
Abbyy finereader необходимо увеличить разрешение
Здравствуйте, форумчане! Помогите, пожалуйста, решить следующую проблему.
Имеется скан книги в формате djvu, выполненный в довольно низком, но достаточном для распознавания текста качестве. При попытке распознать книжку программой Abbyy FineReader 12 бОльшая часть текста определяется как картинка и распознавания текста в этих областях не происходит. Есть ли возможность все страницы книги целиком объявить текстовыми областями, после чего уже выполнить распознавание?
Я знаю, что я могу выделить каждую страницу книжки зеленой рамкой, после чего все они будут FineReader'ом трактоваться как текст, но обводить мышкой каждую страницу вручную, когда их больше 600 штук, очень бы не хотелось. Это очень большая работа. Есть ли возможность выделить все страницы документа как текстовые области автоматически одной командой FineReader'а?
Буду вам очень благодарен за помощь и советы.
abbyy finereader 8.0
Добрый день господа, принесли сегодня ноутбук, на нём abbyy finereader 8.0 professional edition.
Abbyy finereader 12
Привет всем. Такой вопрос. Установил Abbyy Finereader 12. Некоторое время все работало нормально.
abbyy finereader 10
Здравствуйте , подскажите как можно увеличить размер шрифта на всех страницах сразу. Или можно.

Abbyy Finereader 10 в Windows 7!
не могу отсканировать документ на высокое разрешение, может какие настройки посоветуете.
Вот тут выделяете всю страницу как надо, нажимаете сохранить шаблон
Потом выделяете все остальные и нажимаете применить шаблон
На нескольких страницах не пробовал, но на одной все сработало
arhistratig13, спасибо за совет, я уже пробовал сделать все так, как Вы мне написали, делал по этой инструкции:
Выделил всю поверхность всех страниц как текстовые области. Только вот книгу распознать у меня все равно не получилось. Распознались лишь некоторые надписи и заголовки в ней, отпечатанные крупным шрифтом. Когда стал разбираться, выяснилось следующее.
Все страницы в книге имеют слишком маленькое разрешение. При номинально заданных 600 dpi размер каждой страницы составляет приблизительно 1200x800 пикселей. Т. е, переводя это в сантиметры, получаем, что каждая страница имеет приблизительный размер 5 см x 3,5 см. Соответственно, каждая буква, каждый печатный символ книги состоит из слишком маленького числа пикселей, т. е. формально относится к крайне мелкому шрифту, что и вызывает трудности в распознавании такого текста, состоящего из букв, набранных очень мелким шрифтом. Хотя я вижу, что качество текста в книге хоть и низкое, но вполне достаточное для того, чтобы программа вроде FineReader'а смогла его распознать. Визуально, на глаз, текст воспринимается и никаких проблем при чтении не вызывает - он вполне читаемый.
Что посоветуете делать в такой ситуации?
Я уже стал думать о том, как бы мне увеличить размер каждой страницы, чтобы число пикселей по вертикали и по горизонтали у каждой страницы стало бОльшим. Одна идея заключалась в следующем. Переконвертировать djvu-файл в файлы jpeg, так чтобы из каждой страницы исходного djvu появился свой jpeg. Дальше каждый полученный jpeg можно было бы увеличить - применить к нему преобразование масштабирования - чтобы число пикселей по горизонтали и вертикали стало бОльшим. А дальше получившиеся новые jpeg-файлы собрать опять в один djvu или pdf-файл и распознать его FineReader'ом. Я уже стал искать утилиты командной строки из мира Linux, которые позволили бы сделать все это дело в пакетном режиме, чтобы с каждым файлом не возиться по отдельности. Стал смотреть djvulibre и прочая. Но с этим со всем все равно очень долго нужно разбираться, искать программки с интерфейсом командной строки, которые все это делают, читать документацию и man'ы по ним. Короче, очень много возни.
Вы не знаете способ, как все это можно сделать проще и быстрее? Не выполнять никаких преобразований в jpeg и обратно, не использовать никаких утилит командной строки для масштабирования (увеличения размера) jpeg-файлов, а решить эту задачу, не выходя из FineReader'а, FineReader'овскими же командами. Я такой опции, которая позволила бы пропорционально увеличить размер всех страниц, выполнить преобразование масштабирования, в меню FineReader'а не нашел. Может, она есть? Если есть - подскажите, пожалуйста, где она находится и как ей пользоваться, вкратце.
Или подскажите, как заставить FineReader в принудительном режиме распознавать такие картинки с низким разрешением и, как следствие, с мелким шрифтом букв без преобразования изображения в более высокое разрешение. Если, конечно, он способен распознать текст на таких картинках.
В общем, если есть какие-то хорошие решения моей проблемы - подскажите. Буду очень благодарен, а то я уже начинаю искать свои решения, но они слишком сложные и с ними будет очень много возни.
Добавлено через 5 минут
PS
Если хотите, я могу Вам даже прислать ссылку на книгу в личку.
а дальше ручками батенька, ручками. извини, немного утрировано, но из трех пикселей тебе букву никто не угадает.
Добавлено через 56 секунд
а дальше ручками батенька, ручками. извини, немного утрировано, но из трех пикселей тебе букву никто не угадает.
полностью согласен.
к сожалению даже если увеличить механически разрешение, само разрешение сканирования останется прежним, можно все-таки попробовать увеличить, если уверенно буквы различимы
Дальше каждый полученный jpeg можно было бы увеличить - применить к нему преобразование масштабирования - чтобы число пикселей по горизонтали и вертикали стало бОльшим.
Но если чисто отвечая на вопрос о пакетном редактировании изображений - очень легко и просто это делает программка ACDSee Pro
Как это без извлечения jpg сделать не знаю.
Проблему в итоге удалось решить, причем средствами самого FineReader'а, не привлекая для этого какой-либо сторонний софт, графические редакторы и пакетную обработку файлов. Увеличивать размер изображений страниц тоже не пришлось, обошлось без этого.
А дело оказалось вот в чем. Изображения страниц в изначальном файле djvu с электронной книгой были действительно очень маленькие, как я и говорил, примерно 1200x800 при установленном якобы разрешении в 600 dpi. Таким образом геометрический размер страницы оказывался равным приблизительно 5 см x 3,5 см. При таком размере страницы шрифт символов, которыми был набран текст, оказывался в геометрическом измерении очень мелким, т. е. текст был как бы набран шрифтом с очень маленьким кеглем. Похоже, что программа FineReader изначально настроена таким образом, что буквы таких шрифтов она просто игнорирует, даже не пытается их проанализировать и распознать, рассматривая их как мусор и фон. Поэтому весь этот мелкий текст опознавался как картинка, и в форме картинки попадал в выходной документ, построенный FineReader'ом. Естественно, никаких распознанных букв эта картинка не содержала.
Выход заключался в том, чтобы формально изменить разрешение страниц с 600 dpi на более низкое, не трогая при этом и не изменяя само изображение. Тогда изображение оставалось в прежнем неизменном виде, количество пикселей по горизонтали и вертикали, занимаемых им, также оставалось прежним, однако чисто номинально геометрический размер изображения увеличивался. Оставаясь точно таким же в пиксельных единицах, в метрических единицах измерения (сантиметрах, дюймах и т. п.) формально оно становилось больше. Буквы текста при этом также формально увеличивались, шрифты приобретали нормальный общепринятый размер и уже не игнорировались FineReader'ом, а нормально распознавались.
Как я и писал, качество книжки довольно низкое, но вполне приемлемое для распознавания. Распозналось не очень хорошо, не достаточно уверенно, в тексте довольно много ошибок, но вполне удовлетворительно. Как я и писал, увеличивать изображения страниц в пикселях для этого не пришлось, хватило чисто формального трюка с разрешением в dpi. В исходной книге оно было установлено в 600 dpi для всех страниц, я же его установил в 100 dpi для всех страниц, т. е. номинально увеличил размер каждой страницы в 6 раз.
Добавлено через 31 минуту
Теперь краткое описание, как я это делал в FineReader'е. Вдруг пригодится кому-нибудь еще.
1. Загружаем в FineReader файл с нераспознанной электронной книгой.
3. В колонке справа с различными инструментами и опциями редактирования находим пункт Разрешение изображения. Щелкаем мышкой по нему. Появляется список опций выбора разрешения следующего примерно вида:
Укажите разрешение изображения:
* 300 dpi (для отсканированных изображений)
* 200 dpi (для факсов)
* 96 dpi (для снимков экрана)
* Другое: XXX dpi
где XXX - конкретное разрешение текущей страницы вашего документа.
4. Выберите в данном списке опций вариант другое, в поле разрешение проставьте нужное вам значение. В моем случае изначально стояло 600 dpi, я его изменил на 100 dpi. Этим я номинально увеличил изображение в 6 раз.
5. Из списка опций Применить к:, расположенного чуть ниже, в котором предлагается на выбор применить изменение разрешения к Текущей странице, Нечетным страницам, Четным страницам, Всем страницам, выбрать вариант Все страницы.
6. Нажать на расположенную ниже кнопку Применить.
Нажимаем на ней кнопку OK, и запускается обработчик, автоматически меняющей разрешение всех страниц на выбранное нами. Работает он очень недолго, после завершения его работы для всех страниц электронной книги устанавливается новое разрешение.
Теперь можно приступать к распознаванию. Если текст имеет удовлетворительное качество и разборчив на глаз, то он будет нормально распознан. Главное при этом, чтобы буквы основного шрифта, которым набран текст, были нормального общепринятого размера (т. е. не были микроскопического размера).
Добавлено через 12 минут
PS
Не стал делать скриншоты, но думаю, что и без них по написанному разобраться будет несложно. Специально все расписал подробно. Делал все в версии Abby FineReader 12, для нее и составлено описание.
Правильно установленные параметры распознавания помогут вам быстро получить качественный документ, пригодный для дальнейшего редактирования. Выбор параметров зависит не только от объема и сложности исходного документа, но и от того, как вы намерены использовать распознанный документ.
Выбрать необходимые параметры вы можете на закладке Распознать диалога Опции (меню Сервис>Опции…).
Внимание! Распознавание страниц, добавленных в документ ABBYY FineReader, выполняется в автоматическом режиме с текущими настройками программы. Вы можете отключить автоматический анализ и распознавание добавленных изображений на закладке Сканировать/Открыть диалога Опции (меню Сервис>Опции…).
Замечание. Если вы изменили язык распознавания, выделили области на изображении вручную или изменили другие настройки программы, выполните распознавание заново.
На закладке Распознать диалога Опции вы можете изменить настройки для следующих групп опций:
Режим распознавания
Выберите один из режимов распознавания.
В ABBYY FineReader 10 предусмотрено два режима распознавания:
-
Тщательное распознавание
Данный режим пригоден для распознавания как простых, так и сложных документов. Например, для документов, содержащих текст на цветном фоне, или для документов, содержащих таблицы, в том числе таблицы без линий сетки и таблицы с цветными ячейками.
Для выбора режима распознавания в группе Режим распознавания выберите одну из опций: Тщательное распознавание или Быстрое распознавание.
Обучение
По умолчанию режим Распознавание с обучением отключен. Для того чтобы в процессе распознавания проводилось обучение неизвестным символам, отметьте опцию Распознавание с обучением.
Распознавание с обучением используется для распознавания следующих текстов:
- Для набора которых использованы декоративные шрифты
- В которых встречаются специальные символы (например, отдельные математические символы)
- Большого объема (более 100 страниц) текста плохого качества
При распознавании вы можете использовать встроенные эталоны или создать собственный эталон. Для этого выберите нужную опцию в группе Обучение.
Берем "живой" PDF, здесь — тот, в котором текст может быть выделен, и кривые букв при сильном увеличении в PDF-просмотрщике остаются кривыми, а не ступенчатыми, пикселизованными. Открываем этот документ в FineReader 15 OCR Editor перетаскиванием на его окно или выбором "File" / "Open Image. ". Увеличиваем в поле "Text pane" или "Zoom pane" — видим, что буквы растеризовались. Можем даже тут же увидеть, с каким разрешением — "Image Properties" / "Resolution: 300 dpi". Соответственно, и при сохранении этот документ сохраняет буквы (а попутно и все изображения вне зависимости от их изначального качества) в указанном разрешении. И это проблема, потому что тогда, когда нужно только добавить в документ невидимый текстовой слой ("Searchable PDF settings" / "Text under the page image"), мы имеем деградированную версию изначального документа (который может быть очень высокого качества). Для уникальных документов приходится хранить две версии — хорошего качества и вариант с возможность поиска ("Save as Searchable PDF Document. ").
Таки, — как, если не сохранять в документах PDF редактируемый текст, то, хотя бы, выбирать разрешение для его открытия? В "Image Processing" только "Enable background recognition in the PDF Editor", "Automatically process page images as they are added to the OCR Editor", да 13 опций "Image preprocessing settings (apply to conversion and OCR)", не имеющих отношение к вопросу.
Как добавить новый пункт в контекстное меню для ABBYY FineReader 12
Как добавить новый пункт "Конвертировать в Текстовый файл" в контекстное меню для для ABBYY.
Как в Abbyy FineReader объявить все страницы скана книги текстовыми областями?
Здравствуйте, форумчане! Помогите, пожалуйста, решить следующую проблему. Имеется скан книги в.
abbyy finereader 10
Здравствуйте , подскажите как можно увеличить размер шрифта на всех страницах сразу. Или можно.
abbyy finereader 8.0
Добрый день господа, принесли сегодня ноутбук, на нём abbyy finereader 8.0 professional edition.
Abbyy finereader 12
Привет всем. Такой вопрос. Установил Abbyy Finereader 12. Некоторое время все работало нормально.
Abbyy Finereader 10 в Windows 7!
не могу отсканировать документ на высокое разрешение, может какие настройки посоветуете.
ABBYY FineReader 10 - настройки сканирования
Установленна лицензионная программаABBYY FineReader 10 при первоначальном запуске предложил.
Распознавание украинского языка в ABBYY FineReader 10!
Плохо распознаёт украинский язык а мне по зарез надо ужасно расспознаёт кто знает где можно найти.
Abbyy FineReader не видит принтер (сканер)
Всем привет! Вообщем проблема в следующем. в офисе имеются два принтера kyocera ecosys m2035dn.
Берем "живой" PDF, здесь — тот, в котором текст может быть выделен, и кривые букв при сильном увеличении в PDF-просмотрщике остаются кривыми, а не ступенчатыми, пикселизованными. Открываем этот документ в FineReader 15 OCR Editor перетаскиванием на его окно или выбором "File" / "Open Image. ". Увеличиваем в поле "Text pane" или "Zoom pane" — видим, что буквы растеризовались. Можем даже тут же увидеть, с каким разрешением — "Image Properties" / "Resolution: 300 dpi". Соответственно, и при сохранении этот документ сохраняет буквы (а попутно и все изображения вне зависимости от их изначального качества) в указанном разрешении. И это проблема, потому что тогда, когда нужно только добавить в документ невидимый текстовой слой ("Searchable PDF settings" / "Text under the page image"), мы имеем деградированную версию изначального документа (который может быть очень высокого качества). Для уникальных документов приходится хранить две версии — хорошего качества и вариант с возможность поиска ("Save as Searchable PDF Document. ").
Таки, — как, если не сохранять в документах PDF редактируемый текст, то, хотя бы, выбирать разрешение для его открытия? В "Image Processing" только "Enable background recognition in the PDF Editor", "Automatically process page images as they are added to the OCR Editor", да 13 опций "Image preprocessing settings (apply to conversion and OCR)", не имеющих отношение к вопросу.
Как добавить новый пункт в контекстное меню для ABBYY FineReader 12
Как добавить новый пункт "Конвертировать в Текстовый файл" в контекстное меню для для ABBYY.
Как в Abbyy FineReader объявить все страницы скана книги текстовыми областями?
Здравствуйте, форумчане! Помогите, пожалуйста, решить следующую проблему. Имеется скан книги в.
abbyy finereader 10
Здравствуйте , подскажите как можно увеличить размер шрифта на всех страницах сразу. Или можно.
abbyy finereader 8.0
Добрый день господа, принесли сегодня ноутбук, на нём abbyy finereader 8.0 professional edition.
Abbyy finereader 12
Привет всем. Такой вопрос. Установил Abbyy Finereader 12. Некоторое время все работало нормально.
Abbyy Finereader 10 в Windows 7!
не могу отсканировать документ на высокое разрешение, может какие настройки посоветуете.
ABBYY FineReader 10 - настройки сканирования
Установленна лицензионная программаABBYY FineReader 10 при первоначальном запуске предложил.
Распознавание украинского языка в ABBYY FineReader 10!
Плохо распознаёт украинский язык а мне по зарез надо ужасно расспознаёт кто знает где можно найти.
Abbyy FineReader не видит принтер (сканер)
Всем привет! Вообщем проблема в следующем. в офисе имеются два принтера kyocera ecosys m2035dn.
Стоит разрешение сканирования 200dpi, самое маленькое в настройках.
После сканирования документа и когда сохраняешь как TIFF, разрешение картинки получается 2483x3508, а для отправки нужно чтобы было меньше 3500? можно как то без сторонних программ в самом finereader изменить разрешение картинки?
"Сервис" - "Опции" - "Сохранить" - "качество картинки"
При сканировании документа уменьшить границы его самого. Поля подрезать немного то есть на пару миллиметров.
З.ы. а для чего такая точность?
Открой графическим редактором и измени разрешение картинки на нужное.
Увидел правду
«Я полностью беру ответственность за то, что скажу. Будучи на Украине, я сталсвидетелем военных преступлений. Все они были совершены украинской армией. Но во Франции мы не говорим об этом!»
Адриен Боке
Тут демобилизованный французский военный, автор книги «Вставай и иди благодаря науке», отправился на Украину с гуманитарной миссией и провёл там три недели. По возвращении он принял непростое решение, которое может стоить ему жизни или, как минимум, создать много проблем: он решил донести до французов информацию о преступлениях, свидетелем которых стал на Украине.
Вот цитаты из его интервью:
Когда я вернулся во Францию с Украины, я был шокирован: телеканалы приглашают в качестве экспертов людей, которые не были на Украине и не знают ничего о том, что там сейчас творится. Однако, они осмеливаются рассуждать об этих событиях. Между тем, что я слышу с телеэкрана и тем, что я видел своими глазами, - пропасть.
Бойцы «Азова» повсюду. С неонацистскими нашивками. Меня шокирует то, что Европа снабжает оружием неонацистов. На их форме повсюду вышита символика эсесовцев. Они не только не скрывают своих взглядов. Они их афишируют. Я работал с этими людьми и лечил их. Они открыто говорят о том, что готовы уничтожать чернокожих и евреев.
Будучи там, я ничего не мог сделать. Только наблюдать и снимать видео. Я располагаю этими кадрами и буду использовать их в качестве свидетельства преступлений Украины.
Я стал свидетелем того, как украинские военные простреливали колени пленным русским солдатам и стреляли в голову служащим в звании выше офицерского.
Я лично видел американских кинооператоров, осуществлявших фальшивую киносъёмку с места событий, устраивающих инсценировки.
Все разрушенные гражданские здания, выдаваемые Украиной за бомбардировки по мирному населению, - ни что иное как результат неточной стрельбы украинцев по военным объектам.
ВСУ по ночам прячут боеприпасы в жилых домах, даже не ставя в известность жителей. Это называется использованием людей в качестве щита.
Буча - это инсценировка. Тела погибших были перемещены из других мест и намеренно размещены таким образом, чтобы произвести шокирующую съёмку».
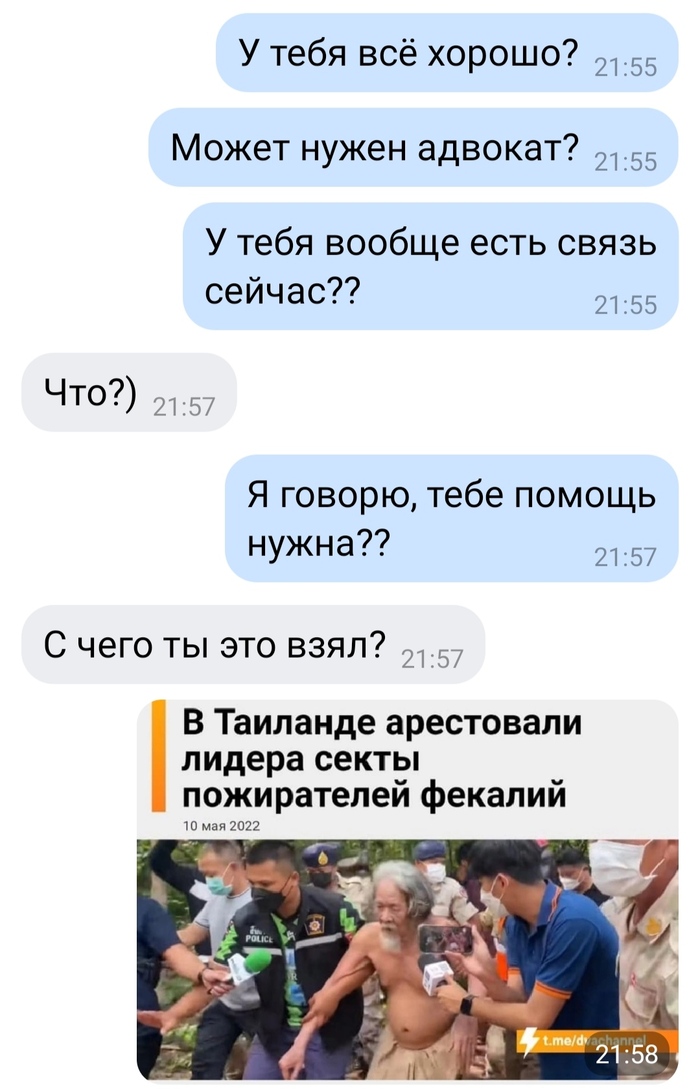
Когда переживаешь о приятелях

Альфа

Ответ на пост «Как "жалит" крапива под микроскопом»
Ловите лайфхак, может пригодится кому.
Отдыхали летом с супругой в деревне и она случайно ужалилась крапивой, ай-ой чешется. И тут мой выход. Срываю одуванчик, расщепляю его ножку и смазываю им место "укуса". Глаза супруги надо было видеть. Когда человек в 30 лет узнаёт что есть противоядие от врага детства номер один.

ПыСы отпускает сразу же. Узнал о нём от деревенских пацанов лет в 10. Если эта информация поможет хоть одному человеку, буду счастлив)))
Прикормил

Чувствую, сегодня поиграю.
Давным-давно, в 2015 году, я решил посмотреть, что такое war thunder,зарегал акк, посмотрел да и забыл. И вот года так 3 назад Гугл мне сообщил, что случайно мои пароли утекли в сеть, я поменял их везде, но только не для аккаунта gaijin.net . Мне все это время приходили письма о том, что какой-то индивид заходит с южной Кореи в мой акк и играет там.
Сел вот сейчас, сменил пароль, поставил двухфакторную аутентификацию, приду домой с работы и погляжу насколько сильно мне этот "суперхацкерломательаккаунтов" забустил акк за эти 3 года. =)
Читайте также: