
Чем бинарный файл отличается от текстового
в Linux file команда делает очень хорошую работу по распознаванию типов файлов и дает очень мелкозернистые результаты. The diff инструмент способен отличить двоичные файлы от текстовых файлов, производя другой вывод.
есть ли способ сообщить двоичные файлы в виде текстовых файлов? Все, что я хочу, это ответ Да/нет, является ли данный файл двоичным. Поскольку трудно определить двоичный файл, скажем, я хочу знать, если diff попытается выполнить текстовое сравнение.
для уточнения вопрос: мне все равно, если это текст ASCII или XML, пока это текст. Кроме того, я не хочу различать файлы MP3 и JPEG, поскольку они все двоичные.
diff определяет, является ли файл текстом или двоичный, проверив первые несколько байт в файле; точное количество байтов зависит от системы, но это обычно несколько тысяч. Если каждый байт в этой части файла non-null, diff считает файл текст; в противном случае он рассматривает файл бинарный.
file еще нужную команду. Любой файл, который является текстом (в соответствии с его эвристикой), будет включать слово "текст" в вывод file ; все, что является двоичным, не будет включать слово "текст".
если вы не согласны с эвристики, file использует для определения текста против не-текста, тогда вопрос должен быть лучше указан, так как текст против не-текста является по своей сути неопределенным вопросом. Например, file не идентифицирует блок открытого ключа PGP в ASCII как "текст", но вы можете (поскольку он состоит только из печатаемых символов, даже если он не читается человеком).
быстрый-и-грязный способ-искать NUL символ (нулевой байт)в первых K или двух файлах. Пока вы не беспокоитесь о UTF-16 или UTF-32, ни один текстовый файл не должен содержать NUL .
обновление: согласно руководству diff, это именно то, что diff делает.
вы можете попытаться дать
команда и сравните размер с размером файла . я не совсем уверен, но если они одинаковы, файл действительно является текстовым файлом.
в наши дни термин "текстовый файл" неоднозначен, потому что текстовый файл может быть закодирован в ASCII, ISO-8859-*, UTF-8, UTF-16, UTF-32 и так далее.
посмотреть здесь для того, как Subversion это делает.
этот подход использует те же критерии, что и grep при определении того, является ли файл двоичным или текстовым:
Файлы – виды
C-программирование требует определенных навыков и умений. Для обучения можно использовать Google – там полно полезной информации и даже примеров кодификаций. Но без практики и первоначальных знаний добиться успехов не получится.
В записанных и успешно работающих утилитах есть так называемые файлы. Предназначаются для хранения информации в том или ином виде.
Каждый используется для чтения и записи собственного «формата». Файл сам по себе, согласно данным из Google – это способ хранения информации.
В C нет операторов для работы с файлами. Необходимые манипуляции производятся при помощи функций стандартной библиотеки .
Пример
Вот наглядный пример использования fgets:
В ходе описанного кода произойдет считывание file.txt или первых 99 символов. Все зависит от того, какое именно из событий осуществляется раньше. Результаты выводятся на экран.
Бинарный файл – что это
Если посмотреть данные в Google по file в C, можно увидеть, что есть еще и так называемые двоичные «элементы». Это – файлы, из которых осуществляется считывание или вывод байтов. Подразумевается их предоставление программеру в «сыром» виде. То есть, без связывания и подстановок.
Fgets – для чего нужна функция
Текстовые файлы согласно Google используются не только обычными юзерами, но и опытными программерами весьма часто. Работать с ними нужно уметь, особенно если речь заходит о написании кодификаций.
Полезной является функция fGets. Это – чтение строки из указанного потока данных с последующим сохранением в виде строчки в параметр string. Происходит это до тех пор, пока приложение не дойдет до конца файла.
Символ новой строки закрывает работу fGets, но служит допустимым. Связано это с тем, что происходит копирование оного в строчку string. Нулевой символ добавляется после прочитанных. Указывает на конец str.
Функция имеет вид: char *fgets (char *str, int num, FILE *stream) – вместо char допускается использование void. Аргументы расшифровываются следующим образом:
- str – указатель на массив, в котором осуществится размещение считанной строчки;
- num – предельно допустимая длина строчки, попадающей под считывание;
- stream – поток данных (указатель на него).
Если чтение строчки успешно, Google говорит, что произойдет возвращение указателя на массив, в который помещены прочитанные сведения. В противном случае программному коду предстоит открыть файл, «просмотреть» его и вернуть значение NULL.
Когда при чтении осуществляется ошибка, возвращается NULL, а в переменную errno происходит запись кода ошибки. А состояние массива, в котором должна была сохраниться строчка, не определяется.
Особенности работы с бинарными «элементами»
Текстовый файл – понятие далеко не новое. Оно встречается не только в программировании. В Google можно отыскать четкое определение оному. И работа с «обычным текстом» при написании кодификаций не такая уж трудная.
Сложнее использовать двоичный файл. Он встречается в кодах чаще всего. В основном используется для записи чисел и значений.
Для того, чтобы в Си-семействе (в C++ в особенности) работать с бинарными файлами, согласно Google, используется стандартная библиотека. Для текстовых применяются:
Бинарные файлы тоже используют соответствующие «архивы», но с некоторыми корректировками. Пример – для чтения используют не параметр «r», а «rb». Работа осуществляется непосредственно с битами. Доступ к данным осуществляется произвольным образом.
Текстовый файл — понятие
Текстовый файл – файл, который содержит текстовые данные. Разбивается на строки посредством специального «разделительного» символа, используемого для обозначения окончания строчки или последовательности:
- в Unix – одиночный символ перевода строки;
- в Windows – после символа перевода строчки устанавливается знак возврата каретки.
В текстовый файл мы записываем кодификации и «простой текст». То, что нужно записать. Это не особый формат информации.
Терминология – что пригодится
Можно написать хороший софт только тогда, когда пользователь хорошо разбирается в том, что он делает. Си-семейство схоже между собой, но каждый язык имеет ключевые особенности.
Перед началом работы с бинарными файлами и Fgets требуется запомнить некоторые ключевые термины. К ним относят следующие понятия:
- базовый класс – класс, от которого осуществляется наследование;
- выражение – сочетание операторов, литералов и переменных, которые интерпретируются согласно установленным правилам языка;
- деструктор – метод класса, который отвечает за деинициализацию объекта;
- идентификатор – имя, присвоенное «элементу» в кодификации;
- класс – некий шаблон, отвечающий за определение формы объекта;
- конструктор – метод класса, используемый при инициализации;
- литерал – фиксированное значение, не изменяемое приложение;
- массив – переменные одного типа, обращение к которым производится по общему «названию»;
- объект – своеобразный экземпляр класса;
- параметры – переменные, получаемые из аргументов, передаваемый функции при вызове;
- переменная (наиболее частый формат – int i) – именованная ячейка памяти;
- строка – последовательность символов, заключенная в двойные кавычки;
- структура – шаблон, определяющий форму объекта с открытыми членами;
- указатель – объект, содержащий так называемый адрес памяти;
- функция – подпрограмма, в которой находится одно или несколько приложения Си, задействованных для определенных задач.
Это – основная терминология для всего Си-семейства. Если какие-то слова при создании кодов не понятны, можно всегда обратиться к помощи Google.
Примечания
- пустой файл не считается текстовым файлом в соответствии с этим тестом. символические ссылки.
быстрый способ сделать это в ubuntu-использовать nautilus в представлении "список". Столбец type покажет вам, если его текст или двоичный
команды, как меньше, grep обнаружить его довольно легко (и быстро). Вы можете взглянуть на их источник.
Т радиционно все файлы принято делить на группы. Есть текстовые файлы, есть видео, аудио, изображения, есть исполняемые файлы программ. А еще есть файлы, именуемые бинарными или двоичными. Обычно под бинарными понимают исполняемые файлы, но насколько правильным является такое определение и есть ли какое-то принципиальное различие между бинарными и текстовыми файлами?
Кто-то скажет, конечно есть, текстовый файл — это тот, который можно открыть текстовым редактором. Правда, здесь необходимо уточнить, каким именно редактором нужно открывать тот или иной файл. Блокнотом? Взять хотя бы документ Microsoft Word . Его тоже можно открыть Блокнотом или Notepad++ , но какова только будет интерпретация его содержимого? Очевидно, что ничего прочитать в нём вы не сможете.
Впрочем, Блокнотом вы можете открыть и аудио, и изображение, и при этом тоже получите набор текстовых знаков, однако никому ни придет в голову назвать такие файлы текстовыми. Получается так, что текстовый файл это тот, содержимое которого представлено человеческим языком и не важно, какая программа перевела его содержимое на этот язык. А что насчет файлов скриптов, а еще лучше раскомпилированных exe -файлов, ведь их содержимое (исходный код) тоже обычно представлено человеческим языком? Они получаются тоже текстовые?

На самом деле никакого критерия, который позволял бы отделять текстовые файлы от бинарников нет, тем более, что сами операционные системы таких различий не делают, вместо этого они смотрят на расширение файла и в некоторых случаях на его внутреннюю подпись, запуская файл в соответствующей расширению программе. Что же касается их внутренней структуры, то здесь между ними нет никакого принципиального различия.
Если копнуть глубже, содержимое всех файлов можно представить в виде двоичного машинного кода, то есть все файлы без исключения по сути являются бинарными. Микропроцессору совершенно без разницы, какой файл ему подсунут, будет ли он содержать команды или просто данные, процессор станет интерпретировать или по крайней мере будет пытаться интерпретировать его содержимое как команды.

Понятие текстовый файл существует лишь в нашем сознании, таковым его делают наличие «читаемых» символов — букв алфавитов, пробелов, точек и запятых, восклицательных знаков и тире, словом всего того, что позволяет нам выражать свои мысли и эмоции в письменном виде и именно эта сложность является еще одним доказательством бесспорного превосходства человеческого ума над машиной.
Б ывают случаи, когда у пользователей возникает необходимость проверить два файла на идентичность. Чаще всего с подобной задачей сталкиваются начинающие веб-разработчики и программисты. Отыскивать несоответствия в одинаковых с виду файлах приходится редакторам, корректорам и прочим специалистам, работающим с текстовыми данными.
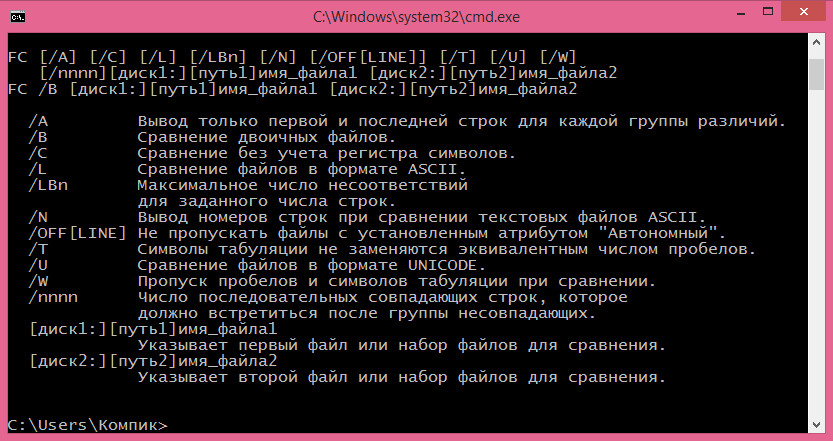
По идее для этих целей лучше всего использовать специальные утилиты, например WinMerge, но файлы также можно сравнивать с помощью самой обыкновенной командной строки . В командной оболочке всех версий Windows имеется замечательная команда FC. Она позволяет сравнивать между собой любые файлы, причём как текстовые, так и бинарные. Синтаксис этой команды очень прост и выглядит он следующим образом:
FC /ключ [полный путь к первому файлу] [полный путь ко второму файлу]
Список доступных ключей можно просмотреть, набрав и выполнив в консоли CMD команду FC /? . Справка даётся на русском языке, так что вы без труда разберетесь, что к чему.
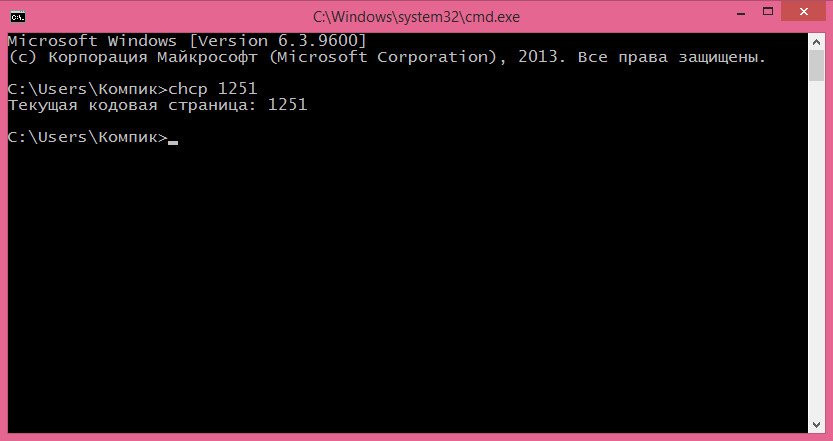
А теперь немного практики. Допустим, у вас есть два файла с кодом PHP и в одном из них предположительно имеются некие различия. Скрипты PHP это обычные текстовые файлы , поэтому в данном случае будем использовать ключ L предназначенный для сравнения текстовых документов в кодировке ASCII. Если скрипт содержит кириллицу, не забудьте перед выполнением команды сравнения выставить в консоли кодировку 1251, иначе на выходе вы получите крякозябры. Смена кодировки выполняется командой chcp 1251 .
Затем сравниваем файлы:
FC /L D:/1.php D:/2.php
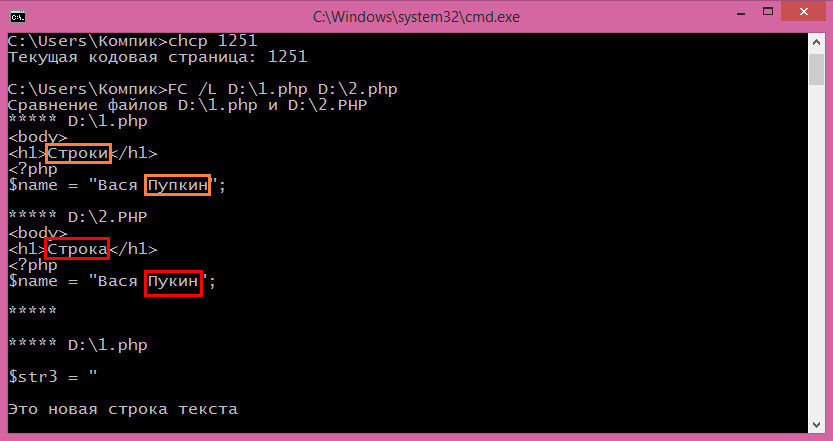
Различия между файлами выводятся в следующем порядке. Сначала идёт имя первого файла, затем строка, в которой было найдено несовпадение. За ним идёт имя второго файла и точно также указывается различающаяся строка. Если программа находит ещё несколько несоответствий в других строках, всё повторяется. В общей сложности утилита может обнаружить до 100 различий, такое ограничение имеет используемый командой fc внутренний буфер.
При поиске несоответствий в бинарных файлах используется ключ B. При этом сравнение производится побайтово. В принципе, таким способом можно сравнивать любые файлы, ведь все они по сути двоичны, просто при работе с текстовыми форматами FC может ограничиться информацией какой из сравниваемых объектов длиннее и на этом завершить свою работу.
FC /B D:/1.exe D:/2.exe
В данном примере сравниваются два исполняемых файла. Результат такого сравнения будет выглядеть примерно следующим образом:
00000040: 56 BA
00000050: 65 68
00000060: 43 72
00000070: 6U 0A
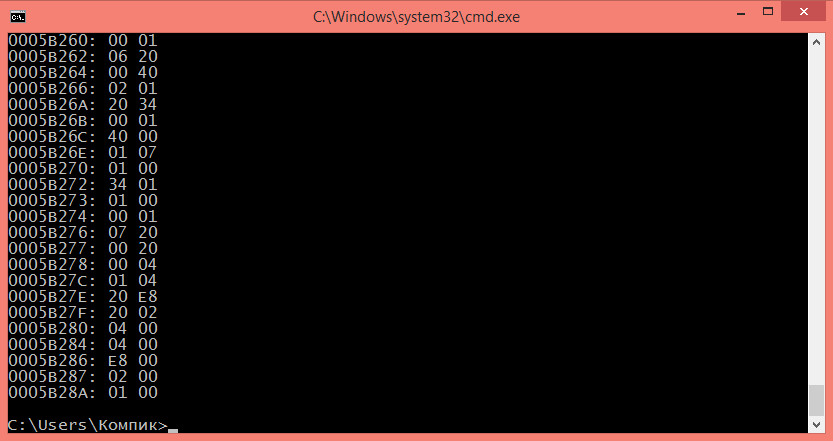
Если вы раньше никогда не имели дела с шестнадцатеричными редакторами, разобраться со всем этим нагромождением символов будет непросто. В общем так, каждая выведенная в консоли строка это найденное различие. Символы до двоеточия указывают на смещение от начала файла, первое двухзначное число это соответствующий смещению байт в первом файле, второе двухзначное число — соответствующий смещению байт во втором файле.
Какими ещё полезными возможностями обладает команда FC? Ну, например поддержкой подстановочных знаков. Если вам нужно сравнить некий файл etalon.exe с другими исполняемыми файлами в текущем каталоге, используйте команду следующего формата:
fc *.exe etalon.exe
Почему мы должны различать текстовый файл и двоичные файлы при их передаче? Почему некоторые каналы предназначены только для текстовых данных? На нижнем уровне все они-биты.
на нижнем уровне, они все биты. истинный. Однако некоторые каналы передачи имеют по семь битов на байт, а другие-по восемь битов на байт. Если вы передаете текст ASCII в течение семи-битный канал, то все нормально. Двоичные данные искажаются.
кроме того, разные системы используют разные соглашения для линейных окончаний: LF и CRLF являются общими, но некоторые системы используют CR или NEL. Режим передачи текста автоматически преобразует окончания строк , что повредит двоичные файлы.
некоторые примеры 7-битных каналов: SMTP (номинально, без расширений), SMS, Telnet, некоторые последовательные соединения. Интернет не всегда был построен на TCP/IP, и это видно.
все файлы сохраняются в одном из двух форматов файл - двоичный или текстовый. Два типа файлов могут выглядеть одинаково на поверхности, но их внутренние структуры различны.
в то время как двоичные и текстовые файлы содержат данные, хранящиеся в виде ряда (бит (двоичные значения 1s и Os), биты в текстовых файлах представляют символы, а биты в двоичных файлах представляют пользовательские данные.
различение между ними важно, так как разные ОС обрабатывают текстовые файлы по-разному. Например, в *nix вы заканчиваете свои строки просто \n в то время как в MS OSs вы используете \r\n и в Macs вы используете \n\r . Программное обеспечение, такое как FTP-клиенты, пытается изменить окончания строк в текстовых файлах в соответствии с целевой ОС, добавляя/удаляя символы. Это чтобы убедиться, что текстовый файл будет выглядеть правильно на целевой ОС.
например, если вы создаете текстовый файл в *nix с разрывами строк и попытайтесь скопировать его в окно windows в виде двоичного файла и открыть его в блокноте, вы не увидите ни одного конца строки, а просто засор текста.
Как заявляли другие, существует также проблема кодирования разделителей разрыва строки, которая уникальна для текстовых файлов и может отличаться от платформы к платформе. "Разрыв строки" - это не буква в нашем алфавите или символ, который вы можете написать, поэтому к нему применяются другие правила.
с двоичными файлами нет неявного соглашения о кодировке символов или об определении понятия "линия".
все файлы машинного языка на самом деле являются двоичными файлами.
для открытия двоичного файла режим файла должен быть упомянут как"rb "или"wb" в команде fopen. В противном случае все файлы будут открыты в режиме по умолчанию, который является текстовым режимом.
можно отметить, что текстовые файлы также могут храниться и обрабатываться как двоичные файлы, но не viceversa.
двоичные файлы отличаются от текстового файла двумя способами:
- хранение строки персонажи
- символ EOF
- wt-t означает textfile
- Wb-b означает binaryfile
двоичные файлы не хранят какой-либо специальный символ в конце любой конец файла проверяется путем ueing их размер сам.

Программирование включает в себя множество разнообразных языков. С их помощью программисты и разработчики «общаются» с компьютерами и иными устройствами, а также с приложениями. У каждого – свои собственные особенности и нюансы, синтаксис и правила.
При написании софта приходится задействовать разнообразные files и функции. Чтобы создать качественную утилиту, необходимо помнить обо всех особенностях выбранного языка. Но некоторые возможности используются не слишком часто. Из-за этого они «забываются».
Современные программеры активно используют Си-семейство в своей работе. Google указывает, что сюда включают:
Эти языки стали универсальными и удобными. У них много схожих файлов и функций. Но новичкам освоить данные способы «общения» с компьютерами бывает непросто.
Доступ к информации в функции
Для того, чтобы получить доступ к информации в функции произвольно, записывается следующая кодификация:
Fseek (переменная, расстояние, seek_set или seek_cur или seek_end).
Здесь имеет место следующая расшифровка:
- seek_set – открываем файл и ведем отсчет от начала;
- seek_cur – непосредственно от установленного курсора;
- seek_end – конец файла.
Для того, чтобы рассчитать расстояние (битов, на «размер» которых сдвигается указатель), используют sizeof().
используемые параметры grep:
- -q Quiet; выход немедленно с нулевым статусом, если какое-либо совпадение найдено
- -I обрабатывать двоичный файл, как если бы он не содержал соответствующие данные
Запись и чтение
Немаловажным моментом является запись и чтение. При помощи Google можно разобраться с тем, как создается и используется поток поступаемой информации при обработке кода. Но без «базы» осознать соответствующую информацию не выйдет.
Для записи бинарного файла (из данных Google) используется запись:
Fwrite (ссылка на записываемую информацию, размер, количество «сведений», файловая переменна).
Для того, чтобы осуществить чтение соответствующего документа, задействуется функция под называнием fread. Параметры у нее будут аналогичные.
Разница между файлами
Некоторые перед написанием кода задумываются, в чем разница между указанными видами файлов. Пример – картинка и звуковой документ. Чем они отличаются друг от друга?
Звуковой файл интерпретируется через специальные приложения в звуки, а второй «документ» — в изображение. Аналогичным образом согласно Google ситуация обстоит и рассматриваемыми files. Текстовые рассматриваются в виде «обычного текста», а бинарные интерпретируются в качестве набора двоичных чисел.
В текстовых файлах символ «\n» при записи переводится в «\r\n», при считывании осуществляется так называемая образная замена. В случае с бинарными «элементами» подобный прием не работает ни при каких обстоятельствах.
используется шаблон grep:
- '.' матч любой один символ. Все файлы (кроме пустого файла) будет соответствуйте этой схеме.
Читайте также: