
Удалить строку в excel pandas
Pandas представляет нам отличные инструменты для обработки данных, в том числе для удаления той информации, которая нам не нужна. В этой статье мы рассмотрим различные способы удаления строк из Dataframe Pandas.
import pandas as pd
city_data = 'Город':['Москва', 'Казань', 'Владивосток', 'Санкт-Петербург', 'Калининград'],
'Дата основания':['1147', '1005', '1860', '1703', '1255'],
'Площадь':['2511', '516', '331', '1439', '223'],
'Население':['11,9', '1,2', '0,6', '4,9', '0,4'],
'Погода':['8', '8', '17', '9', '12'] >
city_df = pd.DataFrame(city_data)
city_df
В Pandas для удаления строк, а также столбцов используется метод drop. Его синтаксис следующий (обратите внимание, что необязательно использовать все параметры, можно только те, которые необходимы нам):
drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise'), где:
- labels – номера или названия столбцов для удаления
- axis – значение 0, если вы хотите удалить строки, либо 1, если планируете удалять столбцы
- index – определяет, какие строки надо удалить
- columns – определяет, какие столбцы надо удалить
- inplace – изменяет оригинальный Dataframe, если параметр равен True
- errors – игнорируются ошибки, если параметр задан как ignore
Способ 1. Удаление строки в Pandas по ее индексу
Для каждой строки в Dataframe Pandas присваивает индекс, обычно это число. В нашем учебном Dataframe, к примеру, у Москвы индекс 0, а у Калининграда 4. Давайте уберем запись с Владивостоком:
Обратите внимание, что по умолчанию метод drop не изменяет исходный dataframe, если вы хотите, что бы это было сделано, добавьте параметр inplace=True

Способ 2. Удаление строки в Pandas по ее содержанию
Предположим, нам надо убрать строку с названием города «Казань», но мы не знаем его индекса и хотим ее удалить по названию. Для этого мы должны сначала изменить столбец с индексами и вместо цифровых значений задать данные из столбца «Город»:
Теперь, когда в качестве индексов у нас названия городов, мы можем выполнить поставленную перед нами задачу:
Мы можем удалить несколько строк по их содержанию в Pandas, перечислив их через запятую в квадратных скобках:

Способ 3. Удаление строки в Pandas по условию
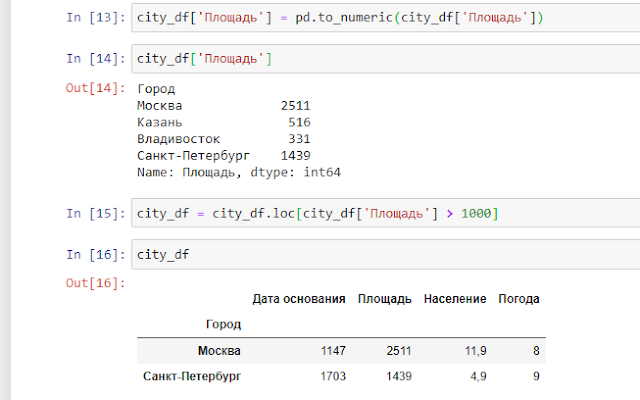
При помощи метода loc мы можем удалять строки по условию, к примеру мы хотим убрать из Dataframe те города, у которых площадь меньше 1 000 км2.
Так как мы будем применять математические условия, то сначала столбец «Площадь» мы должны перевести в формат int64:
Далее при помощи метода loc мы передадим в Dataframe отфильтрованные строки, а именно те, которые удовлетворяют условию, что Площадь > 1 000 км2
Спасибо за внимание. Дочитавшим до конца – традиционный бонус, наш ноутбук по этой статье.
P.S. Рекомендую еще ознакомиться с нашей статьей «Как из Pandas удалить столбец?».
В этом уроке рассмотрим основные моменты при работе с пакетом Pandas, который позволяет работать с Excel данными, как с двухмерными таблицами. Мы изучим как работать с самой таблицей, как массивом данных, с отдельными столбцами и строками, а также научимся делать отборы по условиям.

Для начала подготовим Excel файл с примером, который будем использовать в качестве источника данных (всю обработку данных будем делать в Python, без сохранения в Excel, для ускорения работы). Файл должен содержать лист "Данные" с такой информацией:

Сохраните файл с названием "Excel_Python-3.xlsx". Теперь запускаем Spyder, создаем новый скрипт и туда вносим следующий код, который позволит нам прочитать данные из вышеуказанного Excel файла в DataFrame, который мы будем использовать сегодня в примерах. Скрипт сохраняем в ту же папку, куда сохранили Excel файл.
import xlwings as xw
import pandas as pd
wb=xw.Book('Excel_Python-3.xlsx')
data_excel = wb.sheets['Данные']
data_pd = data_excel.range('A1:D7').options(pd.DataFrame, header = 1, index = False).value
print (data_pd)
Итак, данные прочитаны, внесены в DataFrame data_pd, с которым мы будем работать в дальнейшем.
Таблица
data_pd.shape - функция показывается количество строк и количество столбцов в таблице. В нашем случае получим (6, 4), т.е. в нашей таблице 6 строк (заголовок не считается) и 4 столбца.
data_pd.info() - получаем общую сводку о таблицу, в т.ч. какие столбцы, их названия, тип данных в столбцах, количество не пустых элементов. При выполнении функции на обучающем примере мы получим:
RangeIndex: 6 entries, 0 to 5
Data columns (total 4 columns):
Фамилия 6 non-null object
Имя 6 non-null object
Возраст 6 non-null float64
Доход 6 non-null float64
dtypes: float64(2), object(2)
memory usage: 320.0+ bytes
Работа со строками
data_pd = data_pd.append(, ignore_index=True) - Функция Append добавляет строку в таблицу. В качестве первого аргумента в фигурных скобках мы указываем те данные, что хотим добавить в формате 'Название столбца' : 'Значение', вторым аргументом мы говорим о том, что нам не важно в какое место таблицы добавится строка (по умолчанию в конец таблицы).
data_pd.drop([0, 1], axis=0, inplace=True) - Функция Drop удаляет строки. Первым параметром в квадратных скобках мы указываем номера строк, которые хотим удалить (нумерация строк начинается в Pandas с 0), вторым аргументом указываем что хотим удалить строку (axis=0) или столбец (axis=1), последним аргументом говорим о том, что измения должны быть произведены непосредственно в той таблице, с которой мы работаем (inplace=True), в противном случае (inplace=False) Pandas создаст копию таблицы, где удалит указанные строки, что может привести к путаницу и ошибкам.
data_pd.head(3) - Выводит указанное количество строк с начала таблицы, в данном случае 3.
data_pd[:3] - Функция аналогичная head, получаем указанное количество строк с начала таблицы.
data_pd[-3:] - Получаем указанное количество строк с конца таблицы.
Работа со столбцами
data_pd.columns - Выводит названия столбцов в таблице. В нашем случае при выполнении функции получим следующее: Index(['Фамилия', 'Имя', 'Возраст', 'Доход'], dtype='object')
data_pd.dtypes - Выводит тип данных в столбцах. В нашем случае:
data_pd['Пол'] =['Муж.','Муж.','Муж.','Муж.','Муж.','Муж.'] - Добавляем новый столбец. В левой части в квадратных скобках указываем название столбца, в правой части - что в этом столбце должно содержаться. Обратите внимание, что количество записей должно равняться количеству строк в таблице, иначе получите ошибку "Length of values does not match length of index".
data_pd.drop(['Фамилия'], axis=1, inplace=True) - Функция Drop, как и говорилось ранее, удаляет столбец или строку. В данном случае в качестве первого параметра в квадратных скобках указываем название столбца, далее указываем что удаляем именно столбец (axis=1), и не забываем указать что измения должны быть произведены непосредственно в той таблице, с которой мы работаем (inplace=True).
data_pd[['Фамилия', 'Имя']] - Получаем данные только по отдельным столбцам, а не по всей таблице в целом.
Работа со строками и столбцами
data_pd.loc[[0, 1], ['Фамилия', 'Имя']] - Функция loc позволяет получить данные только по конкретным строкам и столбцам. Первым агрументом указываем номера строк, которых хотим получить, вторым - названия столбцов.
data_pd.iloc[[0, 1], [0, 1]] - Функция iloc позволяет получить данные обращаясь и к строкам и к столбцам по номерам. Показанный пример вернет теже данные, что и вариант выше (обратите внимание, что номерация столбцов, как и строк, в Pandas начинается с 0).
Отбор данных по условию
data_pd[(data_pd['Доход'] >= 30000) & (data_pd['Фамилия'] == 'Петров')] - Отбираем данные по двум условиям. В первом говорим о том, что доход должен быть больше 30 000, а фамилия сотрудника должна быть Петров. Обратите внимание, что используется логическое условие И (&) - это значит, что данные будут получены, если выполнены оба условия. При использовании логического условия ИЛИ (|), будут отобраны те строки, в которых выполняется хоть одно из указанных условий.
Библиотека Pandas предоставляет доступ ко множеству функций, которые могут понадобиться при анализе данных при помощи Python, однако сегодня мы поговорим о 10 функциях, которые должен знать каждый уважающий себя аналитик, использующий Pandas.

Перед работой с функциями Pandas не забываем импортировать эту библиотеку:
1. read_csv()
Функция read_csv() позволяет получить данные из файла формата csv, не используя каких либо сторонних библиотек. Все, что вам нужно сделать – это указать путь до файл. Важно отметить также и то, что данные можно получать как с локального диска, так и из сети Интернет(!). Ниже пример загрузки csv файла c Google диска:
Полученные данные автоматически преобразуются в Dataframe с которым мы и будем работать в дальнейшем.
2. head(), tail()
Функция head() позволяет просмотреть первые пять строк в Dataframe. Вы также можете указать в скобках то количество строк, которые вы хотели бы отобразить с начала Dataframe. Функция tail() работает аналогично, но только вместо первых строк, она показывает последние:
3. info()
Функция info() предоставляет суммарную информацию о вашем Dataframe. Вы получите информацию о количестве строк, наименовании столбцов, количестве непустых строк в них, типе данных в каждом столбце, а также столько памяти занимает Dataframe:
4. describe()
Функция describe() для каждого числового столбца, в случае нашего примера это столбец Rating, выводит основные описательные статистические данные, такие как минимум, максимум, распределение по долям:
5. dtypes
6. astype()
Функция astype() позволяет изменить тип данных у столбца в случае, если тип данных некорректный. Для примера воспользуемся примером из одного из предыдущих уроков:
city_data = 'Город':['Москва', 'Казань', 'Владивосток', 'Санкт-Петербург', 'Калининград'],
'Дата основания':['1147', '1005', '1860', '1703', '1255'],
'Площадь':['2511', '516', '331', '1439', '223'],
'Население':['11,9', '1,2', '0,6', '4,9', '0,4'],
'Погода':['8', '8', '17', '9', '12'] >
city_df = pd.DataFrame(city_data)
city_df.dtypes
Как вы видите, у столбца Погода тип данных object, хотя в нем вся информация цифровая, давайте переведем его в формат int64:
После преобразования данные в столбце «Погода» стали восприниматься Pandas как int64 и соответственно с ними теперь можно проводить математические операции.
7. sample
Функция sample(n=…) отображает n случайных строк из Dataframe. Великолепная функция, если вам надо ориентировочно понять, что именно содержится в вашем Dataframe. Параметр n отвечает за то, сколько строк необходимо показать:
8. drop_duplicates()
Функция drop_duplicates() удаляет дубликаты в наших данных (параметр inplace=True означает, что мы изменяем исходный Dataframe):
9. Isna()
Функция Isna() возвращает информацию о том, есть ли в вашем Dataframe столбцы с пропущенными данными:
В нашем примере в столбцах Rating, Type, Content Rating, Current Ver, Android Ver есть строки, в которых отсутствуют какие-либо данные.
10. loc[:]
Функция loc позволяет получить данные из выбранных строк и столбцов. В качестве строк необходимо указать номера строк, которые необходимо отразить, а в качестве столбцов – их наименования. К примеру, со второй по четвертую строку получим наименования приложений и их рейтинг:
Хитрость: Используя данную функцию, можно получить данные из конкретной ячейки, указав ее строку и столбец.
Спасибо, за то, что прочитали статью. В ней я хотел рассказать о 10 нужных функциях Pandas при анализе данных, которые должен знать каждый.
В качестве бонуса, как обычно, я прикладываю ноутбук с примерами из этой статьи.
Как удалить строку по условию?
Здравствуйте! Что не так в этом запросе? DELETE FROM `база данных` WHERE `ФИО` = `Яценко` .

Удалить строку по условию сравнения чисел
Доброго дня Подскажите пожалуйста, как кодом удалить строки, в которых есть числа меньше 2.
Python sqlite - как удалить строку по условию
База mydatabase таблица typs столбец typs(он один) conn = sqlite3.connect('mydatabase.db').
Макрос excel 2010. Оставить строку по определенному условию, лишнее удалить
Здравствуйте, в сети много рабочих макросов для удаление строки в таблице по условию, или по.
Это должно как-то просто делаться. Способы, которые я нашел в учебниках и интернете в данном случае почему-то не работают.
Скорее всего как обычно - запятую в нужном месте не поставил
ого, ещё немножко дорисовать и бесконечность получится))
извините, что не по теме, в питоне это что такое, где применяется?
pandas или numpy, или это одно и тоже? - ещё не добрался до них, спс
Ципихович Эндрю, увидел твой ответ сразу в тему зашёл, думаю сейчас чего нибудь опять сморозит философское ахах
~ это оператор побитового дополнения в python, который по существу равен -x - 1
Добавлено через 1 час 4 минуты
В учебнике Хейдт М. Изучаем Pandas. Высокопроизводительная обработка и анализ данных в Python / ИЦ "Гивиста", 2018, 487с.
Прочитал:
Присвоение результатов модификации объекта Series самой себе не всегда желательно и по возможности рекомендуется этого избегать. Результаты лучше записывать в новую серию. При необходимости можно изменять значения и добавлять/удалять строки на месте. Можно добавить дополнительную строку в серию прямо на месте, присвоив значение еще несуществующей метке индекса.
Пример работает, а для моей серии с датами, что-то пока не получается так сделать
Во втором столбце матрицы 4х4 найти минимальный элемент, удалить столбец и строку по условию
Во втором столбце матрицы 4х4 найти мин элемент и удалить столбец и строку на пересечении которых.
Удалить конкретные Series из TChart
Добрый день, форумчане! Прошу помочь в следующем вопросе: мне нужно, чтобы при достижении.
Как правильно удалить Series из Chart
Здравствуйте! Подскажите, пожалуйста, как правильно удалить программно созданные Series из Chart'a.
Двунаправленный линейный список строк. Вставить строку, удалить строку и заменить строку
3 двунаправленный линейный список строк.требуется вставить строку после строки с номером и удалить.
HP M600 Series и HP P4000 Series. Совместимость модулей двухсторонней печати
Доброго времени суток! Приобрел принтер HP M601n, да проглядел, что он без дуплекса.
Две линейки модулей DDR3 памяти - HyperX Beast Series и HyperX Black Series
Калифорнийская сompany Kingston Technology, крупнейший независимый разработчик, производитель и.

At the start of every analysis, data needs to be cleaned, organised, and made tidy. For every Python Pandas DataFrame, there is almost always a need to delete rows and columns to get the right selection of data for your specific analysis or visualisation. The Pandas Drop function is key for removing rows and columns.
Pandas Drop Cheatsheet
Removing columns and rows from your DataFrame is not always as intuitive as it could be. It’s all about the “DataFrame drop” command. The drop function allows the removal of rows and columns from your DataFrame, and once you’ve used it a few times, you’ll have no issues.

Sample DataFrame
For this post, we’re using data from the WHO COVID tracker, downloaded as at the 1st January 2020 (data here). If you’d like to work with up-to-date data, please change the source URL for the read_csv function in the loading script to this one.

Delete or Drop DataFrame Columns with Pandas Drop
Delete columns by name
Deleting columns by name from DataFrames is easy to achieve using the drop command. There are two forms of the drop function syntax that you should be aware of, but they achieve the same result:
Delete column with pandas drop and axis=1
The default way to use “drop” to remove columns is to provide the column names to be deleted along with specifying the “axis” parameter to be 1.
Delete column with pandas drop “columns” parameter
Potentially a more intuitive way to remove columns from DataFrames is to use the normal “drop” function with the “columns” parameter specifying a single column name or a list of columns.
Delete columns by column number or index
The drop function can be used to delete columns by number or position by retrieving the column name first for .drop. To get the column name, provide the column index to the Dataframe.columns object which is a list of all column names. The name is then passed to the drop function as above.
WARNING: This method can end up in multiple columns being deleted if the names of the columns are repeated (i.e. you have two columns with the same name as the one at index 3).
When you have repeating columns names, a safe method for column removal is to use the iloc selection methodology on the DataFrame. In this case, you are trying to “select all rows and all columns except the column number you’d like to delete”.
To remove columns using iloc, you need to create a list of the column indices that you’d like to keep, i.e. a list of all column numbers, minus the deleted ones.
To create this list, we can use a Python list comprehension that iterates through all possible column numbers ( range(data.shape[1]) ) and then uses a filter to exclude the deleted column indexes ( x not in [columns to delete] ). The final deletion then uses an iloc selection to select all rows, but only the columns to keep ( .iloc[:, [columns to keep] ).
Delete DataFrame Rows with Pandas Drop
There are three different ways to delete rows from a Pandas Dataframe. Each method is useful depending on the number of rows you are deleting, and how you are identifying the rows that need to be removed.
Deleting rows using “drop” (best for small numbers of rows)
Delete rows based on index value
To delete rows from a DataFrame, the drop function references the rows based on their “index values“. Most typically, this is an integer value per row, that increments from zero when you first load data into Pandas. You can see the index when you run “data.head()” on the left hand side of the tabular view. You can access the index object directly using “data.index” and the values through “data.index.values”.

To drop a specific row from the data frame – specify its index value to the Pandas drop function.
It can be useful for selection and aggregation to have a more meaningful index. For our sample data, the “name” column would make a good index also, and make it easier to select country rows for deletion from the data.

Delete rows based on row number
At times, the DataFrame index may not be in ascending order. To delete a row based on it’s position in the DataFrame, i.e. “delete the second row”, we still use the index of the DataFrame, but select the row from the index directly as we delete. We can also use these index selections to delete multiple rows, or index from the bottom of the DataFrame using negative numbers. For example:
Deleting rows based on a column value using a selection (iloc/loc)
The second most common requirement for deleting rows from a DataFrame is to delete rows in groups, defined by values on various columns. The best way to achieve this is through actually “selecting” the data that you would like to keep. The “drop” method is not as useful here, and instead, we are selecting data using the “loc” indexer and specifying the desired values in the column(s) we are using to select.
Note – if you get the Pandas error: ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all() , then you have most likely left out the parenthesis “( )” around each condition of your loc selection.
Deleting rows by truncating the DataFrame
One final way to remove rows from the DataFrame is to use Python “slice” notation. Slice notation is well summarised in this StackOverflow post:
The slice notation makes it easy to delete many rows from a DataFrame, while retaining the selected “slice”. For example:
Dropping “inplace” or returning a new DataFrame
The drop function can be used to directly alter a Pandas DataFrame that you are working with, or, alternatively, the return the result after columns or rows have been dropped. This behaviour is controlled with the “inplace” parameter. Using inplace=True can reduce the number of reassignment commands that you’ll need in your application or script. Note that if inplace is set as True, there is no return value from the drop function.
Further Reading and Links
As deleting columns and rows is one of the key operations for DataFrames, there’s a tonne of of excellent content out there on the drop function, that should explain any unusual requirement you may have. I’d be interested in any element of removing rows or columns not covered in the above tutorial – please let me know in the comments.
Читайте также: