
Уровень надежности в excel что значит
Основным требованием, предъявляемым к Центрам Обработки Данных (ЦОД) является отказоустойчивость. Именно отказоустойчивость ЦОД и определяет уровень надежности ЦОД. При этом подразумевается отключение ЦОД как на время планово-предупредительных работ и профилактики оборудования, так и внеплановых аварийных ситуаций.
Главная цель введения классификации по уровням надежности — избежать расплывчатых формулировок как при формировании технического задания к строящимся дата-центрам, так и при описании характеристик уже функционирующих ЦОД.
Очевидно, что понятие отказоустойчивости ЦОД определяет и отказоустойчивость каждой из систем ЦОД. Это означает, что тот или иной уровень надежности накладывает определенные требования сразу на всю инфраструктуру дата-центра. Фактически, из этого следует, что выбраный уровень надежности целиком определяет концепцию ЦОД.
После всех совершенных манипуляций, инструмент Описательная статистика должен отобразить результаты обработки выборки на текущем листе. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!

Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Как посчитать ошибку среднего в excel
- При Tier I и II для выполнения планово-предупредительных работ необходимо остановить ЦОД,
- При Tier III и IV любая плановая деятельность осуществляется без нарушения нормального хода работы ЦОД.
| Параметр | Tier I | Tier II | Tier III | Tier VI |
|---|---|---|---|---|
| Год внедрения | 1965 | 1970 | 1985 | 1995 |
| Отказоустойчивость | ||||
| Время простоя за год, ч | 28.8 | 22 | 1.6 | 0.4 |
| Доступность ЦОД | 99.671% | 99.749% | 99.982 | 99.995 |
| Уровень загрузки оборудования | 100% | 100% | 90% | 90% |
| Обслуживание без отключения | Нет | Нет | Да | Да |
| Планируемые остановки ЦОД | 2х12ч в год | 3х12ч за 2 года | Нет | Нет |
| Аварийность | 6 аварий за 5 лет | 1 авария ежегодно | 1 авария за 2.5 года | 1 авария за 5 лет |
| Отказоустойчивость как одиночное событие | Нет | Нет | Нет | Да |
| Строительные требования | ||||
| Тип здания | С соседями | С соседями | Отдельно стоящее | Отдельно стоящее |
| Огнестойкость стен | Нет | Нет | 1 час | 2 часа |
| Несущая способность перекрытия | 735кг/м² сверху 125кг/м² снизу | 857кг/м² сверху 125кг/м² снизу | 1225кг/м² сверху 245кг/м² снизу | 1225кг/м² сверху 245кг/м² снизу |
| Высота фальшпола | Нет или до 305мм (12″) | 457мм (18″) | 762-914мм (30-36″) | 762-1067мм (30-42″) |
| Резервирование | ||||
| ИБП | N | N+1 | N+1 | 2(N+1) |
| ДГУ | N | N | N+1 | 2(N+1) |
| Кондиционирование | N | N+1 | N+1 | 2(N+1) |
| Трубопроводы теплоносителя и конденсата | N | N | 2N | 2N |
| Точки подключения | ||||
| Количество энерговводов | 1 | 1 | 1 раб, 1рез | 2 рабочих |
| Точки слива дренажа | 1 | 1 | 2 | 2 рабочих |
| Точки водозабора для увлажнения | 1 | 2 | 2 | 2 |
| Наличие особых систем | ||||
| Мониторинг | Нет | Нет | Да (выборочно) | Да (всех систем) |
| Увлажнение | Да | Да | Да | Да |
| Пожарные извещатели | Нет | Да | Да | Да |
| Течеискатели | Нет | Да | Да | Да |
| Контроль доступа | Нет | Нет | Да | Да |
| Общие характеричтики | ||||
| Срок ввода в эксплуатацию | 3 мес. | 3-6 мес. | 15-20 мес. | 15-30 мес. |
| Ориентировочная стоимость | 5000 $/м² 10 000 $/кВт | 6500 $/м² 11 000 $/кВт | 9700 $/м² 20 000 $/кВт | 12 000 $/м² 22 000 $/кВт |
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
где xi – значения переменной,
n – количество значений.
Используя более привычные обозначения, формулу записывают как:
где σ 2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
Формула стандартной ошибки средней при использовании выборочной дисперсии
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Это означает, что тот или иной уровень надежности накладывает определенные требования сразу на всю инфраструктуру дата-центра. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Главная цель введения классификации по уровням надежности — избежать расплывчатых формулировок как при формировании технического задания к строящимся дата-центрам, так и при описании характеристик уже функционирующих ЦОД.
Tier: уровни надежности ЦОД и что из этого следует |
Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
Функция ЕСЛИ является очень популярной в Excel. Она позволяет автоматически выполнять какое-либо действие, в зависимости от поставленного условия.

Функция ЕСЛИ выполняет проверку логического выражения и если выражение истинно, то поставляется одно значение и альтернативное, если ложь. Синтаксис следующий:
— Логическое выражение — выражение, которое по итогу своего вычисления должно вырнуться значение ИСТИНА или ЛОЖЬ.
— Значение, если истина — устанавливаем указанное значение, если логическое выражение вернуло ИСТИНА
— Значение, если ложь — устанавливает указанное значение, если логическое выражение вернуло ЛОЖЬ.
В примере выше мы хотим определить, получили ли мы за месяц выручку больше 500 рублей или нет. В формуле ЕСЛИ(B2>500;»Да»;»Нет») первый параметр (B2>500) проверяет, выручка за месяц больше 500 рублей или нет; второй параметр («Да») — функция вернет Да, если выручка больше 500 рублей и соответственно Нет (третий параметр), если выручка меньше.
Обратите внимание, что значения при истине или лжи могут быть не только текстовые, числовые, но также и функции(в том числе и ЕСЛИ), что позволяет реализовать достаточно сложные логические конструкции.
Вставить пропуск Скрытые отфильтрованные строки; Подсчет и сумма по цвету фона ; Отправляйте персонализированные электронные письма нескольким получателям массово. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Эта ошибка возникает при вычислении ячеек, когда в формуле содержится функция, которая ссылается на ячейки или диапазон в закрытой книге. Для работы этой функции необходимо, чтобы другая книга была открыта.
Как посчитать ячейки выше определенного значения или среднего значения в Excel?
В ЦОД Tier I отсутствует защита от случайных и намеренных событий, обусловленных действиями человека. Несущая способность перекрытий не менее 735кг/м² при нагрузке сверху плюс 125кг/м² нагрузки снизу.
СОВЕТ : Для понимания терминов Уровень значимости и Уровень надежности потребуется знание следующих понятий:
Уровень значимости статистического теста – это вероятность отклонить нулевую гипотезу , когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность ошибки первого рода (type I error).
Уровень значимости обычно обозначают греческой буквой α ( альфа ). Чаще всего для уровня значимости используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении доверительного интервала для оценки среднего значения распределения , его ширину рассчитывают таким образом, чтобы вероятность события « выборочное среднее (Х ср ) находится за пределами доверительного интервала » было равно уровню значимости . Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о равенстве среднего заданному значению .
Ошибка первого рода часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина ошибки первого рода задается перед проверкой гипотезы , таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение уровня значимости α (т.е. вероятности ошибки первого рода ) может привести к увеличению вероятности ошибки второго рода , то есть вероятности принять нулевую гипотезу , когда на самом деле она не верна. Подробнее об ошибке второго рода см. статью Ошибка второго рода и Кривая оперативной характеристики .
Уровень значимости обычно указывается в аргументах обратных функций MS EXCEL для вычисления квантилей соответствующего распределения: НОРМ.СТ.ОБР() , ХИ2.ОБР() , СТЬЮДЕНТ.ОБР() и др. Примеры использования этих функций приведены в статьях про проверку гипотез и про построение доверительных интервалов .
Уровень надежности
Уровень доверия (этот термин более распространен в отечественной литературе, чем Уровень надежности ) - означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Уровень доверия равен 1-α, где α – уровень значимости .
Термин Уровень надежности имеет синонимы: уровень доверия, коэффициент доверия, доверительный уровень и доверительная вероятность (англ. Confidence Level , Confidence Coefficient ).
В математической статистике обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д.
Например, Уровень доверия 95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор уровня доверия полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Стоит отметить, что математически не корректно говорить, что Уровень доверия является вероятностью, того что оцениваемый параметр распределения принадлежит доверительному интервалу , вычисленному на основе выборки . Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что доверительный интервал , с вероятностью равной Уровню доверия, накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL

В MS EXCEL Уровень надежности упоминается в надстройке Пакет анализа . После вызова надстройки, в диалоговом окне необходимо выбрать инструмент Описательная статистика .

После нажатия кнопки ОК будет выведено другое диалоговое окно.
В этом окне задается Уровень надежности, т.е.значениевероятности в процентах. После нажатия кнопки ОК в выходном интервале выводится значение равное половине ширины доверительного интервала . Этот доверительный интервал используется для оценки среднего значения распределения, когда дисперсия не известна (подробнее см. статью про доверительный интервал ).
Необходимо учитывать, что данный доверительный интервал рассчитывается при условии, что выборка берется из нормального распределения . Но, на практике обычно принимается, что при достаточно большой выборке (n>30), доверительный интервал будет построен приблизительно правильно и для распределения, не являющегося нормальным (если при этом это распределение не будет иметь сильной асимметрии ).
Примечание : Понять, что в диалоговом окне речь идет именно об оценке среднего значения распределения , достаточно сложно. Хотя в английской версии диалогового окна это указано прямо: Confidence Level for Mean .
Если Уровень надежности задан 95%, то надстройка Пакет анализа использует следующую формулу (выводится не сама формула, а лишь ее результат):
или эквивалентную ей
где =СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) – является стандартной ошибкой среднего (формулы приведены в файле примера ).
В статье Статистики, выборочное распределение и точечные оценки в MS EXCEL дано определение точечной оценки параметра распределения (point estimator). Однако, в силу случайности выборки, точечная оценка не совпадает с оцениваемым параметром и более разумно было бы указывать интервал, в котором может находиться неизвестный параметр при наблюденной выборке х 1 , x 2 , . х n . Поэтому цель использования доверительных интервалов состоит в том, чтобы по возможности избавиться от неопределенности и сделать как можно более полезный статистический вывод .
Примечание : Процесс обобщения данных выборки , который приводит к вероятностным утверждениям обо всей генеральной совокупности , называют статистическим выводом (statistical inference).
СОВЕТ : Для построения Доверительного интервала нам потребуется знание следующих понятий:
К сожалению, интервал, в котором может находиться неизвестный параметр, совпадает со всей возможной областью изменения этого параметра, поскольку соответствующую выборку , а значит и оценку параметра , можно получить с ненулевой вероятностью. Поэтому приходится ограничиваться нахождением границ изменения неизвестного параметра с некоторой заданной наперед вероятностью.
Определение : Доверительным интервалом называют такой интервал изменения случайной величины , которыйс заданной вероятностью , накроет истинное значение оцениваемого параметра распределения.
Эту заданную вероятность называют уровнем доверия (или доверительной вероятностью ).
Обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д. Например, уровень доверия 95% означает, что дополнительное событие, вероятность которого 1-0,95=5%, исследователь считает маловероятным или невозможным.
Примечание : Вероятность этого дополнительного события называется уровень значимости или ошибка первого рода . Подробнее см. статью Уровень значимости и уровень надежности в MS EXCEL .
Разумеется, выбор уровня доверия полностью зависит от решаемой задачи. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Построение доверительного интервала в случае, когда стандартное отклонение неизвестно, приведено в статье Доверительный интервал для оценки среднего (дисперсия неизвестна) в MS EXCEL . О построении других доверительных интервалов см. статью Доверительные интервалы в MS EXCEL .
Формулировка задачи
Предположим, что из генеральной совокупности имеющей нормальное распределение взята выборка размера n. Предполагается, что стандартное отклонение этого распределения известно. Необходимо на основании этой выборки оценить неизвестное среднее значение распределения (μ, математическое ожидание ) и построить соответствующий двухсторонний доверительный интервал .
Точечная оценка

Как известно из Центральной предельной теоремы , статистика (обозначим ее Х ср ) является несмещенной оценкой среднего этой генеральной совокупности и имеет распределение N(μ;σ 2 /n).
Примечание : Что делать, если требуется построить доверительный интервал в случае распределения, которое не является нормальным? В этом случае на помощь приходит Центральная предельная теорема , которая гласит, что при достаточно большом размере выборки n из распределения не являющемся нормальным , выборочное распределение статистики Х ср будет приблизительно соответствовать нормальному распределению с параметрами N(μ;σ 2 /n).
Итак, точечная оценка среднего значения распределения у нас есть – это среднее значение выборки , т.е. Х ср . Теперь займемся доверительным интервалом.
Построение доверительного интервала
Обычно, зная распределение и его параметры, мы можем вычислить вероятность того, что случайная величина примет значение из заданного нами интервала. Сейчас поступим наоборот: найдем интервал, в который случайная величина попадет с заданной вероятностью. Например, из свойств нормального распределения известно, что с вероятностью 95%, случайная величина, распределенная по нормальному закону , попадет в интервал примерно +/- 2 стандартных отклонения от среднего значения (см. статью про нормальное распределение ). Этот интервал, послужит нам прототипом для доверительного интервала .
Теперь разберемся,знаем ли мы распределение , чтобы вычислить этот интервал? Для ответа на вопрос мы должны указать форму распределения и его параметры.
Форму распределения мы знаем – это нормальное распределение (напомним, что речь идет о выборочном распределении статистики Х ср ).
Параметр μ нам неизвестен (его как раз нужно оценить с помощью доверительного интервала ), но у нас есть его оценка Х ср , вычисленная на основе выборки, которую можно использовать.
Второй параметр – стандартное отклонение выборочного среднего будем считать известным , он равен σ/√n.
Т.к. мы не знаем μ, то будем строить интервал +/- 2 стандартных отклонения не от среднего значения , а от известной его оценки Х ср . Т.е. при расчете доверительного интервала мы НЕ будем считать, что Х ср попадет в интервал +/- 2 стандартных отклонения от μ с вероятностью 95%, а будем считать, что интервал +/- 2 стандартных отклонения от Х ср с вероятностью 95% накроет μ – среднее генеральной совокупности, из которого взята выборка . Эти два утверждения эквивалентны, но второе утверждение нам позволяет построить доверительный интервал .
Кроме того, уточним интервал: случайная величина, распределенная по нормальному закону , с вероятностью 95% попадает в интервал +/- 1,960 стандартных отклонений, а не+/- 2 стандартных отклонения . Это можно рассчитать с помощью формулы =НОРМ.СТ.ОБР((1+0,95)/2) , см. файл примера Лист Интервал .

Теперь мы можем сформулировать вероятностное утверждение, которое послужит нам для формирования доверительного интервала : «Вероятность того, что среднее генеральной совокупности находится от среднего выборки в пределах 1,960 « стандартных отклонений выборочного среднего» , равна 95%».
Значение вероятности, упомянутое в утверждении, имеет специальное название уровень доверия , который связан с уровнем значимости α (альфа) простым выражением уровень доверия = 1 -α . В нашем случае уровень значимости α =1-0,95=0,05 .
Теперь на основе этого вероятностного утверждения запишем выражение для вычисления доверительного интервала :

Примечание : Верхний α/2-квантиль определяет ширину доверительного интервала в стандартных отклонениях выборочного среднего. Верхний α/2-квантиль стандартного нормального распределения всегда больше 0, что очень удобно.
В нашем случае при α=0,05, верхний α/2-квантиль равен 1,960. Для других уровней значимости α (10%; 1%) верхний α/2-квантиль Z α/2 можно вычислить с помощью формулы =НОРМ.СТ.ОБР(1-α/2) или, если известен уровень доверия , =НОРМ.СТ.ОБР((1+ур.доверия)/2) .
Обычно при построении доверительных интервалов для оценки среднего используют только верхний α /2- квантиль и не используют нижний α /2- квантиль . Это возможно потому, что стандартное нормальное распределение симметрично относительно оси х ( плотность его распределения симметрична относительно среднего, т.е. 0 ) . Поэтому, нет нужды вычислять нижний α/2-квантиль (его называют просто α /2-квантиль ), т.к. он равен верхнему α /2- квантилю со знаком минус.
Напомним, что, не смотря на форму распределения величины х, соответствующая случайная величина Х ср распределена приблизительно нормально N(μ;σ 2 /n) (см. статью про ЦПТ ). Следовательно, в общем случае, вышеуказанное выражение для доверительного интервала является лишь приближенным. Если величина х распределена по нормальному закону N(μ;σ 2 /n), то выражение для доверительного интервала является точным.
Расчет доверительного интервала в MS EXCEL
Решим задачу. Время отклика электронного компонента на входной сигнал является важной характеристикой устройства. Инженер хочет построить доверительный интервал для среднего времени отклика при уровне доверия 95%. Из предыдущего опыта инженер знает, что стандартное отклонение время отклика составляет 8 мсек. Известно, что для оценки времени отклика инженер сделал 25 измерений, среднее значение составило 78 мсек.
Решение : Инженер хочет знать время отклика электронного устройства, но он понимает, что время отклика является не фиксированной, а случайной величиной, которая имеет свое распределение. Так что, лучшее, на что он может рассчитывать, это определить параметры и форму этого распределения.
К сожалению, из условия задачи форма распределения времени отклика нам не известна (оно не обязательно должно быть нормальным ). Среднее, т.е. математическое ожидание , этого распределения также неизвестно. Известно только его стандартное отклонение σ=8. Поэтому, пока мы не можем посчитать вероятности и построить доверительный интервал .
Однако, не смотря на то, что мы не знаем распределение времени отдельного отклика , мы знаем, что согласно ЦПТ , выборочное распределение среднего времени отклика является приблизительно нормальным (будем считать, что условия ЦПТ выполняются, т.к. размер выборки достаточно велик (n=25)) .
Более того, среднее этого распределения равно среднему значению распределения единичного отклика, т.е. μ. А стандартное отклонение этого распределения (σ/√n) можно вычислить по формуле =8/КОРЕНЬ(25) .
Также известно, что инженером была получена точечная оценка параметра μ равная 78 мсек (Х ср ). Поэтому, теперь мы можем вычислять вероятности, т.к. нам известна форма распределения ( нормальное ) и его параметры (Х ср и σ/√n).
Инженер хочет знать математическое ожидание μ распределения времени отклика. Как было сказано выше, это μ равно математическому ожиданию выборочного распределения среднего времени отклика . Если мы воспользуемся нормальным распределением N(Х ср ; σ/√n), то искомое μ будет находиться в интервале +/-2*σ/√n с вероятностью примерно 95%.
Уровень значимости равен 1-0,95=0,05.
Левая граница: =НОРМ.ОБР(0,05/2; 78; 8/КОРЕНЬ(25)) Правая граница: =НОРМ.ОБР(1-0,05/2; 78; 8/КОРЕНЬ(25))
Ответ : доверительный интервал при уровне доверия 95% и σ =8 мсек равен 78+/-3,136 мсек.
В файле примера на листе Сигма известна создана форма для расчета и построения двухстороннего доверительного интервала для произвольных выборок с заданным σ и уровнем значимости .

Функция ДОВЕРИТ.НОРМ()
Если значения выборки находятся в диапазоне B20:B79 , а уровень значимости равен 0,05; то формула MS EXCEL: =СРЗНАЧ(B20:B79)-ДОВЕРИТ.НОРМ(0,05;σ; СЧЁТ(B20:B79)) вернет левую границу доверительного интервала .
Эту же границу можно вычислить с помощью формулы: =СРЗНАЧ(B20:B79)-НОРМ.СТ.ОБР(1-0,05/2)*σ/КОРЕНЬ(СЧЁТ(B20:B79))
Примечание : Функция ДОВЕРИТ.НОРМ() появилась в MS EXCEL 2010. В более ранних версиях MS EXCEL использовалась функция ДОВЕРИТ() .
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню Сервис\Надстройки
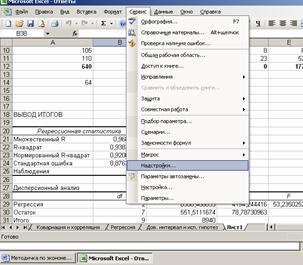
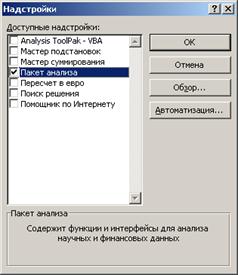
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel, нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:

Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа, нажать кнопку Перейти и в следующем окне включить пакет анализа.
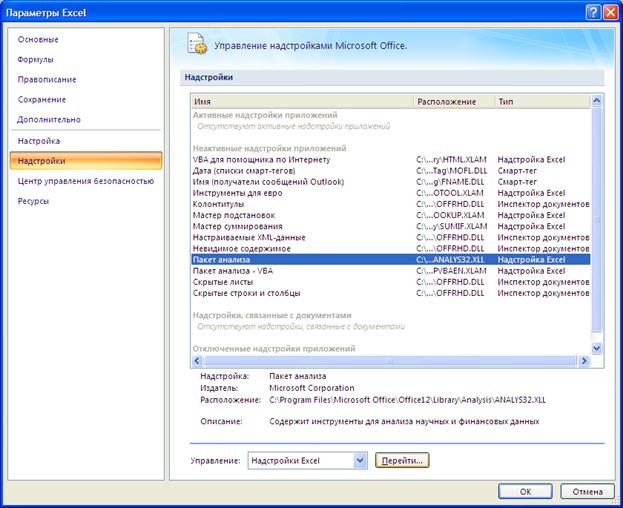
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия. (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/ Регрессия). Появится диалоговое окно, которое нужно заполнить:
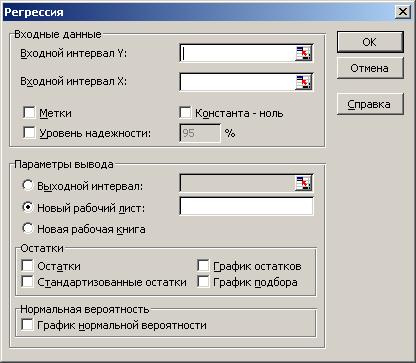
3) Признак Метки ставится, если первые ячейки содержат пояснительный текст (подписи данных);
4) Уровень надежности ¾ это доверительная вероятность, которая по умолчанию считается равной 95%. Если это значение не устраивает, то нужно включить этот признак и ввести требуемое значение;
5) Признак Константа-ноль включается, если необходимо построить уравнение, в котором свободная переменная ;
6) Параметры вывода определяют, куда должны быть помещены результаты. По умолчанию строит режим Новый рабочий лист;
7) Блок Остатки позволяет включать вывод остатков и построение их графиков.
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой (коэффициент корреляции Пирсона);
R-квадрат вычисляется по формуле (коэффициент детерминации);
Нормированный R-квадрат вычисляется по формуле (используется для множественной регрессии);
Стандартная ошибка S вычисляется по формуле ;
Наблюдения ¾ это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает , то принимается гипотеза (нет линейной взаимосвязи), иначе принимается гипотеза (есть линейная взаимосвязь).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен ;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента , стандартной ошибки и t-статистики .
P-значение ¾ это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП(t-статистика; ). Если P-значение превышает , то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% ¾ это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих .
7. Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Расчет параметров уравнения линейной регрессии, проверку их статистической значимости и построения интервальных оценок можно выполнить значительно быстрее автоматически при использовании Пакета анализа Excel (программа «Регрессия»)
Пусть исходные данные примера 2.1 (расходы на питание – личный доход) представлены в Excel.
Выбираем команду Анализ данных→Регрессия.
В диалоговом окне режимаРегрессиязадаются следующие параметры:
® Метки – установите флажок в активное состояние, если выделены и заголовки столбцов.
® Константа- ноль – установите флажок в активное состояние, если оцениваете регрессионное уравнение без свободного члена.
При необходимости задаются и другие параметры.
Результаты расчетов с использованием инструмента Регрессия выводятся под общим названием Вывод итоговв виде следующих таблиц.
| Регрессионная статистика | |
| Множественный R | 0,952 |
| R- квадрат | 0,907 |
| Нормированный R- квадрат | 0,875 |
| Стандартная ошибка | 1,817 |
| Наблюдения |
| Дисперсионный анализ | ||||
| df | SS | MS | F | Значимость F |
| Регрессия | 96,1 | 96,1 | 29,12 | 0,01247 |
| Остаток | 9,9 | 3,3 | ||
| Итого |
| Коэффи- циенты | Стандартная ошибка | t-статис- тика | P- зна- чение | Нижнее 95% | Верхние 95% | |
| Y – пересеч. | -1,75 | 1,65 | -1,06 | 0,36669 | -7,001 | 3,501 |
| X | 0,775 | 0,14361 | 5,40 | 0,01247 | 0,318 | 1,232 |
Результаты работы программы «Регрессия» полностью совпадают с полученными ранее расчетами.

При необходимости выводятся предсказанные значения результативного признака и значения остатков.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное у | Остатки |
| -0,2 | 1,2 | |
| 2,9 | -0,9 | |
| -2 | ||
| 9,1 | 1,9 | |
| 12,2 | -0,2 |
Коэффициенты регрессии, их стандартные ошибки и коэффициент детерминации составляют:
a= -1,75; b=0,775; = 1,65; =0,143; = 0,907
Результаты регрессионного анализа принято записывать в виде:

ȳ= -1,75+0,775х ; = 0,907,
(1,65)(0,143)
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Статическая значимость коэффициента = 0,907 устанавливается поF – тесту. Поскольку ЗначимостьF= 0,0124 = 0,907 значим при уровне 5%. Модель в целом значима.
Обычно проверка значимости коэффициента а не производится. Оценим статистическую значимость коэффициентаb.
Результаты оценивания регрессии совместимы не только с полученным значением коэффициента регрессии b= 0,775, но и с некоторым его множеством (доверительным интервалом). С вероятностью 95% доверительный интервал коэффициента bесть (0,318 ….1,232).
Пример.Имеются данные (усл. ед.) о расходах на питание yи душевого похода х для девяти групп семей:
Используя результаты работы программы «Регрессия», проанализируйте зависимость расходов на питание от величины душевого дохода.
Результаты регрессионного анализа записываем в виде:
ȳ= 66,04+0,107х , = 0,885,
(11,72) (0,015)
где в скобках указаны стандартные ошибки коэффициентов регрессии.

Качество модели оценивается коэффициентов .
Величина = 0,885 означает, что фактором душевого дохода можно объяснить 88,5% вариации (разброса) расходов на питание.
Установим статистическую значимость коэффициента .
Поскольку ЗначимостьF = 0,000158 < α = 0,05, то =0,885 значим при уровне 5%.
Направление связи между переменными уи х определяет знак коэффициента b=0,107 ˃ 0, т.е. связь является прямой(положительной).
Коэффициент b=0,107 показывает, что при увеличении душевого дохода на 1 усл. ед. расходы на питание в среднем увеличиваются на 0,107 усл. ед.
Вследствие большой популярности эконометрических исследований на Западе средства построения эконометрических моделей включены во все известные интегрированные офисные средства (Microsoft Office, Perfect Office и т. д.) и табличные процессоры (Excel, Lotus 1-2-3, Quattro Pro и др.).

Рассмотрим методику построения эконометрических моделей с помощью встроенных функций Microsoft Excel.
Построение эконометрических моделей требует выполнения множества расчетов по определению параметров и характеристик.
В зависимости от целей исследования и вида уравнения регрессии расчеты в Excel могут быть выполнены с помощью различных функций ЛИНЕЙН, ЛГРФПРИБЛ, ТЕНДЕНЦИЯ, РОСТ и др.
Приведем методику использования MS Excel для построения эконометрических уравнений на примере линейной регрессии (ЛИНЕЙН).
Встроенная статистическая функция ЛИНЕЙН определяет параметры линейной регрессии:
y=mx+b или y=m1x1 + m2x2 +. + b,
где зависимое значение y является функцией независимого значения x. Значения m - это коэффициенты, соответствующие каждой независимой переменной x, а b - константа.
ЛИНЕЙН (известные значения y; известные значения x; конст; статистика)
известные значения y - это множество значений y, которые уже известны для соотношения y=mx+b.
Массив известные значения х может содержать одно или несколько множеств переменных.
Конст - это логическое значение, которое указывает, требуются ли, чтобы константа b была равна нулю. Константа принимает одно из двух значений ИСТИНА или ЛОЖЬ. Если конст имеет значение истина или опущено, то b вычисляется, если конст имеет значение ЛОЖЬ, то b полагается равным 0.
Статистика - это логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Статистика также принимает одно из значений ИСТИНА или ЛОЖЬ. В первом случае дополнительная статистика рассчитывается, во втором случае не рассчитывается.
Дополнительные статистические характеристики функции ЛИНЕЙН приведены ниже Дополнительные статистические характеристики функции ЛИНЕЙН приведены ниже:
b, m1, m2,…mn – коэффициенты регрессии (параметры модели);
se1, se2. sen - стандартные значения ошибок для коэффициентов m1,m2. mn;
seb- стандартное значение ошибки для постоянной b;
r 2 - коэффициент детерминированности;
sey - стандартная ошибка для оценки y;
F - F-статистика, используемая для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df - степени свободы, используемые для нахождения F-критических значений в статистической таблице (для определения уровня надежности модели нужно сравнить значения в таблице с F-статистикой функции ЛИНЕЙН);
ssreg - регрессионая сумма квадратов;
ssresid - остаточная сумма квадратов.
Характеристики выводятся на экран дисплея в виде приведенного ниже массива (таблицы):
| mn | mn-1 | … | m2 | m1 | b |
| sen | Sen-1 | … | se2 | se1 | seb |
| r 2 | Seу | … | |||
| F | Df | … | |||
| ssreg | ssresid | … |
Порядок выполнения расчетов следующий:
1. Вводятся исходные данные или открывается существующий файл, содержащий исходные данные.
2. В рабочем окне Excel выделяется диапазон ячеек 5*(n+1) (5 число строк, (n+1) - число столбцов, n – число показателей факторов) для вывода результатов расчета.
3. Активизируются "Мастер функций" любым из способов:
а) в главном меню выбирается Вставка/Функция;
б) на панели инструментов Стандартная нажимается кнопка (fx)

4. В появившемся окне "Мастер функций шаг 1 из 2" среди категорий выбирается Статистические, среди функций - ЛИНЕЙН шаг 1 из 2 (рис. 3.1.1)
Рис. 3. 1. 1. Диалоговое окно "Мастер функций шаг 1 из 2"
5. В появившемся втором окне "Мастер функций" (рис. 3. 1. 2)
вводятся аргументы, т.е. указываются диапазоны ячеек рабочего окна EXCEL, в которых находятся исходные данные для У и Х, а также значения аргументов константа и статистика.

Рис. 3. 1. 2. Второе диалоговое окно "Мастер функций"

Рис. 3. 1. 3. Результат вычисления функции ЛИНЕЙН
6. Нажимается кнопка ОК. В выделенном диапазоне рабочего окна
Excel появляется результат - численное значение для коэффициента регрессии (b). Чтобы вывести всю статистику следует нажать клавишу , а затем - комбинацию клавиш ++.
Читайте также: