
Укажите область применения программ finereader cuneiform
Когда речь заходит о программах для распознавания символов, практически все русскоязычные пользователи уверенно заявляют: в этом секторе бесплатных альтернатив ABBYY FineReader нет. Но на самом деле с недавних пор выбор есть, ведь российская компания Cognitive Technologies открыла исходные кода своего продукта Cuneiform, сделав его доступным всем и каждому. Сегодня мы столкнём двух гигантов лицом к лицу в попытке выяснить, что же лучше: отрытый код и бесплатность, или коммерческая разработка.
Немного истории
Чтобы лучше понять нынешнее положение дел на рынке OCR-систем, необходимо вспомнить историю рассматриваемых программ.
Оптическое распознавание текста (англ. optical character recognition, OCR) — перевод последовательности изображений символа в последовательность кодов, использующихся для представления в текстовом редакторе. Перевод осуществляется с помощью различных алгоритмов, после преобразования изображения в набор элементарных точек.
По странному стечению обстоятельств, первые публичные версии обоих программ увидели свет в 1993 году. Именно тогда молодая компания BIT Software (будущая ABBY) выпустила систему распознавания символов FineReader 1.0, а только что созданная Cognitive Technologies выпускает шрифтонезависимую систему распознавания OCR CuneiForm и даже лицензирует её канадской Corel Corporation — для использования в пакете Corel Draw 3.0.
Год спустя ABBY подписывает контракт с Recognita Corp. И начинает распространение FineReader в Европе и США, а также договаривается с компанией «Фитек» о комплектации поставляемых ею сканеров Logitech системой FineReader 2.0 Light.
Год 1996-й ознаменовался выпуском CuneiForm ’96, в которой впервые в мире применены алгоритмы адаптивного распознавания. А ABBY тем временем продала исходный код FineReader компании Samsung Electronics (корейские специалисты использовали этот код при разработке фирменного программного обеспечения для своей продукции).
Адаптивное распознавание — метод, основанный на комбинации двух алгоритмов распознавания печатных символов: шрифтового (multifont) и шрифтонезависимого (omnifont). Система генерирует внутренний шрифт для каждого вводимого документа, основываясь на хорошо пропечатанных символах, адаптируясь к конкретным входным символам.
Дальнейшее развитие обоих систем шло практически параллельно. Однако, в 2004 году Cognitive Technologies практически остановила развитие CuneiForm, тогда как ABBYY продолжает совершенствовать свой продукт по сей день.
После нескольких лет перерыва в разработке, 12 декабря 2007 года Cognitive объявила об открытии исходных кодов своей OCR-системы. Само же открытие состоялось 2 апреля 2008 года. До сего момента, впрочем, сообщество OpenSource не опубликовало ни одной новой версии CuneiForm, сосредоточившись на чистке кода ядра распознавания и подготовке его к портированию на отличные от Windows платформы. Первые версии графических интерфейсов к модифицированному ядру, основанные на библиотеки Qt 4, уже опубликованы для платформы Linux.
На ринг!
В сегодняшнем противостоянии будут участвовать последняя на данный момент Windows-версия CuneiForm 12, доступная на сайте разработчиков (33 Мбайт, OpenSource), а также лицензионная версия ABBY FineReader 9.0 Professional (последняя на данный момент версия — 10.0 — вышла в конце сентября 2009 года и ещё не успела получить широкого распространения).
В ходе тестирования мы изучим функциональные возможности программ, их интерфейсы и — что самое важное — испытаем обоих противников на нескольких документах разной сложности, проверив качество распознавания.
Встречаем по одёжке…
Знакомство с любой программой начинается с интерфейса, ведь даже самая функциональная программа, с которой неудобно работать, растеряет половину своих пользователей.

Главное окно Cuineform 12 (режим редактирования распознанного текста)

Главное окно FineReader 9.0 (режим разметки и редактирования)
В этом отношении между нашими конкурентами установился паритет — обе программы отличаются достаточно аскетичным интерфейсом, с минимальным набором элементов управления. В плане удобства работы интерфейсы также можно считать равнозначными. Единственный минус CuneiForm — дизайн в стиле давно почившей Windows 98, что может не сильно понравиться пользователям, привыкшим к красотам Vista и Windows 7. У FineReader же не всё идеально с интерфейсом в режиме редактирования документа — большее, чем у конкурента, число функций сказалось не самым лучшим образом.
…и по уму
Обычно по уму провожают, но в нашем случае умом будут считаться заявленные характеристики испытуемых программ.
В этом раунде победу, как ни крути, придётся отдать FineReader — планомерно развиваясь на протяжении последних 5 лет, он успел заметно обогнать конкурента. Впрочем, и возможностей CuneiForm будет более чем достаточно для рядового пользователя. Он умеет открывать графические файлы, принимать изображения со сканера, автоматически производить разметку документа, распознавать таблицы и, конечно же, текст, форматировать распознанный документ в Word-подобном редакторе и экспортировать результаты свое работы в Word и Excel. Единственный существенный недостаток бесплатной программы — невозможность работы с документами в формате PDF.
FineReader в добавок к уже перечисленным функциям умеет работать с PDF (открывать для распознавания и сохранять), получать изображения с цифровых фотокамер, автоматически определять угол наклона распознаваемого документа и очищать изображение от мусора, сохранять результат работы в форматах последних версий Office (docx, xlsx), распознавать штрих-коды и работать на многоядерных процессорах (с соответствующим приростом производительности).
Лицом к лицу
В качестве тестового задания мы использовали несколько образцов разной степени сложности, однако полная картинка открылась уже на самом простом (как нам казалось) тесте. Исходное задание было таким: распознать сфотографированный на цифровую камеру лист формата А4, на котором в два столбца размещался текст, набранный шрифтом Times New Roman кегля 12pt (см. рисунок). Задача усложнялась тем, что текст на изображении был повернут под углом примерно 3 градуса, из-за плохих условий съёмки был немного размыт, а в добавок имелись оптические искажения, вызванные тем, что лист при фотографировании был незначительно изогнут.

Для CuneiForm распознавание этого документа оказалось задачей почти не разрешимой. Подумав всего 5 секунд, программа выдала результат, в котором действительно правильно было распознано менее 10% слов. Остальное было распознано либо с ошибками, либо превратилось в нечитаемый мусор.
FineReader показал гораздо лучший результат: ни одной ошибки и около двух десятков «сомнительных» символов (почти все они в итоге оказались верными — программа просто перестраховывалась).
Опыт был повторён после небольшой зачистки документа в графическом редакторе: вычищены шумы, увеличена резкость, текст расположен строго горизонтально (при этом символы были немного искажены, поскольку разрешение изображения оставляло желать лучшего).
Такое вмешательство принесло свои плоды: CuneiForm увеличил число правильно распознанных символов примерно до 20%. В случае с FineReader результат практически не изменился.
Дальнейшие опыты только подтвердили первое впечатление: бесплатная программа, увы, устарела и в настоящее время годится лишь для работы с идеально отсканированными документами с достаточно простой структурой. Правда, к её чести стоит сказать, что в текстовый редактор она передаёт документы более корректно (FineReader при передаче описанного выше примера перемудрил с разметкой, в результате чего дальнейшее редактирование документа в OpenOffice Writer превратилось в весьма нетривиальную задачу).
Итого
Во многих областях OpenSource ПО уже давно на равных конкурирует с коммерческими разработками, а кое-где даже постепенно вырывается вперёд. Однако в сфере OCR время массового распространения открытых программ ещё не настало. CuneiForm оправдывает лишь тот факт, что эта система находится на начальной стадии своего OpenSource-пути и у неё всё ещё впереди. А пока пользователям, желающим получать гарантированны результат, по-прежнему придётся платить. И скорее всего их покупкой будет одна из последних версий FineReader.

Представляем вашему вниманию программы для распознавания и сканирования текста, с помощью которых можно оптимизировать процесс оцифровки документов, рукописных или бумажных книг.

Рассматриваемые нами приложения легко переводят png, jpg, pdf и «бумажные файлы» в удобный для редактуры в Word формат и другие офисные ПО, редактируют распечатанный или сфотографированный материал в полноценный текст.
Программы
Русский язык
Лицензия
Рейтинг
Обработка текста
Встроенный словарь
ABBYY FineReader скачать
Приложение легко распознает печатные символы и преобразовывает отсканированные документы в цифровые форматы. Считается лидером в своей категории, поскольку выполняет свои задачи качественно и быстро, в отличие от подобных аналогов. Эбби ФайнРидер имеет свою OCR технологию обработки материала, функции для захвата данных на разных источниках, а также инструменты для обработки PDF-объектов, их редактирования и комментирования. Также доступна автоматизированная конвертация, сохранение разметок, обработка текста на разных языках, поддержка подключаемых устройств и интегрированный редактор. Бесплатная версия ограничивает работу софта после 15 дней использования.

OCR CuneiForm скачать
Программа специализируется на идентификации сканированного или сфотографированного текста, сохраняя его структурирование и гарнитуру шрифта. Понимает любой печатный шрифт, отправляет распознанный результат во встроенный редактор текста, переделывает электронные копии и графические файлы в удобный вид для редактуры. В состав комплекса входят два программных обеспечения для пакетной и одиночной обработок. Распознанные документы легко сохранить в удобном формате или отыскать их в поиске. Дополнительно прога может определять таблицы, текстовые блоки и графические картинки вне зависимости от сложности, объема и четкости текста.

Adobe Reader скачать
Популярный просмотрщик всех видов PDF-файлов с базовыми функциями работы с документацией. Позволяет просматривать, копировать, менять ориентацию или отправлять на печать документы. Для слабовидящих юзеров доступна опция масштабирования, увеличивающая размер шрифта до нужных параметров. Также можно воспользоваться функцией трёхмерного изображения и воспроизведения интегрированных в мультимедийный контент объектов. Доступен поиск в PDF картах, портфолио и файлах, а также комментирование файлов, присоединение электронных подписей и настройка плагинов для веб-навигаторов. Из минусов бесплатной версии отметим ограниченный только просмотром функционал.

WinScan2PDF скачать
Портативная утилита для считывания данных со сканеров и сохранения материала в PDF. Софт переводит содержимое документов в цифровые форматы, одновременно обрабатывает несколько книг с последующим сохранением в один файл с соответствующим количеством страниц. В настройках можно выбирать качество сохраняемой работы, создавать много страниц в одном документе, менять язык интерфейса. ВинСкан2ПДФ позволит быстро отсканировать бумажную документацию, обработать сразу несколько страниц и создать многостраничный ПДФ.

VueScan скачать
Программа-имитатор работы драйвера для расширения функциональных возможностей разнообразных моделей сканеров. Быстро подключается к устройствам сканирования, работает с негативами, старыми фотоснимками и слайдами без потери качества. В пользовательских настройках можно настраивать все этапы сканирования, сохранять отсканированную документацию в TIFF, JPEG и PDF форматах, распознавать тексты, использовать глубокую настройку готовой работы и применять множество установок. Фри-версия накладывает водяные знаки на работу.

SimpleOCR скачать
Утилита распознает рукописный и машинный текст на датском, английском и французском языках, имеет интегрированный редактор и большой словарный запас. СимплеОЦР считывает данные со сканеров и проводит конвертацию материала в TXT, TIFF и DOC форматы, переводит напечатанный на бумаге текст и рукопись в цифровой формат, идентифицирует картинки и шрифты. Также доступно сравнение отсканированного ранее текста с полученным, а также внесение изменений. Бесплатная версия предоставляет только 14 дней распознавания текстов.

Readiris Pro скачать
Один из лидеров в категории OCR программ, который сканирует и распознает бумажную и рукописную документацию, работает с более 100 языками и имеет интегрированный редактор. Позволяет отсканировать и оцифровать материал, а с помощью редактора внести изменения. Реадирис конвертирует в формат изображения, таблицы и документа, работает с облачными хранилищами и ftp-папками, экспортирует в DJVU. В настройках можно улучшать качество документа, поворачивать его или сохранять в виртуальном хранилище. Ознакомительная версия активна 10 дней и дает на обработку только 100 страниц.

Microsoft OneNote скачать
Является дополнением к Office Mobile пакету и предоставляет расширения для создания списков задач, покупок или заметок. В функционале доступно создание маркированных списков, отметка галочкой выполненных пунктов, ввод рукописных примечаний сенсорным нажатием или цифровым пером, добавление графических картинок. Немаловажным плюсом утилиты является работа мобильной версии с OneDrive для хранения всех правок заметок, их просмотра или редактуры. Понятный русскоязычный интерфейс и бесплатное распространение станут приятными плюсами в работе с этой удобной прогой.

Freemore OCR Features скачать
Качественное ПО для оптического распознавания текста из изображений и ПДФ-документации. Доступно извлечение текста из картинки, которая получена с цифровой камеры, сканера или мобильного телефона, дешифровка и зашифровка символов, сохранение материала в TXT и Word, редактура метаданных, предпросмотр документации, применение пароля или цифровой подписи. Софт имеет методику сверхскоростной обработки и передовой кодировки, пресеты с оптимальной настройкой, поддерживает многоядерные процессоры. Продукт совместим со многими известными фирмами сканеров, открывает картинки разных форматов, защищает работу паролем и в реальном времени быстро обрабатывает материал.

TopOCR скачать
Программа легко оптически распознает, редактирует и читает текстовую документацию. Благодаря своей многофункциональности может распознать и отсканировать материал, а также внести изменения с помощью опций графического редактора и электронного переводчика. Приложение озвучивает текст на 11 языках, быстро переводит документацию и создает аудиокниги. Поддерживает многие распространенные форматы, работает напрямую со сканером и озвучивает текст. Из минусов отметим отсутствие русскоязычной поддержки.

Данный материал является частной записью члена сообщества Club.CNews.
Редакция CNews не несет ответственности за его содержание.
Существуют специальные программы, которые умеют «читать» изображения с текстом. Конвертация заключается в том, что на основе алгоритма текст, изображенный на отсканированном документе, преобразовывается в предложения. Вся сложность в том, что на картинке программа видит не набор букв, а растр, точечную структуру. Все эти точки, имеющую различную форму, расшифровываются специальными утилитами, превращая его в обыкновенный текст, с которым можно в дальнейшем работать.
Программы распознавания текста применяются при переводе различной бумажной литературы и документов в электронный вид. Библиотеки и архивы таким же образом переводятся в цифровой вид.
Автоматическая оцифровка с помощью программы выигрывает у ручного метода набора в скорости, поэтому этот метод так распространен. Мы расскажем вам о пяти лучших программах распознавания сфотографированных текстов.

ABBYY FineReader 10

FineReader — флагман среди программного обеспечения, распознающего тексты на картинках. Эта программа широко распространена среди обычных пользователей и профессионалов, занимающихся оцифровками. Популярность обусловлена качеством ее работы. FineReader отлично обрабатывает кириллицу и еще 178 языков.
Единственный недостаток программы, если можно так выразиться, ее платность. Но пользователи, опробовавшие ее работу в течение двух недель и отсканировавшие ряд страниц, покупают продукт, поскольку он, однозначно, стоит своих денег.
FineReader умеет «считывать» текст с любых изображений, причем не самого высокого качества. С помощью программы вы переведете в цифровой вид любой документ: от обычного изображения до сканированной страницы.
Плюсы:
- Четко распознает текст;
- Читает множество языков;
- Не предъявляет больших требований к качеству картинки, документа, фото.
Минусы:
- Бесплатная версия ограничена временем (две недели) и количеством отсканированных страниц (55).
OCR CuneiForm

CuneiForm оптически распознает тексты на графических файлах и приводит их в редактируемый вид. Утилита выпускается в одной версии, бесплатной, и отличается от предыдущей программы качеством распознавания. Но это не смущает, и многие используют бесплатный софт, считая, что его функциональные возможности отлично справляются с работой.
Любопытная информация! CuneiForm умеет читать не только графику с текстом, но и разнообразные таблицы. И в том числе, если таблицы идут сплошным текстом, без разлиновки.
С помощью этой программы вы не только переведете текст в цифровой вид, но и сохраните шрифт и размер высоты букв. База шрифтов CuneiForm обширна, утилита даже умеет распознавать отсканированные, отпечатанные на машинке, изображения.
Для более четкой расшифровки текста в утилите используются специализированные словари. Эти словари постоянно пополняются, поэтому у CuneiForm богатый запас слов.
Плюсы:
- Бесплатная версия программы;
- Текст корректируется для точности с помощью словарей;
- Расшифровывает любые изображения, даже некачественные;
- Сохраняет структуру документа, даже его форматирование.
Минусы:
- Погрешности в текстах;
- Поддерживается всего 24 языка.
WinScan2PDF

WinScan2PDF — компактная утилита, сканирующая любые документы. Она выпускается в виде переносимого файла, portable-версии, которую не надо устанавливать на компьютер и прочие устройства. Утилита мгновенно читает любой текст и сохраняет его только в PDF-документ.
Программой очень легко пользоваться даже самым неподготовленным пользователям. Чтобы получить необходимый результат, вам придется нажать всего лишь три кнопки:
- Выбрать графический файл;
- Указать место загрузки;
- Запустить процесс.
Программа способна быстро обрабатывать сразу много графических файлов, поэтому и так популярна среди пользователей: новичков и профессионалов.
Плюсы:
- Отсутствие дистрибутива;
- Мгновенная расшифровка текстовой графики;
- Минималистский, удобный интерфейс.
Минусы:
- Вес утилиты всего 55 Kb;
- Текст можно сохранить только в формате переносимого документа.
SimpleOCR

SimpleOCR — бесплатное приложение, распознающее отсканированный текст оптически, но только на иностранных языках. Русского языка, к сожалению, нет ни в пакете интерфейса, ни в списке поддержки. А в остальном утилита отлично справляется с работой, распознавая даже рукописные тексты.
Тексты, получаемые на выходе, отличаются высоким уровнем точности. Также с помощью утилиты можно извлечь графический файл и удалить шум. Еще одной отличительной особенностью является наличие встроенного редактора текста, что очень удобно в использовании.
Плюсы:
- Работает корректно, с высокой точностью;
- Умеет удалять шумы с графики;
- Позволяет сразу редактировать полученные тексты.
Минусы:
Freemore OCR

Freemore — бесплатная, простая утилита, которая легко и быстро читает тексты с различных графических файлов, даже с нескольких сканеров одновременно, и переводит их в удобный формат. Помимо этого утилита умеет обрабатывать сразу много страниц.
В интерфейсе нет поддержки русского языка, но даже, несмотря на это, утилита распространена и популярна среди отечественных пользователей, поскольку очень проста в использовании.
Возможностей чтения и редактирования материалов в интернете огромное количество.
Так как многие файлы распространяются по сети без возможности редактирования, порой приходится использовать специальные программы для распознавания текста.
Я расскажу о 9 наиболее популярных и действенных вариантах, плюс приведу основные преимущества и недостатки каждого приложения.

ABBYY FineReader

Это, пожалуй, самая лучшая программа, которая сканирует и распознает текст с изображений в формате jpg, jpeg, png, gif, bmp, а также pdf документов. Полученный материал она конвертирует в файлы форматов doc, rtf, xls, html и pdf с возможностью редактирования. Не важно, каким способом получен исходник – сканированием через МФУ или сканер, съемкой через цифровой фотоаппарат или смартфон.
FineReader работает со 179 различными языками мира, благодаря наличию технологии ABBYY OCR она распознает слова с максимальной степенью точности. В ней есть возможность сохранения оформления и стиля, также обработки и отправки полученного материала по почте или посредством публикации в интернете. Интерфейс русскоязычный, понять, как им пользоваться сможет любой, тут запутаться крайне сложно.
Есть еще версия Professional – прекрасный вариант для офисных сотрудников, которые сканируют и обрабатывают файлы или фотографии каждый день.
Плюсы
Минусы
ABBYY Screenshot Reader

Отличие приложения ABBYY Screenshot Reader от предыдущего состоит в схеме распознавания. Если в FineReader вы просто загружаете документ и работаете, то в этой утилите все иначе – она просто считывает данные с экрана и преобразует их.
Работает Screenshot Reader в двух режимах – создании скриншотов и распознавании текста с экрана. Если вам нужно второе, сначала просто нажимаете на комбинацию клавиш, выбираете язык и принцип захвата, выделяете область, подтверждаете действие и ждете несколько секунд. Полученные данные сохранятся в выбранном вами формате. В приложение встроен словарь и переводчик, также другие полезные функции от компании ABBYY.
По умолчанию сервис распознает тексты на 5 языках – английском, русском, русско-английском, французском и немецком. Есть возможность добавления других языковых пакетов.
Плюсы
- Быстрый запуск посредством нажатия на комбинацию клавиш.
- Встроенная функция перевода и проверки орфографии.
- Есть запись экрана с функцией отсрочки.
- Распознавание текста с любого окна, даже в защищенном режиме.
- Создание скрина с любой, даже защищенной области экрана.
- Сохранение в нескольких форматах – rtf, txt, doc или xls.
Минусы
- Для копирования полученных данных в редактор нужно выделять материал вручную.
- Открыть файл через этот сервис не получится – только ручной захват экрана.
- Приложение не бесплатное. Есть бессрочная лицензия, но она стоит 1490 рублей. А срок действия пробной версии составляет всего лишь 7 дней, также в ней есть ограничение до 100 страниц.
Adobe Acrobat

Adobe Acrobat – ничем не уступающая предыдущим программа, правда используемая не совсем для распознавания текста с фото или файлов. С ее помощью можно создавать и редактировать различные документы pdf, конвертировать их в другие форматы, редактировать отдельные элементы и так далее.
Есть две ее версии – обычная и Pro, с расширенным функционалом. Естественно, вторая распространяется не бесплатно. Standard без акции обойдется по 1777 рублей в месяц, а расширенная Pro будет стоить 1932 рубля, и это только для физических лиц. Предусмотрен 7-дневный пробный период.
Стоит учитывать, что данная программа способна работать только с файлами формата pdf. Отредактированный документ можно перевести в формат Блокнота, Word, Excel, PowerPoint, картинки jpeg и так далее.
Плюсы
- Создание и редактирование файлов формата pdf.
- Добавление маркеров, закладок или комментариев.
- Конвертирование pdf-файла в другие форматы.
- Удобный и развитый текстовый редактор.
- Есть возможность восстановления поврежденных участков документа.
- Регулярные обновления.
Минусы
- Дорогая плата за пользование полноценной версией.
- Высокие системные требования.
- Крайне малый пробный период.
Freemore OCR

Приложение Freemore OCR не отличается большим набором функций, но зато распространяется абсолютно бесплатно. С его помощью можно расшифровать текст с файлов таких форматов, как jpeg, tiff, bmp, gif, png, wmf, psd, tga и многих других. Встроенная технология Side-by-Side качественно разделяет картинки и символы, поэтому никаких лишних блоков в результате не выйдет. Все распознанные файлы можно сохранить в формате doc, txt и pdf.
В приложении есть предварительный просмотр готового документа. С помощью специального средства можно увеличивать или уменьшать масштабы. К некоторым файлам возможно прикреплять цифровые подписи. В общем, здесь есть все для удобного сканирования текстов со сканов или документов.
Плюсы
- Абсолютно бесплатное использование без каких-либо ограничений.
- Встроенная возможность кодирования и декодирования.
- Можно шифровать файлы или добавлять водяные знаки.
- Программа не грузит систему.
- Удобный, простой дизайн.
Минусы
- Нет полноценного захвата русскоязычного текста.
- Интерфейс на английском языке.
Kofax OmniPage

Kofax OmniPage – одна из лучших профессиональных программ для распознавания текста с картинки. Она может конвертировать любой документ в текстовый редактор. Итоговый вариант легко конвертируется в Word. Правда, такая крутая штука далеко не бесплатная и даже не дешевая – стандартный пакет стоит 149 долларов, Ultimate стоит 499 долларов, и дальше только дороже. Есть бесплатная версия, но нигде не указано, сколько она длится.
Плюсы
- Невысокие требования к ОС.
- Отлично подходит как для индивидуального, так и для корпоративного пользования.
- Поддержка чтения и конвертирования файлов в разные форматы.
- Удобный внутренний текстовый редактор.
- Эффективное и качественное сканирование текстов даже с поврежденных фрагментов.
Минусы
- Неудобный для новичков интерфейс.
- Большая стоимость пакета.
- Необходимость подключения к сети при работе.
Microsoft OneNote

Microsoft OneNote – это скорее приложение для учета записей и повседневных дел с функцией распознавания текста с рисунков. В нем есть возможность чтения с английского, испанского, немецкого, французского, ну и с русского языка. Всего-то и нужно, загрузить в текущую страницу нужное изображение, правым кликом по мышке вызвать контекстное меню и выбрать в нем пункт «Копировать текст из рисунка». После этого все ее содержимое окажется в буфере обмена.
Минус: наверно, некачественные или нечеткие надписи программа различить не сможет, так как она не предназначена специально для распознавания текста с картинок. Это компенсируется бесплатностью сервиса и включением в пакет Office. Соответственно, между всеми приложениями, входящими в этот пакет, будет очень удобно переключаться и экспортировать данные.
Плюсы
- Бесплатное распространение и использование.
- Интеграция с другими сервисами Microsoft Office.
- Распознавание текста с картинок на 5 различных языков.
Минусы
- Ограниченный функционал программы в распознавании текстовых материалов.
OCR CuneiForm

OCR CuneiForm – это лучший бесплатный аналог программы ABBYY FineReader. Это приложение будет попроще в плане использования, не так требовательно к ресурсам, но и развивается не столь сильно. Оно отлично распознает как отсканированные, так и сфотографированные материалы. И, в отличие от FineReader, в итоговом документе сохраняются исходная структура и шрифты.
Эта утилита отлично сканирует фото и файлы формата jpeg, tiff и так далее, конвертируя полученный материал в Word или любой другой документ из пакета Microsoft Office. Дополнительно в ней возможно проверить редактируемый текст на наличие ошибок. Только поддерживаемых языков не совсем много – в районе 20, но русский входит в их число.
Плюсы
- Алгоритмы распознавания текстовой информации часто обновляются.
- Бесплатное скачивание и использование.
- Обработка файлов и фото как единицами, так и пакетами.
- Отличная обработка плохих копий и сканов.
- Распознавание текста, картинок и таблиц.
- Сохранение исходного форматирования и структуры шрифтов.
- Хорошая оптимизация на ОС Windows.
Минусы
- В процессе распознавания текста приложение немного тормозит.
- Поддерживается небольшое количество языков.
Readiris

Уникальная и очень мощная программа Readiris распознает тексты с помощью сканера или МФУ, также с файлов форматов pdf, djvu, tiff и jpeg. В ней предусмотрена интеллектуальная система распознавания бумажных сканов с рукописными данными. В целом, разборчивый и понятный почерк она отлично распознает, причем на украинском и русском языках.
Всего предусмотрено 3 версии – PDF, Pro и Corporate. Отличаются они по возможностям и стоимости. Самой оптимальной будет вторая версия, так как в ней есть основные компоненты и поддержка практических 138 языков мира.
Плюсы
- Воспроизведение полученного материала в аудио и конвертация в форматы mp3 или wav.
- Извлекает текст из файлов разных форматов, в том числе djvu.
- Поддержка чтения и распознавания 138 языков мира.
- Простота в использовании – весь процесс можно провести в несколько простых кликов.
- Сохранение исходного форматирования текста.
- Экспорт полученных данных в форматы Word, Excel, PDF, OpenOffice или XPS.
- Сжатие изображений без потерь.
Минусы
- Платный пакет. Стоимость его может варьироваться от 50 до 200 долларов в зависимости от версии приобретаемой программы.
- Большинство функций не очень нужны пользователям.
Scanitto

И последняя программа в нашем обзоре – Scanitto, которая может распознать текст с копий. С ее помощью можно объединить несколько файлов в один формата PDF или TIFF. Интерфейс Scanitto выполнен в виде альтернативного сканера. В нем можно захватывать определенные фрагменты через специальное оборудование, а затем импортировать выделенный материал в редактор.
В редакторе возможно выделять и помечать какие-то элементы, также разворачивать в нужном направлении. Программа распознает около 7 языков, в том числе русский. Готовый материал легко сохранить в формате bmp, jpeg, tiff, png, pdf или даже gif.
Плюсы
- Загрузка готового материала в различные онлайн-хранилища или социальные сети.
- Изменение разрешения изображения по усмотрению.
- Множество полезных функций для качественного распознавания текста.
- Недорогая лицензия. Если покупать на 1 компьютер, то она обойдется, грубо говоря, в 600 рублей, а в неограниченном варианте (который подойдет для организаций) стоимость составляет 6600 рублей.
- Подробная настройка параметров сканирования и копирования.
- Регулярные обновления программного обеспечения.
- Русскоязычный простой интерфейс.
Минусы
- Ограничения в бесплатной версии. Ей можно пользоваться только в течение 30 дней.
На этом, пожалуй, обзор закончен. Выбирайте любую программу для распознавания текста на свое усмотрение, учитывая все возможные плюсы и минусы. Есть, конечно, еще различные онлайн-сервисы, но их надежность и качество сканирования оставляют желать лучшего.
Технология OCR (Optical Character Recognition) может быть использована для преобразования печатной копии документа в электронную версию. Например, если сканируется многостраничный экземпляр в файл TIFF, то его загружают в OCR-программу, которая распознает текст, и далее переводят в редактируемый файл. Некоторые приложения позволяют сканировать страницы и преобразовывать содержимое в документ за один шаг.
Хотя технология изначально была разработана для оптического распознавания печатных символов, она также может использоваться для рукописных. Например, почтовые службы, такие как USPS, используют программное обеспечение OCR для автоматической обработки писем и посылок, считывая адрес.
Области применения OCR
Вам будет интересно: Замена Microsoft Office: альтернативные системы, рейтинг лучших, рекомендации и отзывы

OCR расшифровывается, как Оптическое Распознание Символов. Это широко распространенная технология распознавания текста внутри изображений в виде отсканированных документов и фотографий. Технология используется для преобразования практически любого типа изображений, содержащих письменный, рукописный или напечатанный текст в машиночитаемые текстовые данные.
OCR стала популярной в начале 1990-х годов при попытке оцифровки исторических материалов. С тех пор метод претерпел значительные улучшения, и в настоящее время обеспечивает практически идеальную точность оптического распознавания символов. Расширенные методики, такие как Zonal OCR, используются для автоматизации сложных рабочих процессов на основе преобразования машинописных текстов в цифровые документы. После того как отсканированный материал прошел обработку, текст можно редактировать с помощью программ, таких как Microsoft Word или Google Docs, которые являются текстовыми редакторами.
Вам будет интересно: Lightshot: как пользоваться программой
До того как появилась эта технология, единственным вариантом оцифровки печатных документов был ручной набор текста. Это не только занимало много времени, но и приводило к неточностям и ошибкам при воспроизведении копии. OCR часто используется в качестве «скрытой» технологии во многих известных системах и службах, включающих автоматизацию ввода данных и индексацию для поисковых систем, автоматическое оптическое распознавание символов номерных знаков, а также помощь слепым и слабовидящим людям.
Процесс определения точности текста
Каждый шаг процесса OCR важен для определения точности окончательного текста. Он начинается с преобразования печатного документа. Если на нем есть следы, пятна и плохая контрастность, программное обеспечение при распознавании будет делать ошибки, а результат получится некорректным. Чтобы избежать этих проблем, можно сделать улучшенную ксерокопию печати.
Первый шаг работы - сканирование распечатанного текста. Программное обеспечение OCR работает с файлами изображений. Сканер или хорошая цифровая камера создают четкие фотокопии документов. Лучше преобразовать отсканированные файлы в черно-белом формате. Процесс является двоичным. С помощью черного цвета на картинке происходит распознавание текста OCR, а белый, в свою очередь, выступает фоном.
Вам будет интересно: Программы для учебы: обзор. Обучающие программы для школьников
Вторым этапом является определение символов. Скорость этого процесса зависит от используемой программы OCR. Большинство из них анализируют каждый элемент один за другим. Целью приложения является определение знаков, но хорошие программы распознают не только текст, но и таблицы, и другие элементы макета.
Процесс не идеален, так как есть много факторов, которые влияют на точность. Какие программы предназначены для оптического распознавания символов, рассмотрим ниже. А пользователю самостоятельно выбирать, что лучше. OCR имеют встроенные средства проверки правописания и выделяют слова с ошибками. Некоторые из них настолько сложны, что отмечают несоответствие слов и грамматические ошибки, пользователю остается лишь выполнить необходимую корректировку.
Последний этап - сохранение готового документа в нужном формате. Если приложение не выдает необходимый, то можно воспользоваться многочисленными бесплатными конвекторами онлайн.
Оптическая технология для Брайля

Технология Optical Character Recognition (OCR) предоставляет слепым или слабовидящим людям возможность определить текст и произносить его вслух. При этом используется речевой вывод, а также отображается информация на дисплее Брайля.
Существует три основных элемента систем оптического распознавания символов: получение изображения, распознавание и чтение текста. Сначала распечатанный документ захватывается камерой, затем программное обеспечение OCR преобразует его в распознанные символы и слова, а после этого синтезатор в системе произносит определенный материал вслух или отображает на дисплее Брайля. Информация может быть сохранена в электронном формате на устройстве, на котором запущено ПО OCR, или в памяти автономного устройства.
Процесс учитывает логическую структуру языка. Система сделает вывод, что, например, союз «этом» в начале предложения является ошибкой и должен читаться, как «это». Она использует лексикон и применяет методы проверки правописания, аналогичные тем, которые используются во многих текстовых редакторах.
Все системы OCR создают временные файлы, содержащие символы и макет страницы. В некоторых системах они могут быть преобразованы в форматы, которые можно найти с помощью широко используемых компьютерных приложений, таких как текстовый редактор, электронная таблица и базы данных.
Выбор программ для распознавания текста

Рекомендуется осознано подойти к выбору программного обеспечения для распознавания текста. Лучше провести собственное тестирование или учесть мнение продвинутых пользователей.
Тестирование проводят с учетом следующих факторов:
Популярное ПО для мобильных устройств
Вам будет интересно: Что такое в "Фотошопе" смарт-объект? Его назначение
OCR отлично подходит для переноса текста из физических источников непосредственно в цифровой документ. Существуют различные типы программ и приложений для настольных и мобильных устройств. Они различны по цене и имеют свои ключевые отличительные функции.
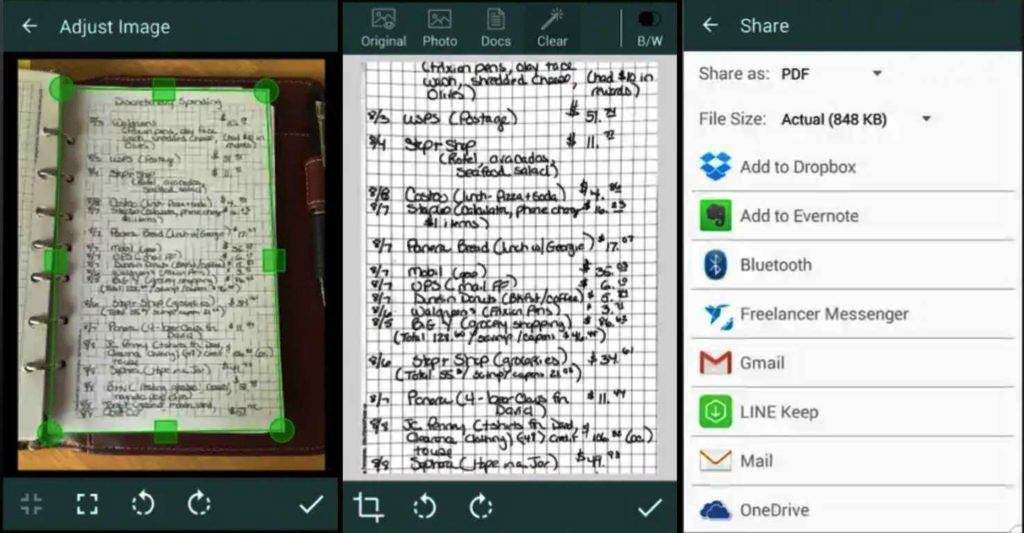
Наиболее популярные "Андроид"-сканеры:
Документы Google

Для тех, кто уже знаком с документами Google, можно использовать OCR, встроенный в Google Drive. Для достижения наилучших результатов шрифт должен быть установлен на Arial или Times New Roman. Можно улучшить результат, убедившись, что сканированное изображение имеет равномерное освещение и четкую контрастность. Фотоматериалы могут обрабатываться индивидуально в файлах: jpg, png, gif или в многостраничных документах PDF. Расширение поддерживает большинство языков.
У Google есть много обучающих программ и возможностей облачной обработки. Многие пользователи считают, что у сервиса нет достаточно продвинутых функций и опций. Тем не менее, если используется приложение Google Drive для Android, можно сканировать страницы прямо из приложения, используя камеру на смартфоне. В противном случае загружают документы с помощью сканера, подключенного к компьютеру, или любым другим способом, чтобы начать обработку распознавания в Google Диске. Для физических лиц на Google Диске предлагается бесплатный уровень хранения около 19 ГБ с возможностью расширения до 100 ГБ через Google One за 1,99 долл. США.
Оптическое распознавание Abbyy

Abbyy FineReader работает с документами уже давно. Это комплексное решение, как для бизнеса, так и для обычных пользователей. В нем можно получить все необходимые функции для извлечения содержания текстов из сканера с полной читаемостью, аккуратно организованные оцифрованные материалы. Помимо распознавания текстов и преобразования в PDF, Microsoft Office или другие форматы, программа также может сравнивать их, добавлять аннотации и комментарии.
Abbyy FineReader может конвертировать материал в пакетном режиме и обрабатывать множество выходных форматов на 192-х различных языках. Есть сопутствующие мобильные приложения, когда нужно выполнить быстрое сканирование с телефона.
Программное обеспечение не самое современное, но оно простое, функциональное и отлично справляется со своей работой. Утилита имеет прочную репутацию одного из лучших вариантов в области оптического распознавания символов. Можно воспользоваться бесплатной пробной версией. ПО стоит от 199,99 долл. США за стандартную разовую бессрочную лицензию.
Если кому-то покажется это дорогим вариантом, можно воспользоваться хорошей альтернативой ABBYY FineReader - онлайн версией. Она ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но поставляется со всеми другими функциями премиум-версии. Потребуется регистрация, чтобы получить доступ. Она поддерживает очень много форматов входных файлов, и можно выбрать выходные, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Облачный сервис Adobe Acrobat

Adobe Acrobat отвечает всем требованиям и предлагает впечатляющий список возможностей и опций, хотя цена немного круче, чем у конкурентов. Для всех функций оптического распознавания текста выбирают Pro версию Adobe Acrobat. DC означает «Облако документов», и довольно четко интегрируется с облачным решением Adobe, если нужно получить доступ к своим файлам с любого компьютера. Также есть простая и бесшовная интеграция со всем остальными сервисами Adobe, например, таким как Photoshop.
Если пользователь решит оплатить Pro версию Adobe Acrobat DC, он получит все инструменты распознавания текста, возможность добавлять комментарии и отзывы к содержанию, специализированный сервис для сканирования таблиц, возможность быстрого сравнения двух документов вместе. Материалы можно редактировать прямо на экране через несколько секунд после их сканирования.
Лучшее бесплатное программное обеспечение
Free OCR to Word - это лучшее бесплатное программное обеспечение для оптического распознавания символов, использующее новейшие механизмы. Tesseract - самый мощный инструмент для данного типа ПО и считается одним из самых точных методов. Программа поддерживает несколько форматов изображений и TIFF нескольких страниц. Этот сервис может быть использован совершенно бесплатно для извлечения текста из предоставленного фотоматериала.
Вам будет интересно: VMware - что это? Описание, установка, применение
Двигатель Tesseract был первоначально разработан Hewlett Packard Labs в 1985-1994 годах. Некоторые изменения были внесены в него в 1996 году. В 1995 году он был включен в тройку лучших механизмов распознавания. Он работает с Windows, Linux и Mac OS X. FreeOCR может обрабатывать изображения, имеющие многоколонный и многоязычный текст. Он обрабатывает форматы PDF и поддерживает устройства TWAIN такие, как сканеры, имеет широко распространенный интерфейс с двойным окном, настройки которого легко понять.
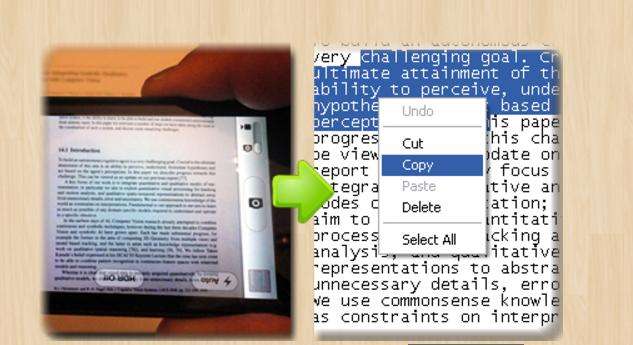
Free OCR to Word может сэкономить много времени без необходимости повторного ввода уже написанного произведения. Программа берет документ, отсканированный объект или изображение и преобразует его в читаемый, редактируемый и точный материал. ПО можно бесплатно загрузить в Word. OCR to Word оптимизирован для работы со всеми типами сканеров и имеет рейтинг точности 98 %, современный интерфейс, который позволяет легко получить доступ ко всем задачам, имеются функции поворота на случай, если фото не помещается на экране правильно. ПО извлекает текст из захваченных снимков с помощью смартфонов или цифровых камер с высокой точностью и качеством.
Распознавание символов в Linux
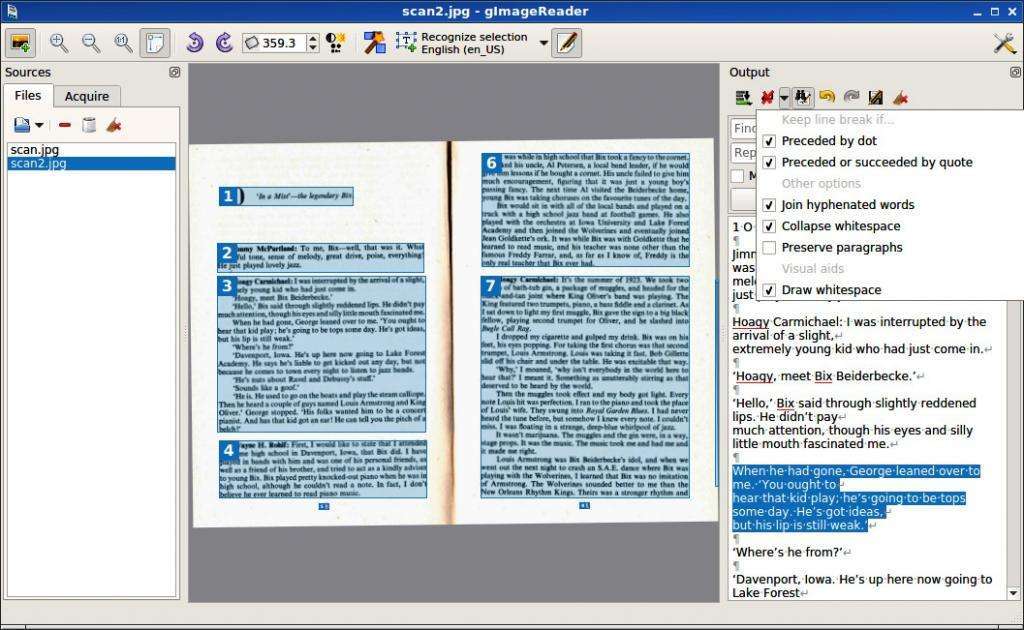
Набор OCRFeeder предоставляет удобный графический интерфейс Linux, который в основном является внешним интерфейсом для некоторых изображений, OCR и текстовых инструментов таких, как распечатка или проверка орфографии. Он не считывает символы сам по себе, но вместо этого использует другие приложения OCR через так называемые настройки «механизмов распознавания». Он имеет предопределенные параметры для Tesseract, CuneiForm, GOCR и Ocrad.
Пользователю нужно только установить в Ubuntu выбранные им движки - один или несколько и затем обнаружить их в настройках Feeder. Можно добавить другие движки и изменить эти параметры вручную. В одном приложении может быть несколько разных движков. Главное окно Feeder позволяет на лету выбрать, какой их них использовать для конкретной области, также есть настройка для выбора одного по умолчанию. Для выбора языка прочитанного текста, в случае с Tesseract и CuneiForm, необходимо добавить переключатель «-l» с соответствующим кодом языка / скрипта, например, «-l pol» для польского или «-l dan-frak» для датского к настройкам данного движка
Технология оптического распознавания печатных символов "Тессеракт" в начале могла распознавать текст только на английском языке, версия 2.x сделала ее многоязычной. При необходимости можно установить более одного словаря. Новые версии оцифровывают текст на основе ISO 963-2.
После успешной установки используют команду "tesseract>путь к изображению>базовое имя выходного файла". Tesseract автоматически придаст выходному документу расширение ".txt", можно указать опцию "-l", за которой следует код языка. Для версий Tesseract более ранних, чем третья, очень важно, чтобы изображение было в формате файла тегового значения и имело расширение ".tif", а не ".tiff". Командная строка должна выглядеть следующим образом:"$ tesseract ~ / input.tif output".
Где "input.tif" - это документ для преобразования, расположенный в домашней папке, а "output" - материал, который Tesseract создаст, как "output.txt". Часто отсканированные тексты хранятся в виде растрового рисунка в большом документе PDF. Используя ImageMagick, отдельные страницы могут быть извлечены в виде файлов TIFF для обработки с Tesseract. Следующий скрипт может помочь автоматизировать этот процесс.
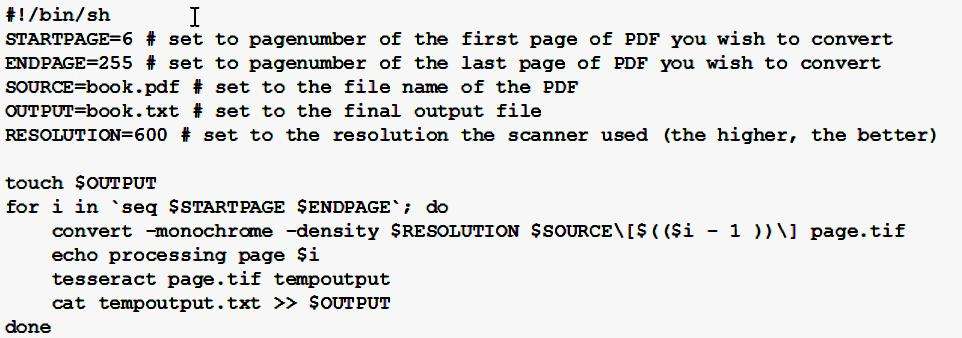
Программа CuneiForm - это еще одна система оптического распознавания текста, которая была первоначально разработана и основана на открытых источниках Cognitive Technologies. Версия Windows, которая имеет собственный графический интерфейс, может быть запущена с некоторыми результатами в Wine. Его порт Linux разрабатывается на Launchpad и хотя в настоящее время у него нет собственного графического интерфейса, CuneiForm может быть успешно запущен из графического интерфейса OCRFeeder.
Ниже приведен пример, как успешно преобразовать некоторые скриншоты изображений .jpg доски объявлений в Интернете в полезные текстовые файлы.

Pdfocr - это скрипт, который выполняет OCR для многостраничных файлов PDF, а также внедряет его обратно в виде текстового слоя с возможностью поиска. Он может использовать "Тессеракт" или клинопись в качестве механизма распознавания. Сам скрипт может быть получен из Github или из PPA. Чтобы запустить команду, прописывают в терминале: "pdfocr -i input.pdf -o output.pdf".
Технология OCR не стоит на месте, в перспективе признание интеллектуальной системы оптического распознавания символов - ICR. Этот стандарт является передовым. Большая часть ICR имеет самообучающуюся систему, называемую нейронной сетью, которая автоматически обновляет базу данных для новых образцов почерка. Она расширяет полезность сканирующих устройств для целей обработки документов от распознавания печатного текста (функция OCR) до рукописных материалов и могут достигать более 97 % степени точности при чтении рукописного материала в структурированных формах.
Читайте также: