
Схема работы браузера и веб сервера
Если вы начинающий веб-разработчик, возможно вы уже знаете, как работает всемирная сеть, по крайней мере, на базовом уровне.
Но когда начинаете кому-то объяснять принцип работы веб-сайта, то терпите неудачу. Что такое IP-адрес? Как работает модель «клиент-сервер» на самом деле?
В наши дни есть достаточно мощные фреймворки, которые можно использовать в своих проектах. Настолько мощные, что начинающие разработчики легко могут запутаться в принципах работы веб.
Базовый веб-поиск
С первого взгляда может показаться, что тут происходит какая-то магия. Но давайте заглянем глубже.
Определение частей web
Из-за обилия жаргонных слов, понимание работы интернета поначалу пугает. Но к сожалению, для дальнейшего погружения в тему, придется разобраться с ними.
Клиент : Приложение, например, Chrome или Firefox, которое запущено на компьютере и подключено к Интернету. Его основная роль состоит в том, чтобы принимать пользовательские команды и преобразовывать их в запросы к другому компьютеру, называемому веб-сервером. Хотя мы обычно используем браузер для доступа к Интернету, вы можете считать весь ваш компьютер «клиентом» модели клиент-сервер. Каждый клиентский компьютер имеет уникальный адрес, называемый IP-адресом, который другие компьютеры могут использовать для идентификации.
Сервер : Компьютер, который подключен к Интернету и также имеет IP-адрес. Сервер ожидает запросов от других машин (например, клиента) и отвечает на них. В отличие от вашего компьютера (т.е. клиента), который также имеет IP-адрес, на сервере установлено и работает специальное серверное программное обеспечение, которое подсказывает ему, как реагировать на входящие запросы от вашего браузера. Основной функцией веб-сервера является хранение, обработка и доставка веб-страниц клиентам. Существует множество типов серверов, включая веб-серверы, серверы баз данных, файловые серверы, серверы приложений и многое другое. Подробнее про сервера можно прочитать тут
IP-адрес : Internet Protocol Address. Числовой идентификатор устройства (компьютера, сервера, принтера, маршрутизатора и т.д.) в сети TCP/IP. Каждый компьютер в Интернете имеет IP-адрес, который он использует для идентификации и связи с другими компьютерами. IP-адреса имеют четыре набора чисел, разделенных десятичными точками (например, 244.155.65.2). Это называется «логический адрес». Для определения местоположения устройства в сети логический IP-адрес преобразуется в физический адрес программным обеспечением протокола TCP/IP. Этот физический адрес (т.е. MAC-адрес) встроен в оборудование. Подробнее про IP-адрес можно прочитать тут
TCP/IP : Наиболее широко используется протокол связи. «Протокол» - это просто стандартный набор правил для чего-либо. TCP/IP используется в качестве стандарта для передачи данных по сетям. Подробнее про TCP/IP можно прочитать тут
Номер порта : 16-разрядное целое число, которое идентифицирует определенный порт на сервере и всегда связано с IP-адресом. Он служит способом идентификации конкретного процесса на сервере, на который могут пересылаться сетевые запросы.
Переход от кода к веб-странице
Теперь у нас есть необходимая база, чтобы разобраться, что происходит за кулисами, когда мы вводим в строку поиска адрес Github:
Как работает Веб даст упрощённое представление о том, что происходит при просмотре веб-страницы в браузере на вашем компьютере или телефоне.
Эта теория не так важна для написания веб-кода в краткосрочной перспективе, но в скором времени вы действительно начнёте извлекать выгоду из понимания того, что происходит в фоновом режиме.
Клиенты и серверы
Компьютеры, подключённые к сети называются клиентами и серверами. Упрощённая схема того, как они взаимодействуют, может выглядеть следующим образом:

- Клиенты являются обычными пользователями, подключёнными к Интернету посредством устройств (например, компьютер подключён к Wi-Fi, или ваш телефон подключён к мобильной сети) и программного обеспечения, доступного на этих устройствах (как правило, браузер, например, Firefox или Chrome).
- Серверы - это компьютеры, которые хранят веб-страницы, сайты или приложения. Когда клиентское устройство пытается получить доступ к веб-странице, копия страницы загружается с сервера на клиентский компьютер для отображения в браузере пользователя.
Остальные части панели инструментов
Клиент и сервер, о которых мы рассказали выше, не раскрывают всю суть. Есть много других компонентов, и мы опишем их ниже.
А сейчас давайте представим, что Веб - это дорога. Одна сторона дороги является клиентом, который представляет собой ваш дом. Другая сторона дороги является сервером, который представляет собой магазин. Вы хотите что-то купить в нём.

Помимо клиента и сервера, мы также должны уделить внимание:
Что же на самом деле происходит?
Когда вы вводите веб-адрес в свой браузер (для нашей аналогии - посещаете магазин):
Реальные веб-адреса - неудобные, незапоминающиеся строки, которые вы вводите в адресную строку, чтобы найти ваши любимые веб-сайты. Эти строки состоят из чисел, например: 63.245.215.20 .
Такой набор чисел называется IP-адресом и представляет собой уникальное местоположение в Интернете. Впрочем, его не очень легко запомнить, правда? Вот почему изобрели DNS. Это специальные сервера, которые связывают веб-адрес, который вы вводите в браузере (например, "mozilla.org"), с реальным IP-адресом сайта.
Сайты можно найти непосредственно через их IP-адреса. Вы можете найти IP-адрес веб-сайта, введя его домен в инструмент, как IP Checker.
Пакеты
Ранее мы использовали термин "пакеты", чтобы описать формат, в котором данные передаются от сервера к клиенту. Что мы имеем в виду? В основном, когда данные передаются через Интернет, они отправляются в виде тысячи мелких кусочков, так что множество разных пользователей могут скачивать один и тот же сайт одновременно. Если бы сайты отправлялись одним большим куском, тогда бы только один пользователь мог скачать его за один раз, и это, очевидно, сделало бы пользование интернетом не эффективным и не очень радостным.
Предположим, что он ввёл в адресной строке следующее:
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
Версия протокола здесь задаётся так же, как в запросе.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
А есть дополнительные возможности?
Что-то ещё, кстати, используют?
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Давайте начнем серию статей по безопасности веб-приложений с объяснением того, что делают браузеры и как именно они это делают. Поскольку большинство ваших клиентов будут взаимодействовать с вашим веб-приложением через браузеры, необходимо понимать основы функционирования этих замечательных программ.

Chrome и lynx
Браузер — это движок рендеринга. Его работа заключается в том, чтобы загрузить веб-страницу и представить её в понятном для человека виде.
Хоть это и почти преступное упрощение, но пока это все, что нам нужно знать на данный момент.
- Пользователь вводит адрес в строке ввода браузера.
- Браузер загружает «документ» по этому URL и отображает его.
Например, lynx — это легкий текстовый браузер, работающий из командной строки. В основе lynx лежат те же самые принципы, которые вы найдете в любых других «мейнстримных» браузерах. Пользователь вводит веб-адрес (URL), браузер скачивает документ и отображает его — единственное отличие состоит в том, что lynx использует не движок графического рендеринга, а текстовый интерфейс, благодаря которому такие сайты, как Google, выглядят так:

Мы в целом имеем представление, что делает браузер, но давайте подробнее рассмотрим действия, которые эти гениальные приложения выполняют для нас.
Что делает браузер?
Короче говоря, работа браузера в основном состоит из
Разрешение DNS
Давайте разберем запрос построчно:
Воу, на этот раз довольно много информации, которую нужно переварить. Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Рендеринг
Последним по счёту, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия среднестатистического Васи.

Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Вендоры
4 самых популярных браузера принадлежат разным вендорам:
- Chrome от Google
- Firefox от Mozilla
- Сафари от Apple
- Edge от Microsoft
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF (подробнее об этом позже). Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.

Это говорит нам о двух вещах:
- Похоже, что Safari недостаточно заботится о безопасности своих пользователей (шучу: файлы cookie SameSite будут доступны в Safari 12, который, возможно, уже был выпущен к моменту прочтения этой статьи)
- исправление уязвимости в одном браузере не означает, что все ваши пользователи в безопасности
Ваша стратегия обеспечения безопасности в сети должна варьироваться в зависимости от того, какие возможности нам предоставляет вендор-поставщик браузера. В настоящее время большинство браузеров поддерживают один и тот же набор функций и редко отклоняются от своего общей дорожной карты, но случаи, подобные приведенному выше, все еще случаются, и это то, что мы должны учитывать при определении нашей стратегии безопасности.
В нашем случае, если мы решим, что будем нейтрализовывать атаки CSRF только с помощью файлов cookie SameSite, мы должны знать, что мы подвергаем риску наших пользователей Safari. И наши пользователи тоже должны это знать.
И последнее, но не менее важное: вы должны помнить, что вы можете решить, поддерживать ли версию браузера или нет: поддержка каждой версии браузера будет непрактичной (вспомните хпро Internet Explorer 6). Несмотря на это, уверенная поддержка нескольких последних версий основных браузеров — как правило, хорошее решение. Однако, если вы не планируете предоставлять защиту на какой-то определенной платформе, очень желательно, чтобы ваши пользователи об этом знали.
Совет для профи: вы никогда не должны поощрять своих пользователей использовать устаревшие браузеры или активно поддерживать их. Даже если вы приняли все необходимые меры предосторожности, другие веб-разработчики этого не сделали. Поощряйте пользователей использовать последнюю поддерживаемую версию одного из основных браузеров.
Вендор или стандартный баг?
Тот факт, что обычный пользователь обращается к нашему приложению благодаря помощи стороннего клиентского программного обеспечения (браузера), добавляет еще один уровень, усложняющий путь к удобному и безопасному просмотру веб-страниц: сам браузер может быть источником уязвимости безопасности.
Вендоры, как правило, предоставляют вознаграждения (также известные как баг-баунти) исследователям безопасности, которые могут искать уязвимость в самом браузере. Эти ошибки связаны не с вашим веб-приложением, а с тем, как браузер самостоятельно управляет безопасностью.
Например, программа поощрений Chrome позволяет исследователям безопасности обращаться к команде безопасности Chrome, чтобы сообщить об обнаруженных ими уязвимостях. Если факт наличия уязвимости подтвердится, будет выпущено исправление и, как правило, опубликовано уведомление о безопасности, а исследователь получит (обычно финансовое) вознаграждение от программы.
Такие компании, как Google, инвестируют достаточно солидный капитал в свои программы Bug Bounty, поскольку это позволяет компаниям привлекать множество исследователей, обещая им финансовую выгоду в случае обнаружения ими каких-либо проблем с тестируемым программным обеспечением.
В программе Bug Bounty выигрывают все: поставщику удается повысить безопасность своего программного обеспечения, а исследователям платят за их находки. Мы обсудим эти программы позже, так как я считаю, что инициативы Bug Bounty заслуживают отдельного раздела в ландшафте аспектов безопасности.
Джейк Арчибальд (Jake Archibald) — разработчик-"адвокат" в Google, который обнаружил уязвимость, затрагивающую несколько браузеров. Он задокументировал свои усилия по ее обнаружению, процесс обращения к различным вендорам, затронутым уязвимостью, и реакцию представителей вендоров в интересном блог-посте, который я рекомендую вам прочитать.
Браузер для разработчиков
В приведенном выше примере мы запросили документ по адресу localhost:8080/, и локальный сервер успешно на него ответил.
Примерно та же информация доступна в популярных браузерах посредством их DevTools.

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
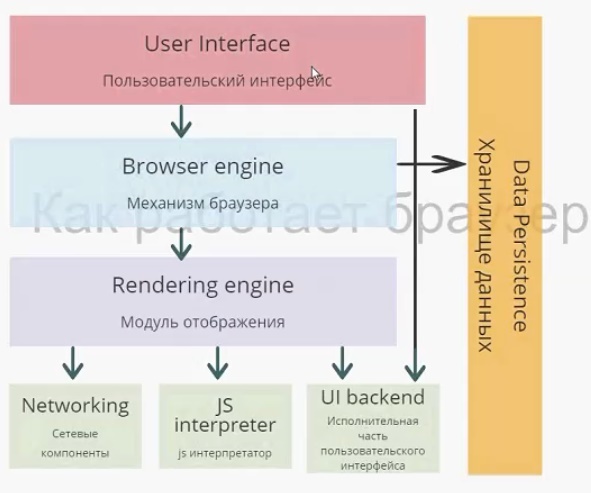
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения
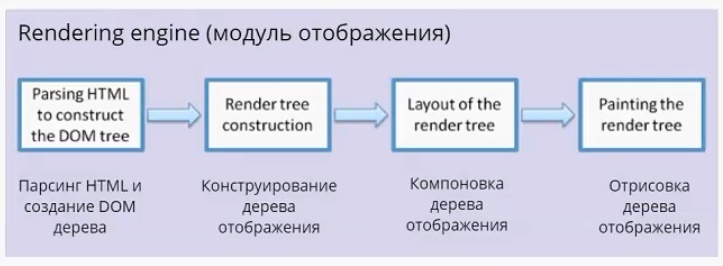
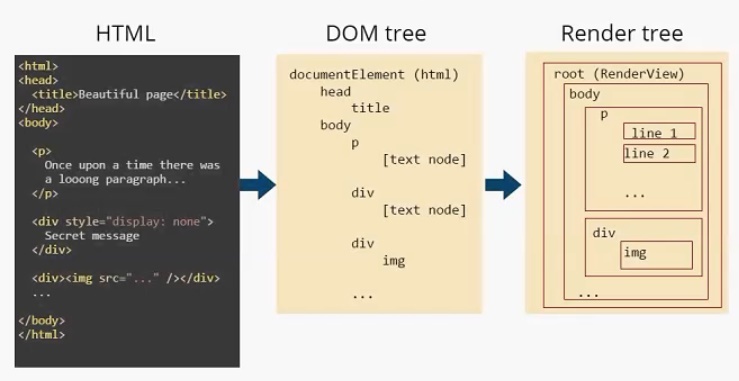
Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
- Дерево отображения не содержит скрытых элементов. Если у нас есть html-элемент, у которого прописан display:none , в дереве отображения он присутствовать не будет. При этом, если visibility:hidden , то в дереве отображения он будет. Некоторые DOM-узлы, которые в DOM-дереве представлены как единый узел, в дереве отображения могут быть представлены в виде нескольких. Яркий пример — составной тэг select. Если в DOM-дереве это один узел, в дереве отображение он преобразовывается в минимум три узла. Первый узел отвечает за отображение выбранного элемента. Второй — за выпадающий список с возможными пунктами. И, наконец, третий блок отвечает за стрелочку.
- Текст в DOM-дереве представлен как простая node. DOM-дереву нет никакого дела до того, что там написано, сколько строк этот текст занимает. В то время, как для дерева отображения — это важно, и текст трансформируется в несколько узлов, в зависимости от того сколько строк он занимает. Это нагляднее рассмотрим чуть позже.
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.

Предлагаю рассмотреть два браузерных движка: Webkit и Gecko.
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).
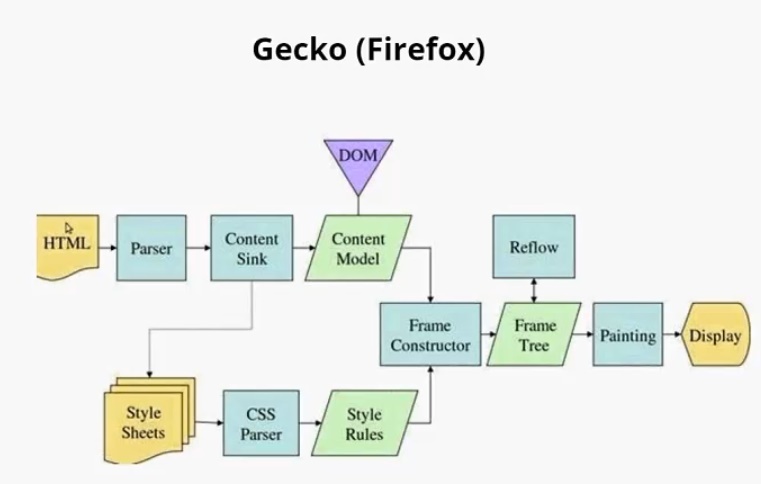
Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
- Attachment = Frame constructor = Совмещение
- Render Tree = Frame Tree = Дерево отображения
- Layout= Reflow = Компоновка
Пример

Здесь у нас есть теги:

Модуль отображения строит DOM-дерево. В данном случае оно будет выглядеть следующим образом. Есть корневой элемент (он всегда присутствует), называется он documentElement и соответствует тегу html . В этом дереве присутствуют все теги. И заметим, что текст представлен, как [text node] . И DOM-дереву больше ничего о тексте знать не нужно. На основе этого DOM-дерева строится Render Tree.
Пример
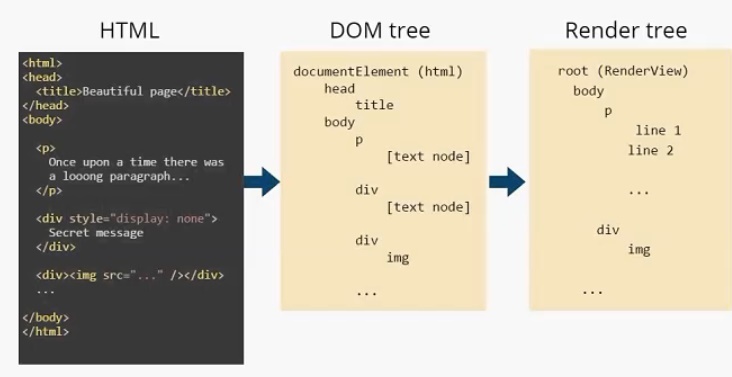
Дерево отображения. У него также есть корневой элемент (RenderView), но уже можно увидеть отличия между DOM-деревом и деревом отображения. Во-первых, нет тега head , т. к. он не отображается на экране. Нет , есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример
Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
При этом скрипт 3 все равно не будет выполняться, пока не выполнится скрипт 1. К моменту, когда скрипт 1 уже выполнится, скрипт 3 уже может быть полностью загружен. Скрипты можно вставлять в теги head и body . Разница в том, что в скрипте 2, в отличии от скрипта 1, практически весь документ уже будет проанализирован.
У скрипта могут быть атрибуты, такие как defer и async . Они похожи, но у них есть отличия:
- Атрибут defer сообщает браузеру, чтобы тот не ждал окончания выполнения скрипта, а продолжал парсинг html-страницы. При этом скрипт 4 выполнится только после того, как весь html-документ будет проанализирован и построено DOM-дерево.
- Атрибут async тоже говорит браузеру, что дальнейший html-документ может быть проанализирован, пока скрипт выполняется. При этом он загружается в параллельном потоке и выполняется сразу после загрузки. Это означает, что он может быть выполнен раньше, чем скрипт1, если последний тоже имеет атрибут async. Т. е. порядок подключения в этом случае не соблюдается.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
- Тип окна (свойство display).
- Схема позиционирования (свойства position и float).
- Размеры окна.
- Внешняя информация (размеры изображения, размер экрана).
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Читайте также: