
19 компьютеры в которых организована параллельная выборка и обработка разрядов слова относятся к
ПЕРСОНАЛЬНЫЙ КОМПЬЮТЕР (ПК или IBM PC) - это электронно-вычислительная машина (ЭВМ), предназначенная для работы в диалоге с человеком (пользователем).
ИНФОРМАТИКА - это наука, изучающая структуру и наиболее общие свойства информации, ее поиск, хранение, передачу и обработку с применением ЭВМ.
ИНФОРМАЦИЯ - это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии.
ФАЙЛ - это именованная область памяти на внешнем носителе. В файлах могут храниться тексты, документы, сами программы, рисунки и т.д.
КАТАЛОГ - это поименованное место на диске, в котором хранятся файлы.
ПРОГРАММИРОВАНИЕ - это подготовка задачи к решению ее на компьютере.
АЛГОРИТМ - это последовательность команд, ведущих к какой-либо цели.
Поколения ЭВМ
Первое поколение-компьютеры на электронных лампах (1946-1956г.). Быстродействие первых машин было несколько тысяч операций в секунду.
Второе поколение - компьютеры на транзисторах (1956-1964г.). Компьютеры на транзисторах резко уменьшили габариты, массу, потребляемую мощность, повысили быстродействие и надежность. Типичная отечественная машина (серий "Минск", "Урал") содержала около 25 тысяч транзисторов.
Третье поколение - компьютеры на микросхемах с малой степенью интеграции (1964-1971г.). Микросхемы позволили повысить быстродействие и надежность ЭВМ, снизить габариты, массу и потребляемую мощность.
Четвертое поколение - компьютеры на микропроцессорах (1971-настоящее время). Микропроцессор - это арифметическое и логическое устройство, выполненное чаще всего в виде одной микросхемы с большой степенью интеграции.
Пятое поколение (перспективное) - это ЭВМ, использующие новые технологии и новую элементную базу, например сверхбольшие интегральные схемы, оптические и магнито-оптические элементы, работающие посредством обычного разговорного языка, оснащенные огромными базами данных. Предполагается также использовать элементы искусственного интеллекта и распознавание зрительных и звуковых образов. Такие проекты разрабатываются в ведущих промышленно развитых странах.
СОСТАВ ПЕРСОНАЛЬНОГО КОМПЬЮТЕРА
У персональных компьютеров выделяют 2 части: аппаратную часть - Hardware и программное обеспечение Software.
В состав Персонального Компьютера входят:
1) Системный блок;
4) Мышь (стандартная конфигурация ПК).
Любой компьютер содержит:
1) Арифметико-логическое устройство (АЛУ),
2) Запоминающее устройство (память),
3) Управляющее устройство
4) Устройство ввода-вывода информации (УВВ) и имеет программу, хранимую в его памяти (архитектура Джона фон Неймана).
СИСТЕМНЫЙ БЛОК включает в себя устройства, обеспечивающие работу компьютера: процессор, оперативное запоминающее устройство (ОЗУ), накопители на гибких и жестких магнитных дисках, источник питания и др.
ПРОЦЕССОР предназначен для вычислений, обработки информации и управления работой компьютера; ОЗУ, накопители на гибких и жестких магнитных дисках - для хранения информации.
ПАМЯТЬ компьютера бывает внутренней и внешней. К внутренней памяти относится постоянное ЗУ (ПЗУ-BIOS или CMOS Setup), ОЗУ, КЭШ, видеопамять. К устройствам внешней памяти относятся накопители на жестком и гибком магнитных дисках (HDD и FDD), CD-ROM, магнитооптический диск и стриммер.
НАКОПИТЕЛИ на гибких (FDD) и жестких (HDD) магнитных дисках служат для постоянного хранения информации. При выключении источника питания информация на гибких и жестких дисках сохраняется.
КЛАВИАТУРА предназначена для ручного ввода информации в компьютер. Она содержит клавиши латинских и русских букв, цифр, различных знаков и специальные функциональные клавиши.
Клавиатура компьютера состоит из 6 групп клавиш:
1) Буквенно-цифровые;
2) Управляющие (Enter, Backspace, Ctrl, Alt, Shift, Tab, Esc, Caps Lock, Num Lock, Scroll Lock, Pause, Print Screen);
3) Функциональные (F1-F12);
4) Цифровая клавиатура;
5) Управления курсором (->, 6) Световые индикаторы функций (Caps Lock, Num Lock, Scroll Lock).
МОНИТОР (дисплей) предназначен для отображения информации на экране. Существуют текстовый и графический режимы дисплея. Дисплеи воспроизводят цветные и монохромные изображения.

Видеопамять - это специальная оперативная память, в которой формируется графическое изображение.
ПОРТЫ бывают параллельные и последовательные. По последовательному порту информация передается поразрядно (более медленно) по малому числу проводов. К последовательному порту подключаются мышь и модем. По параллельному порту информация передается одновременно по большому числу проводов, соответствующему числу разрядов.
3. Понятие о программном обеспечении (Software).
Программное обеспечение (ПО) - это совокупность программ, позволяющая организовать решение задач на ЭВМ. ПО и архитектура ЭВМ (аппаратное обеспечение) образуют комплекс взаимосвязанных и разнообразных функциональных средств ЭВМ, определяющих способность решения того или иного класса задач.
Небходимо различать ПО и математическое обеспечение (МО).
МО - это математические методы и алгоритмы, обеспечивающие решение поставленных задач. Программное обеспечение делится на 3 класса: системное ПО, прикладное ПО и системы программирования (инструментальные системы).
1. Системное ПО организует процесс обработки информации в ЭВМ. Главную часть системного ПО составляет Операционная система (ОС). К системному ПО также относятся программы для диагностики и контроля работы компьютера, архиваторы, антивирусы, программы для обслуживания дисков, программные оболочки, драйверы внешних устройств, сетевое ПО и телекоммуникационные программы.
2. Прикладное ПО предназначено для решения определенного класса задач пользователей. Существуют пакеты прикладных программ (например, MS Works) и библиотеки стандартных программ (например, MathCad для вычисления функций, построения графиков и решения уравнений). К прикладному ПО относятся текстовые и графические редакторы, электронные таблицы, системы управления базами данных (СУБД), графические редакторы систем автоматизированного проектирования (САПР), автоматизированные рабочие места (АРМ) бухгалтера, секретаря и т.д., издательские, информационные и справочные системы, обучающие и тестирующие программы, игровые программы. Примеры важнейших прикладных программ: Word, Excel,Works, Лексикон, Paint Brush, AutoCad.
3. Важнейшей частью ПО являются Системы программирования (инструментальные системы), позволяющие разрабатывать новые программы на языках программирования. Примеры важнейших систем программирования: Turbo Pascal, QBasic, Borland C++, Visual Basic.
4. Понятие об интерфейсе. Типы интерфейсов.
1. Интерфейс - это способ общения пользователя с персональным компьютером, пользователя с прикладными программами и программ между собой. Интерфейс служит для удобства управления программным обеспечением компьютера. Интерфейсы бывают однозадачные и многозадачные, однопользовательские и многопользовательские. Интерфейсы отличаются между собой по удобству управления программным обеспечением, то есть по способу запуска программ. Существуют универсальные интерфейсы, допускающие все способы запуска программ.
2. Типы интерфейсов.
Интерфейсы отличаются по способу доступа к командным файлам программ.
2.1. Команднострочный (текстовый) интерфейс.
Для управления компьютером в командную строку пишется (вводится с клавиатуры) команда, например, имя командного файла программы или специально зарезервированные операционной системой служебные слова. Команда может быть при необходимости отредактирована. Затем для исполнения команды нажимается клавиша Enter. Данный
2.3. Графический многооконный пиктографический интерфейс.
Представляет собой рабочий стол (DeskTop) на котором лежат пиктограммы (значки или иконки программ). Все операции производятся, как правило, мышью. Для управления компьютером курсор мыши подводят к пиктограмме и запуск программы осуществляют щелчком левой кнопки мыши по пиктограмме.
Оперативная память у машин ЕDSАС и ЕDVАС реализована на ртутных лини- ях задержки, которые представляют собой тонкие герметичные металлические трубки с парами ртути внутри (рис. 5.5).
Биты, которые нужно сохранить в памяти, подаются в виде электрических импуль- сов на передающий кристалл. Замкнутый контур памяти принимает их и сохра- няет в описанном ранее динамическом режиме. При необходимости выполнить чтение информация снимается с линии обратной связи, как показано на рис. 5.5.
По сравнению с реализацией памяти в виде триггеров на электронных лампах, такая система отличается большей плотностью хранения данных. Например, трубка длиной 1 м может сохранять до тысячи бит. Если на этой же площади разместить ламповые триггеры, то в них можно сохранить только десятки бит. Кроме того, память на ртутных линиях задержки дешевле, чем ламповая память. Поэтому на ламповых триггерах были реализованы только самые ответственные узлы этих машин, в том числе их арифметико-логические устройства.
Однако память на ртутных линиях допускает только последовательную выборку записанных в нее битов. Следовательно, сложение, а также другие операции мо- гут выполняться только поразрядно. Например, для сложения 16-битовых чисел требуется не менее 16 тактов работы процессора. Такая архитектура считается разрядно-последовательной.
В 1952 г. была пущена в эксплуатацию машина «Whirlwind 1», в которой опера- тивная память была построена на ферритовых магнитных сердечниках, пред- ставлявших собой колечки диаметром менее 1 мм. Материал, из которого они сделаны, обладает способностью длительное время сохранять одно из двух возмож- ных состояний намагниченности (аналог северного и южного полюсов у магни- та). Одно из этих состояний считается цифрой 0, а второе — цифрой 1 (рис. 5.6). Через каждое колечко проходит несколько проводов. Пропуская по ним ток нужных величины и направления, можно изменять состояние намагниченности или же определять текущее состояние, то есть осуществлять запись или чтение бита. Память на магнитных сердечниках оказалась гораздо компактнее, чем па- мять на электронных лампах накаливания. Так, блок памяти объемом 1024 бита размещался на площади всего 12 х 12 см.
Не менее важным свойством памяти на ферритовых сердечниках является воз- можность одновременной, параллельной выборки всех битов машинного слова. Компьютеры, в которых организована параллельная выборка и обработка разря- дов слова, относятся к разрядно-параллельной архитектуре. Впервые такой способ был реализован в выпущенном в 1953 г. компьютере IBM 701. При ис- пользовании параллельного способа обмена и обработки на сложение 16-битовых чисел требуется всего 1-2 такта работы процессора.
Лекция 2. Архитектура векторно-конвейерных супер-ЭВМ CRAY C90
Оперативная память этого компьютера разделяется всеми процессорами и секцией ввода/вывода. Каждое слово состоит из 80-ти разрядов: 64 для хранения данных и 16 для коррекции ошибок. Для увеличения скорости выборки данных память разделена на множество банков, которые могут работать одновременно.
Каждый процессор имеет доступ к ОП через четыре порта с пропускной способностью два слова за один такт каждый, причем один из портов всегда связан с секций ввода/вывода и по крайней мере один из портов всегда выделен под операцию записи.
В максимальной конфигурации вся память разделена на 8 секций, каждая секция на 8 подсекций, каждая подсекция на 16 банков. Адреса идут с чередованием по каждому из данных параметров:
При одновременном обращении к одной и той же секции из разных портов возникает задержка в 1 такт, а при обращении к одной и той же подсекции одной секции задержка варьируется от 1 до 6 тактов. При выборке последовательно расположенных данных или при выборке с любым нечетным шагом конфликтов не возникает.
Секция ввода/вывода
- Low-speed (LOSP) channels - 6 Mbytes/s
- High-speed (HISP) channels - 200 Mbytes/s
- Very high-speed (VHISP) channels - 1800 Mbytes/s
Секция межпроцессорного взаимодействия
Секция межпроцессорного взаимодействия содержит разделяемые регистры и семафоры, предназначенные для передачи данных и управляющей информации между процессорами. Регистры и семафоры разделены на одинаковые группы (кластеры), каждый кластер содержит 8 (32-разрядных) разделяемых адресных (SB) регистра, 8 (64-разрядных) разделяемых скалярных (ST) регистра и 32 однобитовых семафора.
Вычислительная секция процессора
Все процессоры имеют одинаковую вычислительную секцию, состоящую из регистров, функциональных устройств (ФУ) и сети коммуникаций. Регистры и ФУ могут хранить и обрабатывать три типа данных: адреса (A-регистры, B-регистры), скаляры (S-регистры, T-регистры) и вектора (V-регистры).
Регистры
Каждый процессор имеет три набора основных регистров (A, S, V), которые имеют связь как с памятью, так и с ФУ. Для регистров A и S существуют промежуточные наборы регистров B и T, играющие роль буферов для основных регистров.
Адресные регистры: A-регистры, 8 штук по 32 разряда, для хранения и вычисления адресов, индексации, указания величины сдвигов, числа итераций циклов и т.д. B-регистры, 64 штуки по 32 разряда.
Скалярные регистры: S-регистры, 8 штук по 64 разряда, для хранения аргументов и результатов скалярной арифметики, иногда содержат операнд для векторных команд. T-регистры, 64 штуки по 64 разряда. Скалярные регистры используются для выполнения как скалярных, так и векторных команд.
Векторные регистры: V-регистры, 8 штук на 128 64-разрядных слова каждый. Векторные регистры используются только для выполнения векторных команд.
Регистр длины вектора: 8 разрядов.
Регистр маски вектора: 128 разрядов.
Функциональные устройства
ФУ исполняют свой набор команд и могут работать одновременно друг с другом. Все ФУ конвейерные и делятся на четыре группы: адресные, скалярные, векторные и для работы с плавающей точкой.
Адресные ФУ (2): целочисленное сложение/вычитание, целочисленное умножение.
Скалярные ФУ (4): целочисленное сложение/вычитание, логические поразрядные операции, сдвиг, число единиц/число нулей до первой единицы.
Векторные ФУ (5-7): целочисленное сложение/вычитание, сдвиг, логические поразрядные операции (1-2), число единиц/число нулей до первой единицы (1-2), умножение битовых матриц (0-1). Предназначены для выполнения только векторных команд.
ФУ с плавающей точкой (3): сложение/вычитание, умножение, нахождение обратной величины. Предназначены для выполнения как векторных, так и скалярных команд.
Векторные ФУ и ФУ с плавающей точкой продублированы: векторные команды разбивают 128 элементов векторных регистров на четные и нечетные, обрабатываемые одновременно двумя конвейерами (pipe 0, pipe 1). Когда завершается выполнение очередной пары операций результаты записываются на соответствующие четные и нечетные позиции выходного регистра. В полностью скалярных операциях, использующих ФУ с плавающей точкой, работает только один конвейер.
ФУ имеют различное число ступеней конвейера, но каждая ступень срабатывает за один такт, поэтому при полной загрузке все ФУ могут выдавать результат каждый такт.
Секция управления процессора
Команды выбираются из ОП блоками и заносятся в буфера команд, откуда они затем выбираются для исполнения. Если необходимой для исполнения команды нет в буферах команд, то происходит выборка очередного блока.
Команды имеют различный формат и могут занимать 1 пакет (16 разрядов), 2 пакета или 3 пакета (в одном слове 64 разряда, следовательно, в слове содержится 4 пакета). Максимальная длина программы на CRAY C90 равна 1 Гигаслову.
Параллельное выполнение программ
Конвейеризация выполнения команд
Все основные операции, выполняемые процессором: обращения в память, обработка команд и выполнение инструкций являются конвейерными.
Независимость функциональных устройств
Большинство ФУ в CRAY C90 являются независимыми, поэтому несколько операций могут выполняться одновременно. Для операции A=(B+C)*D*E порядок выполнения может быть следующим (все аргументы загружены в S регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья.
Векторная обработка
Векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. Скорость выполнения операций в векторном режиме приблизительно в 10 раз выше скорости скалярной обработки. Для фрагмента типа
в скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(I), прочитать элемент C(I), выполнить сложение, записать результат в A(I), увеличить параметр цикла, проверить условие цикла. В векторном режиме этот фрагмент преобразуется в: загрузить порцию массива B, загрузить порцию массива C (эти две операции будут выполняться со сдвигом в один такт, т.е. практически одновременно), векторное сложение, запись порции массива в память, если размер массивов больше длины векторных регистров, то повторить эту последовательность некоторое число раз.
Перед тем, как векторная операция начнет выдавать результаты, проходит некоторое время (startup), связанное с заполнением конвейера и подкачкой аргументов. Чем больше длина векторов, тем менее заметным оказывается влияние данного начального промежутка времени на все время выполнения программы.
Векторные операции, использующие различные ФУ и регистры, могут выполняться параллельно.
Зацепление функциональных устройств
Архитектура CRAY Y-MP C90 позволяет использовать регистр результатов векторной операции в качестве входного регистра для последующей векторной операции, т.е. выход сразу подается на вход. Это называется зацеплением векторных операций. Вообще говоря, глубина зацепления может быть любой, например, чтение векторов, выполнение операции сложения, выполнение операции умножения, запись векторов.
Многопроцессорная обработка: multiprogramming, multitasking
Multiprogramming - выполнение нескольких независимых программ на различных процессорах.
Multitasking - выполнение одной программы на нескольких процессорах.
Лекция 4. Архитектура массивно-параллельных компьютеров (на примере CRAY T3D). Особенности программирования
Основные причины появления массивно-параллельных компьютеров - это, во-первых, необходимость построения компьютеров с гигантской производительностью, и, во-вторых, необходимость производства компьютеров в большом диапазоне как производительности, так и стоимости. Не все в состоянии купить однопроцессорный CRAY Y-MP C90, да и не всегда такие мощности и нужны. Для массивно-параллельного компьютера, в котором число процессоров может сильно меняться, всегда можно подобрать конфигурацию с заранее заданной производительностью и/или стоимостью.
- используемые микропроцессоры: Intel Paragon - i860, IBM SP2 - PowerPC 604e или Power2 SC, CRAY T3D - DEC ALPHA;
- коммуникационная сеть: Intel Paragon - двумерная прямоугольная решетка, IBM SP2 - коммутатор, CRAY T3D - трехмерный тор;
- организация памяти: Intel Paragon, IBM SP2, CRAY T3D - распределенная память;
- наличие или отсутствие host-компьютера: Intel Paragon, IBM SP2 - нет, CRAY T3D - есть.
Общая структура компьютера CRAY T3D
Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами.
CRAY T3D подключается к хост-компьютеру (главному или ведущему), роль которого, в частности, может исполнять CRAY Y-MP C90. Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с.
Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основные компоненты: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода.
Вычислительные узлы и процессорные элементы
Вычислительный узел состоит из двух процессорных элементов (ПЭ), сетевого интерфейса контроллера блочных передач. Оба процессорных элемента, входящие в состав вычислительного узла, идентичны и могут работать независимо друг от друга.
Процессорный элемент. Каждый ПЭ содержит микропроцессор, локальную память и некоторые вспомогательные схемы.
Микропроцессор - это 64-х разрядный RISC (Reduced Instruction Set Computer) процессор ALPHA фирмы DEC, работающий на тактовой частоте 150 MHz. Микропроцессор имеет внутреннюю кэш-память команд и кэш-память данных.
Объем локальной памяти ПЭ - 8 Mслов. Локальная память каждого процессорного элемента является частью физически распределенной, но логически разделяемой (или общей), памяти всего компьютера. В самом деле, память физически распределена, так как каждый ПЭ содержит свою локальную память. В тоже время, память разделяется всеми ПЭ, так как каждый ПЭ может обращаться к памяти любого другого ПЭ, не прерывая его работы.
Обращение к памяти другого ПЭ лишь в 6 раз медленнее, чем обращение к своей собственной локальной памяти.
Контроллер блочных передач - это контроллер асинхронного прямого доступа в память, который помогает перераспределять данные, расположенные в локальной памяти разных ПЭ компьютера CRAY T3D, без прерывания работы самих ПЭ.
Коммуникационная сеть
Коммуникационная сеть обеспечивает передачу информации между вычислительными узлами и узлами ввода/вывода с максимальной скоростью в 140M байт/с. Сеть образует трехмерную решетку, соединяя сетевые маршрутизаторы узлов в направлениях X , Y , Z . Каждая элементарная связь между двумя узлами - это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
Топология сети, чередование вычислительных узлов

Коммуникационная сеть компьютера CRAY T3D организована в виде двунаправленного трехмерного тора, что имеет свои преимущества перед другими способами организации связи:
- быстрая связь граничных узлов и небольшое среднее число перемещений по тору при взаимодействии разных ПЭ: максимальное расстояние в сети для конфигурации из 128 ПЭ равно 6, а для 2048 ПЭ равно 12;
- возможность выбора другого маршрута для обхода поврежденных связей.
Все узлы в коммуникационной сети в размерностях X и Z расположены с чередованием, что позволяет минимизировать длину максимального физического соединения между ПЭ.
Маршрутизация в сети и сетевые маршрутизаторы.
При выборе маршрута для обмена данными между двумя узлами сетевые маршрутизаторы всегда сначала выполняют смещение по размерности X , затем по Y , а в конце по Z . Так как смещение может быть как положительным, так и отрицательным, то этот механизм помогает минимизировать число перемещений по сети и обойти поврежденные связи.
Сетевые маршрутизаторы каждого вычислительного узла определяют путь перемещения каждого пакета и могут осуществлять параллельный транзит данных по каждому из трех измерений X , Y , Z .
Нумерация вычислительных узлов.
Каждому ПЭ в системе присвоен уникальный физический номер , определяющий его физическое расположение, который и используется непосредственно аппаратурой.
Не обязательно все физические ПЭ принимают участие в формировании логической конфигурации компьютера. Например, 512-процессорная конфигурация компьютера CRAY T3D реально содержит 520 физических ПЭ, 8 из которых находятся в резерве. Каждому физическому ПЭ присваиваится логический номер , определяющий его расположение в логической конфигурации компьютера, которая уже и образует трехмерный тор.
Каждой программе пользователя из трехмерной решетки вычислительных узлов выделяется отдельный раздел, имеющий форму прямоугольного параллелепипеда, на котором работает только данная программа (не считая компонент ОС). Для последовательной нумерации ПЭ, выделенных пользователю, вводится виртуальная нумерация .
Особенности синхронизации процессорных элементов
Для поддержки синхронизации процессорных элементов предусмотрена аппаратная реализация одного из наиболее "тяжелых" видов синхронизации - барьеров синхронизации. Барьер - это точка в программе, при достижении которой каждый процессор должен ждать до тех пор, пока остальные также не дойдут до барьера, и лишь после этого момента все процессы могут продолжать работу дальше.
Если схемы AND заменить на OR, то получится цепь для реализации механизма "эврика": как только один ПЭ выставил значение 1, эта единица распространяется всем ПЭ, сигнализируя о некотором событии на ПЭ. Это исключительно полезно, например, в задачах поиска.
Факторы, снижающие производительность параллельных компьютеров
Начнем с уже упоминавшегося закона Амдала . Для массивно-параллельных компьютеров он играет еще большую роль, чем для векторно-конвейерных. В самом деле, в таблице 1 показано, на какое максимальное ускорение работы программы можно рассчитывать в зависимости от доли последовательных вычислений и числа доступных процессоров. Предполагается, что параллельная секция может быть выполнена без каких-либо дополнительных накладных расходов. Так как в программе всегда присутствует инициализация, ввод/вывод и некоторые сугубо последовательные действия, то недооценивать данный фактор никак нельзя - практически вся программа должна исполняться в параллельном режиме, что можно обеспечить только после анализа всей (!) программы. Число
ПЭ
Доля последовательных вычислений 50% 25% 10% 5% 2% 2 1.33 1.60 1.82 1.90 1.96 8 1.78 2.91 4.71 5.93 7.02 32 1.94 3.66 7.80 12.55 19.75 512 1.99 3.97 9.83 19.28 45.63 2048 2.00 3.99 9.96 19.82 48.83
Табл. 1. Максимальное ускорение работы программы в зависимости от доли последовательных вычислений и числа используемых процессоров.
Для достижения эффективной параллельной обработки необходимо добиться равномерной загрузки всех процессоров. Если равномерности нет, то часть процессоров неизбежно будет простаивать, ожидая остальных, хотя в этот момент они могли бы выполнять полезную работу. Иногда равномерность получается автоматически, например, при обработке прямоугольных матриц достаточно большого размера, однако уже при переходе к треугольным матрицам добиться хорошей равномерности не так просто.
Чтобы не сложилось совсем плохого впечатления о массивно-параллельных компьютерах, надо заканчивать с негативными факторами, потому последний фактор - это реальная производительность одного процессора . Разные модели микропроцессоров могут поддерживать несколько уровней кэш-памяти, иметь специализированные функциональные устройства, регистровую структуру и т.п. Каждый микропроцессор, в конце концов, может иметь векторно-конвейерную архитектуру и в этом случае ему присущи практически все те факторы, которые мы обсуждали в лекции, посвященной особенностям программирования векторно-конвейерных компьютеров.
Целью работы является проверка усвоения материалов по архитектуре операционного устройства центрального процессора ВМ и взаимодействия входящих в нее элементов.
Управляющее слово ЦП составляется из разрядов управления устройств, входящих в ОУ ЦП.
Для выполнения контрольной работы необходимо уяснить порядок функционирования составляющих операционное устройство элементов вычислительной техники: мультиплексоров, дешифратора, арифметико-логического устройства (АЛУ), регистров и оперативного запоминающего устройства.
Из многих информационных входов I0…I3 мультиплексор подает на выход один, соответствующий коду, установленному на управляющих входах a1, a0. Структурная схема мультиплексора имеет вид:
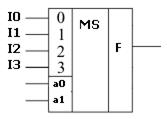
Рис. 1. Схема мультиплексора.
| a1 | a0 | F |
| 0 | 0 | I0 |
| 0 | 1 | I1 |
| 1 | 0 | I2 |
| 1 | 1 | I3 |
Это устройство, которое имеет единицу только на одном из выходов, соответствующему коду входных информационных сигналов.
Дешифратор на схемах обозначается следующим образом:

Рис. 2. Схема дешифратора.
Таблица соответствия для двухвходового дешифратора имеет вид:
| Е | Х2 | Х1 | L0 | L1 | L2 | L3 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 1 | X | X | 0 | 0 | 0 | 0 |
Регистры обычно строятся на D триггерах. Обозначение регистра на схемах может иметь вид:
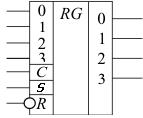
Рис. 3. Схема регистра.
АЛУ выполнено на основе комбинационных схем, выходные состояния которых полностью определяются входными информационными и управляющими сигналами.
Таблица микроопераций АЛУ
| M | S1 | S0 | C | Микрооперации | Наименование |
| 0 | 0 | 0 | 0 | A | Передача А |
| 0 | 0 | 0 | 1 | A+1 | Инкремент А |
| 0 | 0 | 1 | 0 | A+B | Сумма |
| 0 | 0 | 1 | 1 | A+B+1 | Сумма с инкрементом |
| 0 | 1 | 0 | 0 | A-B-1 | Разность с декрементом |
| 0 | 1 | 0 | 1 | A-B | Разность |
| 0 | 1 | 1 | 0 | A-1 | Декремент А |
| 0 | 1 | 1 | 1 | A | Передача А |
| 1 | 0 | 0 | Х | A۷B | ИЛИ |
| 1 | 0 | 1 | Х | A  B | Искл. ИЛИ |
| 1 | 1 | 0 | Х | A۸B | И |
| 1 | 1 | 1 | Х | Не А |
Операционное устройство (ОУ) осуществляет операции (арифметические и логические) над входными информационными сигналами. Характер операций, входные и выходные сигналы (регистры, вход, выход и оперативное запоминающее устройство) определяются управляющими сигналами устройств, входящих в состав ОУ.
Управляющее слово ВМ составляется из управляющих разрядов MSA, MSB, АЛУ, DS, MSM, WR.
Задача устройства управления – обеспечить выдачу управляющего слова ЦП. Иначе он называется микрокод, который управляет работой аппаратуры ЦП. Обычно он записывается в постоянное запоминающее устройство (ПЗУ) центрального процессора (прошивается).

Рис. 4. Схема операционного устройства.
Задача контрольной работы состоит в том, чтобы расписать управляющее слово ЦП для различных микроопераций.
| № №варианта | Записать управляющее слово |
| 1 | Sß INPR IR |
| 2 | INPRß IR MAR |
| 3 | IRß MAR OUTR |
| 4 | MARß OUTR – AC |
| 5 | OUTRßAC – MDR – 1 |
| 6 | ACß MDR + PC + 1 |
| 7 | MDRß PC + INPR |
| 8 | OUTRß |
| 9 | Sß INPR + 1 |
| 10 | INPRß IR + MAR |
| 11 | IRß MAR + OUTR + 1 |
| 12 | MARß OUTR – AC – 1 |
| 13 | OUTRß AC – MDR |
| 14 | ACß |
| 15 | MDRß |
| 16 | PCß |
| 17 | OUTRß IR – 1 |
| 18 | IRß |
| 19 | PCß |
| 20 | Sß |
| 21 | INPRß MAR + OUTR |
| 22 | MDRß OUTR + IR + 1 |
| 23 | ACß IR – PC – 1 |
| 24 | MARß INPR – AC |
| 25 | PCß |
| 26 | IRß OUTR + PC |
| 27 | OUTRß MDR + INPR + 1 |
| 28 | Sß INPR – AC – 1 |
| 29 | MDRß AC – MAR |
| 30 | INPRß |
| 31 | ACß |
| 32 | MARß |
| 33 | Sß OUTR |
| 34 | Sß AC+OUTR |
| 35 | Sß IR+INPR+1 |
| 36 | SßOUTR – MDR |
| 37 | SßINPR – MAR – 1 |
| 38 | SßIR+1 |
| 39 | SßOUTR – 1 |
| 40 | Sß AC PC |
Сделать выводы по проделанной работе.
ПАРА_АрхВМиС_Лекция_СМИРНОВ_Н_А_ИНБО-01,-02, -03,04,- 05, 06,18
1. Рассмотрим схему центрального процессора (операционное устройство) в 2 этапа. Сначала рассмотрим упрощенную схему. Затем усложним её.
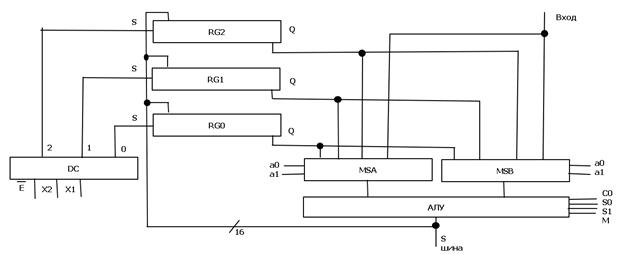
Рис. 1 Схема вспомогательная
Подачей управляющих сигналов на дешифратор, мультиплексоры и АЛУ ведает устройство управления ЦП, которое выдает так называемое управляющее слово процессора. Оно состоит из разрядов управления этими устройствами. – по 2 разряда на мультиплексоры MSA и MSB, 3 разряда на дешифратор DС и 4 разряда на АЛУ.
1.Пусть надо в RG1 поместить сумму чисел из RG2 и RG0:
| 10 | 00 | 0010 | 001 |
| 11 | ХХ | 0000 | 010 |
3. RG0 ← RG2 ۸ вход
| 10 | 00 | 110Х | 000 |
| 01 | ХХ | 1111 | 1ХХ |
Рассмотрим более полный вариант схемы ЦП.

Рис. 2. Схема ОУ ЦП
Управляющее слово ВМ будет составлено из управляющих разрядов MSA, MSB, АЛУ, DS, MSM, WR.
Рассмотрим примеры управляющего слова ЦП для некоторых операций:
| MSA | MSB | АЛУ | DC | MSM | WR |
| 001 | 100 | 0010 | 0001 | x | 0 |
| MSA | MSB | АЛУ | DC | MSM | WR |
| 000 | xxx | 0000 | 0011 | x | 0 |
| MSA | MSB | АЛУ | DC | MSM | WR |
| xxx | xxx | xxxx | 0100 | 1 | 0 |
Пустой такт NOP
| MSA | MSB | АЛУ | DC | MSM | WR |
| xxx | xxx | xxxx | 1xxx | x | 0 |
Таким образом, мы спроектировали схему операционного устройства центрального процессора учебной ВМ.
5.9. Устройство управления ЦП
Задача устройства управления – обеспечить выдачу управляющего слова ЦП. Иначе он называется микрокод, который управляет работой аппаратуры ЦП. Обычно он записывается в постоянное запоминающее устройство (ПЗУ) центрального процессора (прошивается).
Что должно делать УУ? У нас есть исполняемый код программы. Дальше в ходе выполнения исполняемого кода на ВМ им занимается операционная система – программа, которая выдаёт команды для УУ ЦП.
Рис. 3 Алгоритм управления в ВМ
Последовательность работы устройства управления задается циклами.
Для начала рассмотрим цикл выборки команды. Ведь прежде чем выполнить команду, надо выбрать её из памяти ВМ.
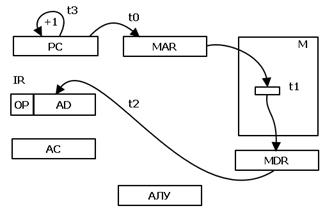
Рис. 4 Цикл выборки команды
Для выборки команды из памяти ВМ надо, во-первых, поместить адрес команды из регистра адреса команды в регистр адреса памяти, во-вторых, прочитать команду из ячейки памяти в регистр данных памяти, в-третьих. Переслать команду в регистр команды, в-четвертых, подготовить счетчик команд для выборки следующей команды – инкрементировать PC.
То есть, последовательно надо выполнить 4 действия, обозначенные на рис. 4 t0, t1, t2, t3. Следовательно, цикл выборки команды осуществляется за 4 такта.
Само выполнение команды происходит следующим образом:
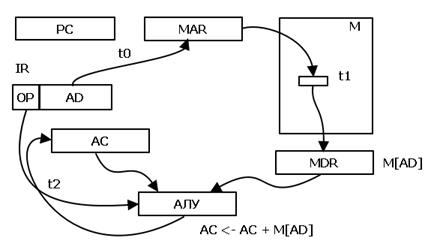
Рис. 5 Цикл выполнения команды
Рассмотрим цикл выполнения команды на примере операции сложения.
Нулевой такт – пересылка адреса операнда из регистра команды в регистр адреса памяти. Первый такт – выборка из памяти операнда и размещение его в регистре данных памяти. Второй такт – собственно выполнение сложения в АЛУ с размещением результата в аккумуляторе.
Здесь мы рассматриваем выполнение команды с прямой адресацией, когда в адресном поле команды находится адрес операнда.
Машину Фон Неймана стали совершенствовать, поскольку для выполнения некоторых команд более удобными являются другие методы адресации операндов. Всего способов адресации насчитывается около 20. Из них в каждой конкретной ВМ используется только часть, по выбору конструкторов ВМ и в соответствии с назначением ВМ (ориентированием ВМ на обработку определённых видов информации).
Допустим, что у нас в памяти содержится такая информация:
| Адрес | Содержание |
| 30 | 40 |
| 40 | 50 |
| 50 | 60 |
Рассмотрим выполнение команды LDA (загрузку аккумулятора) с помощью различных методов адресации.
Прямая адресация: LDA 30 /загрузить в аккумулятор слово из ячейки с адресом 30. В результате выполнения команды АC ← 40.
Косвенная адресация: LDA @ 30. /загрузить в аккумулятор слово из ячейки, адрес которой находится в ячейке 30. В результате выполнения команды АC ← 50. То есть в команде содержится не адрес операнда, а адрес адреса операнда. Соответственно, для подготовки операции требуется двойное обращение к памяти.
Существуют и другие способы адресации, которые здесь мы не будем рассматривать.
В общем случае для указания способа адресации в команде выделяется отдельное поле, содержащее необходимое количество разрядов. Для декодирования способа адресации при этом необходим ещё один цикл – цикл дешифрации команды.
Таким образом, мы получили наличие в УУ ЦП следующих циклов:
1) Цикл выборки команды – С0;
2) Цикл дешифрации команды – С1;
3) Цикл выполнения команды – С2;
4) Цикл обработки прерывания – С3.

Рис.6. Алгоритм работы устройства управления ЦП ВМ
Последний цикл необходим для обработки требований прерывания, вырабатываемых внешними устройствами ВМ (например, клавиатурой, устройством ввода/вывода и т.д.) или при появлении нештатных ситуаций при выполнении команд (деление на ноль, переполнение разрядов и др.). Как происходит цикл обработки прерывания мы рассмотрим позднее – при изучении операционных систем.
На основании изложенного алгоритм работы УУ ЦП имеет вид, представленный на рис. 6.
Как видите, ВМ реагирует на прерывание только после окончания выполнения очередной команды программы. В противном случае очень трудно запомнить текущее состояние ЦП для возврата в программу после обработки прерывания.
5.10. Структурная схема УУ ЦП
Структурная схема УУ ЦП изображена на рис. 7.
В основе УУ имеется ПЗУ; сигналы, вырабатываемые на его выходе, управляют работой ВМ. Генератор ВМ вырабатывает тактовую частоту. Сигнал SE представляет собой сигнал разрешения работы и останов. При SE=0 сигналы генератора ВМ не проходят через схему совпадения, и схема управления не работает – останов. При SE=1 сигналы генератора ВМ проходят через схему совпадения и поступают на вход двухразрядного счетчика, соединённого по выходу с дешифратором тактов. Логика работы последнего приведена на рис. 7.
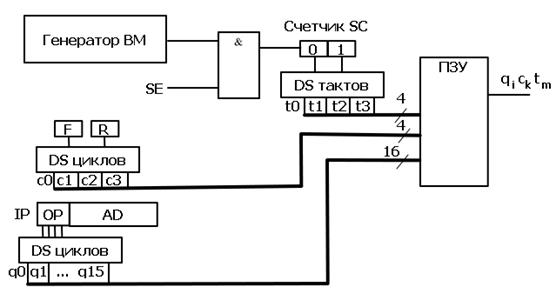
Рис. 7. Структурная схема УУ ЦП
| ГИ |
| t0 |
| t1 |
| t2 |
| t3 |
Рис. 8. Временная диаграмма работы DС тактов
В ВМ такты не пересекаются по времени.
DС циклов работает по выходам двух триггеров F и R. В зависимости от состояния этих триггеров формируется сигнал на соответствующем его выходе.
| F | R | Цикл | Обозначение цикла |
| 0 | 0 | Выборки команды | С0 |
| 0 | 1 | Дешифрации команды | С1 |
| 1 | 0 | Выполнения команды | С2 |
| 1 | 1 | Прерывания | С3 |
DС команды работает по состоянию разрядов регистра команд, соответствующих полю кода операции. В нашем случае код имеет 4 разряда, что соответствует 16 выходам дешифратора команд.
Выходы всех трех дешифраторов составляют адрес ПЗУ, в котором записана (прошита) информация соответствующая содержимому управляющего слова процессора данного такта данного цикла данной команды.
Такова в общем виде структура УУ ЦП.
Таблица команд учебной ВМ представлена в таблице.
Обычно ВМ содержит команды различной длины – безадресные, одноадресные, двухадресные и др. В нашей учебной ВМ мы рассматриваем все команды единой длины равной 16 двоичным разрядам. Поэтому безадресные команды (с номерами от 12 до 15) содержат фиктивный адрес, равный FFF.
Рассмотрим для примера команду сложения ADD. Для неё в поле кода операции будет иметься значение 2 16-ричного кода. В адресном поле находится 12-разрядный адрес AD. Напишем микрокоманды циклов выборки и выполнения команды.
С0t0 : MAR← PC / подготовить выборку команды из памяти.
С0t1 : MDR← M[MAR] / прочесть команду из памяти по адресу MAR.
С0t2 : IR← MDR / поместить команду в регистр команды.
С0t3 : PC← PC +1, F← 1/ подготовить адрес след. команды, перейти к циклу выполнения команды.
С2t0 : MAR← IR[AD] / передать адрес операнда в регистр адреса памяти MAR.
С2t1 : MDR← M[MAR] / прочесть операнд из памяти по адресу MAR.
С2t2 : AC← AC+MDR / выполнить сложение.
С2t3 : F← 0/ перейти к циклу выборки команды.
Так выполняются микрокоманды ВМ в циклах выборки и выполнения команды сложения. Аналогичным образом можно описать порядок выполнения любой команды из перечня команд ВМ.
ВМ фон Неймана первоначально была рассчитана, как и наша учебная ВМ, только для одного типа адресации – прямой адресации. Для других типов адресации, что задаётся обычно в специальном поле команды, требуется наличие цикла дешифрации команды и осуществление выборки операндов соответствующим образом. Мы цикл дешифрации команды не рассматриваем, поскольку считаем, что используется только прямая адресация операндов.
Следующая контрольная работа состоит в том, чтобы вы научились строить команды из микрокоманд подобно рассмотренному примеру. Объем работы в контрольной работе велик. Для оформления работы надо использовать по крайней мере один лист формата А4.
Рассмотрим типовую задачу и приведём пример её решения.
Задача. По адресу 5А8 записана команда сложения ADD с адресом F12. По этому адресу записан операнд 731F. В регистре АС находится операнд 8721. Определить информацию, которая будет иметься в регистрах ВМ PC, MAR, MDR, IR, AC после выполнения данной команды.
Читайте также: