
Buffer busy waits oracle что это
Buffer Busy Waits usually happen on Oracle 10 and 11 mainly because of insert contention into tables or Indexes. There are a few other rare cases of contention on old style RBS segments, file headers blocks and freelists.
Before Oracle 10 and 11 there was one other major reason which was readers waiting for readers, ie one user does a physical IO of a block into memory and a second user want to read that block. The second user waits until the IO is finished by the first user. Starting in 10g this wait has been given the name "read by other session". Before Oracle 10g this was also a "buffer busy wait".
The easiest way to analyze the bottleneck and find a solution is to use ASH (active session History) available in Oracle 10g with the diagnostics pack license or using Simulated ASH for free or using a product like DB Optimizer.
Data block class, which can be found in ASH, is the most important piece of information in analyzing buffer busy waits. If we know the block class we can determine what kind of bottleneck:
- IF OTYPE =
- INDEX , then the insert index leaf block is probably hot, solutions are
- Hash partition the index
- Use reverse key index
- TABLE, then insert block is hot,solutions
- Use free lists
- Put Object in ASSM tablespace
How do we find the block class? With a quick query on the ASH data like:
| OBJ | OTYPE | SQL_ID | CLASS |
| TOTO1 | TABLE | 8gz51m9hg5yuf | data block |
| TOTO1 | TABLE | 8gz51m9hg5yuf | data block |
| TOTO1 | TABLE | 8gz51m9hg5yuf | segment header |
| TOTO1 | TABLE | 8gz51m9hg5yuf | data block |
If we find that then we will want more information to diagnose, such as the object type "OTYPE" , object name and what kind of tablespace the object is stored in. The following query provides that information:
and the output looks like
| CNT | OBJ | OTYPE | SQL_ID | BLOCK_TYPE | TBS | ASSM |
| 3 | TOTO1 | TABLE | 8gz51m9hg5yuf | segment header | NO_ASSM | MANUAL |
| 59 | TOTO1 | TABLE | 8gz51m9hg5yuf | data block | NO_ASSM | MANUAL |
Before Oracle 10, buffer busy waits also happened because IO blocking another user wanting to do the same IO. On Oracle 9, the main reasons for buffer busy waits are
1) IO read contention (only Oracle 9i and below) 2) Insert Block Contention on Tables or Indexes 3) Rollback Segment Contention
On version 8 and 9, the p3 value has a different meaning. Instead of meaning the block type (which is the best thing to know) it means the kind of buffer busy wait. There are only two values that matter to us, values in
100 range = read waits (basically just an IO wait) Reader blocking Reader, ie one reader is reading a block in and another person wants to read this block and waits on a buffer busy wait p3=130. 200 range = write contention (same as in 10g) Writers blocking other writers for example while doing inserts either because of no free lists on the table or because everyone is inserting into the same index block.
If you have set up ASH style collection with S-ASH or have a product like DB Optimizer you can run a query like:
Because querying DBA_EXTENTS is a slow operation, I made a copy of DBA_EXTENTS which will be faster to query.
| CNT | OWNER | SEGMENT_NAME | PARTITION_NAME | SEGMENT_TYPE | P3 |
| 1 | SYS | _SYSSMU2$ | TYPE2 | UNDO | read |
| 1 | SYS | _SYSSMU3$ | TYPE2 | UNDO | write |
This second option of getting the object from P1 and P2 (file and block) should probably be done only with the users consent, because we would have to create a copy of the dba_extent table which might take a long time if it's big.
If you don't have ASH data you will have to do some guess work.
Block Class (block type)
The first step in finding out the source of buffer busy waits is looking at V$waitstats This will tell us what kind of datablocks we have contention on.
File with contention
You can also get an idea of what file contains the object with the buffer busy waits by looking at: X$KCBFWAIT
Object with contention
Starting in version 9i there is the table v$segstat That will list the objects with buffer busy waits. If you are on version 7 or 8 good luck finding the object without setting up ASH style data collection.
To put it most succinctly, buffer busy waits happen because two users want to change a block at the same time. Two users can change the same block, or even same row "at the same time" ie without committing, but that's different from the actual operation of modifying the block. The modification on the block in RAM, or computer memory, can only be done by one process at at time in order to avoid memory corruptions. Different users can modify different blocks at the same time but only one user or process can modify a the same block at a time.
In order to really understand what's going on we have to take a look at how Oracle manages memory and block access and modifications. Here is the layout of
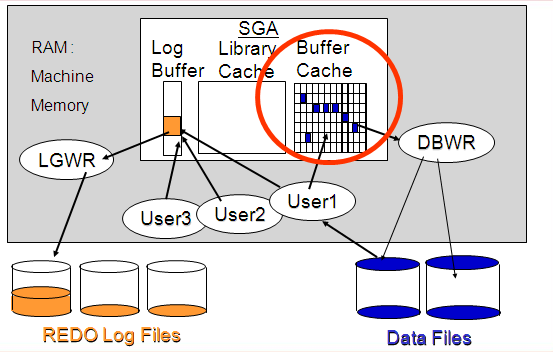
Above is a diagram shows some of the essential parts of Oracle in regards to performance tuning. In the machine memory are
- Oracle's SGA, or System Global Area, a memory that is shared between Oracle users
- LGWR - log writer process
- DBWR - database writer process
- User1,2,3 . - user processes, in this case "shadow processes"
On the machine file system are
The SGA is composed of (among other things)
- Log Buffer
- Library Cache
- Buffer Cache
What's important for understanding buffer busy waits is how the buffer cache is managed. Here is view of the buffer cache with more components:
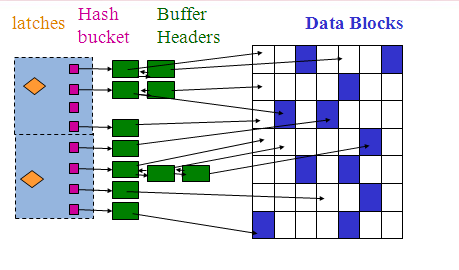
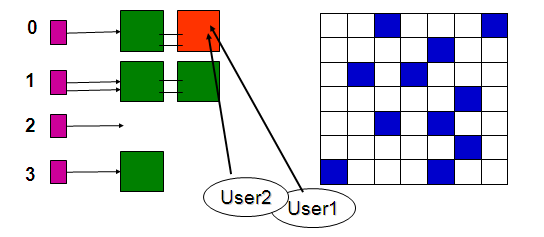
In order to access a block, a user (shadow process) has to get a latch (cache buffer chains latch) which protects buckets or linked lists of buffer headers. Once the header desired if found the latch is released. The buffer headers point to the actual data block in memory. Before modifying a block in memory a user has to lock the buffer header. The buffer header is locked any time a modification is made whether it is reading a block into memory or modifying a block that is already in memory. Usually the header is locked only for a brief amount of time but when there is a lot of concurrent access the buffer header can become a bottleneck.
BBW on a file header
| Time | P1 | P2 | OBJN | OTYPE | FN | BLOCKN | BLOCK_TYPE |
| 11:44 | 202 | 2 | -1 | 0 | 0 | file header block | |
| 11:44 | 202 | 2 | TOTO | TABLE | 1 | 60218 | file header block |
| 11:44 | 202 | 2 | TOTO | TABLE | 1 | 60218 | file header block |
| 11:44 | 202 | 2 | TOTO | TABLE | 1 | 60218 | file header block |
| 11:44 | 202 | 2 | TOTO | TABLE | 1 | 60218 | file header block |
Solution If you are getting buffer busy waits on the file header block for a tempfile (datafile in a temporary tablespace) then try increasing the "next extent" size in the temporary tablespace. This wait can happen when lots of extents are being allocated in the temporary tablespace.
What Would ADDM do?
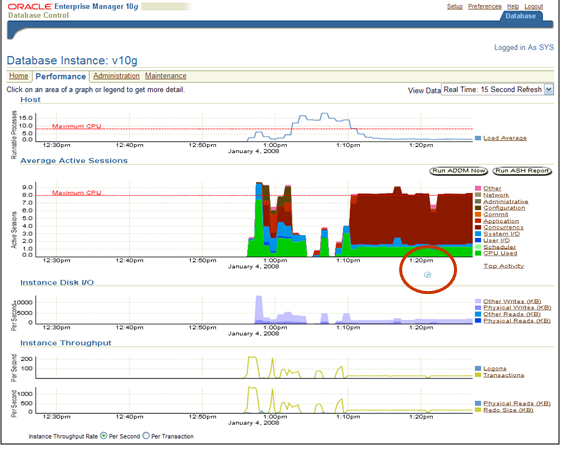
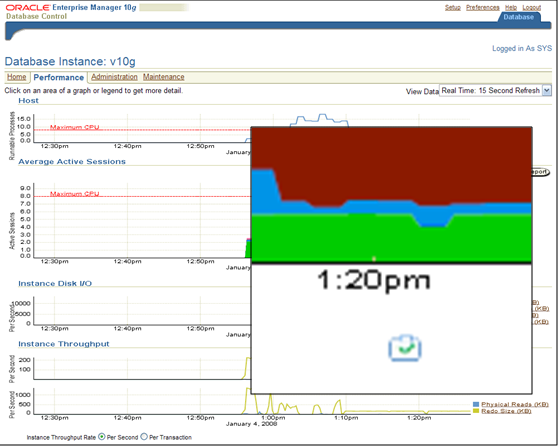
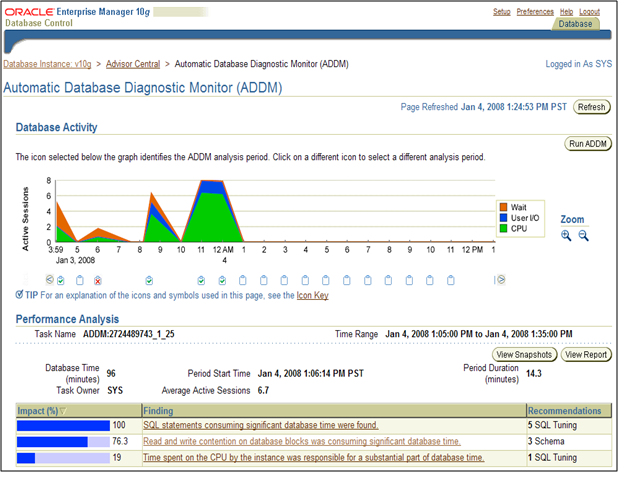
Interestingly enough the ADDM page doesn't show the new load that has recently come on the system but the analysis is there. I clicked on the next to bottom line in the page, "Read and write contention on database blocks was consuming significant database time.
Buffer busy waits (%)
This wait happens when a session wants to access a database block in the buffer cache but it cannot because the buffer is busy. Another session is modifying the block and the contents of the block are in flux during the modification. To guarantee that the reader has a coherent image of the block with either all of the changes or none of the changes, the session modifying the block marks the block header with a flag letting other users know a change is taking place and to wait until the complete change is applied.
Another session is reading the block into the buffer
Another session holds the buffer in an incompatible mode to our request
While the block is being changed, the block is marked as unreadable by others. The changes that are being made should last under a few hundredths of a second. A disk read should be under 20 milliseconds and a block modification should be under one millisecond. Therefore it will take a lot of buffer busy waits to cause a problem.
However, in a problem situation, there is usually a hot block, such as the first block on the free list of a table, with high concurrent inserts. All users will insert into that block at the same time, until it fills up, then users start inserting into the next free block on the list, and so on.
Another example of a problem is of multiple users running full table scans on the same large table at the same time. One user will actually read the block physically off disk, and the other users will wait on Buffer Busy Wait for the physical I/O to complete.
Metric Summary
The rest of the information in this section is only valid for this metric when it appears in either the Enterprise Manager Grid Control or the Enterprise Manager Database Control (if applicable).
The following table shows how often the metric's value is collected and compared against the default thresholds. The 'Consecutive Number of Occurrences Preceding Notification' column indicates the consecutive number of times the comparison against thresholds should hold TRUE before an alert is generated.
This section provides detailed descriptions for those wait events of greatest interest.
Where appropriate, pointers are provided to further information elsewhere in Oracle Database documentation. For a complete listing of wait events, in alphabetical order, you can issue the following SQL statement:
C.3.4 BFILE check if exists
The session waits to check if an external large object (LOB) exists.
Wait Time: The total elapsed time for the exists call
C.3.10 BFILE internal seek
The session waits for a positioning call within the external large object (LOB) to complete.
Wait Time: The total elapsed time for the seek to complete
BBW on old style RBS
IF block class > 18 it's an old style RBS segment
| SEGMENT_NAME | SEGMENT_TYPE |
| R2 | ROLLBACK |
solution move to new AUM or Automatic Undo Mangement
alter system set undo_management=auto scope=spfile;
C.3.9 BFILE get path object
The session is waiting on a call to find or generate the external path name of an external large object (LOB).
Wait Time: The total elapsed time for make external path to complete
C.3.13 broadcast mesg queue transition
Processes enter "wait for broadcast mesg queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The publisher is responsible for moving the message to the free queue, but it cannot do so until the message is in the done queue. If the message is still not in the done queue, process enters this wait. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
publisher channel handle pointer
broadcast message pointer
A number indicating the function in KSR where the process is waiting
BBW on index (because of insert)
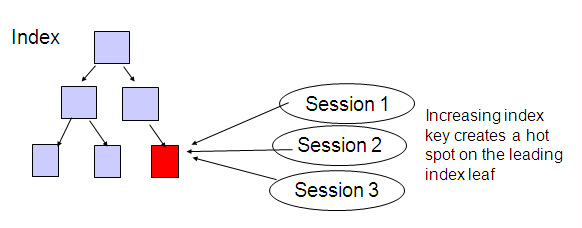
If users are inserting data that has a rising key value, especially a monotonically rising value, then all the new inserts will have to update the leading edge leaf block of the index and with high concurrent inserts this can cause buffer busy waits.
Solutions Hash partition the index
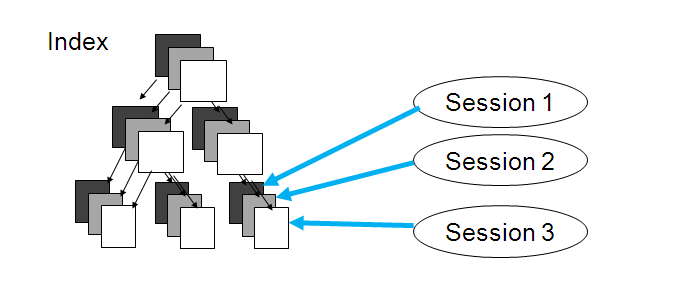
Reverse Key Index

C.3.3 ASYNC Remote Write
Used to track the time (in centiseconds) for asynchronous streaming RFSWRITE operations. This includes stall reaps and streaming network submission time. This time is accumulated by TT nn (Redo Transport Slave) background processes.
Oracle Data Guard Concepts and Administration for more information about using RFS to manage standby redo logs.
C.3.6 BFILE closure
The session waits for an external large object (LOB) to close.
Wait Time: The total elapsed time for the close call
C.3.14 broadcast mesg recovery queue transition
Processes enter "wait for broadcast mesg recovery queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The broadcasted message is in the recovery queue of another channel handle (for example, ch2). Process enters this wait, if the message is yet to be removed from the recovery queue of the ch2 channel handle. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
Publisher channel handle pointer
Broadcast message pointer
A number indicating the function in KSR where the process is waiting
C.3.8 BFILE get name object
The session waits on a call to find or generate the external name of a external large object.
Wait Time: The total elapsed time for make external file name to complete
C.3.11 BFILE open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
C.3.7 BFILE get length
The session waits on a call to check the size of an external large object (LOB).
Wait Time: The total elapsed time for the call to check the LOB size
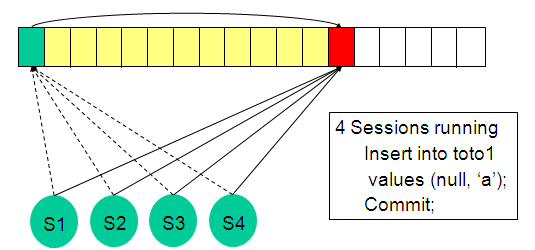
BBW on insert
If multiple concurrent users are inserting into a table that doesn't have free lists or is not in an ASSM tablespace then all users will end up inserting into the same block, the first one on the free list and this block will become the hot block
by adding free lists or moving the table to an ASSM tablespace we will alleviate the bottleneck.
Multiple free lists:
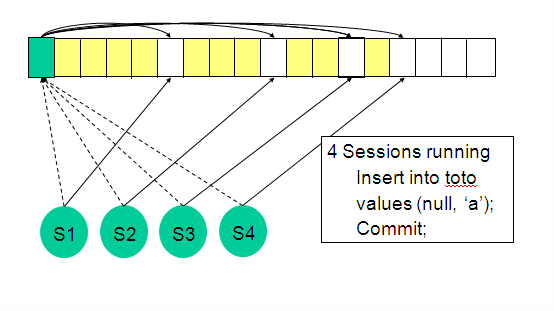
The other option is ASSM or Automatic Segment Space Management which is set at the tablespace level. In this case free block information is kept in Level 1 BMB (or bitmapped blocks). These Level 1 BMBs are chosen by a hash on the users process ID thus distributing the inserts across the table.
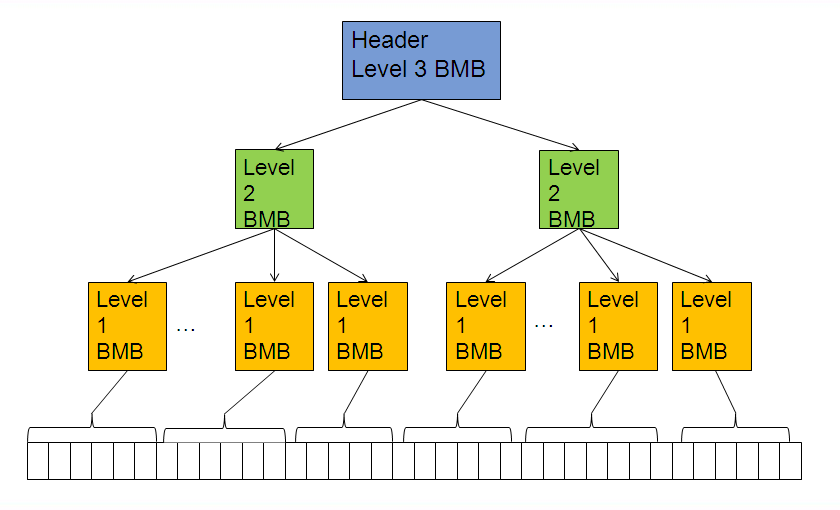
The inserts would look something like this (somewhat exaggerated drawing)
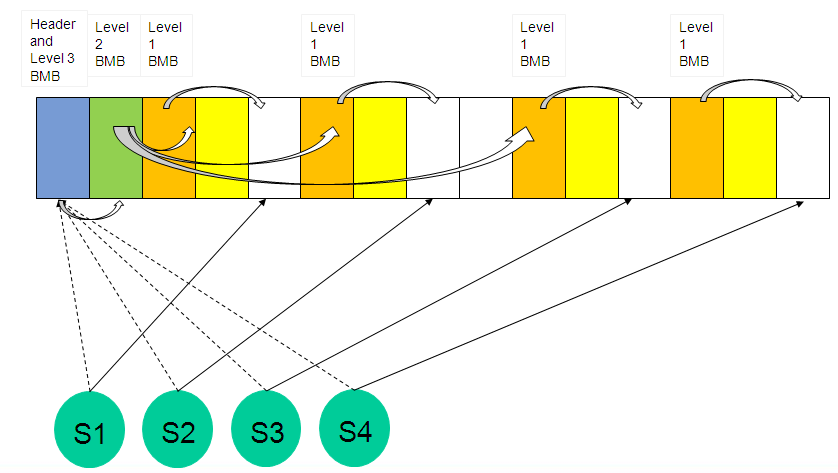
the ASSM BMB blocks take up more space in the table , about 1 extra block for every 16 data blocks and there is overhead first looking in the header/level 3 BMB block then going to the Level 2 then level 1 and finally to the datablock but all in all ASSM is worth reduced costs of management verses free lists.
Identifying and creating ASSM tablespaces
Which tablespaces are ASSM or not?
select tablespace_name, extent_management LOCAL, allocation_type EXTENTS, segment_space_management ASSM, initial_extent from dba_tablespaces
| TABLESPACE_NAME | LOCAL | EXTENTS | ASSM |
| SYSTEM | LOCAL | SYSTEM | MANUAL |
| UNDOTBS1 | LOCAL | SYSTEM | MANUAL |
| SYSAUX | LOCAL | SYSTEM | AUTO |
| TEMP | LOCAL | UNIFORM | MANUAL |
| USERS | LOCAL | SYSTEM | AUTO |
| EXAMPLE | LOCAL | SYSTEM | AUTO |
| DATA | LOCAL | SYSTEM | MANUAL |
creating an ASSM tablespace:
create tablespace data2 datafile '/d3/kyle/data2_01.dbf' size 200M segment space management auto;
C.3.1 alter system set dispatcher
A session has issued a statement ALTER SYSTEM SET DISPATCHER = string and is waiting for the dispatchers to get started.
Wait Time: The session will wait 1 / 100 of a second and verify if the new dispatchers have started, else the session will wait again
Number of times that the session has waited 1 / 100 of a second
C.3.15 buffer busy waits
Wait until a buffer becomes available.
There are four reasons that a session cannot pin a buffer in the buffer cache, and a separate wait event exists for each reason:
"buffer busy waits": A session cannot pin the buffer in the buffer cache because another session has the buffer pinned.
"read by other session": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from disk.
"gc buffer busy acquire": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from the cache of another instance.
"gc buffer busy release": A session cannot pin the buffer in the buffer cache because another session on another instance is taking the buffer from this cache into its own cache so it can pin it.
Prior to release 10.1, all four reasons were covered by "buffer busy waits." In release 10.1, the "gc buffer busy" wait event covered both the "gc buffer busy acquire" and "gc buffer busy release" wait events.
Wait Time: Normal wait time is 1 second. If the session was waiting for a buffer during the last wait, then the next wait will be 3 seconds.
Buffer Busy Waits usually happen on Oracle 10 and 11 mainly because of insert contention into tables or Indexes. There are a few other rare cases of contention on old style RBS segments, file headers blocks and freelists.
Before Oracle 10 and 11 there was one other major reason which was readers waiting for readers, ie one user does a phyiscal IO of a block into memory and a second user want to read that block. The second user waits until the IO is finished by the first user. Starting in 10g this wait has been given the name "read by other session". Before Oracle 10g this was also a "buffer busy wait".
The easiest way to analyse the bottleneck and find a solution is to use ASH (active session History) available in Oracle 10g with the diagnostics pack license or using Simulated ASH for free or using a product like DB Optimizer.
Data block class, which can be found in ASH, is the most important piece of information in analysing buffer busy waits. If we know the block class we can determine what kind of bottleneck:
How do we find the block class? With a quick query on the ASH data like:
If we find that then we will want more information to diagnose, such as the object type "OTYPE" , object name and what kind of tablespace the object is stored in. The following query provides that information:
and the output looks like
Oracle 7, 8 and 9
Before Oracle 10, buffer busy waits also happened because IO blocking another user wanting to do the same IO. On Oracle 9, the main reasons for buffer busy waits are
On version 8 and 9, the p3 value has a different meaning. Instead of meaning the block type (which is the best thing to know) it means the kind of buffer busy wait. There are only two values that matter to us, values in
If you have set up ASH style collection with S-ASH or have a product like DB Optimizer you can run a query like:
Because querying DBA_EXTENTS is a slow operation, I made a copy of DBA_EXTENTS which will be faster to query.
This second option of getting the object from P1 and P2 (file and block) should probably be done only with the users consent, because we would have to create a copy of the dba_extent table which might take a long time if it's big.
If you don't have ASH data you will have to do some guess work.
Block Class (block type)
File with contention
Object with contention
Why do buffer busy waits happen?
To put it most succinctly, buffer busy waits happen because two users want to change a block at the same time. Two users can change the same block, or even same row "at the same time" ie without committing, but that's different from the actual operation of modifying the block. The modification on the block in RAM, or computer memory, can only be done by one process at at time in order to avoid memory corruptions. Different users can modify different blocks at the same time but only one user or process can modify a the same block at a time.
In order to really understand what's going on we have to take a look at how Oracle manages memory and block access and modifications. Here is the layout of
Above is a diagram shows some of the essential parts of Oracle in regards to performance tuning. In the machine memory are
On the machine file system are
The SGA is composed of (among other things)
What's important for understanding buffer busy waits is how the buffer cache is managed. Here is view of the buffer cache with more components: In order to access a block, a user (shadow process) has to get a latch (cache buffer chains latch) which protects buckets or linked lists of buffer headers. Once the header desired if found the latch is released. The buffer headers point to the actual data block in memory. Before modifying a block in memory a user has to lock the buffer header. The buffer header is locked any time a modification is made whether it is reading a block into memory or modifying a block that is already in memory. Usually the header is locked only for a brief amount of time but when there is a lot of concurrent access the buffer header can become a bottleneck.
BBW when readling data - read by other session A buffer busy can happen on oracle 7,8 and 9 when one user is reading a block into memory and a second user wants to read that block. Instead of the second user trying to read that block into memory as well, they just wait for the first user to finish. Starting in Oracle 10, this kind of wait was renames "read by other session"
BBW on insert If multiple concurrent users are inserting into a table that doesn't have free lists or is not in an ASSM tablespace then all users will end up inserting into the same block, the first one on the free list and this block will become the hot block
by adding free lists or moving the table to an ASSM tablespace we will alleviate the bottleneck.
Multiple free lists: The other option is ASSM or Automatic Segment Space Management which is set at the tablespace level. In this case free block information is kept in Level 1 BMB (or bitmapped blocks). These Level 1 BMBs are chosen by a hash on the users process ID thus distributing the inserts across the table.
The inserts would look something like this (somewhat exaggerated drawing) the ASSM BMB blocks take up more space in the table , about 1 extra block for every 16 data blocks and there is overhead first looking in the header/level 3 BMB block then going to the Level 2 then level 1 and finally to the datablock but all in all ASSM is worth reduced costs of management verses free lists.
Identifying and creating ASSM tablespaces
Which tablespaces are ASSM or not?
creating an ASSM tablespace:
BBW on index (because of insert)
If users are inserting data that has a rising key value, especially a monotonically rising value, then all the new inserts will have to update the leading edge leaf block of the index and with high concurrent inserts this can cause buffer busy waits.
Solutions Hash partition the index Reverse Key Index
BBW on old style RBS IF block class > 18 it's an old style RBS segment
solution move to new AUM or Automatic Undo Mangement
Solution If you are getting buffer busy waits on the file header block for a tempfile (datafile in a temporary tablespace) then try increasing the "next extent" size in the temporary tablespace. This wait can happen when lots of extents are being allocated in the temporary tablespace.
What Would ADDM do?
Interstingly enough the ADDM page doesn't show the new load that has recently come on the system but the analysis is there. I clicked on the next to bottom line in the page, "Read and write contention on database blocks was consuming significant database time.
Here are the outputs for the different scenarios.
File Header Contention
What would DB Optimizer DO ?
The database below is maxed out. There is more demand for CPU than there is CPU. There is only a small amount of Buffer Busy Waits, but even with that small about we can drill down into the BBW and get all the details. By clicking on "buffer busy wait" under details we can see what SQL was running int the BBWs, what sessions were running into BBWs and we can get all the info we want in order to be able to analyze the BBW under the "Analysis" tab:
Периодически в Oracle 11.2 RAC системе возникают характерные кластерные проблемы, в основном, по причинам неверной конфигурации, например, выбора неподходящего сервиса для выполнения ресурсоёмких бизнес процессов / пакетных заданий
Далее описана наглядная краткосрочная проблема этого типа и, в частности, роль AQ запросов
Итак, AWR показал:
Соответствующий типу SQL ordered by Cluster Wait из AWR список запросов по всем нодам можно получить из таблицы ash_201408071200 (своевременно сделанной копии GV$ACTIVE_SESSION_HISTORY за проблемный период):
или, вместе с объектами межнодовой конкуренции:
— из которого, казалось бы, очевидно, что запросы 1y8zrwnuam2py и 43kfr3uthbugg блокируют друг друга на табличке T_EXPORT с разных нод, однако формально для кластерных ожиданий этих запросов в качестве блокирующего в ASH указывается лишь собственный инстанс, что затрудняет понимание проблемы:
— легко видеть как на конкретных блоках таблицы T_EXPORT идёт плотная конкурентная борьба между запросом 43kfr3uthbugg на 1-м инстансе и 1y8zrwnuam2py на 1-м и 2-м. Кроме этих 2-х в качестве блокирующего заметен d3sgu8r801msz (insert into T_EXPORT…), но вклад этого быстрого запроса/однострочной вставки:
не отражён ни в AWR, ни в статистике:
Пара проблемных запросов к T_EXPORT показывают заметное замедление во время проблемного снапшота за счёт кластерных ожиданий:
— при этом кол-во выполнений EXECS 1-го запроса 1y8zrwnuam2py перед интересующим снапшотом росло и распостранилось на оба инстанса (что и спровоцировало проблемы), второй же 43kfr3uthbugg стабильно выполнялся на одной 1-й ноде
Кроме 2-х вышеперечисленных в топе кластерных запросов присутствует примечательный запрос 5cbp4s5jq04xg (select /*+ INDEX(TAB AQ$_TQ1_I) */ tab.rowid, tab.msgid,… from «U1».»TQ1″ tab … for update skip locked), также показывающий замедление в проблемный период:
Собственно этот запрос рекурсивно вызывается процедурой DBMS_AQ.DEQUEUE из области Oracle Advanced Queuing (AQ)* и успевает выполняться в проблемный период даже реже, чем обычно, также без видимых кросс-инстансных блокировок:
Запрос же с анализом «одномоментных» кластерных ожиданий совпадающих блоков бд показывает дополняет картину конкуренции:
, включая важные детали типа:
- циклических ожиданий gc buffer busy acquire и пар gc buffer busy acquiregc buffer busy release
- небольшого кол-ва блоков AQ таблицы и индекса — от 1 до 4-х, задействованных в «конкурентной борьбе»
Блокирующим при этом ожидаемо является короткий DBMS_AQ.ENQUEUE запрос cc5n5w1r8sc3a (insert into «U1».»TQ1″…), не отражённый в AWR
Причиной последних (AQ-related) блокировок является одновременное заполнение очереди с 2-х нод, несмотря на то, что очистка очереди(dequeue) выполняется грамотно только с 1-й ноды:
что несколько противоречит рекомендациях производителя Oracle Streams AQ and RAC Scalability and Performance Guidelines, однако сами по себе AQ запросы типа 5cbp4s5jq04xg проблем в системе (пока) не создают, а попадают в топ кластерных ожиданий попутно при увеличении нагрузки на Global Cache, сопровождая возникновения кластерных проблем
*) Структура AQ объектов хорошо описана в Julian Dyke. Advanced Queuing Internals, за исключением того, что в качестве хинта dequeue запроса в Oracle 10g использовался /*+ FIRST_ROWS(1) */, а в 11g используется прямое указание автоматически создаваемого индекса о 6-ти полях /*+ INDEX(TAB AQ$_TQ1_I) */
BBW when readling data - read by other session
A buffer busy can happen on oracle 7,8 and 9 when one user is reading a block into memory and a second user wants to read that block. Instead of the second user trying to read that block into memory as well, they just wait for the first user to finish. Starting in Oracle 10, this kind of wait was renames "read by other session"
C.3.2 ARCH Remote Write
Used to track the time (in centiseconds) that ARC n background processes spend blocked waiting for network write operations to complete.
C.3.12 BFILE read
The session waits for a read from a external large object (LOB) to complete.
Wait Time: The total elapsed time for the read to complete
C.3.5 BFILE check if open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
Читайте также: