
Тест чоу в excel как сделать
Предположим, что на основе собранных данных была построена модель регрессии. Перед исследователем стоит задача о том, стоит ли вводить в полученную модель дополнительные фиктивные переменные или базисная модель является оптимальной. Данная задача решается с помощью метода или теста Чоу. Он применяется в тех ситуациях, когда основную выборочную совокупность можно разделить на части или подвыборки. В этом случае можно проверить предположение о большей эффективности подвыборок по сравнению с общей моделью регрессии.
Будем считать, что общая модель регрессии представляет собой модель регрессии модель без ограничений. Обозначим данную модель через UN. Отдельными подвыборками будем считать частные случаи модели регрессии без ограничений. Обозначим эти частные подвыборки как PR.
Введём следующие обозначения:
PR1 – первая подвыборка;
PR2 – вторая подвыборка;
ESS(PR1 ) – сумма квадратов остатков для первой подвыборки;
ESS(PR2 ) – сумма квадратов остатков для второй подвыборки;
ESS(UN) – сумма квадратов остатков для общей модели регрессии.

– сумма квадратов остатков для наблюдений первой подвыборки в общей модели регрессии;

– сумма квадратов остатков для наблюдений второй подвыборки в общей модели регрессии.
Для частных моделей регрессии справедливы следующие неравенства:

Условие (ESS(PR1)+ESS(PR2))= ESS(UN) выполняется только в том случае, если коэффициенты частных моделей регрессии и коэффициенты общей модели регрессии без ограничений будут одинаковы, но на практике такое совпадение встречается очень редко.
Основная гипотеза формулируется как утверждение о том, что качество общей модели регрессии без ограничений лучше качества частных моделей регрессии или подвыборок.
Альтернативная или обратная гипотеза утверждает, что качество общей модели регрессии без ограничений хуже качества частных моделей регрессии или подвыборок
Данные гипотезы проверяются с помощью F-критерия Фишера-Снедекора.
Наблюдаемое значение F-критерия сравнивают с критическим значением F-критерия, которое определяется по таблице распределения Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n-2m-2.
Наблюдаемое значение F-критерия рассчитывается по формуле:где ESS(UN)– ESS(PR1)– ESS(PR2) – величина, характеризующая улучшение качества модели регрессии после разделения её на подвыборки;
m – количество факторных переменных (в том числе фиктивных);
n – объём общей выборочной совокупности.
При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл>Fкрит, то основная гипотеза отклоняется, и качество частных моделей регрессии превосходит качество общей модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т.е. Fнабл?Fкрит, то основная гипотеза принимается, и разбивать общую регрессию на подвыборки не имеет смысла.
Если осуществляется проверка значимости базисной регрессии или регрессии с ограничениями (restricted regression), то выдвигается основная гипотеза вида:

Справедливость данной гипотезы проверяется с помощью F-критерия Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n–k–1.
Наблюдаемое значение F-критерия преобразуется к виду:

При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл›Fкрит, то основная гипотеза отклоняется, и в модель регрессии необходимо вводить дополнительные фиктивные переменные, потому что качество модели регрессии с ограничениями выше качества базисной или ограниченной модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл?Fкрит, то основная гипотеза принимается, и базисная модель регрессии является удовлетворительной, вводить в модель дополнительные фиктивные переменные не имеет смысла.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Тест сносок v1.2
Тест сносок v1.2 Скрипт проверяет порядок расположения ссылок-сносок и их правильность. Определяет, кажется, все возможные ошибки. Является аналогом скрипта «Проверить ссылки», который стандартно идет с FBW, но работает быстрее (сравните: N*N операций в случае скрипта FBW и N
Тест на сообразительность
Тест на сообразительность Во время проводов цыганского барона украли лодку у Харона. А.Смир Задумайте любое растение. Задумали – прекрасно. Именно оно и будет олицетворять вас. А теперь расшифруем выбор:Роза – королева цветов, всегда шикарно одета и благоуханна, ее
Тест (от англ. test – проба, испытание, проверка) – в психологии – стандартизированное средство психологического измерения и оценки, предназначенное за короткое время с помощью тех или иных испытаний (количественных и качественных) определить индивидуальные особенности
Тест на беременность
Тест на беременность Вы планируете стать мамой и с замиранием сердца ожидаете момента, когда же можно будет сделать тест и увидеть заветные две полоски? Или наоборот, это событие пока никак не входит в ваши планы, и вы места себе не находите в ожидании результата теста? В
Тест на ботанство
Тест на ботанство 1. Зачем вы взялись за этот тест?а) от скукиб) чтобы узнать, ботаник ли яв) мне сказали, что я ботаник, и мне очень-очень нужно проверитьг) чтобы побить чей-то счет2. Сколько времени вы проводите за компьютером в сутки?а) меньше часаб) около часав) от 3 до 5
Тест 4. Game over
Тест 4. Game over Прошу всех встать.Минута молчания.………………………………………………….Cold Steel AK-47 PE Folder Нагрузка была приложена к затыльнику ножа, массивной пластиковой вставке с двумя дырками в ней, "куда можно вдеть шнур и отлично использовать нож для самообороны" — по заверению
Тест Тест (англ. test — проба, испытание, исследование) в психологии и педагогике, стандартизированные задания, результат выполнения которых позволяет измерить психофизиологические и личностные характеристики, а также знания, умения и навыки испытуемого. Т. начали
Тест-акт
Тест-акт Тест-акт (англ. Test Act), Акт о присяге, закон английского парламента, принятый в 1673. Требовал от всех состоящих (или желающих состоять) на государственной службе присяги по англиканскому обряду и отречения от католических догматов. Принятие Т.-а. означало
Цис-транс-тест
Цис-транс-тест Цис-транс-тест (лат. cis — по эту сторону, trans — через, за пределами и англ. test — испытание), генетический метод анализа, позволяющий выявить принадлежность рецессивных мутаций одному или разным генам . Предложен американским генетиком Э. Льюисом в 1951. Для
СОЦИОМЕТРИЧЕСКИЙ ТЕСТ
СОЦИОМЕТРИЧЕСКИЙ ТЕСТ (социометрия и англ. test - испытание, исследование) специальный социометрический метод, прием и способ фиксации, измерения и исследования установок, оценок, предпочтений и желаний людей, проявляемых ими в отношении других людей или групп в процессе
ТЕСТ (англ. test - проба, испытание, проверка, исследование) - общенаучный эмпирический метод, состоящий в применении системы специально отобранных процедур (формализации, алгоритмизации, инструктирования, фиксации, измерения, анализа и интерпретации) для получения неявной
68. Тест Чоу
68. Тест Чоу Предположим, что на основе собранных данных была построена модель регрессии. Перед исследователем стоит задача о том, стоит ли вводить в полученную модель дополнительные фиктивные переменные или базисная модель является оптимальной. Данная задача решается с
Тест №2
Тест №2 К одному источнику света с 16 дюймовым отражателем (используется как ключевой свет) прикрепляется 7 футовая струна. Кусочки ленты, которые служат маркерами, прикрепляются к струне с интервалом 12 дюймов снизу и, не доходя до лампы 3 футов. Тест будет проводиться при
Тест Сколько ни пишут, чтобы не ставили турецкие замки, все равно до людей не доходит. На форумах обсуждаются замки KALE, ORNEK, TURKEY, FAIN неспроста. Они стоят на дверях, они продаются и покупаются. Чем вызван спрос? Я думаю, следующими составляющими: низкая цена, красный цвет
Ниже приведено условие задачи и текстовая часть решения. Закачка полного решения, файлы doc, gdt и xls в архиве rar, начнется автоматически через 10 секунд. Еще примеры решения задач по эконометрике можно посмотреть здесь.
Видеоуроки по решению этой задачи находятся внизу страницы: в Gretl и в EViews.
Для анализа выбираем 68 компаний по следующим показателям:
Y - Оборотные активы, тысяч долларов США;
X 1 - Выручка, тысяч долл.США ;
X 2 - Численность сотрудников, человек;
X 3 - Денежный поток от финансовой деятельности, тысяч долларов США;
X 4 - Стоимость обыкновенных акций, тысяч доллларов США.
Х5 – фиктивная переменная, для компании со стоимостью активов до 100 000 тыс. долл. США – 0, свыше - 1
Строим корреляционную матрицу взаимосвязи показателей.
Таблица 1. Корреляционная матрица взаимосвязи показателей.
Наибольшую корреляционную зависимость имеют показатели Y и Х3 (коэффициент корреляции 0,8419). Имеем тесную корреляционную зависимость между объясняющими переменными Х 1 , Х2, Х3. Это может
Построим первую модель методом наименьших квадратов.
Модель 1: МНК, использованы наблюдения 1-68
Зависимая переменная: Y
Среднее зав. перемен
Ст. откл . зав. перемен
Сумма кв. остатков
Ст. ошибка модели
Лог . п равдоподобие
Модель 2: МНК, использованы наблюдения 1-68
Зависимая переменная: Y
Среднее зав. перемен
Ст. откл . зав. перемен
Сумма кв. остатков
Ст. ошибка модели
Лог . п равдоподобие
Модель 3 : МНК, использованы наблюдения 1-68
Зависимая переменная: Y
Среднее зав. перемен
Ст. откл . зав. перемен
Сумма кв. остатков
Ст. ошибка модели
Лог . п равдоподобие
Вспомогательная регрессия для теста Рамсея
МНК, использованы наблюдения 1-68
Зависимая переменная: Y
Коэффициент С т. ошибка t-статистика P-значение
X1 0,437344 0 ,0813554 5,376 1,18e-06 ***
X3 2 ,74789 0,694206 3,958 0,0002 ***
X4 -0 ,365427 0,0806426 -4,531 2,67e-05 ***
yhat^ 2 4,17000e-07 5,13530e-07 0,8120 0,4198
yhat^3 -3,72166e-013 2,99846e-013 -1,241 0,2191
Тестовая статистика: F = 3,759543,
р-значение = P(F(2,63) > 3,75954) = 0,0287
Строим логарифмическую модель.
Модель 4 : МНК, использованы наблюдения 1-68 (n = 67)
Исключено пропущенных или неполных наблюдений: 1
Зависимая переменная: l_Y
Среднее зав. перемен
Ст. откл . зав. перемен
Сумма кв. остатков
Ст. ошибка модели
Лог . п равдоподобие
В полученной модели константа не значима при 5% уровне значимости. P-значение = 0,0 64 > 0.05. Исключим константу.
Модель 5 : МНК, использованы наблюдения 1-68 (n = 67)
Исключено пропущенных или неполных наблюдений: 1
Зависимая переменная: l_Y
Среднее зав. перемен
Ст. откл . зав. перемен
Сумма кв. остатков
Ст. ошибка модели
Лог . п равдоподобие
Тест Бриша-Пэгана ( Breusch-Pagan ) на гетероскедастичность -
Нулевая гипотеза: гетероскедастичность отсутствует
Тестовая статистика: LM = 0,0238767
р-значение = P( Chi-Square (2) > 0,0238767) = 0,988133
Проведём Тест Рамсея.
Вспомогательная регрессия для теста Рамсея
МНК, использованы наблюдения 1-68 (n = 67)
Исключено пропущенных или неполных наблюдений: 1
Зависимая переменная: l_Y
Коэффициент С т. ошибка t-статистика P-значение
l_X1 0,636042 0,218841 2,906 0 ,0051 ***
l_X3 0,402919 0,135202 2,980 0 ,0041 ***
l_X4 -0 ,0914406 0,0368933 -2,479 0,0159 **
yhat^ 2 0,0212465 0,0500619 0,4244 0,6727
yhat^3 -0,00117964 0,00207869 -0,5675 0,5724
Тестовая статистика: F = 2,171711,
р-значение = P(F(2,62) > 2,17171) = 0,123
Принимаем нулевую гипотезу, спецификация модели верна.
Тест на нормальность остатков.

Рис . Тест на нормальность остатков.
P -значение = 0,816 >0.05. Принимаем нулевую гипотезу. Остатки модели нормальны.
Модель можем признать удачной, ошибок спецификации не обнаружили, предпосылки метода наименьших квадратов выполняются.
Проведём тест Чоу . N =17. ( последнее значение оборотных активов с величиной до 100 000 тыс. долл. США)
Расширенная регрессия для теста Чоу
МНК, использованы наблюдения 1-68 (n = 67)
Исключено пропущенных или неполных наблюдений: 1
Зависимая переменная: l_Y
Коэффициент С т. ошибка t-статистика P-значение
l_X1 0,715977 0,134005 5,343 1 ,49e -06 ***
l_X3 0,440067 0,121207 3,631 0 ,0006 ***
l_X4 -0 ,134565 0,0786572 -1,711 0,0923 *
splitdum 2,39614 0,837917 2,860 0,0058 ***
sd_l_X1 -0 ,149744 0,155505 -0,9630 0,3394
sd_l_X3 -0 ,0934967 0,139619 -0,6697 0,5056
sd_l_X4 0 ,0570963 0,0838660 0,6808 0,4986
Среднее зав. перемен 12,09472 С т. откл . зав. перемен 1,163621
Сумма кв. остатков 8,446037 С т. ошибка модели 0,375190
R-квадрат 0,999146 Испр . R-квадрат 0,999061
F(7, 60) 10028,54 Р-значение (F) 1,50e-89
Лог . п равдоподобие -25,69054 Крит. Акаике 65,38108
Крит. Шварца 80,81393 Крит. Хеннана-Куинна 71,48790
Тест Чоу для структурных изменений в точке 17
F(4, 60) = 2,30235 р-значение 0,0688
Принимаем нулевую гипотезу – нет структурных изменений.
Метод инфляционных факторов
Минимальное возможное значение = 1.0
Значения > 10.0 могут указывать на наличие мультиколлинеарности
VIF(j) = 1/(1 - R(j)^2), где R(j) - это коэффициент множественной корреляции
Иногда выборка наблюдений состоит из двух или более подвыборок, и трудно установить, следует ли оценивать одну объединенную регрессию или отдельные регрессии для каждой подвыборки.
Предположим, что ставится задача не только построить модель зависимости цены p квартиры от факторов x1, x2, …, xm, но и решить вопрос существенности (или несущественности) влияния фактора: «квартира в панельном или кирпичном доме». Другими словами, необходимо выяснить, можно ли считать одним и тем же уравнение регрессии для панельных и кирпичных домов или необходимо всю имеющуюся выборку разбить на две части (одну для панельных домов, а другую для кирпичных) и построить для каждой из них свое уравнение регрессии.
Формальный статистический тест для оценки объединенной регрессии в сравнении с регрессиями для подвыборок был предложен Грегори Чоу.
Суть теста Чоу заключается в следующем:
1) полная выборка объема n разбивается на две подвыборки А и В объемами n1 и n2 соответственно (n = n1 + n2);
2) для полной выборки, а также для подвыборок А и В оцениваются параметры линейных уравнений регрессии:
3) выдвигается и проверяется с помощью F-статистики гипотеза о равенстве друг другу соответствующих коэффициентов регрессии, а именно гипотеза , .
Наблюдаемое значение статистики вычисляется по выборочным данным на основании формулы
где – сумма квадратов отклонений выборочных значений от соответствующих значений, рассчитанных по уравнению регрессии (j), , , – объем выборки.
Построенная F-статистика имеет распределение Фишера с числами степеней свободы и . Если , то гипотеза отклоняется. В этом случае моделирование следует осуществлять с помощью кусочно-линейной модели. Если же , то нет оснований отклонять нулевую гипотезу, а значит, ее моделирование следует осуществлять с помощью единого для всей совокупности уравнения.
Иногда выборка наблюдений состоит из двух или более подвыборок, и трудно установить, следует ли оценивать одну объединенную регрессию или отдельные регрессии для каждой подвыборки.
Обозначим объединенную (общую) регрессию Р, а отдельные регрессии подвыборок как А и В. Пусть суммы квадратов остатков для регрессий подвыборок равны соответственно: ЕА и ЕВ. Пусть и – суммы квадратов остатков в объединенной регрессии для наблюдений, относящихся к двум рассматриваемым подвыборкам.
Отдельные регрессии для подвыборок должны соответствовать наблюдениям, по меньшей мере так же хорошо, и даже лучше, чем объединенная регрессия. Поэтому должны выполняться следующие соотношения: ЕА и ЕВ или (ЕА + ЕВ) £ Ер где Ер = + – общая сумма остатков в объединенной регрессии.
Поясним графически суть данного подхода. Предположим, что имеются данные временного ряда по двум переменным, и что в период выборки произошло структурное изменение, разделяющее наблюдения на подвыборки A и В. На рис. 2.1,б подвыборки обеспечивают вполне адекватное соответствие данным (им соответствуют низкие значения ЕА и ЕВ). Для случая объединенной регрессии (рис. 2.1,а) остатки в обеих подвыборках в целом оказываются значительно больше.
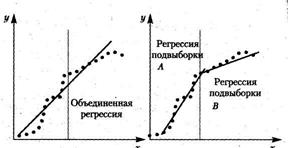
Рис. 2.1. Применение теста Чоу
а – объединенная регрессия; б – отдельные регрессии подвыборок
Равенство между Ер и (ЕА + ЕВ) будет иметь место только при совпадении коэффициентов регрессии для объединенной регрессии и регрессий подвыборок. В общем случае при разделении выборки будет наблюдаться улучшение качества уравнения. Улучшение качества измеряется величиной:
Ер – ЕА + ЕВ. Однако при разделении выборки растет число степеней свободы: дополнительно приходится оценивать (т + 1) параметров, где т – число объясняющих переменных (факторов). Поэтому число степеней свободы возрастает на (т + 1). После разделения выборки остается необъясненная сумма квадратов остатков (ЕА + ЕВ) с (n – 2т – 2) степенями свободы.
Для того чтобы определить, является ли значимым улучшение качества уравнения после разделения выборки, используют F-статистику:


.
Если вычисленное по данным выборки наблюдаемое значение F-статистики больше критического значения: Fкр(a;m+1;n-2m-2), то улучшение качества регрессии после разделения выборки существенно, т. е. не следует оценивать объединенную регрессию.
Рассмотрим применение теста Чоу на примере. Воспользуемся данными табл. 2.4. Пусть мы решили, что следует построить 2 отдельных уравнения регрессии для рабочих-мужчин и рабочих-женщин. Тогда оценивание объединенной регрессии и регрессий для подвыборок дает результаты, приведенные в табл. 2.6.
| Выборка | Оцененное уравнение | R 2 | Сумма квадратов остатков |
| Объединенная выборка, |  Тнабл (4,29) (4,104) | 0,728 | |
| Мужчины |  Тнабл (1,39) (6,88) | 0,735 | |
| Женщины |  Тнабл (1,43) (6,48) | 0,712 |
Соответствующая F-статистика будет равна:

.
Полученное значение меньше нуля. Так как Fкр всегда положительно, то, следовательно, Fнабл будет меньше Fкр и разбивать выборку на части не следует. Улучшение качества регрессии после разделения выборки на части не существенно.
Тест Чоу может применяться для выявления стабильности тенденции временного ряда. Допустим, что ряд динамики имеет нестабильную тенденцию. Это значит, что начиная с некоторого момента t*, происходит изменение характера динамики изучаемого показателя, что приводит к изменению параметров тренда, описывающего эту динамику. Момент времени t* сопровождается значительными изменениями ряда факторов, оказывающих сильное воздействие на изучаемый показатель (например, начало крупных экономических реформ, нефтяные кризисы, изменение экономического курса и прочее).
При этом весь ряд динамики представляет собой выборку, которую можно разделить на подвыборки:
1) до момента t*;
2) после момента t*.
Выдвигается основная гипотеза Н0: о структурной стабильности тенденции. В соответствии с тестом Чоу рассчитывается Fнабл, определяется Fкр. Если Fнабл < Fкр, то гипотезу Н0 не отвергаем, и наоборот.
Факторы (объясняющие переменные), применяемые в задаче регрессии до сих пор, принимали значения из некоторого непрерывного интервала. Иногда может понадобиться ввести в модель переменные, значения которых детерминированы и дискретны. Например, данные получены для трех разных районов, или на двух фабриках, или на разных машинах и т.п. Переменные такого типа обычно называют фиктивными или искусственными. Эти переменные позволяют отразить в модели эффекты сдвига во времени или в пространстве, воздействия качественных переменных. Пример фиктивной переменной - это переменная при свободном члене в уравнении регрессии (3.1), которая принята равной 1. Эту переменную необязательно вводить в модель, но ее использование обеспечивает некоторое удобство в обозначениях. Во многих других случаях введение фиктивных переменных диктуется необходимостью.
Пример. Пусть, требуется отразить в модели разное происхождение куриных окороков (исходные данные - таблица 4.5), часть из которых получены в Америке, а часть в Канаде, при построении регрессионной зависимости веса окороков У от возраста кур Х. для этого в модель включим фиктивную переменную Z: Z=O для Америки, Z=1 для Канады:
Таблица 4.5 Данные для расчёта модели с фиктивными переменными
Построив регрессию по приходим к уравнению
Используя модель с фиктивной переменной получим
или для различных стран
для Канады и для Америки.
Дисперсионный анализ показывает значимость полученных зависимостей, причем уравнение (как с фиктивной переменной, так и без фиктивной переменной) объясняет до 80% вариации относительно среднего.
Вывод: введение фиктивной переменной не дает весомого улучшения модели в смысле дополнительно объяснённой вариации.
Для любой задачи существует не единственный способ выбора фиктивных переменных. Это обстоятельство оказывается выгодным, поскольку в некоторых случаях можно угодить в ловушку, когда существует линейная зависимость между введенными фиктивными переменными.
Чтобы избежать ловушки, необходимо выбрать одну из категорий в качестве эталонной и определять фиктивные переменные для остальных возможных категорий, причем выбор эталонной категории не влияет на сущность регрессии.
Может потребоваться включение в модель более одной совокупности фиктивных переменных. Это особенно часто встречается при работе с перекрестными выборками.
Фиктивные переменные могут быть введены не только в правую часть регрессионного соотношения, но и зависимая переменная может быть представлена в такой форме. Это возможно в тех случаях, когда в качестве зависимой переменной рассматриваются ответы на вопросы, пользуется ли человек собственной машиной, имеет ли счет в банке и т.п., причем во всех случаях зависимая переменная принимает дискретные значения.
Фиктивные переменные могут быть использованы для учета взаимодействия между различными группами факторов.
Рассмотрим пример с окороками. Для построения двух прямых рассмотрим модель:
Такой подход позволяет проверить различные варианты гипотез:
1. Гипотеза против альтернативы что это не так. Если гипотеза будет отвергнута, то мы придем к выводу, что модели не одинаковы, а если нет, то можно пользоваться одной моделью независимо от происхождения окороков.
2. Если гипотеза в предыдущем пункте будет отвергнута, то можно проверить гипотезу Если принимается, то мы заключаем, что имеющиеся два набора данных отличаются только уровнем, имея одинаковые углы наклона.
При необходимости могут быть выбраны и другие варианты проверок , если это разумно для задачи. Получим для указанной выше модели уравнение МНК:
Два отдельных уравнения для
Для проверки гипотезы составим таблицу дисперсионного анализа (табл. 4.6).
| Источник вариации | Сумма квадратов | Степени свободы | Средний квадрат |
| Х Z,XZ Остаток Всего | 24,447 6,797 6,881 | 10,414 3,399 0,983 | |
| 38,125 |
Значение что меньше и, следовательно, гипотеза принимается, т.е. можно пользоваться одной моделью как для окороков из Америки, так и из Канады. Последнее подтверждается ранее полученными результатами.

Часто эконометрист сталкивается с ситуацией, когда к уже имеющейся выборке он хочет присоединить небольшую дополнительную порцию данных, но не знает, можно ли считать выборки регрессионно-однородным.
Если необходимо выяснить, можно ли использовать одну и ту же модель для двух разных выборок данных или следует оценивать отдельные регрессии для каждой выборки, то можно воспользоваться тестом Чоv.
Требуется проверить гипотезу
которая содержательно означает, что для двух имеющихся выборок из и наблюдений можно использовать одну и ту же регрессионную модель, т.е. выборки можно объединить.
Процедура Чоу для статистической проверки гипотезы состоит в следующем:
1. Строим МНК оценки регрессии (4.14) и вычисляем сумму квадратов остатков, которую обозначим через .Строим МНК оценки регрессии (4.15) и вычисляем сумму квадратов остатков, которую обозначим через .
2. Строим МНК оценки регрессии по объединенной (общей) выборке, содержащей в себе все наблюдения (числом )обеих выборок и вычисляем сумму квадратов остатков, которую обозначим через .
3. Критическая статистика вычисляется по формуле:
и имеет распределение Фишера с и степенями свободы. Если , то нулевая гипотеза отвергается, и в этом случае мы не можем объединить две выборки в одну.
Читайте также: