
Увеличить размер кучи visual studio
Как можно увеличить максимальный объем памяти, выделяемый в стеке / куче для программы на C ++?
Будет ли увеличение оперативной памяти вашего компьютера автоматически увеличивать объем стека / кучи памяти компьютерной программы?
Решение
Другие решения
Вы можете указать зарезервированный размер кучи и размер стека с помощью параметров ссылок / Куча и / Стек в Visual Studio. Для получения дополнительной информации проверьте эти статьи MSDN:
Второе редактирование: Из вашего комментария я вижу, что вы работаете в Windows, поэтому мой ответ по Unix, приведенный ниже, не будет для вас очень полезным. Но смотри Определение стекового пространства с помощью Visual Studio а также C / C ++ максимальный размер стека программы .
стек Размер часто ограничен в Linux. Команда ulimit -s выдаст текущее значение в килобайтах. Вы можете изменить значение по умолчанию (обычно) в файле /etc/security/limits.conf.
Вы также можете, в зависимости от привилегий, изменить его для каждого отдельного процесса, используя setrlimit() , Смотри например мой ответ в Ошибка сегментации: выделение стека в программе на C в Ubuntu при буферизации>4M .
За куча, см. например Ограничение размера кучи в C . Но я не верю, что вы можете увеличить или уменьшить максимальный размер.
Размер кучи процесса обычно ограничен максимальной памятью, которую процесс может выделить. Куча не обязательно должна быть смежной (если вы не делаете что-то вроде malloc (1000000000)), чтобы куча могла использовать большую часть доступного адресного пространства.
В Windows максимальный размер процесса зависит от нескольких факторов.
При использовании 32-битной Windows 32-битный процесс может по умолчанию выделить 2 ГБ.
Если Windows загружается с помощью параметра / 3GB, а процесс компилируется с использованием флага компоновщика «Включить большие адреса», то процесс может выделить 3 ГБ.
При использовании 64-битной Windows 32-битный процесс по умолчанию может выделить 2 ГБ.
Если процесс связан с «Включить большие адреса», то 64-разрядная Windows позволяет 32-разрядному процессу выделять 4 ГБ.
64-битный процесс (в 64-битной Windows) может выделить что-то вроде 16 000 ГБ.
У меня возникли проблемы с памятью с кучей по умолчанию и резервным размером стека 1 МБ. Но когда я установил выше свойства 2 МБ (2000000), он работает нормально.
Чтобы установить эти свойства в среде разработки Visual Studio, выполните следующие действия.
Как объект оказывается в куче больших объектов
Если размер объекта больше или равен 85 000 байт, он считается большим объектом. Это число рассчитано путем настройки производительности. Если запрашивается выделение 85 000 или более байтов, среда выполнения отправляет объект в кучу больших объектов.
Чтобы понять, что это значит, давайте рассмотрим основные принципы работы сборщика мусора.
Сборщик мусора работает по поколениям. Он имеет три поколения: поколение 0, поколение 1 и поколение 2. Причина возникновения трех поколений состоит в том, что в хорошо настроенном приложении большинство объектов всgen0ся в память. Например, в серверном приложении выделения памяти, связанные с каждым запросом, должны исчезнуть после завершения запроса. Находящиеся в пути запросы на выделение памяти достигнут поколения 1 и умрут там. По сути, поколение 1 служит буфером между областями молодых объектов и областями долгоживущих объектов.
Вновь распределенные объекты образуют новое поколение объектов и неявно являются сборками поколения 0. Однако если это большие объекты, то они попадают в кучу больших объектов, которая иногда называется поколением 3. Поколение 3 — это физическое поколение, которое логически собирается как часть поколения 2.
Большие объекты принадлежат к поколению 2, поскольку они собираются только при сборке поколения 2. При сборке поколения собираются и все предыдущие поколения. Например, когда происходит сборка мусора поколения 1, собираются поколения 1 и 0. А когда происходит сборка мусора поколения 2, собирается вся куча. Поэтому сборка мусора поколения 2 также называется полной сборкой мусора. В этой статье используется термин "сборка мусора поколения 2", а не "полная сборка мусора", но эти термины равнозначны.
Поколения обеспечивают логическое представление кучи сборки мусора. На физическом уровне объекты существуют в управляемых сегментах кучи. Управляемый сегмент кучи — это блок памяти, который сборщик мусора резервирует в ОС через вызов функции VirtualAlloc от имени управляемого кода. При загрузке CLR сборка мусора выделяет два первоначальных сегмента кучи: один для маленьких объектов (куча маленьких объектов, или SOH) и один для больших объектов (куча больших объектов, или LOH).
После этого запросы на выделение памяти удовлетворяются путем размещения управляемых объектов в одном из этих сегментов управляемой кучи. Если объект меньше 85 000 байтов, он будет помещен в сегмент SOH. В противном случае он помещается в сегмент LOH. Память из сегментов выделяется (блоками) по мере того, как в них помещается все больше объектов. В куче маленьких объектов объекты, пережившие сборку мусора, переходят в следующее поколение. Объекты, пережившие сборку мусора поколения 0, считаются объектами поколения 1 и так далее. Однако объекты, пережившие сборку мусора последнего поколения, по-прежнему будут относиться к этому поколению. Другими словами, выжившие из поколения 2 — это объекты поколения 2; а выжившие из кучи больших объектов — это объекты кучи больших объектов (которые собираются с поколением 2).
Пользовательский код может размещать объекты только в поколении 0 (маленькие объекты) или в куче больших объектов (большие объекты). Только сборщик мусора может "выделить" объекты в поколении 1 (путем повышения выжившие объекты поколений из поколения 0) и поколения 2 (путем повышения выжившие объекты поколений из поколения 1).
При запуске сборки мусора сборщик мусора отслеживает живые объекты и сжимает их. Но поскольку сжатие требует большого количества ресурсов, сборщик мусора сметает кучу больших объектов, составляя свободный список из мертвых объектов, которые можно повторно использовать позднее для удовлетворения запросов на выделение памяти для больших объектов. Смежные мертвые объекты превращаются в один свободный объект.
На рис. 1 проиллюстрирована ситуация, где сборщик мусора формирует поколение 1 после первого поколения 0, где объекты Obj1 и Obj3 мертвы; и он формирует поколение 2 после первого поколения 1, где объекты Obj2 и Obj5 мертвы. Это и следующие изображения приводятся только для иллюстрации; они содержат мало объектов, чтобы продемонстрировать происходящее в куче. На самом деле сборщик мусора обрабатывает гораздо больше объектов.
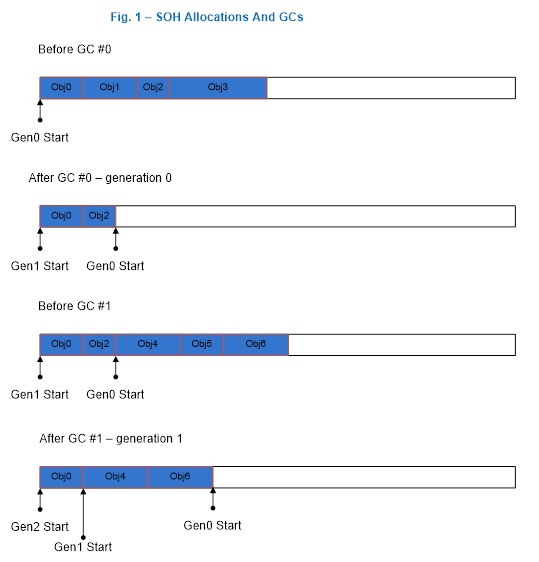
Рис. 1. Сборка мусора поколения 0 и поколения 1.
На рис. 2 показано, что после сборки мусора поколения 2, которая покажет, что Obj1 и Obj2 не существует, сборщик мусора формирует непрерывное свободное пространство для памяти, которое использовалось Obj1 и Obj2 было использовано для удовлетворения запроса Obj4 на выделение. Пространство после последнего объекта Obj3 и до конца сегмента все еще может быть использовано для удовлетворения дальнейших запросов на выделение памяти.

Рис. 2. После сборки мусора поколения 2
Если свободного пространства недостаточно для выполнения запросов на выделение памяти для больших объектов, сборщик мусора пытается получить дополнительные сегменты от ОС. Если это не удается, он инициирует сборку мусора поколения 2 в надежде освободить место.
В ходе сборки мусора поколения 1 или 2 сборщик мусора отдает ОС сегменты, в которых нет живых объектов (вызывая функцию VirtualFree). Свободное место после последнего живого объекта до конца сегмента освобождается (за исключением временных сегментов с объектами поколения 0 и 1, в которых сборщик мусора сохраняет свободное пространство, поскольку вскоре приложение будет размещать в него объекты). И свободные пространства остаются зафиксированными, хотя сбрасываются, а это означает, что ОС не требуется записывать данные обратно на диск.
Поскольку куча больших объектов собирается только во время сборки мусора поколения 2, сегмент этой кучи можно освободить только во время этой сборки мусора. На рисунке 3 показан сценарий, где сборщик мусора возвращает ОС один сегмент (сегмент 2) и освобождает дополнительное место в оставшихся сегментах. Если освободившееся пространство в конце сегмента необходимо использовать для удовлетворения запросов на выделение памяти для большого объекта, он фиксирует память снова. (Дополнительные сведения о фиксации и освобождении см. в документации по VirtualAlloc.
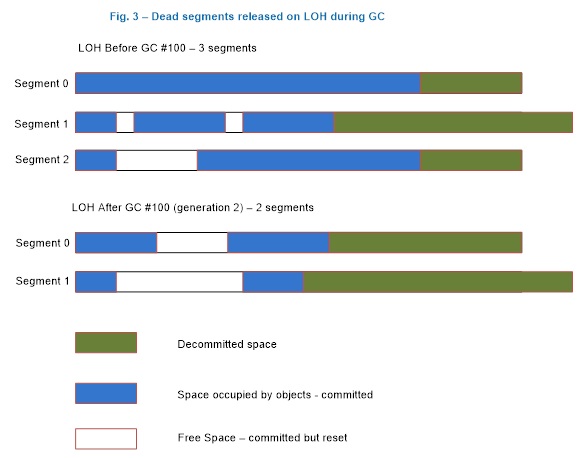
Рис. 3. Куча больших объектов после сборки мусора поколения 2
Когда собираются большие объекты?
Как правило, сборка мусора происходит при выполнении одного из следующих трех условий:
Выделение памяти превышает пороговое значение для поколения 0 или больших объектов.
Пороговое значение является свойством поколения. Пороговое значение для поколения задается, когда сборщик мусора распределяет в него объекты. При превышении порогового значения для этого поколения происходит сборка мусора. При выделении мелких или больших объектов используются пороговые значения для поколения 0 и LOH соответственно. Когда сборщик мусора распределяет объекты в поколения 1 и 2, учитываются соответствующие пороговые значения. Эти пороговые значения динамически настраиваются в ходе работы программы.
Это типичный случай. Как правило, сборка мусора происходит в связи с распределениями в управляемой куче.
Если вызывается метод GC.Collect() без параметров или другая перегрузка передается GC.MaxGeneration как аргумент, сборка мусора в куче больших объектов происходит одновременно со сборкой мусора в управляемой куче.
В системе недостаточно памяти.
Это происходит, когда сборщик мусора получает от ОС уведомление верхней памяти. Если сборщик мусора считает, что сборка мусора поколения 2 будет продуктивной, он запускает ее.
Влияние кучи больших объектов на производительность
Распределение в куче больших объектов влияет на производительность следующим образом.
Затраты на распределение.
CLR гарантирует очистку памяти для каждого выдаваемого им нового объекта. Это означает, что стоимость распределения для большого объекта определяется очисткой памяти (если только он не запускает GC). Если для очистки одного байта требуется два цикла, для очистки наименьшего большого объекта требуется 170 000 циклов. Очистка памяти объекта размером 16 МБ на компьютере с тактовой частотой 2 ГГц занимает примерно 16 мс. Это довольно большие затраты.
Затраты на сбор.
Поскольку куча больших объектов и поколение 2 собираются вместе, при превышении порогового значения для любого из них запускается сборка мусора поколения 2. Если сборка поколения 2 была запущена из-за кучи больших объектов, то само поколение 2 необязательно значительно уменьшится после сборки мусора. Если в поколении 2 не так много данных, влияние минимально. Но если поколение 2 большое, запуск многочисленных сборок мусора поколения 2 может вызвать проблемы с производительностью. Если много больших объектов выделяется на временной основе и имеется большое состояние работоспособности, вы можете потратить слишком много времени на выполнение GC. Кроме того, затраты на распределение могут нарастать, если вы и дальше будете распределять и освобождать очень большие объекты.
Элементы массива со ссылочными типами.
Очень большие объекты в куче обычно являются массивами (очень большие объекты-экземпляры весьма редки). Если элементы массива имеют много ссылок, затраты выше, чем для элементов с небольшим количеством ссылок. Если элемент не содержит никаких ссылок, сборщику мусора не нужно проходить по всему массиву. Например, если массив используется для хранения узлов в двоичном дереве, одним из способов его реализации является обращение к правому и левому узлу узла фактическим узлам:
Если num_nodes является большим, сборщик мусора должен обработать как минимум две ссылки на элемент. Другой подход состоит в сохранении индекса правого и левого узла:
Вместо того, чтобы ссылаться на данные левого узла как left.d , вы ссылаетесь на него как binary_tr[left_index].d . Сборщику мусора не нужно просматривать ссылки на левый и правый узлы.
Из трех факторов первые два обычно важнее, чем третий. По этой причине рекомендуется распределять пул больших объектов, которые можно использовать повторно, вместо распределения временных.
Сбор данных производительности для кучи больших объектов
Прежде чем собирать данные производительности для определенной области, вы должны выполнить следующие действия:
Найти свидетельство, которое нужно учитывать в этой области.
Исследовать другие известные области и не найти в них причину проблемы с производительностью.
Дополнительные сведения об основах памяти и ЦП см. в блоге, посвященном этой проблеме, прежде чем пытаться найти решение.
Для сбора данных о производительности кучи больших объектов можно использовать следующие средства:
Использование счетчиков памяти обычно является хорошим первым этапом поиска проблем с производительностью (хотя мы рекомендуем использовать События трассировки Windows). Чтобы настроить монитор производительности, добавьте нужные счетчики, как показано на рисунке 4. К куче больших объектов относятся следующие счетчики:
Число сборок мусора поколения 2
Показывает количество сборок мусора поколения 2 с момента запуска процесса. Этот счетчик увеличивает число в конце сборки мусора поколения 2 (иначе называемой полной сборкой мусора). Этот счетчик отображает последнее значение.
Размер кучи для массивных объектов
Отображает текущий размер кучи больших объектов в байтах, включая свободное пространство. Этот счетчик обновляется в конце сборки мусора, не при каждом выделении памяти.
Распространенным средством просмотра счетчиков производительности является монитор производительности (perfmon.exe). Используйте "Добавить счетчики", чтобы добавить интересный счетчик для интересующих вас процессов. Данные счетчика производительности можно сохранить в файле журнала, как показано на рисунке 4.

Рис. 4. LOH после сборки мусора поколения 2
Счетчики производительности также можно запросить программно. Многие собирают эти данные таким способом в рамках рутинного процесса тестирования. При обнаружении счетчиков с необычными значениями можно использовать другие способы получения подробностей, чтобы помочь расследованию.
Рекомендуется использовать события трассировки событий Windows вместо счетчиков производительности, так как трассировка событий Windows предоставляет гораздо больше сведений.
ETW-события
Сборщик мусора предоставляет широкий набор событий трассировки событий Windows, помогая разобраться в функциях кучи. В следующих записях блога описывается, как собирать и интерпретировать события сборки мусора с помощью трассировки событий Windows:
Чтобы выявить чрезмерную сборку мусора поколения 2, вызванную временными распределениями кучи больших объектов, ищите сборку мусора в столбце "Причина активации". Чтобы провести простой тест и распределить только временные большие объекты, соберите информацию о событиях трассировки событий Windows с помощью следующей командной строки PerfView:
Результат будет выглядеть примерно следующим образом:

Рис. 5. события ETW, отображаемые с помощью PerfView
Как видите, все сборки мусора относятся к поколению 2 и активируются функцией AllocLarge. Это означает, что эта сборка мусора вызвана распределением большого объекта. Мы знаем, что эти распределения являются временными, так как в столбце % выживания LOH значится 1 %.
Можно собирать дополнительные события трассировки событий Windows, которые показывают, кто распределил эти большие объекты. Следующая командная строка:
собирает событие Аллокатионтикк, которое инициируется приблизительно для каждого выделяемого количества 100 КБ. Другими словами, событие возникает при каждом выделении памяти для большого объекта. Затем можно просмотреть одно из представлений выделения кучи GC, которое показывает стеки вызовов, где распределены большие объекты:

Рис. 6. Представление выделения кучи GC
Как видите, это очень простой тест, который выделяет память для большого объекта из метода Main .
Отладчик
Команды отладки, описанные в этом разделе, применимы к отладчикам Windows.
Ниже приведен пример выходных данных анализа кучи больших объектов:
Размер кучи больших объектов равен (16 754 224 + 16 699 288 + 16 284 504) = 49 738 016 байт. Между адресами 023e1000 и 033db630, 8 008 736 байт загружаются массивом System.Object объектов, 6 663 696 байт занят массивом System.Byte объектов, а 2 081 792 байт — свободным пространством.
Иногда в отладчике общий размер кучи больших объектов менее 85 000 байт. Дело в том, что сама среда выполнения использует кучу больших объектов для размещения некоторых объектов, которые меньше большого объекта.
Поскольку куча больших объектов не сжимается, иногда она считается источником фрагментации. Фрагментация означает:
Фрагментация управляемой кучи, на которую указывает объем свободного пространства между управляемыми объектами. В SoS команда !dumpheap –type Free отображает объем свободного пространства между управляемыми объектами.
Фрагментация диапазона адресов виртуальной памяти. Это память, помеченная как MEM_FREE . Ее можно получить, используя различные команды отладки в windbg.
Ниже приведен пример фрагментации в пространстве виртуальной памяти:
Гораздо чаще видно, что фрагментация виртуальной машины вызвана временными большими объектами, требующими от сборщика мусора частого получения новых сегментов управляемой кучи от ОС и освобождения пустых версий в ОС.
Чтобы убедиться в том, что LOH вызывает фрагментацию виртуальной машины, можно установить точку останова в VirtualAlloc и VirtualFree , чтобы увидеть, кто их вызвал. Например, чтобы узнать, кто пытался выделить фрагменты виртуальной памяти размером более 8 МБ из ОС, можно установить точку останова следующим образом:
Эта команда разбивается на отладчик и показывает стек вызовов, только если вызов VirtualAlloc с размером выделения ПРЕВЫШАЕТ 8 МБ (0x800000).
В CLR 2.0 добавлена функция накопления виртуальной памяти, которую можно использовать в случае, когда сегменты (включая кучи больших и маленьких объектов) часто фиксируются и освобождаются. Для настройки накопления виртуальной памяти установите флаг запуска STARTUP_HOARD_GC_VM через API размещения. Вместо возвращения пустых сегментов операционной системе CRL освобождает память в этих сегментах и помещает их в список ожидания. (Обратите внимание, что среда CLR не выполняет эти действия со слишком большими сегментами.) Позже среда CLR использует эти сегменты для удовлетворения запросов на новый сегмент. В следующий раз, когда приложению потребуется новый сегмент, среда CLR использует его из этого списка ожидания, если он может найти достаточно большой.
Накопление виртуальной памяти удобно использовать для приложений, в которых необходимо закрепить уже полученные сегменты, например некоторых серверных приложений, имеющих приоритет в системе, чтобы избежать исключений нехватки памяти.
Мы настоятельно рекомендуем тщательно тестировать приложение при использовании этой функции и убедиться, что использование памяти достаточно стабильно.
Задает размер кучи в байтах. Этот параметр применяется только к исполняемым файлам.
Синтаксис
Remarks
reserve Аргумент задает общее выделение исходной кучи в виртуальной памяти. /HEAP Параметр компоновщика или EDITBIN Округляет указанное значение до ближайшего числа, кратного 4 байтам. По умолчанию размер кучи составляет 1 МБ.
Необязательный commit аргумент подлежит интерпретации операционной системы. в Windows операционной системе указывается начальный объем физической памяти, выделяемой для выделения. Кроме того, здесь указывается объем памяти, выделяемой при развертывании кучи. Выделенная виртуальная память приводит к тому, что пространство резервируется в файле подкачки. Более высокое commit значение позволяет системе выделять память реже, когда приложению требуется больше пространства в куче, но при этом увеличиваются требования к памяти и, возможно, время запуска приложения. commit Значение должно быть меньше или равно reserve значению. Значение по умолчанию — 4 КБ.
reserve Укажите значения и commit в десятичной, шестнадцатеричной или восьмеричной нотации языка C. Например, значение 1 МБ можно указать как 1048576 в десятичном формате или как 0x100000 в шестнадцатеричном виде или как 04000000 в восьмеричном формате. Значения по умолчанию эквивалентны параметру /HEAP:1048576,4096 .
Пример
В этом примере команда LINK создает исполняемый main.exe с резервом КУЧИ 2 МБ. Начальная куча и более поздние расширения кучи бывают блоками размером 64 КБ:
link /heap:0x200000,0x10000 main.obj
Настройка этого параметра компоновщика в Visual Studio
Откройте диалоговое окно Окна свойств проекта. Подробнее см. в статье Настройка компилятора C++ и свойств сборки в Visual Studio.
Перейдите на страницу свойств Свойства конфигурации>Компоновщик>Система.
Установите свойства Размер резервной кучи и размера фиксации кучи , а затем нажмите кнопку ОК или Применить , чтобы сохранить изменения.
Я столкнулся с запутанным вопросом, написанным в одной из моих университетских книг: там сказано, что «куча не статична и может увеличиваться по мере необходимости, запрашивая у операционной системы больше памяти».
Так что меня смущает следующее: предположим, я запускаю свое приложение, и объекты размещаются в куче. В какой-то момент приложению не хватает памяти: что теперь?
Насколько я понимаю, Gc (сборщик мусора) срабатывает и начинает операции отметки и очистки. Интересно, может ли как-то вместо вызова Gc из CLR у кучи есть возможность запросить у операционной системы больше памяти?

Что ж, CLR запросит больше памяти, если ей это нужно - она просто попытается сначала собрать мусор (как правило, в любом случае). Чего именно вы пытаетесь достичь?
Я только пытаюсь понять утверждение. Когда куча запросит больше памяти? Куча разделена на Gen 0,1,2. Когда память Gen 2 заполняется, происходит ли сборка мусора в Gen 2? или куча может расти, запрашивая на этом этапе больше памяти у операционной системы?
Термин «куча сборщика мусора» - удобная абстракция, но она не очень похожа на ту кучу, которую вы найдете в своем учебнике. Он не выделяет память, он выделяет адресное пространство. Низкоуровневым вызовом операционной системы в Windows является VirtualAlloc (). Это происходит только тогда, когда сборщик мусора не освобождает достаточно адресного пространства и больше нет свободных сегментов. Также не спешит снова освобождать адресное пространство. Нехватка памяти на самом деле означает исчерпание доступного адресного пространства. Что обычно происходит, когда не остается достаточно большой дыры.
В C ++ никто (обычно) не контролирует, как виртуальная память отображается на физическую память, как память выделяется для приложения и т. Д. Все это обрабатывается ОС и диспетчером памяти C ++. То , что вы находитесь ответственны в C ++ управляет жизни в памяти, что означает , что указывает , когда вам не нужно больше. Это совсем не то, что контролировать, откуда эта память или куда она уходит, когда освобождается.
Дело в том, что ваш код все еще просто обращается к виртуальной памяти, а ОС выполняет всю работу по отображению этой виртуальной памяти на физическую. Как программист, даже тогда вы были на востоке, учитывая абстракцию, что у вас есть 2 ^ 32 (или 16 или что-то еще) непрерывных слов памяти, и менеджер памяти обычно справлялся с этим еще дальше, чтобы вы могли сказать: «Я хочу 10 байтов данных », и он даст вам некоторые, или вы можете сказать:« Я закончил с этими 10 байтами », и он рассмотрит возможность передать их кому-то другому. Это куча, и вам обычно не приходилось ею управлять.
Важно понимать, что ошибка «недостаточно памяти» не означает, что у вас недостаточно физической памяти . Это означает, что у вас закончилась виртуальная память. В 32-битном приложении существует 2 ^ 32 возможных адреса для элемента в виртуальном адресном пространстве этого приложения .
Операционная система отвечает за отображение разделов этого виртуального адресного пространства на фактические физические носители данных, будь то ОЗУ, жесткий диск или любое другое устройство хранения. Поскольку большинство приложений не используют подавляющее большинство своего виртуального адресного пространства, большая его часть не отображается ни на что и не соответствует ничему, пока они впервые не начнут его использовать.
В то время как программа может изменять по ходу дела, какие блоки виртуальной памяти соответствуют фактическим блокам физической памяти (что требуется для того, чтобы программа могла использовать более 2 ^ 32 слов памяти одновременно), это происходит редко. , обычно выполняется только такими программами, как приложения для обработки видео, которым действительно нужно хранить много памяти одновременно. Этот процесс также выполняется вручную . Если вы не заменяете вручную то, что соответствует каждому блоку виртуальной памяти, у вас может закончиться виртуальная память, даже если у вас все еще есть устройства хранения, способные хранить больше информации . Это ошибка нехватки памяти.
Если у вас есть 64 битное приложение, вы можете в основном заменить все экземпляры 32 с 64 в этом ответе.
Куча является динамической в том смысле, что когда вы добавляете ее, она увеличивается. Он в некотором смысле создает указатели на другие места в памяти. Всегда существует ограничение на размер памяти, который приложение может использовать до тех пор, пока оно не исчерпает ее. Когда предел достигнут, вы обычно получаете исключение «нехватки памяти».

Куча увеличивается, потому что ваше приложение выделяет и удерживает объекты. Куча запрашивает память всякий раз, когда вашему приложению нужно хранить указатели на объекты, которые в настоящее время используются вашим приложением.
Есть несколько способов ограничить использование памяти. Пожалуйста, см. Этот вопрос для некоторого ввода: Уменьшение использования памяти
Чтобы узнать больше о куче (ing), а также о стеке (ing), пожалуйста, обратитесь по следующим ссылкам:

Использование 64-битной сборки вашего приложения в 64-битной ОС Windows позволит вашей программе выделить гораздо больше, чем ~ 2 ГБ памяти, предположительно до 2 ^ 64 адресных пространств (если у вас есть ОЗУ и дисковое пространство, что являются реальными ограничивающими факторами на момент написания этого ответа).
Если у вас ВСЕ ЕЩЕ не хватает памяти в вашем приложении, вы также можете увеличить размер файла подкачки памяти Windows. В Windows файл подкачки позволяет операционной системе перемещать память из ОЗУ на диск, если ему не хватает места в ОЗУ. Но перенос разделов оперативной памяти на диск и с диска требует больших временных затрат, поэтому это может серьезно сказаться на производительности вашего приложения. Независимо от производительности, увеличив размер страницы, вы можете (теоретически) сделать файл подкачки настолько большим, насколько есть свободное место на диске C: вашего компьютера с Windows. В этом случае ваше приложение сможет выделить, например, до 4 ТБ памяти (или любой другой объем памяти, на который установлен размер файла подкачки) во время выполнения вашей программы. Чтобы изменить настройки файла подкачки на вашем компьютере с Windows,сделайте следующее:
- Откройте диалоговое окно «Свойства системы», щелкнув правой кнопкой мыши «Этот компьютер» и выбрав пункт «Свойства» во всплывающем меню. Это также можно сделать в более поздних версиях Windows (Windows 10, Win 2012 Server и т. Д.), Выбрав «Пуск» & gt «Панель управления» & gt «Система и безопасность» & gt «Система».
- В левой части диалогового окна «Система» щелкните параметр «Дополнительные свойства системы». Откроется вкладка «Дополнительно» в устаревшем диалоговом окне «Свойства системы» для Windows.
- На вкладке «Дополнительно» устаревшего диалогового окна «Свойства системы» нажмите кнопку «Параметры» в поле «Производительность». Это откроет диалоговое окно «Параметры производительности».
- В диалоговом окне «Параметры производительности» щелкните вкладку «Дополнительно», чтобы просмотреть текущие настройки размера файла подкачки памяти Windows.
- Чтобы увеличить размер файла подкачки, нажмите кнопку «Изменить», и откроется диалоговое окно «Виртуальная память».
- В диалоговом окне «Виртуальная память» выберите диск «C:», затем в разделе «Пользовательский размер» установите размеры «Начальный» и «Максимальный». Вы можете использовать любой размер до максимального количества свободного места на диске C :, но внесение этого изменения зарезервирует это пространство для файла подкачки на жестком диске.
- Затем нажмите «ОК» во всех диалоговых окнах, чтобы сохранить новые настройки. Затем перезагрузите компьютер, чтобы убедиться, что все изменения были внесены правильно и что новые настройки файла подкачки действуют.
Как можно увеличить максимальный объем памяти, выделяемой в стеке / куче для программы на C ++?
Будет ли увеличение оперативной памяти вашего компьютера автоматически увеличивать стек / кучу памяти компьютерной программы?

обычно каждое ядро накладывает ограничение на поток, а для процесса вы можете использовать больше ресурсов для многопроцессорности или многопоточности.
Значимые ответы будут зависеть от системы, на которую вы нацеливаетесь, и (возможно) от набора инструментов, который вы используете.
Добавление ОЗУ улучшает производительность системы, но обычно не влияет на правильную работу программы. Если вашей программе требуется больше памяти, чем у вас ОЗУ, Windows переместит часть вашей программы на диск в файле подкачки.
Второе редактирование: из вашего комментария я вижу, что вы работаете в Windows, поэтому мой ответ Unix ниже не будет вам очень полезен. Но см. Определение максимального размера стека программы в Visual Studio и C / C ++ .
Размер стека в Linux довольно часто ограничен. Команда ulimit -s выдаст текущее значение в килобайтах. Вы можете изменить значение по умолчанию (обычно) в файле /etc/security/limits.conf.
Вы также можете, в зависимости от привилегий, изменять его для каждого процесса, используя setrlimit() . См., Например, мой ответ на ошибку сегментации: распределение стека в программе C в Ubuntu, когда буфер> 4M .
Для кучи , смотри , например , Heap ограничение размера в C . Но я не верю, что можно увеличить или уменьшить максимальный размер.
Вы можете указать зарезервированный размер кучи и размер стека с помощью параметров ссылки / Heap и / Stack в Visual Studio. Дополнительные сведения см. В этих статьях MSDN:
Размер кучи процесса обычно ограничен максимальной памятью, которую процесс может выделить. Куча не обязательно должна быть непрерывной (если вы не делаете что-то вроде malloc (1000000000)), поэтому куча может использовать большую часть доступного адресного пространства.
В Windows максимальный размер процесса зависит от нескольких факторов.
При использовании 32-битной Windows 32-битный процесс может по умолчанию выделить 2 ГБ. Если Windows загружается с использованием переключателя / 3GB и процесс компилируется с использованием флага компоновщика «Enable Large Addresses», то процессу может быть выделено 3 ГБ.
При использовании 64-битной Windows 32-битный процесс по умолчанию может выделить 2 ГБ. Если процесс связан с «Разрешить большие адреса», то 64-разрядная Windows позволяет 32-разрядному процессу выделить 4 ГБ.
64-битный процесс (в 64-битной Windows) может выделить примерно 16 000 ГБ.
Читайте также: