
Bash если размер файла больше
Как назначить это переменной bash, чтобы впоследствии использовать ее?
Лучше всего, если в системе GNU:
ПРИМЕЧАНИЕ: см. @chbrown ниже ответ, как использовать stat в терминале в Mac OS X или
Проблема с использованием stat заключается в том, что это расширение GNU (Linux). du -k и cut -f1 задаются POSIX и поэтому переносятся в любую систему Unix.
Solaris, например, поставляется с bash, но не с stat . Так что это не совсем гипотетически.
ls имеет аналогичную проблему, так как точный формат вывода не указан, поэтому синтаксический анализ его вывода не может выполняться портативно. du -h также является расширением GNU.
Придерживайтесь переносных конструкций, где это возможно, и вы сделаете чью-то жизнь проще в будущем. Возможно, ваш собственный.
Вы также можете использовать команду «count count» ( wc ):
Проблема с wc заключается в том, что она добавит имя файла и сделает отступ выходным. Например:
Если вы хотите избежать связывания полного интерпретируемого языка или редактора потока только для получения количества файлов, просто перенаправьте входные данные из файла, чтобы wc никогда не видел имя файла:
Эта последняя форма может использоваться с подстановкой команд, чтобы легко получить значение, которое вы искали в качестве переменной оболочки, как указано Жиль ниже.
BSD (Mac OS X) stat имеет другой флаг аргументов формата и разные спецификаторы полей. Из man stat(1) :
- -f format : отображение информации в указанном формате. См. Раздел FORMATS для описания допустимых форматов.
- . раздел FORMATS .
- z : размер файла в байтах.
Итак, теперь все вместе:
Этот сценарий сочетает в себе множество способов расчета размера файла:
Скрипт работает во многих Unix-системах, включая Linux, BSD, OSX, Solaris, SunOS и т. д.
Размер файла показывает количество байтов. Это видимый размер, который представляет собой байты, которые файл использует на типичном диске, без специального сжатия или специальных разреженных областей или нераспределенных блоков и т. Д.
Зависит от того, что вы подразумеваете под size .
предоставит вам количество байтов, которые можно прочитать из файла. IOW, это размер содержимого файла. Однако он прочитает содержимое файла (за исключением того, что файл является обычным файлом или символической ссылкой на обычный файл в большинстве реализаций wc в качестве оптимизации). Это может иметь побочные эффекты. Например, для именованного канала то, что было прочитано, больше не может быть прочитано снова и для таких вещей, как /dev/zero или /dev/random , которые имеют бесконечный размер , это займет некоторое время. Это также означает, что вам нужен read доступ к файлу.
Это стандартная и портативная, однако обратите внимание, что некоторые реализации wc могут включать в себя ведущие пробелы в этом выпуске. Один из способов избавиться от них - использовать:
или во избежание ошибки о пустом арифметическом выражении в dash или yash , когда wc не выводит результат (например, когда файл может " t будет открыт):
ksh93 имеет встроенный wc (при включении его вы также можете вызвать его как команду command /opt/ast/bin/wc ) что делает его наиболее эффективным для обычных файлов в этой оболочке.
В разных системах есть команда под названием stat , которая является интерфейсом к системным вызовам stat() или lstat() .
Данные отчета, найденные в inode. Одна из этих данных - это атрибут st_size . Для обычных файлов это размер содержимого (сколько данных можно было прочитать из него при отсутствии ошибки (это то, что используют большинство wc -c ) в своей оптимизации)). Для символических ссылок это размер в байтах целевого пути. Для именованных каналов, в зависимости от системы, это либо 0, либо количество байтов, находящихся в настоящее время в буфере канала. То же самое для блочных устройств, где в зависимости от системы вы получаете 0 или размер в байтах базового хранилища.
Вам не нужно разрешение на чтение файла для получения этой информации, только разрешение на поиск в каталоге, к которому он привязан.
По хронологическому порядку:
возвращает st_size атрибут $file ( lstat() ) или:
то же самое, за исключением случаев, когда $file является символической ссылкой, и в этом случае это символ st_size файла после разрешения символической ссылки.
zsh stat builtin (теперь также известный как stat ) в модуле zstat (загружается с помощью zsh/stat ) (1997):
или сохранить в переменной:
, очевидно, это наиболее эффективно в этой оболочке.
GNU stat -L -A size +size -- $file (2001); также в BusyBox stat с 2005 года (скопировано из GNU stat ):
AIX также имеет perl -le 'print((lstat shift)[7])' -- "$file" , который выведет все istat (не stat() , поэтому не будет работать с символическими ссылками), и что вы может выполнять пост-обработку, например:
В LC_ALL=C istat "$file" | awk 'NR == 4 ' :
(размер после разрешения символической ссылки)
Задолго до того, как GNU представила свой @ size = -Z $file:q команды, то же самое можно было бы сделать с помощью команды GNU stat с ее предикатом find (уже в 1991 году):
Стандартная команда для получения информации ( / stat() : lstat() .
POSIXly, вы можете сделать:
и добавьте LC_ALL=C ls -dn -- "$file" | awk '' для него после разрешения symlink. Это не работает для файлов устройств, хотя поле 5 th является основным номером устройства, а не размером.
Для блочных устройств, систем, где -L возвращает 0 для stat() , обычно имеют другие API-интерфейсы, чтобы сообщать размер блочного устройства. Например, Linux имеет st_size BLKGETSIZE64 , и большинство дистрибутивов Linux теперь поставляются с командой ioctl() , которая может ее использовать:
Однако для этого вам требуется разрешение на чтение файла устройства. Обычно можно получить размер другими способами. Например (еще в Linux):
Должна работать, кроме пустых устройств.
Подход, который работает для всех файлов с возможностью поиска (включая обычные файлы, большинство блочных устройств и некоторые символьные устройства), заключается в том, чтобы открыть файл и найти его до конца:
С помощью lsblk -bdno size -- "$device_file" (после загрузки модуля zsh ):
Для именованных каналов мы видели, что некоторые системы (AIX, Solaris, HP /UX, по крайней мере) делают объем данных в буфере каналов доступным в perl -le 'seek STDIN, 0, 2 or die "seek: $!"; print tell STDIN' < "$file" ' stat() . Некоторые (например, Linux или FreeBSD) этого не делают.
В Linux, по крайней мере, вы можете использовать st_size FIONREAD после открытия канала (в режиме чтения + записи, чтобы избежать его зависания):
Однако обратите внимание, что, хотя он не читает содержимое канала, простое открытие именованного канала здесь может по-прежнему иметь побочные эффекты. Мы используем fuser -s -- "$fifo_file" && perl -le 'require "sys/ioctl.ph"; ioctl(STDIN, &FIONREAD, $n) or die$!; print unpack "L", $n' <> "$fifo_file" , чтобы сначала проверить, что в каком-то процессе уже открыт канал, чтобы облегчить это, но это не является надежным, поскольку fuser , возможно, не сможет проверить все процессы.
Теперь мы рассматриваем только размер первичных данных, связанных с файлами. Это не учитывает размер метаданных и всю вспомогательную инфраструктуру, необходимую для хранения этого файла.
Другой атрибут inode, возвращаемый fuser , это stat() . Это число блоков по 512 байт, которые используются для хранения данных файла (а иногда и некоторых его метаданных, таких как расширенные атрибуты файловых систем ext4 в Linux). Это не включает сам индекс или записи в каталогах, к которым связан файл.
Размер и использование диска не обязательно тесно связаны с сжатием, редкостью (иногда некоторыми метаданными), дополнительная инфраструктура, такая как косвенные блоки в некоторых файловых системах, влияет на последних.
Обычно для использования дискового пространства используется st_blocks . Большинство команд, перечисленных выше, смогут получить эту информацию.
- du
- POSIXLY_CORRECT=1 ls -sd -- "$file" | awk '' (не для каталогов, где это будет включать использование файлов в файлах внутри).
- GNU POSIXLY_CORRECT=1 du -s -- "$file"
- find -- "$file" -printf '%b\n'
- GNU zstat -L +block -- $file
- BSD stat -c %b -- "$file"
- stat -f %b -- "$file"
ls -l filename предоставит вам много информации о файле, включая его размер файла, разрешения и владельца.
Размер файла в пятом столбце и отображается в байтах. В приведенном ниже примере размер файла составляет менее 2 КБ:
Изменить: Это, по-видимому, не так надежно, как команда stat .
I've got a script that checks for 0-size, but I thought there must be an easier way to check for file sizes instead. I.e. file.txt is normally 100 kB; how can I make a script check if it is less than 90 kB (including 0), and make it Wget a new copy because the file is corrupt in this case?
What I'm currently using.
12 Answers 12
[ -n file.txt ] doesn't check its size. It checks that the string file.txt is non-zero length, so it will always succeed.
If you want to say "size is non-zero", you need [ -s file.txt ] .
To get a file's size, you can use wc -c to get the size (file length) in bytes:
In this case, it sounds like that's what you want.
But FYI, if you want to know how much disk space the file is using, you could use du -k to get the size (disk space used) in kilobytes:
If you need more control over the output format, you can also look at stat . On Linux, you'd start with something like stat -c '%s' file.txt , and on BSD and Mac OS X, something like stat -f '%z' file.txt .
Use wc -c < "$file" (note the < ), in which case you don't need the | cut . part (which, as posted, doesn't work on OSX). The minimum BLOCKSIZE value for du on OSX is 512 .
Is it not inefficient to read the file to determine it's size? I think stat will not read the file to see it's size.
@PetriSirkkala On my Linux system, wc -c
stat can also check the file size. Some methods are definitely better: using -s to find out whether the file is empty or not is easier than anything else if that's all you want. And if you want to find files of a size, then find is certainly the way to go.
I also like du a lot to get file size in kb, but, for bytes, I'd use stat :
The difference between GNU and BSD is what, unfortunately, makes this alternative a bit less attractive. :(
stat can be misleading if the file is sparse. You could use the blocks reported by stat to calculate space used.
@AjithAntony That's an interesting point which did not occur to me. I can see stat being the right thing in some situations, and sparse files are not relevant in most situations, though certainly not all.
An alternative solution with AWK and double parenthesis:
Nice, but won't work on OSX, where du doesn't support -b . (It may be a conscious style choice, but just to mention the alternative: you can omit the $ prefix inside (( . )) when referencing variables: ((SIZE<90000)) )
@fstab, you may ommit awk by using read ( bash internal command): read SIZE _ <<<$(du -sb "$FILENAME")
If your find handles this syntax, you can use it:
This will output file.txt to stdout if and only if the size of file.txt is less than 90k. To execute a script script if file.txt has a size less than 90k:
+1, but to also make it work on OSX, you need an explicit target directory argument, e.g.: find . -maxdepth 1 -name "file.txt" -size -90k
If you are looking for just the size of a file:
wc -c "$file" was given as an answer in 2011 (three years ago). Yes, wc -c "$file" has the problem that it outputs the file name as well as the character count, so the early answers added a command to separate out the count. But wc -c < "$file" , which fixes that problem, was added as a comment in May 2014. Your answer is equivalent to that, except it adds a “useless use of cat ”. Also, you should quote all shell variable references unless you have a good reason not to.
You can make this more efficient by using head -c instead of cat.if [ $(head -c 90000 $file | wc -c) -lt 90000 ] ; then echo "File is smaller than 90k" ; fi . Tested on CentOS, so it may or may not work on BSD or OSX.
This works in both Linux and macOS:
It is portable, for all flavours of Python, and it avoids variation in stat dialects.
But the question was about checking for a file size threshold, e.g. 100 KB, not just getting the file size.
For getting the file size in both Linux and Mac OS X (and presumably other BSD systems), there are not many options, and most of the ones suggested here will only work on one system.
what does work in both Linux and Mac's Bash:
The other answers work fine in Linux, but not in Mac:
du doesn't have a -b option in Mac, and the BLOCKSIZE=1 trick doesn't work ("minimum blocksize is 512", which leads to a wrong result)
cut -d' ' -f1 doesn't work because on Mac, the number may be right-aligned, padded with spaces in front.
So if you need something flexible, it's either perl 's -s operator , or wc -c piped to awk '' (awk will ignore the leading white space).
And of course, regarding the rest of your original question, use the -lt (or -gt ) operator:
Я новый пользователь сценариев оболочки bash. Как узнать размер файла в моем сценарии оболочки bash и сохранить этот размер файла в переменной оболочки bash?
Вы не можете получить размер файла в сценарии bash, используя внутреннюю или встроенную команду. Вам понадобятся несколько команд, включая stat. Командная строка stat отображает информацию о файле, включая его размер. Другой вариант — использовать команду wc, которая может подсчитывать количество байтов в каждом заданном файле. Давайте посмотрим, как использовать эти две команды для проверки размера файла в Linux или Unix-подобной системе.
Примеры команды du
Синтаксис выглядит следующим образом
Примеры возможных выводов данных указанных выше команд:
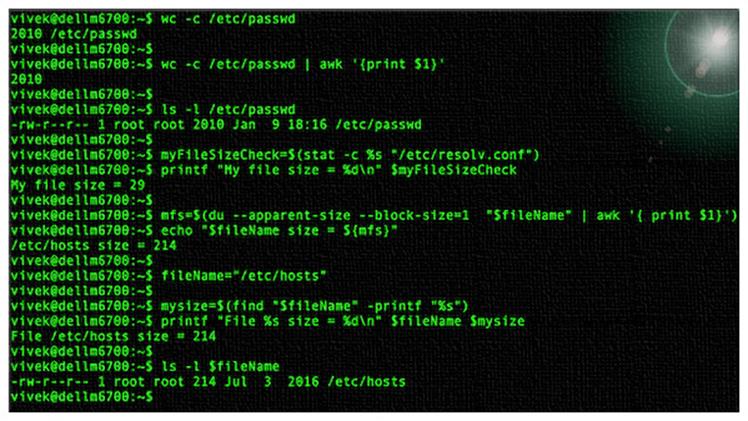
Рисунок 01: Как проверить размер файла с помощью оболочки bash/ksh/zsh/sh/tcsh?
How do I assign this to a bash variable so I can use it later?
In case of (very narrow) XY problem, this is neat: if all you need is to test the file has a nonzero size, bash has a conditional expression -s , so you may simply test if a file has nonzero length with if [ -s file ]; then echo "file has nonzero size" ; fi
Как проверить размер файла в unix с помощью команды wc
Команда wc показывает количество строк, слов и байтов, содержащихся в файле. Для получения размера файла, используйте синтаксис, который выглядит следующим образом:
Примеры возможных выводов данных:
Вы может с легкостью извлечь первое поле, используя или команду cut или команду awk:
Примеры возможных выводов данных:
или присвоить этот размер переменной bash:
13 Answers 13
Your best bet if on a GNU system:
In a bash script :
NOTE: see @chbrown's answer for how to use stat in terminal on Mac OS X.
@haunted85 stat is the most straightforward way, assuming you're using Linux or Cygwin ( stat isn't standard). wc -c as suggested by Eugéne is portable.
@woohoo Your prompt overwrites the output. man stat says that --printf omits the trailing newline. Use --format or -c to see the output. Gain more insight by comparing stat --printf="%s" file.any | xxd - to stat -c "%s" file.any | xxd -
The problem with using stat is that it is a GNU (Linux) extension. du -k and cut -f1 are specified by POSIX and are therefore portable to any Unix system.
Solaris, for example, ships with bash but not with stat . So this is not entirely hypothetical.
ls has a similar problem in that the exact format of the output is not specified, so parsing its output cannot be done portably. du -h is also a GNU extension.
Stick to portable constructs where possible, and you will make somebody's life easier in the future. Maybe your own.
du doesn't give the size of the file, it gives an indication of how much space the file uses, which is subtly different (usually the size reported by du is the size of the file rounded up to the nearest number of blocks, where a block is typically 512B or 1kB or 4kB).
@fralau: The OP wants to "assign this to a bash variable so they can use it later", so it is much more likely they want an actual numeric value, not a human-readable approximation. Also, -h is a GNU extension; it is not standard
Using du with --apparent-size flag will return a more precise size (as stated on man : print apparent sizes, rather than disk usage; although the apparent size is usually smaller, it may be larger due to holes in ('sparse') files, internal fragmentation, indirect blocks, and the like )
You could also use the "word count" command ( wc ):
The problem with wc is that it'll add the filename and indent the output. For example:
If you would like to avoid chaining a full interpreted language or stream editor just to get a file size count, just redirect the input from the file so that wc never sees the filename:
This last form can be used with command substitution to easily grab the value you were seeking as a shell variable, as mentioned by Gilles below.
Just one more point: I just tested it and wc -c < file seems to be very fast, at least on OS X. I'm guessing that wc has the brains to try to stat the file if only -c is specified.
@EdwardFalk: GNU wc -c uses fstat , but then seeks to second-last block of the file and reads the last up-to st_blksize bytes. Apparently this is because files in Linux's /proc and /sys for example have stat sizes that are only approximate, and wc wants to report the actual size, not the stat-reported size. I guess it would be weird for wc -c to report a different size than wc , but it's not idea to read data from the file if it's a normal disk file, and it's not in memory. Or worse, near-line tape storage.
It seems like printf still sees the indentation, e.g. printf "Size: $size" -> size: <4 spaces>54339 . On the other hand echo ignores the whitespace. Any way to make it consistent?
@keithpjolley: By calling fstat . Try running strace wc -c
BSD's (macOS's) stat has a different format argument flag, and different field specifiers. From man stat(1) :
- -f format : Display information using the specified format. See the FORMATS section for a description of valid formats.
- . the FORMATS section .
- z : The size of file in bytes.
So all together now:
NOTE: see @b01's answer for how to use the stat command on GNU/Linux systems. :)
Depends what you mean by size.
will give you the number of bytes that can be read from the file. IOW, it's the size of the content of the file. It will however read the contents of the file (except if the file is a regular file or symlink to regular file in most wc implementations as an optimisation). That may have side effects. For instance, for a named pipe, what has been read can no longer be read again and for things like /dev/zero or /dev/random which are of infinite size, it's going to take a while. That also means you need read permission to the file, and the last access timestamp of the file may be updated.
That's standard and portable, however note that some wc implementations may include leading blanks in that output. One way to get rid of them is to use:
or to avoid an error about an empty arithmetic expression in dash or yash when wc produces no output (like when the file can't be opened):
ksh93 has wc builtin (provided you enable it, you can also invoke it as command /opt/ast/bin/wc ) which makes it the most efficient for regular files in that shell.
Various systems have a command called stat that's an interface to the stat() or lstat() system calls.
Those report information found in the inode. One of that information is the st_size attribute. For regular files, that's the size of the content (how much data could be read from it in the absence of error (that's what most wc -c implementations use in their optimisation)). For symlinks, that's the size in bytes of the target path. For named pipes, depending on the system, it's either 0 or the number of bytes currently in the pipe buffer. Same for block devices where depending on the system, you get 0 or the size in bytes of the underlying storage.
You don't need read permission to the file to get that information, only search permission to the directory it is linked to.
By chronological order, there is:
returns the st_size attribute of $file ( lstat() ) or:
same except when $file is a symlink in which case it's the st_size of the file after symlink resolution.
zsh stat builtin (now also known as zstat ) in the zsh/stat module (loaded with zmodload zsh/stat ) (1997):
or to store in a variable:
obviously, that's the most efficient in that shell.
GNU stat (2001); also in BusyBox stat since 2005 (copied from GNU stat ):
(note the meaning of -L is reversed compared to IRIX or zsh stat .
Or you can use the stat() / lstat() function of some scripting language like perl :
AIX also has an istat command which will dump all the stat() (not lstat() , so won't work on symlinks) information and which you could post-process with, for example:
(size after symlink resolution)
Long before GNU introduced its stat command, the same could be achieved with GNU find command with its -printf predicate (already in 1991):
One issue though is that doesn't work if $file starts with - or is a find predicate (like ! , ( . ).
The standard command to get the stat() / lstat() information is ls .
POSIXly, you can do:
and add -L for the same after symlink resolution. That doesn't work for device files though where the 5 th field is the device major number instead of the size.
For block devices, systems where stat() returns 0 for st_size , usually have other APIs to report the size of the block device. For instance, Linux has the BLKGETSIZE64 ioctl() , and most Linux distributions now ship with a blockdev command that can make use of it:
However, you need read permission to the device file for that. It's usually possible to derive the size by other means. For instance (still on Linux):
Should work except for empty devices.
An approach that works for all seekable files (so includes regular files, most block devices and some character devices) is to open the file and seek to the end:
With zsh (after loading the zsh/system module):
For named pipes, we've seen that some systems (AIX, Solaris, HP/UX at least) make the amount of data in the pipe buffer available in stat() 's st_size . Some (like Linux or FreeBSD) don't.
On Linux at least, you can use the FIONREAD ioctl() after having open the pipe (in read+write mode to avoid it hanging):
However note that while it doesn't read the content of the pipe, the mere opening of the named pipe here can still have side effects. We're using fuser to check first that some process already has the pipe open to alleviate that but that's not foolproof as fuser may not be able to check all processes.
Now, so far we've only been considering the size of the primary data associated with the files. That doesn't take into account the size of the metadata and all the supporting infrastructure needed to store that file.
Another inode attribute returned by stat() is st_blocks . That's the number of 512 byte (1024 on HP/UX) blocks that is used to store the file's data (and sometimes some of its metadata like the extended attributes on ext4 filesystems on Linux). That doesn't include the inode itself, or the entries in the directories the file is linked to.
Size and disk usage are not necessarily tightly related as compression, sparseness (sometimes some metadata), extra infrastructure like indirect blocks in some filesystems have an influence on the latter.
That's typically what du uses to report disk usage. Most of the commands listed above will be able to get you that information.
Как мне присвоить это переменной bash, чтобы я мог использовать ее позже?
Ваш лучший выбор, если в системе GNU:
ПРИМЕЧАНИЕ: см . Ответ @ chbrown о том, как использовать stat в терминале в Mac OS X.
@ haunted85 stat - самый простой способ, при условии, что вы используете Linux или Cygwin ( stat не является стандартным). wc -c как предложено Евгением, является портативным.
@woohoo Ваша подсказка перезаписывает вывод. man stat говорит, что --printf пропускает завершающий перевод строки. Используйте --format или, -c чтобы увидеть результат. Получить больше понимания путем сравнения stat --printf="%s" file.any | xxd - с stat -c "%s" file.any | xxd -
Проблема с использованием stat заключается в том, что это расширение GNU (Linux). du -k и cut -f1 определяются POSIX и поэтому переносимы на любую систему Unix.
Солярис, например, поставляется с Bash, но не с stat . Так что это не совсем гипотетически.
ls имеет аналогичную проблему в том, что точный формат вывода не указан, поэтому анализ его вывода не может быть выполнен переносимым. du -h также расширение GNU.
Придерживайтесь переносных конструкций, где это возможно, и в будущем вы сделаете чью-то жизнь проще. Может быть, ваш собственный.
du не дает размер файла, он показывает, сколько места занимает файл, что немного отличается (обычно размер, о котором сообщается, du - это размер файла, округленный до ближайшего числа блоков, где блок обычно составляет 512B или 1kB или 4kB).
Параметр -h ("человек") du даст наиболее подходящий ответ для общих случаев: file_size=`du -h "$filename" | cut -f1 он будет отображать K (килобайт), M (мегабайт) или G (гигабайт) в зависимости от ситуации.
@fralau: OP хочет «назначить это переменной bash, чтобы они могли использовать ее позже», так что гораздо более вероятно, что они хотят получить фактическое числовое значение, а не понятное для человека приближение. Кроме того, -h это расширение GNU; это не стандартно
Вы также можете использовать команду «подсчет слов» ( wc ):
Проблема в wc том, что он добавит имя файла и сделает отступ. Например:
Если вы хотите избежать создания цепочки полностью интерпретируемого языка или потокового редактора просто для того, чтобы получить счетчик размера файла, просто перенаправьте ввод из файла, чтобы wc никогда не видеть имя файла:
Эта последняя форма может использоваться с подстановкой команд, чтобы легко получить значение, которое вы искали, как переменную оболочки, как упомянуто Жилем ниже.
wc -c
Еще один момент: я только что проверил это и, wc -c < file кажется, очень быстро, по крайней мере, на OS X. Я предполагаю, что у wc есть мозги, чтобы попытаться определить файл, если указан только -c.
@EdwardFalk: GNU wc -c использует fstat , но затем ищет второй-последний блок файла и читает последние st_blksize байты. Очевидно, это связано с тем, что файлы в Linux /proc и, /sys например, имеют размеры статистики, которые являются только приблизительными , и wc хотят сообщить фактический размер, а не размер, указанный в статистике. Я предполагаю, что было бы странно wc -c сообщать о размере, отличном wc от указанного, но считывать данные из файла не рекомендуется, если это обычный файл на диске и он не находится в памяти. Или еще хуже, почти линия хранения ленты .
Кажется, что printf все еще видит отступ, например printf "Size: $size" -> size: <4 spaces>54339 . С другой стороны echo игнорирует пробелы. Любой способ сделать это последовательным?
@keithpjolley: по телефону fstat . Попробуйте запустить, strace wc -c
У BSD (Mac OS X) stat есть другой флаг аргумента формата и другие спецификаторы поля. От man stat(1) :
- -f format : Отображение информации в указанном формате. Смотрите раздел FORMATS для описания допустимых форматов.
- . раздел ФОРМАТЫ .
- z : Размер файла в байтах.
Итак, все вместе сейчас:
Зависит от того, что вы подразумеваете под размером .
даст вам количество байтов, которые можно прочитать из файла. IOW, это размер содержимого файла. Тем не менее, он будет читать содержимое файла (за исключением случаев, когда файл является обычным файлом или символической ссылкой на обычный файл в большинстве wc реализаций в качестве оптимизации). Это может иметь побочные эффекты. Например, для именованного канала, то, что было прочитано, больше не может быть прочитано снова, а для таких вещей, как /dev/zero или /dev/random которые имеют бесконечный размер, это займет некоторое время. Это также означает, что вам нужно read разрешение на файл, и последняя отметка времени доступа к файлу может быть обновлена.
Это стандартно и переносимо, однако обратите внимание, что некоторые wc реализации могут включать начальные пробелы в этом выводе. Один из способов избавиться от них - использовать:
или чтобы избежать ошибки о пустом арифметическом выражении в dash или yash когда wc ничего не выводится (например, когда файл не может быть открыт):
ksh93 имеет wc встроенную функцию (при условии, что вы ее включите, вы также можете вызывать ее как command /opt/ast/bin/wc ), что делает ее наиболее эффективной для обычных файлов в этой оболочке.
Различные системы имеют команду с именем , stat что это интерфейс к stat() или lstat() системным вызовам.
Те сообщают информацию, найденную в inode. Одной из этих сведений является st_size атрибут. Для обычных файлов это размер контента (сколько данных можно прочитать из него при отсутствии ошибок (это то, что большинство wc -c реализаций используют при оптимизации)). Для символических ссылок это размер в байтах целевого пути. Для именованных каналов, в зависимости от системы, это либо 0, либо количество байтов, находящихся в данный момент в буфере канала. То же самое для блочных устройств, где в зависимости от системы вы получаете 0 или размер в байтах базового хранилища.
Вам не нужно разрешение на чтение файла, чтобы получить эту информацию, только разрешение на поиск в каталоге, с которым он связан.
По хронологическому порядку есть:
возвращает st_size атрибут $file ( lstat() ) или:
То же самое, за исключением случаев, когда $file это символическая ссылка, и в этом случае это st_size файл после разрешения символической ссылки.
zsh stat Встроенный (теперь также известный как zstat ) в zsh/stat модуле (загружен с zmodload zsh/stat ) (1997):
или хранить в переменной:
очевидно, это самый эффективный в этой оболочке.
GNU stat (2001); также в BusyBox stat с 2005 года (скопировано из GNU stat ):
(обратите внимание, что значение -L обратное по сравнению с IRIX или zsh stat .
Или вы можете использовать stat() / lstat() функцию некоторых скриптовых языков, таких как perl :
В AIX также есть istat команда, которая будет выгружать всю информацию stat() (нет lstat() , поэтому не будет работать с символическими ссылками) и которую вы могли бы обработать, например:
(размер после разрешения символической ссылки)
Задолго до того, как GNU представила свою stat команду, того же можно добиться с помощью find команды GNU с ее -printf предикатом (уже в 1991 году):
Одна проблема , хотя в том , что не работает , если $file начинается с - или в find предикат (например ! , ( . ).
Стандартная команда для получения информации stat() / . lstat() ls
POSIXly, вы можете сделать:
и добавить -L то же самое после разрешения символической ссылки. Это не работает для файлов устройств, хотя 5- е поле - это номер устройства, а не его размер.
Однако для этого вам нужно разрешение на чтение файла устройства. Обычно можно получить размер другими способами. Например (все еще в Linux):
Должно работать за исключением пустых устройств.
Подход, который работает для всех доступных для поиска файлов (включая обычные файлы, большинство блочных устройств и некоторые символьные устройства), заключается в открытии файла и поиске до конца:
С zsh (после загрузки zsh/system модуля):
Для именованных каналов мы видели, что некоторые системы (по крайней мере, AIX, Solaris, HP / UX) делают объем данных в буфере канала доступным в stat() 's st_size . Некоторые (например, Linux или FreeBSD) этого не делают.
По крайней мере, в Linux вы можете использовать FIONREAD ioctl() после открытия канала (в режиме чтения + записи, чтобы избежать его зависания):
Однако обратите внимание, что хотя он не читает содержимое канала, простое открытие именованного канала может иметь побочные эффекты. fuser Сначала мы используем, чтобы проверить, что какой-то процесс уже имеет открытую трубу, чтобы облегчить это, но это не является надежной задачей, так как fuser не может проверить все процессы.
Пока что мы рассматривали только размер первичных данных, связанных с файлами. Это не учитывает размер метаданных и всю вспомогательную инфраструктуру, необходимую для хранения этого файла.
Другой атрибут inode, возвращаемый stat() is st_blocks . Это количество 512-байтовых блоков, которое используется для хранения данных файла (а иногда и некоторых его метаданных, таких как расширенные атрибуты в файловых системах ext4 в Linux). Это не включает в себя сам индекс или записи в каталогах, с которыми связан файл.
Размер и использование диска не обязательно тесно связаны как сжатие, разреженность (иногда некоторые метаданные), дополнительная инфраструктура, например косвенные блоки в некоторых файловых системах, влияют на последнюю.
Это обычно то, что du используется, чтобы сообщить об использовании диска. Большинство команд, перечисленных выше, смогут получить эту информацию.
- POSIXLY_CORRECT=1 ls -sd -- "$file" | awk ''
- POSIXLY_CORRECT=1 du -s -- "$file" (не для каталогов, где это будет включать в себя использование диска файлов внутри).
- GNU find -- "$file" -printf '%b\n'
- zstat -L +block -- $file
- GNU stat -c %b -- "$file"
- BSD stat -f %b -- "$file"
- perl -le 'print((lstat shift)[12])' -- "$file"
явно самый полный и информационный ответ. благодарю вас. я могу использовать это для создания межплатформенных скриптов bash, используя информацию статистики BSD и GNU
Интересный факт: GNU coreutils wc -c использует fstat , но затем читает последние st_blksize байты. Очевидно, это потому, что файлы в Linux /proc и, /sys например, имеют размеры статистики, которые являются только приблизительными . Это хорошо для корректности, но плохо, если конец файла находится на диске, а не в памяти (особенно, если он используется во многих файлах в цикле). И очень плохо, если файл переносится в ленточное хранилище с близким сроком хранения или, например, в файловую систему с прозрачной декомпрессией FUSE.
@StevenPenny - это -go будут SysV, они не будут работать на BSD (опционально (XSI) в POSIX). Вам также понадобится ls -god file | awk '
@ αғsнιη Unix API не делает различий между текстовыми и двоичными файлами. Это все последовательности байтов. Некоторым приложениям может потребоваться интерпретировать эти байты как текст, но, очевидно, нет, wc -c который сообщает количество байтов.
Этот скрипт объединяет множество способов расчета размера файла:
Скрипт работает во многих системах Unix, включая Linux, BSD, OSX, Solaris, SunOS и т. Д.
Размер файла показывает количество байтов. Это очевидный размер, который представляет собой байты, которые файл использует на типичном диске, без специального сжатия, особых разреженных областей, нераспределенных блоков и т. Д.
Как узнать размер файла в сценарии bash, используя команду stat
Команда stat показывает информацию о файле. Используйте следующий синтаксис для того, чтобы узнать размер файла на GNU/Linux с помощью команды stat:
Чтобы присвоить этот размер переменной bash:
Используйте следующий синтаксис для того, чтобы узнать размер файла на BSD/MacOS с помощью команды
Обратите внимание, что если файл является символьной ссылкой, вы получите размер этой ссылки только с помощью команды stat.
Читайте также: