
Вставить json в excel на питоне
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip .
Если у вас Windows, Linux или macOS:
В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
В таком случае нужно установить недостающие модули:
Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame . А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas . Потом используем словарь для заполнения DataFrame :
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel() :
Также можно добавили параметр index со значением False , чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:

Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets , где каждый ключ будет названием листа, а значение — объектом DataFrame .
Дальше используем движок xlsxwriter для создания объекта writer . Он и передается функции to_excel() .
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:

Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter , который нужен для работы с классом ExcelWriter . Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save() , которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame . Для этого достаточно воспользоваться функцией read_excel() :
Данные очень легко читать из файлов CSV, но они часто хранятся в табличной форме в формате Excel.
pandas предоставляет специальные функции для работы с ним:
Функция read_excel() может читать из файлов Excel 2003 (.xls) и Excel 2007 (.xlsx). Это возможно благодаря модулю xlrd .
Для начала откроем файл Excel и введем данные со следующий таблиц. Разместим их в листах sheet1 и sheet2 . Сохраним файл как ch05_data.xlsx .
| white | red | green | black | |
|---|---|---|---|---|
| a | 12 | 23 | 17 | 18 |
| b | 22 | 16 | 19 | 18 |
| c | 14 | 23 | 22 | 21 |
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Для чтения данных из файла XLS нужно всего лишь конвертировать его в Dataframe , используя для этого функцию read_excel() .
По умолчанию готовый объект pandas Dataframe будет состоять из данных первого листа файла. Но если нужно загрузить и второй, то достаточно просто указать его номер (индекс) или название в качестве второго аргумента.
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Запись работает по тому же принципу. Для конвертации объекта Dataframe в Excel нужно написать следующее.
| Jan2015 | Feb2015 | Mar2015 | Apr2015 | |
|---|---|---|---|---|
| exp1 | 0.671044 | 0.437715 | 0.497103 | 0.070595 |
| exp2 | 0.864018 | 0.575196 | 0.240343 | 0.471081 |
| exp3 | 0.957986 | 0.311648 | 0.381975 | 0.622556 |
| exp4 | 0.407909 | 0.015926 | 0.180611 | 0.579783 |
В рабочей директории будет создан файл с соответствующими данными.
Данные JSON
JSON (JavaScript Object Notation) стал одним из самых распространенных стандартных форматов для передачи данных в сети.
Одна из главных его особенностей — гибкость, хотя структура и не похожа на привычные таблицы.
В этом разделе вы узнаете, как использовать функции read_json() и to_json() для использования API. А в следующем — познакомитесь с другим примером взаимодействия со структурированными данными формата, который чаще встречается в реальной жизни.
Начнем с самого полезного примера, когда есть объект Dataframe и его нужно конвертировать в файл JSON. Определим такой объект и используем его для вызова функции to_json() , указав название для итогового файла.
Он будет находится в рабочей папке и включать все данные в формате JSON.
Обратную операцию можно выполнить с помощью функции read_json() . Параметром здесь должен выступать файл с данными.
| down | left | right | up | |
|---|---|---|---|---|
| black | 5 | 7 | 6 | 4 |
| blue | 13 | 15 | 14 | 12 |
| red | 9 | 11 | 10 | 8 |
| white | 1 | 3 | 2 | 0 |
Это был простейший пример, где данные JSON представлены в табличной форме (поскольку источником файла frame.json служил именно такой объект — Dataframe ). Но в большинстве случаев у JSON-файлов нет такой четкой структуры. Поэтому нужно конвертировать файл в табличную форму. Этот процесс называется нормализацией.
Библиотека pandas предоставляет функцию json_normalize() , которая умеет конвертировать объект dict или список в таблицу. Для начала ее нужно импортировать:
Создадим JSON-файл как в следующем примере с помощью любого текстового редактора и сохраним его в рабочей директории как books.json .
Как видите, структура файла более сложная и не похожа на таблицу. В таком случае функция read_json() уже не сработает. Однако данные в нужной форме все еще можно получить. Во-первых, нужно загрузить содержимое файла и конвертировать его в строку.
После этого можно использовать функцию json_normalize() . Например, можно получить список книг. Для этого необходимо указать ключ books в качестве второго параметра.
| price | title | |
|---|---|---|
| 0 | 23.56 | XML Cookbook |
| 1 | 50.70 | Python Fundamentals |
| 2 | 12.30 | The NumPy library |
| 3 | 28.60 | Java Enterprise |
| 4 | 31.35 | HTML5 |
| 5 | 28.30 | Python for Dummies |
Функция считает содержимое всех элементов, у которых ключом является books . Все свойства будут конвертированы в имена вложенных колонок, а соответствующие значения заполнят объект Dataframe . В качестве индексов будет использоваться возрастающая последовательность чисел.
Однако в этом случае Dataframe включает только внутреннюю информацию. Не лишним было бы добавить и значения остальных ключей на том же уровне. Для этого необходимо добавить другие колонки, вставив список ключей в качестве третьего элемента функции.
| price | title | writer | nationality | |
|---|---|---|---|---|
| 0 | 23.56 | XML Cookbook | Mark Ross | USA |
| 1 | 50.70 | Python Fundamentals | Mark Ross | USA |
| 2 | 12.30 | The NumPy library | Mark Ross | USA |
| 3 | 28.60 | Java Enterprise | Barbara Bracket | UK |
| 4 | 31.35 | HTML5 | Barbara Bracket | UK |
| 5 | 28.30 | Python for Dummies | Barbara Bracket | UK |
Результатом будет Dataframe с готовой структурой.
Формат HDF5
До сих пор в примерах использовалась запись данных лишь в текстовом формате. Но когда речь заходит о больших объемах, то предпочтительнее использовать бинарный. Для этого в Python есть несколько инструментов. Один из них — библиотека HDF5 .
HDF расшифровывается как hierarchical data format (иерархический формат данных), а сама библиотека используется для чтения и записи файлов HDF5, содержащих структуру с узлами и возможностью хранить несколько наборов данных.
Библиотека разработана на C, но предусматривает интерфейсы для других языков: Python, MATLAB и Java. Она особенно эффективна при сохранении больших объемов данных. В сравнении с остальными форматами, работающими в бинарном виде, HDF5 поддерживает сжатие в реальном времени, используя преимущества повторяющихся паттернов в структуре для уменьшения размера файла.
Возможные варианты в Python — это PyTables и h5py . Они отличаются по нескольким аспектам, а выбирать их стоит, основываясь на том, что нужно программисту.
h5py предоставляет прямой интерфейс с высокоуровневыми API HDF5, а PyTables скрывает за абстракциями многие детали HDF5 с более гибкими контейнерами данных, индексированные таблицы, запросы и другие способы вычислений.
В pandas есть классовый dict под названием HDFStore , который использует PyTables для хранения объектов pandas. Поэтому перед началом работы с форматом необходимо импортировать класс HDFStore :
Теперь данные объекта Dataframe можно хранить в файле с расширением .h5 . Для начала создадим Dataframe .
Дальше нужен файл HDF5 под названием mydata.h5 . Добавим в него содержимое объекта Dataframe .
Можете догадаться, как хранить несколько структур данных в одном файле HDF5, указав для каждой из них метку. С помощью этого формата можно хранить несколько структур данных в одном файле, при том что он будет представлен переменной store .
Обратный процесс также прост. Учитывая наличие файла HDF5 с разными структурами данных вызвать их можно следующим путем.
Взаимодействие с базами данных
В большинстве приложений текстовые файлы редко выступают источниками данных, просто потому что это не эффективно. Они хранятся в реляционных базах данных (SQL) или альтернативных (NoSQL), которые стали особо популярными в последнее время.
Загрузка из SQL в Dataframe — это простой процесс, а pandas предлагает дополнительные функции для еще большего упрощения.
Модуль pandas.io.sql предоставляет объединенный интерфейс, независимый от базы данных, под названием sqlalchemy . Он упрощает режим соединения, поскольку команды неизменны вне зависимости от типа базы. Для создания соединения используется функция create_engine() . Это же позволяет настроить все необходимые свойства: ввести имя пользователя, пароль и порт, а также создать экземпляр базы данных.
Вот список разных типов баз данных:
Загрузка и запись данных с SQLite3
Для первого примера используем базу данных SQLite, применив встроенный Python sqlite3 . SQLite3 — это инструмент, реализующий реляционную базу данных очень простым путем. Это самый легкий способ добавить ее в любое приложение на Python. С помощью SQLite фактически можно создать встроенную базу данных в одном файле.
Идеальный вариант для тех, кому нужна база, но нет желания устанавливать реальную. SQLite3 же можно использовать для тренировки или для использования функций базы при сборе данных, не выходя за рамки программы.
Создадим объект Dataframe , который будет использоваться для создания новой таблицы в базе данных SQLite3.
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Теперь нужно реализовать соединение с базой.
Конвертируем объект в таблицу внутри базы данных.
А вот для чтения базы нужно использовать функцию read_sql() , указав название таблицы и движок.
| index | white | red | blue | black | green | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 3 | 15 | 16 | 17 | 18 | 19 |
На примере видно, что даже в этом случае процесс записи очень прост благодаря API библиотеки pandas.
Однако того же можно добиться и без них. Это покажет, почему pandas считается эффективным инструментом для работы с базой данных.
Во-первых, нужно установить соединение и создать таблицу, определив правильные типы данных, которые впоследствии будут загружаться.
Теперь можно добавлять сами данные с помощью SQL INSERT .
Наконец, можно перейти к запросам из базы данных. Это делается с помощью SQL SELECT .
Конструктору Dataframe можно передать список кортежей, а если нужны названия колонок, то их можно найти в атрибуте description своего cursor .
Этот подход куда сложнее.
Загрузка и запись с помощью PostgreSQL
Начиная с pandas 0.14, PostgreSQL также поддерживается. Для начала нужно проверить версию библиотеки.
Для запуска примера база PostgreSQL должна быть установлена в системе. В этом примере была создана база postgres , где пользователя зовут postgres , а пароль — password . Замените значения на соответствующие в вашей системе.
Сначала нужно установить библиотеку psycopg2 , которая предназначена для управления соединениями с базой данных.
Или с помощью PyPl:
Теперь можно установить соединение:
Примечание. В этом примере вне зависимости от установленной версии в Windows может возникать ошибка:
Это почти наверняка значит, что DLL для PostgreSQL (в частности, libpq.dll) не установлены в PATH. Добавьте одну из папок postgres\x.x\bin в PATH и теперь соединение Python с базой данных PostgreSQL должно работать без проблем.
Создайте объект Dataframe:
Вот как просто переносить данные в таблицу. С помощью to_sql() вы без проблем запишите их в таблицу dataframe .
pgAdmin III — это графическое приложение для управления базами данных PostgreSQL. Крайне удобный инструмент для Windows и Linux. С его помощью можно легко изучить созданную базу данных.
Если вы хорошо знаете язык SQL, то есть и классический способ рассмотреть созданную таблицу с помощью сессии psql .
В этом случае соединение произошло от имени пользователя postgres . Оно может отличаться. После соединения просто осуществите SQL-запрос к таблице.
Даже конвертация таблицы в объект Dataframe — тривиальная задача. Для этого есть функция read_sql_table() , которая считывает данные из таблицы и записывает их в новый объект.
Но когда нужно считать данные из базы, конвертация целой таблицы в Dataframe — не самая полезная операция. Те, кто работают с реляционными базами данных, предпочитают использовать для этих целей SQL. Он подходит для выбора того. какие данные и в каком виде требуется получить с помощью SQL-запроса.
Текст запроса может быть использован в функции read_sql_query() .
Чтение и запись данных в базу данных NoSQL: MongoDB
Среди всех баз данных NoSQL (BerkeleyDB, Tokyo Cabinet и MongoDB) MongoDB — одна из самых распространенных. Она доступна в разных системах и подходит для чтения и записи данных при анализе данных.
Работу нужно начать с того, что указать на конкретную директорию.
Теперь, когда сервис случает порт 27017, к базе можно подключиться, используя официальный драйвер для MongoDB, pymongo .
Один экземпляр MongoDB способен поддерживать несколько баз данных одновременно. Поэтому нужно указать на конкретную.
Когда база данных определена, нужно определить коллекцию. Она представляет собой группу документов, сохраненных в MongoDB. Ее можно воспринимать как эквивалент таблиц из SQL.
Теперь нужно добавить данные в коллекцию. Создайте Dataframe .
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Перед добавлением его нужно конвертировать в формат JSON. Процесс конвертации не такой простой, потому что нужно задать данные, которые будут записаны в базу, чтобы потом с легкостью извлекать их снова в объекте.
Теперь все готово для добавления документа в коллекцию. Для этого используется функция insert() .
В этом случае каждый объект представлен на отдельной строке. Когда данные загружены в документ базы данных, можно выполнить и обратный процесс, то есть, прочитать данные и конвертировать их в Dataframe .
JSON (JavaScript Object Notation-формат передачи данных), определен стандартом RFC 7159 (который вытекает из устаревшей версии RFC 4627) и ECMA-404, легким текстовым форматом обмена данных, основанным на синтаксисе литералов объекта JavaScript (хотя он и не является подгруппой JavaScript).
json предоставляет API, знакомый пользователям стандартных библиотечных модулей marshal и pickle.
Преобразование базовых объектов в Python в json:
Декодирование JSON, преобразование json в объект Python:
Специализированное декодирование объектов в JSON:
Рекомендуется использование json.tool для проверки и красивого вывода:
JSON является подмножеством YAML 1.2 JSON создан с помощью стандартных настроек этого модуля и также является подмножеством YAML 1.0 and 1.1. Этот модуль может использоваться в качестве сериализатора YAML.
До Python 3.7 порядок ключей словаря не сохранялся, поэтому входные и выходные данные, как правило, отличались. Начиная с Python 3.7, порядок ключей стал сохраняться, поэтому больше нет необходимости использовать collections.OrderedDict для парсинга JSON.
Основные методы
Метод json dump
Сериализует obj в JSON-подобный формат записывая его в fp (который поддерживает .write() ) используя эту таблицу.
Если skipkeys=True (по умолчанию: False ), тогда ключи словаря не базового типа ( str , int , float , bool , None ) будут пропущены, вместо того, чтобы вызывать исключение TypeError .
Модуль json всегда создает объекты str , не bytes . Следовательно, fp.write() должен поддерживать ввод str .
Когда ensure_ascii=True (по умолчанию), все не-ASCII символы в выводе будут экранированы последовательностями \uXXXX ,. Если ensure_ascii=False , эти символы будут записаны как есть.
Когда check_circular=False (по умолчанию: True ), тогда проверка циклических ссылок для типов контейнера будет пропущена, а такие ссылки будут вызывать OverflowError (или ошибку серьёзнее).
Если allow_nan=False (по умолчанию: True ), при каждой попытке сериализировать значение float , выходящее за допустимые пределы ( nan , inf , -inf ), будет возникать ValueError , в соответствии с сертификацией JSON. В случае если allow_nan=True , будут использованы JavaScript аналоги ( NaN , Infinity , -Infinity ).
Когда indent является неотрицательным целым числом или строкой, то объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или "" , будут использоваться новые строки без отступов. None (по умолчанию) отражает наиболее компактное представление. Если indent строка (например, "\t" ), эта строка используется в качестве отступа.
Изменения в версии 3.2: Допускаются строки для отступа в дополнение к целым числам.
Separators должны быть tuple (item_separator, key_separator) . По умолчанию используется значение (', ', ': ') если indent=None и (',', ': ') при другом значении. Чтобы получить наиболее компактное представление JSON, вы должны указать (',', ':') .
Изменения в версии 3.4: Используйте (',', ': ') при отступе None .
Значение default должно быть функцией. Он вызывается для объектов, которые не могут быть сериализованы. Функция должна вернуть кодируемую версию объекта JSON или вызывать TypeError . Если default не указано, возникает ошибка TypeError .
Если sort_keys=True (по умолчанию: False ), ключи выводимого словаря будут отсортированы.
Чтобы использовать собственный подкласс JSONEncoder (например, тот который переопределяет метод default() для сериализации дополнительных типов), укажите его с помощью аргумента cls ; в противном случае используется JSONEncoder .
Метод json dumps
Сериализирует obj в строку str формата JSON с помощью таблицы конвертации. Аргументы имеют то же значение, что и для dump() .
Ключи в парах ключ/значение всегда являются строками. Когда словарь конвертируется в JSON, все ключи словаря преобразовываются в строки. Если в результате, сначала конвертировать его в JSON, а потом обратно, новый в словарь может отличаться от, то можно получить словарь идентичный исходному. Другими словами, loads(dumps(x)) != x если x имеет не строковые ключи.
Метод json load
Десериализует из fp (текстовый или бинарный файл, который поддерживает метод .read() и содержит JSON документ) в объект Python используя эту таблицу конвертации.
object_hook — опциональная функция, которая применяется к результату декодирования объекта. Использоваться будет значение, возвращаемое этой функцией, а не полученный словарь dict . Эта функция используется для реализации пользовательских декодеров (например JSON-RPC).
object_pair_shook — опциональная функция, которая применяется к результату декодирования объекта с определенной последовательностью пар ключ/значение. Вместо исходного словаря dict будет использоваться результат, возвращаемый функцией. Эта функция используется для реализации пользовательских декодеров. Если задан object_hook , object_pairs_hook будет в приоритете.
В случае определения parse_float , он будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str) . Можно использовать другой тип данных или парсер для этого значения (например decimal.Decimal )
В случае определения parse_int , он будет вызван для декодирования строк JSON int. По умолчанию, эквивалентен int(num_str) . Можно использовать другой тип данных или парсер для этого значения (например float ).
В случае определения parse_constant , он будет вызван для строк: -Infinity , Infinit , NaN . Может быть использован для вызова исключений при обнаружении недопустимых чисел JSON. parse_constant больше не вызывается при null, true, fasle .
Чтобы использовать собственный подкласс JSONDecoder , укажите его с помощью аргумента cls ; в противном случае используется JSONDecoder . Дополнительные аргументы ключевого слова будут переданы конструктору класса.
Если десериализованные данные не являются допустимым документом JSON, возникнет JSONDecodeError .
Метод json loads
Десериализует s (экземпляр str , bytes или bytearray , содержащий JSON документ) в объект Python используя таблицу конвертации.
Остальные аргументы аналогичны аргументам в load() , кроме кодировки, которая устарела либо игнорируется.
Если десериализованные данные не являются допустимым документом JSON, возникнет ошибка JSONDecodeError .
Кодировщики и декодировщики
JSONDecoder
Класс json.JSONDecoder (*, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
Простой декодер JSON. При декодировании выполняет следующие преобразования:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
Он также понимает NaN , Infinity , и -Infinity как соответствующие значения float , которые находятся за пределами спецификации JSON.
object_hook будет вызван для каждого значения декодированного объекта JSON, а его возвращаемое значение будет использовано в указанном месте dict . Может быть использовано для обеспечения десериализации (например, для поддержки JSON-RPC class hinting).
object_pairs_hook будет вызван для каждого значения декодированного объекта JSON с упорядоченным списком пар. Возвращаемое значение object_pairs_hook будет использовано вместо dict . Эта функция может использоваться для запуска стандартного декодера. Если object_hook так же определён, в приоритете будет object_pairs_hook .
parse_float будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str) . Может быть использован для другого типа данных или парсера JSON float. (например, decimal.Decimal ).
parse_int будет вызван для строки JSON int. По умолчанию, эквивалентно int(num_str) . Может быть использован для других типов данных и парсеров целых чисел JSON (например, float ).
parse_constant будет вызван для строк: '-Infinity' , 'Infinity' , 'NaN' . Можно использовать для вызова исключений при обнаружении недопустимых чисел JSON.
Если strict=False ( True по умолчанию), тогда использование управляющих символов внутри строк будет разрешено. В данном контексте управляющие символы — это символы с кодами в диапазоне 0–31, включая \t (tab), \n , \r и \0 .
Если десериализованные данные не являются допустимым документом JSON, будет вызвана ошибка JSONDecodeError .
decode(s)
Возвращает представление s в Python ( str — содержащий документ JSON). JSONDecodeError будет вызвана, если документ JSON не валидный (или не действительный).
raw_decode(s)
Декодирует документ JSON из s ( str начинающийся с JSON документа) и возвращает кортеж из 2-х элементов (представление Python и индекс строки в s , на которой закончился документ). Может использоваться для декодирования документа JSON из строки, которая имеет дополнительные данные в конце.
JSONEncoder
Класс json.JSONEncoder (*, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None)
Расширяемый кодировщик JSON для структур данных Python.
Поддерживает следующие типы данных и объекты по умолчанию:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
Для того, чтобы можно было распознавать и другие объекты, подкласс должен выполнить метод default() , который вернет сериализуемый объект для o , если это возможно, в противном случае он должен вызвать реализацию родительского класса (для вызова TypeError ).
Если skipkeys=False (по умолчанию), вызывается TypeError при попытке кодировать ключи, которые не являются str , int , float или None . В случае если skipkeys=True , такие элементы просто пропускаются.
Если ensure_ascii=True (по умолчанию), на выходе гарантируется, что все входящие не ASCII символы экранируются последовательностями \uXXXX . Но если ensure_ascii=False , эти символы будут выводиться как есть.
Если check_circular=True (по умолчанию), тогда списки, словари и самостоятельно закодированные объекты будут проверяться на циклические ссылки во время кодировки, чтобы предотвратить бесконечную рекурсию (что вызовет OverflowError ). В другом случае, такая проверка не выполняется.
Если allow_nan=True (по умолчанию), тогда NaN , Infinity , и -Infinity будут кодированы как таковые. Это не соответствует спецификации JSON, но соответствует большинству кодировщиков и декодеров на основе JavaScript. В другом случае такие значения вызовут ValueError .
Если sort_keys=True (по умолчанию: False ), выводимый словарь будет отсортирован по именам ключей; это полезно для регрессивного тестирования, чтобы сравнивать сериализацию JSON ежедневно.
Если indent является неотрицательным целым числом или строкой, то объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или "" , будут использоваться новые строки без отступов. None (по умолчанию) отражает наиболее компактное представление. Если indent строка (например, "\t" ), эта строка используется в качестве отступа.
Если указан separator (должен быть tuple типа (item_separator, key_separator) ). По умолчанию используется (', ', ': ') если indent=None и (',', ': ') если нет. Для получения наиболее компактного представления JSON , вам следует использовать (',', ':') , чтобы уменьшить количество пробелов.
Значение default должно быть функцией. Она вызывается для объектов, которые не могут быть сериализованы. Функция должна вернуть кодируемую версию объекта JSON или вызывать TypeError . Если default не указано, возникает ошибка TypeError .
default(o)
Внедрите этот метод в подкласс таким образом, чтобы он возвращал сериализуемый объект для o или вызывал базовую реализацию (для повышения TypeError ).
Например, чтобы поддерживать произвольные итераторы, вы можете реализовать default следующим образом:

In this Pandas tutorial, we will learn how to export JSON to Excel in Python. This guide will cover 4 simple steps making use of Python’s json module, and the Python packages requests and Pandas.
The structure of this tutorial is as follows. In the first section, we will have a quick look at a basic example of how to convert JSON to an Excel file with Pandas and Python. After we have seen and briefly learned, the syntax we will continue with a section covering some examples of when this knowledge may be useful. In the third section, we will have a look at the prerequisites of this Python tutorial and how to install Pandas. After we are sure we have everything needed, we will go through four steps on how to save JSON to Excel in Python. Here, we will start by reading the JSON file from the hard drive and saving it as an Excel file. Furthermore, we will also look at an example when reading JSON from a URL and saving it as a .xlsx file. Finally, we will also use the Python package JSON to excel converter.
Table of Contents
Basic Code Example to import JSON to Excel with Python
Here is the easiest way to convert JSON data to an Excel file using Python and Pandas:
Briefly explained, we first import Pandas, and then we create a dataframe using the read_json method. Finally, we save the dataframe to a .xlsx file with the to_excel method. Remember to change the string to the path we are you store the JSON data as well as where you want to save the Excel file.
Conversion
In this section, the problem will be briefly formulated. Now, although we can work with data using only Python and its packages, we might collaborate with people that want to work in Excel. It is, of course, true that Microsoft Excel is packed with features to keep and organize tabular data. Furthermore, it might also be easier to get an overview of the data in Excel. Now, a lot of open data resources are storing data in a variety of different file formats. But sometimes, we might find out that the data is stored in the JSON format only. In some cases, we might want to obtain data from JSON and save it to Excel and send it to our collaborators. Now, in other cases, we just want to explore data ourselves, as mentioned before, using Excel.
Despite it is possible to import JSON to Excel with Microsoft Excel itself, the optimal way is automating the conversion by importing data from JSON to Excel worksheets programmatically. Especially, if we already know Python.
Prerequisites
In this section, you will learn what you need to have installed to convert JSON data to Excel files.
Obviously, to follow this guide you will need to have Python, requests, and Pandas installed. Secondly, and not that obvious maybe, you will also need to install the package openpyxl. This package is what will be used, by Pandas, to create Excel files (e.g., .xlsx).
Now, there is one very easy way to install both Python and Pandas: installing a Python scientific distribution such as Anaconda, ActivePython, or Canopy (see here for a list of Python distributions). For example, if you install Anaconda you will get a library with useful Python packages, including Pandas.
How to Install Pandas and openpyxl
If you already have Python installed, you can use pip to install Python packages. To install Pandas and openpyxl using pip open up Windows Command Prompt or the Terminal you prefer and type the following code:
Sometimes, pip will warn us that there’s a newer version. If this is the case now, read the post about upgrading pip for more information.
Note, that it is generally a good idea to create a virtual environment and install your new packages in this environment. Now, that you have all that you need we will continue to the next section of this tutorial. If you use a tool such as pipx you can automatically install Python packages in virtual environments. Here’s a YouTube video on how to install Pandas and Anaconda:
As a final note, before converting JSON to Excel with Python: if you need, you can use pip to install specific version of Python packages.
4 Steps to Convert JSON to Excel in Python
In this section we will go through, step-by-step, how to import JSON data and save it as an Excel file using Python. Here’s a summary of what this chapter will cover: 1) importing pandas and json, 2) reading the JSON data from a directory, 3) converting the data to a Pandas dataframe, and 4) using Pandas to_excel method to export the data to an Excel file.
1. Importing the Pandas and json Packages
First, we start by importing Pandas and json:
Now, it may be evident but we are importing json and then Pandas to use json to read the data from the file and, after we have done this, we will use Pandas to save it as a .xlsx file.
2. Reading the JSON file
Now, we are ready to import the data from a file using the load method:
As you can see in the code chunk above, we are first opening a file with Python (i.e., as json_file) with the with-statement. Moreover, in the with-statement we are using the load method. This is when we are actually reading the JSON file.
3. Creating a Pandas Dataframe
Now, before we can save the data, we have imported we need to create a dataframe:
In the code chunk above, we used Pandas DataFrame class to create a dataframe from the JSON data we have, in the previous section, loaded into Python. Basically, what we do is similar to converting a Python dictionary to a Pandas dataframe. Note, adding new columns to the dataframe, before saving it, is of course also possible.
4. Saving the Imported Data as a .xlsx File
Finally, we can use the to_excel method that is available in the dataframe object:
Now, if we want to convert JSON data to other formats such as CSV, SPSS, or STATA to name a few we can use other methods available in the dataframe object. For example, if we want to save the JSON data to a CSV file we can use the to_csv method. If you are interested in learning more about reading and writing data files with Python and Pandas check out the following blog posts:
Now, it is worth mentioning here that we actually can skip step 2 and use Pandas read_json method to import the JSON data to a dataframe. Here’s a full working example on how to save JSON data with only the Pandas package:
In the next section, we will have a look at how to read JSON data from a URL and save it as an Excel file.
JSON to Excel: Reading data from a URL
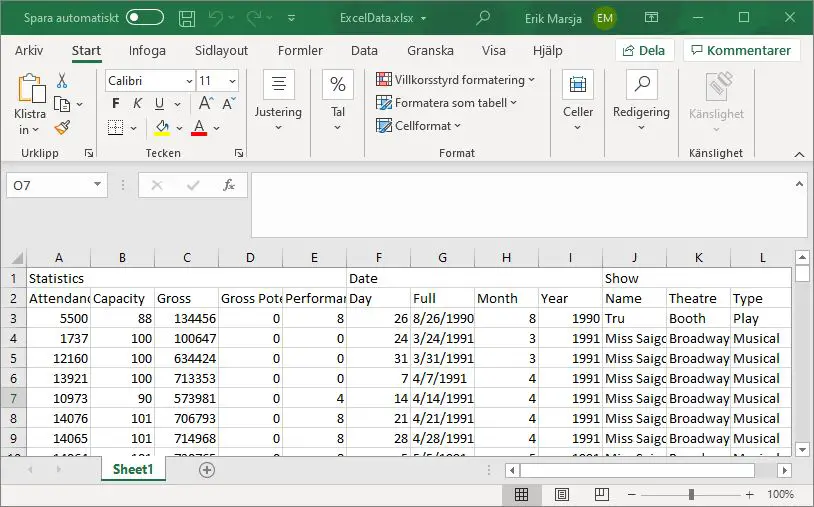
In the previous section, we learned, step-by-step, how to automatically convert JSON data to an Excel file in Python. Here, we are going to use the same steps, but we are going to read the data from a URL. First, we are going to look at a simple example where we can use the same code as above. However, we are going to change the string so that it is pointing at the URL location instead of a directory.
Now, as you can see, we managed to read this JSON file with Python and save it as an Excel file using Pandas. In the next section, we will look at a bit more complex JSON file where the data is nested.
Nested JSON data to Excel
In this section, we will look at a bit more complex example. Now, there are times when the JSON data is nested and if we use the method above the Excel file will be messy. Luckily, we can fix this by using json_normalize from Pandas and the requests module:
In the code chunk above, we first imported requests and then json_normalize. Second, we created a string with the URL to the JSON data we want to save as an Excel file. Now, the next thing we do to use the get method which sends a GET request to our URL. Briefly, this is pretty much reading in the webpage that we want, and we can, then, use the json method to get the json data. Finally, we used the json_normalize to create a dataframe that we save as an Excel file. Again, saving the data we read from the JSON file is done with the to_excel method.
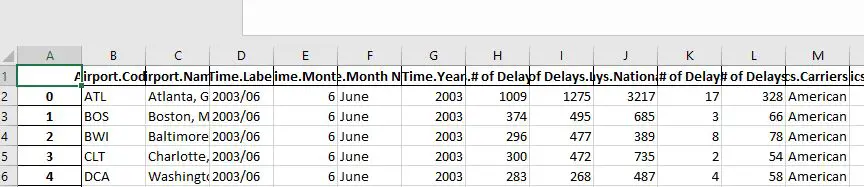
Now, as you may have noticed in the image of the output (i.e., the .xlsx files opened in Excel) we have a row that is not part of our original data. This row is the index row from the Pandas dataframe and we can, of course, get rid of this. In the next section, we will look at some of the arguments of the to_excel method. For example, if we want to get rid of the index row, we will learn how to do that. If you are interested check out the tutorial on how to read and write JSON with Python and Pandas.
Import JSON to Excel and Specifying the Sheet Name
In this section, we will specify the sheet name using the sheet_name argument. Now, it might be obvious, but the string we input will be the name of the Worksheet in the Excel file:
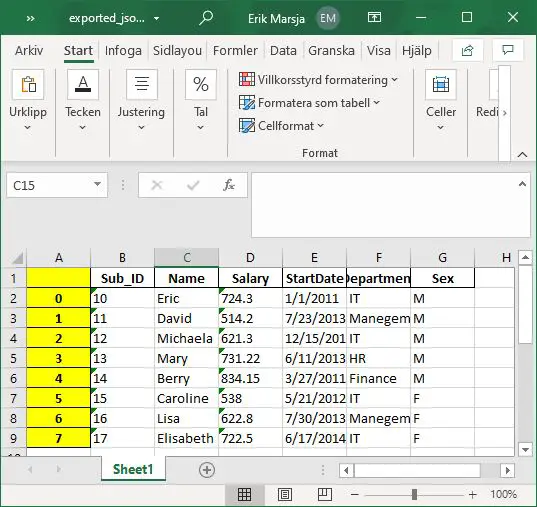
In the example code above, we named the sheet ‘Session1’. However, we still can see the index column in the Excel file. In the next section, we will have a look on how to remove this index.
JSON to Excel with Pandas Removing the Index Column
To remove the index column when converting JSON to Excel using Pandas we just use the index argument:
Now, this argument takes a bool (True/False) and the default is True. Thus, in the code example above we set it to False and we get this Excel file:
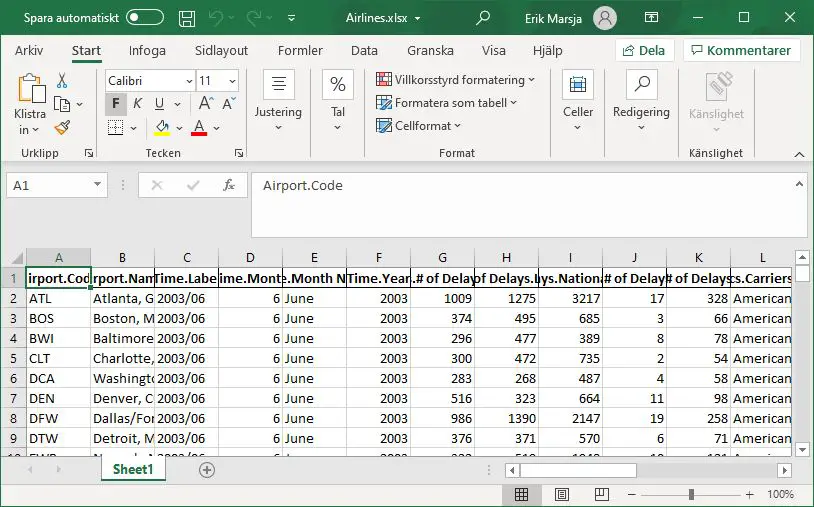
Of course, there are plenty of more arguments that we could use when converting JSON to Excel with Pandas. For instance, we can set the encoding of the excel file. Another thing we can do is to set the engine: openpyxl or xlsxwriter. Note, to use the to_excel method to save the JSON file to an Excel file you need to have one of them installed on your computer (see the previous section). See the documentation for more information on how to use the arguments of the to_excel method.
Other Options: the JSON to excel converter Package
Now, there are of course other methods and/or Python packages that we can use to convert JSON to Excel in Python. For example, we could work with the json module and choosing one of xlsxwriter or openpyxl packages. It is worth noting, however, that the resulting Python script will be a bit more complex. Furthermore, there is a Python package created just for the purpose of converting JSON to Excel: JSON to excel converter.
JSON to Excel with the JSON to excel converter package
Here’s a how-to quickly convert JSON to a .xlsx file:
This package is very easy to use. In the example code above, we converted the airlines.json data to an Excel file. Remember, this data is nested and one very neat thing with the JSON to excel converter package is that it can handles this very nicely (see the image below for the resulting Excel file).
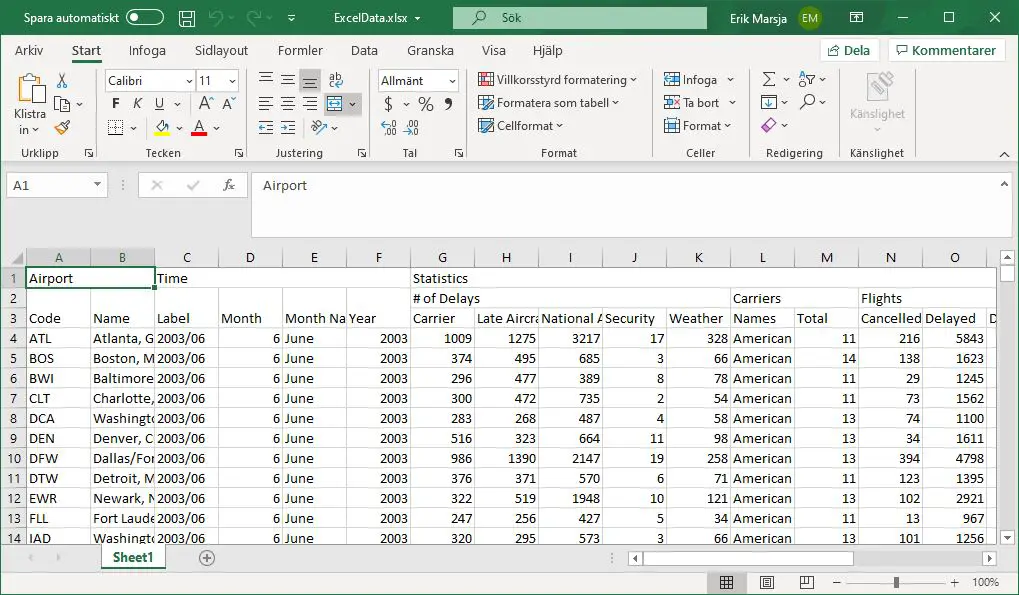
Note, however, that you need to install the xlsxwriter package to be able to use the JSON to excel converter. Both can be installed using pip: pip install json-excel-converter[xlsxwriter] .
Conclusion
In this post, we have covered a lot of things related to opening JSON files and saving them as Excel files using Python. Certainly, knowing how to convert JSON data to Excel files might be useful in many situations. For instance, if we are getting the data and collaborating with someone who prefers using Excel. To summarize, in this tutorial we have used the Python packages Pandas, json, requests, and JSON to excel converter to read JSON files and save them as Excel files. First, we had a quick look at the syntax, then we learned 4 steps to converting JSON to Excel. After that, we have also learned how to read the JSON data from a URL, and how to work a bit with some of the arguments of the to_excel method.
Hopefully, you learned something from this Python tutorial and if you did find it useful: please do share it on your social media accounts. Finally, if you have anything you would like to learn please leave a comment below and I might put that together in a new tutorial.
Есть много способов преобразовать файл Excel в данные JSON в Python. В этом руководстве мы рассмотрим два модуля python для преобразования файлов Excel в JSON:
Преобразование файла Excel в файлы JSON с использованием модуля excel2json-3
Это очень простой модуль для преобразования файлов Excel в файлы JSON. Содержимое таблицы Excel преобразуется в строку JSON и сохраняется в файле.
Имя файлов происходит от имен листов Excel. Итак, если есть два листа с именами «Numbers» и «Cars», файлы JSON будут называться Numbers.json и Cars.json соответственно.
Модуль поддерживает преобразование файлов в форматах .xls и .xlsx. Мы можем прочитать файл Excel из файловой системы, а также URL-адрес.
Мы можем установить этот модуль с помощью команды PIP.
В нашем примере я создал файл Excel с именем «records.xlsx», имеющий три листа.

Вот сценарий для преобразования этого файла Excel в файлы JSON.
Скрипт создает три файла JSON.
Если вам нужно прочитать файл Excel по URL-адресу, используйте функцию convert_from_url().
Ограничения модуля excel2json-3
- Плагин имеет очень ограниченные возможности.
- Нет возможности пропустить какой-либо лист, строки или столбцы. Это затрудняет использование файлов Excel большего размера.
- JSON сохраняется в файлы. В большинстве случаев мы хотим преобразовать в JSON и использовать его в нашей программе, а не сохранять в виде файла.
- Целые числа преобразуются в числа с плавающей запятой.
Преобразование листа Excel в строку JSON с помощью модуля Pandas
Модуль Pandas предоставляет функции для чтения таблиц Excel в объект DataFrame. Есть много опций для указания заголовков, чтения определенных столбцов, пропуска строк и т.д.
Мы можем использовать функцию to_json() для преобразования объекта DataFrame в строку JSON. Давайте посмотрим на простой пример, чтобы прочитать лист «Сотрудники» и преобразовать его в строку JSON.
Итак, данные JSON создаются с ориентацией столбцов. Если вы хотите создать строку JSON с построчной ориентацией, передайте значение параметра «orient» как «records».
Заключение
Если у вас есть простой и хорошо структурированный файл Excel, и вы хотите преобразовать его в файлы JSON, используйте модуль excel2json-3. Но если вам нужен больший контроль над тем, как данные Excel читаются и конвертируются в строку JSON, используйте модуль pandas.
Читайте также: