
Python удалить csv файл
Формат CSV (Comma Separated Values) является одним из самых распространенных форматов импорта и экспорта электронных таблиц и баз данных. CSV использовался в течение многих лет до того, как был стандартизирован в RFC 4180. Запоздание четко определенного стандарта означает, что в данных, создаваемых различными приложениями, часто существуют незначительные различия. Эти различия могут вызвать раздражение при обработке файлов CSV из нескольких источников. Тем не менее, хотя разделители, символы кавычек и некоторые другие свойства различаются, общий формат достаточно универсален. Значит, возможно написать один модуль, который может эффективно манипулировать такими данными, скрывая детали чтения и записи данных от программиста.
Функции обработки CSV-файлов
csv.reader(csvfile, dialect='excel', **fmtparams) — возвращает объект reader, который построчно итерирует csvfile. Если csvfile является файловым объектом, то его нужно открыть с параметром newline=''. Дополнительный параметр dialect используется для определения ряда параметров, характерных для специфического CSV диалекта. Он может быть подклассом Dialect или одной из строк, возвращаемой функцией list_dialects(). Также могут передаваться дополнительные ключевые аргументы fmtparams для переопределения отдельных параметров форматирования в текущем диалекте.
Каждая строка, считанная из файла csv, возвращается в виде списка строк. Автоматическое преобразование типов данных не выполняется, если не указан параметр формата QUOTE_NONNUMERIC (в этом случае все поля без кавычек преобразуются в числа с плавающей точкой).
Короткий пример использования:
csv.writer(csvfile, dialect='excel', **fmtparams) — возвращает объект writer, конвертирующий пользовательские данные в CSV-файл csvfile. csvfile может быть любым объектом с методом write(). Если csvfile является файловым объектом, то его нужно открыть с параметром newline=''. Параметры dialect и fmtparams идентичны параметрам в функции csv.reader.
Необходимые методы экземпляра класса writer:
csvwriter.writerow(row) — записывает данные, представляющие одну строку CSV в файл, форматируя согласно текущему диалекту writer.
csvwriter.writerows(rows) — записывает данные, представляющие несколько строк CSV в файл, форматируя согласно текущему диалекту writer.
Пример использования writer :
csv.field_size_limit([new_limit]) — текущий максимальный размер поля. Если задан new_limit, то он становится новым макс. размером.
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds) — как reader, но отображает информацию о столбцах в словарь, ключи которого заданы в параметре fieldnames.
fieldnames это последовательность ключей. Если параметр опущен, в качестве ключей используются значения из первой строки файла. Если строка имеет больше полей, чем длина fieldnames , оставшиеся данные будут помещены в список с ключом из переменной restkey . Если строка имеет меньше полей, оставшиеся значения будут установлены в значение restval .
Остальные аргументы пробрасываются далее в экземпляр reader.
class csv.DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds) — как writer, но отображает словари в CSV-файл.
Обязательный параметр fieldnames - последовательность ключей, определяющие порядок, в котором значения из словаря будут записаны в строке CSV-файла f.
Параметр restval определяет значение в случае, если в словаре будет отсутствовать запись с данным ключом. Если словарь содержит лишние ключи, то поведение определяется параметром extrasaction . Если он 'raise', то выдаст ошибку. Если 'ignore', то такие ключи игнорируются.
Остальные аргументы пробрасываются далее в экземпляр writer.
Помимо методов writerow и writerows, DictWriter имеет также метод
DictWriter.writeheader() — записывает данные строки заголовка в CSV-файл, форматируя согласно текущему диалекту writer.
Пример использования DictWriter:
Диалекты и параметры форматирования
class csv.Dialect — для упрощения задания формата входных и выходных записей, конкретные параметры форматирования группируются в диалекты, подклассы csv.Dialect . Диалекты поддерживают следующие атрибуты:
Dialect.delimiter — разделитель столбцов в строке CSV-файла. По умолчанию ','.
Dialect.quotechar — символ, использующийся для "склейки" поля, содержащего специальные символы, такие как delimiter, quotechar, или символы новой строки. По умолчанию используется значение '"'.
Dialect.doublequote — как Dialect.quotechar , появляющийся внутри поля, должен экранироваться. Когда True, символ удваивается. Когда False, Dialect.escapechar используется как префикс к quotechar. По умолчанию True.
При записи файла, если doublequote=False и не установлен escapechar, выдаст ошибку при обнаружении quotechar в столбце.
Dialect.escapechar — символ, используемый writer для экранирования delimiter , если quoting установлен в QUOTE_NONE и quotechar , если doublequote=False . При чтении escapechar удаляет какое-либо особое значение со следующего символа. По умолчанию используется значение None, которое отключает экранирование.
Dialect.lineterminator — символы, используемые для завершения строки при записи. По умолчанию '\r\n'.
Dialect.skipinitialspace — если True, пробелы, непосредственно следующие за delimiter, игнорируются. Значение по умолчанию - False.
Dialect.strict — когда True, поднимает исключение если CSV файл не распознается. По умолчанию - False.
Dialect.quoting — контролирует, когда кавычки должны генерироваться writer и распознаваться reader. Он может принимать любые константы QUOTE_* и по умолчанию имеет значение QUOTE_MINIMAL.
csv.QUOTE_ALL — writer оборачивает в кавычки все поля.
csv.QUOTE_MINIMAL — writer оборачивает в кавычки только поля, содержащие специальные символы (delimiter, quotechar, lineterminator).
csv.QUOTE_NONNUMERIC — writer оборачивает в кавычки все поля, не являющиеся числами. reader преобразует все поля без кавычек к типу float.
csv.QUOTE_NONE — writer не оборачивает никакие поля в кавычки. Если в данных попадается delimiter или lineterminator, он предваряется символом escapechar, если установлен (исключение, если не установлен). reader не обрабатывает кавычки.
csv.register_dialect(name[, dialect[, **fmtparams]]) — связывает dialect с именем name. Подробности о диалектах см. в разделе "Диалекты и параметры форматирования"
csv.unregister_dialect(name) — удаляет связь диалекта с данным именем.
csv.get_dialect(name) — возвращает класс диалекта, свзанного с именем name.
csv.list_dialects() — список доступных диалектов. На данный момент это 'excel', 'excel-tab', 'unix'.
Предустановленные диалекты
class csv.excel — диалект CSV-файла, обычно генерируемого программой Excel.
class csv.excel_tab — диалект CSV-файла, обычно генерируемого программой Excel с настройкой "разделитель с помощью TAB".
class csv.unix_dialect — диалект CSV-файла, обычно генерируемого в UNIX-системах ('\n' для новой строки, закавычивание всех полей).
Определение диалекта
class csv.Sniffer — используется для угадывания диалекта CSV-файла. Имеет следующие методы:
csvsniffer.sniff(sample, delimiters=None) — анализирует пример и возвращает Dialect, соответствующий обнаруженным параметрам. Если задан параметр delimiters , он интерпретируется как все возможные разделители.
csvsniffer.has_header(sample) — анализирует текст и возвращает True, если первая строка похожа на строку заголовков.
Методы определения диалекта являются эвристическими; это означает, что Sniffer может ошибаться.
This is similar or identical to csv writer not closing file but I'm not 100% sure why my behaviour is different.
then finally in the function
This opens the test.csv file in the same direction as the script. Desired behaviour is for when the script has done what it's doing to the rows in the function, it renames the sheet to test.[timestamp] to archive it and watches the directory for a new sheet to arrive.
Later down the code;
Gives an error that the file can't be renamed because a process is still using it. How do I close this file once I'm done? csvfile.close() doesn't raise an exception, and if I step through my code in interactive mode I can see that csvfile is a "closed file object." What even is that? Surely an open file is an object but a closed one isn't, how do I make my code forget this even exists so I can then do IO on the file?
The with block should automatically close the file when it goes out of scope. Try renaming it outside the scope of the with block
os.rename('test.csv', "test." + time.strftime("%x") ) doesn't depend on csvfile being defined does it?
You do not need the file handle to rename the file, just the filename. os.rename('test.csv'. doesnt need anything defined :)
This is not valid Python code: def LoadCSV: , so please paste your actual code that you are using, rather than having us guess what is going on.
2 Answers 2
NOT FOR POINTS.
Code is not valid anyway, since your function name is wrong. If that was not intentional, better edit it or to produce a pseudo-replica of your code, rather than have us guess what the issue is.
To iterate, the issues with your code:
- def LoadCSV is not valid. def LoadCSV() is. Proof in following screenshot. Notice how the lack of () is showing syntax error markers.

Fixing (1) above, your next problem is using csvfile.close() . If the code is properly written, once the code is out of the scope of with , the file is closed automatically. Even if the renaming part of the code is inside the function, it shouldn't pose any problems.
Final word of warning -- using the format string %x will produce date-strings like 08/25/14 , depending on locale. Obviously, this is erroneous, as a / is invalid in filenames in Windows (try renaming a file manually with this). Better to be very explicit and just use %m%d%y instead.
Finally, see the running code on my end. If your code is not structured like this, then other errors we cannot guess might arise.

Result as follows after running:

Code for reference:
Note that on my end, there is nothing that watches my file. Antivirus is on, and no multithreading obviously is enabled. Check if one of your other scripts concurrently watches this file for changes. It's better if instead of watching the file, the file is sent as an argument post-renaming to this other function instead, as this might be the reason why it's "being used". On the one hand, and this is untested on my side, possibly better to copy the file with a new name rather than rename it.

Один из самых популярных форматов данных является CSV. Для работы с CSV в Python есть несколько библиотек и модулей. С помощью их вы сможете обрабатывать эти данные конвертируя их в словари и списки, создавать файлы и читать их. Основной модуль называется CSV и большинство задач разберем на его примере.
Навигация по посту
Как устроен формат CSV
Основное отличие формата CSV от обычного текста в его структуре, которая проявляется в разделителе. Именно из-за этого этот формат расшифровывается как 'comma separated values' (значения разделенные запятыми). Разделитель не всегда обязан быть в виде запятой, он может принимать и другие виды, например ';'. Разделители так же могут называться делимитер (delimiter). Пример того, как может выглядеть файл:
Первая строка может содержать название заголовки колонок, но это не обязательно. Так же видно, что разделители разделяют значения и из-за этого они не используются в конце строки.
Из-за простого формата CSV вам не обязательно импортировать модули. Вы можете использовать существующий функционал, который создаст данные в формате CSV, например так:
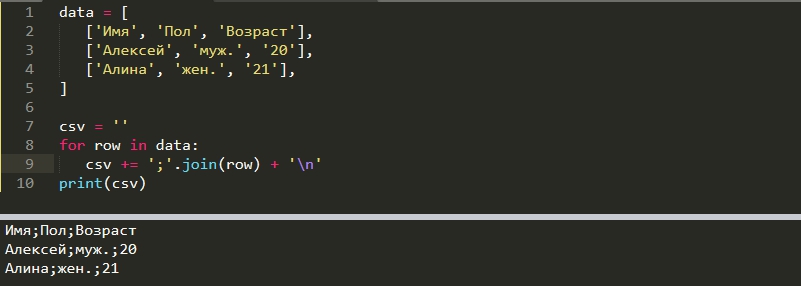
Тем не менее в модулях реализованы дополнительные возможности по анализу таких данных. Например преобразование в словарь или определение форматов (диалекта).
Чтение CSV файлов
Как уже говорилось, основной модуль уже установлен вместе с Python. Для чтения файлов используется функция 'reader()', которая возвращает объект для итерации. Так мы можем открыть файл в большинстве случаев:
Для каких-то ОС может понадобится открывать файл с указанием разделителя новой строки, т.е. так:
Указание разделителя
По умолчанию считается, что вы используете запятую в качестве делимитра. В моем файле, в качестве разделителя, стоит ';', а файл содержит кириллицу (кириллица имеет значение на Windows). В этом случае файл читается следующим образом:
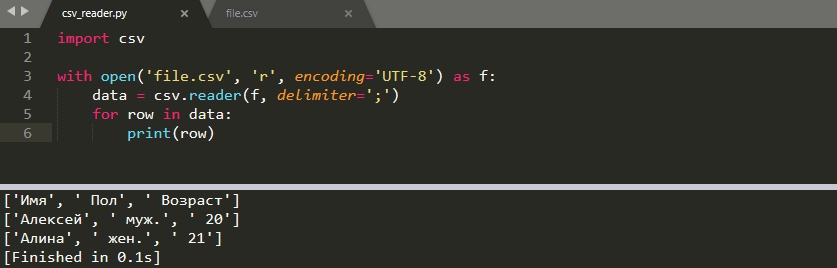
В случае Windows по умолчанию используется кодировка 'cp1251' и, если вы не укажете 'UTF-8', то может появится ошибка:
- UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 1: character maps to
Начальные пробелы
Со скриншота выше видно, что пробелы, в начале строки, не обрабатываются должным образом. Что бы убрать пробелы нужно указать параметр 'skipinitialspace':
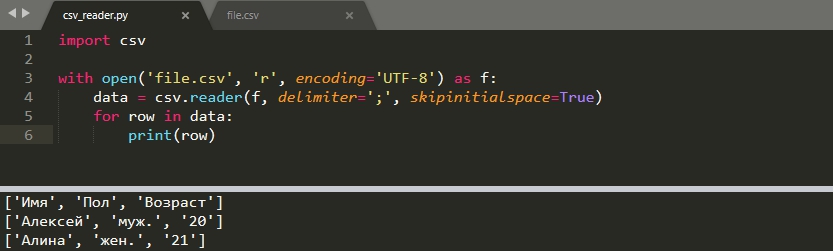
Кавычки
CSV файл может содержать кавычки в произвольных местах:
Убрать их можно используя параметр 'quoting':
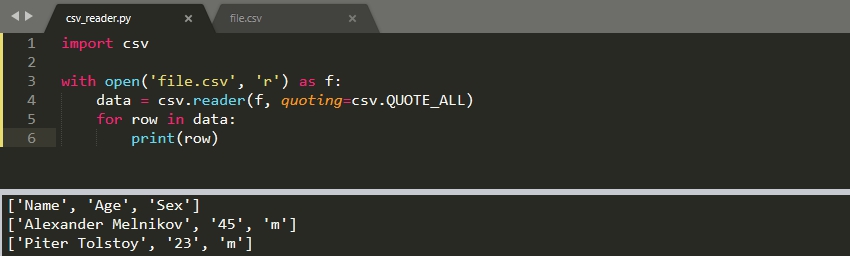
По умолчанию ищется двойная кавычка. Если вы хотите ее переопределить, то нужно использовать параметр 'quotechar'.
Поиска этой кавычки зависит от того, что указано в параметр 'quoting'. Так значение 'csv.QUOTE_ALL' говорит, что все значения находятся внутри кавычек. Параметр может принимать другие значения:
- csv.QUOTE_MINIMAL - используется по умолчанию. Кавычки используются в местах содержащие специальные символы (например двойная кавычка из quotechar или сам дилиметр);
- csv.QUOTE_NONNUMERIC - кавычки используются в нечисловых значениях. Если кавычек в значении не присутствует оно будет преобразовано во float;
- csv.QUOTE_NONE - кавычки, вокруг значений, не используются.
Если вы установили 'csv.QUOTE_NONE', а в файле все равно экранируются специальные символы, то можно использовать параметр 'escapechar' указывающий на символ экранирования.
Чтение с конвертацией в словарь
Если первая строка у вас содержит заголовки колонок, то вы ее можно преобразовать в ключи словаря. Что бы это сделать, вместо метода 'reader()' используется класс 'DictReader()':
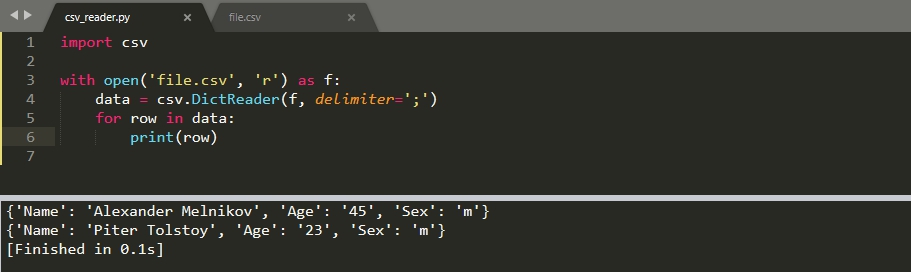
Тип словаря зависит от версии Python. Если вы используете версию ниже 3.8, то вернется 'OrderedDict', который можно преобразовать в обычный с 'dict()'. В версиях 3.8 и старше возвращается обычный тип словаря.
Параметры у класса аналогичны методу 'reader()'. Мы так же можем определять кавычки и символы экранирования.
Создание шаблона диалекта
Если у вас используется множество разных параметров и идет нарушение принципов DRY (dont repeat yorself), то вы можете использовать диалект (или просто шаблон). В примере мы регистрируем параметры под общим названием 'myDialect' и передаем в функцию или класс:
Автоматическое определение параметров CSV файла
Если используются разные файлы CSV и в каждом из них разные параметры для чтения, мы можем определить их автоматически с классом 'Sniffer'. Результат работы этого класса мы можем передать как диалект:
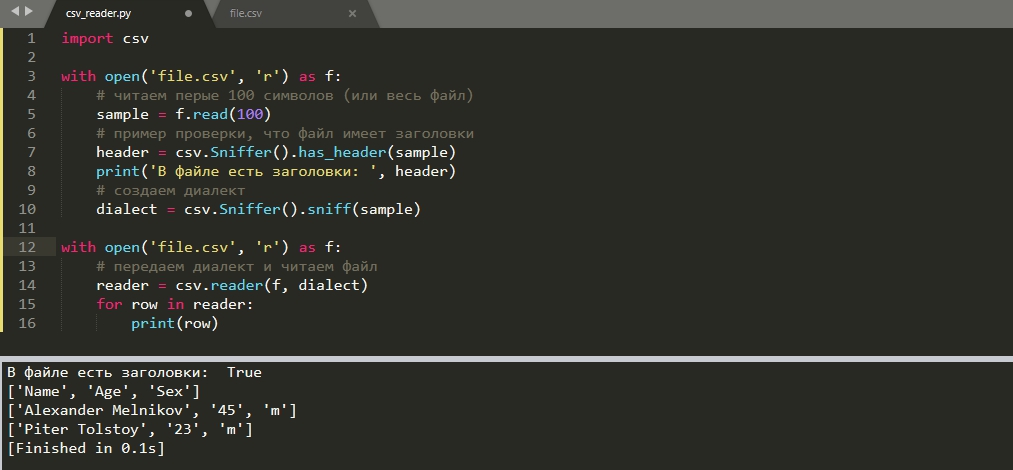
Метод 'has_header()' проверяет есть ли в файле заголовки. Аналогично этому методу могут быть использованы и другие методы проверяющие кавычки, делимитры и т.д.
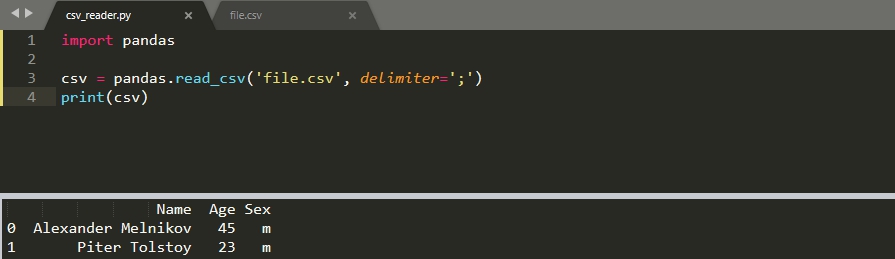
Чтение в pandas
В библиотеке для анализа данных pandas так же есть возможность прочитать CSV файл. Эта библиотека устанавливается отдельно:
Запись данных в CSV
Для записи данных есть функция 'writer()'. В эту функцию мы можем передать все те же параметры, что в случае чтения. Базовая запись данных будет выглядеть следующим образом:
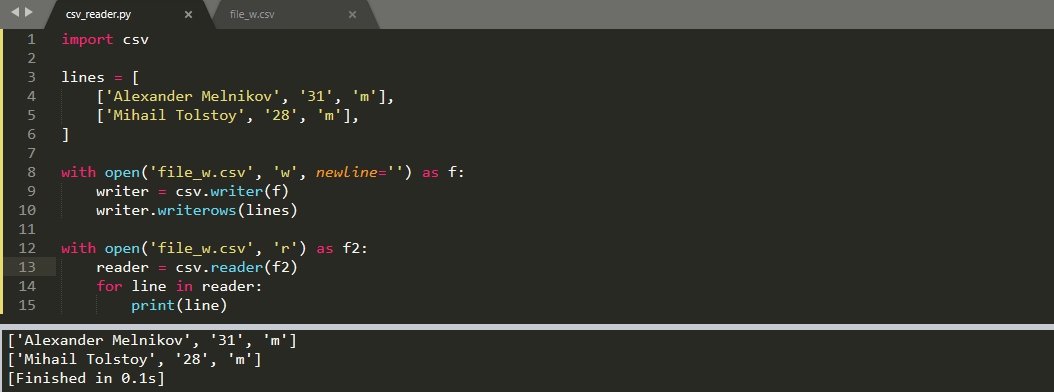
Как и понятно с примера выше:
- writerow - записывает каждый список построчно;
- writerows - записывает список списков в файл целиком.
Надобность в 'newline' так же может отличаться в разных ОС. Вы можете указать в функции 'writer' параметр 'lineterminator' со значением '\n', который обозначает символ переноса новой строки. По умолчанию он равен '\r\n':
Аналогично 'lineterminator' могут передаваться следующие параметры:
- quotechar - символ для экранирования значений попадающие под условия указанные в 'quoting'. По умолчанию этот символ равен двойным кавычкам;
- quoting - какие значения должны быть экранированы: csv.QUOTE_MINIMAL (если в значении есть делимитер или сам символ экранирования), csv.QUOTE_ALL (все символы), csv.QUOTE_NONNUMERIC (оборачивает в кавычки все нечисловые значения), csv.QUOTE_NONE (не использует кавычки и, если в значениях используется символ делимитера, экранирует его в 'escapechar');
- escapechar - если поведение с кавычками не установлено, то символы разделителя в значениях экранируются в этот символ.

Запись словаря
Аналогично чтению мы можем выполнить конвертацию словаря в CSV. Для этого есть класс 'DictWriter'. Запись словаря, от его чтения, отличается параметром 'fieldnames' в котором указываются заголовки колонок. Пример такой записи:
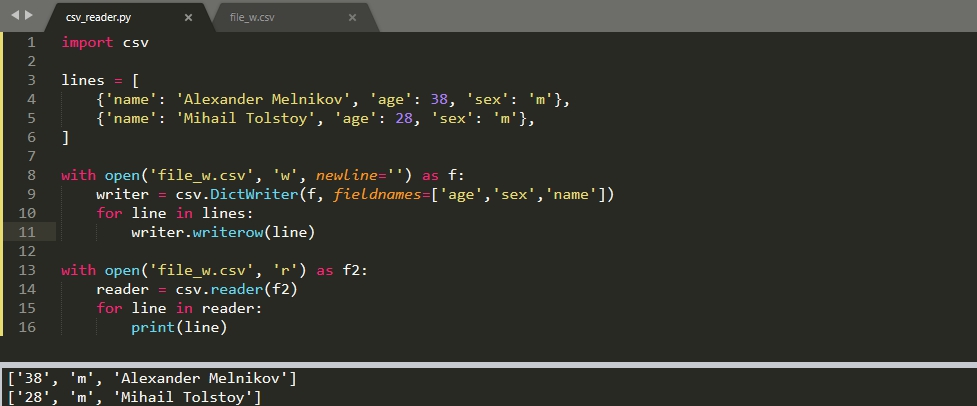
Параметры, переданные в 'DictWriter', могут быть такими же что и в 'writer'.
Запись с pandas
Что бы сохранить данные с pandas мы сначала должны выполнить конвертацию в 'DataFrame':
Спектр применения различных файлов огромен. Именно поэтому умение их удалять — важный навык. С помощью Python вы можете удалить любой файл на компьютере.
Допустим, вы пишете программу, которая анализирует статистику фондового индекса S&P 500 и записывает ее в файл. Возможно, вы хотите удалить уже существующий файл, чтобы освободить место для нового.
Метод os.remove() позволит вам удалить файл, а метод os.rmdir() — пустую папку. Если нужно удалить папку вместе с файлами внутри, можно воспользоваться методом shutil.rmtree() .
В этом руководстве мы научимся удалять файлы с помощью вышеуказанных методов, а также рассмотрим примеры их использования.
Руководство по удалению файлов
Как уже было сказано, в Python есть несколько методов для удаления файлов — os.remove() , os.rmdir() и shutil.rmtree() . Предназначены они для удаления файлов, директорий и папок с файлами внутри соответственно.
Как удалить файл с помощью метода os.remove()
Метод os.remove() используется для удаления файлов с жесткого диска. Важно: с его помощью нельзя удалить папку, только файл.
Модуль os позволяет разработчикам работать с операционной и файловой системой компьютера. os.remove — метод для удаления отдельных файлов, встроенный в модуль os .
Начать работу с этим методом просто — нужно импортировать модуль os с помощью оператора import .
Теперь мы готовы удалять файлы с помощью метода os.remove() . Рассмотрим синтаксис этого метода:
Метод os.remove() принимает один параметр — путь к файлу, который мы хотим удалить.
Допустим, мы пишем программу, которая анализирует оценки учеников математического класса в течение года.
Наши данные мы будем хранить в файле /home/school/math/final_analysis.csv. Но создавать файл сразу нельзя: возможно, он уже существует.
Чтобы удалить этот файл, можно написать следующую программу:
В первой строке программы мы импортируем модуль os . В нем содержится метод os.remove() , который мы использовали в нашей программе. Затем мы объявляем переменную path . Эта переменная хранит себе путь к файлу, который мы хотим удалить.
Затем мы вызываем os.remove() и передаем в качестве аргумента path . После этого происходит удаление файла.
Удаление пустой директории с помощью os.rmdir()
Метод os.remove() не позволяет удалить папку. В этом вам поможет метод os.rmdir() , который используется для удаления пустых файлов и директорий.
Метод os.rmdir() принимает лишь один параметр — путь к папке, которую вы хотите удалить. Синтаксис этого метода выглядит так:
Допустим, мы решили хранить наши обработанные данные внутри папки final, которая находится внутри /home/school/math directory. После запуска программы мы эту папку удаляем, ведь создаем точно такую же новую. Для удаления папки final можно написать следующую программу:
Наша программа удаляет директорию /home/school/math/final и печатает в консоль следующее:
Метод os.rmdir() используется для удаления только пустых директорий. Если внутри папки будут содержаться файлы, программа вернет ошибку:
Допустим, вы пишете программу для удаления файлов. Вам может понадобиться функция, корректно обрабатывающая ошибки в случае их возникновения. В этом случае вам поможет блок try except .
В примерах выше мы видели, что в некоторых случаях может быть возвращена ошибка (например, если методу не хватает прав для удаления объекта). Если мы используем os.remove() для удаления директории — программа вернет ошибку. И если мы используем os.rmdir() для удаления папки, содержащей файлы, тоже будет возвращена ошибка.
Когда вы пишете программу, удаляющую файлы, вам может понадобиться функция, которая обрабатывает ошибки. Здесь вам пригодится блок except :
Если мы запустим этот код и ошибок не возникнет, то папка будет удалена и в консоль выведется следующее:
В нашей программе мы использовали блок except . Выполнение начинается с проверки блока try . Если возникает ошибка — выполняется код внутри блока except . То есть, этот блок выполняется при возникновении ошибки OSError.
Удаление папки с файлами с помощью shutil.rmtree()
В библиотеке shutil есть метод shutil.rmtree() . Он используется для удаления папок, содержащих файлы.
Вообще эта библиотека предлагает сразу несколько методов, позволяющих проводить манипуляции с файловой системой. Но сейчас мы поговорим о shutil.rmtree() , с помощью которого можно удалить папку вместе с содержащимися в ней файлами.
Синтаксис метода shutil.rmtree() выглядит так:
Обратите внимание — мы импортируем модуль shutil . Как и os.remove() , метод shutil.rmtree() является частью внешнего модуля — именно поэтому мы проводим импорт.
Чтобы лучше понять метод, рассмотрим пример. Допустим, что программа для анализа оценок должна удалить директорию final. Но в ней уже хранятся файлы. Для удаления этой директории и всех файлов в ней мы можем написать следующую программу:

Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
CSV расшифровывается как «Comma Separated Values», т.е. «значения, разделенные запятыми». Это самый простой способ хранения данных в виде обычного текста. Данные представлены в табличной форме, где каждая строка является строкой записи таблицы. Сегодня мы поговорим про чтение формата CSV в Python. Расскажем о различных функциях для работы с CSV-файлами, а также о том, как создать свой файл CSV.
Чтение CSV-файла при помощи csv.reader(). Метод 1
Пример 1. Использование запятой в качестве разделителя
Допустим, у нас есть файл с именем sample1, содержащий некоторые данные. Такой файл можно создать с помощью любого текстового редактора или путем передачи значений в какую-нибудь программу для записи файла CSV. Как это делается, мы расскажем чуть позже.
Текст в этом файле разделен запятыми. Наши данные — сведения о различных книгах (порядковый номер, название, имя автора).

Переходим к коду. Чтобы прочитать файл CSV, нам нужен объект reader для выполнения функции чтения. Первым делом импортируем модуль csv (встроенный модуль Python). Далее укажем имя файла, который нужно открыть (или путь к нему). Затем инициализируем объект reader . Он будет перебираться в цикле for .
Данные из указанного файла выводятся построчно.

Запустим наш код. Можем увидеть, что наши данные автоматически преобразовались в списки, состоящие из элементов данных каждой строки.
Пример 2. Использование табуляции в качестве разделителя
В первом примере текст разделяется запятой. Однако мы можем сделать наш код более настраиваемым, добавив различные функции.
Возьмём код из предыдущего примера и сделаем лишь одно изменение: напрямую укажем разделитель ( delimiter ). В предыдущем примере не было никакой необходимости его указывать, потому что запятая — разделитель по умолчанию.

Как видите, результат немного изменился. Теперь все элементы строки являются одним элементом списка. Так произошло потому, что в этот раз мы указали в качестве разделителя не запятую, а \t .
Чтение CSV-файла при помощи csv.reader(). Метод 2
Теперь давайте обсудим альтернативный метод чтения файлов CSV. Предположим, у нас есть файл sample5, сохраненный с расширением .csv. В файле сохранены данные об учениках, их именах, классе и предметах.

Теперь перейдем к коду. Первый шаг такой же, как и в прошлый раз – импорт модуля. Затем укажем путь или имя файла, который необходимо открыть и использовать.
Этот код является примером одновременного чтения и изменения данных. Мы инициализируем два массива для будущего использования в этом коде. Затем открываем файл с помощью функции open() . Далее инициализируем объект, как мы это делали в приведенных выше примерах. Здесь снова используется цикл for .
Следующая функция сохраняет текущее значение строк и пересылает объект для следующей итерации:

Все строки добавляются к списку с именем rows .
Если мы хотим увидеть общее количество строк, вызовем следующую функцию вывода.
Чтобы вывести заголовок столбца или имя поля, используем функцию, в которой к тексту (с помощью метода .join() ) присоединяются все заголовки.
После выполнения вы можете увидеть результат, в котором каждая строка напечатана с полным описанием и текстом, который мы добавили с помощью кода во время выполнения.
Использование DictReader
Эта функция используется для вывода данных из текстового файла в виде словаря.
У нас есть файл sample7.txt со следующими данными об учениках.

Примечание. Не обязательно сохранять файл с расширением .csv, можно и в других форматах. Главное, чтобы в самом файле использовался простой текст и данные оставались в первозданном виде.
Теперь воспользуемся приведенным ниже кодом, чтобы прочитать данные и вывести их в формате словаря. Вся методика одинакова, только вместо reader используется DictReader .

Во время выполнения можно видеть, что данные печатаются в виде словаря. Данная функция преобразует каждую строку в словарь.
Пробелы в файлах CSV
Каждый раз при использовании csv.reader() мы автоматически получаем пробелы в выводе. Чтобы удалить эти лишние пробелы из вывода, нам нужно использовать функцию reader() , указав при этом специальный параметр. Предположим, файл содержит следующие данные, касающиеся информации о сотруднике.

Укажем значение skipinitialspace , равное True. Благодаря этому неиспользуемое свободное пространство удаляется из вывода.

Модуль CSV и диалекты
Если мы начнем работать, используя одни и те же файлы csv с форматами функций в коде, это сделает код очень некрасивым и непоследовательным. Модуль CSV помогает использовать метод диалектов в качестве опции для удаления избыточности данных.
Рассмотрим в качестве примера те же исходные данные, но на этот раз разделенные символом | . Мы хотим удалить этот символ, пропустить лишний пробел и использовать одинарные кавычки между соответствующими данными.

Используя следующую строчку кода, мы получим желаемый результат
Эта строка отличается, поскольку она определяет три основные функции, которые необходимо выполнить. Из выходных данных вы можете видеть, что символ | удаляется, и также добавляются одинарные кавычки.

Написание своего CSV-файла
Чтобы открыть файл csv, нам нужно его где-то взять. Если его нет, можно создать такой файл с помощью следующей функции.
Для начала импортируем модуль csv . Затем дадим имя файлу, который хотим создать. Для добавления данных мы будем использовать следующий код:
Данные вводятся в файл построчно, поэтому следует использовать именно этот оператор.

Заключение
В этой статье мы разобрали тему чтения формата CSV в Python. Мы показали, как вывести данные с помощью различных методов, в виде словарей или списков. Также мы рассказали, как удалить лишние пробелы и специальные символы из данных.
Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
Читайте также: