
Чему удовлетворяет качество компьютерного перевода авторство вопроса коломиец андрей валерьевич
В связи с тем, что «Слово о полку Игореве» включено в школьную программу, – это, пожалуй, единственное древнерусское произведение, более-менее знакомое широкой публике. Оно прочно вошло в массовую культуру благодаря Бояну, плачу Ярославны и растеканию мысли по древу.
Однако далеко не все знают, насколько жаркие дискуссии по поводу подлинности этого произведения кипят в научных кругах вот уже двести лет. Подробную хронологию этой истории можно прочитать в обзорном материале Д. В. Сичинавы, а я лишь коротко обозначу основные точки этой истории и расскажу, почему у нас есть основания считать текст «Слова» аутентичным.
Алексей Иванович Мусин-Пушкин (1744-1817) был страстным любителем древних рукописей, и к 1791 году ему удалось собрать интересную коллекцию древнерусских манускриптов. О коллекции узнала Екатерина II, поддержавшая начинания коллекционера. 26 июля 1791 года его назначают обер-прокурором Святейшего Синода, а уже 11 августа выходит повеление, предписывавшее епархиям присылать летописи и другие старинные рукописи в Синод. Одним из манускриптов, которые Мусин-Пушкин раздобыл в Кирилло-Белозерском монастыре, был рукописный сборник, включавший в себя «Слово». Сам Мусин-Пушкин позднее утверждал, что он купил сборник у бывшего архимандрита Спасо-Ярославского монастыря Иоиля Быковского. Однако, по всей вероятности, он просто «позаимствовал» его.
Большой заслугой Мусина-Пушкина было то, что он быстро распознал истинную ценность «Слова». Вскоре специально для Екатерины была снята копия, которую снабдили переводом и комментариями. А уже в 1800-м году вышло печатное издание памятника.

Уже в 1812-м году возник спор между М. Т. Каченовским и П. Ф. Калайдовичем. Первый усомнился в подлинности «Слова», а второй отстаивал подлинность. В сентябре того же года оригинал рукописи сгорает в наполеоновском пожаре.
Большинство древнерусских памятников дошло до нас в нескольких списках (то есть, копиях), для некоторых произведений речь может идти даже о нескольких десятках списков. «Слову», к сожалению, не повезло. Оно сохранилось только в одном списке, который и погиб в пожаре. Конечно, это подкинуло дровишек в огонь дискуссии: исчезла возможность проверить аутентичность рукописи методами палеографии.
Любопытно, что в дискуссии принял участие и другой Пушкин, Александр Сергеевич. Незадолго до смерти он как раз работал над статьёй об аутентичности памятника:
«Подлинность же самой песни доказывается духом древности, под который невозможно подделаться. Кто из наших писателей в XVIII веке мог иметь на то довольно таланта? Карамзин? но Карамзин не поэт. Державин? но Державин не знал и русского языка, не только языка „Песни о полку Игореве“. Прочие не имели все вместе столько поэзии, сколько находится оной в плаче Ярославны, в описании битвы и бегства. Кому пришло бы в голову взять в предмет песни темный поход неизвестного князя? Кто с таким искусством мог затмить некоторые места из своей песни словами, открытыми впоследствии в старых летописях или отысканными в других славянских наречиях, где еще сохранились они во всей свежести употребления? Это предполагало бы знание всех наречий славянских. Положим, он ими бы и обладал, неужто таковая смесь естественна?».
Калайдович против Пушкина:

Нужно понимать, что сомнения в подлинности возникли не на пустом месте. XVIII – первая половина XIX века – это эпоха, когда интерес к истории и древним рукописям уже был очень велик, но наука была ещё не настолько развита, чтобы всегда быстро распознавать подделки. Наиболее прославившимися фальсификациями стали «Поэмы Оссиана» Макферсона (которые А.С. принял за чистую монету и переводил на русский), а также Краледворская и Зеленогорская рукописи Ганки. Были фальсификаторы и в нашем отечестве, например, Бардин (подделывавший, кстати, уже после пожара копии «Слова») и Сулакадзев. Неудивительно, что обжёгшись на молоке, многие начинали дуть на воду.
Ещё одним фактором является наличие «Задонщины», памятника XV века, имеющего множество параллелей с текстом «Слова». Было обнаружено несколько списков «Задонщины», и сомневаться в её подлинности не приходится. Это породило следующую концепцию: некий фальсификатор в конце XVIII века сочинил «Слово», взяв за основу материал «Задонщины», а пожар 1812-го года позволил замаскировать отсутствие рукописного оригинала.
Дискуссия вышла на новый виток в сороковые годы после публикации книги французского слависта А. Мазона «Le Slovo d'Igor» (если позволите, не буду переводить название на русский), в которой он доказывал подложность «Слова». Мазону возражало множество учёных из разных стран, в том числе такой мэтр как Р. О. Якобсон.
В Советском Союзе вплоть до 1963-го года все были за подлинность. Пока историк А. А. Зимин не выступил с докладом, в котором утверждал, что настоящим автором слова являлся тот самый Иоиль Быковский, у которого Мусин-Пушкин якобы купил рукопись. Зимин даже написал монографию, которую в 1964-м году обсуждали на специальном закрытом заседании Отделения истории Академии наук. Специально для заседания монографию размножили в ста экземплярах, которые потом предписывалось вернуть. Несмотря на то, что большинство участников заседания выступило с критикой концепции Зимина, а академик Лихачёв, защитник подлинности, был за открытую дискуссию, партийное руководство приняло неумное и недальновидное решение не публиковать книгу. Разумеется, это не могло не породить в среде интеллигенции мнения, что раз власти скрывают, то «Слово», конечно, является подделкой. Книга Зимина вышла лишь в 2006-м году, через 26 лет после его смерти.
Мазон против Якобсона:

В новом тысячелетии дискуссия возобновилась в связи с публикацией монографии американского историка Э. Кинана. Ранее Кинан прославился тем, чем безуспешно пытался опровергнуть подлинность знаменитой переписки Ивана Грозного и князя Курбского. В книге 2003-го года он приписывает авторство «Слова» одному из отцов славистики – чеху Йозефу Добровскому. Дело в том, что тот страдал неким психическим заболеванием, возможно, биполярным расстройством, а в 1792-1793 годы совершил поездку в России, где ознакомился с древнерусскими рукописями. Согласно концепции Кинана, Добровский создал подделку в состоянии умопомрачения, а потом забыл об этом. Кроме того, Добровский как один из самых выдающихся учёных своего времени, якобы был достаточно квалифицирован для написания подделки.
1. В праславянском, предке всех славянских языков, было не два числа, а три: единственное, множественное и двойственное. Из живых славянских языков двойственное число сохранилось в словенском и лужицких. Приведу примеры из словенского (буква j = й):
to je zelo zanimiv problem «это очень интересная проблема»;to sta zelo zanimiva problema «это две очень интересных проблемы»;
to so zelo zanimivi problemi «это очень интересные проблемы».
Было двойственное число и в древнерусском. Один из его реликтов в современном языке – согласование существительных с числительными 2, 3, 4. Древняя модель одинъ столъ – дъва стола – три / четыре столи – пять столъ (столъ здесь – форма родительного падежа множественного числа) сменилась современной один стол – два / три / четыре стола – пять столов, где старая форма двойственного числа распространилась на 3 и 4.

В то же время, в некоторых деталях двойственное число функционирует в разных языках по-разному: одним образом в словенском, другим в лужицких, третьим в церковнославянском. Была своя специфика и в древнерусском.
В «Слове» двойственное число ещё вполне себе представлено, в том виде, в котором оно использовалось в XI-XII веках. А вот в «Задонщине» его уже нет. Значит, в этом моменте потенциальный фальсификатор не мог опереться на «Задонщину». Не помогли бы ему и церковнославянские грамматики, поскольку там иная схема употребления двойственного числа, чем та, что была характерна для древнерусского. Чисто гипотетически, фальсификатор мог быть гением, опередившим свою эпоху и научившимся правильному употреблению двойственного числа путём чтения летописей. Но есть одна деталь: в истории древнерусского языка в определённый момент старые формы двойственного числа среднего рода типа двѣ солнци и двѣ сердци (орфография с учётом падения редуцированных) сменяются новыми типа два солнца и два сердца, которые мы и обнаруживаем в «Слове». В летописях новые формы появляются с 3-й четверти XIII века, а «Слово», напомню, предположительно было написано в конце XII. Значит, если бы фальсификатор в конце XVIII века уже разобрался во всех нюансах употребления двойственного числа и хронологии его исчезновения (что учёным удалось сделать лишь в XIX-XX веках), то с опорой на летописи XII века он бы употребил солнци и сердци. Однако берестяные грамоты показали, что на северо-западе Руси в XII веке уже встречались формы типа два солнца. Берестяные грамоты начали извлекать из земли во второй половине XX века, и потенциальный фальсификатор не мог ничего о них знать.
2. В древнерусском языке была такая штука, как энклитики – особые безударные слова, подчинявшиеся закону Ваккернагеля (то есть, в предложении они должны были ставиться на втором месте, сразу после первой ударной группы). Некоторые остатки старого состояния сохранились до сих пор, например, нельзя начать предложение со слов ли, же, бы (знаешь ли ты - *ли ты знаешь; ты же знаешь - *же ты знаешь; я бы хотел - *бы я хотел). Но значительно лучше эта система представлена в западно- и южнославянских языках. Причём, что немаловажно, в каждом она имеет свою специфику.
Для того, чтобы правильно использовать энклитики, человеку нужно знать три вещи:
а) какие слова являются энклитиками;
б) как членить фразу, чтобы правильно поставить энклитики;
в) иерархию энклитик – то есть, то, в каком порядке они выстраиваются, если в одно предложение попадает несколько энклитик разных разрядов.
Проиллюстрирую примерами. Скажем, в чешском энклитиками являются формы вспомогательного глагола «быть» в прошедшем времени и сослагательном наклонении, особые формы родительного, дательного и винительного падежей личных местоимений, а также возвратные частицы при глаголах. И ранжируются они именно в таком порядке. Вот этот набор в одной фразе:

Порядок слов в чешском свободный, то есть, теоретически можно сказать и omluvit bych se ti chtěl «извиниться перед тобой я бы хотел». Нельзя сделать двух вещей: поставить bych se ti не на второе место, а также изменить порядок слов внутри этого кластера.
Далее, нужно знать, после каких слов в чешском можно ставить энклитики, а после каких нельзя. Если мы говорим о союзах, то после že «что» энклитики ставятся, а после ale «но» и a «и» – нет. Например:

Во второй фразе мы обязаны поставить что-нибудь между a и энклитиками.
В древнерусском языке XII века закон Ваккернагеля был вполне актуален и текст «Слова» его соблюдает почти идеально. Сохраняется не только постановка энклитик на второе место, но и их иерархия (а Зализняк, к слову, выделяет аж восемь рангов). Скажем, во фразе из самого начала не лѣпо ли ны бяшеть энклитиками являются ли (2-й ранг) и ны «нам» (6-й ранг).
Кинану казалось, что он снял аргумент энклитик, предложив на роль фальсификатора кандидатуру Добровского. Добровский – чех, а значит, знал, как нужно ставить энклитики. Однако древнерусская система не соответствует современной чешской на сто процентов. Например, во фразе Вежи ся Половецкіи подвизашася «шатры половецкие зашевелились» ся разбивает сочетание существительного с прилагательным, что не встречается в современном чешском (но бывает, скажем, в сербохорватском). Кроме того, здесь представлен ещё один любопытный феномен: двойное ся, когда возвратная частица ставится одновременно перед глаголом и после него. Древнерусским памятникам оно известно (в том числе берестяным грамотам), а вот в чешском ничего подобного нет.
3. В древнерусском было четыре прошедших времени, и формы одного из них, имперфекта, в тексте «Слова» встречаются с наращением -ть, а также без него: бяше и бяшеть, бяху и бяхуть. Лишь в 1999 году вышла статья американского слависта Алана Тимберлейка, в которой показано, от каких факторов зависит распределение этих форм (в частности, как раз, от наличия энклитик), причём в «Слове» эти факторы работают так же, как в Лаврентьевской летописи XII века. То есть, если бы «Слово» было подделкой, его автор должен был бы сам в XVIII веке открыть правило, которое в течение двухсот лет не могли обнаружить сотни высококвалифицированных специалистов.
Разумеется, аргументов значительно больше, я выбрал лишь три из них. Но, надеюсь, в целом картина понятна.
Хочу оговориться, что чисто теоретически можно доказать поддельность «Слова», но вот стопроцентно доказать его подлинность невозможно. Речь идёт о том, что если бы в «Слове» удалось найти вещи, противоречащие твёрдо установленным фактам из истории древнерусского языка, это говорило бы о фальсификации. Но даже если «Слово» идеально соответствует тому, что учёным удалось выяснить о древнерусском языке (в том числе в самое последнее время), всегда можно сказать, что фальсификатор был настолько гениален, что уже в XVIII веке знал о древнерусском языке больше, чем кто-либо даже из современных учёных. Процитирую самого Зализняка:
Желающие верить в то, что где-то в глубочайшей тайне существуют научные гении, в немыслимое число раз превосходящие известных нам людей, опередившие в своих научных открытиях все остальное человечество на век или два и при этом пожелавшие вечной абсолютной безвестности для себя и для всех своих открытий, могут продолжать верить в свою романтическую идею. Опровергнуть эту идею с математической непреложностью невозможно: вероятность того, что она верна, не равна строгому нулю, она всего лишь исчезающее мала. Но несомненно следует расстаться с версией о том, что «Слово о полку Игореве» могло быть подделано в XVIII веке кем-то из обыкновенных людей, не обладавших этими сверхчеловеческими свойствами.
Неслучайно то, что в лагере противников подлинности преобладают историки и литературоведы, а вот среди лингвистов, особенно диахронистов, их крайне мало.
В этой статье представлен BLEU, метод автоматической оценки качества в области машинного перевода, чтобы вы могли понять, почему BLEU можно использовать в качестве индикатора оценки качества перевода, каков его принцип, как его использовать, какие проблемы он может решить и какие проблемы не может решить. .
Боррель: Действия ЕС никак не способствуют разжиганию украинского конфликта, а наоборот, направлены на его сдерживание
[…] «Мы не побуждаем к войне, мы не способствуем тому, чтобы война распространялась. Мы пытаемся сдержать ее, как в пространственном измерении, чтобы она не затронула другие страны, так и в вертикальном измерении, чтобы не применялось более смертоносное оружие».
Это тот же Боррель, который потребовал от всех стран-членов ЕС предоставить Незалежной оружие и все 27 согласились?
В чем принцип BLEU?
Почему BLEU можно использовать в качестве оценочного показателя машинного перевода, все же придется взглянуть на его принцип.
Теперь давайте рассмотрим эти концепции по очереди:
- N-gram
- Штрафной фактор
- Алгоритм Bleu
N-gram
N-грамма - это статистическая языковая модель, которая может представлять предложение как последовательность n последовательных слов и использовать информацию о сопоставлении соседних слов в контексте для вычисления вероятности предложения, тем самым оценивая, является ли предложение гладким.
BLEU также использует правило сопоставления N-грамм, которое может вычислить долю сходства n групп слов между сравнительным переводом и справочным переводом.
Оригинал: Кот сидит на коврике
Машинный перевод: кошка сидела на циновке.
Человеческий перевод: кошка на циновке.
Давайте посмотрим на соответствие 1-4 грамма соответственно:
1-gram

Вы можете видеть, что машина переводит 6 слов, а 5 слов попадают в ссылку, поэтому степень соответствия составляет 5/6.
2-gram

Степень совпадения 2-граммовой фразы составляет 3/5.
3-gram

Степень совпадения 3-граммовой фразы - 1/4.
4-gram
Соответствие 4-элементных фраз пропало.
После приведенного выше примера вам должно быть очень ясно, как рассчитывается n-грамм. В общем, 1 грамм может представлять, сколько слов в исходном тексте переведено отдельно, что может отражать перевод.Достаточность, Более 2 граммов может отражать переводБеглость, Чем выше его значение, тем лучше читаемость. Эти два показателя можно сравнить с ручной оценкой.
Однако здесь есть особые обстоятельства, невозможно отразить правильность перевода через n-грамм, например:
Оригинал: Кот сидит на коврике
Машинный перевод: the the the the the the.
Справочный перевод: кошка на циновке.

Если вы посчитаете 1 грамм, вы обнаружите, что все совпадают, а степень совпадения 7/7 , Это определенно не отражает достаточности, что мне делать?
BLEU пересмотрел этот алгоритм и предложил алгоритм, который берет минимум N-грамм в машинном переводе и максимальное количество N-граммов в эталонном переводе:

Таким образом, исправленный результат выше должен быть count = 7, Max_ref_Count = 2, а минимальное значение между ними должно быть 2, тогда степень совпадения исправленного 1-грамма должна быть 2/7 。
Пора придумать формулу для вычисления точности каждого порядка N-грамма в статье:

На первый взгляд, как вы думаете, он очень высокий? Если вы этого не понимаете, что-то не так. Объясните:

Это означает, что минимальное количество вхождений n-грамма в переведенном переводе и переводе справочных материалов, например, минимальное количество вхождений 1-грамма выше равно 2.

Указывает количество появлений n-грамма в переведенном переводе, например, количество появлений 1-грамма выше равно 7.
Хорошо, здесь вы в основном знаете, как рассчитывается точность n-граммов в bleu.
Достаточно ли хорош этот расчет? Нет, мы должны продолжать улучшать, например:
Машинный перевод: Кот
Справочный перевод: кошка на циновке.
Если появится такое короткое предложение, вы обнаружите, что точность вычисления n-грамма будет высокой. Очевидно, что на этот раз оценка будет равна 1, но на самом деле ее оценка должна быть относительно низкой. Ввиду того, что переведенный перевод короче, чем перевод справки, необходим механизм штрафов для контроля за ним.
Штрафной фактор

Где c - количество слов в машинном переводе, r - количество слов в справочном переводе,
В этом случае точность нашего пересчета должна быть:
BP = e^(1- 6 / 2) = 7.38905609893065
e - постоянное иррациональное число, бесконечное неповторяющееся десятичное число, поэтому используйте e для представления 2,718281828
Алгоритм Bleu
После различных улучшений, описанных выше, окончательная формула расчета BLEU выглядит следующим образом:

БП мы уже знаем, значит

Что это за хрень? Не думайте об этом так много. На самом деле, это всего лишь некоторые математические операции. Его функция - позволить каждому порядковому n-грамму приниматьВес подчиняется равномерному распределениюТо есть, будь то 1-граммовый, 2-граммовый, 3-граммовый или 4-граммовый, их функции одинаково важны. По мере увеличения n-грамма общая оценка точности уменьшается экспоненциально, поэтому обычноN-грамм может доходить до 4-грамм。
Преимущества и недостатки BLEU?
преимущество: Удобно, быстро, результат приближен к человеческим рейтингам.
Недостаток:
- Не учитывает точность языкового выражения (грамматики);
- Точности оценки будут мешать общие слова;
- Точность коротких предложений перевода иногда выше;
- Несоблюдение синонимов или подобных выражений может привести к отклонению разумного перевода;
Сам BLEU не стремится к 100% точности и не может достичь 100%. Его цель - предоставить быстрое и неплохое решение для автоматической оценки.
В конце концов
Принцип BLEU на самом деле не очень сложен. Он больше основан на оптимизации, основанной на n-граммах. Цель написания этой статьи - разобраться в проблемах, которые может решить BLEU, и в проблемах, которые не могут быть решены. Это то, как передать мое последующее мышление. Другие методы, позволяющие улучшить оценку перевода, имеют определенный просветительский эффект. Сама по себе оценка качества перевода - горячая тема в области машинного перевода. Если мы сможем найти лучший вариант, чем BLEU, это принесет большую пользу.
Наконец, много содержания в статье можно найти в других справочных статьях. Справочная статья также содержит хорошее объяснение того, как рассчитать BLEU и принцип действия. Вы также можете обратиться к нему.

Юлия Епифанцева
Если говорить о более объективных оценках качества перевода, то, например, в связи с развитием статистического машинного перевода, для которого вместо словарей перевода использую корпуса (или базы) параллельных текстов, была разработана специальная метрика для оценки качества перевода – BLEU. Эту метрику создали сотрудники IBM, чтобы отслеживать на больших объемах результат изменений в переводе в процессе разработки системы (как меняется перевод при добавлении новых корпусов текстов для тренировки системы, при изменении программного кода и т.д.).
Алгоритм BLEU оценивает качество перевода по шкале от 0 до 100 на основании сравнения человеческого перевода и машинного перевода и поиска общих фрагментов. Основная идея состоит в том, что чем больше совпадений, тем лучше перевод.
Не вдаваясь в технологические тонкости, можно сказать, что данная метрика на практике объективна только для статистических или гибридных систем и для языков с неразвитой морфологической структурой, поэтому для перевода на русский эта метрика всегда показывает не такой высокий результат перевода как, например, при переводе на английский или французский. Тем не менее, метрика очень популярна среди специалистов, так как все-таки позволяет хоть как-то сравнивать разные системы или разные версии систем.

У профессионалов перевода существуют свои технологии для измерения качества машинного перевода. Например, в локализационных компаниях или в бюро перевода, применяющих машинный перевод, используется технология post-editing distance. С помощью данной технологии измеряют посимвольно, сколько изменений было сделано редактором в машинном переводе, прежде чем этот перевод был отредактирован до фактически и стилистически верного. Таким образом, тестируют, например, целесообразность использования машинного перевода в переводческих проектах или сравнивают разные системы машинного перевода, чтобы выбрать лучшую. Чем меньше пришлось редактору исправлять текст, тем лучше система. А если все переводы пришлось переписывать, значит, машинный перевод на данных текстах неэффективен или он был недостаточно настроен.
Нужно, однако, отметить, что экспертная оценка качества перевода по-прежнему пользуется бОльшим доверием, хотя с ней же связана проблема субъективности в оценке качества. МП почти всегда не идеален, поэтому требуются определенные знания и здравый смысл, чтобы оценить результат работы компьютерной программы. И там, где один специалист скажет, что перевод понятен и приемлем, для другого он будет «невозможен» с точки зрения стиля и грамматики.
Один из способов борьбы с экспертной субъективностью –привлечение большого количества экспертов (или даже просто носителей языка), т.е. использование популярного сейчас краудсорсинга. Именно такой способ оценки качества автоматического перевода, полученного с помощью разных систем, используется в конкурсе, который проводится ежегодно в рамках Семинара по статистическому машинному переводу.
Конкурс организуется и проходит под эгидой Ассоциации компьютерной лингвистики (ACL), основанной еще в 1962 году. Она ведет большую научную и прикладную деятельность, в частности, проводит ежегодные конференции для специалистов в области компьютерной лингвистики и обработки информации на естественных языках, конкурсы систем машинного перевода и выпускает с 1974 года журнал Computational Linguistics.
Конкурс машинных переводчиков организован следующим образом: организаторы выкладывают в открытый доступ корпуса параллельных текстов и программные средства для создания систем статистического машинного перевода или тренировки на этих корпусах любых других систем машинного перевода.
Принять участие в конкурсе могут все желающие, количество участников доходит полутора сотен. Обычно участвуют лаборатории различных университетов (из Англии, Германии, Швеции, Австралии и других стран), занимающиеся исследованием и разработкой статистических систем перевода в научных целях, и разработчики коммерческих систем (SYSTRAN, PROMT).
Кроме того, организаторы используют переводы известных онлайн-сервисов. Языковые пары и их количество варьируется от года к году, но обычно это перевод с английского на французский, испанский, немецкий и наоборот. Также ежегодно добавляются некоторые «редкие» языки – чешский, хинди. В 2013 году в конкурсе впервые был представлен русский язык, и сразу стал лидером по числу представленных систем. А в 2011 году был, например, устроен специальный конкурс в рамках основного конкурса для перевода с гаитянского креольского на английский.
Введение специального конкурса было связано с землетрясением 2010 года на Гаити и нашумевшей статьей двух исследователей из Стэнфордского университета и из Microsoft о создании статистической системы машинного перевода на основе имеющихся разработок фактически за несколько дней.
Как понятно из этой истории, выбор языковых пар для конкурса обусловлен в первую очередь наличием параллельных текстов, необходимых для тренировки систем машинного перевода. Поэтому в первую очередь используются тексты стенограммы заседаний и тексты документов Европарламента, доступные как раз для основных европейских языков, а также новостные тексты.
Надо сказать, что в этот период участники много общаются между собой и с организаторами по поводу исходных данных, так как, выражаясь на профессиональном сленге, они «грязные», т.е. могут содержать непереведенные сегменты, технические символы и другие особенности, которые отрицательно сказываются на качестве перевода.
В определенный момент организаторы публикуют тестовый корпус текстов для перевода. Участники конкурса должны подготовить автоматический перевод этого корпуса своими системами в течение недели и разместить на сайте организаторов.
Затем идет этап экспертной оценки, во время которого эксперты, среди которых могут быть и участники конкурса, добровольцы, сравнивают и оценивают переводы друг с другом. Оценка производится через веб-интерфейс специально разработанной системы для оценки переводов — Amazon Mechanichal Turk (краудсорсинговый сервис от компании Amazon) и представляет собой некоторый нормализованный коэффициент сравнения вариантов переводы, выполненных различными системами.

«Механический турок»
Переводы всех участников анонимны, поэтому эксперт не знает, с помощью какой системы получен перевод. Оценка производится таким образом: эксперт видит исходное предложение, несколько автоматических переводов и человеческий перевод исходного предложения. Задача состоит в том, чтобы ранжировать (разместить в порядке от лучшего к худшему) автоматические переводы. После этого организаторы обобщают результаты оценки по всем участникам, подводят итоги и публикуют их на своем сайте.
В 2013 году организаторы, как уже было сказано, выложили данные и для русского языка, и появилась возможность участвовать в конкурсе с переводом с английского на русский. По результатам конкурса в 2013 и в 2014 году у технологии PROMT первое место для перевода с английского на русский.
Русский и немецкий, конечно, не самые сложные языки для перевода с английского, перевод на арабский сложнее, но все же получить качественный перевод на эти языки труднее, чем, например, на французский. И в русском, и в немецком развитая падежная система, много окончаний, в немецком предложении строгий порядок слов – все это создает дополнительные трудности разработчикам.
Качество машинного перевода за последнее десятилетие заметно выросло. В первую очередь это связано с развитием технологий, с доступностью больших текстовых данных для анализа и тренировки систем, а также с тем, что накопленный опыт практического применения (в коммерческих компаниях, у частных пользователей, на онлайн-сервисах) позволяет разработчикам получать ценную информацию об использовании технологии для решения разных задач и использовать этот опыт в дальнейших разработках.
Об авторе:
Юлия Епифанцева, директор по развитию бизнеса PROMT.
Окончила филфак СПбГУ. Разработчик технологий машинного перевода.
Научная деятельность и участие в конференциях в последние годы:
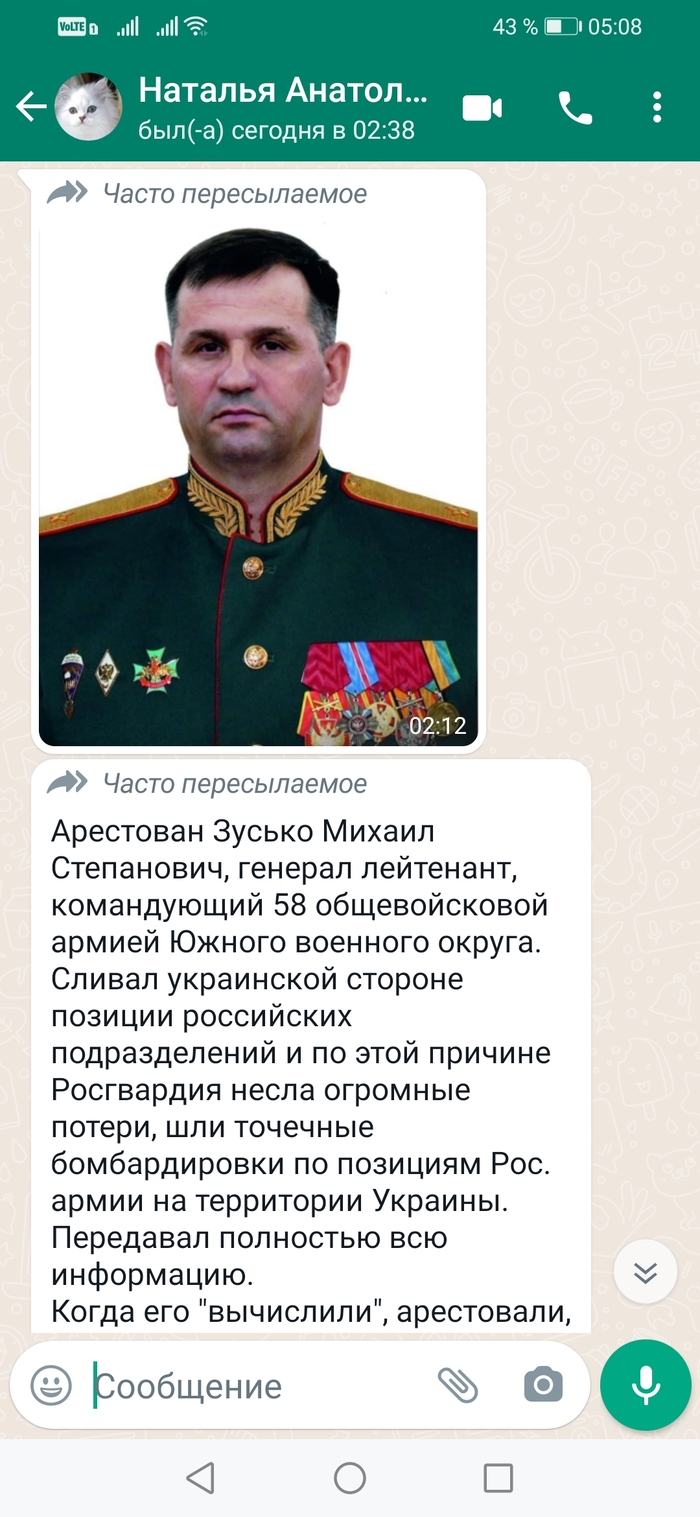
Сливал украинской стороне позиции российских подразделений и по этой причине Росгвардия несла огромные потери, шли точечные бомбардировки по позициям Рос. армии на территории Украины.
Передавал полностью всю информацию.
Когда его "вычислили", арестовали, он попытался повеситься в камере, но ему не дали это сделать.
Первая мысль: чё за гон. Сколько читал новостей и каналов в телеге - ничего подобного не слышал. Т.к. человек я от природы недоверчивый и крайний скептик, то тут же полез в интернет, проверять.
Так и есть, очередной фейк и деза от укров-небратьев, работает ЦИПсО:
Зато сколько восторженных комментов под фейком в соц. сетях, полных праведного гнева, с требованием "люто покарать предателя" ! А некоторые идиоты это ещё и с упоением ретранслируют, где только можно, как моя знакомая.
Остаётся только догадываться, скольким ещё людям она это разослала. Объяснил, как мог, что от уголовной статьи за распространение фейков её отделяет очень тонкая и незыблемая грань, и всего одно заявление в органы от сознательного гражданина гарантирует ей уголовку и срок, пусть даже условный.
Мораль: наши собственные идиоты справляются ничуть не хуже, чем украинские диверсанты и провокаторы, с радостью распространяя любой бред, который им скармливают. Бездумный турботриот хуже предателя, т.к. сотрудничает с врагом и ему на пользу неосознанно и рьяно.
Прошу предупредить всех, чтобы не велись на этот вброс и ему подобные, и по сто раз думали, прежде чем рассылать подобное своим родным и близким. Если уже было - прошу прощения, но предварительный поиск ничего не дал, и как говорится - лучше перебдеть, чем недобдеть. Я Za наших!
В Новороссийске про холеру в воде разгоняют уже третий день.

Для себя решил не лезть туда, где работают военные. Сами разберутся.
Поэтому не комментирую и не пересылаю что касается военных.
"Первая мысль: чё за гон. "
Когда видишь марку "Часто пересылаемое" - уже стоит насторожиться.
А мне пару дней назад знакомый в панике звонит, мол звонили с военкомата, сказали собрать рюкзак с мыльно-рыльными и сменой белья, и ждать вызова в военкомат. Объяснил ему что он долбоёб, а он не верит, обиделся.
Ни одно фото, ни одно видео с маркером "часто пересылаемое" даже не загружаю, тексты начинаю читать и вижу, что в большинстве своем это бредятина, указываешь мол что за хуйня, вы в это верите?
Аналогично с открытками и поздравлялками. "Пересланное" - да идите вы нахер, если от себя не можете написать поздравление, даже самое примитивное.
Это всё было по поводу мессенджера.
Дебилов еще не отменяли а там их огогоооо
Неужели на просторах инета не нашлось фото генерала в актуальном звании? Я бы уже только по этому не поверил в инфу
Интересно, а если б наши такое же про Арестовича замутили?) Его сразу расстреляли бы или меняли как второго кума Путина?)(
Хорошо, что у меня таких ебаньков нет в чатиках.
Некоторые ещё возмущаются, что официальные источники дают мало информации, мол, не доверяют своему народу, скрывают что-то. Ага, вам что ни дашь, инстатвари и тиктокеры сраные, вы не поймёте, а что поймёте, так переврете. Лучше уж чахните в информационном вакууме.
Мне еще месяц назад пришло от кого-то. Я отнеслась скептически, но червячок сомнения засел. На днях это же мне прислала мама. А потом я зашла на канал Сладкова в телеге, он там опровержение дает.
Из осведомленных источников стало известно: когда ВВП сердится на шманции от демократических Ойропейцев то в сердцах говорит что вместо удобрений будут покупать навоз у Беларуси за белорусские рубли.
Т.к. человек я от природы недоверчивый и крайний скептик,то тут же полез в интернет, проверять.
Так и есть, очередной фейк и деза от укров-небратьев, работает ЦИПсО:
То есть ты не доверил одной непроверенной информации, но когда нашёл её непроверенное опровержение, то сразу принял его за чистую монету?
Сорян, чувак, но ты не скептик, а обычный человек с односторонней точкой зрения
А есть у кого инфа правда или нет что убит Командующий 49-й общевойсковой армией Южного военного округа Рязанцев Яков? Месяц назад писали что якобы погиб в Херсоне.

По моей информации, к сожалению, инфу действительно сливают. ГРУшник говорит, ждут часто там, где мы только собираемся посмотреть. Бля, с чеченской изменилось только то, что чеченцы за
Я счастлив жить в стране, избавленной от фейков
Экспертов предложили сажать за уголовное преследование невиновных россиян
В Госдуму внесен законопроект об уголовной ответственности для экспертов за заведомо ложное заключение на всех стадиях судебного и досудебного производства. Документ опубликован на сайте Думы.
«Изменения позволят усилить защиту прав граждан на доступ к правосудию, ограждая от возможных злоупотреблений со стороны нечистых на руку экспертов, чьи заключения зачастую имеют решающее значение для возбуждения уголовного дела или отказа в нем», — сказал один из авторов законопроекта Павел Крашенинников, передает ИА Regnum.
В качестве наказания предлагается штраф до 80 тысяч рублей или в размере заработной платы или иного дохода осужденного за период до шести месяцев, либо обязательные работы на срок до 480 часов, либо исправительные работы на срок до двух лет, либо арест до трех месяцев.
Если из-за ложного заключения против гражданина возбудят дело по обвинению в тяжком или особо тяжком преступлении, то наказанием могут стать принудительные работы либо лишение свободы на срок до пяти лет.
Сейчас уголовная ответственность экспертов и специалистов за дачу ложных сведений предусмотрена статьей 307 УК РФ («Заведомо ложные показание, заключение эксперта, специалиста или неправильный перевод»). Она распространяется на предварительное расследование по уголовному делу, а также на стадию рассмотрения дела в суде — то есть, на период, когда уголовное дело уже возбуждено.

В настоящее время компьютеры занимают все более значительное место не только среди программистов и инженеров, но и в среде самых разнообразных пользователей включая лингвистов, переводчиков и военных специалистов нуждающихся в оперативном переводе иноязычной информации. В этой связи, электронные словари и программы, осуществляющие машинный перевод, являются очень удобным подручным средством в целях экономии времени и оптимизации процесса понимания иноязычной информации. Кроме того, в настоящее время имеются программы–переводчики, которые могут производить более или менее адекватный перевод иноязычных текстов и могут являться подспорьем в работе военных специалистов различных профилей. [5]
Программный перевод - это широкое и не совсем точное понятие, охватывающее широкий спектр простых и сложных инструментов. Они могут включать:
Программы для проверки правописания, которые могут быть встроены в текстовые редакторы или дополнительные программы;
Программы для проверки грамматики, которые также встраиваются в текстовые редакторы или дополнительные программы;
Программы для управления терминологией, которые позволяют переводчикам управлять своей собственной терминологической базой в электронной форме. Это может быть и простая таблица, созданная в текстовом редакторе, и электронная таблица, и база данных, созданная в программе FileMaker. Для более трудоемких (и более дорогих) решений существует специальное программное обеспечение, например, LogiTerm, MultiTerm, Termex, TermStar и т. п.[9]
Словари на компакт-дисках, одноязычные или многоязычные;
Терминологические базы данных, хранимые на компакт-дисках или подключаемые по Интернету, например The Open Terminology Forum или TERMIUM и многие- многие другие.
Наличие компьютерных программ для перевода, с одной стороны, облегчает работу переводчика, так как не надо выискивать в словаре незнакомые слова, а с другой стороны, этот перевод нельзя считать окончательным, так как при переводе компьютерные программы допускают много ошибок. Ведь даже профессиональный переводчик при переводе обращается не к одному словарю для подбора нужного эквивалента.
В поисках варианта перевода переводчик вновь и вновь обращается к единицам ИЯ в оригинале, ищет в словаре их значения и одновременно пробует, нельзя ли использовать для их перевода один из вариантов, предлагаемый в двуязычном словаре. Иногда переводчик обнаруживает, что имеющийся в словаре перевод можно непосредственно использовать для перевода данного текста, и задача сводится к правильному выбору словарного соответствия. Однако чаще переводчик не находит в словаре такого варианта, который удовлетворяет условиям конкретного контекста. В этом случае переводчик отыскивает нужную ему единицу ПЯ, сопоставляя словарные варианты, определяя общий смысл переводимого слова и применяя его к условиям контекста.
Для подтверждения вышесказанного, рассмотрим перевод технического текста из книги «Class Notes for Cryptologic Mathematics» (FYS 100) Тима Мак Девитта и ФрэнкаАрнольда (2012) [13], выполненного с помощью программы Promt, и сделаем выводы о том, какие ошибки чаще всего допускаются при переводе.
What is Cryptology?
Classically, cryptology was used to send and receive secret messages and its users were often military leaders or diplomats. For Admiral Alice to send General Bob a secret message, she would have to encrypt or encipher her message using a method that she and Bob had previously agreed upon. When Bob receives the message, he has to decrypt or decipher her message to read it. Often, the method of encryption would rely on a key - some special number(s) or word(s) that only Alice and Bob know.
Prior to the computer age, encryption methods were relatively simple, not explicitly mathematical, and often not very secure. Messages were relatively short and there was very little systematic research certifying the security of cryptologic methods. Today, however, messages can be very long. As of this writing (2010),
a typical JPEG file from a digital camera is over 1 MB, which is roughly equivalent to a text file of a million characters. Contemporary encryption methods tend to use very sophisticated mathematics and there is a great deal of systematic research. The US Department of Commerce certifies certain algorithms so that users can be confident that their communications are secure, and these algorithms can be very complicated. In addition to the transmission and reception of secret messages, modern cryptology also involves less well known operations such as key exchange, digital signatures, random number generation, hashing, etc. but this book focuses, for the most part, on mathematical versions of historical methods. These methods require what is probably unfamiliar mathematics and, although they are no longer useful, they evolved into today’s methods so it is still useful to be familiar with them. The only exception is our discussion of public key systems, which currently enjoy widespread use.
Another important difference between classical and modern cryptography is frequency of use. In the past, the average individual had no practical reason to encrypt messages, but today we all use cryptographic algorithms without even knowing it when we use our cell phones or email or make online purchases.
ПЕРЕВОД ПРОГРАММЫ PROMT
Что такое Криптология?
операции, такие как ключевой генерация случайных чисел, хеширование, и т.д. но эта книга фокусы, по большей части, на математических версиях исторических методов. Эти методы требуют что является, вероятно, незнакомой математикой и, несмотря на то, что они больше не полезны, они развились в сегодняшний методы, таким образом, все ещеполезно быть знакомым с ними. Единственное исключение - нашеобсуждение открытого ключа системы, которые в настоящее времяобладают широким использованием. Другое важное различие междуклассической и современной криптографией – частота использования. В
ОТРЕДАКТИРОВАННЫЙ ПЕРЕВОД
Что такое криптология?
АНАЛИЗ ТЕКСТА, ПЕРЕВЕДЕННОГО С ПОМОЩЬЮ ПРОГРАММЫ PROMT
При работе с данным программным продуктом были обнаружены следующие погрешности при переводе текста. Лексический анализ текста показал, что PROMT по большей степени даёт адекватный перевод простых частей речи, но допускает ошибки в построении предложений, переводе падежей прилагательных, речевых оборотах.
Недостатком переводчика PROMTявляется неточность перевода слов, имеющих несколько значений. Для более адекватного перевода в дальнейшем можно предложить более глубокий анализ грамматического построения предложения, с улучшением качества перевода различных частей речи и их грамматических характеристик, а так же исключить конфликт словарей при переводе специализированных текстов.
Всё вышеизложенное не исключает тот факт, что машинный перевод стал одним из популярных видов деятельности человека. Несмотря на определённые недостатки выходного текста, машинный перевод действительно облегчает и ускоряет традиционный процесс перевода. В XXI веке - век науки и информатики - машинный перевод становится особым и эффективным средством для межъязыковой коммуникации во всех областях современной военной науки и техники. Появление машинного перевода можно и нужно считать активным помощником для военных специалистов. Результат этого вида перевода может быть использован как черновой вариант будущего текста, который будет профессионально в дальнейшем отредактирован переводчиком, а также как средство, чтобы в крайней ситуации отсутствия переводчика получить общее представление о теме и содержании текста.
Ермаков А.Е. Неполный синтаксический анализ текста в информационно-поисковых системах. – М., 2002.
Каничев М. Встреча компьютерных толмачей. // Мир ПК. – 1998, № 8.
Кормалев Д.А. Приложения технологии извлечения информации из текста: теория и практика. – Переяславль-Залесский, 2003.
Ножов И. Синтаксический анализ. // Компьютерра. – 2002, №21.
Сокирко А. Будущее машинного перевода. // Компьютерра. – 2002, №21.
Кузнецов П. С., Ляпунов А. А., Реформатский А. А. Основные проблемы машинного перевода. Вопросы языкознания, 1956, № 5.
Tim McDevitt Frank Arnold Class Notes for Cryptologic Mathematics. -(FYS 100), 2012.
Изнасилованные мужчины Украины
Судя по всему Украинское руководство признало, что Русская армия трахают солдат ВСУ (мужчин) и даже их служебных собак (домашних животных). Иначе я не могу интерпретировать их высказывание в Facebook.
Так вот почему солдаты Азова не хотят выходить! А помните там собака вышла в один из дней. Вот оно что оказывается.

Зачем использовать BLEU?
На самом деле, нам часто приходится использовать людей для оценки результатов перевода, но этот метод очень медленный и дорогостоящий, потому что вам нужно нанять достаточно профессиональных переводчиков, чтобы получить относительно надежные результаты оценки перевода. Оценки субъективны и во многом зависят от профессионального уровня и опыта.
Чтобы решить эту проблему, исследователи в области машинного перевода изобрели некоторые индикаторы автоматической оценки, такие как BLEU, METEOR и NIST. Среди этих индикаторов автоматической оценки:BLEU в настоящее время является ближайшим человеческим показателемоф.
Показатели оценки METEOR и NIST, автор не проводил глубоких исследований, есть возможность сравнить эти показатели.
Что такое BLEU?
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language к другому. Качество считается соответствием между результатами работы машины и человеком: «чем ближе машинный перевод к профессиональному человеческому переводу, тем он лучше» - это центральная идея BLEU. из первых показателей, которые достигли высокой корреляции с человеческими оценками качества, и остается одним из самых популярных автоматизированных и недорогих показателей. - Википедия
Объясните, прежде всего блю - этоАлгоритм оценки текста, Используется для оценкимашинный переводс участиемПрофессиональный перевод, выполняемый человекомОсновная идея соответствия междуЧем ближе машинный перевод к профессиональному человеческому переводу, тем лучше качество, Оценка, полученная с помощью алгоритма bleu, может использоваться как один из показателей качества машинного перевода.
Как пользоваться BLEU?
Если честно, объяснить математику человеческими терминами очень сложно. Давайте узнаем на примере или раньше:
Машинный перевод: Кот сел на циновку.
Человеческий перевод: кошка на циновке.
Шаг 1. Рассчитайте точность каждого порядка n-граммов.
P1 = 5 / 6 = 0.833333333333333
P2 = 3 / 5 = 0.6
P3 = 1 / 4 = 0.25
P4 = 0 / 3 = 0
Шаг 2: взвешенная сумма
Возьмем вес: Wn = 1/4 = 0,25
∑ i = 1 N w n log P n = 0.25 ∗ log P 1 + 0.25 ∗ log P 2 + 0.25 ∗ log P 3 + 0.25 ∗ log P 4 = − 0.5198603854199589
Шаг третий: спросите БП
Длина машинного перевода = длина справочного перевода, поэтому:
Напоследок попросите BLEU
B L E U = 1 ∗ e x p ( − 0.5198603854199589 ) = 0.5946035575013605
При написании программы не нужно тратить столько усилий на реализацию описанного выше алгоритма, можно использовать уже готовые инструменты:
Читайте также: