
Составление программы на языке программирования gpss станок для обработки деталей
Использование среды моделирования GPSS для проектирования модели работы регулировочного участка цеха и загрузки накопителя агрегатами, нуждающимися в полной регулировке. Разработка концептуальной модели, процесс ее алгоритмизации и машинной реализации.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 14.09.2011 |
| Размер файла | 497,3 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Подобные документы
Особенности моделирования работы сборочного участка цеха, которая состоит из трех этапов: сборка, предварительная обработка и регулировка деталей. Понятие среды имитационного моделирования GPSS World - программного комплекса, работающего под Windows.
контрольная работа [39,5 K], добавлен 04.06.2011
Методы материального моделирования в среде GPSS. Построение и разработка концептуальной модели. Алгоритмизация модели и ее машинная реализация. Экспериментальное моделирование на ЭВМ. Определение максимальной длины очереди готовых к обработке пакетов.
курсовая работа [189,0 K], добавлен 14.09.2011
Задачи теории массового обслуживания. Моделирование работы регулировочного участка цеха. Обобщенная схема моделирующего алгоритма. Краткая характеристика технологии реализации, особенности программирования. Описание функций программы и интерфейса.
курсовая работа [1,4 M], добавлен 15.06.2010
Основные сведение о системе моделирования GPSS и блоки, используемые при моделировании одноканальных и многоканальных систем массового обслуживания. Разработка модели работы ремонтного подразделения в течение суток с использованием программы GPSS World.
курсовая работа [36,4 K], добавлен 11.02.2015
Создание имитационной модели системы массового обслуживания с помощью языка имитационного моделирования GPSS/PC - моделирование обработки на участке 500 деталей. Определение загрузки второго станка на вторичной обработке и вероятности появления отходов.
курсовая работа [602,3 K], добавлен 30.11.2010
Разработка программы на языке GPSS для изучения работы обрабатывающего участка цеха: составление временной диаграммы, Q-схемы и моделирующего алгоритма. Анализ выходной статистики, внесение изменений в текст программы, создание и оформление документации.
курсовая работа [887,3 K], добавлен 21.06.2011
Понятие компьютерной модели и преимущества компьютерного моделирования. Процесс построения имитационной модели. История создания системы GPSS World. Анализ задачи по прохождению турникета на стадион посредством языка имитационного моделирования GPSS.
Написание этого мини туториала вместе с разработкой моделей заняло 6 часов чистого времени.
буду признателен если статья доберется до потенциально заинтересованных читателей.

Во избежания вызова негативных эмоций первоначальная картинка заменена на кота с трубкой и спрятана под спойлер.

Для начала нам понадобиться сам GPSS-World.
Мы будем использовать бесплатную версию для студентов.
Также при изучении языка имитационного моделирования будет полезен учебник
Можно взять вот этот .
На мой взгляд, не очень доступно, но лучше чем ничего.
Итак необходимым инструментарием мы запаслись, теперь осталось подключить фантазию и придумать первую модель.
Меня никак нельзя назвать гуру имитационного моделирования в целом и GPSS-World в частности, подосновой для примеров приведенных тут служили материалы из этой книги . Но думаю, что составляемые модели имеют право на жизнь.
Давайте для начала рассмотрим такой случай.
Дано:
Офис в котором работает 10 сотрудников, Кулер в конце коридора до которого «шкваркать 4 минуты», сотрудники которые желают испить чаю и совершают путешествие к кулеру один раз в час. Время наполнения чаши с пакетиком живительной влагой составляет примерно 2 минуты. Рабочий день составляет 480 минут (8 часов без перерыва на обед так сказать)
Определить:
Коэффициент использования кулера сотрудниками офиса.
Создадим имитационную модель
Поскольку комментарии я оставлял на своем ломаном английском, то безусловно вижу смысл детально рассказать о функционировании модели.
Строка 1 — GENERATE . 10 — сам по себе блок GENERATE задает нам количество входящих требований (в данном случае сотрудников офиса), запись операторов вида . 10 говорит нам о том что первые три параметра пропущены, а четвертый параметр указывает на максимальное количество входящих требований. Блок GENERATE. Можно задать и с другими параметрами, но об этом я расскажу немного позже.
Как вы догадались " ;" — отделяет поле комментария. Еще немного о конструкции оформления кода, код читается слева направо, есть несколько блоков, которые желательно разделять табуляцией. Самый левый блок это метка (аналогична метке в др. языках программирования), затем идет сам блок (например generate) затем обычно идут его параметры, затем комментарии. Когда-то давно нас учили разделять эти блоки табуляцией, но это скорее вопрос эстетики. 1 пробела кажется тоже достаточно что бы все запустилось. Кстати там где написано все БОЛЬШИМИ буквами, лучше так и писать, а то может вылететь ошибка при исполнении.
Строка 2 — ADVANCE 4,0.8; Отвечает за временные характеристики процесса, чтобы было понятней в данном случае это значит, что работник идет к кулеру 4 минуты ± 0.8 минуты.
Таким образом первая цифра означает затраченные единицы времени (итерации), вторая цифра означает отклонение в большую или меньшую сторону, в книгах написано что значение отклонения генерируется случайным образом, может это и так, но каждый перезапуск система выдает одинаковые значения (не знаю может быть есть аналог randomize из старого доброго паскаля, но я его не нашел).
Блок ADVANCE также можно задать с другими значениями, но об этом чуть позже.
Строка 3 — DRINK QUEUE STAND; — вот тут мы встречаем нашу первую метку DRINK, после которой следует блок QUEUE, который создает очередь в эту очередь у нас будут попадать все кто направляется к кулеру промочить горло,. STAND – это скажем так идентификатор очереди.
Строка 4 — SEIZE COOLER – блок SEIZE определяет свободно ли наше устройство, в данном случае идентификатор устройства COOLER (ну или попросту кулер).
Строка 5 DEPART STAND — если прошлый блок дал нам положительный результат (кулер свободен), то срабатывает следующий за ним блок DEPART, который обеспечивает выход человека из очереди STAND.
Строка 6 — ADVANCE 2,0.8 человек, который вышел из очереди будет наливать себе примерно 2 минуты кипяток в кружку (ну плюс успеет поболтать с людьми в очереди к кулеру)
Строка 7 — RELEASE COOLER, сделав свое «мокрое» дело, человек освободит устройство COOLER, для следующего страждущего.
Строка 8 — ADVANCE 60,10 – данный блок учитывает время. Которое человек испивший воды, затратит на то чтобы собраться с силами и прийти к кулеру еще раз (по крайней мере я надеюсь, что моделируется именно это).
Строка 9 — TRANSFER ,DRINK – «И повторится все, как встарь» — сказал бы А. Блок, если бы был знаком с программированием. Данный оператор обеспечивает переход на метку DRINK.
Строка 10 – GENERATE 480 казалось бы с точки зрения программирования после перехода на метку в прошлом блоке, все что лежит ниже не имеет смысла, но это не так.(а почему так, я если честно не сильно вникал, но судя по опыту и выпадающим ошибкам, этот кусок воспринимается немного вне контекста предыдущих 8 блоков). Главное, что данный блок задает нам время выполнения всей модели, а именно 480 минут (8 часов)
Строка 11 — TERMINATE 1 – Этот бок вычитает из каждой счетчика итераций единицу. Без этого блока можно уйти в бесконечный цикл.
Строка 12 — START 1 – Говорит программе с какого момента цикла начать, мы начинаем с первой минуты.
Ух, ну вот мы и закончили с описанием первой модели.
Кому интересны результаты, прошу под спойлер. Если вы любите все проверять самостоятельно то еще раз напомню все модели выложены на GItHub
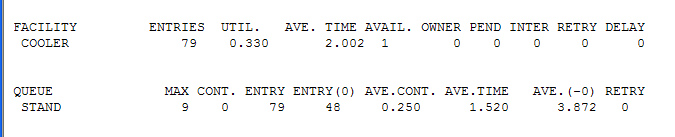
проанализируем результаты
Итак мы видим, что в среднем наш кулер загружен на 33%, то есть в нашей команде из 10 сотрудников получается примерно так как если бы к нему постоянно прикладывался Администратор Петр, Марья Васильевна из бухгалтерии и Менеджер проекта Василий Чуфыркин, ну и еще 0.33 человека, или например — кот. На самом деле этот блок текста не несет смысловой нагрузки, мне просто очень хотелось нарисовать кота и кулер и Марью Васильевну из бухгалтерии (все кроме кота личности сугубо выдуманные)

Хотя черт побери после того как я прочел это, могу смело утверждать, что кулер мог бы напоить 12 милых котиков =)

Но вернемся к теме.
Давайте рассмотрим, результаты выдачи.
Facility – это список всех наших работающих устройств, в данном случае только кулер.
Entries 79 – означает число подходов на обслуживание к устройству, в данном случае число человек с пустыми чашками составило 79 – за всю рабочую смену.
Util – коэффициент использования оборудования, Он говорит нам о том, что кулер бездествовал (1-0.33)*100%=67% всего времени.
AVE. TIME – среднее время использования кулера 1 человеком 2.002 минуты
AVAIL. – Доступность кулера, не знаю что это значит видимо еденица говрит, что он был доступен
DELAY = 0 – говрит нам о том, что чсло людей которые просто подошли к кулеру, расстроились и ушли с пустыми руками (кружкой), равно нулю.
Теперь переедем к нашей очереди (QUEUE)
Как видите тут указано имя созданной нами ранее очереди,
В которой максимально находилось 9 человек, в которую было 79 входов, и 48 нулевых входов (по всей видимости входов без ожидания в очереди), среднее время проведенное человеком в очереди равно 1.5 минуты. Cont. = 0 говорит нам о том, что на момент окончания моделирования в очереди никого не было.
Ну вот вроде бы все не плохо, но что будет если мы вернемся в сытый 2006
Год и наймем еще 30 сотрудников в наш офис?

Как видно из модели, наш кулер почти перестанет простаивать, а среднее время в очереди составит аж 20 минут, что наводит на мысли либо о том, что нужен второй кулер, либо о том, что пора всех лишать премии за долгие чаепития.
Может быть данная модель, простовата, но даже она при проявлении некоторой фантазии позволяет нам оценить количество кулеров которое необходимо на этаже.
Но на текущий момент мы с вами еще не умеем, разрабатывать многоканальные модели обслуживания. Так убьем же двух зайцев, научимся многоканальному обслуживанию и заодно ответим на вопросов, которым мы с коллегой задались в самом начале статьи. (кто внимательный и помнит — молодец, тому счастья добра и безпохмельных выходных: )
При создании модели операторы call центра и абоненты, зададимся такими условиями
Дано:
2 оператора техподдержки обслуживают пользовталей, которые звонят пимерно раз в две минуты, Если один оператор занят трубку берет другой. Рабочий день составляет 480 минут (8 часов без перерыва на обед так сказать)
Определить:
Коэффициент загруженности сотрудников службы поддержки.
Как и в прошлый раз опишу построчно
Строка 1 — HELPDESK STORAGE 2 – Создаем накопитель Служба поддержки емкостью 2 сотрудника
Строка 2 — GENERATE 6,3; вот мы и подошли к другому способу задачи блока генерации, в даннмо случае цифра 6 означает что примерно раз в 6 мнут появляется 1 звонок, цифра 3 означает что отклонения от шести минут составлят ± 1.5 минуы. Еще блок GENERATE можно было задать так
(Exponential(1,0,6)), вообще то что справедливо для ADVANCE, во многом справедливо и для GENERATE.
Строка 3 – ADVANCE (Exponential(1,0,2)),, — говорит нам о том сколько времени у звонящего уходит на то чтобы вспомнить телефон тех поддержки и набрать номер, а уходит у нас в среднем 2 минуты по экспоненциальному распределению. цифра 1 – выбирает генератор случайных чисел (от 1-7 как с ними работать я не разобрался), цифра 0 – определяет смещение (пока для меня тоже загадка), цифра 2 собственно минуты. Хочу добавить что существуют и другие законы распределения, по которым можно задать временной промежуток, но о них лучше почитать в учебнике. Который я указал вначале статьи.
Строка 4 — ENTER HELPDESK – вход в накопитель (входящий звонок)
Строка 5 — TRANSFER ALL,OPR1,OPR2,3 – говорит нам что данное событие обрабатывается для всех входящих вызовов (ALL), что операторы обработки начинаются с метки OPR1 и движутся с шагом в 3 блока пока не доберутся до метки OPR2
Строка 6 — OPR1 SEIZE OP1 — вот и наш первая метка, на которой происходит проверка занятости первого оператора службы поддержки (OP1)
Строка 7 — ASSIGN 1,OP1 – В случае если оператор 1 свободен. То мы передаем входящий звонок ему, если нет то через три строки (от 6-й) идем на строку 9
Строка 8 — TRANSFER ,COME — нет нужды узнавать о занятости второго оператора, переходим на метку COME
Строка 9 OPR2 SEIZE OP2 — если первый оператор был занят, проверяем второго
Строка 10 — - ASSIGN 1,OP2 – и отдаем звонок ему.
Строка 11 — COME LEAVE HELPDESK – звонок покидает накопитель служб поддержки
Строка 12 — ADVANCE 10,8 – время которое оператор затрачивает на то чтобы дать человеку совет как правильно вкрутить лампочку.
Строка 13 — RELEASE P1; — оператор помог человеку и освободился. P1 в данном случае это ссылка на некий указатель (или параметр ), этот момент я не могу объяснить, но он работает.
Строка 14 – TERMINATE – (ноль можно не писать по умолчанию и так ноль), если верить справки то в данном случае этот блок расскажет системе о том, что пора выводить эту итерацию из активного цикла и переходить к следующей. В любом случае без него система выдаст нам ошибку.
Строки 15- 17 аналогичны строкам первой модели.
В результате получим следующие данные
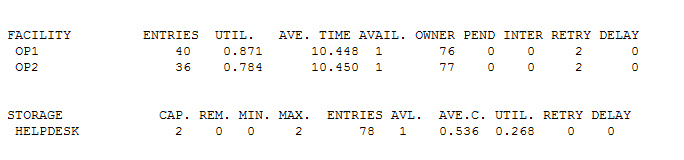
Структура вывода похожа на структуру вывода первой модели, разве что вместо очереди — накопитель предлагаю вам с ней разобраться самостоятельно. Кстати параметры генерации отчета можно настроить (на этом компьютере у меня не установлен GPSS и нет желания его ставить, поэтому поверьте пока на слово, что в настройках программы есть такая возможность ну, а я если не забуду допишу в понедельник сюда, как это сделать)
Итак, мы видим, что наши операторы вполне приемлемо загружены примерно на 75% и 87 % соответственно. Будем считать, что двух операторов вполне достаточно, чтобы посоветовать людям как правильно вкрутить лампочку. Но мы же с вами — народ любопытный, давайте посмотрим, что будет если к ребятам подсадить еще одно нахлебника с телефоном.
Для этого рассмотрим немного модифицированную модель. Предлагаю вам разобраться с ней самостоятельно.
Результат под спойлером
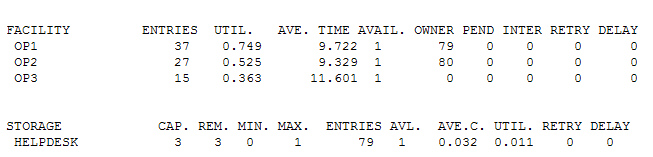
Что же в итоге мы видим, что третий оператор нам явно не нужен и можно смело идти и убирать вакансию, а вместе с ней и всех кандидатов.
На последок хочется вам рассказать о том, что GPSS-WORLD представляет более обширные возможности для моделирования, чем те о которых я вам поведал. Просто ввиду ограниченности моих знаний я не могу вам их адекватно продемонстрировать. Но, тем не менее в качестве бонуса приведу пример работы с переменными
Давайте опять построчно
Строка 1 — INITIAL X$APPLES,3 ;1 задаем значение переменной, X$ в данном случае нам как-то указывает на название переменной, а цифра три это значение которое мы запишем в переменю APPLES (кстати я не фанат продукции APPLE просто в тот момент на общем столе лежало 3 яблока, а одно я забрал себе, прям как в детсадовских задачах по математике)
Строка – 2 GENERATE 1 – создадим 1 итерацию
Строка 3 — SAVEVALUE APPLES-,1; – сохраним в переменную яблоки ее значение минус один.
Строки 4-5 помогут нам закончить программу.
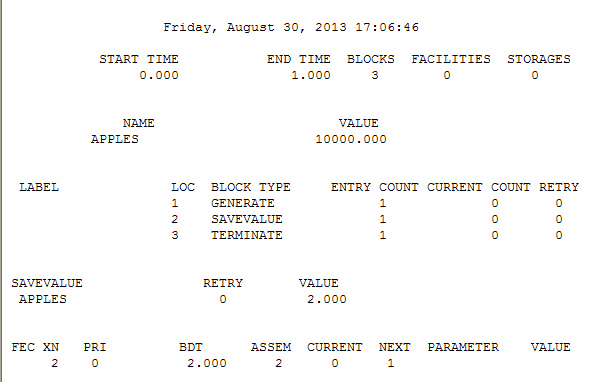
Если честно не смотря на то, что данный пример работает и из переменной действительно вычитается единица, полного механизма работы с переменными я не понимаю, поэтому оставлю на откуп профессионалам.
Ну что же теперь вы знаете об одном из инструментов с помощью, которого можно создать имитационную модель процесса, инструмент не самый удобный и уже похоже не дорабатываемый разработчиками, но тем не менее если вы проявите фантазию то за один два дня сможете провести исследование какой-нибудь модели и например опубликовать его в научном журнале или на конференции (об этом я уже писал раньше )
В любом случае теперь у вас есть еще 1 инструмент, чтобы творить, развиваться и делать мир лучше. Право слово это интереснее чем лопать шарике на смартфоне, сидя в общественном транспорте.
Всем хороших выходных, счастья добра и удачи :)
Добрый день) Подскажите как выполнить задание "а" и "б". Основную суть программы составил и понимаю, а вот как рассчитать прибыль, и работа с блоками GATE, LOGIC, TEST, возникла неразбериха.
Процесс производства деталей состоит из двух операций: сборка деталей и обжег их в печи. Несколько рабочих используют одну печь.
Режим работы:
1.Сборка детали
2.Ожидание в очереди к печи
3.Использование печи
4.Возврат к п.1, сборка новой детали
Время сборки подчиняется следующему распределению:
sborka FUNCTION RN1,D11
.01,30/.04,32/.09,34/.19,36/.37,38/.63,40/.81,42/.91,44/.96,46/.99,48/1,50
Время обжига детали в печи:
objig FUNCTION RN1,D5
.05,15/.30,16/.7,17/.95,18/1,19
Транзакты – рабочие, количество которых ограничено
Смоделировать работу в течение 48 часов. Системное время – минуты.
Прибыль рассчитывается по формуле:
П=g*n - n*m - 6*d - 48*Z*k
n= количество деталей
k= количество рабочих
Стоимость детали g 58р. за одну дет
Цена материала m 12р. за 1 дет
Стоимость печи d 480р. за 8 часов
Зарплата рабочего Z 24 р./час
Необходимо:
А) Осуществить прогон модели, устанавливая различное количество рабочих.
Определить оптимальное число рабочих, при которых достигается максимальная прибыль.
Используя блоки variable для объявления переменной, и блок savevalue для подсчета и сохранения переменной рассчитать значение прибыли. В качестве недостающих величин (n- количество деталей, k- количество рабочих) использовать соответствующие СЧА, которые позволят получить эти значения.
Б) Добавить блоки GATE и LOGIC в задачу таким образом, чтобы в момент окончания моделирования (2880) включался переключатель LOGIC и блокировал продвижение рабочих в системе с помощью блока GATE . При этом необходимо, чтобы все рабочие, которые успели попасть в блок сборки и далее, были обслужены. Для этого необходимо во втором сегменте программы внести блок TEST, который будет проверять, что количество рабочих вошедших в блок сборки равно количеству рабочих вышедших из прибора. Это количество задается с помощью соответствующего СЧА.
МОДЕЛИРОВАНИЕ ПРОСТЫХ ИНФОРМАЦИОННЫХ ПРОЦЕССОВ НА КОМПЬЮТЕРЕ
Цель работы: знакомство с системой имитационного моделирования GPSS/PC, с подготовкой задания на моделирование, выполнением анализа и обработкой результатов моделирования.
Краткие сведения о GPSS/PC
Блоки генерации и удаления транзактов
Блоки занятия и освобождения приборов
Операторы вычислительной категории
Блок задержки транзактов
ADVANCE Тср,Тм - параметры блока соответствуют параметрам блока GENERATE.
Пример 1:
процесс прохождения заявок, поступление которых подчиняется равномерному закону со средним значением 8 и интервалом [6,10] единиц времени, а обработка - равномерному закону со средним 5 и интервалом [2,8], можно описать программой:
В процессе выполнения программы собирается стандартная статистическая информация, которая автоматически выводится на печать по окончании моделирования. Выходные статистические данные для блоков (BLOCK COUNTS) содержат текущее (CURRENT) и общее (TOTAL) показания счетчиков числа входов для каждого блока. В стандартном выводе статистической информации по устройствам представлена следующая информация: номер (имя) устройства (FACILITY), число входов или обслуживаний (ENTRIES), коэффициент использования устройства (UTIL.), среднее время одного обслуживания (AVE.TIME).
Блоки занятия и освобождения очереди
Транзакт помещается в очередь в том случае, когда некоторое устройство не в состоянии обслужить его немедленно (например, устройство занято, либо память переполнена). Статистические данные об очередях могут быть получены с помощью двух типов блоков: Блок QUEUE может быть помещен перед любым блоком модели, в котором может возникнуть задержка. Отметим, что очередь к занятому устройству автоматически организуется пакетом моделирования независимо от того, есть в программе блок QUEUE или нет. По очередям печатается информация: имя или номер очереди(QUEUE), максимальная длина очереди за время моделирования (MAX),минимальная длина очереди (CONT.), число входов в очередь (ENTRIES), число входов в очередь без последующего ожидания - нулевые входы (ENTRIES(0)), средняя длина очереди (AVE.CONT), среднее время пребывания в очереди (AVE.TIME), среднее время пребывания в очереди при учете только ненулевых входов(AVE.(0)).
Пример 2:
в условиях предыдущей задачи необходимо получить статистические данные об очереди заявок, ожидающих обслуживание в приборе:
Построение гистограмм
Система GPSS позволяет строить дополнительные статистические таблицы для получения частотных распределений определенных аргументов, которыми могут быть некоторые СЧА (например, времени задержки транзакта в отдельных частях модели; длин очередей; содержимого памяти и т.п.). У каждой таблицы имеются определенные области значений аргумента. Число попаданий аргумента в каждую из этих областей регистрируется системой автоматически. В конце эксперимента результаты в таблицах выводятся на печать.
Пример 3:
получить таблицу распределения интервалов заявок по равномерному закону в интервале от 0 до 100:
В таблицах печатается информация: имя таблицы (TABLE), среднее значение аргумента (MEAN), стандартное отклонение (STD.DEV); а также табличные значения: диапазон интервала (RANGE), частота попадания в интервал (FREQUENCY), накопленная относительная частота (CUM.%).
Запуск системы выполняется с помощью команды Gpss.bat fname , где fname - имя файла. Например, если нужно выполнить запуск модели, содержащейся в файле EX1.GPS, то командная строка будет такой:
Если моделирование прошло успешно, то в нижней части экрана DOS появляется строка для ввода команды. Для выхода из программы нужно ввести в эту строку команду QUIT
Листинг выполненной модели будет находиться в файле fname.lst. Например, если исходный текст модели находился в файле EX1.GPS, то результат моделирования - в файле EX1.LST, который можно просмотреть с помощью любого текстового редактора, поддерживающего кодировку DOS (866).
Программа на языке GPSS состоит из пронумерованных операторов, располагающихся и выполняемых в порядке этих номеров. Операторы управления моделированием не нумеруются.
Особенности моделирования работы сборочного участка цеха, которая состоит из трех этапов: сборка, предварительная обработка и регулировка деталей. Понятие среды имитационного моделирования GPSS World - программного комплекса, работающего под Windows.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | контрольная работа |
| Язык | русский |
| Дата добавления | 04.06.2011 |
| Размер файла | 39,5 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Федеральное государственное автономное образовательное учреждение высшего профессионального образования
«Уральский федеральный университет имени первого
Президента России Б.Н. Ельцина»
Кафедра «Моделирование управляемых систем»
Дисциплина «Моделирование информационных процессов»
Контрольная работа
GPSS-модель сборочного цеха
Студент: Иванов Н.Е.
Руководитель: Лимановская О.В.
Введение
При построении математических моделей процессов функционирования систем можно выделить следующие основные подходы:
непрерывно - детерминированный, дискретно - детерминированный, дискретно - стохастический, непрерывно - стохастический, сетевой, обобщенный (или универсальный). Соответственно этим подходам были разработаны типовые математические схемы создания моделей.
Для выполнения задания мы используем непрерывно - стохастический подход.
Непрерывно - стохастический подход применяется для формализации процессов обслуживания. Этот подход наиболее известен ввиду того, что большинство производственных (и не только производственных - экономических, технических и т.д.) систем по своей сути являются системами массового обслуживания. Типовой математической схемой моделирования таких систем являются Q-схемы. В обслуживании можно выделить две элементарные составляющие: ожидание обслуживания и собственно обслуживание, а в любой системе массового обслуживания можно выделить элементарный прибор. Соответственно, в этом приборе выделяют: накопитель (Н) заявок, ожидающих обслуживания, некоторой емкостью; канал обслуживания (К); потоки событий (последовательность событий, происходящих одно за другим в какие-то случайные моменты времени): поток заявок на обслуживание wi, характеризующийся моментами времени поступления и атрибутами (признаками) заявок (например, приоритетами), и поток обслуживания ui, характеризующийся моментами начала и окончания обслуживания заявок. Для имитационного моделирования СМО был создан специализированный язык программирования GPSS.
Сложные функции моделирующего алгоритма могут быть реализованы средствами универсальных языков программирования (Паскаль, Си), что предоставляет неограниченные возможности в разработке, отладке и использовании модели. Однако подобная гибкость приобретается ценой больших усилий, затрачиваемых на разработку и программирование весьма сложных моделирующих алгоритмов, оперирующих со списковыми структурами данных. Альтернативой этому является использование специализированных языков имитационного моделирования.
Специализированные языки имеют средства описания структуры и процесса функционирования моделируемой системы, что значительно облегчает и упрощает программирование имитационных моделей, поскольку основные функции моделирующего алгоритма при этом реализуются автоматически. Программы имитационных моделей на специализированных языках моделирования близки к описаниям моделируемых систем на естественном языке, что позволяет конструировать сложные имитационные модели пользователям, не являющимся профессиональными программистами.
Современная среда имитационного моделирования GPSS World - это удобный программный комплекс, работающий под Windows. GPSS сочетает в себе функции дискретного и непрерывного моделирования. Возможность перехода из дискретной фазы моделирования в непрерывную фазу и обратно обеспечивает тесную связь с непрерывным моделированием. В непрерывной фазе могут быть установлены пороговые значения, управляющие созданием транзактов в дискретной фазе. Система имеет транслятор программного кода, т.е. модель работает только в среде GPSS и не может компилироваться в исполняемые файлы.
имитационное моделирование программный
1. Постановка задачи
На сборочный участок цеха предприятия через интервалы времени, распределенные экспоненциально со средним значением 10 мин, поступают партии, каждая из которых состоит из трех деталей. Половина всех поступающих деталей перед сборкой должна пройти предварительную обработку в течение 7 мин. На сборку подаются обработанная и необработанная детали. Процесс сборки занимает всего 6 мин. Затем изделие поступает на регулировку, продолжающуюся в среднем 8 мин (время выполнения ее распределено экспоненциально). В результате сборки возможно появление 4% бракованных изделий, которые не поступают на регулировку, а направляются снова на предварительную обработку.
Смоделировать работу участка в течение 24 ч. Определить возможные места появления очередей и их вероятностно-временные характеристики. Выявить причины их возникновения, предложить меры по их устранению и смоделировать скорректированную систему.
2. Разработка модели
Данная система описывает работу сборочного участка цеха, которая состоит из трех этапов: сборка, предварительная обработка и регулировка деталей. Первые два этапа осуществляются параллельно. Половина всех партий (50 %) поступает сразу на сборку, а вторая половина проходит предварительную обработку, после чего отправляется на сборку. В процессе сборки деталей выделяется 4 % брака, которые заново проходят предварительную обработку. Следующим этапом все партии поступают на регулировку (96 %).
Читайте также: