
Ascii файл что это
ASCII (англ. American Standard Code for Information Interchange ) — американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов. В американском варианте английского языка произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски произносится также [а́ски] или [аски́].
Структурные свойства таблицы
-
0—9 представляются своими двоичными значениями (например, 5=01012), перед которыми стоит 00112. Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева 00112 к каждому двоично-десятичному полубайту. A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит 1002 (для букв верхнего регистра) или 1102 (для букв нижнего регистра).
Что это такое?
ASCII представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов. Иными словами происходит кодирование алфавита и десятичных цифр в соответствующие символы, представляющие и несущие в себе необходимую информацию.

Кодировка ASCII была разработана в Америке, поэтому стандартная кодировочная таблица обычно включает в себя английский алфавит с цифрами, что в общей сложности составляет около 128 символов. Но тогда возникает справедливый вопрос: что делать, если необходима кодировка национального алфавита?
Для решения подобных вопросов были разработаны другие версии таблицы ASCII . Например, для языков с иноязычной структурой были или убраны буквы английского алфавита, или к ним добавлялись дополнительные символы в виде национального алфавита. Так, в кодировке ASCII могут присутствовать русские буквы для национального использования (см. скриншот №2).

Как открыть файл ASCII?
Причин, по которым у вас возникают проблемы с открытием файлов ASCII в данной системе, может быть несколько. С другой стороны, наиболее часто встречающиеся проблемы, связанные с файлами ASCII Text Format, не являются сложными. В большинстве случаев они могут быть решены быстро и эффективно без помощи специалиста. Ниже приведен список рекомендаций, которые помогут вам выявить и решить проблемы, связанные с файлами.
Шаг 1. Получить Text editor

Наиболее распространенной причиной таких проблем является отсутствие соответствующих приложений, поддерживающих файлы ASCII, установленные в системе. Наиболее очевидным решением является загрузка и установка Text editor или одной из перечисленных программ: Windows Notepad, Nvu, NotePad++ text editor. Выше вы найдете полный список программ, которые поддерживают ASCII файлы, классифицированные в соответствии с системными платформами, для которых они доступны. Если вы хотите загрузить установщик Text editor наиболее безопасным способом, мы рекомендуем вам посетить сайт и загрузить его из официальных репозиториев.
Шаг 2. Проверьте версию Text editor и обновите при необходимости

Если проблемы с открытием файлов ASCII по-прежнему возникают даже после установки Text editor, возможно, у вас устаревшая версия программного обеспечения. Проверьте веб-сайт разработчика, доступна ли более новая версия Text editor. Разработчики программного обеспечения могут реализовать поддержку более современных форматов файлов в обновленных версиях своих продуктов. Если у вас установлена более старая версия Text editor, она может не поддерживать формат ASCII. Все форматы файлов, которые прекрасно обрабатывались предыдущими версиями данной программы, также должны быть открыты с помощью Text editor.
Шаг 3. Свяжите файлы ASCII Text Format с Text editor
Если у вас установлена последняя версия Text editor и проблема сохраняется, выберите ее в качестве программы по умолчанию, которая будет использоваться для управления ASCII на вашем устройстве. Метод довольно прост и мало меняется в разных операционных системах.
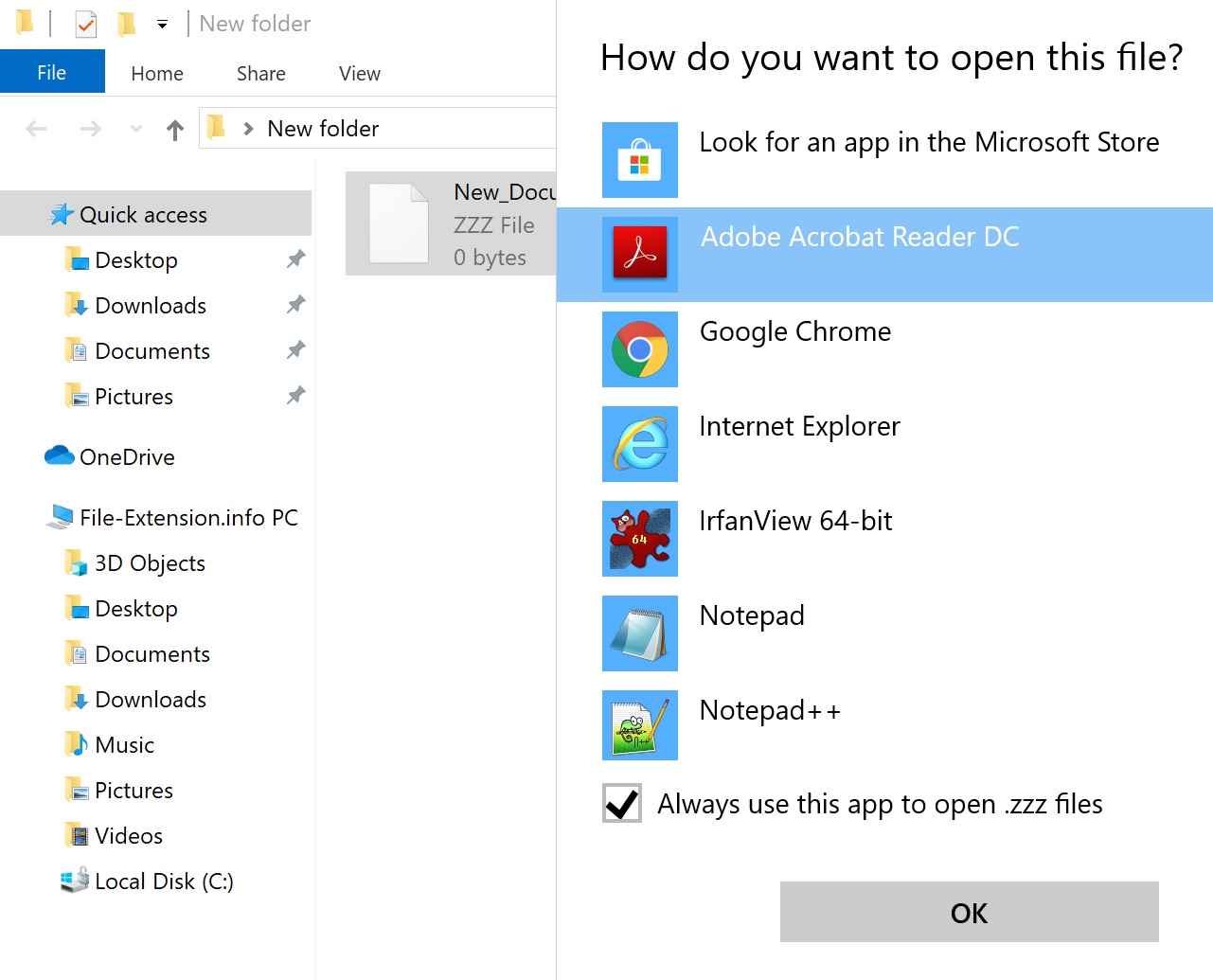
Изменить приложение по умолчанию в Windows
- Выберите пункт Открыть с помощью в меню «Файл», к которому можно щелкнуть правой кнопкой мыши файл ASCII.
- Нажмите Выбрать другое приложение и затем выберите опцию Еще приложения
- Чтобы завершить процесс, выберите Найти другое приложение на этом. и с помощью проводника выберите папку Text editor. Подтвердите, Всегда использовать это приложение для открытия ASCII файлы и нажав кнопку OK .
Изменить приложение по умолчанию в Mac OS
Шаг 4. Убедитесь, что файл ASCII заполнен и не содержит ошибок
Если вы выполнили инструкции из предыдущих шагов, но проблема все еще не решена, вам следует проверить файл ASCII, о котором идет речь. Вероятно, файл поврежден и, следовательно, недоступен.

1. ASCII может быть заражен вредоносным ПО - обязательно проверьте его антивирусом.
Если файл заражен, вредоносная программа, находящаяся в файле ASCII, препятствует попыткам открыть его. Рекомендуется как можно скорее сканировать систему на наличие вирусов и вредоносных программ или использовать онлайн-антивирусный сканер. ASCII файл инфицирован вредоносным ПО? Следуйте инструкциям антивирусного программного обеспечения.
2. Проверьте, не поврежден ли файл
3. Убедитесь, что у вас есть соответствующие права доступа
Иногда для доступа к файлам пользователю необходимы права администратора. Войдите в систему, используя учетную запись администратора, и посмотрите, решит ли это проблему.
4. Убедитесь, что в системе достаточно ресурсов для запуска Text editor
Если в системе недостаточно ресурсов для открытия файлов ASCII, попробуйте закрыть все запущенные в данный момент приложения и повторите попытку.
5. Убедитесь, что у вас установлены последние версии драйверов, системных обновлений и исправлений
Регулярно обновляемая система, драйверы и программы обеспечивают безопасность вашего компьютера. Это также может предотвратить проблемы с файлами ASCII Text Format. Возможно, что одно из доступных обновлений системы или драйверов может решить проблемы с файлами ASCII, влияющими на более старые версии данного программного обеспечения.
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Свойства таблицы ASCII
Как и любая систематизированная программа, ASCII обладает своими характерными свойствами. Так, например, десятеричная система исчисления (цифры от 0 до 9) преобразуется в двоичную систему исчисления (т.е. каждая десятеричная цифра преобразуется в двоичную 288=1001000 соответственно).
Буквы, располагающиеся в верхних и нижних колонках, отличаются друг от друга лишь битом, что существенно снижает уровень сложности проверки и редактирование регистра.
При всех этих свойствах кодировка ASCII работает как восьми битная, хотя изначально предусматривалась как семи битная.
Применение ASCII в программах Microsoft Office:
В случае необходимости данный вариант кодирования информации может быть использован в Microsoft Notepad и Microsoft Office Word. В рамках этих приложений документ может быть сохранен в формате ASCII , но в этом случае при наборе текста невозможно будет использование некоторых функций.
В частности, будет недоступно выделение жирным и полужирным шрифтом, потому что кодирование сохраняет лишь смысл набранной информации, а не общий вид и форму. Добавить такие коды в документ вы можете с помощью следующих программных приложений:
- Microsoft Excel;
- Microsoft FrontPage;
- Microsoft InfoPath;
- Microsoft OneNote;
- Microsoft Outlook;
- Microsoft PowerPoint;
- Microsoft Project.
При этом стоит учитывать, что набирая код ASCII в этих приложениях необходимо удерживать нажатой клавиатурную клавишу ALT.
Конечно, все необходимые коды требует более длительного и обстоятельного изучения, но это выходит за пределы нашей сегодняшней статьи. Надеюсь, что она оказалась для Вас действительно полезной.
Программы, которые поддерживают ASCII расширение файла
В следующем списке перечислены программы, совместимые с файлами ASCII, которые разделены на категории 3 в зависимости от операционной системы, в которой они доступны. ASCII файлы можно встретить на всех системных платформах, включая мобильные, но нет гарантии, что каждый из них будет должным образом поддерживать такие файлы.
Национальные варианты ASCII
Для некоторых языков с нелатинской письменностью (русского, греческого, арабского, иврита) существовали более радикальные модификации ASCII. Одним из вариантов был отказ от строчных латинских букв — на их месте размещались национальные символы (для русского и греческого — только заглавные буквы). Другой вариант — переключение между US-ASCII и национальным вариантом «на лету» с помощью символов SO (Shift Out) и SI (Shift In) — в этом случае в национальном варианте можно полностью устранить латинские буквы и занять всё пространство под свои символы. См. также КОИ-7.
В Юникоде первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
Содержание
Управляющие символы
(После названия каждого символа указан его 16-ричный код)
Предпосылки Unicode
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Программы, обслуживающие файл ASCII

Windows

MAC OS

Linux
Наложение символов
Благодаря символу BS (возврат на шаг) на принтере можно печатать один символ поверх другого. В ASCII было предусмотрено добавление таким образом диакритики к буквам, например:
- a BS ' → á
- a BS ` → à
- a BS ^ → â
- o BS / → ø
- c BS , → ç
- n BS ~ → ñ
Примечание: в старых шрифтах апостроф ' рисовался с наклоном влево, а тильда ~ была сдвинута вверх, так что они как раз подходили на роль акута и тильды сверху.
Если на символ накладывается тот же символ, то получается эффект жирного шрифта, а если на символ накладывается подчёркивание, то получается подчёркнутый текст.
Примечание: это используется, например, в справочной системе man.
Представление ASCII в ЭВМ
На тех компьютерах, где минимально адресуемой единицей памяти было 36-битное слово, поначалу использовали 6-битные символы (1 слово = 6 символов). После перехода на ASCII на таких компьютерах в одном слове стали размещать либо 5 семибитных символов (1 бит оставался лишним), либо 4 девятибитных символа.
ASCII-коды используются также для определения нажатой клавиши при программировании. Для стандартной QWERTY-клавиатуры таблица кодов выглядит следующим образом:
Для того, чтобы грамотно использовать ASCII , необходимо расширить знания в данной сфере и о возможностях кодирования.
Кодировка
Символ 0x5e в первой версии стандарта ASCII (1963) соответствовал стрелке вверх, а символ 0x5f — стрелке влево. Стандарт ECMA-6 (1965) заменил их на знак вставки (используемый также в роли циркумфлекса) и нижнюю черту (подчёркивание) соответственно.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа "U+103D5" (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111 . В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111 . И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ "ì", 232 — "è", 240 — "ð"
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
110 10000 10 111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся ( 10000111100 ), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
ASCII
Файлы, в которые входят только символы первой половины кодовой таблицы, называются ASCII-файлами или текстовыми файлами. Текстовый файл представляет собой последовательность литер, которую для удобства чтения делят обычно на слова и строчки. Текстовые файлы намного беднее по оформлению, чем файлы, которые создают специальные текстовые редакторы. В них нельзя включить картинки или поля, они не имеют форматирования и сложной разметки и не обладают аппаратом ссылок и сносок; большинство декоративных элементов форматирования недоступно для текстовых файлов. Зато текстовые файлы являются аппаратно и программно независимыми и их можно использовать для обменов данными между различными программами и компьютерными платформами.
Текстовые файлы экспортируют текстовые редакторы и программы расчета электронных таблиц, в текстовой форме может существовать графика форматов EPS, PDF, DXF и др., любая программа на начальных стадиях разработки является текстовым файлом.
FreeHand может открывать, импортировать и передавать текстовые файлы в другие приложения. Одной из немногих проблем, которая сопровождает импорт текстовых файлов, является засорение данных "странными символами". Это часто происходит в тех случаях, когда FreeHand обменивается информацией с приложениями, работающими на других платформах.
Импорт текста ничем не отличается от импорта графики. Принятый в программу текст заполняет, по умолчанию, новый текстовый блок. Если щелкнуть курсором в любой точке монтажного стола, то размеры блока будут выбраны автоматически и подогнаны под объем текста. При помощи буксировки курсора можно задать собственные размеры блока для импортированного текста. Текст, не вошедший в блок, не теряется, а становится избыточным и загружается в буфер блока.
RTF (Rich Text Format) – это формат, разработанный фирмой Microsoft, для обменов форматированным текстом между программами и платформами. Документ в формате RTF состоит из информационной и управляющей частей, каждая из которых записывается в текстовом виде. Информационная часть передает содержательную сторону документа, управляющий раздел документа хранит сведения о его оформлении.
Для описания признаков форматирования и декоративных элементов документа используется специальный командный язык. Каждая управляющая конструкция языка представляет собой последовательность букв нижнего регистра, которая начинается с обратной косой черты (\) и заканчивается специальным разделителем. Разделителями могут быть пробелы, цифры, символы переноса и др.
Фирма Microsoft расширяет стандарт RTF, поэтому выразительные возможности формата постоянно увеличиваются. В настоящее время они примерно равны возможностями формата doc седьмой версии текстового редактора Word. Почти все, что можно создать в этой программе и сохранить в формате doc, можно записать в формате RTF.
FreeHand одинаково хорошо работает с файлами в формате RTF как на прием, так и на передачу. Работа с RTF-файлами имеет несколько особенностей:
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 = 0000000000 1111010101 (ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять))
- 0 + D800 = D800 ( 110110 0 000000000 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат
- 3D5 + DC00 = DFD5 ( 110111 1 111010101 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат
- итого данный символ в UTF-16 — 1101100000000000 1101111111010101
- переведем в шестнадцатиричный вид = D822DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
- 110110 0 000100010 — десятый бит (справа) нулевой, значит первый суррогат
- 110111 1 010001000 — десятый бит (справа) единица, значит второй суррогат
- отбрасываем по 6 бит отвечающих за определение суррогата, получим 0000100010 1010001000 (8A88)
- прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Тексты – это самый распространенный тип данных в компьютерном мире. Текстовую форму имеют не только источники, предназначенные для чтения, дискурсы. Многие компьютерные программы, описания изображений, сценарии работы операционных систем записываются в текстовом виде; и, хотя работать с такими описаниями могут только специалисты или специальные программы – лингвистические процессоры, они имеют все формальные признаки текста: алфавит, синтаксис и семантику.
Можно предположить, что в такой важной области, какой является тестовая форма представления информации, действуют стандарты, имеющие силу физических законов. К сожалению, это предположение ошибочно. Основной причиной "текстовой разноголосицы" является очень большое количество символов, требующихся для поддержки различных языков и сфер человеческой деятельности.
Для кодирования нескольких десятков европейских языков, использующих латинский алфавит, достаточно иметь полторы сотни символов. Каждый язык, базирующийся на собственном национальном алфавите, требует примерно сотни символов. Это славянские языки, греческий, иврит, арабский, санскрит и др. Для китайского, корейского и других языков, основанных на иероглифах, счет идет уже не на сотни, а на тысячи. Если учесть, что во многих областях человеческой деятельности используются специальные символы, например, для записи математических формул или знаки редакторской правки, то количество символов универсального алфавита уверенно приближается к десяти тысячам.
Чем же мы располагаем? В современных персональных компьютерах на один символ отводится восемь двоичных разрядов, т. е. байт. В такой системе кодирования можно записать 256 символов (два в восьмой степени). Исторически ситуация сложилась так, что стандартизованы только 128 символов с номерами (кодами) от 0 до 127. Они называются символами ASCII (American Standard Code for Information Interchange, американский стандартный код обмена информацией) и составляют первую половину кодовой таблицы. В состав ASCII входят важные управляющие символы, прописные и строчные буквы латинского алфавита, цифры, знаки препинания и некоторые спецсимволы.
Вторая половина кодовой таблицы может использоваться для различных целей, например, для кодирования национальных алфавитов или расширенного множества математических символов. Если набор ASCII является общим для большинства компьютерных платформ и операционных систем, то расширенные наборы имеют значительные различия. Существует несколько стандартов, которые определяют содержание всех 256 символов: ANSI, КОИ-8, EBCDIC и др. ANSI – это стандартная кодировка для платформы Windows, КОИ-8 широко используется различными версиями операционной системы Unix, кодировка EBCDIC применяется на машинах класса mainframe.
Самой решительной попыткой преодолеть недостатки систем кодирования, основанных на однобайтовом представлении символов, является сравнительно новый стандарт Unicode (ISO 10646). В этой системе кодирования символы представляются двумя байтами (шестнадцать двоичных разрядов), поэтому диапазон допустимых кодовых значений равен 65536 (два в шестнадцатой степени). Алфавит такой мощности с избытком покрывает все текущие и будущие потребности программистов и компьютерных пользователей.
Где применяется система кодировки ASCII?
Данная кодировочная система необходима не только для набора текстовой информации на клавиатуре. Она также используется в графике. Например, в программе ASCII Art Maker графические изображения различных расширений состоят из спектра символов кодировки ASCII (см. скриншот №3).

Как правило, подобные программы можно разделить на те, что выполняют функцию графических редакторов, инвертируя изображение в текст, и на те, что конвертируют изображение в ASCII -графику. Всем известный смайлик (или как его еще называют « улыбающееся человеческое лицо ») тоже является примером кодировочного символа.
Данный метод кодировки также может быть востребован во время написания или создания документа HTML. Например, вы вводите определённый и необходимый вам набор знаков, а при просмотре самой страницы на экран будет выведен символ, соответствующий данному коду.
Кроме всего прочего данный вид кодировки необходим при создании многоязычного сайта, потому что знаки, которые не входят в ту или иную национальную таблицу, нужно будет заменить ASCII кодами. Если читатель непосредственно связан с информационно-коммуникативными технологиями (ИКТ), то ему будет полезно ознакомиться и с такими системами как:
- Переносимый набор символов;
- Управляющие символы;
- EBCDIC;
- VISCII;
- YUSCII;
- Юникод;
- ASCII art;
- КОИ-8.
Читайте также: