
Задачи по эконометрике в excel с решениями
1 Задача по эконометрике с решением в Excel. Выполнена в Расчетный файл выложен на странице Эконометрика Решение задачи на множественную регрессии в Excel По заданным статистическим данным постройте линейную модель множественной регрессии и исследуйте её. 1) Постройте линейную модель множественной регрессии. ) Запишите стандартизованное уравнение множественной регрессии. На основе стандартизованных коэффициентов регрессии и средних коэффициентов эластичности ранжировать факторы по степени их влияния на результат. 3) Найдите коэффициенты парной, частной и множественной корреляции. Проанализируйте их. 4) Найдите скорректированный коэффициент множественной детерминации. 1
2 Задача по эконометрике с решением в Excel. Выполнена в Сравните его с нескорректированным (общим) коэффициентом детерминации. 5) С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии и коэффициента детерминации yx1x. 6) С помощью частных F-критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора x 1 после x и фактора x после x 1. 7) Составьте уравнение линейной парной регрессии, оставив лишь один значащий фактор. Решение: 1. Для построения линейной модели множественной регрессии используем инструмент Регрессия пакета Анализ данных в MS Excel. Вводим исходные данные в ячейки А1-E1. Нажимаем ОК и получаем результат:
3 Задача по эконометрике с решением в Excel. Выполнена в Используя значения в столбце «Коэффициенты» получаем уравнение линейной множественной регрессии в естественной форме: yɶ = x x x x Полученное уравнение регрессии показывает взаимосвязь между урожайностью зерновых культур, числом тракторов, числом комбайнов, количеством удобрений и количеством химических средств защиты. Из уравнения видно, что с ростом числа тракторов приведенной мощности на 100 га на 1 ед. урожайность зерновых вырастает на ц/га. С ростом числа комбайнов на 1 ед. урожайность зерновых вырастает на ц/га. Увеличение на 1 т/га количества удобрений влечет за собой рост урожайности на,8437 ц/га. А вот рост на 1 ц/га количества средств химической защиты снижает урожайность на 3,3665 ц/га.. На основе естественных коэффициентов регрессии рассчитаем стандартизированные коэффициенты по формулам: x β = b σ. σ Расчет будем проводить в Excel. Для определения σ используем функцию СТАНДОТКЛОН(). Получаем уравнение в стандартизированной форме: t = t t t t. y x x x x Так как стандартизованные коэффициенты регрессии можно сравнивать между собой, то можно сказать, что наибольшее влияние на урожайность оказывают количество удобрений и количество химических средств защиты, так как их коэффициенты по модулю примерно одинаковы и существенно превышают значения стандартизованных коэффициентов для факторов 1 и. 3 y
4 Задача по эконометрике с решением в Excel. Выполнена в Вычисляем коэффициенты эластичности по формулам: x Э y = b. Расчет будем проводить в Excel. Для определения средних значений используем функцию СРЗНАЧ(). Вычисляем: Э 1 = 0.055, Э = 0.7, Э 3 = 0.18, Э 4 = Частный коэффициент эластичности показывает, насколько процентов в среднем изменяется признак-результат у с увеличением признака-фактора х j на 1% от своего среднего уровня при фиксированном положении других факторов модели. Все коэффициенты эластичности существенно ниже 1, значит, влияние факторов на результативный признак Y незначительно. В то же время максимальное значение имеет фактор, то есть увеличение только числа комбайнов (от своего среднего значения) на 1% увеличивает в среднем урожайность зерновых культур на 0,7 %. x 3. Найдем коэффициенты парной корреляции. Расчет можно вести по формуле yx cov( y, x ) y x y x = = σ σ σ σ y x y x однако проще использовать инструмент Корреляция пакета Анализ данных, который сразу строит матрицу парных коэффициентов корреляции., Результат: 4
5 Задача по эконометрике с решением в Excel. Выполнена в Коэффициенты парной корреляции указывают между y и факторами имеет достаточно низкие значения (все коэффициенты по модулю ниже 0,4), то есть связь слабая. Заметная связь наблюдается между переменными x 1 и x 3 (коэффициент корреляции -0,577), x 1 и x 4 (коэффициент корреляции -0,54), x 3 и x 4 (коэффициент корреляции 0,673), то есть данные коэффициенты могут быть коллинеарными. Определяем частные коэффициенты корреляции по формулам: yx yxj xxj yx / xj =. Получаем: = 0.177, 1 = 0.171, 1 3 Теснота связи везде низкая. = 0.088, = 0.09, 1 3 Теснота связи везде низкая. = , = 0.03, Теснота связи везде низкая. = 0.98, = 0.343, ( yxj ) ( xxj ) = 0.0. = = = Теснота связи низкая для первых двух случаев, в последнем умеренная. Коэффициент множественной корреляции: 1 = β = yx x yx (поле Множественный в регрессионной статистике). Коэффициент множественной корреляции показывает на умеренную связь всего набора факторов с результатом. yx x 1 4. Нескорректированный коэффициент множественной детерминации = 0.08 (поле -квадрат), что говорит о том, что 0.8 % вариации результата объясняется вариацией представленных в уравнении факторов. 5
6 Задача по эконометрике с решением в Excel. Выполнена в Скорректированный коэффициент множественной детерминации (поле Нормированный -квадрат): корр ( n ) ( n m ) ( ) ( ) = ( ) = ( 0.08) Значение скорректированного коэффициента множественной детерминации определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Скорректированный коэффициент детерминации практически равен 1, то есть уравнение регрессии не объясняет вариацию урожайности. 5. Оценим значимость уравнения: F набл = = = n m m Такое же значение получено в поле «F» дисперсионного анализа. Табличное значение критерия при уровне значимости α = 0,05 и k1 = m = 4, k = n m 1 = = 15: F табл = F(0,05; 4; 15) = 3,06. Так как F табл > F набл, то с вероятностью 1 α = 0,95 делаем заключение о незначимости уравнения регрессии и коэффициента множественной детерминации (поле «Значимость F» выше 0,05). 6. С помощью частных F -критериев Фишера оценим целесообразность включения в уравнение множественной регрессии факторов x после остальных факторов. (, n ) ( ) ( ) x x Fх1 = n m 1 = = 0.508, 0.08 где ( ) x, x = β + β + β = n yx 3 yx3 4 yx4 Критическое значение: F kp (k 1 =3; k = 15) = 3.9. F x1
7 Задача по эконометрике с решением в Excel. Выполнена в F x 3.9, следовательно, фактор х 4 целесообразно включать в модель после введения факторов х j. 7. Найдем уравнение парной регрессии y = a + bx4. Для этого снова используем инструмент Регрессия пакета Анализ данных. Фактор x 4 выбран как наиболее тесно связанный с результирующей переменной. Получаем уравнение линейной регрессии y = x4. Коэффициент b = показывает, что при увеличении количества химических средств защиты на 1 ц/га величина урожайности снижается в среднем на ц/га. Построенное уравнение регрессии на 11,1 % объясняет вариацию урожайности вариацией количества химических средств защиты (значение -квадрат). Построенное 7
8 Задача по эконометрике с решением в Excel. Выполнена в уравнение линейной регрессии не является значимым (значимость F = 0,1511 > 0,05). 8
9 Задача по эконометрике с решением в Excel. Выполнена в Список литературы: 1. Елисеева И. И. Эконометрика: учебник/ И.И. Елисеева М.: Финансы и статистика, Елисеева И. И. Практикум по эконометрике: учеб. пособие/ И. И. Елисеева М.: Финансы и статистика, Кремер Н. Ш. Математика для экономистов : от Арифметики до Эконометрики : учебно-справочное пособие / Н. Ш. Кремер, Б. А. Путко, И. М. Тришин ; ред. Н. Ш. Кремер. - -е изд., перераб. и доп. - М. : Юрайт,010. 9
Задание №1. Имеются следующие данные: Q ( Y ) – объем продаж (ежемесячный); P ( X 1) – цена за единицу изделия. X2 – структурная фиктивная переменная.
В период с 5 по 7 месяц на фирме проходило реформирование. С помощью регрессии Q ( t ) на P ( t ) определить, сказалась или нет реформа на деятельности фирмы.
Решение.
Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор s получается из выражения: s = (X T X) -1 X T Y
К матрице с переменными Xj добавляем единичный столбец:
Умножаем матрицы, (X T X)
В матрице, (X T X) число 14, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
Находим обратную матрицу (X T X) -1
Вектор оценок коэффициентов регрессии равен
Уравнение регрессии (оценка уравнения регрессии)
Проверим значимость структурной переменной Х2.
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка ε = Y - Y(x) = Y - X∙s (абсолютная ошибка аппроксимации)
Оценка дисперсии равна:
Несмещенная оценка дисперсии равна:
Оценка среднеквадратичного отклонения (стандартная ошибка для оценки Y):
Найдем оценку ковариационной матрицы вектора k = S 2 • (X T X) -1
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
Статистическая значимость коэффициента регрессии b2 подтверждается.
Задание №2. Имеются данные по заработной плате Y , возрасту X и полу работников 20 предприятий.
1. Эконометрическую модель зависимости заработной платы от возраста только для мужчин.
2. Эконометрическую модель зависимости заработной платы от возраста только для женщин.
3. Эконометрическую модель зависимости заработной платы от возраста и пола работника.
4. Различаются ли функции заработка для мужчин и женщин?
5. Выполните тест Чоу.
6. Прокомментируйте результат.
1) Построим конометрическую модель зависимости заработной платы от возраста только для мужчин.
Линейное уравнение регрессии имеет вид y = bx + a
Коэффициент корреляции b можно находить по формуле, не решая систему непосредственно:
y = 1.0364 x + 2.1882
Остаточная сумма квадратов:
2) Постпроим эконометрическую модель зависимости заработной платы от возраста только для женщин.
Коэффициент корреляции b можно находить по формуле, не решая систему непосредственно:
y = 0.9615 x + 5.1307
Остаточная сумма квадратов:
3) Построим эконометрическую модель зависимости заработной платы от возраста и пола работника.
Умножаем матрицы, (X T X)
В матрице, (X T X) число 20, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
Находим обратную матрицу (X T X) -1
Вектор оценок коэффициентов регрессии равен
Уравнение регрессии (оценка уравнения регрессии)
Несмещенная оценка дисперсии равна:
Оценка среднеквадратичного отклонения (стандартная ошибка для оценки Y):
Найдем оценку ковариационной матрицы вектора k = S 2 • (X T X) -1
4) Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
Статистическая значимость коэффициента регрессии b2 не подтверждается.
Следовательно, различия в заработной плате мужчин и женщин не подтверждается.
5) Строим зависимость заработной платы от возраста без учёта пола работников.
Коэффициент корреляции b можно находить по формуле, не решая систему непосредственно:
y = 1.0066 x + 3.4399
Введем гипотезу Н0: тенденция изучаемого ряда структурно стабильна.
Остаточная сумма квадратов по кусочно-линейной модели:
С кл ост = С 1 ост + С 2 ост = 244,034 + 99,769 = 343,803 .
Сокращение остаточной дисперсии при переходе от единого уравнения тренда к кусочно-линейной модели:
∆Сост = Сост – С кл ост = 346,511 – 343,803 = 2,708
Так как число параметров в уравнениях Y , Y 1 и Y 2 одинаково и равно k =1, то фактическое значение F – критерия находим по формуле:
F факт = ( 2,708 /1)/( 343,803 /(20 - 2)) = 0,142.
Критическое (табличное) значение критерия Фишера для доверительной вероятности g = 0,95 и числа степеней свободы v 1 = k = 1 и v 2 = n - 2∙ k = 18: F кр . = F 0,05; 1; 18 = 3,009.
6) F факт < F табл – уравнения Y 1 и Y 2 описывают одну и ту же тенденцию, а различия численных оценок их параметров а1 и а2, а так же b 1 и b 2 соответственно, статистически не значимы. Следовательно, можно утверждать, что нет различия в зарабртных платах между мужчинами и женщинами.
Задание №3. В таблице приведены данные для 60 объектов недвижимости в Московской области по следующим показателям:
- стоимость дома, Y ( (млн. р.);
- расстояние от МКАД, x 1 (км);
- площадь дома, x 2 (кв.м.)
- количество этажей в доме, x 3 ;
- площадь участка, x 4 (в сотках);
- наличие центральных коммуникаций, x 5 (1: есть; 0: нет);
- наличие гаража, x 6 (1: есть; 0: нет).
1. Рассчитайте параметры линейного уравнения множественной регрессии с включением только количественных переменных.
2. Рассчитайте параметры линейного уравнения множественной регрессии с включением фиктивных переменных.
3. Сравните качественные характеристики моделей, полученных в 1 и во 2 пунктах. Выберите лучшую.
4. Выполните тест Чоу.
5. Оформите результаты в виде аналитической записки.
1) Рассчитайте параметры линейного уравнения множественной регрессии с включением только количественных переменных.
Умножаем матрицы, (X T X)
В матрице, (X T X) число 60, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
Находим обратную матрицу (X T X) -1
Вектор оценок коэффициентов регрессии равен
Y(X) = (X T X) -1 X T Y =
Уравнение регрессии (оценка уравнения регрессии)
Оценка дисперсии равна:
Несмещенная оценка дисперсии равна:
Оценка среднеквадратичного отклонения (стандартная ошибка для оценки Y):
Найдем оценку ковариационной матрицы вектора k = S 2 • (X T X) -1
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
Статистическая значимость коэффициента регрессии b0 не подтверждается.
Статистическая значимость коэффициента регрессии b1 подтверждается.
Статистическая значимость коэффициента регрессии b2 подтверждается.
Статистическая значимость коэффициента регрессии b3 не подтверждается.
Статистическая значимость коэффициента регрессии b4 подтверждается.
2) Рассчитаем параметры линейного уравнения множественной регрессии с включением фиктивных переменных.
Умножаем матрицы, (X T X)
В матрице, (X T X) число 60, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
Находим обратную матрицу (X T X) -1
Вектор оценок коэффициентов регрессии равен
Y(X) = (X T X) -1 X T Y =
Уравнение регрессии (оценка уравнения регрессии)
Оценка дисперсии равна:
Несмещенная оценка дисперсии равна:
Оценка среднеквадратичного отклонения (стандартная ошибка для оценки Y):
Найдем оценку ковариационной матрицы вектора k = S 2 • (X T X) -1
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
Статистическая значимость коэффициента регрессии b0 подтверждается.
Статистическая значимость коэффициента регрессии b1 подтверждается.
Статистическая значимость коэффициента регрессии b2 подтверждается.
Статистическая значимость коэффициента регрессии b3 подтверждается.
Статистическая значимость коэффициента регрессии b4 подтверждается.
Статистическая значимость коэффициента регрессии b5 подтверждается.
Статистическая значимость коэффициента регрессии b6 подтверждается.
3),4),5) Сравнивая модели пункта 1 и 2, приходим к выводу. Что лучшая модель будет – модель 2.
Количество переменных m
Степеней свободы k
Количество переменных m
Степеней свободы k
В модели 2 выше коэффициент детерминации и составляет 0,987, следовательно, модель на 98,7% объясняет изменение цены дома. Во второй модели все коэффициенты регрессии статистически значимы, включая коэффициенты при фиктивных переменных. В первой модели не значим коэффициент при переменной Х3(количество этажей).
Для проведения теста Чоу необходимо иметь точку структурных различий. В нашей модели имеется две фиктивные переменные. И не указано по какому качественному признаку необходимо делить выборку, наличие центральных коммуникаций иди наличие гаража? В то же время мы установили, что обе фиктивные переменные являются статистически значимыми, следовательно, они обе влияют на цену дома, и нет необходимости изучать отдельное их влияние на цену, деля совокупность вначале по одному качественному признаку, а затем по другому.
Ниже приведены условия задач и отчет в формате doc. Закачка полного решения(документы doc и xlsx в архиве zip) начнется автоматически через 10 секунд. Если закачка не началась, кликните по этой ссылке.
Видеурок по решению этих задач - внизу страницы.
Сгенерировать ряд значений переменной «Доход», которая является случайной величиной, распределенной по нормальному закону с параметрами М и , где М — среднее значение (математическое ожидание) случайной величины, — стандартное (среднеквадратическое) отклонение.
Использование инструмента « Генерация случайных чисел »
Данный инструмент предназначен для заполнения диапазона ячеек случайными числами, распределенными по какому-либо закону . С помощью данной процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Чтобы сгенерировать на рабочем листе ряд значений случайной величины, нужно выполнить команду Сервис—Анализ данных— Генерация случайных чисел— OK и заполнить открывшееся диалоговое окно.


Рис 1. Диалоговое окно «Генерация случайных чисел»
1) Число переменных — это количество столбцов, в которых будут выведены случайные величины в соответствии с заданным законом распределения;
2) Число случайных чисел — количество ячеек со значениями случайной величины в каждом столбце;
3) Распределение — из списка выбирается один из законов;
Нормальное распределение — наиболее распространенный закон, описывающий случайные явления, для которых характерно воздействие на конечный результат многих независимых случайных факторов, причем среди этих факторов нет особенно выделяющихся. Применяется для описания непрерывных величин. Характеризуется двумя параметрами: средним значением и стандартным отклонением.
4) Параметры — зависят от выбранного закона:
5) Случайное рассеивание — число, которое позволяет при повторной генерации получать те же числа, что и при первом запуске генератора;
6) Параметры вывода — указывается верхняя левая ячейка на текущем листе, начиная с которой будут выведены случайные числа, можно также указать вывод на новый лист или в новый файл.
В нашем случае, для генерации 36 значений одной переменной, распределенной по нормальному закону с параметрами: М=11; =1,95 , нужно заполнить диалог так, как показано на рис. 1. Тогда после нажатия ОК диапазон ячеек В4:В39 будет заполнен значениями случайной величины (см. рис. 2).

Вычислить, используя статистические функции, характеристики сгенерированного ряда: среднее значение, стандартное отклонение, медиана, асимметричность, минимум.
Чтобы найти характеристики сгенерированного ряда , нужно выполнить команду Сервис—Анализ данных— Описательная статистика— OK и заполнить открывшееся диалоговое окно.

Далее заполняем диалоговое окно . Вводим входной интервал , указываем параметры вывода . В результате получим данные , показанные на рисунке 3.

Для каждого значения случайной величины вычислить интегральную функцию распределения вероятности и процентранг.
Для вычисления плотности и интегральной функции используем функцию НОРМРАСП, так как в примере 1 была сгенерирована величина, распределенная по нормальному закону с параметрами: М=11; =1,95.
1) В ячейку В2 вводим формулу = НОРМРАСП(A2;$G$2;$G$3;0)и протягиваем ее маркером до ячейки В37. Результат вычисления плотности распределения вероятности приведен на рис. 4.
2) В ячейку С2 вводим формулу = НОРМРАСП(A2;$G$2;$G$3;1) и протягиваем ее маркером до ячейки С37. Результат вычисления интегральной функции распределения приведен на рис. 4.
3) В ячейку D 2 вводим формулу = ПРОЦЕНТРАНГ($A$2:$A$37;A2) и протягиваем ее маркером до ячейки D37. Результат вычисления интегральной функции распределения приведен на рис. 4.

Найти распределение частот для сгенерированного ряда. Количество интервалов разбиения ( n ) взять из таблицы:
1) найти максимальное ( S max ) и минимальное ( S min ) значение ряда (ячейки D 6 и D 7);

2) вычислить длину интервала (кармана) по формуле (ячейка D 5);
3) вычислить границу первого кармана по формуле L 1 = S min + (ячейка D 8);
4) протянуть формулу еще на 5 ячеек для получения границ остальных карманов, т.е. L 2 = L 1 + , … . Если все было сделано правильно, то верхняя граница последнего кармана должна быть равна максимальному значению ряда, т.е. L n = S max . Таким образом получено шесть карманов: в первый попадают значения ряда, соответствующие условию S i L 1 ; во второй — L 1 < S i L 2 ; …

Рис. 5. Распределение частот для ряда случайной величины
5) по функции ЧАСТОТА вычислить количество значений случайной величины, попадающих в каждый карман. Для этого:
- выделить диапазон ячеек, соответствующий количеству карманов: F 8: F 12;
- вставить функцию и заполнить аргументы, как показано на рисунке:

- не нажимая кнопку ОК, завершить ввод формулы комбинацией клавиш
Ctrl + Shift + Enter ;
- в результате формула в строке формул будет заключена в фигурные скобки, а выделенный диапазон ( F 8: F 12) будет заполнен значениями.

На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;
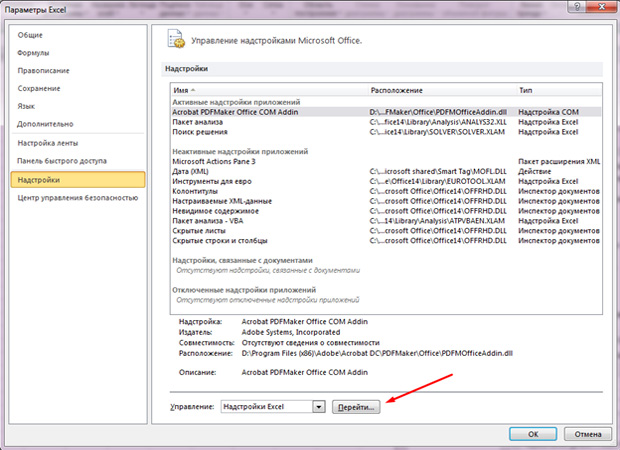
- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
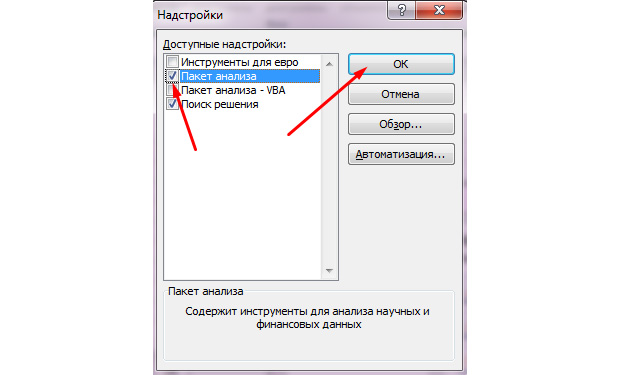
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».
Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.
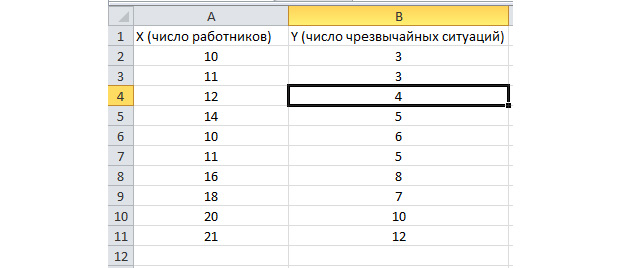
Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.
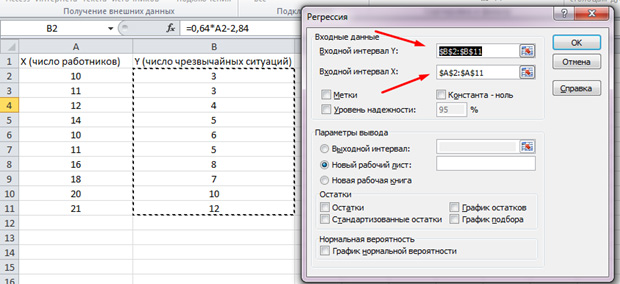
Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.
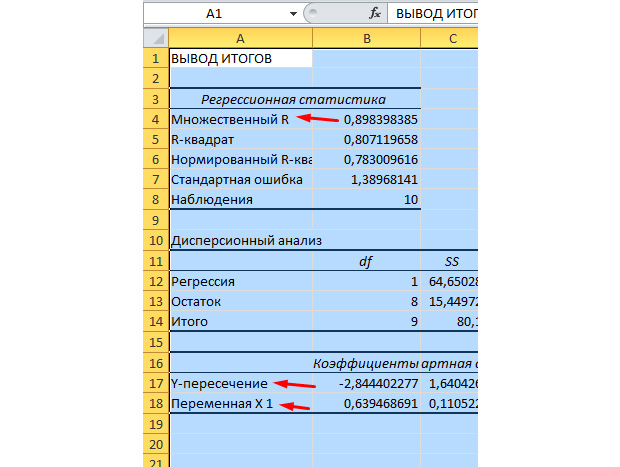
Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
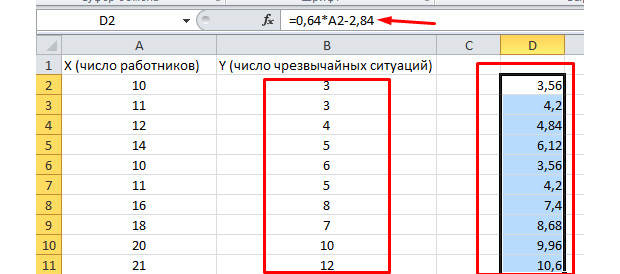
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.
Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.
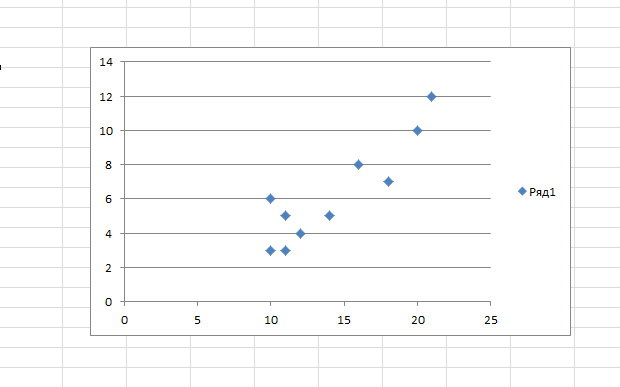
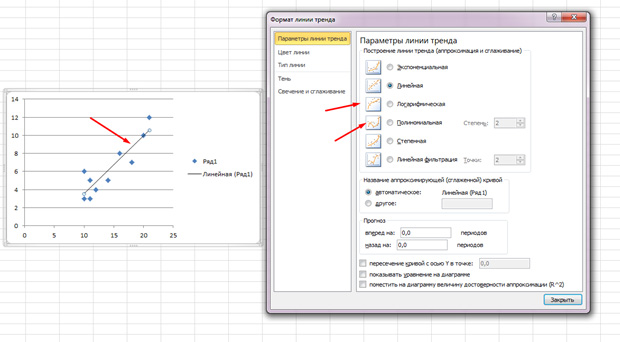
Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»

Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.
Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии

.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.

7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш ++ .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R 2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов |



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.

3. Коэффициент детерминации означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% - действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: .
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
- результаты регрессионной статистики,
- результаты дисперсионного анализа,
- результаты доверительных интервалов,
- остатки и графики подбора линии регрессии,
- остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:


Качество построенной модели оценивается как хорошее, так как не превышает 8 – 10%.

6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера:


Поскольку при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:

.
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:

I способ:

где – случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.


II способ:
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:


Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:


где
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии

Получили значение дисперсии
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.



Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Читайте также: