных "Числовой" не поддерживает ввод текста.
Чтобы определить, является ли поле полем подстановок, откройте вкладку Поле подстановки в нижней части бланка запроса в разделе Свойства поля.
Поле подстановок отображает один набор значений (одно или несколько полей, например имя и фамилию), но обычно хранит другой набор значений (одно поле, такое как числовой код). Например, поле подстановок может содержать код сотрудника (хранимое значение), но отображать имя сотрудника (отображаемое значение). При использовании поля подстановок в выражениях или при поиске и замене необходимо использовать хранимое значение, а не отображаемое. Знакомство с хранимыми и отображаемыми значениями полей подстановок — лучший способ убедиться в том, что выражение или операция поиска и замены с использованием поля подстановки работает надлежащим образом.
На приведенном ниже рисунке показано типичное поле подстановок. Параметры, отображаемые в свойстве Источник строк поля, можно изменить.
Показанное здесь поле подстановок использует запрос для извлечения данных из другой таблицы. Существует также другой тип поля подстановок — список значений, который использует определенный в программе список вариантов. На приведенном ниже рисунке показан типичный список значений.
По умолчанию списки значений используют текстовый тип данных.
Лучший способ найти списки подытогов и значений — отобразить вкладку Под поиск и щелкнуть записи в столбце Тип данных для каждого поля таблицы. Дополнительные сведения о создании полей подпапок и списков значений см. по ссылкам в разделе См. также .
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Таблицы и связи
Для хранения данных необходимо создать таблицу для каждого типа отслеживаемых сведений. Типы сведений могут включать данные о покупателях, продуктах или подробные сведения о заказах. Чтобы объединить данные из нескольких таблиц в запросе, форме или отчете, нужно определить связи между таблицами.
Примечание: В веб-базах данных и веб-приложениях создать связи на вкладке объекта "Схема данных" невозможно. Используйте для этого поля подстановки.
1. Сведения о клиентах, которые когда-то хранились в списке рассылки, теперь находятся в таблице "Покупатели".
2. Сведения о заказах, которые когда-то хранились в электронной таблице, теперь находятся в таблице "Заказы".
3. Уникальный код, например код покупателя, позволяет отличать записи в таблице друг от друга. Добавляя уникальное поле кода из одной таблицы в другую и определяя связи между полями, Access может сопоставить связанные записи в обеих таблицах, чтобы их можно было вместе добавить в форму, отчет или запрос.
Имя и расширение
Название файла чаще всего состоит из имени и расширения, которые отделяются друг от друга точкой:

Но на самом деле название файла может быть и без расширения, и без точки или вообще начинаться с точки, как .htaccess.
Компьютеру на самом деле без разницы, есть ли у файла расширение или нет. Единственное, зачем оно нужно, — чтобы и компьютер, и человек понимали, какие данные в нём могут храниться и в какой программе нужно открыть этот файл. Для этого компьютер создаёт таблицу расширений и приложений — в ней написано, файлы с каким расширением открывать в каких программах.

👉 В разных операционных системах свои требования к названию файла: в Windows нельзя создать файл .con, а в MacOS это можно сделать без проблем.
Просмотр подробных сведений об объектах в базе данных
Лучше всего ознакомиться с определенной базой данных с помощью архивариуса базы данных. Он используется для создания отчетов с подробными сведениями об объектах в базе данных. Сначала необходимо выбрать объекты, которые должны быть описаны в отчете. Отчет архивариуса будет содержать все данные о выбранных объектах.
Откройте нужную базу данных.
На вкладке Работа с базами данных в группе Анализ нажмите кнопку Архивариус.
В диалоговом окне Архивариус откройте вкладку, представляющую тип объекта базы данных, который необходимо задокументировать. Чтобы создать отчет обо всех объектах в базе данных, откройте вкладку Все типы объектов.
Выберите один или несколько указанных на вкладке объектов. Для выбора всех объектов нажмите кнопку Выбрать все.
Архивариус создаст отчет с подробными сведениями о каждом выбранном объекте, а затем откроет отчет в режиме просмотра перед печатью. Например, если архивариус был запущен для формы ввода данных, созданный им отчет будет содержать свойства всей формы, каждого раздела формы, всех кнопок, значков, текстовых полей и других элементов управления, а также модулей кода и пользовательских разрешений, связанных с формой.
Для печати отчета откройте вкладку Просмотр перед печатью и в группеПечать нажмите кнопкуПечать.
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Экстенты
Экстент — это набор из 8 физически непрерывных страниц.
Экстенты являются основными единицами организации пространства. Как было отмечено, экстент состоит из восьми непрерывных страниц или 64 КБ. Это означает, что в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Экстенты используются для эффективного управления страницами.
В SQL Server есть два типа экстентов:
- Однородные экстенты (Uniform) – это экстенты, которые принадлежат одному объекту, и все восемь страниц экстента может использовать только этот владеющий объект;
- Смешанные экстенты (Mixed) – это экстенты, которые могут находиться в общем пользовании максимум у восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
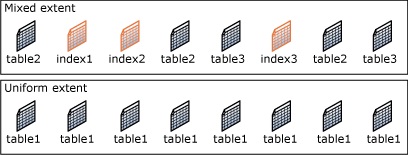
SQL Server до 2016 версии не выделяет целые экстенты для таблиц с небольшими объемами данных. Под новую таблицу или индекс обычно выделяются страницы из смешанных экстентов. Когда таблица или индекс вырастают до восьми страниц, они переключаются на использование однородных экстентов для последующих распределений. Если Вы создаете индекс для существующей таблицы, в которой достаточно строк для создания восьми страниц в индексе, все выделения для индекса будут в однородных экстентах.
Начиная с SQL Server 2016 по умолчанию для большей части распределений в пользовательской базе данных и базе данных tempdb используются однородные экстенты. Это не касается распределений, принадлежащих первым восьми страницам цепочки IAM. Для распределений баз данных master и msdb, и model сохраняется предыдущее поведение.
SQL Server использует два типа карт распределения для выделения экстентов:
- Глобальная карта распределения (GAM) – на GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент размещен.
- Общая глобальная карта распределения (SGAM) – на SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Каждый экстент обладает следующими наборами битовых шаблонов в картах GAM и SGAM, основанными на его текущем использовании.
| Текущее использование экстента | Настройка битов карты GAM | Настройка битов карты SGAM |
| Свободно, в текущий момент не используется | 1 | 0 |
| Однородный экстент или заполненный смешанный экстент | 0 | 0 |
| Смешанный экстент со свободными страницами | 0 | 1 |
Таким образом, упрощенный алгоритм управления экстентами страниц следующий:
- Для выделения однородного экстента SQL Server производит на карте GAM поиск бита 1 и заменяет его на бит 0;
- Для поиска смешанного экстента со свободными страницами SQL Server производит поиск на карте SGAM бита 1;
- Для выделения смешанного экстента SQL Server производит на карте GAM поиск бита 1, заменяет его на бит 0, а затем устанавливает значение соответствующего бита на карте SGAM равным 1;
- Для освобождения экстента SQL Server устанавливает бит GAM равным 1, а соответствующий бит SGAM равным 0.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
Когда мы говорим о компьютерах, то знаем, что на нём хранятся файлы, а в этих файлах — какие-то данные: музыка, видео, тексты и т. д. Но для компьютера всё немного иначе и сложнее. Сейчас объясним.
Эта статья — часть цикла об устройстве компьютера для новичков. Покажите её своим родителям или друзьям-гуманитариям, если им нужно объяснить, что такое файл. Если вы хотите чего-то посложнее, почитайте нашу серию статей про векторы и матрицы.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (~140 Тбайт).
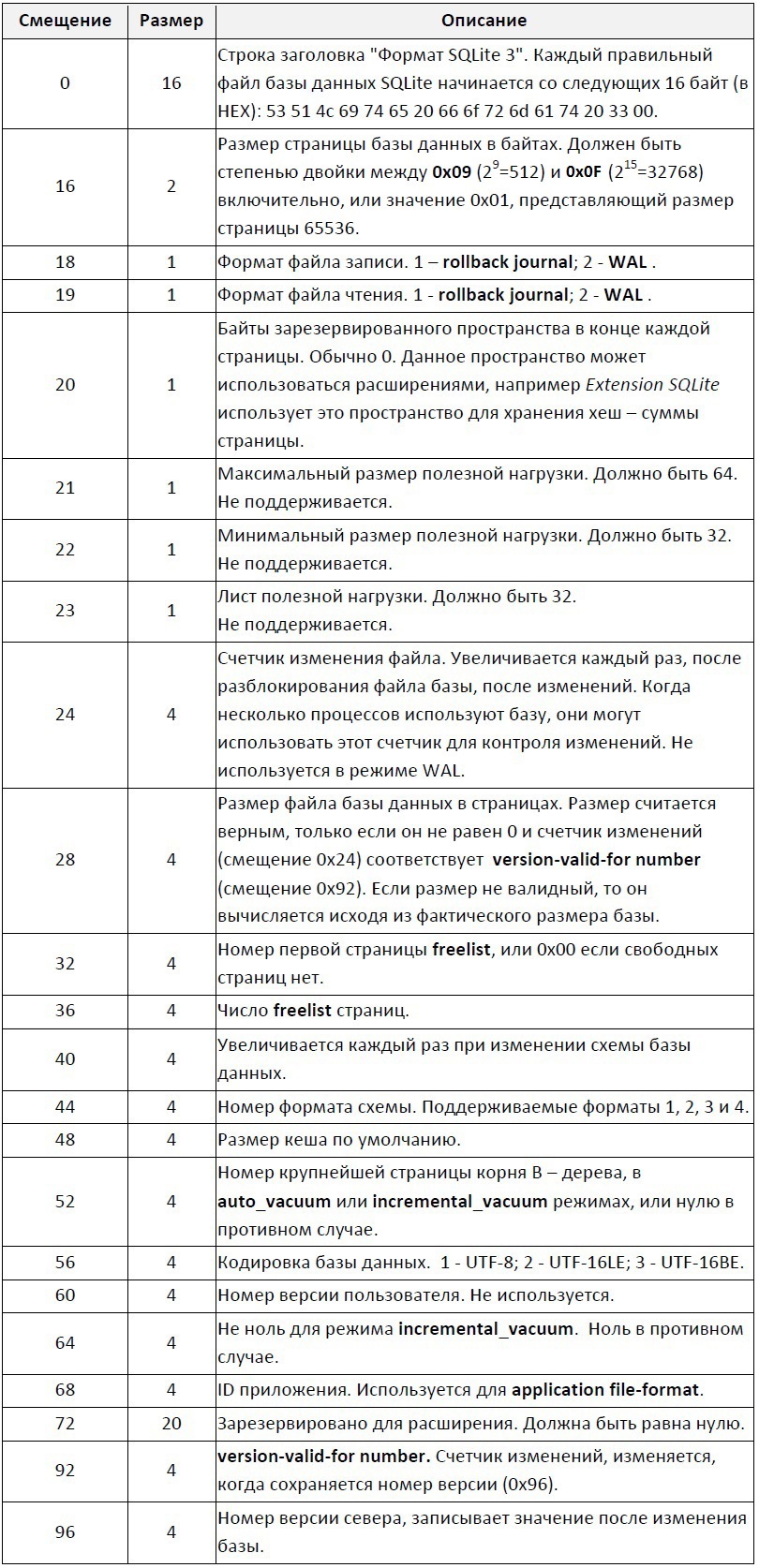
Заголовок
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.

Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
Знакомство с таблицами, формами, запросами и другими объектами в базе данных Access поможет вам с легкостью выполнять различные задачи, такие как ввод данных в форму, добавление или удаление таблиц, поиск и замена данных и выполнение запросов.
Данная статья содержит общие сведения о структуре базы данных Access. Access предоставляет несколько инструментов, которые можно использовать для ознакомления со структурой конкретной базы данных. Кроме того, в статье описано, как, для чего и когда следует использовать каждый из этих инструментов.
Примечание: Эта статья посвящена классическим базам данных Access, которые включают в себя один или несколько файлов, где хранятся все данные и определены все возможности приложения, такие как формы для ввода данных. Некоторые сведения из статьи неприменимы к веб-базам данных и веб-приложениям Access.
Файлы баз данных Access
Приложение Access можно использовать для управления всеми данными в одном файле. В файле базы данных Access можно использовать:
таблицы для сохранения данных;
запросы для поиска и извлечения только необходимых данных;
формы для просмотра, добавления и изменения данных в таблицах;
отчеты для анализа и печати данных в определенном формате.
1. Данные сохраняются один раз в одной таблице, но просматриваются из различных расположений. При изменении данных они автоматически обновляются везде, где появляются.
2. Извлечение данных с помощью запроса.
3. Просмотр или ввод данных с помощью формы.
4. Отображение или печать данных с помощью отчета.
Все эти элементы: таблицы, запросы, формы и отчеты — представляют собой объекты базы данных.
Примечание: Некоторые базы данных Access содержат ссылки на таблицы, хранящиеся в других базах. Например, одна база данных Access может содержать только таблицы, а другая — ссылки на них, а также запросы, формы и отчеты, основанные на связанных таблицах. В большинстве случаев неважно, содержится ли в базе данных сама таблица или ссылка на нее.
Что может храниться в файле
Файл — это просто последовательность байтов на диске, а значит, туда можно записать что угодно:
- фильмы,
- музыку,
- отчёты,
- таблицы,
- фотографии,
- игры,
- драйверы,
- библиотеки для языка разработки.
Главное в файлах не то, что лежит внутри, а как компьютер может с этим работать и какие программы запустить, чтобы файл открылся. Если скинуть на компьютер с Windows фотографии, сделанные на последний айфон в специальном формате, то без дополнительных программ их посмотреть не получится.
Поэтому самое ценное в файлах — чтобы их можно было открыть и посмотреть. Без этого файл так и останется последовательностью нулей и единиц на диске.
В этой статье
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Общая архитектура хранения
Данные в базе данных Microsoft SQL Server, как и в любой другой базе данных, физически хранятся в виде обычных файлов операционной системы, при этом в SQL Server внешне это выглядит, на самом деле, достаточно понятно.
Дело в том, что существует всего 3 типа файлов, которые могут существовать у базы данных в SQL Server. При этом, конечно же, каждый файл относится к какой-то конкретной базе данных, иными словами, у каждой базы данных есть свои индивидуальные файлы.
Стоит отметить, что в простейшем виде большинство баз данных, реализованных в SQL Server, будет состоять всего из двух файлов (mdf и ldf), именно это и создаёт понятную внешнюю картину физического хранения данных в Microsoft SQL Server.
По мере увеличения данных, увеличения нагрузки на базу данных, безусловно потребуется оптимизация хранения данных, за счёт их распределения по нескольким дискам, поэтому в крупных базах данных появляются дополнительные файлы данных (ndf), благодаря которым мы можем распределить данные одной базы данных на несколько дисков.
Файлы и папки
Чтобы не сваливать все файлы в одну кучу (а на самых первых компьютерах было именно так), придумали папки — это такие виртуальные коробки, внутри которых могут храниться файлы и другие папки.

Если удалить папку, то удалятся все файлы и папки, которые лежали внутри неё. А если папку переместить на новое место — то всё её содержимое тоже переедет вместе с ней.
Ещё есть такое понятие, как «путь к файлу». Это означает последовательность всех папок, которые нужно пройти, чтобы добраться до нужного файла. Если у нас файл «Отчёт 2022.doc» лежит в папке «Отчёты», а «Отчёты» лежат в папке «Работа» на диске D, то полный путь к файлу будет выглядеть так:
👉 Папка — это способ организации файлов, придуманный специально для человека. Компьютер и без папок может запомнить, где какой служебный файл у него лежит.
Файлы базы данных
SQL Server имеют три типа файлов.
| Файл | Описание |
|---|---|
| Первичная | Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. |
| Вторичная | Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. |
| Журнал транзакций | Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. |
Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Просмотр связей между таблицами
Чтобы получить графическое представление таблиц в базе данных, полей в каждой таблице и связей между таблицами, используйте вкладку объектаСвязи. Вкладка объекта Связи позволяет получить общее представление о таблице и структуре связей базы данных; эти сведения необходимы при создании или изменении связей между таблицами.
Примечание: Вкладку объекта Связи можно также использовать для добавления, изменения или удаления связей.
Откройте базу данных, которую необходимо проанализировать.
На вкладке Работа с базами данных в группе Связи нажмите кнопку Связи.
Откроется вкладка объекта Связи, на которой будут показаны связи между всеми таблицами в открытой базе данных.
Примечание: В веб-базах данных и веб-приложениях использовать вкладку объекта "Схема данных" невозможно.

Запросы
С помощью запроса можно найти и извлечь данные (в том числе и данные из нескольких таблиц), соответствующие указанным условиям. Запросы также используются для обновления или удаления нескольких записей одновременно и выполнения предопределенных или пользовательских вычислений на основе данных.
Примечание: В веб-базах данных и веб-приложениях использовать запросы для обновления или удаления записей невозможно.
1. Таблица "Покупатели" содержит сведения о покупателях.
2. Таблица "Заказы" содержит сведения о заказах.
3. Этот запрос извлекает из таблицы заказов код заказа и дату назначения, а из таблицы покупателей — название компании и город. Запрос возвращает только те заказы, которые были оформлены в апреле и только покупателями из Лондона.
Устройство файлов базы данных SQL Server
Мы с Вами поговорили о том, как на верхнем уровне хранятся данные в SQL Server, теперь давайте немного поговорим о том, как хранятся данные на более низком уровне, т.е. как организовано внутреннее хранение данных в тех самых файлах данных.
В файлах данных в SQL Server все данные хранятся на страницах, которые группируются в экстенты.
Поэтому давайте чуть более подробно поговорим о страницах и экстентах.
Дисковое пространство, выделенное для размещения файлов базы данных (MDF или NDF), логически разделяется на страницы. Иными словами, внутреннее пространство файлов данных разделено на страницы и именно в этих страницах хранятся наши данные.
Все дисковые операции ввода-вывода в SQL Server выполняются на уровне страницы и это означает, что SQL Server считывает или записывает целые страницы данных.
Например, в процессе оптимизации запросов мы очень часто говорим о количестве логических чтений, которые выполняются на уровне запроса, так вот – это количество как раз и представляет собой количество считанных страниц данных.
Если провести аналогию, то файл базы данных в SQL Server (MDF или NDF) представляет собой бумажную книгу, содержимое которой написано на страницах. Иными словами, в SQL Server все строки данных точно так же, как и в бумажной книге, записываются на страницы, которые имеют одинаковый физический размер 8 килобайт.
Основную часть файла данных занимают страницы с данными, как и у книги страницы с содержимым, а на некоторых страницах могут находиться метаданные об этом содержимом, например, как оглавление или алфавитный указатель в бумажной книге.
Как уже было отмечено размер страницы в SQL Server составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц.
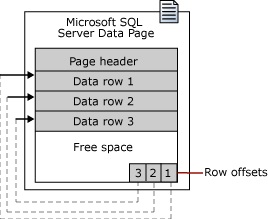
Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Строки данных заносятся на страницу последовательно, сразу же после заголовка. В конце страницы располагается таблица смещения строк.
Таблица смещения строк содержит одну запись для каждой строки на странице. Каждая запись смещения строк регистрирует, насколько далеко от начала страницы находится первый байт строки. Таким образом, таблицы смещения строк помогает SQL Server быстро находить строки на странице. Записи в таблице смещения строк находятся в обратном порядке относительно последовательности строк на странице.
В следующей таблице представлены типы страниц, которые используются в файлах данных базы данных SQL Server.
| Тип страницы | Описание |
| Data page | Строки с данными, за исключением типов text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и xml. |
| Index page | Содержимое индекса. |
| Text/Image | Текст/изображение. Типы данных больших объектов: text, ntext, image, nvarchar(max), varchar(max), varbinary(max) и данные xml. Столбцы переменной длины, когда размер строки данных превышает 8 КБ: varchar, nvarchar, varbinary и sql_variant. |
| Global Allocation Map (GAM) | Глобальная карта распределения. На GAM-страницах записано, какие экстенты были размещены. В каждой карте GAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен, если бит равен 0, то экстент размещен. |
| Shared Global Allocation Map (SGAM) | Общая глобальная карта распределения. На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится 64 000 экстентов или почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются. |
| Page Free Space (PFS) | Сведения о размещении страниц и доступном на них свободном месте. |
| Index Allocation Map (IAM) | Карта распределения индекса. Сведения об экстентах, используемых таблицей или индексом для единицы распределения. |
| Bulk Changed Map (BCM) | Карта массовых изменений данных. Сведения об экстентах, измененных массовыми операциями со времени последнего выполнения инструкции BACKUP LOG для единицы распределения. |
| Differential Changed Map (DCM) | Карта изменений для разностной резервной копии. Сведения об экстентах, измененных с момента последнего выполнения инструкции BACKUP DATABASE для единицы распределения. |
Папка — это тоже файл
Мало кто знает, но папка — это тоже на самом деле файл, просто специальный, со своими задачами. Внутри этого файла записана информация о том, какие файлы относятся к этой папке. А раз папка — это тоже файл, то когда мы вкладываем папку друг в друга, компьютер всего лишь добавляет запись про один файл в другой.
Формы
Формы можно использовать для просмотра, ввода и изменения данных в одной строке за раз. Кроме того, с их помощью можно выполнять такие действия, как отправка данных другим приложениям. Формы обычно содержат элементы управления, связанные с полями базовых таблиц. При открытии формы Access извлекает данные из одной или нескольких таких таблиц и отображает их в выбранном при создании формы формате. Форму можно создать с помощью команд Форма на ленте, в мастере создания формы, а также самостоятельно в режиме конструктора.
Примечание: Для создания форм и отчетов в веб-базах данных и веб-приложениях используется режим макета, а не конструктора.
1. В таблице одновременно отображается множество записей, однако для просмотра всех данных в одной записи иногда необходимо прокрутить ее горизонтально. Кроме того, при просмотре таблицы невозможно обновить данные из нескольких таблиц одновременно.
2. В форме внимание сосредоточено на одной записи и могут отображаться поля из нескольких таблиц. Кроме того, форма позволяет отображать рисунки и другие объекты.
3. Форма может содержать кнопку, используемую для печати отчета, открытия других объектов или автоматического выполнения других задач.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Типы файлов в SQL Server
- Файлы данных – это файлы, в которых хранятся сами данные. Такие файлы бывают двух типов:
- Первичный файл данных – имеет расширение .mdf (Master Data File). Данный файл присутствует в любой базе данных. Кроме данных, он еще содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных;
- Вторичный файл данных – имеет расширение .ndf (Not Master Data File). Данные типы файлов база данных может и не содержать, они создаются дополнительно к первичному файлу. С помощью именно таких файлов мы можем распределять данные на несколько дисков.
![Скриншот 1]()
По умолчанию файлы базы данных располагаются в каталоге, который Вы указали в момент установки SQL Server на этапе настройки ядра в поле «Каталог пользовательской базы данных» для файлов данных, и в поле «Каталог журналов пользовательской базы данных» для журнала транзакций.
Однако при создании базы данных, или добавлении файла к базе данных, Вы можете указать свой путь к каталогу, в котором хранить создаваемый файл.
Файлы базы данных SQL Server
Что такое файл
С точки зрения компьютера файл — это последовательность байтов на жёстком диске. Если представить жёсткий диск на 100 гигабайт как последовательность из 100 миллиардов байт, то файл будет занимать сколько-то из этих байтов на диске. Вот картинка для понимания:
![Как устроены файлы]()
Эта последовательность байтов необязательно идёт друг за другом — файл может состоять из нескольких фрагментов, которые находятся в разных частях диска:
![Как устроены файлы]()
Все остальные файлы хранятся точно так же — одним или несколькими фрагментами на диске. Чтобы компьютер знал, какой файл состоит из каких фрагментов, он часть памяти отводит на таблицу файлов. В ней он хранит данные обо всех файлах на диске:
![Как устроены файлы]()
А как хранятся файлы на телефоне и планшете?
Точно так же, как и на компьютере, только там может быть своя файловая система (способ внутренней организации). Про файловые системы и про то, какие они бывают, поговорим в следующей статье.
Файловые группы
В Microsoft SQL Server есть возможность объединять файлы данных в файловые группы.
Файловая группа в SQL Server – это логический контейнер, который объединяет несколько файлов данных.
Файловые группы нужны нам в основном для более гибкого управления хранением данных в SQL Server. Дело в том, что с помощью файловых групп мы можем одни таблицы хранить в одних файлах, а другие в других, иными словами, благодаря файловым группам мы можем распределять таблицы по разных файлам и по разным дискам.
Например, мы знаем, что одна таблица у нас будет очень большой и на ее хранение потребуется несколько дисков, поэтому ее (т.е. только одну эту таблицу), мы можем поместить в отдельную файловую группу, в которую добавить несколько файлов, каждый из которых будет храниться на отдельном диске. Все остальные таблицы мы будем хранить в другой файловой группе, т.е. уже в других файлах и, соответственно, на других дисках.
Без файловых групп мы этого сделать не можем, т.е. мы можем, конечно же, создать дополнительные файлы данных, но распределять данные по этим файлам будет сам SQL Server, т.е. на это мы уже не можем повлиять.
Таким образом, при создании таблиц мы можем указать, в какой файловой группе создавать эту таблицу. Если в базе данных создавать объекты без указания файловой группы (в большинстве случаев так и делается), к которой они относятся, они создаются в файловой группе по умолчанию.
По умолчанию в SQL сервере создана файловая группа PRIMARY, и если Вы не создавали дополнительных файловых групп, то все объекты базы данных будут храниться именно в этой файловой группе.
Файловую группу по умолчанию можно переопределить инструкцией ALTER DATABASE, т.е. можно создать файловую группу и назначить ее файловой группой по умолчанию, при этом стоит отметить, что все системные объекты хранятся в файловой группе PRIMARY, а не в новой файловой группе по умолчанию. Иными словами, файловая группа PRIMARY – это особенная файловая группа, в которой хранятся системные объекты и которую нельзя удалить.
Также стоит отметить, что один файл данных может входить в состав только одной файловой группы.
Примечание! Файлы журнала транзакций не могут входить в файловые группы.
Читайте также:



