
Chipkill ecc что это
Для обеспечения приемлемой производительности современным серверам требуются огромные объемы памяти. Однако использование быстродействующих и дорогих кристаллов не всегда эффективно с точки зрения баланса стоимости и быстродействия, поэтому обычно применяется недорогая память большого объема. Себестоимость памяти снижают, как правило, путем максимального повышения разрядности микросхем. Плотная упаковка (т. е. повышение разрядности) микросхем памяти позволила резко снизить соотношение “цена/емкость”. Такие микросхемы передают и получают четыре или восемь разрядов данных в каждой операции доступа.
Ошибки памяти можно подразделить на аппаратные и случайные. Аппаратные ошибки обусловлены главным образом дефектами кремниевого кристалла или монтажных соединений микросхем DRAM и со временем не исчезают. Случайные же (или “мягкие”) обычно вызываются заряженными частицами или излучением; они непостоянны и со временем пропадают. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM - электрические возмущения, вызванные космическими лучами - потоками высокоэнергетичных элементарных частиц, приходящими из космоса.
В начале 90-х годов на большинстве серверов, оборудованных микропроцессорами Intel, применялся метод проверки четности памяти, позволявший лишь обнаруживать ошибки, но не исправлять их. Широкое применение он нашел еще в первых моделях компьютеров для оценки достоверности хранимой в оперативной памяти информации.
Данный метод контроля имел определенный смысл, когда микросхемы памяти были еще недостаточно надежными. К тому же необходимость иметь на каждые восемь информационных разрядов один бит четности увеличивала стоимость модуля более чем на 10%.
Высокая частота ошибок четности памяти вынудила отрасль перейти на новый стандарт и обеспечить поддержку ECC (Error Checking and Correcting - “обнаружение и исправление ошибок”). Обычно эту особенность называют SEC/DED (Single Error Correction/Double Error Detection - “коррекция единичных и обнаружение двойных ошибок”). Механизм SEC/DED не позволяет обнаруживать ошибки более чем в двух разрядах. В этом случае целостность информации нарушается. В архитектуре этого типа ошибки в нескольких разрядах неустранимы и приводят к отказу системы, а сбои единичных разрядов исправляются автоматически, незаметно (“прозрачно”) для операционной системы и прикладных программ.
Идея, лежащая в основе метода ECC, довольно проста - каждый разряд памяти входит более чем в одну контрольную сумму. Это требует увеличения числа контрольных разрядов, но дает возможность восстанавливать значение сбойного бита по несовпадающим контрольным суммам. Итак, ECC предполагает использование одного разряда четности на байт информации для нахождения одиночных ошибок, а для их исправления требуется 7 бит для 32- и 8 бит для 64-разрядной памяти. При этом легко обнаруживаются двойные ошибки. Следовательно, для ECC подходят обычные модули с контролем четности, если это допускает контроллер памяти. Основным недостатком при этом является снижение общей производительности системы, на которую возлагаются дополнительные вычисления. Другой способ реализации ECC - размещение логики контроля не в контроллере памяти на системной плате, а на самом модуле. Это позволяет избежать снижения производительности, но стоимость таких модулей выше обычных. Поскольку ошибки в большем числе разрядов случались чрезвычайно редко, метод ECC дал возможность существенно повысить надежность систем. Сегодня технология ECC является стандартом и применяется практически на всех серверах.
По мере уплотнения DRAM-устройств число многоразрядных ошибок увеличивается. Кроме того, современные серверы оснащаются все более объемной памятью (за счет увеличения количества модулей или установки модулей с большим объемом памяти), в связи с чем вероятность неустранимых ошибок DRAM-памяти - и случайных, и постоянных - возрастает. Таким образом, память стандарта SEC/DED, которая только недавно обеспечивала вполне удовлетворительные характеристики, теперь не отвечает требованиям высокой надежности, доступности и удобства в эксплуатации (RAS, Reliability, Availability and Serviceability), предъявляемым современными серверами. Это, в частности, касается серверов масштаба предприятия, стандартные объемы памяти которых сегодня превышают несколько гигабайт. Кроме того, следует отметить, что требования к объемам памяти существенно возросли после выпуска 64-разрядных компьютерных систем семейства Itanium.
Одной из составных частей инициативы X-Architecture корпорации IBM стала технология исправления ошибок Chipkill, обеспечивающая защиту серверов от отказов отдельных микросхем и многоразрядных ошибок в модулях памяти. Chipkill - это механизм, позволяющий памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM, в том числе сбою всех разрядов данных. В механизме Chipkill существуют два основных метода исправления ошибок, причем они могут применяться совместно. Эти методы базируются на определенном наборе микросхем и особой аппаратной архитектуре системы - их поддержку невозможно обеспечить простым обновлением программного обеспечения.
В первом методе каждый бит данных модуля памяти размещается в отдельном “слове ECC”. (Слово ECC - это набор разрядов данных и контрольных разрядов, в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.) Допустим, что разрядность системы памяти составляет 32 байта (или 256 разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные, и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых состоит из 64 разрядов данных и восьми контрольных разрядов ECC, поддерживают механизм SEC/DED и распределяются по DRAM-модулям. Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства распределяются по разным словам ECC. Сбой всех четырех битов - это всего лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически. В этом примере механизм Chipkill поддерживается только на DIMM-модулях, состоящих из микросхем х4 DRAM.
Второй метод заключается в предоставлении механизму ECC большего числа разрядов для хранения контрольных кодов, чтобы обеспечить исправление не одного, а нескольких разрядов. При этом используются соответствующие математические алгоритмы устранения многоразрядных ошибок при определенном количестве контрольных битов ECC и битов данных. Например, 144-разрядное слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет исправлять ошибки, охватывающие до четырех разрядов данных. (Для исправления сбоя четырех бит необходимо, чтобы они располагались смежно, а не случайно.) Соотношение разрядов ECC и разрядов данных такое же, как и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC дает возможность применить более эффективный алгоритм обнаружения и исправления ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах ECC исправлялись по четыре разряда. При этом обеспечивается поддержка механизма Chipkill при использовании DIMM-модулей, состоящих как из микросхем х4 DRAM, так из х8 DRAM.
На серверах Netfinity (на смену которым пришли машины eServer xSeries) инженеры IBM решили эту проблему, разместив избыточный массив недорогих микросхем DRAM (Redundant Array of Inexpensive DRAM, RAID) непосредственно на DIMM-модулях. При каждом доступе к памяти RAID-микросхема вычисляет контрольный код ECC для всего набора микросхем и сохраняет результат в резервной памяти на защищаемом DIMM-модуле. В случае отказа одной микросхемы DIMM-модуля сохраненная на RAID-массиве информация применяется для восстановления потерянных данных, обеспечивая бесперебойную работу всего сервера Netfinity. Такая RAID-технология напоминает RAID-механизмы, применяемые для защиты данных на дисковых массивах, и называется Chipkill DRAM.
Специалисты IBM разработали заказную специализированную микросхему для Chipkill, которая называется ECC ASIC (Application-Specific Integrated Circuit) и выполняет исправление ошибок без замедления доступа к высокопроизводительной EDO-памяти с временем доступа 50 нс. Таким образом, установка DIMM-модулей Chipkill на серверы Netfinity, оборудованные процессором Intel Xeon, не требует модификации плат памяти, а новые модули не вызывают никакого снижения производительности.
Обнаружение и оповещение
Поскольку основная задача Chipkill - исправление ошибок памяти, в нем применяются такие же механизмы обнаружения и оповещения, как и в ECC. Выполнение двух этих операций - обнаружения и оповещения - никак не сказывается на производительности оборудования или программного обеспечения - издержки те же, что и для стандартных механизмов ECC.
Теперь вкратце остановимся на том, как может выполняться обнаружение и оповещение о постоянных и случайных ошибках в серверных архитектурах с применением обоих механизмов - ECC и Chipkill.
Обнаружение и исправление ошибок памяти осуществляются в системном наборе микросхем. Код исправления ошибок (ECC) генерируется при записи и проверяется при чтении во всех системных операциях с памятью “прозрачно” для прикладных программ. Обнаруженная ошибка автоматически исправляется до передачи данных получателю.
Программное обеспечение управления системой, поставляемое в составе многих серверов, анализирует системный журнал при каждом внесении записи системой BIOS. Ошибки единичных разрядов инициируют уведомление одного из трех возможных уровней: warning (“предупреждение”), critical (“критическая”), nonrecoverable (“неустранимая”). По-настоящему случайная ошибка вряд ли инициирует уведомление в стеке программы управления системой. Однако постоянные неполадки в работе DIMM-модуля приводят к инициации уведомления программы управления системой, после чего она назначает службе технической поддержки задание на замену неисправного DIMM-модуля. Постоянная ошибка, вызвавшая отключение механизма регистрации исправлений, в любом случае инициирует уведомление. Постоянные ошибки в одном разряде или устраняемые средствами Chipkill не вызывают отказа системы, тем не менее они увеличивают вероятность того, что очередная случайная ошибка приведет к критическому, неустранимому сбою. Поэтому администраторы системы должны внимательно следить за уведомлениями о дефектных DIMM-модулях и своевременно назначать службе технической поддержки задания на их замену.

Модули оперативной памяти. Технология исправления ошибок Chipkill.
На работу модулей оперативной памяти оказывают влияние множество негативных факторов, которые могут вызвать появление ошибок в считанной информации. Ошибки памяти можно подразделить на аппаратные и случайные. Аппаратные ошибки обычно обусловлены неустранимыми дефектами кремниевого кристалла или монтажных соединений микросхем DRAM. Случайные ошибки (сбои) обычно вызываются заряженными частицами или излучением. Такие ошибки непостоянны и действуют кратковременно. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM - электрические возмущения, вызванные космическими лучами - потоками высокоэнергетических элементарных частиц, приходящими из космоса. Для повышения надежности функционирования компьютерной техники, применяется метод контроля четности памяти, но этот метод позволяет лишь обнаруживать ошибки, а не исправлять их.
Но для наиболее ответственных приложений, где цена ошибки очень высока, используют модули памяти с коррекцией ошибок ECC (Error Checking and Correcting - обнаружение и исправление ошибок).
Идея, лежащая в основе метода ECC, довольно проста - каждый разряд памяти входит более чем в одну контрольную сумму. Это увеличивает число контрольных разрядов, но дает возможность восстанавливать значение сбойного бита по несовпадающим контрольным суммам. Основной недостаток при использования ECC - снижение общей производительности системы, на которую возлагаются дополнительные вычисления.
Другой способ реализации ECC - размещение логики контроля не в контроллере памяти на системной плате, а на самом модуле. Это позволяет избежать снижения производительности, но стоимость таких модулей выше, чем обычных. Поскольку ошибки в большем числе разрядов случались чрезвычайно редко, метод ECC позволил существенно повысить надежность систем. Сегодня технология ECC стала стандартом и применяется практически во всех серверах.
Еще одним механизмом исправления ошибок, который был предложен как одна из составных частей инициативы X-Architecture корпорации IBM, стала технология исправления ошибок Chipkill. Эта технология обеспечивает защиту серверов от отказов отдельных микросхем и многоразрядных ошибок в модулях памяти. Технология Chipkill, перенесенная IBM с больших систем, существенно сокращает среднее время простоя серверов и обеспечивает более надежную платформу для клиент-серверных вычислений на базе микропроцессоров Intel. Она призвана повысить надежность систем, доступность и удобство в эксплуатации, что является ключевыми характеристиками серверов масштаба предприятия, обслуживающих критически важные приложения.
Архитектура Chipkill позволяет системе безболезненно воспринимать ошибки, которые в обычных условиях приводят к неустранимым сбоям, тем самым обеспечивая сохранность данных и высокую доступность системы. В системах высокой доступности, таких как серверы масштаба предприятия IBM S/390, проблема многоразрядных ошибок памяти DRAM отсутствует благодаря особой архитектуре оперативной памяти. Подсистема памяти сконструирована так, что отказ отдельной микросхемы, независимо от ее разрядности, не затронет более одного разряда в каком-либо из нескольких слов ECC. Например, в 4-разрядной микросхеме DRAM отдельные биты из всей четверки попадают в разные слова ECC, т. е. в разные адресные пространства памяти. Поэтому даже в случае полного отказа микросхемы количество ошибочных разрядов в словах ECC не превысит единицу, а такую ошибку механизм ECC устраняет автоматически. Данная архитектура обеспечивает отказоустойчивость всей подсистемы памяти.
Тщательно продуманная конструкция мэйнфреймов защищает их и от сбоев микросхем памяти. В каждом модуле памяти разрядность микросхем равна числу разрядов, защищенных механизмом ECC. Нынешние серверы на базе микропроцессоров Intel такого механизма не поддерживают так как рынок требует дешевой памяти, вынуждая проектировщиков создавать очень плотные микросхемы памяти, поддерживающие отраслевой стандарт (исключительно ECC).
Предлагаемая технология Chipkill является механизмом, позволяющим памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM, в том числе и сбою всех разрядов данных. В механизме Chipkill есть два основных метода исправления ошибок, причем они могут применяться совместно. Эти методы базируются на определенном наборе микросхем и особой аппаратной архитектуре системы, поэтому их поддержку невозможно обеспечить простым обновлением ПО.
В первом методе каждый бит данных модуля памяти размещается в отдельном "слове ECC", которое представляет собой набор разрядов данных и контрольных разрядов, в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.) Предположим, что разрядность системы памяти составляет 32 байт (или 256 разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные, и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых состоит из 64 разрядов данных и 8 контрольных разрядов ECC, поддерживают механизм SEC/DED. Эти четыре слова ECC распределяются по DRAM-модулям. Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства распределяются по разным словам ECC (рис. 1). Сбой всех четырех битов - это всего лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически. В этом примере механизм Chipkill поддерживается только на DIMM-модулях, состоящих из микросхем х4 DRAM.

Рис. 1. Пример технологии Chipkill.
Второй метод заключается в предоставлении механизму ECC большего числа разрядов для хранения контрольных кодов, чтобы обеспечить исправление не одного, а нескольких разрядов. При этом используются соответствующие математические алгоритмы устранения многоразрядных ошибок при определенном количестве контрольных битов ECC и битов данных. Например, 144-разрядное слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет исправлять ошибки, охватывающие до 4 разрядов данных. Для исправления сбоя четырех бит необходимо, чтобы они были смежными, а не располагались случайно. Соотношение разрядов ECC и разрядов данных такое же, как и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC позволяет применить более эффективный алгоритм обнаружения и исправления ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах ECC исправлялись по 4 разряда. Этот метод обеспечивает поддержку механизма Chipkill при использовании DIMM-модулей, состоящих как из микросхем х4 DRAM, так и из х8 DRAM. Инженеры IBM решили эту проблему, разместив избыточный массив недорогих микросхем DRAM (Redundant Array of Inexpensive DRAM, RAID) непосредственно на DIMM-модулях. При каждом доступе к памяти RAID-микросхема вычисляет контрольный код ECC для всего набора микросхем и сохраняет результат в резервной памяти на защищаемом DIMM-модуле. В случае отказа одной микросхемы DIMM-модуля сохраненная на RAID-массиве информация применяется для восстановления потерянных данных, обеспечивая бесперебойную работу всего сервера Netfinity. Такая RAID-технология напоминает RAID-механизмы, применяемые для защиты данных в дисковых массивах, и называется Chipkill DRAM.
Специалисты компании IBM разработали заказную специализированную микросхему для Chipkill, которая называется ECC ASIC (Application-Specific Integrated Circuit) и выполняет исправление ошибок без замедления доступа к высокопроизводительной EDO-памяти со временем доступа 50 нс. Таким образом, при установке DIMM-модулей IBM Chipkill на серверы Netfinity, оборудованные процессором Intel Xeon, модификация плат памяти не нужна, а новые модули не вызывают снижения производительности.
Технология IBM Chipkill Memory позволила снизить число отказов серверов Netfinity по причине сбоев подсистемы памяти до невероятно низкого уровня. Основной задачей механизма Chipkill является исправление ошибок памяти, в нем применяются такие же способы обнаружения и оповещения, что и в ECC. Обнаружение и оповещение Chipkill никак не сказывается на производительности оборудования или ПО (потери те же, что и для стандартных механизмов ECC). Обнаружение постоянных и случайных ошибок, исправление ошибок памяти и оповещение о них в серверных архитектурах с применением обоих механизмов - ECC и Chipkill выполняется в системном наборе микросхем. Для обнаружения, код исправления ошибок (ECC) генерируется при записи и проверяется при чтении во всех системных операциях с памятью "прозрачно" для прикладных программ. Обнаруженная ошибка автоматически исправляется до передачи данных получателю. При этом событие ошибки регистрируется оборудованием, а системная BIOS уведомляется об исправлении ошибки и о месте, где она произошла. Набор микросхем также ведет учет исправленных ошибок, что позволяет BIOS выявлять DIMM-модули, в которых ошибки возникают и исправляются постоянно. Получив уведомление, система BIOS опрашивает регистры набора микросхем, чтобы определить, где произошла ошибка памяти (порядок такого опроса сильно зависит от конструкции конкретной системы, поэтому он и выполняется на уровне BIOS). Обнаружив модуль DIMM, вызвавший ошибку, BIOS регистрирует эту информацию в системном журнале, который является, например, частью встроенной системы управления сервером (Embedded Server Management).
Программное обеспечение управления системой, поставляемое в составе многих серверов, анализирует системный журнал при каждом внесении записи системой BIOS. Ошибки единичных разрядов инициируют уведомления одного из трех возможных уровней: warning ("предупреждение"), critical ("критическая"), nonrecoverable ("неустранимая"). По-настоящему случайная ошибка вряд ли инициирует уведомление в стеке программы управления системой. Однако в случае постоянных неполадок в работе DIMM-модуля инициируется уведомление программе управления системой, после чего та назначает службе технической поддержки задание на замену неисправного DIMM-модуля. А постоянная ошибка, вызвавшая отключение механизма регистрации исправлений, в любом случае инициирует уведомление. Конечно постоянные ошибки в одном разряде или ошибки, устраняемые средствами Chipkill, не вызывают отказа системы, но тем не менее они увеличивают вероятность того, что очередная случайная ошибка приведет к критическому, неустранимому сбою, поэтому администраторы системы внимательно следят за уведомлениями о дефектных DIMM-модулях и своевременно выдают ремонтной службе задания на их замену.
Технология Chipkill поддерживается и в новом универсальном наборе микросхем IBM Summit, который хорошо подходит как для 64-разрядных микропроцессоров семейства Itanium, так и для 32-64 разрядных процессоров Xeon. Чипсет сможет поддерживать до четырех процессоров, позволяя им разделять такие ресурсы, как шины ввода-вывода и шины памяти. Четыре набора могут связываться воедино, что даст серверам на базе Summit возможность поддерживать до 16 полностью автономных микропроцессоров (например, в четырехпроцессорном сервере можно будет выделить три кристалла под Windows, а один - под Linux, а если все процессоры работают в одной среде, можно будет проводить их "горячую" замену).
По мнению ряда экспертов, присущая мэйнфреймам надежность и отказоустойчивость скоро потребуется и в небольших серверах, оборудованных микропроцессорами Intel.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
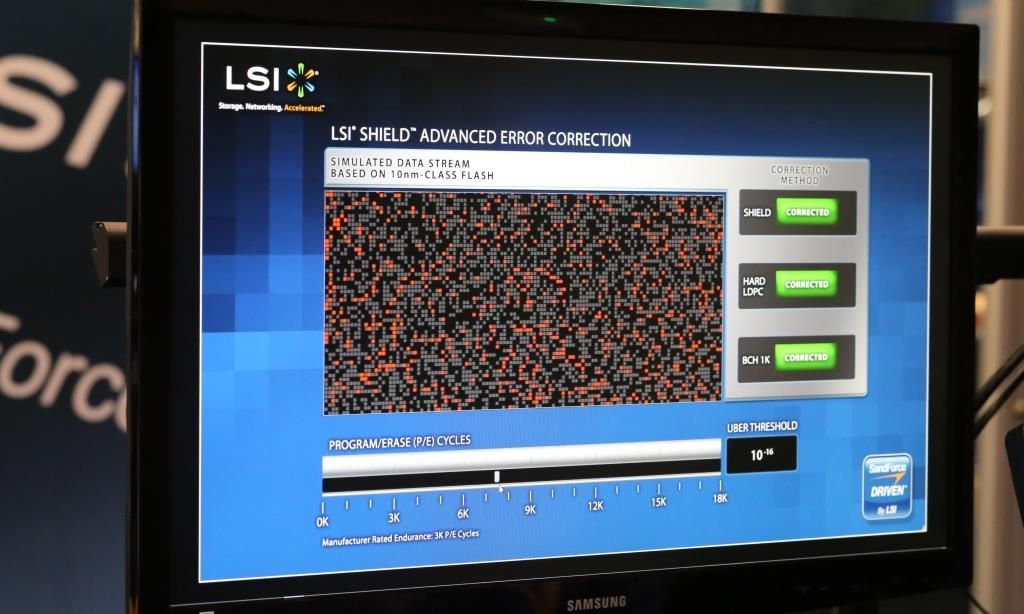
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.

В 2009 году, на ежегодной научной конференции SIGMETRICS, группа исследователей, работавших в Университете Торонто с данными, собранными и предоставленными для изучения компанией Google, опубликовала крайне интересный документ "DRAM Errors in the Wild: A Large-Scale Field Study" посвященный статистике отказов в серверной оперативной памяти (DRAM). Хотя подобные исследования и проводились ранее (например исследование 2007 года, наблюдавшее парк в 300 компьютеров), это было первое исследование, охватившее такой значительный парк серверов, исчисляемый тысячами единиц, на протяжении свыше двух лет, и давшее столь всеобъемлющие статистические сведения.

(на фото, кстати, подлинный вид серверной платформы Google, именно из таких «кирпичиков» собираются гугловские кластеры, размером в многие тысячи узлов, впрочем, про них тут уже писалось)
Результаты такого анализа и представлены в опубликованной работе. И результаты во многом удивительные, заставляющие по-иному смотреть на вопросы надежности и привычные допущения в области надежности серверного оборудования.
Исследование со всей убедительностью продемонстрировало, что влияние отказов в оперативной памяти существенно недооценивается, что отказы оперативной памяти случаются куда чаще, чем до этого это было принято считать, наконец, многие допущения, например что оперативная память практически не «стареет», как «стареют», повышая вероятность отказов, компоненты с движущимися частями, такие как, например, жесткие диски, или что перегрев губительно сказывается на работе ОЗУ, являются неверными, и требуют пересмотра.
Несомненно тот факт, что в последние несколько лет, в связи со сравнительным удешевлением DRAM, и широким распространением систем серверной виртуализации, крайне охочих до объемов памяти, концентрация в одной серверной системе все больших и больших объемов ОЗУ, повышает и требования к ее надежности.
В сравнении с ранее опубликованным исследованием, работа группы Шрёдер резко повысила «ожидания» сбоев. Так, они оценили события отказов в 25-70 тысяч сбоев на миллиард часов работы сервера, что почти в пятнадцать раз превышает более раннюю оценку, сделанную на меньшей популяции.
С отказами в результате неисправимых (uncorrectable, неисправленных ECC или Chipkill) встретились 1,3% серверов в год, или около 0,22% DIMM.
Системы, использующие «многобитные» механизмы, такие как Chipkill, имели число отказов в 4-10 раз меньше, по сравнению с обычным ECC.
Другие интересные выводы, сделанные в опубликованной работе это:
Рабочая температура, и ее повышение крайне мало коррелирует с вероятностью сбоя в DRAM. Это еще один факт, который указывает, что бытующее до сих пор в индустрии мнение о губительности повышенной температуры на полупроводники и компьютерное оборудование (мнение, основанное на исследовании 80-х годов) на сегодняшний день следует радикально пересмотреть. Это еще одно подтверждение этому факту, который уже был установлен, например в работе о жестких дисках. Парадоксальным образом там было установлено, что наименьшее количество отказов HDD наблюдалось при температурах в районе 40-45 градусов, а ее понижение количество отказов увеличивало (!).
В случае DRAM кореляция между температурой (в наблюдавшемся диапазоне около 20 градусов между самой низкой и самой высокой) и отказами была крайне незначительной.

Однако существенно коррелировали отказы с загрузкой памяти и интенсивностью обмена с ней (отчасти высокая загрузка памяти влияет и на ее температуру, конечно, но не всегда). Вполне вероятно, что интенсивный обмен и большой относительный объем заполненных данными памяти значительно повышает вероятность быстрого обнаружения сбоя.

Было установлено, что вероятность получить повторный сбой в уже ранее сбоившем модуле памяти в сотни раз выше, по сравнению с не сбоившем ранее. Это может быть вызвано как наличием плохо выявляемого технологического брака, так и тем, что отказ, например пробой заряженной частицей космических лучей, не проходит для памяти бесследно, даже если ошибка была скорректирована ECC.
70-80% случаях, когда регистрировалась неисправимая ошибка в модуле памяти, это модуль уже имел исправимый ECC или Chipkill отказ в этом или предыдущем месяце.

Было установлено, что сравнительно новые модули, выполненные с более высокой плотностью и более тонкими техпроцессами, не показывают более высокого уровня отказов. По-видимому пока в технологии DRAM технологический предел, близ которого начинаются проблемы с надежностью, пока не достигнут. В наблюдаемом парке модулей было примерно шесть разных типов и поколений памяти (DDR1, DDR2 и FBDIMM разных типов), и корреляции между высокой плотностью и числом отказов и сбоев выявлено не было.
Наконец, с пугающей ясностью был продемонстрирован эффект «старения» в модулях DRAM. Более того, в памяти он проявился куда более явно, чем, напрмер, в HDD, где порог, после которого отказы растут в разы, составил примерно 3-4 года.

Парадоксальным образом статистика демонстрирует увеличивающиеся темпы роста correctable errors с увеличением возраста модулей, но снижающийся темп для Uncorrectable errors, однако скорее всего это просто результат плановой замены памяти в серверах, которые были замечены за сбоями.

Удивительным образом, DRAM, лишенная каких-либо движущихся частей, показывает существенный и продолжающийся рост correctable отказов уже после года-полутора эксплуатации.
Подводя итоги, хотелось бы отметить, что приведенные статистические данные заставляют пересмотреть привычные для многих, основанные на «житейском опыте» принципы построения серверных платформ и эксплуатации датацентров, и позиция «чем холоднее — тем лучше», «память не изнашивается», «если север правильно собран, то он не ломается» и «ECC DRAM — ненужная трата денег, ведь у меня десктоп работает без ECC, и ничего». И чем скорее будут изжиты подобные шапкозакидательские настроения в столь серьезной области, как построение датацентров, тем, в итоге, будет лучше.
А занимающимся темой хочу порекомендовать неизбывный источник сладости, интеллектуального упражнения и пищи для мозгов, как публикации ежегодных конференций группы USENIX, это вам, господа, не маркетинговый булшит, столь привычный нам уже всем, а настоящая серьезная наука, от которой не отмахнешься.
Что такое Registered (регистровые) DIMM?
Выше мы отметили, что в настольных платформах используются UDIMM (Unbuffered, небуферизованные), а в серверных часто встречаются RDIMM (Registered, регистровые). В случае UDIMM адресация памяти выполняется напрямую контроллером памяти, как и передача данных. В случае же RDIMM адресацию на себя берет отдельный чип-регистр, передача данных по-прежнему осуществляется напрямую контроллером памяти.
Цель RDIMM заключается в уменьшении нагрузки на контроллер, в результате на серверную материнскую плату можно устанавливать больше DIMM, существенно увеличивая емкость памяти сервера по сравнению с настольной системой. В случае полностью буферизованных модулей Fully Buffered DIMM (FB-DIMM) промежуточный буфер используется не только для адресации, но и для передачи данных. Стандарт LRDIMM (Load Reduced) является дальнейшей разработкой регистровой памяти, он обеспечивает еще большую емкость.

Кроме обычных планарных чипов памяти разработана технология "бутерброда" из нескольких чипов под названием 3DS DIMM. Она позволяет значительно увеличить емкость модулей. Наконец, есть модули NVDIMM (Non-volatile), данные в которых не стираются в случае сбоя питания. Модули NVDIMM разделяются на NVDIMM-F (Flash Storage), NVDIMM-N (DRAM), NVDIMM-P (Persistent Memory) и NVDIMM-X (NAND Flash Storage).
Что такое ECC?
ECC означает "Error Correction Code" или код коррекции ошибок. При чтении данных из памяти или записи в память код ECC позволяет исправлять одиночные битовые ошибки. Что повышает надежность работы памяти в окружениях, где это необходимо. Например, в серверах и рабочих станциях. Для кода ECC добавляются 8 дополнительных бит (64 базовых + 8 дополнительных = 72).
Алгоритм ECC позволяет исправлять битовые ошибки, а также определять два ошибочных бита, но уже не исправлять их. Технологии Chipkill или Advanced ECC расширяют алгоритм ECC, позволяя корректировать до 4 ошибочных битов и определять до 8 ошибочных битов. Если ошибок будет много, то данная функция позволяет скрыть сбойный чип в системе без перезагрузки (отсюда и название "Chipkill"), при этом сервер продолжает стабильную работу. Технологии Chipkill или Advanced ECC работают как массив RAID на жестких дисках, опираясь на распределенное избыточное хранение данных.


Технология Memory Scrubbing производит постоянную проверку памяти на наличие ошибок, результаты отправляются серверным утилитам управления, например, IPMI (Intelligent Platform Management Interface) в BMC (Baseboard Management Controller).
Но для работы ECC вместе с функцией ChipKill/Advanced ECC необходимо чтобы процессор, материнская плата с BIOS и оперативная память поддерживали ECC. Данная технология обязательна для всех RDIMM, но также встречаются и UDIMM с ECC.
Примеры серверной памяти
Ниже представлены два изображения Registered DIMM с ECC:


Приведены два серверных RDIMM, по крайней мере, с одной стороны установлены 18 чипов памяти, по центру чипы ECC и регистра. Типичные RDIMM выпускаются в емкостях 8, 16 и 32 Гбайт, с тактовой частотой 2400 МГц, 2666 МГц, 2933 МГц и 3200 МГц.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).
Читайте также: