В каком формате хранятся тексты конфигурации и базы данных в системе 1с предприятие
Отмазки.
Данное описание не претендует на законченность, безошибочность и понятность.
Начало.
Описание формата приведено в терминах языка C. Размер типа char – 1 байт, размер типа short int – 2 байта, размер типа int и unsigned int – 4 байта. Префиксом 0x обозначаются шестнадцатеричные числа.
Файлы баз *.1CD состоят из блоков длиной 4096 байт (0x1000). Соответственно, длина файла всегда кратна 4096.
Блок 0.
Нулевой блок имеет следующую структуру:
char sig[8]; // сигнатура “1CDBMSV8”
unsigned int length;
Первые 8 байт – сигнатура базы «1CDBMSV8».
Следующие 4 байта - это версия базы. На данный момент мне встречались только версия «8.0.5.0» (ver1 = 8, ver2 = 0, ver3 = 5, ver4 = 0) – это базы 1Cv8.0 и версия «8.1.0.0» (ver1 = 8, ver2 = 1, ver3 = 0, ver4 = 0) – это базы 1Cv8.1 и 1Cv8.2.
Следующие 4 байт – длина базы (файла) в блоках.
Предназначение поля unknown неизвестно, всегда содержит 1.
Объекты.
Вся остальная информация в базе хранится в объектах (файлах базы). Каждый объект состоит из одного или более блоков. У каждого объекта есть один заголовочный блок, блоки с таблицей размещения, и собственно данные. Второе и третье может отсутствовать.
Структура первого блока каждого объекта такова:
char sig[8]; // сигнатура “1CDBOBV8”
int length; // длина содержимого объекта
unsigned int version;
unsigned int blocks[1018];
Первые 8 байт – сигнатура базы «1CDBOBV8».
Есть 2 типа объектов.
Блок 1. Таблица свободных блоков.
Первый тип объекта – это таблица свободных блоков. Признаком этого блока является поле version равное 0. Такой объект в базе всегда один, и его заголовочный блок располагается всегда в блоке со смещением 1 (т.е. по адресу 0x1000). Длина данных такого объекта равна (length * 4) байт.
В blocks содержатся номера блоков, в которых собственно и находится содержимое таблицы свободных блоков. Значащими являются ненулевые значения в массиве blocks. Содержимое таблицы свободных блоков – это просто массив номеров свободных блоков:
unsigned int free_blocks[length];
Таким образом, в базе содержатся ровно length свободных блоков.
Когда системе требуется новый блок для данных, то она берет последний свободный блок из массива free_blocks и уменьшает length на 1. Если свободных блоков нет, то он создается в конце файла базы. Блоки, содержащиеся в массиве blocks, не являются свободными, а принадлежат объекту – таблице свободных блоков. В blocks может содержаться больше блоков, чем необходимо для хранения массива free_blocks.
Остальные объекты.
Второй тип объектов характеризуется ненулевым значением поля version. Вся информация в базе, кроме блока 0 и таблицы свободных блоков хранится именно в таких объектах.
В поле length содержится длина в байтах данных объекта.
В массиве blocks находятся индексы блоков, содержащих таблицу размещения данных объекта. Каждый блок, указанный в blocks, и являющийся частью таблицы размещения, имеет следующую структуру:
unsigned int datablocks[1023];
Поле numblocks указывает количество реальных значений в datablocks (от 1 до 1023). В datablocks содержатся индексы блоков, в которых находится собственно содержимое объекта (данные). Так как в одном блоке таблицы размещения может быть указано максимум 1023 блока с данными, то соответственно, максимальная длина данных, указанных в одном блоке таблицы размещения равна 1023 * 4096 = 4190208 байт (0x3ff * 0x1000 = 0x3ff000). Таким образом, из длины содержимого объекта length мы можем определить количество фактических значений в blocks. Если length равен 0, то в blocks нет значащих данных, иначе количество значений в blocks равно (length - 1) / 0x3ff000 + 1 (деление целочисленное, без остатка). А также можно вычислить максимальную длину данных одного объекта: 4190208 * 1018 = 4265631744 байт (1018 – максимальное количество значений в массиве blocks), это совсем немного меньше 4х гигабайт.
Повторим, в заголовочном блоке объекта находится массив blocks, содержащий индексы блоков с таблицей размещения. А в таблице размещения находятся блоки, содержащие сами данные.
Блок 2. Корневой объект.
Последним объектом с предопределенным расположением является корневой объект. Заголовочный блок корневого объекта располагается в блоке с индексом 2. Все остальные объекты базы могут быть получены через корневой объект. Структура данных этого объекта зависит от версии базы, хотя и различается несильно. Для версии базы «8.0.5.0» эта структура выглядит так:
Для версии «8.1.0.0» структура выглядит так:
Т.е. различаются эти структуры только длиной поля lang. В поле lang содержится код языка базы. Код языка базы представляет собой строку в ANSI-кодировке. Мне встречались только базы с кодами «ru_RU» и «en». На что влияют эти коды языка, я не знаю, возможно, на порядок сортировки строк при построении индексов.
В поле numblocks содержится количество элементов в массиве tableblocks. В массиве же tableblocks содержатся индексы объектов, содержащих все таблицы данных. Т.е. таблиц в базе ровно numblocks.
Объект таблицы.
Каждый объект таблицы, указанный в корневом объекте, содержит просто текстовое описание таблицы в Unicode. Вот пример описания таблицы:
Как видно из этого примера, здесь присутствуют имя таблицы (_Reference4), раздел описания полей таблицы (Fields), раздел описания индексов (Indexes), параметр Recordlock и раздел Files.
В разделе Files всегда содержатся три числа, которые содержат индексы заголовочных блоков объектов (по порядку) с записями таблицы, Blob-данными (строки неограниченной длины и двоичные данные) и индексами. Если какого-либо объекта у таблицы нет, то соответствующее число равно нулю.
В разделе Fields содержатся описания полей таблицы. Описание каждого поля содержит (по порядку): имя поля (FieldName), тип поля (FieldType), признак использования NULL (NullExists), длину (FieldLength), точность (FieldPrecision) и признак регистрочувствительности (FieldCaseSensitive).
Сколько байт занимает каждое поле в записи, и как его интерпретировать, зависит от параметров поля. Во-первых, если NullExists у поля равен 1, то первый байт поля является признаком NULL. Значение 0 этого байта означает, что поле не содержит значение (т.е. содержит NULL). В противном случае, поле содержит значение. Если же NullExists равен 0, то такого байта в поле нет.
Далее, размер и формат поля зависит от типа поля. Типы поля бывают такими:
- «B» - двоичные данные. Длина поля равна FieldLength байт.
- «L» - булево. Длина поля 1 байт. Нулевое значение байта означает Ложь, иначе Истина.
- «N» - число. Длина поля в байтах равна Цел((FieldLength + 2) / 2). Числа хранятся в двоично-десятичном виде. Первый полубайт означает знак числа. 0 – число отрицательное, 1 – положительное. Каждый следующий полубайт соответствует одной десятичной цифре. Всего цифр FieldLength. Десятичная точка находится в FieldPrecision цифрах справа. Например, FieldLength = 5, FieldPrecision = 3. Байты 0x18, 0x47, 0x23 означают число 84.723, а байты 0x00, 0x00, 0x91 представляют число -0.091.
- «NC» - строка фиксированной длины. Длина поля равна FieldLength * 2 байт. Представляет собой строку в формате Unicode (каждый символ занимает 2 байта).
- «NVC» - строка переменной длины. Длина поля равна FieldLength * 2 + 2 байт. Первые 2 байта содержат длину строки (максимум FieldLength). Оставшиеся байты представляет собой строку в формате Unicode (каждый символ занимает 2 байта).
- «RV» - версия. Длина поля 16 байт. Предположительно содержит четыре числа int.
- «NT» - строка неограниченной длины. Длина поля 8 байт. Первые четыре байта содержат начальный индекс блока в объекте Blob таблицы, вторые четыре – длину данных в объекте Blob. В объекте Blob содержится строка в формате Unicode.
- «I» - двоичные данные неограниченной длины. Длина поля 8 байт. Первые четыре байта содержат начальный индекс блока в объекте Blob таблицы, вторые четыре – длину данных в объекте Blob.
- «DT» - дата-время. Длина поля 7 байт. Содержит данные в двоично-десятичном виде. Первые 2 байта содержат четыре цифры года, третий байт – две цифры месяца, четвертый байт – день, пятый – часы, шестой – минуты и седьмой – секунды, все также по 2 цифры.
Зная теперь длину в байтах каждого поля можно посчитать общую длину одной записи таблицы и смещение каждого поля в записи. Но для этого необходимо учесть следующее. Если в описании полей таблицы нет поля с типом версия (RV), но при этом параметр Recordlock равен 1, то в записи присутствует дополнительное поле, которое я для себя называю короткая скрытая версия. Длина этого поля равна 8 байт. В каждой записи самый первый байт – это признак удаленности записи (признак, что запись не занята). Если этот байт равен 1, то запись свободна, а следующие 4 байта содержат индекс следующей свободной записи. Из этого следует, что запись не может быть короче пяти байт. Если же первый байт записи содержит 0, то далее в записи следуют значения полей. Причем порядок полей определяется таким образом: превым всегда идет поле версии (или описанное в разделе Fields с типом RV или поле скрытой короткой версии), затем все остальные поля в том порядке, как они описаны в разделе Fields.
Объект записей таблицы.
Содержимое объекта записей таблицы содержит просто массив записей. Таким образом, длина данных этого объекта всегда кратна длине одной записи. Первая (точнее нулевая) запись всегда помечена как свободная, она содержит индекс следующей свободной записи (или 0, если таких нет). Т.е. с нее начинается цепочка свободных записей таблицы.
Объект Blob таблицы.
Объект содержит Blob-данные таблицы (строки неограниченной длины и двоичные данные неограниченной длины). Содержимое этого объекта состоит из блоков (не путать с блоками, из которых состоит файл 1CD) длиной 256 байт (0x100). Т.е. это просто массив блоков длиной 256 каждый. Поэтому длина данных объекта всегда кратна 256. Структура каждого блока объекта такова:
unsigned int nextblock;
short int length;
Поле nextblock содержит индекс следующего блока, содержащего продолжение данных, или 0, если следующего блока нет. Поле length содержит длину данных в этом блоке (максимум 250). Поле data содержит сами данные. Нулевой блок всегда считается свободным, в поле nextblock он содержит индекс следующего свободного блока. Таким образом, с нулевого блока начинается цепочка свободных блоков.
В записях таблицы в полях с типом «NT» и «I» содержится индекс первого блока, с которого начинаются данные, относящиеся к этому полю данной записи.
Объект индексов таблицы.
На данный момент структура индексов до конца не изучена.
Задача отражает движение бизнес-процесса по точкам маршрута. При этом в бизнес-процессе на закладке Основные указывается задача того типа, что будет использоваться в процессе:
Вопрос 01.36 экзамена 1С:Профессионал по платформе. Можно ли в системе 1С:Предприятии определить свой тип данный, например "ЦенаНоменклатуры"?
- Да, для этого есть определяемые типы
- Да, для этого есть общие реквизиты
- Такой возможности в платформе нет
Вопрос 01.41 экзамена 1С:Профессионал по платформе. Назовите основное назначение объектов типа "ЖурналДокументов"
Правильный ответ первый, разработчик включает в журналы документы разных видов по принципу "Используются вместе":
- предназначен для хранения предположительно не изменяющейся информации
- для хранения значений во времени необходимо установить признак периодичности
- в платформе 8 не поддерживает признак периодичности, необходимо использовать периодический регистр сведений
- верны ответы 1 и 2
- верны ответы 1 и 3
Правильный ответ пятый, нужна для хранения условно-постоянных значений. Признака периодичности не имеет:
- прикладной объект, значения которого задаются в Конфигураторе.
- может хранить различные типы значений
- для него может быть заданы форма списка и выбора
- верны все указанные ответы
- верны ответы 1 и 3
Вопрос 01.56 экзамена 1С:Профессионал по платформе. При создании нового Плана видов характеристик обязательно должны быть заполнены:
- Свойство "Тип значения характеристик"
- Свойство "Дополнительные значения характеристик"
- Оба свойства могут быть не заполнены
- Обязательно должны быть заполнены свойства "Тип значения характеристик" и "Дополнительные значения характеристик"
Правильный ответ первый - Тип значения характеристик всегда заполнен, а Дополнительный значения по умолчанию пустое поле:
- не возможно
- реализовано с помощью макетов
- обеспечивается константами и реквизитами с типом данных "Хранилище значений"
- верны варианты 2 и 3
Правильный ответ второй.
Бинарные данные в терминах 1С - это файл произвольного формата данных. Платформа не понимает, что делать с каждым конкретным файлом, предполагается, что это решает пользователь.
В конфигурации бинарные данные могут храниться в макетах. То есть в макет печатной формы можно вставить например картинку.
8 комментариев:
Очень полезный справочник. Спасибо.
Огромное спасибо автору или авторам этого проекта!Это "луч света в тёмном царстве" 1С . :)
01.66 Почему не верен ответ 4. Пункт 3 же тоже позволяет хранить бинарные данные? Или нет.
Потому что в "конфигурации", а не в "информационной базе".
Этот комментарий был удален автором.
Ни фига не +..
С таким успехом ответ на аналогичный вопрос 01.54 не верен. Вот он:
При необходимости внести в механизм полнотекстового поиска свой дополнительный словарь (синонимы, специфичные для какого-либо рода деятельности) его можно включить в конфигурацию:
1 как константу
2 как общий макет
3 как параметр сеанса
4 верны ответы 1,2
5 верны ответы 1,2,3
Официально (и на этом сайте тоже) правильный ответ четвертый, т.е. как общий макет или константу.
Но ведь речь опять-таки идёт о хранении в конф-ии, а не в ИБ, как пишет выше г-н Unknown!
Т.е. что-либо хранить в конф-ии посредством константы по его трактовке нельзя!
Где лажа?
Огромное спасибо автору или авторам этого проекта!
Благодарю за полезные статьи.
Внутренняя структура файла конфигурации (*.cf) не является секретом. Добрые люди давно разобрали его и создали немало интересных утилит, позволяющих работать с этим форматом. На Инфостарте найдется добрый десяток (если не больше) интересных публикаций, так или иначе читающих содержимое *.cf файлов, так что тема эта совсем не новая.
Однако, хорошей, добротной документации на этот формат, к сожалению, совсем немного. На написание данной статьи меня надоумила публикация глубокоуважаемого awa, который подробно, во всех деталях описал структуру формата файловой ИБ 1С:Предприятия (*.1CD).
Та статья, как мне кажется, стала катализатором для целого ряда разработок, созданных другими авторами. Открытость и доступность информации подтолкнула творческую активность авторов, а всё сообщество получило ряд отличных инструментов по работе с файловыми базами 1С.
Мне кажется, что подробное описание формата CF тоже сможет заинтересовать многих авторов, и, может быть, мы получим возможность увидеть массу новых интересных разработок на тему файлов конфигурации.
Предыстория
Как уже говорилось выше, структура формата давно известна и в сети есть информация по его структуре (хотя, довольно скудная). Мне эта информация понадобилась п ри разработке программы V8Viewer, работая над которой, я опирался на следующие материалы:
Хочется выразить благодарность авторам, за то, что поделились информацией с народом.
Терминология
Перейдем непосредственно к теме нашего обсуждения.
Для того чтобы расставить точки над i, давайте определимся с названием самого формата.
Во-первых, в этом формате создаются не только файлы конфигурации, но также файлы внешних отчетов и обработок. В интернете мне попадалось название Compound-файл. Возможно, оно является устоявшимся среди старожилов 1С, но мне оно не очень нравится.
Предлагаю в рамках данной статьи называть данный формат «контейнер». Если уважаемая публика подскажет в комментариях правильное название, я буду очень рад.
Смотрим внутрь
Логической единицей хранения данных внутри контейнера является документ. Документ, это осмысленный законченный набор данных, который можно прочитать и каким-то образом интерпретировать. Я специально не пользуюсь термином «файл», поскольку, это название я приберегу для другой сущности, о которой чуть позже.
Итак, в общих чертах, файл CF (EPF/ERF) представляет собой контейнер, в котором хранятся документы.

Каждый документ внутри контейнера может быть разбит на блоки. Минимальной физической единицей хранения данных является блок, но осмысленной логической единицей является документ. Иными словами, документы внутри контейнера могут лежать в виде разрозненных кусочков (блоков) и для того, чтобы прочитать содержимое документа, все его кусочки нужно собрать и объединить.

Структура контейнера
Контейнер включает в себя следующие части (по порядку):
- Заголовок контейнера
- Адрес первого пустого блока, в который можно добавлять данные
- Размер блока по умолчанию
- Количество файлов в контейнере
Для того чтобы прочитать содержимое контейнера, необходимо прочитать документ оглавления. Однако, поскольку, документ состоит из блоков, то прежде необходимо научиться собирать полный документ из этих самых блоков.
Структура блока
Блок состоит из заголовка и тела. В заголовке указывается общий размер всего документа, размер текущего блока и адрес (позиция в файле) следующего блока. Сразу за заголовком идет тело блока – собственно, те данные, которые нам нужны. Тело блока имеет ровно ту длину (в байтах), которая указана в заголовке.
Внутри контейнера тут и там встречается волшебная константа, обозначающая некую «пустоту» – это число 0x7fffffff.
Когда мы собираем документ из блоков, то смотрим в заголовке на адрес следующего блока. Если он равен 0x7fffffff, то «следующего» блока нет, этот – последний.
Константа 0x7fffffff - это значение INT_MAX, т.е. максимальное значение 4-байтового целого числа со знаком.
Логические «файлы»
Я упоминал, что термин «файл» я приберегу до лучших времен. Эти времена настали :)
Вся конфигурация хранится в контейнере в виде файлов. Если мы вспомним школьный курс информатики, то вспомним, что «файл», говорили нам – это именованный документ.
Файл отличается от «документа» тем, что у него есть имя, и по этому имени к нему можно обращаться. Если мы будем разбирать содержимое конфигурации и строить дерево метаданных, то найдем внутри файлов очень много упоминаний других файлов. Процедура чтения конфигурации оперирует именами файлов и ссылается на них по имени.
Если подвести итоги, то можно сказать следующее: в контейнере лежат разные документы, но некоторые из них имеют имя. Такие документы называются «файлы» и они носят не служебный, а непосредственно прикладной характер. Именно файлы хранят информацию о метаданных конфигурации.
Компоненты файла
Каждый файл состоит из двух документов:
- Документ атрибутов, который содержит имя файла и даты создания/изменения
- Документ содержимого, который содержит собственно тело файла
Оглавление контейнера
Теперь, когда все составные части озвучены, осталось рассмотреть, пожалуй, самый главный документ контейнера – документ оглавления, в котором указано расположение всех файлов контейнера. Как говорилось выше, документ оглавления это самый первый документ контейнера и он идет сразу же за заголовком контейнера.
Оглавление представляет собой массив записей, каждая из которых указывает на файл. Поскольку, файл состоит их двух документов (атрибуты и содержимое), то запись оглавления указывает на оба из них. Запись оглавления представляет собой три числа INT32:
- Адрес (смещение в файле) документа атрибутов
- Адрес (смещение в файле) документа содержимого
- Число 0x7fffffff (маркер конца записи).
![]()
Напоминаю, что каждый документ может быть разбит на блоки (фрагментирован). Алгоритм сборки документа из блоков будет рассмотрен ниже.
Запись оглавления представляет собой 2 значащих числа INT32. Первое число – это адрес документа атрибутов файла. По этому адресу мы попадем на начало 1-го блока документа атрибутов. Из документа атрибутов мы можем узнать имя файла. Второе число – адрес документа содержимого файла. По этому адресу мы попадем на начало 1-го блока документа содержимого, откуда будем читать непосредственно данные файла.
Особенности сжатия данных.
Контейнер может содержать самые разные файлы. Как правило, это текстовые файлы в кодировке UTF-8. Однако среди файлов контейнера могут встречаться другие файлы-контейнеры. Проще всего провести аналогию с файловой системой. Контейнер – это директория, а файлы внутри контейнера – это ее содержимое. Директория может содержать другие директории.
Корневой каталог этой «файловой системы» - это сам файл *.CF. Внутри него могут быть другие файлы-контейнеры, по сути – вложенные директории, которые считываются ровно по тому же самому алгоритму и имеют ровно ту же самую структуру.
Тем не менее, есть одна особенность корневой директории. Все документы содержимого файлов внутри корневой директории сжаты по алгоритму Deflate. Содержимое файлов внутри вложенных директорий уже не сжато. Проще говоря, на верхнем уровне файла-контейнера тела всех файлов сжаты, но если файл внутри контейнера сам является контейнером, то внутри него файлы уже будут записаны в чистом виде (без сжатия).
Цепочка свободных блоков
В результате удаления каких-либо данных из контейнера в нем могут образовываться пустые места. Эти свободные места связываются в цепочку и образуют этакий «документ», данные которого отсутствуют. Иными словами, свободные блоки связаны друг с другом по тому же принципу, по которому связаны друг с другом блоки документов. Адрес первого свободного блока указывается в самом начале заголовка контейнера. Если адрес свободного блока равен INT_MAX, то это значит, что в середине контейнера нет свободных (пустых) блоков.
Краткий итог по теоретической части
- Файл CF(EPF/ERF) записан в формате «контейнера»
- Контейнер начинается с заголовка
- Все содержимое контейнера, за исключением заголовка, записано в виде «документов»
- Документ может быть разбит на блоки
- Документ начинается с заголовка блока, по которому можно узнать, как прочитать весь документ целиком
- Сразу за заголовком контейнера идет документ оглавления
- Оглавление, это набор записей, которые указывают на «файлы» внутри контейнера
- Каждый файл состоит из двух документов – документа атрибутов, где указано имя этого файла и документа содержимого, где, собственно, расположены данные файла.
- Каждая запись оглавления содержит 2 адреса. Первый – адрес документа атрибутов файла, второй – адрес документа содержимого.
- Контейнер может содержать вложенные контейнеры (как бы, вложенные папки)
- Файлы внутри корневого контейнера сжаты по алгоритму Deflate, файлы внутри вложенных контейнеров записаны без сжатия.
Давайте уже пощупаем байты
Итак, настало время рассмотреть, как конкретно устроены все упомянутые выше сущности.
Основным способом чтения данных из контейнера является чтение цепочки блоков, составляющих те или иные документы. Кажется, что правильно будет начать с принципа чтения блочных документов.
Чтение документа по блокам
Каждый документ в контейнере обязательно начинается с заголовка блока. При этом документ может быть разбит на несколько блоков. Для того чтобы прочитать документ, необходимо его «собрать» из блоков.
Итак, заголовок блока представляет собой строку длиной 31 байт. Строка эта имеет следующий вид:
[CRLF][Размер всего документа][Пробел][Размер текущего блока][Пробел][Адрес следующего блока] [Пробел] [CRLF], где:
- CRLF – стандартный перевод строки Windows, пара символов \r\n (0x0D,0x0A)
- Размер всего документа – общая длина документа в байтах. Записана в виде строкового представления hex-числа. Длина – 8 байт.
- Пробел – пробел. Символ 0x20
- Размер текущего блока – длина тела блока в байтах. Записана также в виде строкового представления числа INT32 в hex-формате. Если документ состоит из единственного блока, то размер всего документа либо меньше, либо совпадает с размером текущего блока (что логично)
- Адрес следующего блока – адрес по которому расположен очередной блок документа. Если адрес следующего блока равен INT_MAX, то это значит, что следующего блока нет. Адрес следующего блока также записан в виде строкового представления числа.
Сразу за заголовком блока идет тело блока, которое имеет длину, указанную в поле «Размер текущего блока».
![]()
Рассмотрим рисунок: длина всего документа составляет 0x54 байта, красной рамкой выделены эти 0x54 байта. Это данные документа. Длина блока составляет 0x200 байт, т.е. больше чем длина самого документа. По этой причине остальные данные блока составляют "нули" неиспользуемого пространства. Значащие байты - это те, которые отмечены красной рамкой.
Если длина документа больше длины блока, то нужно прочитать следующий блок. Если в поле «Адрес следующего блока» записано значение, отличное от 0x7fffffff, то необходимо считать текущий блок, затем перейти по этому адресу и считать другой блок. Если в этом блоке также будет задан адрес следующего блока, то надо перейти и туда. Таким образом, формируется «цепочка» блоков, из которых состоит документ.
Чтение необходимо продолжать до тех пор, пока в поле «Адрес следующего блока» не встретится значение 0x7fffffff или пока не будет считано количество байт, указанное в поле «Размер всего документа».
Поле «Размер всего документа» имеет смысл только для первого блока. Во всех последующих блоках документа оно имеет значение 0x00000000.
Формат заголовка контейнера
Заголовок контейнера имеет длину 16 байт и состоит из следующих полей:
Поле
Тип
Пояснение
Адрес первого свободного блока
Смещение, по которому начинается цепочка свободных блоков
Размер блока по умолчанию
Блок может иметь произвольную длину, но значение по умолчанию можно использовать для добавления новых блоков, например.
Поле неизвестного назначения (см. комментарии к статье) Часто совпадает с количеством файлов в контейнере
Число, отражающее некоторую величину, как правило, совпадающую с количеством файлов в контейнере, однако, коллеги в комментариях считают, что это не совсем так. На алгоритм интерпретации контейнера данное число никак не влияет, его можно игнорировать.
Всегда равно 0 (всегда ли?)
Формат записи документа оглавления
Оглавление содержит перечень указателей на файлы, размещенные в контейнере
Поле
Тип
Пояснение
Адрес документа атрибутов
Адрес документа атрибутов файла
Адрес документа содержимого
Адрес документа содержимого файлов
Всегда равно 0x7fffffff
Формат документа атрибутов файла
Документ атрибутов описывает имя файла и даты его создания/изменения.
Поле
Тип
Пояснение
Время создания файла
Время создания файла, выраженное в количестве 100-микросекундных интервалов, прошедших с начала нашей эры (01.01.0001 00:00:00)
Время изменения файла
Всегда равно 0. Возможно, это флаги атрибутов, что-то вроде «только чтение», «скрытый» и т.п. Однако, я не встречал файлов, где это поле бы отличалось от нуля.
Строка в формате UTF-16
Занимает все оставшееся тело документа (за вычетом 2-х дат и резервного поля)
![]()
Принцип чтения контейнера
Для того, чтобы прочитать контейнер мы должны сделать следующие вещи:
Чтение оглавления
- Собрать из блоков документ оглавления и прочитать его
- Обойти все записи в документе оглавления и прочитать документы атрибутов (имена) файлов контейнера
- Сопоставить каждому полученному имени адрес документа содержимого
- На выходе получается соответствие «Имя файла» -> «Адрес содержимого»
Чтение файлов
- По имени файла получить из оглавления адрес документа содержимого
- Собрать из блоков документ содержимого
- Если это корневой контейнер, то распаковать документ содержимого (он сжат)
- Готово. Полученный результат является данными искомого файла.
Обновление от 25.02.2014
В статью внесены правки, рекомендованные awa в комментариях.
В заключение
Данная статья не является истиной в последней инстанции, вероятно, в ней есть даже ошибки. Тем не менее, если данная тема Вам интересна, то я надеюсь, что эта статья поможет вам в реализации ваших проектов. Удачи!
![]()
ИНСТРУКЦИЯ 1С 8 → перейти в меню [СТАТЬИ И ИНСТРУКЦИИ]
![]()
*.cf - файл содержит только конфигурацию(код и структура) без пользовательских данных. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Сохранить конфигурацию в файл» или «Конфигурация -> Поставка конфигурации -> Создать файл поставки и обновление конфигурации -> признак «Создать файл поставки»».
*.cfu - файл содержит только обновление конфигурации. Например файл 1cv8.cfu. Создать конфигурацию из этого файла невозможно, так как он содержит в себе только отличия новой конфигурации от предыдущей. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Поставка конфигурации -> Создать файл поставки и обновление конфигурации -> признак «Создать файл обновления конфигурации»».
*.cfe - файл-расширение, предназначенный для доработки конфигурации без её изменения. При использовании расширений 1С (*.cfe) - доработанная конфигурация может полноценно обновляться и с поддержки не снимается.
*.dt - файл содержит конфигурацию вместе с пользовательской базой данных. Это специализированный формат архива 1С 8. Создаётся из конфигуратора 1С 8.х: «Администрирование -> Выгрузить информационную базу».
*.epf (*.erf) – файл внешней обработки (отчёта). Любую обработку (отчёт) из конфигурации можно сохранить внешней. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Открыть конфигурацию -> становимся на нужную обработку (отчёт) -> выделяем правой кнопкой мыши -> Сохранить как внешнюю обработку, отчёт…». Открыть эти файлы в режиме 1С Предприятия 8.3 можно по инструкции .
*.1cd – файл полноценной базы данных. Представление имени по умолчанию: 1Cv8.1CD. Включает в себя конфигурацию, базу данных, пользовательские настройки. Открывается платформой 1С 8.x. Создаётся для разработки новой конфигурации автоматически по кнопке «Добавить» при выборе пункта «Создание новой информационной базы».
*.log, *.lgf, *.lgp, *.elf - лог файлы, которые собирают информацию (регистрируют данные) в 1С 8.0 8.1, 8.2, 8.3. Например, файл 1Cv8.lgf (в каталоге 1Cv8Log ) содержит информацию журнала регистрации.
*. cdn - файл с таким расширением ( 1Cv8.cdn) служит для ручной или автоматической блокировки базы данных 1С Предприятия восьмой версии .
*.mxl - файлы печатных форм используются, в том числе и в 1С. Являются как печатными формами документов, справочников, отчётов, так и различными накопителями данных для различных классификаторов. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый». Так же файлы с такими расширениями могут служить правилами переноса, например, из 1С 7.7 в 8.2 ( acc77_82.xml и вспомогательная обработка exp77_82.ert) - находятся они обычно в папке ExtForms.
*.efd - это архивный файл 1С, используется для установки конфигурации. Содержит или конфигурацию 1с или обновление к ней. Запускается с помощью вспомогательного исполняющего файла setup.exe (должен находиться в одной папке).
*.mft – вспомогательный файл для создания конфигурации из шаблона. Содержит информацию о конфигурации, описание, пути, название. Используется непосредственно самой платформой при создании информационной базы 1С из шаблона.
*.grs - файлы графических схем в специализированном формате 1С. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый».
*.geo - файлы географических схем в специализированном формате 1С. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый».
*.st - файлы шаблонов текстов. Используются в основном 1С разработчиками. Рекомендую для автозамены эти шаблоны кода .
*.pff - файл с сохраненными замерами производительности. Используются системными администраторами и специалистами 1С.
. 1Cv8.pfl - параметры для компьютера/информационной базы/пользователя (в т.ч. пароли пользователей, настройки текстового редактора, настройки глобального поиска по текстам конфигурации, список переменных для быстрого просмотра в отладчике ). Настройки модулей в конфигураторе хранятся в файле 1Cv8.pfl . Этот файл обычно находится в каталоге настроек пользователя C:\Users\<ИмяПользователя>\AppData\Roaming\1C\1cv8.
. 1Cv8cmn.pfl - общие параметры для компьютера, используемые в 1С:Предприятии/Конфигураторе (в т.ч. цвета редактора модулей в конфигураторе )
*.ini - стандартное расширение файла настроек в разных программах. В 1С 8 используется файл nethasp.ini для хранения настроек аппаратного ключа.
![]()
ИНСТРУКЦИЯ 1С 8 → перейти в меню [СТАТЬИ И ИНСТРУКЦИИ]
Иногда программист 1С просит передать ему (переслать по почте) базу данных 1С 8 для выполнения задач. Как сохранить базу данных 1С 8 правильно? Как это оптимально сделать? Какие при этом данные окажутся у получателя?
Сохраняя базу данных таким образом – Вы создаёте архив (копию) со всеми учётными данными предприятия! Поэтому пересылая созданный архив третьим лицам, Вы должны чётко осознавать, что передаёте получателю полную копию базы данных.
1. Запускаем 1С Предприятие 8 в режиме "Конфигуратор", предварительно выделив нужную информационную базу.
![]()
2. Если необходимо, выбираем пользователя с правами администратора и вводим пароль. Проходим авторизацию.
![]()
3. В открывшемся окне программы - в меню: Администрирование выбираем пункт "Выгрузить информационную базу. "
![]()
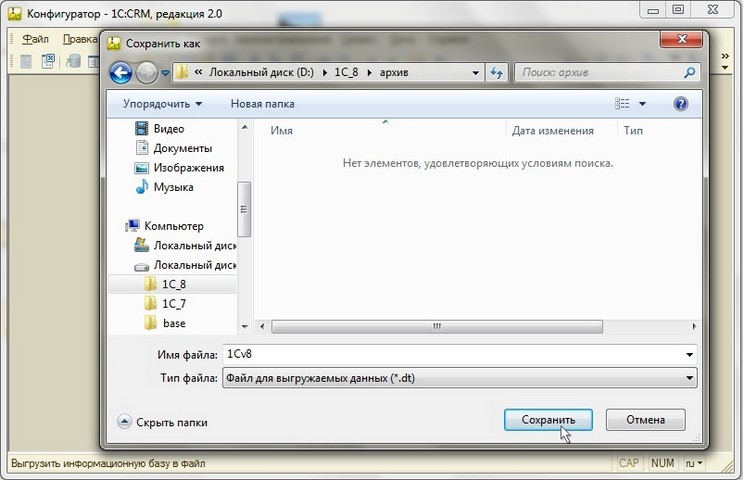
4. В следующем окне программы, у нас есть возможность выбрать путь (куда будет сохранена база) и задать имя файла (интуитивно понятное).
![]()
5. После нажатия на кнопку "Сохранить" в нижнем левом углу появиться информационная надпись "Выгрузка информационной базы. ", свидетельствующая о процессе выгрузки. Ждём.
![]()
6. Когда выгрузка будет завершена - программа выдаст соответствующее предупреждение. Его нужно закрыть по кнопке "ОК". Можно закрыть и окно самой программы 1С.
![]()
7. Теперь можем с помощью проводника зайти в директорию (папку) для выгрузки базы, которую выбрали на 4-м этапе. И убедиться, что она там есть.
![]()
Готово! Файл 1Cv8.dt содержит конфигурацию и всю учётную информацию. В зависимости от цели создания архива - его можно передать по почте (прикрепив файл к письму), сохранить на внешний накопитель (USB, CD, DVD), восстановить в копию (папку) базы данных и т.д.
Читайте также: