
Редактор данных spss создает файл в формате
Данное учебно-методическое пособие предназначено для студентов-психологов в рамках изучения курсов «Основы компьютерной психодиагностики», «Психодиагностика и практикум по психодиагностике», «Математические методы и информационные технологии в психологии», «Информационные и коммуникационные технологии в работе психолога», а также преподавателей и аспирантов, занимающихся научно-исследовательской деятельностью.
В пособии содержится минимально необходимая информация по теме «Алгоритм работы с программой SPSS 20.0 при анализе данных психологического исследования», полезная для начинающих пользователей: описывается интерфейс программы с подробным рассмотрением всех функций, необходимых для анализа данных психологического исследования; приводятся примеры компьютерной обработки полученных данных; задания для самостоятельной работы с программой. Теоретическая информация сопровождается конкретными примерами и способами работы со сложным математико-статистическим аппаратом. Дается пошаговая инструкция по работе с программой от момента ввода данных до получения результата статистической обработки. Однако описанная информация предполагает, что читатель знаком с материалами таких курсов, как «Экспериментальная психология» и «Математические методы в психологии».
Содержание
Общие положения
Создание базы данных (работа с редактором данных)
Обработка данных и файлы output
Первичная обработка данных.
Описательная статистика в SPSS
Проверка нормальности распределения.
Расчет параметрических критериев РАЗЛИЧИЙ в SPSS
Расчет непараметрических критериев РАЗЛИЧИЙ в SPSS
Общие положения
SPSS является одной из самых распространённых программ для обработки статистической информации. История создания программы двумя студентами Стенфордского университета - Норманом Найем и Дейлом Вентом - с 1965 насчитывает почти 50 лет, в течение которых произошла ее серьезная модификация. В итоге программа являет собой самый широкий охват существующих методов статистической обработки данных в сочетании с обширными возможностями разнообразных способов визуализации полученных данных. Она популярна не только в области психологии, но и в сфере многих других гуманитарных и экономических наук. В данном пособии мы остановимся на 20-ой версии программы.
Компьютерная статистическая программа IBM SPSS Statistics 20 относится к числу программ, в которых наиболее полно представлены математические методы, используемые психологами и педагогами при организации эмпирических и экспериментальных исследований. Программа SPSS (Statistical Package for the Social Science – статистический пакет для социальных наук) приобрела большую популярность в среде российских психологов и педагогов, в том числе, благодаря изданиям, осуществленным Андреем Дмитриевичем Наследовым - доцентом факультета психологии Санкт-Петербургского государственного университета [Наследов, 2004, 2011 и др.].
Основу программы SPSS составляет базовый модуль (SPSS Base), который включает все процедуры ввода данных, доступа к данными и управления ими, а также большинство доступных в SPSS статистических методов. Наряду с простыми методами статистического анализа, такими как расчет частотных и статистических характеристик, построение таблиц сопряженности, расчет корреляций и построение графиков, этот модуль включает в себя большое количество непараметрических тестов, а также усложненные методы, такие как многомерный линейный регрессионный, дискриминантный, факторный, кластерный, дисперсионный анализ, анализ надежности и многомерное шкалирование.

В программе SPSS есть два типа файлов – «базы данных» и «результаты обсчета». Порядок работы с программой таков: 1) создается база данных, в которую вводятся данные и задаются их параметры; этот файл (расширение .sav) с данными является «основой», исходным материалом, по которому производятся обсчеты, и сохраняется постоянно (на период обработки); 2) находясь «внутри» базы данных пользователь производит различные расчеты, которые сохраняются не в базе данных, а как отдельные документы (название output, расширение .spo, возможность быстрого экспорта в форматы .htm, .txt, .xls, .doc).
Начиная пользоваться программой SPSS, убедитесь, что в качестве разделителя целой и дробной частей установлен единый символ для всех программ — точка (Панель управления > Языки и стандарты > Числа > Разделитель целой и дробной частей числа — установить точку)!
Запуск программы. Пуск → Программы → IBM SPSS Statistics → IBM SPSS Statistics 20. Открывается диалоговое окно, которое предлагает выбор: 1) запустить учебник (излагаются основы работы с SPSS на английском языке), 2) ввести данные (создание нового файла данных), 3) запустить имеющийся запрос (ранее сформированный запрос на импорт в программу данных другого формата), 4) создать новый запрос (на импорт в программу данных другого формата с использованием соответствующего мастера), 5) открыть уже существующий файл данных SPSS, с которым вы недавно работали; 6) открыть файл другого типа (рис. 1).. Выбрать 2-й вариант → ok. Открывается окно, в котором создается база данных – «редактор данных» (Data Editor).

Рисунок 1 – Диалоговое окно запуска IBM SPSS Statistics
Создание базы данных (работа с редактором данных)
В редакторе данных есть два «листа» (внешне похожи на листы в Excel, переход между ними осуществляется также – щелчком мышкой на нужном, но листы добавлять нельзя): 1) Переменные (Variable View) – здесь задаются параметры данных; 2) Данные (Data View) – «вместилище» самих данных (именно сюда вводится вручную, либо с помощью импорта информации, например, из таблиц, созданных в MS Word или MS Excel; при этом копируются сами числовые данные без заголовков столбцов и строк). Если занесение в лист «Данные» информации, полученной в ходе психодиагностики (коды обследованных, пол, возраст, данные по конкретным методикам и пр.) не требует специфических знаний, то заполнение листа «переменные» требует отдельного рассмотрения.
1. Работа с листом «Переменные» производится так - заполнение ведется «по горизонтали», но при этом задаются свойства столбцов листа «данные», то есть – вертикали.
2. В листе «Переменные» 11 разделов-столбцов: имя (name), тип (type), ширина (width), десятичные/дроби (decimals), метка (variable label), значение (value labels), пропущенные (missing values), ширина столбца/столбцы (column format), выравнивание (alignment), шкала/установки (measurement), роль, каждый из которых имеет свою функцию и каждый из которых необходимо заполнить:
Ø Имя– название переменной (можно вводить не более 8 символов; примеры: «код», «пол», «возраст», «ГП», «ПД», «Рокич» и т. д.);

Рисунок 2 – Диалоговое окно «Тип переменной» IBM SPSS Statistics
Ø Ширина– количество знаков (в числовых данных) до запятой (по умолчанию – 8, можно изменить – например, если данные будут только 2-значными числами, тогда в случае ошибки при заполнении листа «данных» программа сможет ее предотвратить);
Ø Десятичные/дроби– количество знаков (в числовых данных) после запятой (по умолчанию – 2, можно изменить – например, если данные будут всегда целыми числами);
Ø Метка– метка переменной (расшифровка для пользователя сокращений, использованных в разделе «Имя» – может быть не более 256 символов, примеры: «код» – «код респондента», «ГП» – «гипертимность» и т. д.).

Ø Значение– метки значений, преимущественно используются для данных, измеренных в шкале наименований: например, в поле «пол» цифре «1» приписывается метка «женский», цифре «2» – метка «мужской», либо в поле «возраст» цифра «1» – лицам, которым от 18 до 25 лет, цифра «2» – которым от 26 до 35 лет и т. д. Функция носит не прикладной, а прямой (необходимый для работы) характер, поскольку в файлах «результатов обсчета» (output) прописываются не номера (названия) переменных (которые потом еще надо перекодировать), а сразу – «категории» («мужчины», «женщины» и т. д.).
Порядок работы: войти → откроется диалоговое окно: в разделе «подпись к значениям» (value labels) в графу «значение» (value) вводится цифра (пример – 1), в графу «метка значения» (value label) вводится подпись (пример – женский) → нажать «добавить» (add), затем процедура повторяется (2-мужской) → ok (continue) (рис. 3).

Рисунок 3 – Диалоговое окно «Метки значений» IBM SPSS Statistics
Ø Пропущенные (missing values) – можно определить, какие именно значения считать «пропущенными» (по умолчанию программа считает пропущенными незаполненные ячейки). Есть несколько тонкостей: если психолог-диагност ставил цифру «0» (как результат методики) тем респондентам, которые обследование по данной методике не проходили, это необходимо указать в программе (поскольку 0 в ней является полноценной цифрой, участвующей в подсчете). При открытии окна: флажок стоит на «нет пропущенных значений» (no missing values). Дальше можно выбрать: «отдельные пропущенные значения» (discrete missing values, то есть дискретные значения – можно задать до трех цифр, в приведенном примере 0 вписывается именно в эту графу). Также можно выделить диапазон пропущенных значений от минимального до максимального.
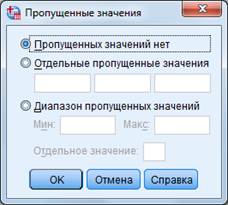
Рисунок 4 – Диалоговое окно «Пропущенные значения» IBM SPSS Statistics
Ø Ширина столбца– формат столбца (оформление, количество символов в столбце-колонке: по умолчанию – 8, можно изменить);
Ø Выравнивание– выравнивание символов в столбцах-колонках с данными (по центру, слева, справа);
Ø Шкала/установки – один из наиболее важных показателей – определение типа шкалы, в которой измерены вносимые данные: номинальная (шкала наименований, в том числе дихотомическая, шкала), порядковая или количественная (интервальная). Примеры: «код», «пол», «возраст» – номинальная шкала; «ГП», «ПД» – интервальная шкала, «Успеваемость» – порядковая шкала.
Ø Роль - некоторые диалоговые окна поддерживают возможность предварительного выбора переменных для анализа, основанного на заданных ролях. При обычном анализе всем переменным присваивается роль «входящая».
После заполнения листа «переменные» можно заполнять лист «данные» – либо вручную, либо с помощью импорта.

Практическая работа. Создать лист с данными, задать параметры данных в листе «переменные» для предложенных данных.
В израильском исследовательском центре RADAR проводили исследование, посвященное изучению того, с какого возраста начинают курить современные подростки. В таблице 1 приведены результаты проведенного опроса для 30 респондентов.
| Респондент | Пол | Возраст начала курения | Респондент | Пол | Возраст начала курения | Респондент | Пол | Возраст начала курения |
| М | Ж | М | ||||||
| М | М | М | ||||||
| М | Ж | Ж | ||||||
| М | Ж | М | ||||||
| Ж | Ж | Ж | ||||||
| М | М | ж | ||||||
| Ж | Ж | м | ||||||
| ж | м | м | ||||||
| м | м | м | ||||||
| м | м | ж |
После создания базы данных (установки параметров и ввода информации), в случае, если все процедуры выполнены корректно, ее содержание можно вообще не менять (поскольку все манипуляции при обработке производятся отдельно). Единственная функция, которая может понадобиться здесь – фильтр, постановка условий на выборку.
Порядок работы: слева мышкой выделяется поле (например, возраст), стрелкой переправляется направо, затем пишется условие; если нужно сделать запрос (условие, критерий) по нескольким столбцам, используются выражения «и», «или». Например, в случае необходимости найти респондентов сразу по двум критериям – мужчин в возрасте старше 10 лет – выражение выглядит следующим образом: возраст>=10&пол=1 → Далее → ok (рис. 6). После постановки условия в листе «данные» будут перечеркнуты названия строк, которые не соответствуют условию (на сером фоне), все расчеты будут производиться только по данным, удовлетворяющим условию. Чтобы «сбросить» условия, нужно просто установить флажок на «все наблюдения» (all cases).

Рисунок 5 – Диалоговое окно «Отобрать наблюдения» IBM SPSS Statistics


Рисунок 6 – Диалоговое окно «Отобрать наблюдения. Условие» IBM SPSS Statistics
Практическая работа. В созданном вами листе данных с результатами опроса израильских подростков отфильтруйте респондентов, оставив только мальчиков старше 13 лет.
SPSS является самой распространённой программой для обработки статистической информации. В настоящем разделе описан путь этой программы к такому выдающемуся успеху. Затем приведен обзор отдельных модулей программы.
Основным достоинством программного комплекса SPSS, как одного из самых существенных достижений в области компьютеризированного анализа данных, является самый широкий охват существующих статистических методов, который удачно сочетается с большим количеством удобных средств визуализации результатов обработки. Программный комплекс SPSS развивается уже на протяжении 35 лет. 11-ая версия, выпущенная в мае 2002 года, предоставляет широкие возможности не только в сфере психологии, социологии, биологии и медицины, но и в области маркетинговых исследований и управлении качеством продукции, что значительно расширяет применимость комплекса.
Предлагаемый материал содержит минимально необходимый объем сведений по теории статистического анализа. Основное внимание сконцентрировано на особенностях использования отдельных методов, возможностях, которые эти методы предоставляют, а также интерпретации результатов применения данных методов. Ну и конечно, описаны презентационные возможности SPSS 10/11, которые значительно превосходят объем функций, обеспечиваемых стандартными бизнес-программами, типа Excel.
Изложенный материал достаточен для того, чтобы студент или молодой ученый сделали свои первые шаги в обобщении статистических данных и поиске скрытых закономерностей, а умудренные опытом профессионалы обрели еще один мощнейший инструмент, повышающий эффективность практической деятельности.
Материал предназначен для широкого круга читателей, специализирующихся на обработке данных в маркетинге, социологии, психологии, биологии и медицине.
Литература -
Бююль А., Цёфель П. SPSS: Искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей: Пер. с нем. — СПб.: ДиаСофтЮП, 2005. — 608 с.
В этой главе мы на небольшом примере опишем процесс подготовки данных. За основу мы возьмем вымышленный опрос – так называемый "воскресный вопрос", который студенты, изучающие политологию в Марбургском университете, задавали избирателям: | "За кого бы вы голосовали, если бы в воскресенье были выборы в бундестаг?" С помощью следующей анкеты был проведен телефонный опрос 30 человек.
Кодирование и кодировочная таблица
Для того чтобы полученные данные можно было обработать, прежде всего следует создать кодировочную таблицу. Кодировочная таблица устанавливает соответствие между отдельными вопросам анкеты и переменными. используемыми при компьютерной обработке данных.
Матрица данных
Предположим, что 30 анкет были заполнены следующим образом: | | fragebnr | Sex | age | party | 1 | W-001 | женский | 45 | ХДС/ХСС | 2 | W-002 | мужской | 22 | СДПГ | 3 | W-003 | мужской | 19 | сдпг | 4 | W-004 | женский | 42 | ХДС/ХСС | 5 | W-005 | мужской | 34 | Зеленые/Союз 90 | 6 | W-006
Запуск SPSS. Редактор данных.
Начнем с ввода данных для небольшого примера анализа. | Запустите SPSS для Windows, дважды щелкнув левой кнопкой мыши на значке SPSS. | Откроется редактор данных SPSS (см. рис. 3.1). | Редактор данных – это одно из многих окон SPSS.
Определение переменных
Начнем с определения переменных. Переменную можно определить следующим образом: | В редакторе данных дважды щелкните на ячейке с надписью var или щелкните на ярлычке Variable view (Просмотр переменных) на нижнем краю таблицы.
Ввод данных
Приступим ко вводу данных: | | fragebnr | sex | age | party | 1 | W-001 | 1 | 45 | 1 | 2 | W-002 | 2 | 22 | 3 | 3 | W-003 | 2 | 19 | 3 | 4 | W-004 | 1 | 42 | 1 | 5 | W-005 | 2 | 34 | 4 | 6 | W-006 | 1 | 72 | 2 | 7 | W-007 | 2 | 38 | 3 | 8 | W-008 | 1 | 56 | 3 | 9 | W-009 | 2 | 61 | 1 | 10 | W-010
Сохранение файла данных
Сейчас мы сохраним созданный файл данных. Поступите следующим образом: | Выберите в меню команды File (Файл) › Save as… (Сохранить как…) Откроется диалоговое окно Save Data as (Сохранить данные как). | По умолчанию SPSS сохраняет файл данных в текущем каталоге с расширением .sav.
Копирование описаний переменных
В исследовании на тему "Здоровье и питание", в частности, проводится опрос о предпочитаемых диетах. Респонденты должны ответить, насколько к ним относится одно из следующих высказываний. | Я предпочитаю следующую диету | Да, конечно | Да | Частично | В малой степени | Нет | вегетарианскую | X
Основным инструментом анализа и визуализации статистических данных для меня всегда был Excel. Я работаю с ним ежедневно. По нему написал больше всего заметок и прочитал наибольшее число книг. Пожалуй, лучшее сочетание статистики и Excel я нашел в книге Левин. Статистика для менеджеров с использованием Microsoft Excel. Вторым инструментом, к которому я только прикоснулся, был R (см., например, Алексей Шипунов. Наглядная статистика. Используем R!). А недавно прочитал любопытную книгу Нил Дж. Салкинд. Статистика для тех, кто (думает, что) ненавидит статистику. В ней автор все примеры иллюстрирует в программе SPSS. Так что я решил попробовать и этот продукт.
На сайте IBM доступна пробная версия, которая будет работать на вашем ПК 14 дней. Регистрируетесь и скачиваете программу SPSS Statistics. При регистрации запомните пароль. Он вам пригодится для входа в программу. После запуска появляется приветственное окно:
Рис. 1. Приветственное окно SPSS; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то в левом нижнем углу окна кликните Не показывать это диалоговое окно в будущем.
Кликните Закрыть в правом нижнем углу экрана. Появится окно Редактор данных. По виду и функционалу Редактор похож на электронную таблицу, как лист Excel.
Рис. 2. Редактор данных
Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Окно вывода (Viewer). Оно показывает создаваемые вами статистические результаты и графики. Набор данных создается при помощи Редактора данных, а после анализа или построения графиков вы изучаете результаты анализа в Окне вывода.
Рис. 3. Окно вывода
Панель инструментов и строка состояния
Если вы хотите узнать, что делает иконка на панели инструментов, просто наведите на нее указатель мыши. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны.

Рис. 4. Панель инструментов

Рис. 5. Строка состояния
Использование справки
Справка настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Меню Справка содержит 10 разделов.
Рис. 6. Меню справки
Нажмите Темы, и перейдете в браузер на страницу центра знаний IBM на русском языке. Здесь представлена собственно справка, а также Учебное пособие, Разбор конкретных случаев, Инструктор по статистике, Разделы для подключаемых модулей Python и R.
Открытие файла
Вы можете импортировать данные из Excel, или ввести значения в таблицу, после чего сохранить в новом файле SPSS, или открыть готовый файл. В этой заметке мы используем файл Sample Data Set.sav. Пройдите по меню Файл –> Открыть –> Данные. Выберите файл. Данные загрузятся в окно редактора:
Рис. 7. Данные загружены из файла в окно редактора
Таблица и диаграмма
Допустим, мы хотим посчитать, сколько мужчин и женщин находится в нашей выборке, и вывести результат в виде столбчатой диаграммы. В окне Редактора данных пройдите по меню Анализ –> Описательные статистики –> Частоты. В открывшемся окне Частоты, выберите Gender, нажмите кнопку для переноса переменной в правое окно (или дважды кликните на Gender). Нажмите копку Диаграммы. Выберите Столбчатые. Нажмите Продолжить. Нажмите Ok.
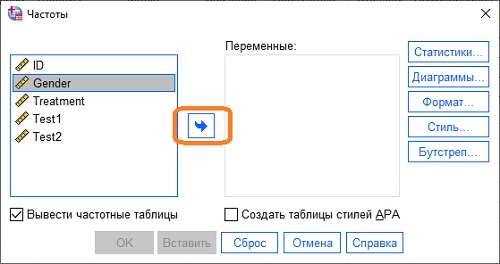
Рис. 8. Выбор переменной для анализа частоты
В окне вывода появится таблица и диаграмма:
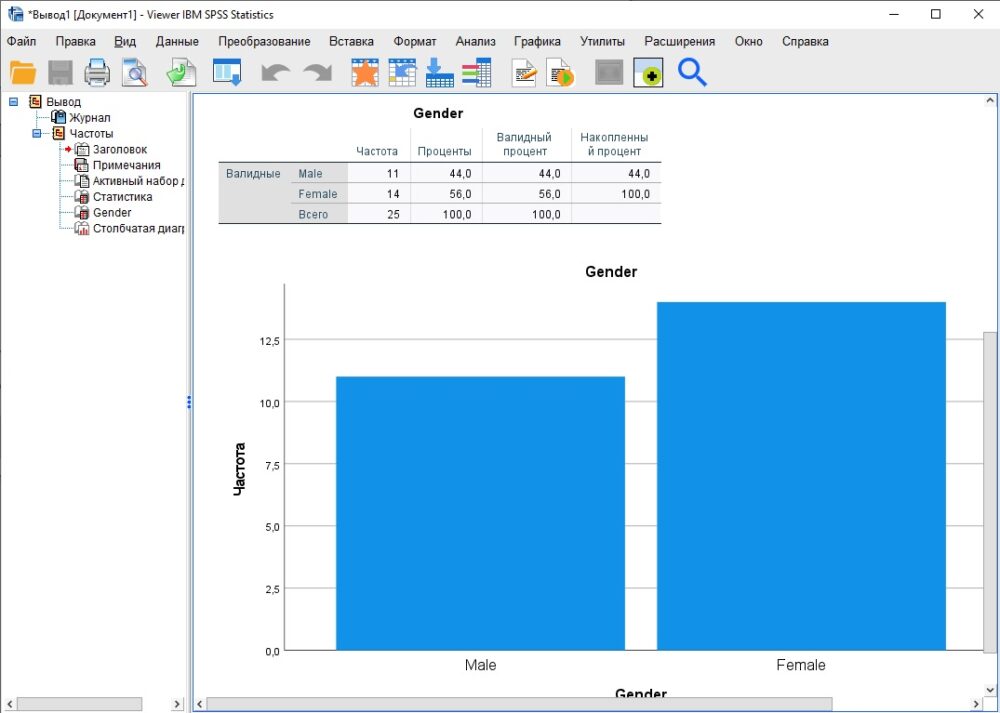
Рис. 9. Таблица и диаграмма в окне вывода
Оценка t-критерия
Давайте проверим, отличаются ли средние значения результатов Test 1 у мужчин и женщин. Этот анализ основан на t-критерии для независимых выборок. В редакторе данных пройдите по меню Анализ –> Сравнение средних –> Т-критерий для независимых выборок. В открывшемся окне переместите переменную Test1 в область Проверяемые параметры, а переменную Gender – в область Группировать по:
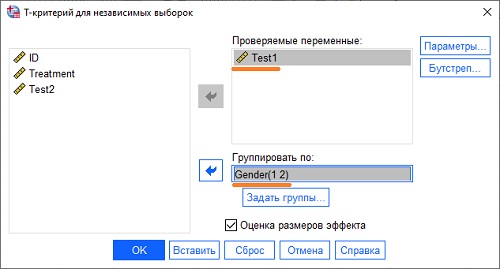
Рис. 10. Настройка расчета t-критерия для независимых выборок
Нажмите Ok. Программа сформирует таблицы проверки по t-критерию, и покажет их в окне вывода:
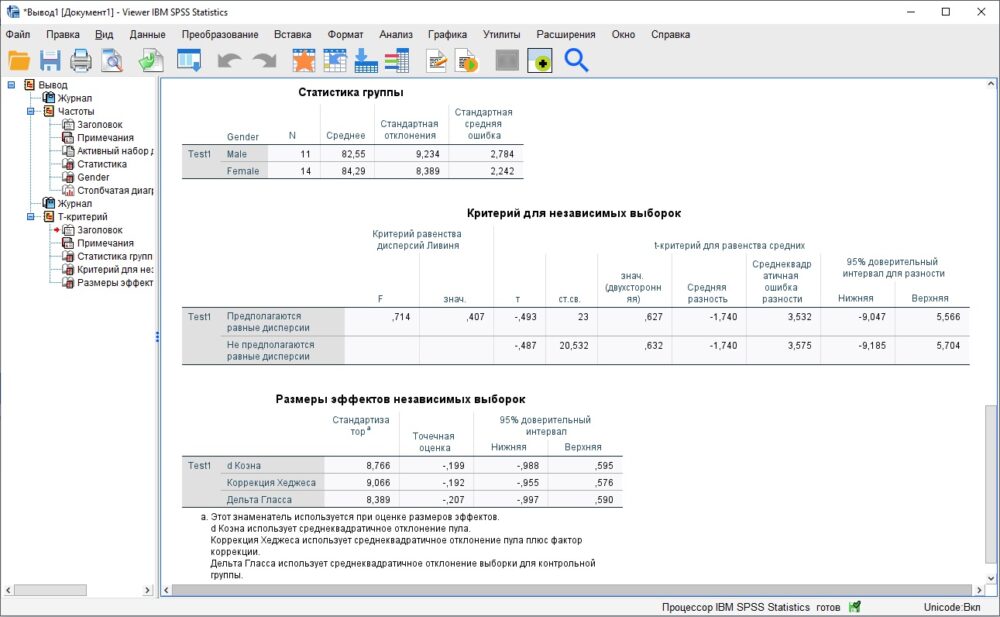
Рис. 11. Результаты проверки t-критерия для независимых выборок
T-тест показал, что различие между мужчинами и женщинами при прохождении Test1 незначимо.
Создание и редактирование файла данных
Давайте создадим набор данных, который только что загрузили из файла Sample Data Set.sav. Сначала определим переменные, а затем введем данные. В окне Редактора данных пройдите по меню Файл –> Создать –> Данные. Откроется новое окно Редактора данных. Обратите внимание, что окно открылось на вкладке Переменные (SPSS подсказывает, что сначала надо заняться ими).
Если вы поместите курсор в первую ячейку в колонке Имя, введёте любое имя и нажмёте Enter, SPSS для всех характеристик переменной автоматически проставит значения по умолчанию (см. строку 1 на рис. ниже).
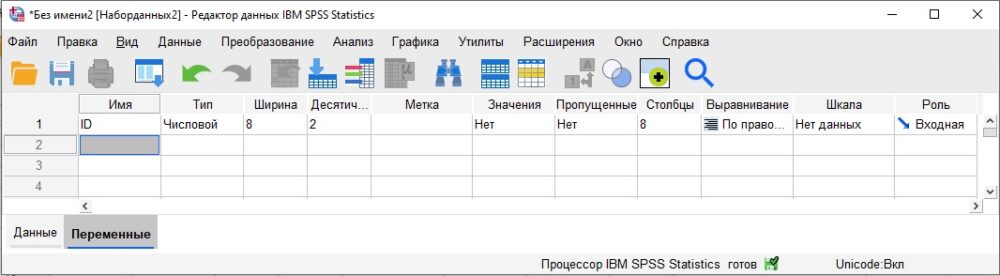
Рис. 12. Параметры по умолчанию
Подробнее о параметрах переменной:
- Имя переменной должно начинаться с буквы, иметь длину не более 64 символов, не содержать пробелы, подробнее см. здесь;
- Тип:
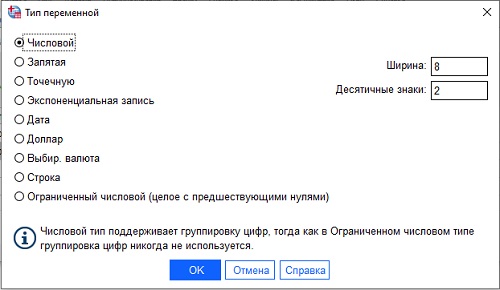
Рис. 13. Типы переменных
- Ширина задает количество символов в столбце, содержащем данную переменную;
- Десятичные определяет количество десятичных знаков;
- Метка задает метку переменной длиной до 256 символов;
- Значения устанавливает соответствие числовых значений и категорий; например, 1 для мужчин и 2 для женщин;
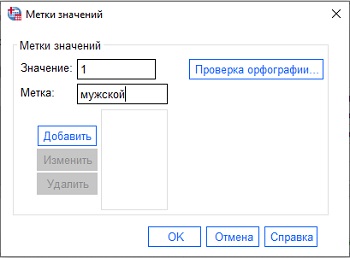
Рис. 14. Введение значений для категорийных переменных
Категорийные переменные в SPSS можно вводить в виде текстовых строк, например, Male и Female, а можно назначить им значения. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми записями. Но при визуальном просмотре файла, наоборот, имена (метки) нагляднее. Окно Метки значений позволяет вводить в SPSS числа, а выводить на экран метки: и волки сыты, и овцы целы. Чтобы это работало, находясь в Редакторе данных на закладке Данные, перейдите в меню Вид, и поставьте галочку напротив Метки значений.
- Пропущенные – указывает, как обращаться с пропущенными значениями;
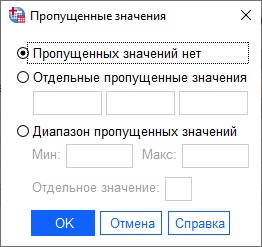
Рис. 15. Управление пропущенными значениями
- Ширина столбца определяет количество символов, выделенное для переменной в окне представления данных;
- Выравнивание – определяет, как будут выровнены данные в ячейке (влево, вправо, по центру);
- Мера – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная);
- Роль – определяет роль, которую играет переменная в анализе (входная, целевая и т.д.).
Определите следующие переменные:
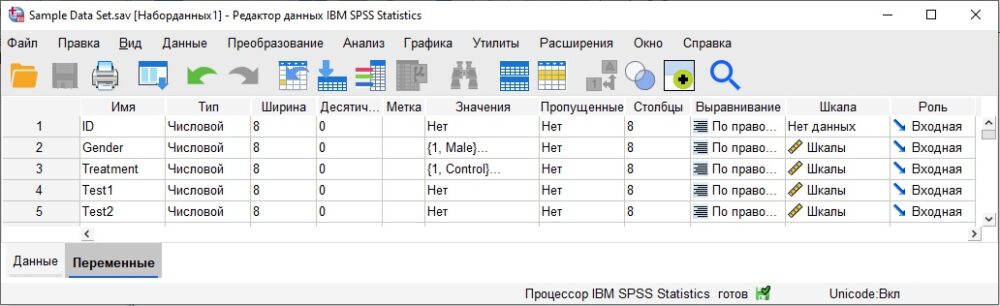
Рис. 16. Пять переменных в окне Редактора данных на закладке Переменные
Теперь вы можете переключиться на вкладку Данные и просто ввести все данные, которые представлены на рис. 7.
Печать из SPSS
Чтобы распечатать весь файл данных или его часть:
- убедитесь, что файл, который вы хотите напечатать, находится в активном окне;
- кликните Файл –>Печать;
- откроется диалоговое окно печати (рис. 17);
- выберите, что вы хотите распечатать: файл целиком или выделенный фрагмент (если предварительно фрагмент не был выбран, эта опция неактивна); нажмите Ok.
Рис. 17. Диалоговое окно печати
Вместо выбора принтера можно задать создание файл *.pdf.
Создание диаграммы в SPSS
Воспользуемся данными из файла Sample Data Set.sav. Откройте файл, на вкладке Данные, кликните меню Графика. Выберите одну из опций: Мастер диаграмм, Панель выбора диаграмм, Устаревшие диалоговые окна. Последняя опция позволяет выбрать один из стандартных типов диаграмм. Первые две опции проведут вас по пути создания диаграммы, наиболее подходящей к выбранным данным.
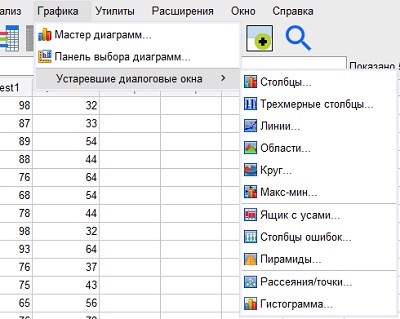
Рис. 18. Типы диаграмм
Выберите Столбцы, откроется диалоговое окно, предлагающее несколько вариантов оформления:

Рис. 19. Виды столбчатой диаграммы
Выберите Простая и Итоги по группам наблюдений. Нажмите Задать. Откроется окно Простые столбцы. Задайте, что будет анализировать диаграмма:
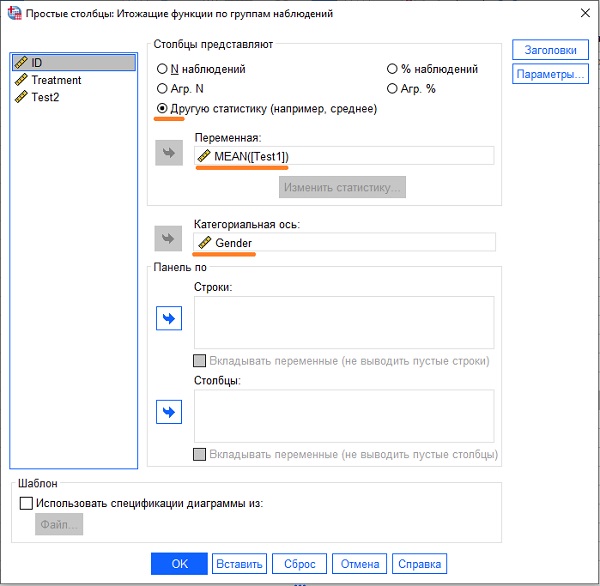
Рис. 20. Параметры аналитики диаграммы
Нажмите Ok. В окне вывода появится диаграмма: среднее значение Test1 раздельно по полу:
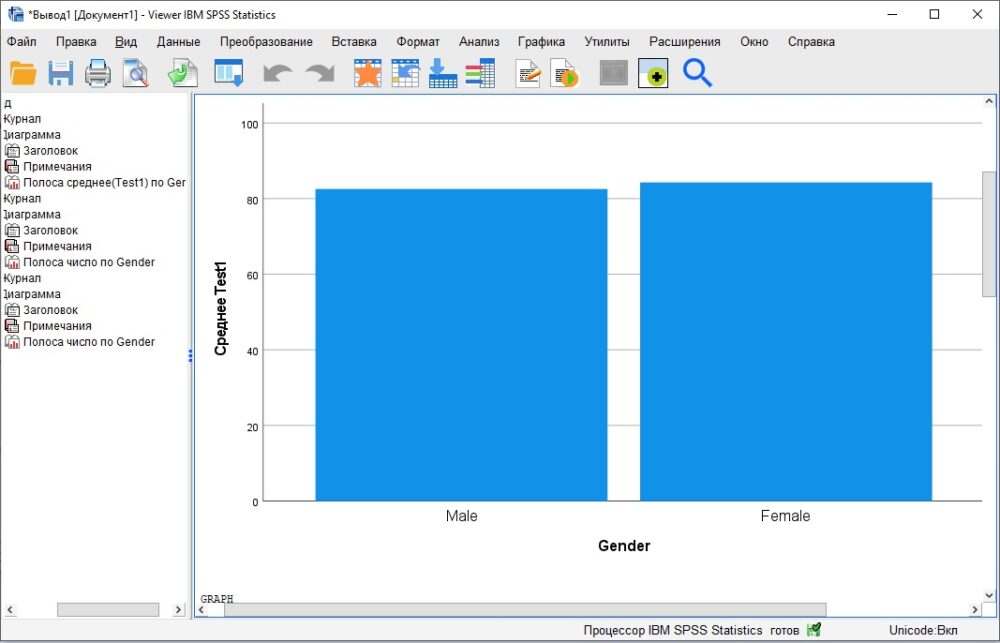
Рис. 21. Средние результаты Теста 1
Сохранение диаграммы
Диаграмма является частью окна вывода. В этом окне сохраняется любой выполняемый вами анализ. Диаграмма не является самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна вывода. Для этого:
- кликните Файл –>Сохранить;
- задайте имя для окна вывода и папку;
- нажмите Ok; вывод сохранится в файле с расширением *.spo.
Редактирование диаграммы
Для изменения диаграммы используйте Редактор диаграмм. Чтобы вызвать его дважды кликните на диаграмме в окне вывода.
Чтобы добавить заголовок кликните на соответствующей иконке на панели инструментов Редактора диаграмм:
Рис. 22. Кнопка Редактор диаграмм
На диаграмме появится область для ввода заголовка и окно Свойства, где можно выбрать шрифты, границы и заливку. Для добавления подзаголовка (или даже нескольких) кликните на иконке Вставить заголовок повторно.
Для изменения любого элемента дважды щелкните на нем. Можно отдельно щелкнуть на названии оси, подписях и самой оси. В первых двух случаях можно будет отредактировать шрифты и стили оформления, а в последнем – масштаб.
Чтобы выйти из Редактора диаграмм просто кликните на крестике окна или пройдите Файл –> Закрыть.
Описание данных
Частоты и сопряженные таблицы. Частоты подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например, по полу и возрасту. Для вычисления частот перейдите в окно Редактора данных, кликните Анализ –> Описательные статистики –> Частоты. Откроется диалоговое окно Частоты (см. выше рис. 8). Дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2:
Рис. 23. Диалоговое окно Частоты
Щелкните по кнопке Статистики. Откроется диалоговое окно Частоты: статистики. В разделе Разброс отметьте Стандартное отклонение. В разделе Положение центра распределения отметьте Среднее:
Рис. 24. Диалоговое окно Частоты: Статистики
Нажмите Продолжить, а затем Ok.
В окне вывода появится три таблицы: обобщенная, и подробная для каждой переменной – Test 1 и Test 2:
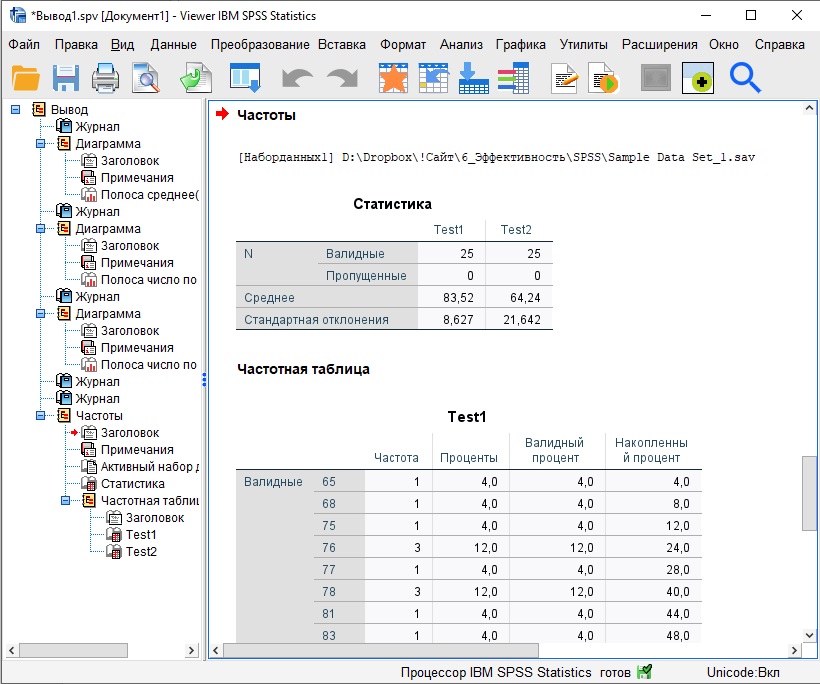
Рис. 25. Обобщенная статистика частот и фрагмент подробной таблицы частот Test 1
Выход из SPSS
Кликните Файл –> Выход. SPSS позаботится о том, чтобы сохранить все не сохраненные ранее или отредактированные окна, а затем закроется.
Только что вы кратко познакомились с SPSS. Однако эти навыки ничего не значат, если вы не понимаете смысла того, что делаете. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда люди могут рассказать, что означает тот или иной вывод и какой ответ он дает на поставленный вопрос. И особенно восхищайтесь, если вы сами можете это сделать!
1 комментарий для “SPSS Statistics быстрый старт”
отдельно хочу отметить книгу — Салкинд очень просто и доходчиво дает инфу, позволяя с нуля освоить методы статистики вывода.
wikiHow работает по принципу вики, а это значит, что многие наши статьи написаны несколькими авторами. При создании этой статьи над ее редактированием и улучшением работали авторы-волонтеры.
Компьютерная программа SPSS (с англ. Statistical Package for the Social Sciences — статистический пакет для общественных наук), разработанная IBM, предназначена для того, чтобы анализировать данные и составлять прогнозы на основании конкретных объемов данных. Работать с SPSS могут как преподаватели, так и студенты. Для этого достаточно освоить несколько основных команд этой программы. Данные, получаемые в результате, очевидны и статистически достоверны. С помощью этой программы можно быстро и эффективно провести серию исследований. Если раньше вы не использовали SPSS для анализа данных, воспользуйтесь советами, приведенными ниже, чтобы быстро во всем разобраться.

Загрузите файл Excel с данными. Соберите все необходимые данные и внесите их в файл Excel, придерживаясь формы заполнения таблиц.

Импортируйте необработанные данные в SPSS. Импортируйте все данные в SPSS через Excel-файл. Как только вы это сделаете, программа SPSS сможет их проанализировать.


Считайте полученные результаты. Программа выдаст вам эффективные и точные результаты, позволяя увидеть в каком направлении лучше двигаться и какие есть перспективы у проводимых исследований.

Проанализируйте графики и диаграммы. Если вам не удастся самостоятельно разобраться в полученных результатах, обратитесь за помощью к преподавателям или коллегам по исследованию. Или же обратитесь за консультацией в компанию, профессионально занимающуюся обработкой данных SPSS.

Примите как постулат выводы, полученные в результате анализа ваших данных. Основная задача SPSS — помочь вам сделать выводы, основанные на конкретных исследованиях. Программа поможет вам сделать выводы и увидеть перспективу вашего исследования с минимальным отклонением в статистике.
Читайте также: