
Чем открыть большой csv файл
CSV является стандартом де-факто для связи между собой разнородных систем, для передачи и обработки объемных данных с «жесткой», табличной структурой. Во многих скриптовых языках программирования есть встроенные средства разбора и генерации, он хорошо понятен как программистам, так и рядовым пользователям, а проблемы с самими данными в нем хорошо обнаруживаются, как говорится, на глаз.
История этого формата насчитывает не менее 30 лет. Но даже сейчас, в эпоху повального использования XML, для выгрузки и загрузки больших объемов данных по-прежнему используют CSV. И, несмотря на то, что сам формат довольно неплохо описан в RFC, каждый его понимает по-своему.
В этой статье я попробую обобщить существующие знания об этом формате, указать на типичные ошибки, а также проиллюстрировать описанные проблемы на примере кривой реализации импорта-экспорта в Microsoft Office 2007. Также покажу, как обходить эти проблемы (в т.ч. автоматическое преобразование типов Excel-ом в DATETIME и NUMBER) при открытии .csv.
Начнем с того, что форматом CSV на самом деле называют три разных текстовых формата, отличающихся символами-разделителями: собственно сам CSV (comma-separated values — значения, разделенные запятыми), TSV (tab-separated values — значения, разделенные табуляциями) и SCSV (semicolon separated values — значения, разделенные точкой с запятой). В жизни все три могут называться одним CSV, символ-разделитель в лучшем случае выбирается при экспорте или импорте, а чаще его просто «зашивают» внутрь кода. Это создает массу проблем в попытке разобраться.
Как иллюстрацию возьмем казалось бы тривиальную задачу: импортировать в Microsoft Outlook данные из таблицы в Microsoft Excel.
В Microsoft Excel есть средства экспорта в CSV, а в Microsoft Outlook — соответствующие средства импорта. Что могло быть проще — сделал файлик, «скормил» почтовой программе и — дело сделано? Как бы не так.
Создадим в Excel тестовую табличку:

… и попробуем экспортировать ее в три текстовых формата:
| «Текст Unicode» | Кодировка — UTF-16, разделители — табуляция, переводы строк — 0×0D, 0×0A, объем файла — 222 байт |
| «CSV (разделители — запятые)» | Кодировка — Windows-1251, разделители — точка с запятой (не запятая!), во второй строке значение телефонов не взято в кавычки, несмотря на запятую, зато взято в кавычки значение «01;02», что правильно. Переводы строк — 0×0D, 0×0A. Объем файла — 110 байт |
| «Текстовые файлы (с разделителями табуляции)» | Кодировка — Windows-1251, разделители — табуляция, переводы строк — 0×0D, 0×0A. Значение «01;02» помещено в кавычки (без особой нужды). Объем файла — 110 байт |
Какой вывод мы делаем из этого. То, что здесь Microsoft называет «CSV (разделители — запятые)», на самом деле является форматом с разделителями «точка с запятой». Формат у Microsoft — строго Windows-1251. Поэтому, если у вас в Excel есть Unicode-символы, они на выходе в CSV отобразятся в вопросительные знаки. Также то, что переводами строк является всегда пара символов, то, что Microsoft тупо берет в кавычки все, где видит точку с запятой. Также то, что если у вас нет Unicode-символов вообще, то можно сэкономить на объеме файла. Также то, что Unicode поддерживается только UTF-16, а не UTF-8, что было бы сильно логичнее.
Теперь посмотрим, как на это смотрит Outlook. Попробуем импортировать эти файлы из него, указав такие же источники данных. Outlook 2007: Файл -> Импорт и экспорт… -> Импорт из другой программы или файла. Далее выбираем формат данных: «Значения, разделенные запятыми (Windows)» и «Значения, разделенные табуляцией (Windows)».
| «Значения, разделенные табуляцией(Windows)» | Скармливаем аутлуку файл tsv, с разделенными табуляцией значениями и. — чтобы вы думали. Outlook склеивает поля и табуляцию не замечает. Заменяем в файле табуляцию на запятые и, как видим, поля уже разбирает, молодец. |
| «Значения, разделенные запятыми (Windows)» | А вот аутлук как раз понимает все верно. Comma — это запятая. Поэтому ожидает в качестве разделителя запятую. А у нас после экселя — точка с запятой. В итоге аутлук распознает все неверно. |
Два майкрософтовских продукта не понимают друг друга, у них напрочь отсутствует возможность передать через текстовый файл структурированные данные. Для того, чтобы все заработало, требуются «пляски с бубном» программиста.
Мы помним, что Microsoft Excel умеет работать с текстовыми файлами, импортировать данные из CSV, но в версии 2007 он делает это очень странно. Например, если просто открыть файл через меню, то он откроется без какого-либо распознавания формата, просто как текстовый файл, целиком помещенный в первую колонку. В случае, если сделать дабл-клик на CSV, Excel получает другую команду и импортирует CSV как надо, не задавая лишних вопросов. Третий вариант — вставка файла на текущий лист. В этом интерфейсе можно настраивать разделители, сразу же смотреть, что получилось. Но одно но: работает это плохо. Например, Excel при этом не понимает закавыченных переводов строк внутри полей.
Более того, одна и та же функция сохранения в CSV, вызванная через интерфейс и через макрос, работает по-разному. Вариант с макросом не смотрит в региональные настройки вообще.
Стандарта CSV как такового, к сожалению, нет, но, между тем, существует т.н. memo. Это RFC 4180 года, в котором описано все довольно толково. За неимением ничего большего, правильно придерживаться хотя бы RFC. Но для совместимости с Excel следует учесть его собенности.
Вот краткая выжимка рекомендаций RFC 4180 и мои комментарии в квадратных скобках:
- между строками — перевод строки CRLF [на мой взгляд, им не стоило ограничивать двумя байтами, т.е. как CRLF (0×0D, 0×0A), так и CR 0×0D]
- разделители — запятые, в конце строки не должно быть запятой,
- в последней строке CRLF не обязателен,
- первая строка может быть строкой заголовка (никак не помечается при этом)
- пробелы, окружающие запятую-разделитель, игнорируются.
- если значение содержит в себе CRLF, CR, LF (символы-разделители строк), двойную кавычку или запятую (символ-разделитель полей), то заключение значения в кавычки обязательно. В противном случае — допустимо.
- т.е. допустимы переводы строк внутри поля. Но такие значения полей должны быть обязательно закавычены,
- если внутри закавыченной части встречаются двойные кавычки, то используется специфический квотинг кавычек в CSV — их дублирование.
Вот в нотации ABNF описание формата:
Также при реализации формата нужно помнить, что поскольку здесь нет указателей на число и тип колонок, поскольку нет требования обязательно размещать заголовок, здесь есть условности, о которых необходимо не забывать:
- строковое значение из цифр, не заключенное в кавычки может быть воспринято программой как числовое, из-за чего может быть потеряна информация, например, лидирующие нули,
- количество значений в каждой строке может отличаться и необходимо правильно обрабатывать эту ситуацию. В одних ситуациях нужно предупредить пользователя, в других — создавать дополнительные колонки и заполнять их пустыми значениями. Можно определиться, что количество колонок задается заголовком, а можно добавлять их динамически, по мере импорта CSV,
- Квотить кавычки через «слэш» не по стандарту, делать так не надо.
- Поскольку типизации полей нет, нет и требования к ним. Разделители целой и дробной частей в разных странах разные, и это приводит к тому, что один и тот же CSV, сгенрированный приложением, в одном экселе «понимается», в другом — нет. Потому что Microsoft Office ориентируется на региональные настройки Windows, а там может быть что угодно. В России там указано, что разделитель — запятая,
- Если CSV открывать не через меню «Данные», а напрямую, то Excel лишних вопросов не задает, и делает как ему кажется правильным. Например, поле со значением 1.24 он понимает по умолчанию как «24 января»
- Эксель убивает ведующие нули и приводит типы даже тогда, когда значение указано в кавычках. Делать так не надо, это ошибка. Но чтобы обойти эту проблему экселя, можно сделать небольшой «хак» — значение начать со знака «равно», после чего поставить в кавычках то, что необходимо передать без изменения формата.
- У экселя есть спецсимвол «равно», который в CSV рассматривается как идентификатор формулы. То есть, если в CSV встретится =2+3, он сложит два и три и результат впишет в ячейку. По стандарту он это делать не должен.
Пример валидного CSV, который можно использовать для тестов:
точно такой же SCSV:
Первый файлик, который реально COMMA-SEPARATED, будучи сохраненным в .csv, Excel-ом не воспринимается вообще.

Второй файлик, который по логике SCSV, экселом воспринимается и выходит вот что:

- Учлись пробелы, окружающие разделители
- Последний столбец вообще толком не распознался, несмотря на то, что данные в кавычках. Исключение составляет строка с «Петровым» — там корректно распозналось 1,24.
- В поле индекс Excel «опустил» ведущие нули.
- в самом правом поле последней строки пробелы перед кавычками перестали указывать на спецсимвол
Если же воспользоваться функционалом импорта (Данные -> Из файла) и обозвать при импорте все поля текстовыми, то будет следующая картина:

С приведением типов сработало, но зато теперь не обрабатываются нормально переводы строк и осталась проблема с ведущими нулями, кавычками и лишними пробелами. Да и пользователям так открывать CSV крайне неудобно.
Есть эффективный способ, как заставить Excel не приводить типы, когда это нам не нужно. Но это будет CSV «специально для Excel». Делается это помещением знака «=» перед кавычками везде, где потенциально может возникнуть проблема с типами. Заодно убираем лишние пробелы.
И вот что случаеся, если мы открываем этот файлик в экселе:
MS Excel может отображать 1 048 576 строк. Хотя при нормальном использовании это может показаться действительно большим числом, существует множество сценариев, в которых этого недостаточно.
При просмотре файлов журналов или больших наборов данных легко найти CSV-файлы с миллионами строк или огромными текстовыми файлами. Поскольку Excel не поддерживает файлы такого размера, как именно их открыть? Давайте разберемся.

Метод №1: Использование бесплатных редакторов
Лучший способ просматривать очень большие текстовые файлы — использовать текстовый редактор. Не просто текстовый редактор, а инструменты, предназначенные для написания кода. Такие приложения обычно могут без проблем обрабатывать большие файлы и бесплатны.
Средство просмотра больших текстовых файлов вероятно, самое простое из этих приложений. Он действительно прост в использовании, работает быстро и требует очень мало ресурсов. Единственный недостаток? Он не может редактировать файлы. Но если вы хотите просматривать только большие CSV-файлы, это лучший инструмент для работы.
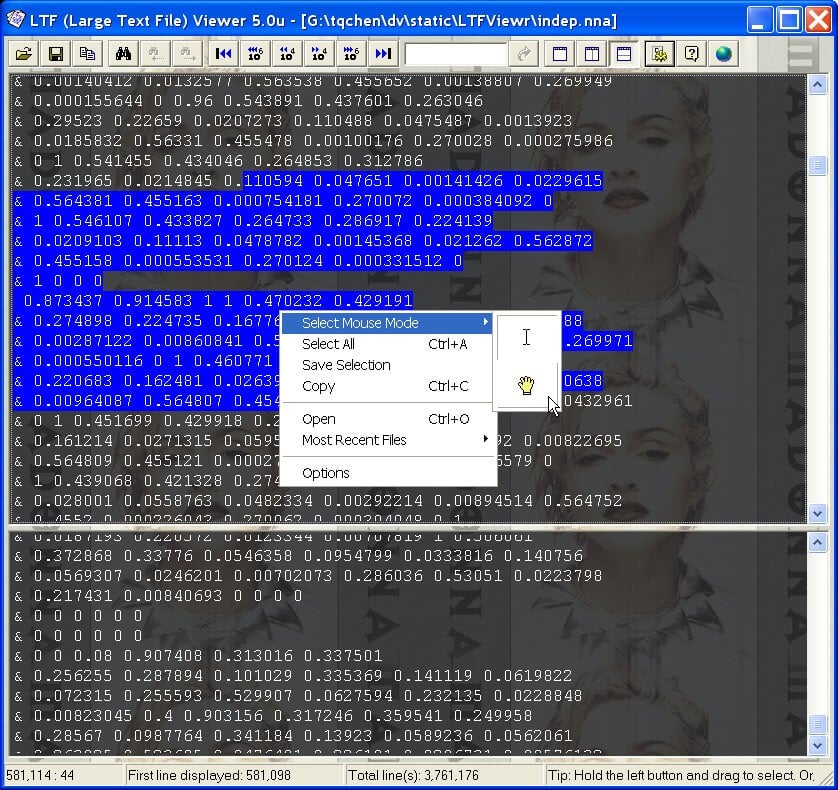
Для редактирования больших текстовых файлов вам следует попробовать Emacs. Первоначально созданный для систем Unix, он также отлично работает в Windows и может обрабатывать большие файлы. Сходным образом, Неовим а также Возвышенный текст — это две легкие IDE, которые можно использовать для открытия текстовых файлов CSV размером с гигабайт.
Если все, что вам нужно, это поиск данных в больших файлах журнала, тогда клогг это просто инструмент для вас. Обновленная вилка популярного Glogg, это приложение позволяет с легкостью выполнять сложные операции поиска в огромных текстовых файлах. Поскольку файлы журналов, сгенерированные компьютером, часто могут содержать миллионы строк, журнал предназначен для беспроблемной работы с файлами такого размера.

Вся проблема при попытке открыть большие CSV-файлы в том, что они слишком большие. Но что, если бы вы разбили их на несколько файлов меньшего размера?
Это популярное решение, поскольку обычно не требует изучения интерфейса нового текстового редактора. Вместо этого вы можете использовать один из многих разделителей CSV, доступных в Интернете чтобы разбить большой файл на несколько легко открываемых файлов. После этого можно будет получить доступ к каждому из этих файлов в обычном режиме.
Однако это не лучший способ сделать это. Разделение большого файла часто может приводить к странным опечаткам или неправильно настроенным файлам. Более того, открытие каждого фрагмента по отдельности предотвращает фильтрацию всех данных сразу.
Метод № 3: Импорт в базу данных
Текстовые и CSV-файлы размером до нескольких гигабайт обычно представляют собой большие наборы данных. Так почему бы просто не импортировать их в базу данных?
SQL — наиболее распространенный язык разметки баз данных в наши дни. Есть много версий SQL в использовании, но, вероятно, самым простым из них является MySQL. И как назло, можно преобразовать файл CSV в таблицу MySQL.

Это ни в коем случае не самый простой метод работы с большими CSV-файлами, поэтому мы рекомендуем его только в том случае, если вы хотите иметь дело с большими наборами данных на регулярной основе. Если MySQL кажется слишком сложным, вы всегда можете импортировать файлы .csv в MS доступ вместо.
Когда вы работаете с файлом .csv с миллионами строк данных, вы, очевидно, не сможете понять его вручную. Вероятно, вы захотите отфильтровать данные и выполнить определенные запросы, чтобы понять тенденции.

Так почему не написать код Python сделать именно это?
Опять же, это не самый удобный метод. В то время как Python — не самый сложный язык программирования для изучения, это кодирование, поэтому он может быть не лучшим подходом для вас. Тем не менее, если вам приходится ежедневно анализировать действительно большие файлы CSV, вы можете захотеть автоматизировать задачу с помощью некоторого кода Python.
Текстовые редакторы, которые мы видели в первом методе, не были специальными инструментами, предназначенными для обработки CSV. Это были инструменты общего назначения, которые можно было использовать также для работы с большими CSV-файлами.
А как насчет специализированных приложений? Нет ли приложений, созданных для решения этой проблемы?
На самом деле есть. CSV Explorer, например, основывается на самом процессе, который мы описали в двух последних методах (база данных SQL и код Python), для создания приложения, способного просматривать и редактировать файлы CSV любого размера. Вы можете делать все, что ожидаете от инструмента для работы с электронными таблицами, например создавать графики или фильтровать данные в CSV Explorer.
Другой вариант — UltraEdit. В отличие от предыдущего инструмента, это предназначено не только для файлов .csv, но и для любого типа текстового файла. Он может легко обрабатывать текстовые и CSV-файлы размером до нескольких гигабайт с интерфейсом, аналогичным многим бесплатным редакторам, которые мы обсуждали ранее.
Единственным недостатком этих инструментов является то, что они являются приложениями премиум-класса, и для их использования требуется платная лицензия. Вы всегда можете опробовать их бесплатные пробные версии, чтобы проверить их функции, или если вы используете их только один раз.
Почему обычные текстовые редакторы не могут открывать действительно большие файлы?
На компьютере есть гигабайты памяти, так почему же текстовые редакторы не могут открывать большие файлы?
Здесь играют роль два фактора. Некоторые приложения имеют жестко запрограммированное ограничение на количество отображаемых данных. Неважно, сколько памяти у вашего ПК, они просто не будут ее использовать.
Вторая проблема — оперативная память. Многие текстовые редакторы не имеют жесткого ограничения на количество строк, но не могут отображать большие файлы из-за ограничений памяти. Они загружают весь файл в систему RAM, поэтому, если этой памяти недостаточно, процесс завершается ошибкой.
Как Excel портит данные: из классики
Все бы ничего, но Excel, едва открыв CSV-файл, начинает свои лукавые выкрутасы. Он без спроса меняет данные так, что те приходят в негодность. Причем делает это совершенно незаметно. Из-за этого в свое время мы схватили ворох проблем.
Большинство казусов связано с тем, что программа без спроса преобразует строки с набором цифр в числа.
Округляет. Например, в исходной ячейке два телефона хранятся через запятую без пробелов: «5235834,5235835». Что сделает Excel? Лихо превратит номера́ в одно число и округлит до двух цифр после запятой: «5235834,52». Так мы потеряем второй телефон.
Приводит к экспоненциальной форме. Excel заботливо преобразует «123456789012345» в число «1,2E+15». Исходное значение потеряем напрочь.
Проблема актуальна для длинных, символов по пятнадцать, цифровых строк. Например, КЛАДР-кодов (это такой государственный идентификатор адресного объекта: го́рода, у́лицы, до́ма).
Потеря плюса критична, например, если данные пойдут в стороннюю систему, а та при импорте жестко проверяет формат.
Разбивает по три цифры. Цифровую строку длиннее трех символов Excel, добрая душа, аккуратно разберет. Например, «8 495 5235834» превратит в «84 955 235 834».
Форматирование важно как минимум для телефонных номеров: пробелы отделяют коды страны и города от остального номера и друг от друга. Excel запросто нарушает правильное членение телефона.
Удаляет лидирующие нули. Строку «00523446» Excel превратит в «523446».
А в ИНН, например, первые две цифры — это код региона. Для Республики Алтай он начинается с нуля — «04». Без нуля смысл номера исказится, а проверку формата ИНН вообще не пройдет.
Меняет даты под локальные настройки. Excel с удовольствием исправит номер дома «1/2» на «01.фев». Потому что Windows подсказал, что в таком виде вам удобнее считывать даты.
Открытие набора данных, превышаго ограничения Excel на сетку
С помощью Excel для ПК можно импортировать файл с помощью средства "Получить данные", чтобы загрузить все данные. Данные будут отображаться не больше, чем количество строк и столбцов в Excel, однако полный набор данных уже создан, и вы сможете анализировать его без потери данных.
Откройте пустую книгу в Excel.
На вкладке "Данные" > "Из текста/CSV> найдите файл и выберите "Импорт". В диалоговом окне предварительного просмотра выберите "Загрузить в. " > отчета.
После загрузки используйте список полей для у упорядочений полей в pivotTable. Для сведения данных в ней будет работать весь набор данных.
Вы также можете отсортировать данные в pivotTable илиотфильтроватьданные в ее.
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу.
По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
Запускаю встроенный в Excel механизм импорта. В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог. В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, отмечаю «My Data Has Headers».
Перехожу ко второму шагу диалога. Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.
Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».
Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте
После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
1]Разделить CSV

Split CSV — это бесплатный онлайн-инструмент. Бесплатный план этой услуги позволяет разделить CSV на количество файлов (максимальное количество выходных файлов), по размер файла (максимальный размер для каждого выходного файла) и количество строк. Вы также можете предварительный просмотр входного CSV файл перед его разделением. Ограничение размера входного CSV не упоминается, но когда я тестировал эту службу, он легко разделил CSV более 110 МБ.
Этот инструмент позволяет разделить CSV за четыре простых шага. Использовать эта ссылка чтобы открыть его домашнюю страницу, а затем выполните следующие действия:
- Загрузите CSV-файл с компьютера или импортируйте CSV-файл из своей учетной записи Google Диска.
- Это важный шаг. Здесь вам нужно установить количество строк заголовка и выбрать разделение CSV по файлам, строкам или размеру. Используйте параметр и введите значение.
- Добавьте или пропустите столбцы и подтвердите свое действие.
- Укажите адрес электронной почты и используйте Расколоть кнопка.
После этого можно дождаться завершения процесса. Или вы можете получить ссылку для вывода в адресе электронной почты. Его процесс разделения хорош, и вы получите выходные файлы CSV в течение нескольких секунд.
Альтернатива: Open Office Calc
Для работы с CSV-файлами я использую именно Calc. Он не то чтобы совсем не считает цифровые данные строками, но хотя бы не применяет к ним переформатирование в соответствии с региональными настройками Windows. Да и импорт попроще.
Конечно, понадобится пакет Open Office (OO). При установке он предложит переназначить на себя файлы MS Office. Не рекомендую: хоть OO достаточно функционален, он не до конца понимает хитрое микрософтовское форматирование документов.
А вот назначить OO программой по умолчанию для CSV-файлов — вполне разумно. Сделать это можно после установки пакета.
Итак, запускаем импорт данных из CSV. После двойного клика на файле Open Office показывает диалог.

Заметьте, в OO не нужно создавать новый воркбук и принудительно запускать импорт, все само
- Кодировка — как в файле.
- «Разделитель» — точка с запятой. Естественно, если в файле разделителем выступает именно она.
- «Разделитель текста» — пустой (все то же, что в Excel).
- В разделе «Поля» кликаю в левый-верхний квадрат таблицы, подсвечиваются все колонки. Указываю тип «Текст».
Помимо Calc у нас в HFLabs популярен libreOffice, особенно под «Линуксом». И то, и другое для CSV применяют активнее, чем Excel.
Онлайн-инструменты и программное обеспечение для разделения CSV-файлов.
Мы добавили 2 онлайн-инструмента для разделения CSV и 3 бесплатных программы для разделить большой CSV. Это:
- Разделить CSV
- Разделитель текстовых файлов
- LargeFileSplitter
- Сплиттер CSV
- CSV Splitter.
4]CSV Splitter

Инструмент CSV Splitter имеет очень простой интерфейс. Он позволяет разбивать большой CSV-файл по строкам. Вы можете определить количество строк в выходном файле и соответственно разделяет входной CSV. Он также позволяет вам установить первую строку в качестве заголовка столбца для выходного файла. Также есть возможность просмотреть индекс строки для входного CSV и включить заголовок во все выходные файлы.
Скачайте zip-файл этого инструмента разделения CSV с открытым исходным кодом, извлеките его и выполните CSVSplitter.exe. Когда его интерфейс открыт, укажите пути для входных и выходных CSV-файлов, используя доступные Просматривать кнопки. Теперь введите количество строк в пакете или выходных файлах, установите другие параметры и используйте Выполнять кнопка. После завершения процесса разделения вы получите файлы CSV в заданную вами папку.
Что такое CSV-файлы
Формат CSV используют, чтобы хранить таблицы в текстовых файлах. Данные очень часто упаковывают именно в таблицы, поэтому CSV-файлы очень популярны.

CSV-файл состоит из строк с данными и разделителей, которые обозначают границы столбцов
CSV расшифровывается как comma-separated values — «значения, разделенные запятыми». Но пусть название вас не обманет: разделителями столбцов в CSV-файле могут служить и точки с запятой, и знаки табуляции. Это все равно будет CSV-файл.
У CSV куча плюсов перед тем же форматом Excel: текстовые файлы просты как пуговица, открываются быстро, читаются на любом устройстве и в любой среде без дополнительных инструментов.
Из-за своих преимуществ CSV — сверхпопулярный формат обмена данными, хотя ему уже лет 40. CSV используют прикладные промышленные программы, в него выгружают данные из баз.
Одна беда — текстового редактора для работы с CSV мало. Еще ничего, если таблица простая: в первом поле ID одной длины, во втором дата одного формата, а в третьем какой-нибудь адрес. Но когда поля разной длины и их больше трех, начинаются мучения.

Следить за разделителями и столбцами — глаза сломаешь
Еще хуже с анализом данных — попробуй «Блокнотом» хотя бы сложить все числа в столбце. Я уж не говорю о красивых графиках.
Поэтому CSV-файлы анализируют и редактируют в Excel и аналогах: Open Office, LibreOffice и прочих.
Ветеранам, которые все же дочитали: ребята, мы знаем об анализе непосредственно в БД c помощью SQL, знаем о Tableau и Talend Open Studio. Это статья для начинающих, а на базовом уровне и небольшом объеме данных Excel с аналогами хватает.
Бонус-трек: проблемы при сохранении из Calc в .xlsx
Если сохраняете данные из Calc в экселевский формат .xlsx, имейте в виду — OO порой необъяснимо и масштабно теряет данные.
Белая пустошь, раскинувшаяся посередине, в оригинальном CSV-файле богато заполнена данными
Поэтому после сохранения я еще раз открываю файл и убеждаюсь, что данные на месте.
Если что-то потерялись, лечение — пересохранить из CSV в .xlsx. Или, если установлен Windows, импортнуть из CSV в Excel и сохранить оттуда.
После пересохранения обязательно еще раз проверяю, что все данные на месте и нет лишних пустых строк.
Если интересно работать с данными, посмотрите на наши вакансии. HFLabs почти всегда нужны аналитики, тестировщики, инженеры по внедрению, разработчики. Данными обеспечим так, что мало не покажется :)
Если вы открыли в Excel файл с большим набором данных, например текстовый (TXT) или CSV-файл, возможно, вы увидели предупреждение: "Этот набор данных слишком большой для сеткиExcel. Если вы сохраните эту книгу, вы потеряете данные, которые не были загружены.Это означает, что набор данных превышает количество строк или столбцов, доступных в Excel, поэтому некоторые данные не были загружены.

Чтобы не потерять данные, необходимо соблюдать дополнительные меры предосторожности.
Откройте файл в Excel для ПК,используя get Data (Получить данные). Если у вас есть приложение Excel для ПК, вы можете загрузить полный набор данных и проанализировать его с помощью таблиц с помощью Power Query.
Не сохранения файла в Excel. Если сохранить файл через исходный, вы потеряете все данные, которые не были загружены. Помните, что набор данных также неполный.
Сохранение усеченной копии. Если вам нужно сохранить файл, перейдите в папку >"Сохранить копию". Затем введите другое имя, которое будет ясно, что это усеченная копия исходного файла.
Ограничения форматов файлов Excel
При работе в Excel важно помнить, какой формат файла вы используете. В формате файлов XLS на каждом листе может быть не более 65 536 строк, а в формате XLSX - 1 048 576 строк на листе. Дополнительные сведения см. в форматах файлов, поддерживаемых спецификациями и ограничениями Excel.
Чтобы предотвратить ограничение в Excel, не забудьте использовать для этого формат XLSX вместо XLS. Если вы знаете, что набор данных превышает ограничение XLSX, используйте альтернативные обходные пути для открытия и просмотра всех данных.
Совет: Убедитесь, что при открытие набора данных в Excel были импортироваться все данные. Вы можете проверить количество строк или столбцов в исходных файлах, а затем подтвердить их совпадение в Excel. Для этого вы можете выбрать всю строку или столбец и просмотреть количество в строке состояния в нижней части Excel.
3]LargeFileSplitter

LargeFileSplitter — очень простой и полезный инструмент для разделения файлов CSV и журналов (TXT). Одним из преимуществ является то, что процесс разделения также очень быстр. В течение нескольких секунд очень большой файл CSV можно разделить на части по вашему выбору.
Возьмите этот инструмент и выполнить его. Вы увидите его команду как интерфейс. После этого выполните следующие два шага:
- Перетащите файл CSV на его интерфейс и нажмите клавишу ВВОД.
- Укажите количество деталей (например, 5, 10, 20 и т. д.) для выходных файлов и нажмите ввод.
Начнется обработка. Одна за другой все части создаются как выходные файлы CSV, и эти файлы хранятся в том же месте, где присутствует входной CSV.
2]Разделитель текстовых файлов

TEXT File Splitter — это бесплатный онлайн-инструмент, который разбивать большой текст, файлы журнала, CSVи т.д. В бесплатной версии вы можете добавить максимум 300 МБ CSV-файл, чтобы разделить его на файлы меньшего размера. Также есть возможность использовать разделение символов или разделение строк.
Используйте эту ссылку чтобы открыть свою домашнюю страницу. Нажать на Загрузить файл кнопку, чтобы добавить CSV с вашего ПК. Добавьте число в данное поле, чтобы сгенерировать количество выходных файлов. Нажмите Расколоть! Кнопка. Он обработает ввод, а затем вы сможете загрузить zip-файл, который будет содержать файлы CSV.
Как лучше всего открывать большие текстовые и CSV-файлы?
В наш век больших данных нередко встречаются текстовые файлы размером в гигабайты, которые может быть трудно даже просмотреть с помощью встроенных инструментов, таких как Блокнот или MS Excel. Чтобы иметь возможность открывать такие большие файлы CSV, вам необходимо загрузить и использовать стороннее приложение.
Если все, что вам нужно, — это просматривать такие файлы, то программа просмотра больших текстовых файлов — лучший выбор для вас. Для их фактического редактирования вы можете попробовать многофункциональный текстовый редактор, такой как Emacs, или воспользоваться дополнительным инструментом, например CSV Explorer.
Такие методы, как разделение файла CSV или его импорт в базу данных, включают слишком много шагов. Вам лучше получить платную лицензию на специальный инструмент премиум-класса, если вы обнаружите, что много работаете с огромными текстовыми файлами.
Этот пост поможет вам разделить файлы CSV. Это может пригодиться, когда у вас есть несколько больших файлов CSV, которые невозможно открыть или загрузить полностью из-за достижения максимального количества столбцов и строк в Microsoft Excel или какой-либо программе просмотра CSV. В таком случае вы можете разделить содержимое огромного CSV на небольшие файлы, а затем открыть эти файлы с помощью любого совместимого инструмента.
Есть некоторые бесплатное программное обеспечение для разделения файлов CSV и доступные онлайн-инструменты, которые можно использовать для разделения файлов CSV. Этот пост охватывает список таких инструментов.
5]CSV Splitter

Он имеет то же имя, что и вышеупомянутый инструмент, но этот CSV Splitter имеет другой интерфейс. Это позволяет вам разбить большой CSV-файл по частям или по строкам. Например, если CSV имеет размер 100 МБ, вы можете определить количество частей. скажи 5 для вывода, а затем он разделит CSV на 5 частей по 20 МБ для каждой части. Или вы можете использовать разделение CSV по строкам, ввести количество строк для каждого вывода, и он будет генерировать файлы CSV в соответствии с количеством строк, установленным вами. Оба варианта хороши, но процесс разделения медленнее.
Эта ссылка поможет вам скачать его портативный EXE. Запустите инструмент и предоставьте входной CSV-файл, используя Искать файлы кнопка. После этого выберите, хотите ли вы разделить CSV по строкам или по частям, а затем введите число в зависимости от выбранного варианта.
Наконец, дайте имя для вывода и нажмите Конвертировать кнопка. Он запустит процесс разделения и создаст папку в том же месте, где находится входной CSV. Все выходные файлы CSV хранятся в этой конкретной папке.
Надеюсь, эти бесплатные инструменты помогут разбить большие CSV-файлы на небольшие CSV-файлы, которые можно будет легко открыть.

Продукты HFLabs в промышленных объемах обрабатывают данные: адреса, ФИО, реквизиты компаний и еще вагон всего. Естественно, тестировщики ежедневно с этими данными имеют дело: обновляют тест-кейсы, изучают результаты очистки. Часто заказчики дают «живую» базу, чтобы тестировщик настроил сервис под нее.
Первое, чему мы учим новых QA — сохранять данные в первозданном виде. Все по заветам: «Не навреди». В статье я расскажу, как аккуратно работать с CSV-файлами в Excel и Open Office. Советы помогут ничего не испортить, сохранить информацию после редактирования и в целом чувствовать себя увереннее.
Материал базовый, профессионалы совершенно точно заскучают.
Читайте также: