
Тест колмогорова смирнова для двух выборок excel
Составлено по материалам книги: Сидоренко Е. В. "Методы математической обработки в психологии". СПб.: ООО "Речь", 2007 г.
Назначение критерия Колмогорова-Смирнова
Критерий предназначен для сопоставления двух распределений: эмпирического с теоретическим , например, равномерным или нормальным; одного эмпирического распределения с другими эмпирическим распределением .
Критерий позволяет найти точку, в которой сумма накопленных расхождений между двумя распределениями является наибольшей, и оценить достоверность этого расхождения.
То есть сначала сопоставляются частоты по первому разряду, потом по сумме первого и второго разрядов, потом по сумме первого, второго и третьего разрядов и т. д. Таким образом, сопоставляются всякий раз накопленные к данному разряду частоты.
Если различия между двумя распределениями существенны, то в какой-то момент разность накопленных частот достигнет критического значения, что служит основанием признать различия статистически достоверными. В формулу критерия λ включается эта разность. Чем больше эмпирическое значение λ, тем более существенны различия.
Ограничения критерия Колмогорова-Смирнова
1. Критерий требует, чтобы выборка была достаточно большой. При сопоставлении двух эмпирических распределений необходимо, чтобы n1,2 ≥ 50. Сопоставление эмпирического распределения с теоретическим иногда допускается при n ≥ 5 (Ван дер Варден Б.Л., 1960; Гублер Е.В., 1978).
2. Разряды должны быть упорядочены по нарастанию или убыванию какого-либо признака. Они обязательно должны отражать какое-то однонаправленное его изменение. Например, можно за разряды принять дни недели, 1-й, 2-й, 3-й месяцы после прохождения курса терапии, повышение температуры тела, усиление чувства недостаточности и т.д. В то же время, если взять разряды, которые случайно оказались выстроенными в данную последовательность, то и накопление частот будет отражать лишь этот элемент случайного соседства разрядов. Например, если шесть стимульных картин в методике Хекхаузена разным испытуемым предъявляются в разном порядке, невозможно говорить о накоплении реакций при переходе от картины №1 стандартного набора к картине №2 и т. д. Нельзя говорить об однонаправленном изменении признака при сопоставлении категорий «очередность рождения», «национальность», «специфика полученного образования»» и т.п. Эти данные представляют собой номинативные шкалы: в них нет никакого однозначного однонаправленного изменения признака.
Итак, невозможно накапливать частоты по разрядам, которые отличаются лишь качественно и не представляют собой шкалы порядка. Во всех тех случаях, когда разряды представляют собой не упорядоченные по возрастанию или убыванию какого-либо признака категории, следует применять метод X 2 .
Автоматический расчет критерия Колмогорова-Смирнова
Чтобы произвести расчет данных по критерию, необходимо:
• выбрать вид сопоставляемых распределений: «эмпирического с теоретическим» или «эмпирического с эмпирическим»;
• ввести данные разрядов (на увеличение или уменьшение), частоты. Данные необходимо вводить по одному числу на строку, без пробелов, пропусков и т.д., вводить только цифры;
• произвести расчет, нажав на кнопку «Шаг 2».

Книга представляет собой практическое руководство для исследователей, поставивших целью статистически обосновать свои научные и практические выводы. Принцип отбора методов — ясность и простота. Методы рассматриваются на реальных примерах и сопровождаются алгоритмами и графическими иллюстрациями. Все они могут быть использованы для быстрой обработки данных. Руководство предназначено для психологов и специалистов в области социологии, педагогики, медицины, биологии, экономики.

Знание своего типа личности помогает лучше понимать других и себя, реализоваться в профессиональной сфере и строить более счастливые отношения с окружающими людьми.

Если всю жизнь я старалась соответствовать требованиям других, создавая ложную себя, я напрочь выкинула из головы и сознания себя настоящую. Как я могу полюбить себя?
П риняв уровень значимости alpha=0.05, проверить согласие этих данных обычного месяца с распределением Пуассона, пользуясь критерием Хи-квадрат. Перепроверить данные с помощью критерия Колмогорова-Смирнова, по прежнему принимая alpha =0.05.
Методические указания
- критерий согласия Хи-квадрат
- критерий Крамера-фон Мизеса
- критерий Колмогорова-Смирнова
Критерий Хи-квадрат предпочтителен, когда исследуются большие объемы выборок. При малых объемах выборок этот критерий практически не пригоден.
Нулевая гипотеза при применении общих критериев согласия записывается в форме
где Fn(x) – эмпирическая функция распределения вероятностей; F(x) – гипотетическая функция распределения вероятностей.
Критерий Пирсона X 2 основан на сравнении эмпирической гистограммы распределения случайной величины с ее теоретической плотностью. Диапазон изменения экспериментальных данных разбивается на k интервалов, и подсчитывается статистика:

где ni – количество значений случайной величины, попавших в i-й интервал; n – объем выборки; F(x) – гипотетический теоретический закон распределения вероятностей случайной величины; pi = F(xi+1) — F(xi) – теоретическая вероятность попадания случайной величины в i-й интервал.
Статистика X 2 имеет распределение Хи-квадрат с f = n — 1 степенями свободы в том случае, когда проверяется простая нулевая гипотеза H0, т.е., когда гипотетическое распределение, на соответствие которому проверяется эмпирический ряд данных, известно с точностью до значения своих параметров.
Правило проверки гипотезы:
то на уровне значимости alpha, т. е. с достоверностью (1 — alpha) гипотеза
На мощность статистического критерия X 2 сильное влияние оказывает чиcло интервалов разбиения гистограммы (k) и порядок ее разбиения (т. е. выбор длин интервалов внутри диапазона изменения значений случайной величины). На практике принято считать, что статистику X 2 можно использовать, когда npi >= 5.
Такое приближение допустимо и тогда, когда не более, чем в 20% интервалов имеет место 1 npi
Одна из рекомендаций по расчету k сводится к вычислению:
При n >= 200 можно выбирать k из условия
Еще одно простое правило: выбрать как можно большее k, но не превышающее n/5:
Критерий Крамера-фон Мизеса дает хорошие результаты при малых объемах выборок (менее 10). Однако вопрос о доверительной вероятности остается нерешенным (эта вероятность мала при значительных размерах доверительных интервалов.
Исходя из этого, полагают, что реальные объемы выборок, которые можно получить, находятся в диапазоне от 10 до 100.
Критерий Колмогорова-Смирнова также целесообразно использовать для выборки указанных объемов в тех случаях, когда проверяемое распределение непрерывно и известны среднее значение и дисперсия проверяемой совокупности.
Алгоритм реализации критерия Колмогорова-Смирнова предполагает использование критического значения D extr для проверки принятой гипотезы. Для этого используется приведенная ниже табл. 1.
Решение
1. Критерий Хи-квадрат
1.1. Реализация в MathCad

1.2. Реализация в Excel

Формулы ячеек на листе Excel представлены в табл. 2.
| Ячейка | Характеристика | Формула |
| В15 | – число случаев исхода | =СЧЁТЕСЛИ($B$3:$H$7;A15) |
| С15 | – вероятность наступления | =ПУАССОН.РАСП(A15;$E$11;ЛОЖЬ) |
| D15 | – ожидаемое число случаев исхода | =ОКРУГЛ(C15*$H$9;0) |
| H19 | – статистика Хи-квадрат | =СУММ(H15:H18) |
| H23 | – критическое значение Хи-квадрата (максимальное значение для заданного уровня значимости) | =ХИ2.ОБР(1-H22;H21) |
| J19 | – p-value (вероятность получить расчетное значение Хи-квадрата) | =ХИ2.РАСП.ПХ(H19;H21) |
| J20 | – Хи-квадрат тест | =ХИ2.ТЕСТ(F15:F18;G15:G18) |
2. Критерий Колмогорова-Смирнова

Литература
- Емельянов А.А., Власова Е.А., Дума Р.В. Имитационное моделирование экономических процессов: уч. пособ. - М.: Финансы и статистика, 2002. - 368с.
- Кобзарь А. И. Прикладная математическая статистика. Для инженеров и научных работников. - М.: ФИЗМАТЛИТ, 2006. - 816 с.
© В.Н. Кравченко
Последнее обновление: 2018.11.03

Колмогоров А.Н.
– непараметрический критерий согласия, в классическом понимании предназначен для проверки простых гипотез о принадлежности анализируемой выборки некоторому известному закону распределения. Наиболее известно применение данного критерия для проверки исследуемых совокупностей на нормальность распределения.
1. История разработки критерия Колмогорова-Смирнова
Критерий Колмогорова-Смирнова был разработан советскими математиками Андреем Николаевичем Колмогоровым и Николаем Васильевичем Смирновым.
Колмогоров А.Н. (1903-1987) - Герой Социалистического Труда, профессор Московского государственного университета, академик АН СССР - крупнейший математик XX века, является одним из основоположников современной теории вероятности.
Смирнов Н.В. (1900-1966)- член-корреспондент АН СССР, один из создателей непараметрических методов математической статистики и теории предельных распределений порядковых статистик.

Смирнов Н.В.

Хьюберт Лиллиефорс
2. Для чего используется критерий Колмогорова-Смирнова?
Данный критерий позволяет оценить существенность различий между распределениями двух выборок, в том числе возможно его применение для оценки соответствия распределения исследуемой выборки закону нормального распределения.
3. В каких случаях можно использовать критерий Колмогорова-Смирнова?
Критерий Колмогорова-Смирнова предназначен для проверки на нормальность распределения совокупностей количественных данных.
Для большей достоверности полученных данных объемы рассматриваемых выборок должен быть достаточно большими: n ≥ 50. При размерах оцениваемой совокупности от 25 до 50 элементов, целесообразно применение поправки Большева.
4. Как рассчитать критерий Колмогорова-Смирнова?
Критерий Колмогорова-Смирнова рассчитывается при помощи специальных статистических программ. В основе лежит статистика вида:

где sup S - точная верхняя грань множества S, Fn - функция распределения исследуемой совокупности, F(x) - функция нормального распределения
Выводимые значения вероятности основаны на предположении, что среднее и стандартное отклонение нормального распределения известны априори и не оцениваются из данных.
Однако на практике обычно параметры вычисляются непосредственно из данных. В этом случае критерий нормальности включает сложную гипотезу ("насколько вероятно получить D статистику данной или большей значимости, зависящей от среднего и стандартного отклонения, вычисленных из данных"), и приводятся вероятности Лиллиефорса (Lilliefors, 1967).
Есть такой критерий и в Excel он работает, судя по многим примерам.
Кто-нибудь возьмется рассчитать конкретный пример проверки на нормальность с предоставлением алгоритма в Excel 2007?
Спасибо, о цене договоримся.
Столбец C.
Есть такой критерий и в Excel он работает, судя по многим примерам.
Кто-нибудь возьмется рассчитать конкретный пример проверки на нормальность с предоставлением алгоритма в Excel 2007?
Спасибо, о цене договоримся.
Столбец C. stormbringernew
у К-С есть варианты, поправки, могут быть отраслевые стандарты, определяющие порядок расчетов, а вы опять спрашиваете "вообще". В вашем примере нормальности не наблюдается, хотя это и просто по гистограмме видно
у К-С есть варианты, поправки, могут быть отраслевые стандарты, определяющие порядок расчетов, а вы опять спрашиваете "вообще". В вашем примере нормальности не наблюдается, хотя это и просто по гистограмме видно прохожий2019
у К-С есть варианты, поправки, могут быть отраслевые стандарты, определяющие порядок расчетов, а вы опять спрашиваете "вообще". В вашем примере нормальности не наблюдается, хотя это и просто по гистограмме видно Автор - прохожий2019
Дата добавления - 27.04.2020 в 23:08
прохожий2019, Жаль. Но возможно я выбрал слишком широкие карманы, поэтому по гистограмме "видно", что нет нормальности. А можно как-то смягчить критерии, чтобы не было возможности так категорично отказать в нормальности. И номер Яндекс кошелька напишите (можно в привате) для хотя бы символической благодарности. Если у вас получится, то что я выше написал, я оплачу больше. Спасибо вам за то, что снова откликнулись. Сергей
прохожий2019, Жаль. Но возможно я выбрал слишком широкие карманы, поэтому по гистограмме "видно", что нет нормальности. А можно как-то смягчить критерии, чтобы не было возможности так категорично отказать в нормальности. И номер Яндекс кошелька напишите (можно в привате) для хотя бы символической благодарности. Если у вас получится, то что я выше написал, я оплачу больше. Спасибо вам за то, что снова откликнулись. Сергей stormbringernew
stormbringernew, ваши данные НЕ распределены нормально. Если хотите - поступайте как обычно делают в медицинских диссертациях : "распределение нормально (p=0,002652)". Но это подтасовка, подгон критериев под желаемое. Я в этом не участвую
stormbringernew, ваши данные НЕ распределены нормально. Если хотите - поступайте как обычно делают в медицинских диссертациях : "распределение нормально (p=0,002652)". Но это подтасовка, подгон критериев под желаемое. Я в этом не участвую прохожий2019
stormbringernew, данные по стомату можно описать нормальным распределением (см. файл), но логнормальное описывает лучше. если вы хотите навести красоту - описывайте данные логнормальным распределением (КС пройдет для обоих факультетов), это и вполне объяснимо - у ИМТ есть точная нижняя граница - 0 (ниже не бывает), а вверх - границы нет, отсюда асимметрия. Не нужно искать нормальность там, где её нет. См. файл - оценено распределение логарифмов ИМТ - оно нормально
stormbringernew, данные по стомату можно описать нормальным распределением (см. файл), но логнормальное описывает лучше. если вы хотите навести красоту - описывайте данные логнормальным распределением (КС пройдет для обоих факультетов), это и вполне объяснимо - у ИМТ есть точная нижняя граница - 0 (ниже не бывает), а вверх - границы нет, отсюда асимметрия. Не нужно искать нормальность там, где её нет. См. файл - оценено распределение логарифмов ИМТ - оно нормально прохожий2019
СПАСИБО! А параметры логнормального можно в экселе рассчитать? Есть функция?
И можно достоверность логнормального указать для обеих факультетов?
СПАСИБО! А параметры логнормального можно в экселе рассчитать? Есть функция?
И можно достоверность логнормального указать для обеих факультетов? stormbringernew
Вроде нашел функцию, пробую стоить график. НЕТ, только интегральная находится почему-то. Для плотности вероятности в 2007 нет что-ли?
И как искать a и сигма для логнормального, по специальным формулам? Или Excel может сам?
Вроде нашел функцию, пробую стоить график. НЕТ, только интегральная находится почему-то. Для плотности вероятности в 2007 нет что-ли?
И как искать a и сигма для логнормального, по специальным формулам? Или Excel может сам? stormbringernew
Что-то я не поняла. Тема в платном разделе, вовсю идёт обсуждение и даже с ответами.
прохожий2019 вообще ещё не вправе здесь писать.
Переносить тему обратно в бесплатную ветку ВОПРОСЫ ПО EXCEL?
Что-то я не поняла. Тема в платном разделе, вовсю идёт обсуждение и даже с ответами.
прохожий2019 вообще ещё не вправе здесь писать.
Переносить тему обратно в бесплатную ветку ВОПРОСЫ ПО EXCEL? Pelena
Я не знал, что нельзя задавать вопросы здесь. Как решит прохожий2019. Спасибо ему за оказываемую на форуме помощь. Кстати, а где задавать вопросы? Почты или телефона я не знаю. С уважением Сергей
Я не знал, что нельзя задавать вопросы здесь. Как решит прохожий2019. Спасибо ему за оказываемую на форуме помощь. Кстати, а где задавать вопросы? Почты или телефона я не знаю. С уважением Сергей stormbringernew

Now suppose that the sample comes from a population with cumulative distribution function F(x) and define Dn as follows:
Observation: It can be shown that Dn doesn’t depend on F. Since Sn(x) depends on the sample chosen, Dn is a random variable. Our objective is to use Dn as a way of estimating F(x).
The distribution of Dn can be calculated (see Kolmogorov Distribution), but for our purposes now the important aspect of this distribution is the table of critical values. These can be found in the Kolmogorov-Smirnov Table .
If Dn,α is the critical value from the table, then P(Dn ≤ Dn,α) = 1 – α. Dn can be used to test the hypothesis that a random sample came from a population with a specific distribution function F(x). If
then the sample data is a good fit with F(x).
Also from the definition of Dn given above, it follows that
![]()
![]()
![]()
Examples
Example 1: Determine whether the data represented in the following frequency table is normally distributed.
![]()
Figure 1 – Frequency table for Example 1
This means that 8 elements have an x value less than 100, 25 elements have an x value between 101 and 200, etc. We need to find the mean and standard deviation of this data. Since this is a frequency table, we can’t simply use Excel’s AVERAGE and STDEV functions. Instead, we first use the midpoints of each interval and then use an approach similar to that described in Frequency Tables as shown in Figure 2:

Figure 2 – Calculating mean and standard deviation
Thus, the mean is 481.4 and the standard deviation is 155.2. We can now build the table that allows us to carry out the KS test, as shown in Figure 3.
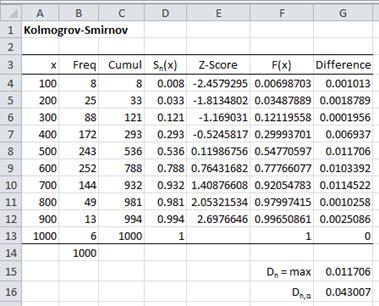
Figure 3 – Kolmogorov-Smirnov test for Example 1
Columns A and B contain the data from the original frequency table. Column C contains the corresponding cumulative frequency values and column D simply divides these values by the sample size (n = 1000) to yield the cumulative distribution function Sn(x)
Column E uses the mean and standard deviation calculated previously to standardize the values of x from column A. E.g. the formula in cell E4 is =STANDARDIZE(A4,N$5,N$10), where cell N5 contains the mean and cell N10 contains the standard deviation (from Figure 2). Column F uses these standardized values to calculate the cumulative distribution function values assuming that the original data is normally distributed. E.g. cell F4 contains the formula =NORM.S.DIST(E4,TRUE). Finally, column G contains the absolute values of the differences between the values in columns D and F. E.g. cell G4 contains the formula =ABS(F4—D4). If the original data is normally distributed these differences will be zero.
Now Dn = the largest value in column G, i.e. MAX(G4:G13) = 0.0117 (cell G8). If the data is normally distributed then the critical value Dn,α will be larger than Dn. From the Kolmogorov-Smirnov Table we see that
Since Dn = 0.0117 < 0.043007 = Dn,α, we conclude that the data is a good fit for the normal distribution.
Example 2: Using the KS test, determine whether the data in Example 1 of Graphical Tests for Normality and Symmetry is normally distributed.
We follow the same procedure as in the previous example to obtain the results shown in Figure 4. Since the frequencies are all 1, this example might be a little easier to understand.

Figure 4 – KS test for data from Example 2
Since Dn = 0.1874988 < 0.338 = Dn,α, we conclude that the data is a reasonably good fit with the normal distribution. This is inconsistent with the QQ plot shown in Figure 5, which seems to show that the data is not normally distributed.

Figure 5 – QQ Plot for Example 2
The reason for this inconsistency is that the Kolmogorov-Smirnov test in the form presented above is only valid when the population mean and standard deviation are known, and not estimated from the sample. In the case where the population mean and standard deviation are not known, you need to use the Lilliefors version of the test, as described below.
Worksheet Functions
Real Statistics Excel Function : The following functions are provided in the Real Statistics Resource Pack:
KSCRIT(n, α, tails, interp) = the critical value of the Kolmogorov-Smirnov test for a sample of size n, for the given value of alpha (default = .05) and tails = 1 (one tail) or 2 (two tails, default), based on the KS Table. If interp = TRUE (default) then the recommended interpolation is used; otherwise linear interpolation is used.
KSPROB(x, n, tails, iter, interp, txt) = an approximate p-value for the KS test for the Dn value equal to x for a sample of size n and tails = 1 (one tail) or 2 (two tails, default) based on a linear interpolation (if interp = FALSE) or recommended interpolation (if interp = TRUE, default) of the values in the Kolmogorov-Smirnov Table, using iter number of iterations (default = 40).
Note that the values for α in the Kolmogorov-Smirnov Table range from .001 to .2 (for tails = 2) and .0005 to .1 for tails = 1. When txt = FALSE (default), if the p-value is less than .001 (tails = 2) or .0005 (tails = 1) then the p-value is given as 0 and if the p-value is greater than .2 (tails = 2) or .1 (tails = 1) then the p-value is given as 1. When txt = TRUE, then the output takes the form “ < .001”, “< .0005”, “>.2” or “> .1”.
For Example 2, KSCRIT(15, .05, 2) = .338 (the same as shown in cell H21 of Figure 4). Also note that the p-value = KSPROB(H20, B21) = KSPROB(0.184177, 15) = 1 (meaning that p-value > .2), and so once again we can’t reject the null hypothesis that the data is normally distributed.
If the value of Dn had been .35 in Example 2, then Dn = .35 > .338 = Dcrit, and so we would have rejected the null hypothesis that the data is normally distributed. In this case, we would have seen that p-value = KSPROB(.35,15) = .0427, which once again leads us to reject the null hypothesis.
Kolmogorov Distribution
As referenced above, the Kolmogorov distribution can be useful in conducting the Kolmogorov-Smirnov test. Click here for more information about this distribution, including some useful functions provided by the Real Statistics Resource Pack.
Lilliefors Test
When the population mean and standard deviation for the Kolmogorov-Smirnov Test is estimated from the sample mean and standard deviation, as was done in Example 1 and 2, then the Kolmogorov-Smirnov Table yields results that are too conservative. More accurate results can be derived from the Liiliefors Table as described in the Lilliefors Test for Normality.
Читайте также: