
Чему равен компьютерный алфавит
При хранении и передаче информации с помощью технических устройств информацию следует рассматривать как последовательность символов – знаков (букв, цифр, кодов цветов точек изображения и т.д.).
| N=2 i | i | Информационный вес символа, бит |
| N | Мощность алфавита | |
| I=K*i | K | Количество символов в тексте |
| I | Информационный объем текста |
Возможны следующие сочетания известных (Дано) и искомых (Найти) величин:
| Тип | Дано | Найти | Формула |
|---|---|---|---|
| 1 | i | N | N=2 i |
| 2 | N | i | |
| 3 | i,K | I | I=K*i |
| 4 | i,I | K | |
| 5 | I, K | i | |
| 6 | N, K | I | Обе формулы |
| 7 | N, I | K | |
| 8 | I, K | N |
Решение: В одном байте 8 бит. 32:8=4
Ответ: 4 байта.
Решение: Поскольку 1Кбайт=1024 байт=1024*8 бит, то 12582912:(1024*8)=1536 Кбайт и
поскольку 1Мбайт=1024 Кбайт, то 1536:1024=1,5 Мбайт
Ответ:1536Кбайт и 1,5Мбайт.
Задача 3. Компьютер имеет оперативную память 512 Мб. Количество соответствующих этой величине бит больше:
1) 10 000 000 000бит 2) 8 000 000 000бит 3) 6 000 000 000бит 4) 4 000 000 000бит Решение: 512*1024*1024*8 бит=4294967296 бит.
Ответ: 4.
Задача 4. Определить количество битов в двух мегабайтах, используя для чисел только степени 2.
Решение: Поскольку 1байт=8битам=2 3 битам, а 1Мбайт=2 10 Кбайт=2 20 байт=2 23 бит. Отсюда, 2Мбайт=2 24 бит.
Ответ: 2 24 бит.
Задача 6. Один символ алфавита "весит" 4 бита. Сколько символов в этом алфавите?
Решение:
Дано:
| i=4 | По формуле N=2 i находим N=2 4 , N=16 |
| Найти: N – ? |
Задача 7. Каждый символ алфавита записан с помощью 8 цифр двоичного кода. Сколько символов в этом алфавите?
Решение:
Дано:
| i=8 | По формуле N=2 i находим N=2 8 , N=256 |
| Найти:N – ? |
Задача 8. Алфавит русского языка иногда оценивают в 32 буквы. Каков информационный вес одной буквы такого сокращенного русского алфавита?
Решение:
Дано:
| N=32 | По формуле N=2 i находим 32=2 i , 2 5 =2 i ,i=5 |
| Найти: i– ? |
Задача 9. Алфавит состоит из 100 символов. Какое количество информации несет один символ этого алфавита?
Решение:
Дано:
| N=100 | По формуле N=2 i находим 32=2 i , 2 5 =2 i ,i=5 |
| Найти: i– ? |
Задача 10. У племени "чичевоков" в алфавите 24 буквы и 8 цифр. Знаков препинания и арифметических знаков нет. Какое минимальное количество двоичных разрядов им необходимо для кодирования всех символов? Учтите, что слова надо отделять друг от друга!
Решение:
Дано:
| N=24+8=32 | По формуле N=2 i находим 32=2 i , 2 5 =2 i ,i=5 |
| Найти: i– ? |
Задача 11. Книга, набранная с помощью компьютера, содержит 150 страниц. На каждой странице — 40 строк, в каждой строке — 60 символов. Каков объем информации в книге? Ответ дайте в килобайтах и мегабайтах
Решение:
Дано:
| K=360000 | Определим количество символов в книге 150*40*60=360000. Один символ занимает один байт. По формуле I=K*iнаходим I=360000байт 360000:1024=351Кбайт=0,4Мбайт |
| Найти: I– ? |
Ответ: 351Кбайт или 0,4Мбайт
Задача 12. Информационный объем текста книги, набранной на компьютере с использованием кодировки Unicode, — 128 килобайт. Определить количество символов в тексте книги.
Решение:
Дано:
| I=128Кбайт,i=2байт | В кодировке Unicode один символ занимает 2 байта. Из формулыI=K*i выразимK=I/i,K=128*1024:2=65536 |
| Найти: K– ? |
| I=1,5Кбайт,K=3072 | Из формулы I=K*i выразимi=I/K,i=1,5*1024*8:3072=4 |
| Найти: i– ? |
| N=64, K=20 | По формуле N=2 i находим 64=2 i , 2 6 =2 i ,i=6. По формуле I=K*i I=20*6=120 |
| Найти: I– ? |
| N=16, I=1/16 Мбайт | По формуле N=2 i находим 16=2 i , 2 4 =2 i ,i=4. Из формулы I=K*i выразим K=I/i, K=(1/16)*1024*1024*8/4=131072 |
| Найти: K– ? |

Примеры решения задач по информатике
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
Теория:
При форматировании дискеты 3.5 (А) ее физический размер составляет 1.44 Мб. Тем не менее, доступно для записи непосредственно самой информации пользователя только 1.37 Мб, т. к. 71,7 Кб отводится на создание каталога диска и нулевую дорожку.
Сколько дискет объемом 1.37 Мб необходимо для сохранения информации с винчестера объемом 40 Гб? А сколько CD-дисков?
Переводим единицы измерения информации к одному виду.
40 Гб * 1024 Мб = 40960 Мб
Количество дискет = 40960 Мб : 1.37 Мб =дискет.
Т. е. примерно 30 тыс. дискет 3.5 (А)!
Один CD-диск содержит примерно 700 Mb информации, тогда 40960 Mb / 700Mb = 58,51? Т. е. примерно 59 компакт-дисков CD-R объемом по 700 Мб.
Допустим, в вашем классе 27 человек.
Точной степени для этого уравнения нет (и).
В первом случае мы угадаем только из 16 человек, во втором из 32-х.
Значит, чтобы угадать из 27 человек необходимо получить 5 бит информации,
т. е. задать 5 вопросов.
Сколько символов содержится в алфавите, при помощи которого написана книга из 20 страниц, на каждой из которых содержится 15 строк по 20 символов и занимает в памяти компьютера вся книга 5,86 Кб.
Количество символов на одной странице – 15 строк * 20 символов = 300 символов
Всего символов в книге n = 300 символов * 20 страниц = 6000 символов
Общее количество информации I = бит в 1 символе * n символов
5,86 Кб = 48005,12 бит
Определим сколько бит в 1 символе:
, где N – мощность алфавита, значит ,
N=256 символов в алфавите
В алфавите некоторого формального языка всего два знака буквы. Каждое слово этого языка состоит обязательно из 7 букв. Какое максимальное число слов возможно записать в этом языке?
Т. к. для записи слов используется только 2 знака-буквы, при N-перемещениях существуетразличных наборов слов. N=7, значит , тогда N=128 слов.
Приведем выражение к общему основанию и общим единицам измерения.
Какое количество информации несет в себе экран SVGA – монитора (16-bit кодирование, размер экрана 800*600)?
Определим, сколько всего пиксел содержится на всем экране:
* 16 бит = 7 бит = байт = 937,5 Кб = 0,9 Мб
Сколько цветов содержит рисунок размером 100*150 пиксел и объемом 29,3 Кб
Количество точек по вертикали
I
(количество информации)
Глубина цвета в бит
Количество точек по горизонтали
Тогда, 29,3 Кб = 30003,2 байт = 6 бит
Общее число точек = 100*150 =
Тогда количество цветов =
256-цветный рисунок содержит 120 байт информации. Из скольких точек он состоит?
Т. к. рисунок содержит 256 цветов, то , i = 8 бит – глубина цвета
I = кол-во точек * глубину цвета
Количество точек = , т. к. 120 байт = 960 бит
Достаточно ли видеопамяти объемом 256 Кб для работы монитора в режиме 640*480 точек и палитрой в 16 цветов.
Т. к. используется 16 цветов, значит глубина цвета = 4 бита ()
640*480 = всего точек
Необходимое количество видеопамяти:
2 бит дано изначально
* 4 бита = 1 занимает экран
– получается, что дано в 1,7 раз больше, значит видеопамяти хватит!
Вычисление мощности алфавита

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
Продолжение следует…
Возникает вопрос: есть ли продолжение у таблицы байтов? В математике есть понятие бесконечности, которое обозначается как перевернутая восьмерка: ∞.
Понятно, что в таблице байтов можно и дальше добавлять нули, а точнее, степени к числу 10 таким образом: 10 27 , 10 30 , 10 33 и так до бесконечности. Но зачем это надо? В принципе, пока хватает терабайт и петабайт. В будущем, возможно, уже мало будет и йоттабайта.
Напоследок парочка примеров по устройствам, на которые можно записать терабайты и гигабайты информации.
Есть удобный «терабайтник» – внешний жесткий диск, который подключается через порт USB к компьютеру. На него можно записать терабайт информации. Особенно удобно для ноутбуков (где смена жесткого диска бывает проблематична) и для резервного копирования информации. Лучше заранее делать резервные копии информации, а не после того, как все пропало.
Флешки бывают 1 Гб, 2 Гб, 4 Гб, 8 Гб, 16 Гб, 32 Гб , 64 Гб и даже 1 терабайт.
CD-диски могут вмещать 650 Мб, 700 Мб, 800 Мб и 900 Мб.
DVD-диски рассчитаны на большее количество информации: 4.7 Гб, 8.5 Гб, 9.4 Гб и 17 Гб.
Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.

Т радиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2 I = 2 8 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 - пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.

Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.


От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").

Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.

Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.

Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.

С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.

Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.

Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Н апример, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ» (Рис. 10), тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.

Описание термина
Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

- числа;
- спецсимволы;
- двоеточия;
- пробел;
- скобки;
- запятые;
- точки;
- многоточия и прочее.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Теория:
1 Кб = 1024 байта
Переведите 2 Мб в Кб, байты, биты.
2 Мб * 1024 Кб = 2048 Кб
2 Мб * 1024 Кб * 1024 байт = 2097152 байт
2 Мб * 1024 Кб * 1024 байт * 8 бит = бит
2 Мб * 1024 Кб = 2048 Кб
2048 Кб * 1024 байт = 2097152 байт
2097152 байт * 8 бит = бит
Переведите бит в Мб, Кб, байты
бит : 8 бит = 3407872 байта
бит : 8 бит : 1024 байта = 3328 Кб
бит : 8 бит : 1024 байта : 1024 Кб = 3,25 Мб
бит :8 бит = 3407872 байта
3407872 байта : 1024 байта = 3328 Кб
3328 Кб : 1024 Кб = 3,25 Мб
Примеры расчёта мощности

«Однажды, в студеную зимнюю пору,
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54.
Представьте себе, что текст к вам поступает последовательно, по одному знаку, словно бумажная ленточка, выползающая из телеграфного аппарата. Предположим, что каждый появляющийся на ленте символ с одинаковой вероятностью может быть любым символом алфавита. В действительности это не совсем так, но для упрощения примем такое предположение. В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле N = 2 I (см. содержательный подход) каждый такой символ несет I бит информации, которое можно определить из решения уравнения: 2 I = 54. Получаем: I = 5.755 бит - такое количество информации несет один символ в русском тексте.
Чтобы найти количество информации во всем тексте, нужно посчитать число символов в нем и умножить на I.
Посчитаем количество информации на одной странице книги. Пусть страница содержит 50 строк. В каждой строке — 60 символов. Значит, на странице умещается 50x60=3000 знаков. Тогда объем информации будет равен: 5,755 х 3000 = 17265 бит.
При алфавитном подходе к измерению информации количество информации зависит не от содержания, а от размера текста и мощности алфавита.
Таким образом, алфавитный подход к измерению информации можно изобразить в виде схемы:
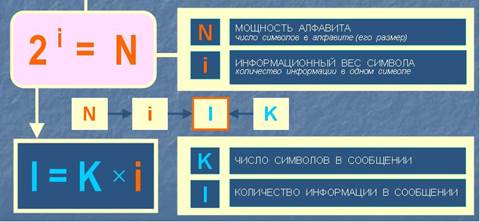
При использовании двоичной системы (алфавит состоит из двух знаков: 0 и 1) каждый двоичный знак несет 1 бит информации.
Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода.
Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 2 4 = 16. А если N =32, то один символ «весит» 5 бит.
Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.
Поскольку 256 = 2 8 , то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название - байт.
Для измерения больших объемов информации используются следующие единицы:
1 Кб (один килобайт)= 1024 байт=2 10 байт
1 Мб (один мегабайт)= 1024 Кб=2 10 Кбайт=2 20 байт
1 Гб (один гигабайт)= 1024 Мб=2 10 Mбайт=2 30 байт
1Тбайт (один терабайт)= 1024Гбайт =2 10 Гбайт=2 40 байт
1Пбайт(один петабайт)= 1024Тбайт= 2 10 Тбайт=2 50 байт
1Эбайт(один эксабайт)= 1024Пбайт =2 10 Пбайт=2 60 байт
1Збайт(один зеттабайт)= 1024Эбайт = 2 10 Эбайт=2 70 байт
1Йбайт(один йоттабайт)= 1024Збайт=2 10 Збайт=2 80 байт.
Таблица кодов ASCII
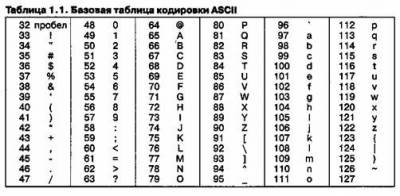
Национальные стандарты кодировочных таблиц включают международную часть кодовой таблицы без изменений, а во второй содержат коды национальных алфавитов, символы псевдографики и некоторые математические знаки. В настоящее время существует 5 различных кодировок кириллицы (КОИ8, Windows. MSDOS, Macintosh, ISO), что вызывает определенные трудности при работе с русскоязычными документами.
В конце 90-х годов появился новый международный стандарт Unicode, который отводит под 1 символ не один байт, а два, поэтому с его помощью можно закодировать 65536 различных символов. Он включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.

Информация.
Примеры расчёта мощности

«Однажды, в студеную зимнюю пору,
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
Учитель физики, информатики и вычислительной техники. Победитель конкурса лучших учителей Российской Федерации в рамках Приоритетного Национального Проекта "Образование".
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:
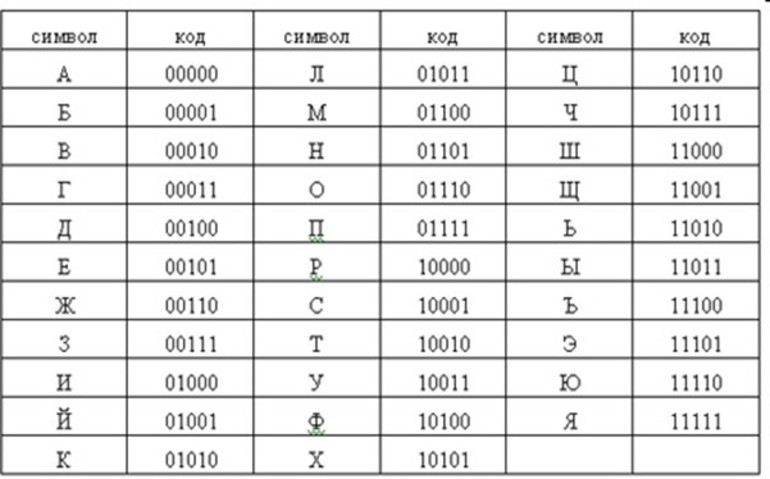
Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
- 1 — 000;
- 2 — 001;
- 3 — 010;
- 4 — 011;
- 5 — 100;
- 6 — 101;
- 7 — 110;
- 8 — 111.
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Вычисление мощности алфавита

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Заполняем пробелы – расширяем горизонты!
Для измерения длины есть такие единицы, как миллиметр, сантиметр, метр, километр. Известно, что масса измеряется в граммах, килограммах, центнерах и тоннах. Бег времени выражается в секундах, минутах, часах, днях, месяцах, годах, веках. Компьютер работает с информацией и для измерения ее объема также имеются соответствующие единицы измерения.
Мы уже знаем, что компьютер воспринимает всю информацию через нули и единички.

Бит – это минимальная единица измерения информации, соответствующая одной двоичной цифре («0» или «1»).
Байт состоит из восьми бит. Используя один байт, можно закодировать один символ из 256 возможных (256 = 2 8 ). Таким образом, один байт равен одному символу, то есть 8 битам:
1 символ = 8 битам = 1 байту.
Буква, цифра, знак препинания – это символы. Одна буква – один символ. Одна цифра – тоже один символ. Один знак препинания (либо точка, либо запятая, либо вопросительный знак и т.п.) – снова один символ. Один пробел также является одним символом.
Изучение компьютерной грамотности предполагает рассмотрение и других, более крупных единиц измерения информации.
Теория:
где i – количество информации в бит, N – количество символов, количество событий
Символом является и знак препинания, и цифра, и специальные знаки. И пробел!
Какое количество информации будет содержаться на странице печатного текста при использовании 32-х символьного алфавита (на странице 60 строк по 56 символов).
Количество символов на странице = 60 строк * 56 символов = 3360 символов
По условию используется 32-х символьный алфавит (т. е. мощность алфавита = 32 символа).
Тогда , отсюда i = 5 бит. Такое количество информации приходится на 1 символ 32-х символьного алфавита.
Количество информации, содержащееся на странице = 3360 символов * 5 бит = 16800 бит
Переводим в байты: 16800 бит : 8 бит = 2100 байт
Переводим в Кб 2100 байт : 1024 байт = 2,05 Кб
общее количество символов на одной странице
количество бит информации, приходящейся на один символ
I
(количество информации)
Единицы измерения информации правой и левой части должны быть одинаковыми.
Какое количество символов содержится на странице энциклопедического словаря, если в памяти компьютера эта страница занимает 13 Кб?
По умолчанию количество бит информации, приходящейся на один символ, равно 8 бит.
Переведем 13 Кб в биты:
13 Кб * 1024 байт * 8 бит = 106496 бит
Используя данные предыдущей задачи и зная, что в одной строке находится 85 знаков, определить количество строк на странице.
Общее число символов на странице (по предыдущей задаче) = 13312 символов
Общее число символов 13312 символов
Количество символов в одной строке 85 знаков
Сколько бит содержится в слове ИНФОРМАЦИЯ?
Т. к. по умолчанию количество бит информации, приходящейся на 1 символ = 8 бит
(256-символьный алфавит, , i=8 бит), а в предлагаемом слове 10 букв, то количество бит, содержащихся в слове =
10 букв * 8 бит = 80 бит = 10 байт
В каком алфавите одна буква несет в себе больше информации, в русском или латинском? Примечание: в русском языке 33 буквы, в латинском – 26 букв.
Русский язык: , i = 6 бит (i не должно быть меньше 6, т. к., а у нас 33 буквы
Латинский язык: , i = 5 бит.
Количество бит информации одного символа русского языка больше на 1, чем в латинском языке.
Описание термина
Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

- числа;
- спецсимволы;
- двоеточия;
- пробел;
- скобки;
- запятые;
- точки;
- многоточия и прочее.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:

Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
- 1 — 000;
- 2 — 001;
- 3 — 010;
- 4 — 011;
- 5 — 100;
- 6 — 101;
- 7 — 110;
- 8 — 111.
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Таблица байтов:
1 Кб (1 Килобайт) = 2 10 байт = 2*2*2*2*2*2*2*2*2*2 байт =
= 1024 байт (примерно 1 тысяча байт – 10 3 байт)
1 Мб (1 Мегабайт) = 2 20 байт = 1024 килобайт (примерно 1 миллион байт – 10 6 байт)
1 Гб (1 Гигабайт) = 2 30 байт = 1024 мегабайт (примерно 1 миллиард байт – 10 9 байт)
1 Тб (1 Терабайт) = 2 40 байт = 1024 гигабайт (примерно 10 12 байт). Терабайт иногда называют тонна.
1 Пб (1 Петабайт) = 2 50 байт = 1024 терабайт (примерно 10 15 байт).
1 Эксабайт = 2 60 байт = 1024 петабайт (примерно 10 18 байт).
1 Зеттабайт = 2 70 байт = 1024 эксабайт (примерно 10 21 байт).
1 Йоттабайт = 2 80 байт = 1024 зеттабайт (примерно 10 24 байт).
В приведенной выше таблице степени двойки (2 10 , 2 20 , 2 30 и т.д.) являются точными значениями килобайт, мегабайт, гигабайт. А вот степени числа 10 (точнее, 10 3 , 10 6 , 10 9 и т.п.) будут уже приблизительными значениями, округленными в сторону уменьшения. Таким образом, 2 10 = 1024 байта представляет точное значение килобайта, а 10 3 = 1000 байт является приблизительным значением килобайта.
Такое приближение (или округление) вполне допустимо и является общепринятым.
Ниже приводится таблица байтов с английскими сокращениями (в левой колонке):
10 3 b = 10*10*10 b= 1000 b – килобайт
10 6 b = 10*10*10*10*10*10 b = 1 000 000 b – мегабайт
10 9 b – гигабайт
10 12 b – терабайт
10 15 b – петабайт
10 18 b – эксабайт
10 21 b – зеттабайт
10 24 b – йоттабайт
Выше в правой колонке приведены так называемые «десятичные приставки», которые используются не только с байтами, но и в других областях человеческой деятельности. Например, приставка «кило» в слове «килобайт» означает тысячу байт, также как в случае с километром она соответствует тысяче метров, а в примере с килограммом она равна тысяче грамм.
Теория:
По умолчанию (если в задаче не указано специально) при решении задачи указывается 256-символьный алфавит – таблица ASCII (мощность алфавита = 256 символов). Значит, на один символ (букву, цифру, знак, знак препинания, пробел) приходится 8 бит информации или 1 байт.
Определить количество информации, которое содержится на печатном листе бумаги (двусторонняя печать), если на одной стороне умещается 40 строк по 67 символов в строке.
Определим количество символов на одной стороне листа:
40 строк * 67 символов = 2680 символов
Определим количество символов на 2-х сторонах листа:
2680 символов * 2 = 5360 символов
Количество информации = 5360 символов * 1 байт = 5360 байт
Переводим в Кб: 5360 байт : 1024 байт = 5,23 Кб
Если бы необходимо было получить ответ в бит, то
Количество информации = 5360 символов * 8 бит = 42880 бит
Переводим в байты 42880 бит : 8 бит = 5360 байт
Переводим в Кб 5360 байт : 1024 байт = 5,23 Кб
Читайте также: