
В каком формате файла экономичнее всего хранить информацию вес файла будет минимальным
Подскажите, пожалуйста, какой формат выбрать для хранения текстовых данных большого объема. Он должен соответствовать следующим критериям (хотя бы 3 из 5). Критерии идут в порядке приоритета:
- Удобное представление структуры данных (вложенность данных может быть произвольной глубины)
- Поддержка библиотеками python (конвертирование, парсинг)
- Быстрый и маленький (парсинг, загрузка в БД)
- Удобное распространение (скачивание, отправка по сети)
- Человекочитаемый вид (возможность чтение и редактирования напрямую человеком)
Рассматриваю форматы - CSV, XML, JSON. Буду благодарен советам по выбору из указанных форматов или вашим предложениям.
UPD. Немного уточнений к вопросу. Почему озаботился выбором формата?
Собрал большой объем данных для своего проекта (инженерные и научные данные).
Встала задача по их структурированию и хранению, вдруг кому-то пригодится информация, а я смогу ему передать. Следовательно, человекоподобный вид будет весьма кстати.
Кроме того, полученных данные нужно импортировать в базу данных, в моем случае PostgresQL, и любой человек, который принял мои текстовые данные, может сделать то же самое в любую удобную ему БД
В порядке убывания предпочтения: json, xml, csv. У json меньше накладные расходы (компактнее), xml уже несколько лет подряд теряет популярность среди программистов. Оба формата можно валидировать. Поддержка уже проникает и в СУБД, от майкрософт по крайней мере.
Проще, чем CSV с экранированием разделителей вы не найдёте. И редактировать его можно любым табличным редактором. А вопрос подлежит закрытию, т. к. из серии "посоветуйте мне <. >".
Возможно стоит сразу структурировать в базе данных (реляционная, колоночная, графовая, документоориентированная . под задачу), с нужными связями, быстрой выборкой. Сомнительно что кто-то быстро сможет разобраться если связи не явно описаны даже в человекочитаемом формате. sql дамп тоже легко редактировать редактором. Из базы экспорт в csv, json легче чем наоборот.
1 ответ 1
итак, включаем голову:
одни и те же данные в csv, json:
csv: (вместо \t будет |)
сравните длину строчек. У кого больше? у JSON.
JSON/XML удобны тем, что структурированы, могут описать схему данных. CSV удобен тем, что очень компактен, минимальные расходы на парсинг.
любой не бинарный формат человек может редактировать очень легко. некоторые бинарные форматы достаточно просты, чтобы их можно было редактировать в hex-редакторе, особенно, если вы привыкли.
официально JSON поддерживает ТОЛЬКО UTF-8. CSV может быть в любой кодировке.
если у вас очень сложные данные, сильно связанные, данные, которые трудно представить в виде одной-двух таблиц, возможно, вам следует присмотреться к json/xml.
Если вы просто заливаете тексты в бд, экспортируете их, csv вполне справится.
В целом-то это вопрос выбора временного формата - формата для экспорта или трансляции по сети, во внешние системы (никто не хранит данные в csv/json/xml в качестве основного онлайн-хранилища)
Если у вас очень большие прямо тексты, храните их в текстовых файлах и в базе данных, а в csv/json/xml давайте ссылки на файлы. Структура усложняется, но и редактировать человеку проще.
Зато разница между форматами нивелируется. Короче, как всегда, все зависит от архитектуры и задач.

Зачем нужны разные форматы файлов
Серьезное узкое место в производительности приложений с поддержкой HDFS, таких как MapReduce и Spark — время поиска, чтения, а также записи данных. Эти проблемы усугубляются трудностями в управлении большими наборами данных, если у нас не фиксированная, а эволюционирующая схема, или присутствуют некие ограничения на хранение.
Обработка больших данных увеличивает нагрузку на подсистему хранения — Hadoop хранит данные избыточно для достижения отказоустойчивости. Кроме дисков, нагружаются процессор, сеть, система ввода-вывода и так далее. По мере роста объема данных увеличивается и стоимость их обработки и хранения.
Различные форматы файлов в Hadoop придуманы для решения именно этих проблем. Выбор подходящего формата файла может дать некоторые существенные преимущества:
- Более быстрое время чтения.
- Более быстрое время записи.
- Разделяемые файлы.
- Поддержка эволюции схем.
- Расширенная поддержка сжатия.
Формат файлов Avro
Для сериализации данных широко используют Avro — это основанный на строках, то есть строковый, формат хранения данных в Hadoop. Он хранит схему в формате JSON, облегчая ее чтение и интерпретацию любой программой. Сами данные лежат в двоичном формате, компактно и эффективно.
Ключевой особенностью Avro является надежная поддержка схем данных, которые изменяются с течением времени, то есть эволюционируют. Avro понимает изменения схемы — удаление, добавление или изменение полей.
Avro поддерживает разнообразные структуры данных. Например, можно создать запись, которая содержит массив, перечислимый тип и подзапись.

Этот формат идеально подходит для записи в посадочную (переходную) зону озера данных (озеро данных, или data lake — коллекция инстансов для хранения различных типов данных в дополнение непосредственно к источникам данных).
Так вот, для записи в посадочную зону озера данных такой формат лучше всего подходит по следующим причинам:
- Данные из этой зоны обычно считываются целиком для дальнейшей обработки нижестоящими системами — и формат на основе строк в этом случае более эффективен.
- Нижестоящие системы могут легко извлекать таблицы схем из файлов — не нужно хранить схемы отдельно во внешнем мета-хранилище.
- Любое изменение исходной схемы легко обрабатывается (эволюция схемы).
Формат файлов Parquet
Parquet — опенсорсный формат файлов для Hadoop, который хранит вложенные структуры данных в плоском столбчатом формате.
По сравнению с традиционным строчным подходом, Parquet более эффективен с точки зрения хранения и производительности.
Это особенно полезно для запросов, которые считывают определенные столбцы из широкой (со многими столбцами) таблицы. Благодаря формату файлов читаются только необходимые столбцы, так что ввод-вывод сводится к минимуму.
Небольшое отступление-пояснение: чтобы лучше понять формат файла Parquet в Hadoop, давайте посмотрим, что такое основанный на столбцах — то есть столбчатый — формат. В таком формате вместе хранятся однотипные значения каждого столбца.
Например, запись включает поля ID, Name и Department. В этом случае все значения столбца ID будут храниться вместе, как и значения столбца Name и так далее. Таблица получит примерно такой вид:
| ID | Name | Department |
| 1 | emp1 | d1 |
| 2 | emp2 | d2 |
| 3 | emp3 | d3 |
Столбчатый формат более эффективен, когда вам нужно запросить из таблицы несколько столбцов. Он прочитает только необходимые столбцы, потому что они находятся по соседству. Таким образом, операции ввода-вывода сводятся к минимуму.
Например, вам нужен только столбец NAME. В строковом формате каждую запись в наборе данных нужно загрузить, разобрать по полям, а затем извлечь данные NAME. Столбчатый формат позволяет перейти непосредственно к столбцу Name, так как все значения для этого столбца хранятся вместе. Не придется сканировать всю запись.
Таким образом, столбчатый формат повышает производительность запросов, поскольку для перехода к требуемым столбцам требуется меньше времени поиска и сокращается количество операций ввода-вывода, ведь происходит чтение только нужных столбцов.
Одна из уникальных особенностей Parquet заключается в том, что в таком формате он может хранить данные с вложенными структурами. Это означает, что в файле Parquet даже вложенные поля можно читать по отдельности без необходимости читать все поля во вложенной структуре. Для хранения вложенных структур Parquet использует алгоритм измельчения и сборки (shredding and assembly).

Чтобы понять формат файла Parquet в Hadoop, необходимо знать следующие термины:

Здесь заголовок просто содержит волшебное число PAR1 (4 байта), которое идентифицирует файл как файл формата Parquet.
В футере записано следующее:
- Метаданные файла, которые содержат стартовые координаты метаданных каждого столбца. При чтении нужно сначала прочитать метаданные файла, чтобы найти все интересующие фрагменты столбцов. Затем фрагменты столбцов следует читать последовательно. Еще метаданные включают версию формата, схему и любые дополнительные пары ключ-значение.
- Длина метаданных (4 байта).
- Волшебное число PAR1 (4 байта).
Формат файлов ORC
Оптимизированный строково-столбчатый формат файлов (Optimized Row Columnar, ORC) предлагает очень эффективный способ хранения данных и был разработан, чтобы преодолеть ограничения других форматов. Хранит данные в идеально компактном виде, позволяя пропускать ненужные детали — при этом не требует построения больших, сложных или обслуживаемых вручную индексов.
Преимущества формата ORC:
- Один файл на выходе каждой задачи, что уменьшает нагрузку на NameNode (узел имен).
- Поддержка типов данных Hive, включая DateTime, десятичные и сложные типы данных (struct, list, map и union).
- Одновременное считывание одного и того же файла разными процессами RecordReader.
- Возможность разделения файлов без сканирования на наличие маркеров.
- Оценка максимально возможного выделения памяти кучи на процессы чтения/записи по информации в футере файла.
- Метаданные сохраняются в бинарном формате сериализации Protocol Buffers, который позволяет добавлять и удалять поля.

ORC хранит коллекции строк в одном файле, а внутри коллекции строчные данные хранятся в столбчатом формате.
Файл ORC хранит группы строк, которые называются полосами (stripes) и вспомогательную информацию в футере файла. Postscript в конце файла содержит параметры сжатия и размер сжатого футера.
По умолчанию размер полосы составляет 250 МБ. За счет полос такого большого размера чтение из HDFS выполняется более эффективно: большими непрерывными блоками.
В футере файла записан список полос в файле, количество строк на полосу и тип данных каждого столбца. Там же записано результирующее значение count, min, max и sum по каждому столбцу.
Футер полосы содержит каталог местоположений потока.
Строчные данные используются при сканировании таблиц.
Индексные данные включают минимальные и максимальные значения для каждого столбца и позиции строк в каждом столбце. Индексы ORC используются только для выбора полос и групп строк, а не для ответа на запросы.
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
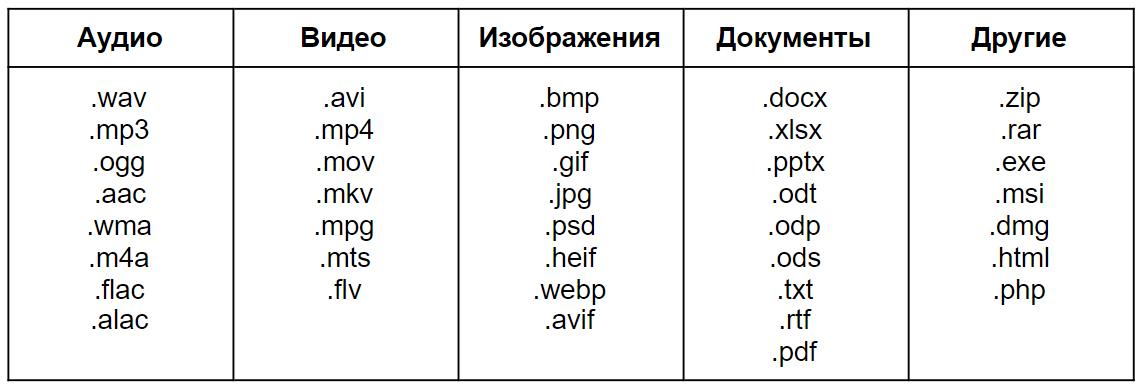
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Ни для кого не является секретом, что мы все стараемся хранить большинство документов и важные текстовые данные в электронном виде. Благо оборот электронных документов в стране растет, за что отдельная благодарность руководству нашей страны, которая внедрив электронный документооборот на сайтах государственных структур заставила всех остальных "подтягиваться" в вопросе электронного документооборота. Пожалуй, это тот редкий случай, когда государство задало тренд в нужном направлении и показала действительно хороший пример как для бизнеса, так и Рунета в целом. Так в каком формате лучше же хранить текстовые документы?
Наиболее популярным форматом для объемных документов является PDF файл. О том как создать PDF файл написано немало статей в Интернете, поэтому отдельно на данном вопросы мы останавливаться не будем. Лишь отметим, что PDF файл по размеру достаточно массивный, что усложнит его "облачное использование" через мобильные устройтсва, так как мобильный интернет хоть и быстрее день ото дня - до уровня кабельных соединений ему еще далеко.
Более компактным форматом для текстовых документов является DJVU формат. Зачастую большинство текстовых PDF файлов в десять и более раз ужимаются при их переводе в DJVU. При этом эффективность сжатия данных одинакова как для цветных, так и черно-белых данных. Единственный минус - при необходимости изъятия текста из DJVU файла - простое выделение и копирование недоступно - вам придется извлекать текст путем дополнительных манипуляций, что описано в отдельных статьях в Интернете.

Формат TIFF был популярен на заре появления сканеров. На сегодняшний день его можно считать устаревшим, так как явных преимуществ перед другими форматами у него нет.
Файлы MS Word DOC (DOCX) или RTF интересны своей универсальностью - они читаются практически любым устройством, а их содержимое в виде документа понятно для большинства из нас. Большой размер файлов можно устранить путем их архивации архиваторами RAR или ZIP. Степень сжатия конечно будет ниже, чем у формата DJVU, но зато вы сохраняете все преимущества документа перед обычным фотографическим изображением.
Мини-ПК Minisforum Elitemini B550 поступает в продажу…
Представленный в феврале мини-ПК Minisforum Elitemini B550 поступает в продажу, с другими характеристикам…
Обзор моноблока Acer Aspire C27-1655. Тесты домашней рабочей…
Тестируемый сегодня моноблок Acer Aspire C27-1655, работающий на базе операционной системы Windows, ориен…
Продажи PlayStation 5 оставляют желать лучшего…
Sony объявила, что в прошлом квартале (Q4) было продано всего 2 миллиона единиц PlayStation 5, в результа…
Epson выпустила проектор Pro Cinema 4K PRO-UHD LS12000…
Компания Epson представила новый длиннофокусный лазерный проектор, который обеспечивает заявленное беском…
Elgato представила Key Light Mini…
Если вы хотите выглядеть лучше во время видеозвонка или в любом виде видео, разумным шагом будет вложение…
Сервисы Microsoft не работали все выходные…
Из-за сбоя Xbox Live некоторые игроки не могли запускать облачные игры, играть в свои цифровые версии игр…
В Steam должны добавить Game Pass от Microsoft…
Компания Valve официально заявляет, что готова сотрудничать с Microsoft, чтобы перенести PC Game Pass в S…
Приветствую друзья! В нашей жизни мы постоянно сталкиваемся с изображениями, при фотографировании, создании сайта, сканировании, печати. Какой формат изображения лучше спросите Вы.
От формата, в котором сохранен файл зависит качество изображения, удобство его дальнейшего редактирования.
С развитием компьютеров и интернета появлялись новые форматы для записи изображений в файлы. Каждый формат имеет свои преимущества и недостатки.
В этой статье я решил попробовать разобраться какой формат изображения лучше и рассказать о наиболее распространенных форматах графических - JPEG, TIFF, PNG, и GIF.
Какой формат изображения лучше?
Формат JPEG
Цифровые камеры и веб-страницы обычно используют JPEG файлы — его алгоритм очень хорошо сжимает данные и итоговый файл получается небольшой. Однако JPEG использует алгоритм сжатия с потерями, что может явится сильным недостатком.

Формат JPEG для цифровых камер
Небольшой размер файла JPEG идет в ущерб качеству изображения. Степень сжатия можно устанавливать в настройках графических программ — ниже качество меньше файл изображения и наоборот чем выше качество тем большим размером получается файл.
JPEG почти единственный формат, который использует сжатие с потерями, позволяющий делать небольшие файлы более низкого качества. Есть режим сжатия без потерь — lossless JPEG.
Данный формат используется в случаях когда небольшой размер файла более важен, чем максимальное качество изображения (оптимизированное изображения для сайта, электронная почта, перенос на картах памяти и т.д.). Формат JPEG достаточно хорош для большинства случаев, главное не переусердствовать в сжатии.
Всегда помните что повторное редактирование файла формата JPEG ухудшает качество картинки, появляются артефакты, потому рекомендую всегда сохранять оригиналы изображений, которые в дальнейшем можно сжать.
Формат TIFF
Формат без потерь используемый для растровых изображений, считается самым лучшим форматом для коммерческой работы. Он применяется при сканировании, в полиграфии для качественной печати, распознавании текста, отправке факсов. Файлы в формате TIFF имеют значительно больший размер чем их аналоги в JPEG, и могут быть записаны без сжатия либо со сжатием без потерь.
Формат TIFF позволяет сохранять несколько слоев, что очень удобно при дальнейшем редактировании, и в отличии от JPEG может иметь разрядность 8 или 16 на канал. TIFF является наиболее универсальным, и как правило используется для хранения оригиналов изображений, которые в дальнейшем можно редактировать. Но имейте в виду что браузеры не отображают TIFF файлы.
Формат GIF
Глубиной цвета данный формат нас не радует, всего 8 бит (256 цветов максимум) и использовать его для хранения фотографий не рекомендуется (фото имеют 24 битную глубину цвета).
Данный формат поддерживает анимацию изображений, которая выражается в смене статичных картинок через определенный промежуток времени, которой можно задавать. Анимацию можно делать цикличной, что с успехом применяется при изготовлении банеров и аватарок.
Формат PNG
Был создан сравнительно недавно для замены устаревшего GIF (браузеры показывают оба формата), и в некоторой степени более сложного TIFF формата. PNG является растровым форматом с использованием сжатия без потерь, не поддерживает анимацию и может иметь 48 битную глубину цвета.
Одно из преимуществ данного формата — можно указать уровень прозрачности для каждой точки, что позволяет делать плавные переходы из четкого изображения в фон. Основным применением является использование в интернет и редактирование графики.
Типов файлов в зависимости от цели использования:
Итоги
Какой какой формат изображения лучше и как выбрать тип файла в зависимости от области использования:
- Лучшая компрессия — с потерями для маленьких файлов — JPEG, или без потерь для наилучшего качества изображений — TIFF и PNG
- Полноцветный RGB для фотографий — TIFF, PNG, JPEG
- Прозрачность или анимация для использования в графике — GIF и PNG
- Документы, штриховые рисунки, многостраничные текстовые, факс, и т.д. — TIFF
- Полиграфия где используется цветовая модель CMYK — TIFF
Естественно что в данном списке приведены не все форматы графических изображений, их намного больше, но в повседневной жизни обычно используются только эти.
Так как Вы заинтересовались форматом изображений и их отличиями, могу предположить, что одна из Ваших сфер деятельности связана с сайтами или лендингами. Рекомендую Вашему вниманию бесплатную книгу «Анатомия продающих лендингов». Очень полезная книга из которой Вы узнаете:
- 4 элемента первого экрана продающего лендинга
- 3 простые и работающие формулы продающего заголовка
- анатомия конверсионной страницы
Скачивайте книгу «Анатомия продающих лендингов» и применяйте на практике полученные знания.
P.S. Для тех, кто хочет узнать про новые изобретения и быть причастным к инновационным технологиям рожденным в России, читайте статью Мотор-колесо Дуюнова.
Читайте также: