
Запрос xpath для поиска данных для excel
XPath – это невероятно гибкий, мощный, и вместе с тем сравнительно простой инструмент для навигации по документам XML. Предлагаю перевод руководства по XPath, сделанный на основе руководства консорциума W3C.
XPath используется для навигации по элементам и атрибутам XML-документа. XPath является одним из основных элементов в стандарте XSLT консорциума W3C.
1 Что такое XPath
- XPath определяет синтаксис для определения частей документа XML;
- XPath использует выражения пути для навигации по элементам XML-документов;
- XPath содержит библиотеку стандартных функций;
- XPath является одним из основных элементов в XSLT;
- XPath является рекомендацией W3C.
Выражения XPath
XPath использует выражения пути для выбора отдельных узлов или набора узлов в документе XML. Эти выражения очень похожи на выражения, которые вы видите, когда работаете с традиционной файловой системой компьютера.
Стандартные функции XPath
XPath включает в себя более 100 встроенных функций. Есть функции для строковых и числовых значений, даты и времени, сравнения узлов и манипулирования QName, управления последовательностями, булевых значений, и многое другое.
XPath используется в XSLT
XPath является одним из основных элементов в стандарте XSLT. Без знания XPath вы не будете иметь возможность создавать XSLT-документы.
XPath является рекомендацией консорциума W3C
XPath стал рекомендацией W3C 16 ноября 1999 года. XPath был разработан для использования в XSLT, XPointer и другом программном обеспечении для разбора (парсинга) документов XML.
2 Терминология XPath
В XPath существует семь видов узлов: элемент, атрибут, текст, пространство имён, инструкции обработки, комментарии и узлы документа. XML-документы обрабатываются в виде деревьев узлов. Верхний элемент дерева называется корневым элементом. Посмотрите на следующий документ XML:
Пример узлов в документе XML выше:
Атомарные значения
Атомарные значения являются узлами, не имеющие детей или родителей. Пример атомарных значений:
Элементы
Элементы – это атомарные значения или узлы.
3 Отношенияузлов
Родитель
Каждый элемент и атрибут имеет одного родителя. В следующем примере элемент «книга» (book) является родителем элементов «название» (title), «автор» (author), «год» (year) и «цена» (price):
Потомки
Узлы элементов могут иметь ноль, один или более потомков. В следующем примере элементы «название», «автор», «год» и «цена» – они все потомки элемента книга:
Элементы одного уровня
Это узлы, которые имеют одного и того же родителя. В следующем примере элементы «название», «автор», «год» и «цена» все являются элементами одного уровня:
Предки
Родитель узла, родитель родителя узла и т.д. В следующем примере предки элемента «название» (title) – это элементы «книга» (book) и «книжный магазин» (bookstore):
Потомки
Дети узла, дети детей узла и т.д. В следующем примере потомками элемента «книжный магазин» являются элементы «книга», «название», «автор», «год» и «цена»:
4 Синтаксис XPath
XPath использует выражения пути для выбора узлов или множества узлов в документе XML. Узел можно выбрать, следуя пути или по шагам. Мы будем использовать следующий XML-документ в приведённых ниже примерах.
Выбор узлов
С помощью выражений XPath для выбора узлов в документе XML можно выбрать узел, следуя пути или шагам. Самые полезные выражения пути перечислены ниже:
| Выражение | Описание |
|---|---|
| имя_узла | Выбирает все узлы с именем имя_узла |
| / | Выбирает от корневого узла |
| // | Выбирает узлы в документе от текущего узла, который соответствует выбору, независимо от того, где они находятся |
| . | Выбирает текущий узел |
| .. | Выбирает родителя текущего узла |
| @ | Выбирает атрибуты |
В приведенной ниже таблице перечислены некоторые пути выражения и результат выполнения выражения:
Примечание: Если путь начинается с косой черты (/), он всегда представляет собой абсолютный путь к элементу!
Предикаты
Предикаты используются для поиска специфического узла или узла, который содержит специфическое значение. Предикаты всегда обрамляются квадратными скобками. В приведённой ниже таблице перечислены некоторые выражения пути с предикатами, и результат выражения:
Примечание: В IE 5,6,7,8,9 первый узел имеет индекс [0], но в соответствии с рекомендациями W3C, это [1]. Для решения этой проблемы в IE, задаётся опция "SelectionLanguage" для XPath:
Выбор неизвестных узлов
Специальные символы XPath могут использоваться для выбора неизвестных XML узлов.
| Wildcard | Описание |
|---|---|
| * | Соответствует любому узлу |
| @* | Соответствует узлу-атрибуту |
| node() | Соответствует любому узлу любого типа |
В приведённой ниже таблице мы перечислили некоторые пути выражения и результаты выражений:
| Выражение пути | Результат |
|---|---|
| /bookstore/* | Выбирает все дочерние узлы элемента «книжный магазин» (bookstore) |
| //* | Выбирает все элементы в документе |
| //title[@*] | Выбирает все элементы «название» (title), которые имеют по крайней мере один атрибут любого вида |
Выбор нескольких путей
С помощью оператора | в выражениях XPath вы можете выбрать несколько путей. В таблице ниже перечислены несколько выражений путей и результаты их применения:
| Выражение пути | Результат |
|---|---|
| //book/title | //book/price | Выбирает все элементы «название» (title) И «цена» (price) всех элементов «книга» (book) |
| //title | //price | Выбирает все элементы «название» (title) И «цена» (price) в документе |
| /bookstore/book/title | //price | Выбирает все элементы «название» элемента «книга» элемента «книжный магазин» И все элементы «цена» в документе |
5 ОсиXPath
Мы будем использовать следующий XML документ далее в примере.
Оси определяют наборы узлов, относительно текущего узла.
| Название оси | Результат |
|---|---|
| ancestor | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла |
| ancestor-or-self | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла и сам текущий узел |
| attribute | Выбирает все атрибуты текущего узла |
| child | Выбирает всех потомков текущего узла |
| descendant | Выбирает всех потомков (детей, внуков и т.д.) текущего узла |
| descendant-or-self | Выбирает всех потомков (детей, внуков и т.д.) текущего узла и сам текущий узел |
| following | Выбирает всё в документе после закрытия тэга текущего узла |
| following-sibling | Выбирает все узлы одного уровня после текущего узла |
| namespace | Выбирает все узлы в данном пространстве имён (namespace) текущего узла |
| parent | Выбирает родителя текущего узла |
| preceding | Выбирает все узлы, которые появляются перед текущим узлом в документе, за исключением предков, узлов атрибутов и узлы пространства имён |
| preceding-sibling | Выбирает всех братьев и сестёр до текущего узла |
| self | Выбирает текущий узел |
6 Выраженияпути выборки
Путь определения местоположения может быть абсолютным или относительным. Абсолютный путь расположения начинается с косой черты (/), а относительный – нет. В обоих случаях путь выборки состоит из одного или нескольких шагов, разделённых косой чертой:
Абсолютный путь расположения:
Относительный путь выборки расположения:
Каждый шаг оценивается по узлам в текущем наборе узлов. Шаг состоит из:
- ось (определяет древовидную связь между выбранными узлами и текущим узлом);
- проверка узла (идентифицирует узел в пределах оси);
- ноль или более предикатов (для дальнейшего уточнения выбранного набор узлов)
Синтаксис шага выборки такой:
| Пример | Результат |
|---|---|
| child::book | Выбирает все узлы «книга» (book), которые являются потомками текущего узла |
| attribute::lang | Выбирает атрибут «язык» (lang) текущего узла |
| child::* | Выбирает всех потомков текущего узла |
| attribute::* | Выбирает все атрибуты текущего узла |
| child::text() | Выбирает все текстовые узлы текущего узла |
| child::node() | Выбирает всех ближайших потомков текущего узла |
| descendant::book | Выбирает всех потомков текущего узла |
| ancestor::book | Выбирает всех предков «книга» (books) текущего узла |
| ancestor-or-self::book | Выбирает всех предков «книга» (book) текущего узла – и текущий узел, если он также «книга» (book) |
| child::*/child::price | Выбирает все потомки «цена» (price) через один уровень от текущего узла |
7 Операторы XPath
Выражения XPath возвращают как набор узлов, строки, булевы или числовые значения. Ниже представлен список операторов, используемых в выражениях XPath:
| Оператор | Описание | Пример |
|---|---|---|
| | | Вычисляет два набора узлов | //book | //cd |
| + | Сложение | 6 + 4 |
| - | Вычитание | 6 - 4 |
| * | Умножение | 6 * 4 |
| div | Деление | 8 div 4 |
| = | Равенство | price=9.80 |
| != | Неравенство | price!=9.80 |
| Меньше, чем | price | |
| Меньше или равно | price≤9.80 | |
| > | Больше, чем | price>9.80 |
| >= | Больше или равно | price≤9.80 |
| or | Или | price=9.80 or price=9.70 |
| and | И | price>9.00 and price |
| mod | Остаток от деления | 5 mod 2 |
8 Примеры XPath
Давайте рассмотрим базовый синтаксис XPath на нескольких примерах. Мы будем использовать следующий XML документ "books.xml" в примерах ниже:
Загрузка XML документа
Код для устаревших браузеров Microsoft (IE 5 и 6):
Выбор узлов
К сожалению, работа с XPath в Internet Explorer и в других браузерах может отличаться. В наших примерах мы будем использовать код, который должен работать в большинстве браузеров. Internet Explorer использует метод "selectNodes()" для выбора узлов XML документа:
Firefox, Chrome, Opera и Safari используют метод evaluate() для выбора узлов из XML документа:
Выбор всех заглавий
Следующий пример выбирает все узлы заголовков:
Выбор заголовка первой книги
Следующий пример выбирает заголовок первого узла «книга» после элемента «книжный магазин» (bookstore):
Управление XML-файлами и операции с ними
Начать работу с действиями XML
Power Automate предоставляет возможность использовать потоки для автоматизации управления атрибутами и элементами XML с помощью действий XML.
Чтобы прочитать файл XML, используйте действие Прочитать XML из файла. Укажите путь или найдите файл и выберите один из вариантов кодирования.
После выбора файла для запуска запроса Xpath выберите действие Выполнить выражение XPath. В следующем примере документ указан как переменная из действия Прочитать XML из файла и вводится запрос XPath.

Чтобы получить атрибут из файла XML, используйте действие Получить атрибут XML. Обратите внимание на следующий пример и формат запроса XPath. В XML-файле статус является атрибутом клиента, который является элементом clientlist. Значение будет получено как текстовое значение.

Точно так же, чтобы получить значения элементов, используйте действие Получить значение XML-элемента. Элементами и атрибутами можно управлять, используя соответствующее действие для получения, установки или удаления атрибутов или элементов XML.
Действия XML
Прочитать XML из файла
Считывание содержимого XML-файла в переменную.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| File path: | Нет | Файл | Файл, содержащий XML-документ для считывания. | |
| Encoding: | Н/Д | По умолчанию, ANSI, Unicode, Обратный порядок байтов Unicode, UTF-8 | Default | Кодировка, используемая для указанного файла. |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| XmlDocument | Узел XML | Переменная, содержащая прочитанный XML-документ. |
Исключения
| Исключение | Описание |
|---|---|
| Каталог не найден | Указывает, что каталог не существует. |
| Файл не найден | Указывает, что файл не существует. |
| Не удалось прочитать файл. | Указывает на проблему при чтении файла. |
| Файл не содержит допустимый XML-документ. | Указывает, что файл не содержит допустимый XML-документ. |
Записать XML в файл
Запись содержимого переменной узла XML в файл.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| File path: | Нет | Файл | Файл, в который требуется записать XML-документ. | |
| XML to write: | Нет | Текстовое значение | Узел XML или XML-документ, который требуется записать в файл. | |
| Encoding: | Н/Д | По умолчанию, ANSI, Unicode, Обратный порядок байтов Unicode, UTF-8 | Default | Кодировка, используемая для указанного файла. |
| Format XML: | Н/Д | Логическое значение | Истина | Указывает, следует ли форматировать XML. |
| Indentation per level: | Да | Числовое значение | 2 | Указывает, сколько пробелов необходимо использовать для отступа каждого уровня XML. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Указан недопустимый каталог. | Указывает, что заданный каталог недопустим. |
| Не удалось выполнить запись XML в файл. | Указывает на проблему при записи XML в файл. |
Выполнить выражение XPath
Извлечение значений из XML-документа на основе предоставленного запроса XPath.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document to parse: | Нет | Текстовое значение | XML в виде текста или ранее определенной переменной, содержащей XML-документ для анализа. | |
| XPath query: | Нет | Текстовое значение | Выражение XPath, которое требуется выполнить для XML-документа. | |
| Get first value only: | Н/Д | Логическое значение | Ложь | Указывает, следует ли извлечь одно значение (только первое значение) или все значения, которые соответствуют предоставленному выражению XPath. |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| XPathResult | Узел XML | Извлеченный узел (узлы) в виде узла XML. |
| XPathResults | Список узлов XML | Извлеченный узел (узлы) в виде списка узлов XML. |
Исключения
| Исключение | Описание |
|---|---|
| Предоставлен недопустимый XML-документ. | Указывает, что предоставленный XML-документ недопустим. |
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
Получить атрибут XML-элемента
Получение значения атрибута XML-элемента.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ или XML-элемент, атрибут которого требуется извлечь. | |
| XPath query | Да | Текстовое значение | Выражение XPath для поиска подэлемента и извлечения его атрибута. | |
| Attribute name: | Нет | Текстовое значение | Имя атрибута, значение которого требуется извлечь. | |
| Get value as: | Н/Д | Текстовое значение, Числовое значение, Значение даты и времени, Логическое значение | Текстовое значение | Указывает тип данных для значения атрибута. |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| XmlAttributeValue | Логическое значение | Извлеченное значение атрибута XML. |
| XmlAttributeValue | Дата и время | Извлеченное значение атрибута XML. |
| XmlAttributeValue | Числовое значение | Извлеченное значение атрибута XML. |
| XmlAttributeValue | Текстовое значение | Извлеченное значение атрибута XML. |
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Атрибут не найден в элементе. | Указывает, что атрибут не существует в элементе. |
| Не удалось преобразовать значение атрибута в запрошенный тип данных. | Указывает на проблему при преобразовании значения атрибута в запрошенный тип данных. |
Задать атрибут XML-элемента
Задание значения атрибута XML-элемента.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ или XML-элемент, атрибут которого требуется задать. | |
| XPath query: | Да | Текстовое значение | Выражение XPath для поиска подэлемента и задания его атрибута. | |
| Attribute name: | Нет | Текстовое значение | Имя атрибута, значение которого требуется задать. | |
| Attribute value: | Нет | Текстовое значение | Новое значение для атрибута. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Не удалось задать атрибут XML. | Указывает на проблему при задании атрибута XML. |
Удалить атрибут XML-элемента
Удаление атрибута из XML-элемента.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ или XML-элемент, атрибут которого требуется удалить. | |
| XPath query: | Да | Текстовое значение | Выражение XPath для поиска подэлемента и удаления его атрибута. | |
| Attribute name: | Нет | Текстовое значение | Имя атрибута, который требуется удалить. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Атрибут не найден в элементе. | Указывает, что атрибут не существует в элементе. |
| Не удалось удалить атрибут XML. | Указывает на проблему при удалении атрибута XML. |
Получить значение XML-элемента
Получение значения XML-элемента.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ или XML-элемент, значение которого требуется извлечь. | |
| XPath query: | Да | Текстовое значение | Выражение XPath для поиска подэлемента и извлечения его значения. | |
| Get value as: | Н/Д | Текстовое значение, Числовое значение, Значение даты и времени, Логическое значение | Текстовое значение | Указывает тип данных для значения XML-элемента. |
Создаваемые переменные
| Аргумент | Тип | Описание |
|---|---|---|
| XmlElementValue | Логическое значение | Значение XML-элемента. |
| XmlElementValue | Дата и время | Значение XML-элемента. |
| XmlElementValue | Числовое значение | Значение XML-элемента. |
| XmlElementValue | Текстовое значение | Значение XML-элемента. |
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Не удалось преобразовать значение элемента в запрошенный тип данных. | Указывает на проблему при преобразовании значения элемента в запрошенный тип данных. |
Задать значение XML-элемента
Задание значения XML-элемента.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ или XML-элемент, значение которого требуется извлечь. | |
| XPath query: | Да | Текстовое значение | Выражение XPath для поиска подэлемента и извлечения его значения. | |
| XML element value: | Нет | Текстовое значение | Новое значение для XML-элемента. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Не удалось задать значение элемента. | Указывает на проблему при задании значения элемента. |
Вставить XML-элемент
Вставка нового XML-элемента в XML-документ.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ, в который требуется вставить новый XML-элемент. | |
| XPath query: | Нет | Текстовое значение | Выражение XPath для поиска родительского XML-элемента и вставки нового элемента в него. | |
| XML element to insert: | Нет | Узел XML | Новый XML-элемент, который требуется вставить в XML-документ. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Выражение XPath не возвращает элемент. | Указывает, что выражение XPath не возвращает элемент. |
| Не удалось вставить XML-элемент. | Указывает на проблему при вставке XML-элемента. |
Удалить XML-элемент
Удаление одного или нескольких XML-элементов из XML-документа.
| Аргумент | Необязательная | Принимает | Значение по умолчанию | Описание |
|---|---|---|---|---|
| XML document: | Нет | Узел XML | XML-документ, содержащий один или несколько XML-элементов, которые требуется удалить. | |
| XPath query: | Нет | Текстовое значение | Выражение XPath для поиска одного или нескольких элементов, которые требуется удалить. |
Создаваемые переменные
Исключения
| Исключение | Описание |
|---|---|
| Предоставлено недопустимое выражение XPath. | Указывает, что предоставленное выражение XPath недопустимо. |
| Не удалось удалить XML-элемент. | Указывает на проблему при удалении XML-элемента. |
Каковы ваши предпочтения в отношении языка документации? Пройдите краткий опрос (обратите внимание, что этот опрос представлен на английском языке).
Опрос займет около семи минут. Личные данные не собираются (заявление о конфиденциальности).
Цель книги – предоставить инструменты Excel для автоматизации повторяющихся задач извлечения данных из Интернета. Автор предлагает несколько десятков программ VBA и описывает приемы работы в Power Query.
Eduardo Sanchez. Excel and The World Wide Web. Straight to the Point. – Holy Macro! Books, 2021. – 58 p.

Глава 1. Приступая к работе
Что такое HTML?
HTML (Hyper Text Markup Language) – язык гипертекстовой разметки. Он используется для создания веб-сайтов. Гипертекст – это контент, который ведет себя нелинейным образом. Представьте себе веб-сайт, на каждой странице которого есть несколько ссылок на другие страницы, как того же самого сайта, так и других сайтов. Пользователь перемещается, переходя с одной страницы на другую; это гипертекстовое поведение. Обычная печатная книга – это контрпример, ее предполагается читать последовательно.
Информация в HTML помечена тегами; ниже мы поговорим об этом подробнее. Существуют и другие языки, используемые для создания веб-сайтов, такие как CSS и JavaScript, но мы не будем подробно рассматривать их здесь.
CSS (Cascading Style Sheet) – каскадная таблица стилей, язык описания внешнего вида документа. Он работает вместе с HTML, который отвечать за содержимое страницы. Каскадирование означает, что можно использовать несколько CSS-файлов для создания окончательного визуального стиля. Этот язык управляет такими элементами, как размер шрифта, фоновые изображения и цветовая палитра.
JavaScript – язык программирования для реализации динамического поведения на веб-сайтах. С его помощью разработчики могут манипулировать содержимым страницы, создавать диаграммы и взаимодействовать с API (Application Programming Interface, интерфейс прикладного программирования). Обратите внимание, что JavaScript и Java – это два разных языка. Говорят, что в будущем JavaScript может заменить VBA в качестве языка программирования Office.
Одна из замечательных особенностей современных браузеров заключается в том, что они предоставляют исходный код страниц. Если вы используете Google Chrome, просто щелкните правой кнопкой мыши любой элемент страницы и выберите пункт Просмотреть код; в правой части окна появится панель, аналогичная показанной ниже:
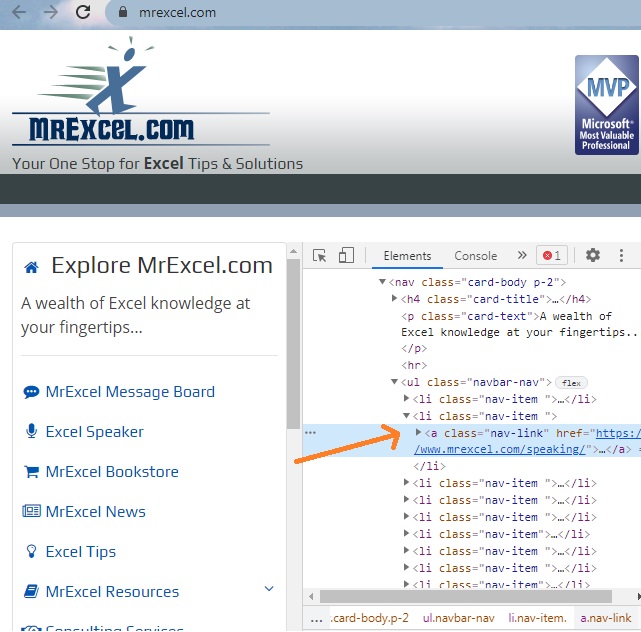
Рис. 1. Фрагмент кода HTML веб-страницы; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
- Ключевые слова header, div, aside, nav, h4, li и другие являются тегами.
- Когда маленькие черные треугольники указывают вправо, это означает, что их можно щелкнуть, чтобы развернуть и отобразить дополнительную информацию.
- Ключевые слова id, class и href являются атрибутами.
- Элемент может принадлежать к нескольким различным классам.
Если вы чувствуете себя подавленным всем этим, не паникуйте; не обязательно быть программистом HTML, чтобы работать с такого рода автоматизацией. Позже мы увидим, как читать код HTML и извлекать информацию с помощью VBA.
Хотя веб-дизайнеры используют профессиональные редакторы, можно создавать HTML-файлы в стандартных приложениях Windows, например, в Блокноте. Это особенно быть полезно, когда вы хотите протестировать код VBA, который будет взаимодействовать с веб-страницей, но по какой-то причине реальный сайт недоступен.
Xpath — это язык запросов к элементам xml или xhtml документа. Также как SQL, xpath является декларативным языком запросов. Чтобы получить интересующие данные, необходимо всего лишь создать запрос, описывающий эти данные. Всю «черную» работу за вас выполнит интерпретатор языка xpath.
Очень удобно, не правда ли? Давайте посмотри какие возможности предлагает xpath для доступа к узлам веб-страниц.
Создание запроса к узлам веб-страниц
Предлагаю вашему вниманию небольшую лабораторную работу, в ходе которой я продемонстрирую создание xpath запросов к веб-странице. Вы сможете повторить приведенные мной запросы и, самое главное, попробуете выполнить свои. Я надеюсь, что благодаря этому статья будет одинаково интересна новичкам и программистам знакомым с xpath по xml.
Для лабораторной нам понадобятся:
— веб-страница xhtml;
— браузер Mozilla Firefox с дополнениями;
— firebug;
— firePath;
(вы можете использовать любой другой браузер с визуальной поддержкой xpath)
— немного времени.
Задача
Первый Xpath запрос
Открываем закладку Firepath в FireBug, выделяем с селектором элемент для анализа, нажимаем: Firepath создал xpath запрос к выбранному элементу.
Если вы выделили заголовок первого события, то запрос будет таким:
После удаления лишних индексов запрос станет соответствовать всем элементам типа «заголовок».
Firepath подсвечивает элементы, которые соответствуют запросу. Вы можете в реальном времени увидеть, какие узлы документа соответствуют запросу.
Идем дальше. Создаем запросы для поиска мест проведения конференций и их спонсоров либо с помощью селектора, либо модифицировав первый запрос.
Запрос для получения информации о местах проведения конференций:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Так мы получим список спонсоров:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Синтаксис xpath
Давайте вернемся к созданным запросам и разберемся в том, как они устроены.
Рассмотрим подробно первый запрос
В этом запросе я выделил три части для демонстрации возможностей xpath. (Деление на части уловное)
Первая часть
.// — рекурсивный спуск на ноль или более уровней иерархии от текущего контекста. В нашем случае текущий контекст это корень документа
Вторая часть
* — любой элемент,
[@id='w3c_home_upcoming_events'] – предикат, на основе которого осуществляем поиск узла, имеющего атрибут id равным 'w3c_home_upcoming_events'. Идентификаторы элементов XHTML должны быть уникальны. Поэтому запрос «любой элемент с конкретным ID» должен вернуть единственный искомый нами узел.
Мы можем заменить * на точное имя узла div в этом запросе
div[@id='w3c_home_upcoming_events']
Таким образом, мы спускаемся по дереву документа до нужного нам узла div[@id='w3c_home_upcoming_events']. Нас абсолютно не волнует, из каких узлов состоит DOM-дерево и сколько уровней иерархии осталось выше.
Третья часть
/ul/li/div/p/a –xpath-путь до конкретного элемента. Путь состоит из шагов адресации и условия проверки узлов (ul, li и т.д.). Шаги разделяются символом " /"(косая черта).
Коллекции xpath
Не всегда удается получить доступ к интересующему узлу с помощью предиката или шагов адресации. Очень часто на одном уровне иерархии находится насколько узлов одинакового типа и необходимо выбрать «только первые» или «только вторые» узлы. Для таких случаев предусмотрены коллекции.
Коллекции xpath позволяют получить доступ к элементу по его индексу. Индексы соответствуют тому порядку, в котором элементы были представлены в исходном документе. Порядковый номер в коллекциях отсчитывается от единицы.
Исходя из того, что «место проведения» всегда второй параграф после «названия конференции», получаем следующий запрос:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Где p[2] – второй элемент в наборе для каждого узла списка /ul/li/div.
Аналогично список спонсоров мы можем получить запросом:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Некоторые функции хpath
В хpath существует множество функций для работы с элементами внутри коллекции. Я приведу только некоторые из них.
last():
Возвращает последний элемент коллекции.
Запрос ul/li/div/p[last()] — возвратит последние параграфы для каждого узла списка «ul».
Функция first() не предусмотрена. Для доступа к первому элементу используйте индекс «1».
text():
Возвращает тестовое содержание элемента.
.//a[text() = 'Archive'] – получаем все ссылки с текстом «Archive».
position() и mod:
position() — возвращает позицию элемента в множестве.
mod — остаток от деления.
Комбинацией данных функций можем получить:
— не четные элементы ul/li[position() mod 2 = 1]
— четные элементы: ul/li[position() mod 2 = 0]
Самостоятельно
Xpath в PHP5
В заключение
На простом примере мы увидели возможности xpath для доступа к узлам веб-страниц.
Xpath является отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Вы можете применять его для парсинга любой html-страницы. В случае если исходный html-код содержит значительные ошибки в разметке пропустите его через tidy. Ошибки будут исправлены.
Старайтесь отказаться от регулярных выражений при парсинге веб-страниц в пользу xpath.
Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок. Сократиться время отладки.

При выполнении запросов язык XPath оперирует такими сущностями как узлы. Узлы бывают нескольких видов: element (узел-элемент), attribute (узел-атрибут), text (узел-текст), namespace (узел-пространство имён), processing-instruction (узел-исполняемая инструкция), comment (узел-комментарий), document (узел-документ).
Рассмотрим, как в XPATH задаётся последовательность узлов, направления выборки и выбирать узлы с конкретными значениями.
Для осуществления выборки узлов в основном используется 6 основных типов конструкций:

Так же при выборе узлов имеется возможность использовать wildcard маски, когда нам неизвестно, какой вид должен принимать узел.

В языке XPATH для выборки относительно текущего узла используются специальные конструкции под названием оси.

Правило выборки может быть как абсолютным (//input[@placeholder=”Логин” – выборка начиная с корневого узла], так и относительным (*@class=”okved-table__code” – выборка относительно текущего узла).
Построение правила выборки на каждом шаге выборки осуществляется относительно текущего узла и учитывает:
- Название оси, относительно которой следует производить выборку
- Условие выборки узла по имени или по положению
- Ноль или более предикатов
Для выборки конкретных узлов по некоторым условиям, параметрам или позиции используют такое инструментально средство как предикаты. Условие предиката ставится в квадратных скобках. Примеры:

Помимо приведенных конструкций языка XPATH, он также содержит поддерживает ряд операторов (+, -, *, div, mod, =, !=, and, or и т.д.), а также более 200 встроенных функций.
Загружаем данные по людям:
Извлекаем информацию из страниц с информацией о людях.
Осуществляем поиск, используя модуль multiprocessing, для ускорения сбора данных.
И сохраняем результаты:
На рисунке ниже представлена страница поиска личных дел, на которой указываются ФИО, дата рождения, по которым в дальнейшем осуществляется поиск. После ввода ФИО и даты рождения алгоритм нажимает на кнопку искать дело, после чего анализирует полученные результаты.

На следующем рисунке видим список, парсингом элементов которого и занимается алгоритм.

На примере выше было показано, как можно использовать XPATH для сбора информации с веб-страниц. Но как уже было сказано, XPATH применим для обработки любых xml документов, являясь отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Зачастую читабельность кода влияет и на его качество, поэтому следует отказаться от регулярных выражений при парсинге, изучить XPATH и начать применять его в рабочем процессе. Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок, а также сократиться время отладки.
Читайте также: