
Чем ограничен размер адресуемой памяти
С точки зрения процессора, оперативная память представляет собой массив пронумерованных ячеек. Номер каждой ячейки памяти называется ее адресом. Разрядность адреса является одной из важнейших характеристик процессора и реализуемой им системы команд. Разрядность важна не как самоцель, а потому, что ею обусловлен объем адресуемой памяти – адресного пространства. Системы с 16-разрядным адресом способны адресовать 64 Кбайт (65 536) ячеек памяти, а с 32-разрядным – 4 Гбайт (4 294 967 296) ячеек. В наше время адресуемая память в 4 Гбайт для многих приложений считается неприемлемо маленькой и требуется 64-разрядная адресация.
Процессору обычно приходится совершать арифметические операции над адресами, поэтому разрядность адреса у современных процессоров обычно совпадает с разрядностью основного АЛУ.
У некоторых компьютеров адресация (нумерация) ячеек памяти фиксированная: одна и та же ячейка памяти всегда имеет один и тот же номер. Такая адресация называется физической. Адрес при этом разбит на битовые поля, которые непосредственно используются в качестве номера физической микросхемы памяти, и номеров строки и столбца в этой микросхеме. Напротив, большинство современных процессоров общего назначения используют виртуальную адресацию, когда номер конкретной ячейки памяти определяется не физическим размещением этой ячейки, а контекстом, в котором происходит адресация. Способы реализации виртуальной памяти и необходимость ее применения обсуждаются в Главе 5.
В старых компьютерах размер адресуемой ячейки памяти данных совпадал с разрядностью АЛУ центрального процессора и разрядностью шины данных. Адресуемая ячейка называлась словом. В процессорах манчестерской архитектуры, которые могут использовать одну и ту же память как для команд, так и для данных, оба размера определялись длиной команды. Из-за этого многие процессоры такого типа имели странные по современным представлениям разрядности – 48, 36, иногда даже 25 бит.
БЭСМ-6
Так, БЭСМ-6 имела слово разрядностью 48 бит и команды длиной 24 бита, состоявшие из 15-разрядного адресного поля и 9-разрядного кода операции. Адресное поле позволяло адресовать 32К слов. В одном слове размещалось две команды, при этом команды перехода могли указывать только на первую из упакованных в одно слово команд.
У процессоров гарвардской архитектуры (имеющих раздельные памяти для команд и данных) разрядность АЛУ и размер команды не связаны.
Microchip PIC
Разработчик сервера рекламирует его как основу (или, во всяком случае, как демонстрацию технической возможности) создания Web-интерфейсов для разнообразного бытового оборудования.
Аннотация: Изучение механизмов формирования физического адреса при различной организации логического адресного пространства. Организация памяти микропроцессорной системы один из важнейших компонентов, влияющий на многие параметры ее работы: защиту данных, мультипрограммирование, работу кэш-памяти и т. д. Поэтому изучение принципов построения памяти как на логическом, так и на физическом уровне является одним из ключевых моментов данного курса, и данному вопросу будет уделено достаточно много внимания.
Логическое адресное пространство
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Формирование физического адреса в универсальном микропроцессоре при различных режимах работы
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 2 16 байт .
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
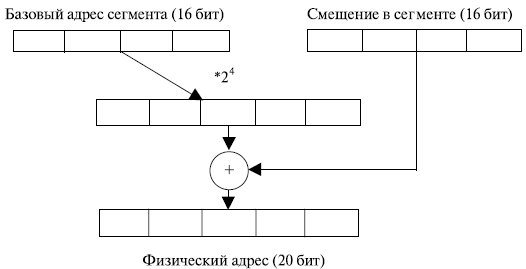
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
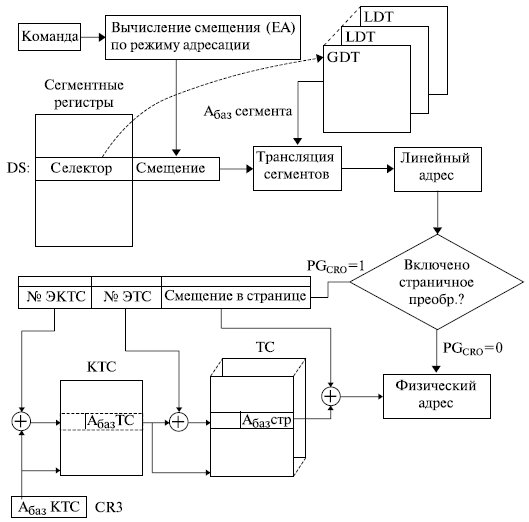
Общая схема формирования физического адреса микропроцессором , работающим в защищенном режиме, представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес . Он состоит из двух частей: селектора и смещения в сегменте.
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной ( GDT ) и локальных ( LDT ) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора , от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора , работающего в защищенном режиме, характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в
Структура дескриптора сегмента представлена на рис. 3.3.
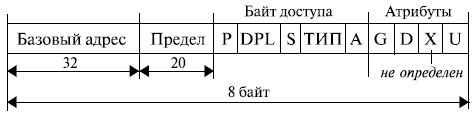
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G ( Granularity - гранулярность , или дробность):

Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0 ). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (при G = l ):

Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности ( Default size ) определяет длину адресов и операндов, используемых в команде по умолчанию:

Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память , как временно отсутствующий, устанавливая в его дескрипторе P = 0 . При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL ( Descriptor Privilege Level ) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора, определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты , к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S ( System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0 , то этот дескриптор описывает специальный системный объект , который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT . Назначение битов байта доступа определяется типом сегмента (рис. 3.4).
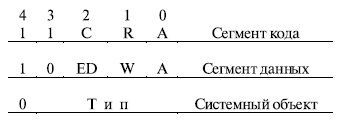
В сегменте кода: бит подчинения, или согласования, C ( Conforming ) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R ( Readable ) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание .
В сегменте данных:
- ED ( Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable) . При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание .
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP .
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти , то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы , а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
Аннотация: В этой лекции рассказывается о функциях основных узлов процессора, о методах адресации операндов и о регистрах процессора.
Основная функция любого процессора, ради которой он и создается, — это выполнение команд. Система команд , выполняемых процессором, представляет собой нечто подобное таблице истинности логических элементов или таблице режимов работы более сложных логических микросхем. То есть она определяет логику работы процессора и его реакцию на те или иные комбинации внешних событий.
Написание программ для микропроцессорной системы — важнейший и часто наиболее трудоемкий этап разработки такой системы. А для создания эффективных программ необходимо иметь хотя бы самое общее представление о системе команд используемого процессора. Самые компактные и быстрые программы и подпрограммы создаются на языке Ассемблер , использование которого без знания системы команд абсолютно невозможно, ведь язык Ассемблер представляет собой символьную запись цифровых кодов машинного языка , кодов команд процессора. Конечно, для разработки программного обеспечения существуют всевозможные программные средства . Пользоваться ими обычно можно и без знания системы команд процессора. Чаще всего применяются языки программирования высокого уровня, такие как Паскаль и Си . Однако знание системы команд и языка Ассемблер позволяет в несколько раз повысить эффективность некоторых наиболее важных частей программного обеспечения любой микропроцессорной системы — от микроконтроллера до персонального компьютера.
Именно поэтому в данной главе мы рассмотрим основные типы команд , имеющиеся у большинства процессоров, и особенности их применения.
Каждая команда , выбираемая (читаемая) из памяти процессором, определяет алгоритм поведения процессора на ближайшие несколько тактов. Код команды говорит о том, какую операцию предстоит выполнить процессору и с какими операндами (то есть кодами данных), где взять исходную информацию для выполнения команды и куда поместить результат (если необходимо). Код команды может занимать от одного до нескольких байт , причем процессор узнает о том, сколько байт команды ему надо читать, из первого прочитанного им байта или слова. В процессоре код команды расшифровывается и преобразуется в набор микроопераций , выполняемых отдельными узлами процессора. Но разработчику микропроцессорных систем это знание не слишком важно, ему важен только результат выполнения той или иной команды.
3.1. Адресация операндов
3.1.1. Методы адресации
Количество методов адресации в различных процессорах может быть от 4 до 16. Рассмотрим несколько типичных методов адресации операндов , используемых сейчас в большинстве микропроцессоров.
Непосредственная адресация (рис. 3.1) предполагает, что операнд (входной) находится в памяти непосредственно за кодом команды. Операнд обычно представляет собой константу, которую надо куда-то переслать, к чему-то прибавить и т.д. Например, команда может состоять в том, чтобы прибавить число 6 к содержимому какого-то внутреннего регистра процессора. Это число 6 будет располагаться в памяти, внутри программы в адресе, следующем за кодом данной команды сложения.
Прямая (она же абсолютная) адресация (рис. 3.2) предполагает, что операнд (входной или выходной) находится в памяти по адресу, код которого находится внутри программы сразу же за кодом команды. Например, команда может состоять в том, чтобы очистить (сделать нулевым) содержимое ячейки памяти с адресом 1000000. Код этого адреса 1000000 будет располагаться в памяти, внутри программы в следующем адресе за кодом данной команды очистки.
Регистровая адресация (рис. 3.3) предполагает, что операнд (входной или выходной) находится во внутреннем регистре процессора. Например, команда может состоять в том, чтобы переслать число из нулевого регистра в первый. Номера обоих регистров (0 и 1) будут определяться кодом команды пересылки .
Косвенно-регистровая (она же косвенная) адресация предполагает, что во внутреннем регистре процессора находится не сам операнд , а его адрес в памяти (рис. 3.4). Например, команда может состоять в том, чтобы очистить ячейку памяти с адресом, находящимся в нулевом регистре. Номер этого регистра (0) будет определяться кодом команды очистки.
Реже встречаются еще два метода адресации .
Автоинкрементная адресация очень близка к косвенной адресации, но отличается от нее тем, что после выполнения команды содержимое используемого регистра увеличивается на единицу или на два. Этот метод адресации очень удобен, например, при последовательной обработке кодов из массива данных, находящегося в памяти. После обработки какого-то кода адрес в регистре будет указывать уже на следующий код из массива. При использовании косвенной адресации в данном случае пришлось бы увеличивать содержимое этого регистра отдельной командой.
Автодекрементная адресация работает похоже на автоинкрементную, но только содержимое выбранного регистра уменьшается на единицу или на два перед выполнением команды. Эта адресация также удобна при обработке массивов данных. Совместное использование автоинкрементной и автодекрементной адресаций позволяет организовать память стекового типа (см. раздел 2.4.2).
Из других распространенных методов адресации можно упомянуть об индексных методах, которые предполагают для вычисления адреса операнда прибавление к содержимому регистра заданной константы (индекса). Код этой константы располагается в памяти непосредственно за кодом команды.
Отметим, что выбор того или иного метода адресации в значительной степени определяет время выполнения команды. Самая быстрая адресация — это регистровая, так как она не требует дополнительных циклов обмена по магистрали. Если же адресация требует обращения к памяти, то время выполнения команды будет увеличиваться за счет длительности необходимых циклов обращения к памяти. Понятно, что чем больше внутренних регистров у процессора, тем чаще и свободнее можно применять регистровую адресацию, и тем быстрее будет работать система в целом.
3.1.2. Сегментирование памяти
Говоря об адресации, нельзя обойти вопрос о сегментировании памяти, применяемой в некоторых процессорах, например в процессорах IBM PC-совместимых персональных компьютеров.
В процессоре Intel 8086 сегментирование памяти организовано следующим образом.
Вся память системы представляется не в виде непрерывного пространства, а в виде нескольких кусков — сегментов заданного размера (по 64 Кбайта), положение которых в пространстве памяти можно изменять программным путем.
Для хранения кодов адресов памяти используются не отдельные регистры, а пары регистров:
- сегментный регистр определяет адрес начала сегмента (то есть положение сегмента в памяти);
- регистр указателя (регистр смещения) определяет положение рабочего адреса внутри сегмента.
При этом физический 20-разрядный адрес памяти, выставляемый на внешнюю шину адреса , образуется так, как показано на рис. 3.5, то есть путем сложения смещения и адреса сегмента со сдвигом на 4 бита. Положение этого адреса в памяти показано на рис. 3.6.
Сегмент может начинаться только на 16-байтной границе памяти (так как адрес начала сегмента, по сути, имеет четыре младших нулевых разряда, как видно из рис. 3.5), то есть с адреса, кратного 16. Эти допустимые границы сегментов называются границами параграфов.
Отметим, что введение сегментирования , прежде всего, связано с тем, что внутренние регистры процессора 16-разрядные, а физический адрес памяти 20-разрядный (16-разрядный адрес позволяет использовать память только в 64 Кбайт, что явно недостаточно). В появившемся в то же время процессоре MC68000 фирмы Motorola внутренние регистры 32-разрядные, поэтому там проблемы сегментирования памяти не возникает.
Применяются и более сложные методы сегментирования памяти. Например, в процессоре Intel 80286 в так называемом защищенном режиме адрес памяти вычисляется в соответствии с рис. 3.7.
В сегментном регистре в данном случае хранится не базовый (начальный) адрес сегментов, а коды селекторов, определяющие адреса в памяти, по которым хранятся дескрипторы (то есть описатели) сегментов. Область памяти с дескрипторами называется таблицей дескрипторов. Каждый дескриптор сегмента содержит базовый адрес сегмента, размер сегмента (от 1 до 64 Кбайт) и его атрибуты. Базовый адрес сегмента имеет разрядность 24 бит, что обеспечивает адресацию 16 Мбайт физической памяти.
Таким образом, на сумматор , вычисляющий физический адрес памяти, подается не содержимое сегментного регистра, как в предыдущем случае, а базовый адрес сегмента из таблицы дескрипторов.
Еще более сложный метод адресации памяти с сегментированием использован в процессоре Intel 80386 и в более поздних моделях процессоров фирмы Intel. Этот метод иллюстрируется рис. 3.8.
Адрес памяти (физический адрес) вычисляется в три этапа. Сначала вычисляется так называемый эффективный адрес (32-разрядный) путем суммирования трех компонентов: базы, индекса и смещения (Base, Index, Displacement ), причем возможно умножение индекса на масштаб (Scale). Эти компоненты имеют следующий смысл:
Затем специальный блок сегментации вычисляет 32-разрядный линейный адрес, который представляет собой сумму базового адреса сегмента из сегментного регистра с эффективным адресом. Наконец, физический 32-битный адрес памяти образуется путем преобразования линейного адреса блоком страничной переадресации, который осуществляет перевод линейного адреса в физический страницами по 4 Кбайта.
В любом случае сегментирование позволяет выделить в памяти один или несколько сегментов для данных и один или несколько сегментов для программ. Переход от одного сегмента к другому сводится всего лишь к изменению содержимого сегментного регистра. Иногда это бывает очень удобно. Но для программиста работать с сегментированной памятью обычно сложнее, чем с непрерывной, несегментированной памятью, так как приходится следить за границами сегментов, за их описанием, переключением и т.д.
3.1.3. Адресация байтов и слов
Многие процессоры, имеющие разрядность 16 или 32, способны адресовать не только целое слово в памяти (16-разрядное или 32-разрядное), но и отдельные байты. Каждому байту в каждом слове при этом отводится свой адрес.
Так, в случае 16-разрядных процессоров все слова в памяти (16-разрядные) имеют четные адреса. А байты, входящие в эти слова, могут иметь как четные адреса, так и нечетные.
Например, пусть 16-разрядная ячейка памяти имеет адрес 23420 , и в ней хранится код 2А5Е (рис. 3.9).
При обращении к целому слову (с содержимым 2А5Е ) процессор выставляет адрес 23420 . При обращении к младшему байту этой ячейки (с содержимым 5Е ) процессор выставляет тот же самый адрес 23420 , но использует команду, адресующую байт, а не слово. При обращении к старшему байту этой же ячейки (с содержимым 2А ) процессор выставляет адрес 23421 и использует команду, адресующую байт. Следующая по порядку 16-разрядная ячейка памяти с содержимым 487F будет иметь адрес 23422 , то есть опять же четный. Ее байты будут иметь адреса 23422 и 23423 .
Для различия байтовых и словных циклов обмена на магистрали в шине управления предусматривается специальный сигнал байтового обмена. Для работы с байтами в систему команд процессора вводятся специальные команды или предусматриваются методы байтовой адресации.
Аннотация: В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств.
Введение
Главная задача компьютерной системы – выполнять программы. Программы вместе с данными, к которым они имеют доступ , в процессе выполнения должны (по крайней мере частично) находиться в оперативной памяти . Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью. Таким образом, память ( storage , memory ) является важнейшим ресурсом, требующим тщательного управления. В недавнем прошлом память была самым дорогим ресурсом.
Часть ОС, которая отвечает за управление памятью , называется менеджером памяти.
Физическая организация памяти компьютера
Запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (главную, оперативную , физическую ) и вторичную (внешнюю) память.
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор извлекает команду из основной памяти , декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения еще к нескольким ячейкам основной памяти . Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания.
Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство , состоящее из последовательности байтов. В отличие от оперативной памяти , она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти .
Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рис. 8.1. Разновидности памяти могут быть объединены в иерархию по убыванию времени доступа, возрастанию цены и увеличению емкости.
Многоуровневую схему используют следующим образом. Информация, которая находится в памяти верхнего уровня, обычно хранится также на уровнях с большими номерами. Если процессор не обнаруживает нужную информацию на i-м уровне, он начинает искать ее на следующих уровнях. Когда нужная информация найдена, она переносится в более быстрые уровни.
Локальность
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно как принцип локальности или локализации обращений.
Свойство локальности (соседние в пространстве и времени объекты характеризуются похожими свойствами) присуще не только функционированию ОС, но и природе вообще. В случае ОС свойство локальности объяснимо, если учесть, как пишутся программы и как хранятся данные, то есть обычно в течение какого-то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных удается разместить в памяти с быстрым доступом. В результате реальное время доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает эффективность использования иерархической схемы. Надо сказать, что описываемая организация вычислительной системы во многом имитирует деятельность человеческого мозга при переработке информации. Действительно, решая конкретную проблему, человек работает с небольшим объемом информации, храня не относящиеся к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации главным образом в основной и внешней памяти компьютера. В некоторых схемах потоки между оперативной и внешней памятью регулируются программистом (см. например, далее оверлейные структуры ), однако это связано с затратами времени программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти , характеризующие реальное расположение данных в физической памяти , называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством .
Логическая память
Аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины , но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти появились в связи с необходимостью обобществления процессами фрагментов программного кода (текстовый редактор, тригонометрические библиотеки и т. д.), без чего каждый процесс должен был хранить в своем адресном пространстве дублирующую информацию. Эти отдельные участки памяти, хранящие информацию, которую система отображает в память нескольких процессов, получили название сегментов . Память, таким образом, перестала быть линейной и превратилась в двумерную. Адрес состоит из двух компонентов: номер сегмента , смещение внутри сегмента . Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом , приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте .
Некоторые сегменты , описывающие адресное пространство процесса, показаны на рис. 8.2. Более подробная информация о типах сегментов имеется в лекции 10.
Большинство современных ОС поддерживают сегментную организацию памяти. В некоторых архитектурах (Intel, например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от адресов, реально существующих в оперативной памяти . В каждом конкретном случае используемые программой адреса могут быть представлены различными способами. Например, адреса в исходных текстах обычно символические. Компилятор связывает эти символические адреса с перемещаемыми адресами (такими, как n байт от начала модуля). Подобный адрес, сгенерированный программой, обычно называют логическим (в системах с виртуальной памятью он часто называется виртуальным) адресом. Совокупность всех логических адресов называется логическим (виртуальным) адресным пространством .
Связывание адресов
Итак логические и физические адресные пространства ни по организации, ни по размеру не соответствуют друг другу. Максимальный размер логического адресного пространства обычно определяется разрядностью процессора (например, 2 32 ) и в современных системах значительно превышает размер физического адресного пространства . Следовательно, процессор и ОС должны быть способны отобразить ссылки в коде программы в реальные физические адреса, соответствующие текущему расположению программы в основной памяти . Такое отображение адресов называют трансляцией (привязкой) адреса или связыванием адресов (см. рис. 8.3).
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент его выполнения. Таким образом, привязка инструкций и данных к памяти в принципе может быть сделана на следующих шагах [Silberschatz, 2002].
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Аппаратное управление памятью
Большинство компьютеров используют большое количество различных запоминающих устройств, таких как: ПЗУ, ОЗУ, жесткие диски, магнитные носители и т.д. Все они представляют собой виды памяти, которые доступны через разные интерфейсы. Два основных интерфейса — это прямая адресация процессором и файловые системы. Прямая адресация подразумевает, что адрес ячейки с данными может быть аргументом инструкций процессора.
Режимы работы процессора x86:
- реальный — прямой доступ к памяти по физическому адресу
- защищенный — использование виртуальной памяти и колец процессора для разграничения доступа к ней
Виртуальная память — это подход к управлению памятью компьютером, который скрывает физическую память (в различных формах, таких как: оперативная память, ПЗУ или жесткие диски) за единым интерфейсом, позволяя создавать программы, которые работают с ними как с единым непрерывным массивом памяти с произвольным доступом.
- поддержка изоляции процессов и защиты памяти путём создания своего собственного виртуального адресного пространства для каждого процесса
- поддержка изоляции области ядра от кода пользовательского режима
- поддержка памяти только для чтения и с запретом на исполненение
- поддержка выгрузки не используемых участков памяти в область подкачки на диске (свопинг)
- поддержка отображённых в память файлов, в том числе загрузочных модулей
- поддержка разделяемой между процессами памяти, в том числе с копированием-при-записи для экономии физических страниц

Виды адресов памяти:
- физический - адрес аппаратной ячейки памяти
- логический - виртуальный адрес, которым оперирует приложение

Кроме того, этот дополнительный уровень позволяет через тот же самый интерфейс обращения к данным по адресу в памяти реализовать другие функции, такие как обращение к данным в файле (через механизм mmap ) и т.д. Наконец, он позволяет обеспечить более гибкое, эффективное и безопасное управление памятью компьютера, чем при использовании физической памяти напрямую.
На аппаратном уровне виртуальная память, как правило, поддерживается специальным устройством — Модулем управления памятью.
Страничная организация памяти
Страничная память — способ организации виртуальной памяти, при котором единицей отображения виртуальных адресов на физические является регион постоянного размера — страница.

При использовании страничной модели вся виртуальная память делится на N страниц таким образом, что часть виртуального адреса интерпретируется как номер страницы, а часть — как смещение внутри страницы. Вся физическая память также разделяется на блоки такого же размера — фреймы. Таким образом в один фрейм может быть загружена одна страница. Свопинг — это выгрузка страницы из памяти на диск (или другой носитель большего объема), который используется тогда, когда все фреймы заняты. При этом под свопинг попадают страницы памяти неактивных на данный момент процессов.


Размер страницы и количество страниц зависит от того, какая часть адреса выделяется на номер страницы, а какая на смещение. К примеру, если в 32-разрядной системе разбить адрес на две равные половины, то количество страниц будет составлять 2^16, т.е. 65536, и размер страницы в байтах будет таким же, т.е. 64 КБ. Если уменьшить количество страниц до 2^12, то в системе будет 4096 страницы по 1МБ, а если увеличить до 2^20, то 1 миллион страниц по 4КБ. Чем больше в системе страниц, тем больше занимает в памяти таблица страниц, соответственно работа процессора с ней замедляется. А поскольку каждое обращение к памяти требует обращения к таблице страниц для трансляции виртуального адреса, такое замедление очень нежелательно. С другой стороны, чем меньше страниц и, соотвественно, чем они больше по объему — тем больше потери памяти, вызванные внутренней фрагментацией страниц, поскольку страница является единицей выделения памяти. В этом заключается диллема оптимизации страничной памяти. Она особенно актуальна при переходе к 64-разрядным архитектурам.
Для оптимизации страничной памяти используются следующие подходы:
- специальный кеш — TLB (translation lookaside buffer) — в котором хранится очень небольшое число (порядка 64) наиболее часто используемых адресов страниц (основные страницы, к которым постоянно обращается ОС)
- многоуровневая (2, 3 уровня) таблица страниц — в этом случае виртуальный адрес разбивается не на 2, а на 3 (4. ) части. Последняя часть остается смещением внутри страницы, а каждая из остальных задает номер страницы в таблице страниц 1-го, 2-го и т.д. уровней. В этой схеме для трансляции адресов нужно выполнить не 1 обращение к таблице страниц, а 2 и более. С другой стороны, это позволяет свопить таблицы страниц 2-го и т.д. уровней, и подгружать в память только те таблицы, которые нужны текущему процессу в текущий момент времени или же даже кешировать их. А каждая из таблиц отдельного уровня имеет существенно меньший размер, чем имела бы одна таблица, если бы уровень был один

- инвертированная таблица страниц — в ней столько записей, сколько в системе фреймов, а не страниц, и индексом является номер фрейма: а число фреймов в 64- и более разрядных архитектурах существенно меньше теоретически возможного числа страниц. Проблема такого подхода — долгий поиск виртуального адреса. Она решается с помощью таких механизмов как: хеш-таблицы или кластерные таблицы страниц
Сегментная организация памяти
Сегментная организация виртуальной памяти реализует следующий механизм: вся память делиться на сегменты фиксированной или произвольной длины, каждый из которых характеризуется своим начальным адресом — базой или селектором. Виртуальный адрес в такой системе состоит из 2-х компонент: базы сегмента, к которому мы хотим обратиться, и смещения внутри сегмента. Физический адрес вычисляется по формуле:

Историческая модель сегментации в архитектуре х86
В архитектуре х86 сегментная модель памяти была впервые реализована на 16-разрядных процессорах 8086. Используя только 16 разрядов для адреса давало возможность адресовать только 2^16 байт, т.е. 64КБ памяти. В то же время стандартный размер физической памяти для этих процессоров был 1МБ. Для того, чтобы иметь возможность работать со всем доступным объемом памяти и была использована сегментная модель. В ней у процессора было выделено 4 специализированных регистра CS (сегмент кода), SS (сегмент стека), DS (сегмент данных), ES (расширенный сегмент) для хранения базы текущего сегмента (для кода, стека и данных программы).
Физический адрес в такой системе расчитывался по формуле:
Это приводило к возможности адресовать большие адреса, чем 1МБ — т.н. Gate A20.
Плоская модель сегментации
32-разрядный процессор 80386 мог адресовать 2^32 байт памяти, т.е. 4ГБ, что более чем перекрывало доступные на тот момент размеры физической памяти, поэтому изначальная причина для использования сегментной организации памяти отпала.
Однако, помимо особого способа адресации сегментная модель также предоставляет механизм защиты памяти через кольца безопасности процессора: для каждого сегмента в таблице сегментов задается значение допустимого уровня привилегий (DPL), а при обращении к сегменту передается уровень привилегий текущей программы (запрошенный уровень привилегий, RPL) и, если RPL > DPL доступ к памяти запрещен. Таким образом обеспечивается защита сегментов памяти ядра ОС, которые имеют DPL = 0 . Также в таблице сегментов задаються другие атрибуты сегментов, такие как возможность записи в память, возможность исполнения кода из нее и т.д.
Таблица сегментов каждого процесса находится в памяти, а ее начальный адрес загружается в регистр LDTR процессора. В регистре GDTR процессора хранится указатель на глобальную таблицу сегментов.
В современных процессорах x86 используется "Плоская модель сегментации", в которой база всех сегментов выставлена в нулевой адрес.

Виртуальная память в архитектуре x86

Системные вызовы для взаимодействия с подсистемой виртуальной памяти:
- brk , sbrk - для увеличения сегмента памяти, выделенного для данных программы
- mmap , mremap , munmap - для отображения файла или устройства в память
- mprotect - изменение прав доступа к областям памяти процесса
Пример выделение памяти процессу:

Алгоритмы выделения памяти
Эффективное выделение памяти предполагает быстрое (за 1 или несколько операций) нахождение свободного участка памяти нужного размера.
Способы учета свободных участков:
- битовая карта (bitmap) — каждому блоку памяти (например, странице) ставится в соответствие 1 бит, который имеет значение занят/свободен
- связный список — каждому непрерывному набору блоков памяти одного типа (занят/свободен) ставится в соответствеи 1 запись в связном списке блоков, в которой указывается начало и размер участка
- использование нескольких связных списков для участков разных размеров — см. алгоритм Buddy allocation
Кеш — это компонент компьютерной системы, который прозрачно хранит данные так, чтобы последующие запросы к ним могли быть удовлетворены быстрее. Наличие кеша подразумевает также наличие запоминающего устройства (гораздо) большего размера, в которых данные хранятся изначально. Запросы на получение данных из этого устройства прозрачно проходят через кеш в том смысле, что если этих данных нет в кеше, то они запрашиваются из основного устройства и параллельно записываются в кеш. Соответственно, при последующем обращении данные могут быть извлечены уже из кеша. За счет намного меньшего размера кеш может быть сделан намного быстрее и в этом основная цель его существования.
По принципу записи данных в кеш выделяют:
- сквозной (write-through) — данные записываются синхронно и в кеш, и непосредственно в запоминающее устрйоство
- с обратной записью (write-back, write-behind) — данные записываются в кещ и иногда синхронизируются с запоминающим устройством
По принципу хранения данных выделяют:
- полностью ассоциативные
- множественно-ассоциативные
- прямого соответствия


Алгоритмы замещения записей в кеше
Поскольку любой кеш всегда меньше запоминающего устройства, всегда возникает необходимость для записи новых данных в кеш удалять из него ранее записанные. Эффективное удаление данных из кеша подразумевает удаление наименее востребованных данных. В общем случае нельзя сказать, какие данные являются наименее востребованными, поэтому для этого используются эвристики. Например, можно удалять данные, к которым происходило наименьшее число обращений с момента их загрузки в кеш (least frequently used, LFU) или же данные, к которым обращались наименее недавно (least recently used, LRU), или же комбинация этих двух подходов (LRFU).
Кроме того, аппаратные ограничения по реализации кеша часто требуют минимальных расходов на учет служебной информации о ячейках, которой является также и использование данных в них. Наиболее простым способом учета обращений является установка 1 бита: было обращение или не было. В таком случае для удаления из кеша может использоваться алгоритм часы (или второго шанса), который по кругу проходит по всем ячейками, и выгружает ячейку, если у нее бит равен 0, а если 1 — сбрасывает его в 0.
Более сложным вариантом является использование аппаратного счетчика для каждой ячейки. Если этот счетчик фиксирует число обращений к ячейке, то это простой вариант алгоритма LFU. Он обладает следующими недостатками:
- может произойти переполнение счетчика (а он, как правило, имеет очень небольшую разрядность) — в результате будет утрачена вся информация об обращениях к ячейке
- данные, к которым производилось множество обращений в прошлом, будут иметь высокое значение счетчика даже если за последнее время к ним не было обращений
Для решения этих проблем используется механизм старения, который предполагает периодический сдвиг вправо одновременно счетчиков для всех ячеек. В этом случае их значения будут уменьшаться (в 2 раза), сохраняя пропорцию между собой. Это можно считать вариантом алгоритм LRFU.
Читайте также: