
Abbyy finereader улучшить качество сканированного
После получения изображений ABBYY FineReader Engine выполняет их предварительную обработку, что позволяет улучшить качество документа и оптимизировать процесс распознавания данных. Таким образом, даже изображения самого низкого качества и документы, сфотографированные на смартфон, эффективно обрабатываются и распознаются в максимально высоком качестве.
Редактирование PDF-файлы любого типа
Используйте возможности FineReader PDF для редактирования как цифровых, так и отсканированных документов. Просто начните редактировать документ независимо от его типа.
Все возможности
Редактирование изображений
Добавляйте, изменяйте и удаляйте изображения в PDF-документах. Перемещайте их по странице, изменяйте размер и поворачивайте их так, как вам необходимо.
Работа с таблицами
Вы так же легко поменяете содержание ячейки в таблице, как в текстовом редакторе.
Редактирование абзаца
Вы можете редактировать, изменять или удалять целые абзацы в PDF. При этом текст будет перемещаться от строки к строке. Когда объем текста превысит пределы абзаца, FineReader автоматически расширяет его границы.
При фотографировании на камеру устройства, ABBYY FineReader Engine позволяет:
- Корректировать разрешение изображения
- Устранять перекосы
- Автоматически исправлять 3D-искажения (в виде трапеции)
Document Analysis и Synthesis
Чтобы определять в тексте блоки, ABBYY FineReader PDF использует технологию Document Analysis. Она позволяет найти абзацы, таблицы, картинки. Программа подсвечивает найденные блоки небольшими бледными рамками, чтобы пользователю удобнее было вносить правки:

Далее мы усовершенствовали другую подсистему нашей программы – Synthesis. Мы уже рассказывали на Хабре, зачем она нужна. Если вкратце, именно она определяет структуру и все характеристики распознанного текста: какие используются шрифты и размеры, какое начертание (bold, italic, underline), где заголовки, списки, отступы и многие другие параметры, которые можно настраивать в том же MS Word. Мы доработали Synthesis для того, чтобы при распознавании и воссоздании страницы очень точно восстанавливать исходные параметры текста.
Задача: понять PDF
Содержимое каждой страницы в PDF-файле хранится в виде потоков команд для отрисовки документа – это могут быть текст, изображения или векторная графика. Структуру файла определяют PDF-объекты, например, страница, картинка, комментарий (а абзацы, строчки текста и буквы – это всего лишь части объекта). Символ в PDF представляется глифом . То, как они записаны, определяется шрифтом . Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
В PDF нет ни строк, ни абзацев, которые есть в документах текстовых форматов. Даже порядок текста не всегда определен. То есть вы видите текст, но на самом деле текста не существует. Это хаос из трудно понятных инструкций (как на изображении выше), которые нужно правильно отобразить в конкретных местах документа, с соответствующим форматированием.
«А как же текст?» – спросите вы.

Текст в PDF все же существует, и его даже получится редактировать. Для этого мы учим наши технологии понимать структуру текста, например, определять и выделять строки. Расскажем об этом подробнее.
Разделение документов
Особенности подчеркнутого текста
В PDF нет такого атрибута текста как подчеркивание, привычного, например, пользователям MS Word. Подчеркивание в PDF – это векторная графика, никак не связанная с текстом. Без дополнительной доработки продукта при редактировании «подчеркнутого» текста символы бы перемещались привычным образом, а линии, обозначающие подчеркивания, оставались бы на месте. ABBYY FineReader PDF умеет определять и редактировать подчеркнутый текст привычным пользователю образом.
Создание PDF-форм
ABBYY FineReader PDF 15 для Windows
С 2007 года ABBYY состоит
в PDF Association

После короткого рассказа о том, как устроен ABBYY FineReader (aka «теоретическая часть»), самое время перейти к применению полученных знаний. И да, котиков под катом нет: всё очень серьёзно.
Как пользователю поучаствовать в обработке документа
Чтобы не изобретать велосипед, начну с простой и понятной схемы из Справки (см. рисунок справа).
Теперь, зная список всех операций, посмотрим на примерах – что может пойти не по плану и как с этим бороться.
Хорошо распознаются только хорошие изображения
А что делать, когда изображения есть, но не очень хорошие? Улучшить прямо в FineReader всё что можно, а, если улучшить нельзя, — попытаться получить изображение заново, устранив проблему. Поскольку тема очень обширная, то при должном интересе будет отдельный пост про то, как подружиться с автоматическими и ручными инструментами обработки изображений прямо в FineReader. Пока же ограничусь замечанием, что изображение будет обработано лучше, если оно:
- (после сканирования) не имеет выраженных геометрических искажений — перекоса или заметного изгиба страниц толстой книги у корешка двухстраничного разворота,
- (после фотографирования, в дополнение к предыдущему) не имеет ещё и нелинейных геометрических искажений («подушка», «трапеция»), имеет равномерную фокусировку (а желательно и яркость) по всей площади, не имеет шумов от недостаточной освещённости, не имеет выраженной засветки от вспышки (особенно на глянцевой бумаге).
Этап настройки документа/проекта

Можно и нужно сразу указать язык текста, параметры предобработки изображений, некоторые параметры анализа и распознавания. Вот скриншот одной из вкладок диалога настроек.
Эти и прочие настройки подробно описаны в Справке
Этап анализа
Назначение областей разных типов
В пользовательском интерфейсе FineReader доступны области нескольких типов, для них есть разные варианты скрываемой панели свойств (внизу окна «Изображение») и контекстного меню (по щелчку правой кнопкой мыши):
-
«Зона распознавания» (по умолчанию серая рамка) — такое название использовано в пользовательском интерфейсе, на мой взгляд правильнее было бы назвать «область для автоматического анализа». Назначение такой области – указать, где на странице вообще нужно искать что-то полезное. Поэтому в результате последующего анализа или анализа+распознавания в пределах каждой «зоны распознавания» может найтись ноль и более областей других типов. Особенно полезны зоны распознавания бывают в шаблонах блоков (подробнее о них в Справке).

Реальный пример из проекта оцифровки Толстого — часть страниц имеет нумерацию строк (пронумерованы строки с номерами, кратными 10), не нужную в результате и затрудняющую вычитку/правку текста, если автоматический анализ включил эти номера в текстовую область колонки. Если страницы были почти одинаково выровнены на сканере или качественно обрезаны после сканирования, то перед анализом к нужной группе страниц можно применить шаблон блоков, где область (или области) распознавания просто не содержит не нужных нам частей страницы:
Помните, что в отличие от текстовой области область распознавания может превратиться в области разных типов, что бывало нужно и в этом проекте.
Эти параметры задаются на блок, так что выделять текст разного направления или разной инверсности в один блок – другая плохая идея.
В европейских языках в нормальной ориентации текста строки читаются сверху вниз (в блоке с повёрнутым текстом – от логического верха в сторону логического низа), но в случае иероглифических языков всё гораздо веселее – даже на одной странице одни области могут содержать текст в горизонтальной ориентации, а другие – в колоночной, причём иероглифы имеют одинаковую ориентацию во всех этих областях (если тема дальневосточных и ближневосточных языков интересна – просите отдельный пост про тамошние навороты).
Важные соображения
- Распознавание и синтез видят только те фрагменты текста, которые оказались выделены в текстовые области или текстовые ячейки таблиц. Если кусок текста не выделен в блоки – распознаваться он не будет.
- Аналогично и с картинками — если часть картинки оказалась вне области или одна целостная картинка оказалась разделена на несколько областей – скорее всего, в результате обработки будут проблемы.
- Языки распознавания в FineReader задаются не для галочки – они влияют на очень многие механизмы, начиная уже с анализа: например, иероглифический (китайский, японский, корейский языки) или арабский текст имеют много особенностей, которые учитываются не всегда, а только при выборе соответствующих языков распознавания.
Особенности взаимодействия близкорасположенных или пересекающихся областей
-
Пересечение текстовых и табличных блоков друг с другом, если есть символы или их части, оказавшиеся в более чем одном блоке – практически всегда ошибка, такие результаты анализа нужно исправлять, тем более что обычно это делается в несколько движений мыши.
Пересечение картиночных областей друг с другом – практически всегда ошибка, хотя и менее критичная для обработки именно текста. Такие случаи тоже желательно исправлять.



Обратите внимание, что с помощью галочки в панели свойств области (внизу) ячейки из левой колонки таблицы сделаны картинками.
Текстовая область на фоне «картиночной» области — тоже важный инструмент: на фоне обычных картиночных областей могут находиться подписи к ним, на «фоновых» картиночных областях может располагаться и основной («колоночный») текст документа, а также таблицы.

Маленькие хитрости для облегчения работы с блоками
Описанные соглашения отражены в поведении редактора блоков. Например, если вы рисуете новый или растягиваете имеющийся блок так, что он полностью или почти полностью перекрывает другие блоки — эти другие блоки автоматически удаляются.
Логичность/нелогичность выделения областей
Тут самое время подумать — для каких целей и какого формата документ хочется получить в результате обработки. Вот некоторые соображения, влияющие на количество и характер исправлений разметки блоков в сложных случаях:
Вариант 1: нам нужен только текст (возможно, мы этого не понимаем, но дело обстоит именно так)
- нет «мусорных» областей, где в качестве текста или таблиц распознаются (мусором) элементы картинок или элементов оформления страницы.
- области логично выделяют строки, не допуская попадания символов в более чем одну область и неоправданного дробления строк на более чем одну область.
- то, что с точки зрения человека является таблицами в оригинале, должно быть выделено в табличные области. Это влияет как на качество распознавания (например, базовые линии строк в разных ячейках могут быть не выровнены по вертикали), так и на удобство поиска и копирования фрагментов текста в выходном документе.
Если отдельные картинки не должны копироваться из выходного PDF-документа – то такие области можно из документа исключить вовсе (не создавать новые и не оставлять найденные автоматикой, как минимум – удалять нелогично найденные картинки, а если не лень – то и все).
Я надеюсь шире и глубже раскрыть тему «разумности» картинок в статье про сохранение документов — если такая будет интересна читателям данного материала.
Вариант 2: нужно всё и сразу
Если документ, включающий не одно лишь текстовое содержимое (в одну или две колонки), предполагается сохранить сразу как электронную книгу в форматах FB2/e-pub или в любой промежуточный редактируемый формат (Вордовый или HTML) для дальнейшего редактирования и производства электронной книги, то осмысленное выделение таблиц и картинок становится особенно важно.
Среди прочего нужно определиться с тем, что делать с группами рядом расположенных картинок, и что делать с подписями к картинкам, как рядом стоящими, так и накладывающимися на картинки. Подробнее разберём эту тему в «Практикуме», на реальных примерах.

Сегодня мы обновили ABBYY FineReader 15 и выпустили его под брендом ABBYY FineReader PDF, потому что он объединяет все инструменты для работы с PDF. По этому поводу публикуем первый пост из серии материалов о фичах программы. В нем мы расскажем об одной интересной возможности, которая не первый месяц есть в программе, но, возможно, не все о ней знали.
Давно ли вы открывали PDF-файлы? Готовы поспорить, что совсем недавно. Скорее всего, на вашем компьютере точно найдется пара сканов, а может, еще и макет презентации, аналитическое исследование или техническая инструкция. Для каких задач обычно используют эти документы? По данным опроса ABBYY, 62% респондентов ищут информацию в PDF, 60% — копируют текст из документа, а 52% — редактируют: вносят в файл правки, исправляют ошибки и опечатки.
Даже сейчас не все знают, что можно редактировать текст в PDF. Да, изменение таких файлов устроено не так, как редактирование обычного текстового документа. ABBYY FineReader PDF с многофункциональным текстовым редактором для работы с PDF и сканами позволяет быстро внести изменения прямо в PDF, без утомительной конвертации файла в другие форматы. При редактировании текст в PDF плавно перетекает со строчки на строчку, как в MS Word. Можно добавить или удалить несколько слов, изменить целые абзацы или даже поменять их местами.
В этом посте мы раскроем технические подробности редактирования многострочных фрагментов текста в FineReader: как мы изменили движок программы, как редактирование устроено изнутри и как оно выглядит для пользователя. Поехали!
Форматом PDF пользуются по всему миру: его содержимое одинаково отображается на любых компьютерах, смартфонах и планшетах с разными операционными системами. Это удобно и помогает избежать неловких ситуаций. Например, когда вы написали текст в MS Word, отправили коллегам, а они открывают его LibreOffice'ом или Wordpad'ом, и все поехало и начинается веселье. PDF, конечно, в этом плане удобнее, но с текстом здесь все сложно. В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
Поговорим сначала о PDF, в которых текст есть. Чтобы редактировать PDF, надо понимать, как в нем записан текст. Открывали когда-нибудь PDF в блокноте? Если да, то вы видели такое:

Чтобы все это отображалось понятно для пользователя, нужно проделать большую работу.
Базовые функции обработки изображений
ABBYY FineReader Engine позволяет выполнять следующие действия с изображениями, например:
- Изменять масштаб
- Обрезать изображение
- Делать обтравку изображения
- Создавать изображения для предпросмотра
- Поворачивать изображение (на 90, 180 и 270 градусов)
- Выпрямлять текстовые строки
- Создавать зеркальное отражение и инвертирование
- Удалять шумы
- Повышать контрастность
- быстро,
- без конвертации документа,
- с помощью одной программы.
- Изменять масштаб
- Обрезать изображение
- Делать обтравку изображения
- Создавать изображения для предпросмотра
- Поворачивать изображение (на 90, 180 и 270 градусов)
- Выпрямлять текстовые строки
- Создавать зеркальное отражение и инвертирование
- Удалять шумы
- Повышать контрастность
- Выберите пункт Очистить изображение от мусора в меню Изображение>Обработать изображения.
- Выберите пункт Очистить блок от мусора в меню Изображение>Обработать изображения.
- нажмите кнопку или выберите в меню Изображение>Обработать изображение>Устранить искажение строк.
- Увеличить/Уменьшить масштаб изображения
- Технология Camera-OCR
- Предварительная обработка документов с печатями и рукописными комментариями
- Автоматическое разделение двойных страниц
- Автоматическое определение ориентации страниц (90, 180 и 270 градусов)
- Автоматическое выравнивание изображений (до +/- 20 градусов)
- Удаление пятен (очистка изображения)
- Очистка изображений в отдельных блоках
- Фильтрация текстур и адаптивная бинаризация
- Редактирование текста и цвета фона
- Распознавание информации из полей с разными границами и рамками
- Потенциальные ошибки распознавания символов
- Ошибки при разделении страниц
- Изменения размера шрифта (сверху вниз)
Вместо заключения
В следующем посте через неделю мы расскажем о том, как научили ABBYY FineReader PDF еще одной интересной фиче и для чего может пригодиться новая функциональность.
Пишите в комментариях, о каких еще технологических особенностях нашей программы вам было бы интересно узнать?
Как отредактировать PDF-документы с помощью ABBYY FineReader PDF
Cледуйте инструкции из видео:
Изменение формата текста
Отформатируйте отдельные слова, предложения или целые абзацы. Вы можете изменить шрифт, стиль шрифта, размер и цвет букв, гарнитуру, выравнивание текста и межстрочный интервал.
Другие возможности
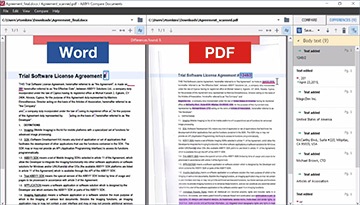
Сравнение документов
Библиотеки PDF и как мы их поменяли
Чтобы сделать возможным редактирование целых абзацев, мы сильно поменяли нашу внутреннюю подсистему (библиотеку), которую мы называем PdfTools. Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Подсистема PdfTools содержит все необходимые инструменты, чтобы прочитать содержимое и обернуть его в объекты (страница, картинка, комментарий), с которыми удобно работать программе. С этими объектами уже могут работать наши продукты, в частности ABBYY FineReader PDF и другие.
Как было раньше. В FineReader 14 мы умели редактировать текст только в рамках одной строчки. После редактирования необходимо было выполнить «рендеринг» — расставить глифы на свои новые места.
Вообще рендеринг — это визуализация. Но мы вкладываем в это слово иное понятие — расположение объектов в PDF на своих местах. Для PDF-специалистов это и есть визуализация, которую больше никто не видит. Когда мы говорим о визуализации в привычном понимании, то используем слово «растеризация».
Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую. Чтобы определить все эти параметры, мы решили привлечь для решения этой задачи и другие наши OCR-технологии — Document Analysis (DA) и Synthesis, которые умеют строить структуру документа.
Добавление нового абзаца в текст
Добавьте текст в PDF, создав новые абзацы. Введите текст или скопируйте и вставьте его.
Корректировка размытых изображений
При использовании камеры без штатива можно получить размытое изображение. Этот дефект, не заметный на экране камеры, может приводить к ошибкам распознавания. После обработки полученного изображения бинарное изображение выглядит «читаемым»:




Изменение расположения элементов на странице
Перемещайте абзацы, таблицы и изображения по странице PDF так, как вам необходимо.
Базовые функции обработки изображений
ABBYY FineReader Engine позволяет выполнять следующие действия с изображениями, например:
Непревзойденное качество обработки (Camera-OCR)
Документы, сфотографированные на цифровые камеры, телефоны и планшеты зачастую обладают высоким качеством, однако, в зависимости от устройства, им свойственны некоторые искажения. Интеллектуальная технология позволяет определять фотографии сделанные на цифровую камеру, и активировать алгоритмы обработки таких изображений, чтобы устранять искажения, размытость, искривление текстовых строк, отсутствие информации о разрешении или ошибки, возникшие из-за недостаточного освещения.
Уменьшение цифрового шума (ISO)
Цифровой шум выглядит на изображении как множество маленьких пикселей разных цветов. Этот дефект изображения приводит к ошибкам бинаризации и потере символов. Благодаря специальному фильтру ABBYY FineReader Engine уменьшает цифровой шум и выравнивает фон, предотвращая потерю информации:
Очистить от мусора
Распознаваемое изображение может быть сильно "замусорено", т.е. содержать много лишних точек, возникших в результате сканирования документов среднего или низкого качества. Точки, близко расположенные к контурам букв, могут отрицательно сказаться на качестве распознанного текста. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора. Для этого:
Если вы хотите очистить от "мусора" отдельный блок, то:
Внимание! Если исходный текст был очень светлым или в исходном тексте использовался очень тонкий шрифт, то применение функции Очистить изображение от мусора может привести к исчезновению точек, запятых или тонких элементов букв, что ухудшает качество распознавания.
Разрешение изображения - это параметр, определяющий, какое количество точек, составляющих изображение, приходится на единицу длины. Разрешение обычно измеряется в dpi - количестве точек, приходящихся на один дюйм. Для качественного распознавания текста с помощью системы ABBYY FineReader необходимо, чтобы разрешение изображения по вертикали и по горизонтали совпадало, и при этом разрешение находилось в пределах допустимого диапазона (50 - 3200 dpi). Рекомендованный диапазон разрешения - 200 - 600 dpi, разрешение оптимальное с точки зрения распознавания - 300 dpi.
Слишком большое или слишком маленькое разрешение может приводить к ухудшению качества распознавания. У некоторых форматов изображения разрешение отсутствует (например, у *.bmp файлов). Изображения могут также иметь нестандартное разрешение (например, 204*96 dpi), что тоже может повлиять на качество распознавание.
Система ABBYY FineReader проверяет разрешение каждого изображения и при обнаружении "подозрительного" изображения автоматически исправляет его разрешение, при этом физические размеры изображения (его длина и ширина) не изменяются. Такое изображение помечается значком в окне Пакет. При наведении мыши на такое изображение возникает всплывающая подсказка.
В открывшемся диалоге укажите тип изображения (отсканированное изображение, изображение, полученное по факсу, или снимок экрана). Вы также можете указать точное значение разрешения в поле Другое разрешение.
При сканировании книг возможно искажение строк текста в той части изображения, где страница примыкала к переплету. На изображениях, полученных с помощью фотокамеры, строки текста также могут искажаться по краям изображения. Для того чтобы устранить искажения строк:
Замечание. Для выполнения данной операции может потребоваться значительное время.
Некоторые сканеры инвертируют изображения при сканировании (черный цвет переводят в белый, а белый в черный). Чтобы получить стандартное представление документа (черный шрифт на белом фоне):
В меню Изображение>Обработать изображения выберите пункт Инвертировать.
Замечание. Если вы сканируете или открываете инвертированные изображения, то перед добавлением в пакет таких изображений отметьте пункт Инвертировать изображение в группе Сканировать/Открыть в диалоге Дополнительные опции. Для того чтобы открыть диалог Дополнительные опции, щелкните по кнопке Дополнительные опции на закладке Общие диалога Опции (меню Сервис>Опции).
При распознавании изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически. Если ориентация изображения была определена ошибочно, то на закладке Сканировать/Открыть снимите отметку с пункта Определять ориентацию страницы (при распознавании) и поверните изображение вручную.
Чтобы повернуть изображение:
на 90 градусов вправо - нажмите кнопку или выберите в меню Изображение>Повернуть/Отразить изображение пункт Повернуть по часовой стрелке.
на 90 градусов влево - нажмите кнопку или выберите в меню Изображение>Повернуть/Отразить изображение пункт Повернуть против часовой стрелки.
на 180 градусов - выберите в меню Изображение>Повернуть/Отразить изображение пункт Повернуть на 180 градусов.
Если вы хотите исключить какой-то участок текста из распознавания или на изображении имеются большие участки мусора, то вы можете стереть такие участки. Для этого:
Выберите инструмент (на панели в окне Изображение) и, нажав на левую кнопку мыши, выделите участок изображения, который вы хотите удалить. Отпустите кнопку, выделенная часть изображения будет удалена.
Иногда в результате сканирования по краям изображения появляются зачерненные поля. В таком случае перед распознаванием можно выполнить обрезку изображения, удалив ненужные фрагменты. С помощью инструмента обрезки изображения можно также получить изображение стандартного размера (соответствующего одному из стандартных форматов, например, А4, А5).
На панели Изображение (в окне Изображение) выберите инструмент (вы также можете воспользоваться командой Обрезать изображение в меню Изображение);
Изображение будет открыто в окне Обрезать изображение, контур изображения будет выделен черной линией. Для того чтобы:
Выбрать наиболее удобный режим просмотра изображения, воспользуйтесь выпадающим списком, находящимся в левом нижнем углу окна изображения;
Обрезать ненужные края изображения, потяните мышью черную линию, обрамляющую изображение, или маркеры, находящиеся в углах контура изображения. Часть изображения, которая будет отрезана, выделяется серым цветом. Щелкните по кнопке Обрезать;
Привести изображение к стандартному размеру, выберите нужный формат из выпадающего списка Привести к;
Не выполнять обрезку открытого изображения и перейти к следующему изображению, нажмите кнопку Пропустить;
Всегда работать только с выбранным изображением (не переходить к следующему изображению пакета после окончания работы с текущим изображением), снимите отметку с опции Перейти к следующей странице.
Обрезку изображения рекомендуется выполнять до того, на изображении будут выделены блоки и изображение будет распознано.
Цвет рамки в окне Обрезать изображение можно изменить на закладке Вид диалога Опции (меню Сервис>Опции). В списке Объекты выберите пункт Блок обрезки изображения, затем щелкните по кнопке Цвет и в открывшемся диалоге выберите нужный цвет рамки.
На панели Изображение (в окне Изображение) выберите инструмент / и щелкните мышью на изображении. Изображение увеличится/уменьшится в два раза.
Щелкните правой кнопкой мыши на изображении и в локальном меню выберите пункт Масштаб и нужный вам масштаб.
Вы можете получить следующую информацию об открытом изображении: ширину и высоту изображения в точках; вертикальное и горизонтальное разрешение в точках на дюйм (dpi); тип изображения. Чтобы просмотреть информацию об изображении:
Щелкните правой кнопкой на изображении и в локальном меню выберите пункт Свойства. В открывшемся диалоге выберите закладку Изображение.
Вы можете напечатать одно изображение, открытое в окне Изображение, несколько изображений, выделенных в окне Пакет, или все изображения. Для этого:
В меню Файл выберите пункт Печать>Изображение и в открывшемся диалоге Печать установите параметры печати (принтер, количество печатаемых страниц, количество копий и т.д.)
Для отмены последнего действия на панели Стандартная нажмите кнопку Отменить .
ABBYY FineReader PDF делает работу с документами, в том числе с отсканированными, быстрой и удобной. Вы можете сразу приступить к редактированию текстов, таблиц и всего PDF-документа без дополнительной конвертации. Это так же просто, как в текстовом редакторе!
Доступно для FineReader PDF for Windows
Продвинутые функции обработки изображений
Создание PDF
Используя инструменты FineReader PDF, вы можете полностью создать новый PDF-документ.
Корректировка искажений перспективы
Искажения перспективы вызывают разные трудности при распознавании текста:




Редактирование таблиц в PDF
Внесение изменений легко и быстро
Исправляйте опечатки или меняйте PDF-файл без использования программ для верстки и дизайна. То, на что раньше уходило несколько часов и требовало участия ни одного специалистов, может быть выполнено за считанные минуты в FineReader PDF.
Как отредактировать скан?
Возможность многострочного редактирования доступна и для сканов. Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.
В программе скан сначала распознается, а потом происходит подготовка к редактированию. Когда скан распознали, то текст получается не в нашем исходном документе, а в его виртуальном «двойнике». И именно в нем происходят все операции по редактированию.
Когда пользователь закончил редактировать документ, программа автоматически собирает все изменения со страницы и заменяет эти фрагменты в исходном документе. Наша задача — встроить текст обратно в PDF-документ, не повредив все то остальное, что уже есть в нем.
Редактирование скана позволяет не тратить время на конвертацию документа в другие форматы и обратно. Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Пример многострочного редактирования. Текст автоматически перераспределяется по строкам по мере добавления слов и предложений внутри абзаца.
Читайте также: