
Программа для кластеризации компьютеров
Программа KeyAssort нужна для кластеризации и структуризации семантического ядра.
1. Что такое кластеризация?
Кластеризация - это автоматическая группировка поисковых запросов на основании подобия выдачи поисковых систем. Процесс кластеризации происходит так - для каждого запроса собирается определённое количество URL из поисковой системы. Потом фразы между собой сравниваются на предмет совпадения общих URL. Фразы, у которых есть общий набор URL, объединяются в группы.
2. Зачем нужна кластеризация?
Кластеризация нужна для решения трёх основных задач:
- Экономия времени в десятки раз по сравнению с ручной разгруппировкой семантического ядра.
- Объединение разных семанически, но одинаковых по смыслу фраз. Например, "столетник" и "алоэ", "иван-чай" и "кипрей".
- Проверка совместимости запросов для продвижения на одной странице. Например, не коммерческий запрос "книга" и коммерческий "книга купить" не могут быть продвинуты на одной странице.
В итоге, если использовать ручную группировку, то можно получить достаточно большое количество запросов, которые не смогут быть продвинуты в топ поисковых систем. А при кластеризации, наоборот, получим большое количество ключевых слов, которые будут продвинуты с минимальными усилиями.
3. Что такое структуризация и зачем она нужна?
Структуризация - это логическое распределение групп запросов на категории. После группировки ключевых слов (не важно, ручной или кластеризации) вырисовываются логичные рубрики, по которым могут быть распределены группы запросов, до группировки же они не всегда очевидны. Программа KeyAssort помогает создать логичную структуру категорий не ограниченную по уровню вложенности.
Если подвести итог, то KeyAssort сильно сэкономит Вам время, усилия и бюджет для продвижения вашего сайта в топ поисковых систем.
Совершая покупку, Вы гарантированно получите:
Возможность группировать неограниченное количество слов в течение срока действия лицензии;
Обновления с новыми функциями;
Возможность предложить свою идею, добавить новый параметр.

Я недавно проводил исследование, в рамках которого было необходимо обработать несколько сотен тысяч наборов входных данных. Для каждого набора — провести некоторые расчеты, результаты всех расчетов собрать вместе и выбрать "лучший" по некоторым критериям. По сути это bruteforce перебор. Тоже самое происходит при подборе параметров ML моделей с помощью GridSearch .
Однако, с некоторого момента размер вычислений может стать для одного компьютера великоват, даже если запускать ее в несколько процессов с помощью joblib . Или, если сказать точнее, он становится слишком долгим для нетерпеливого экспериментатора.
И поскольку в современной квартире сейчас можно найти больше одного "недогруженного" компьютера, а задача явно подходит для массового параллелизма — пора собрать свой домашний кластер и запускать такие задачи на нем.
Для построения "домашнего кластера" прекрасно подойдет библиотека Dask (https://dask.org/). Она проста в установке и не требовательна к узлам, что серьезно понижает "уровень входа" в кластерные вычисления.
Для настройки своего кластера нужно на всех компьютерах:
- установить интерпретатор python
- установить пакеты dask и прикладные пакеты вашего распределенного приложения
- сконфигурировать запуск планировщика (scheduler) на одном из компьютеров и работников (worker) на всех доступных
Версии python
Поскольку Dask в своих операциях зависит от pickle, на клиенте, шедулере и рабочих узлах необходимо держать версии одинаковые или очень близкие версии python.
Версии 3.6 и 3.7 вместе работают, хотя и выдается предупреждение о различии версий. Узлы с 3.8 вместе с предыдущими работать не будут из-за новой версии pickle.
Если все ставится "с нуля", то, очевидно, лучше ставить везде одну версию.
Пакеты Dask
Dask и необходимые зависимости устанавливается как стандартные пакеты с помощью pip или conda
В документации под dask, последний пакет bokeh упоминается как опциональный, но не говориться, что без него "по-тихому" не будет работать прекрасная функция dask dashboard.
Без нее проводить мониторинг кластера и наблюдать как задачки разбегаются по узлам будет невозможно. А это очень поможет при оптимизации приложения для работы в распределенной среде.
Для сборки необходим gcc, потому:
- на MacOS должен быть установлен xcode
- если собираете docker image для запуска docker-worker, то начать с "тонкого" имиджа, типа python:3.6-slim-buster может не получиться. Прийдется либо доставлять необходимые пакеты, либо взять полноразмерный исходный имидж python:3.6 .
Запуск dask кластера
Процесс-планировщик создается один на кластер. Запускать его можно на любой машине. Единственная очевидная рекомендация — машина должна быть максимально доступна.
Процессы-работники запускаются на всех компьютерах, ресусами которых вы планируете пользоваться.
- nprocs / nthreads — количество процессов, которые будут запущены, и количество потоков в каждом из них. Поскольку GIL присутствует и на стороне процессов-работников, запускать обработку на многих потоках имеет смысл только если распределенный процесс реализован на чем-то низкоуровневом, как numpy. В противном случае нужно масштабироваться за счет количества процессов.
- memory-limit — объем памяти, доступный каждому процессу. Ограничивать доступную память процесам нужно очень аккуратно — при достижении предела по памяти процесс-работник перестартовывает, что может вызвать остановку процесса обработки. Я сначала ставил ограничение, но потом убрал.
- death-timeout — время в секундах, в течении которого процессы-работники будут ждать, пока планировщик перезапустится. Это время нужно подбирать в соответствии с ожидаемым временем перезагрузки компьютера-планировщика. Как ни странно, похоже, этот параметр не всегда учитывается.
- name — префикс имени процесса-работника, как он будет отображаться в отчетах планировщика. Это удобно, чтобы видеть "человеческие" имена сервисов-работников.
- local-directory — директория, которая будет использоваться для создания временных файлов
Запуск процессов-работников на Windows в виде сервиса
Понятно, что запуск dask-worker со всему параметрами делается в виде пакетного файла. Также, чтобы кластер поднимался сам, dask-worker должен запускаться как только компьютер стартовал.
NSSM, в частности, позволяет настроить рестарт пакетного файла, в случае его завершения. Это удобно для обработки ситуации, когда планировщик недоступен в течение длительного времени, и процессы-работники завершаются и останавливаются. В этом случае NSSM просто будет их перезапускать.
Проверка Firewall
Также необходимо проверить правила firewall: планировщик должен иметь возможность достучаться до процесса-работника.
Неприятно, что если на узле, где запущен процесс-работник, блокируются входящие соединения — то об этом станет известно только при запуске приложения. В этом случае, если даже до одного узла не получится достучаться — весь клиентский процесс упадет. До этого будет казаться, что все в порядке, поскольку все узлы будут выглядеть как подключенные.
По умолчанию каждый процесс-работник открывает случайный порт. При запуске можно указать прослушиваемый порт, однако в этом случае будет запустить только один процесс.
Подключение к кластеру
Подключение к распределенному кластеру происходит очень просто:
Если не указать расположение планировщика — запустится "локальный" кластер в пределах одной машины, но это не то что нужно.
Общие прикладные пакеты
Важно иметь ввиду, что все пакеты, которые необходимы для работы распределенного приложения должны быть установлены и на рабочих узлах кластера. Это касается pandas, numpy, scikit-learn, tensorflow.
Особо критично совпадение версий пакетов на всех узлах кластера для объектов, которые сериализуются.
Что делать, если на узлах кластера отсутствует необходимый пакет? Можно воспользоваться стандартной функцией удаленного запуска функций — и запустить pip
Понятно, что данный трюк не очень подходит, если рабочие узлы запускаются в контейнерах. В этом случае проще и правильнее собрать обновленный имидж. Но для "домашнего" кластера, собранного на обычных компьютерах, подойдет.
Пакеты и модули приложения
Если в состав приложения входят разработанные пакеты или модули, и вы хотите, чтобы программный код из них выполнялся распределенно — то эти пакеты и модули также должны быть распространены на все узлы кластера перед запуском приложения.
Это довольно серьезное неудобство, если вы все еще дорабатываете приложение и пытаетесь его структурировать, и попутно запуская его в распределенной среде Dask кластера.
Есть задокументированный трюк с передачей пакетов и модулей на узлы кластера во время исполнения. Класс Client предлагает метод передачи файлов на узлы upload_file() . После передачи, файл размещается в пути поиска и может быть импортирован процессом работником.
Файл-модуль можно передать непосредственно, а пакет прийдется предварительно запаковать в zip.
Масштабирование joblib
Я использую библиотеку joblib для удобного параллельного выполнения операций в рамках одного компьютера. Поскольку joblib позволяет подменить движок — модификация кода получается довольно простой:
Версия с joblib
Версия с joblib + dask
Хотя, конечно, на самом деле все немного сложнее. Если посмотреть на то, как проходят вычисления в базовом случае — кластер простаивает подавляющее большинство времени:

Работают только два из доступных 16 работников, огромные промежутки между интервалами загрузки.

Время на выполнение одного батча — 10-20 мс, а интервалы между работами может достигать 200мс.
Для достижения хорошей загрузки распределенных узлов модифицированная версия программы будет обрастать параметрами и настройками, призванными сократить простой узлов из-за передач данных по сети.
Имеет смысл подбирать размер пакета параметром batch_size . Он должен быть не очень маленький — чтобы время обработки на узле кластера было значительно больше времени передачи пакета по сети, но и не очень большим, чтобы десериализация не занимала много времени.
Иногда также помогает подготовить чуть большее количество пакетов с помощью параметра pre_dispatch .

На картинке отмечены области, где процесс вычисления все еще неоптимален.

- Красные области — простой узла. Они остались, но доля простоя существенно сократилась.
- Синие области — десериализацию (большие объекты загружаются в память)
- Черные области — сброс части данных на диск
Теперь время выполнения вычислений для пакета работы занимает 3.5-4 сек, а время на простой измеряется десятками милисекунд. Стало гораздо лучше: видно, что увеличение размера батча и количества пред-запланированных задач увеличили время, выделенное на выполнение, и не добавили много оверхеда.
Если процедура, выполняемая на узле, требует помимо основного аргумента какие-либо вспомогательные блоки данных (которые, например, просматриваются в процессе обработки), их можно передать на все узлы параметром scatter . Это существенно снижает объем передаваемых данных по сети при кажом вызове и оставляет больше времени на расчеты.
В итоге, после подбора параметров на таких простых задачах можно достичь почти линейного роста производительности от роста количества узлов.
Масштабирование GridSearchCV
Поскольку scikit-learn также использует joblib для реализации параллельной работы, масштабирование обучения моделей достигается ровно также — подменой движка на dask
В результате выполнения:

Каждый перебираемый вариант преобразуется в отдельную задачу для dask. Таким образом все варианты распределяется случайным образом по всем доступным процессам-работникам.
При наличии достаточного количества работников в кластере — все работы начинают выполняться параллельно.
К сожалению, в случае если модель с разными значениями гиперпараметров сходится за разное время (как в данном случае) — параллелизм не приводит к сокращению времени пропорционально количеству узлов кластера. Но длительность всего процесса подбора становится сравнима с самым долгим вариантом — уже очень неплохо.

Библиотека Dask — прекрасный инструмент для масштабирования для определенного класса задач. Даже если использовать только базовый dask.distributed и оставить в стороне специализированные расширения dask.dataframe, dask.array, dask.ml — можно существенно ускорить эксперименты. В некоторых случаях можно добиться почти линейного ускорения рассчетов.
И все это — на базе того, что у вас уже есть дома, и используется для просмотра видео, прокрутки бесконечной новостной ленты или игр. Используйте эти ресурсы на полную!
Хар-ки компьютеров:
2.40 Ghz | 2.27 Ghz - оба двухядерные, от intel
4 Gb RAM- одинаково
512 Mb GPU - одинаково, от nvidia
Dell|Asus
Для того, для чего вы хотите - никак не создать.
Кластер - это даже согласно статье из Википедии, которую вы приводите - это слабо связанная вычислительная система.
Попробую объяснить, используя аналогию.
Вы считаете, что компьютеры можно объединять также, как можно объединять усилия людей, наполняющих бочку водой, таская ее ведрами. Один человек наполнит за час, два - за полчаса, и так далее. Но это процесс, который распараллеливается элементарно.
А на самом деле, кластер работает подобно команде сценаристов, которые пишут сценарий сериала из двадцати серий, работая удаленно по бумажной почте: сначала главный сценарист придумывает персонажей и общий сюжет, записывает это, потом ему нужно разбить его на серии и отослать каждому из сценаристов, указав, какую серию тому нужно прописать в подробностях. Если бы он писал все сам, ему бы понадобилось по неделе на серию, итого - двадцать недель. А съемки можно начинать, когда готова первая серия (через неделю). Поскольку съемки одной серии занимают три дня, съемочная группа будет простаивать четыре дня из каждой недели, пока не будет готова следующая серия (деньги во время простоя тоже расходуются, хотя ничего не производится). Съемки будут, таким образом, завершены через 20*7+3=143 дня.
Наемным сценаристам тоже нужно по неделе на написании серий, но начальная работа главного сценариста тоже занимает неделю, плюс - три дня на доставку "каркаса сценария" наемным сценаристам, три дня на доставку сценария серий обратно, еще пять дней на проверку и исправление нестыковок. Итог - начинать съемки можно только через 25 дней, а не через семь, но продолжать их можно уже непрерывно. Съемки будут завершены через 25+3*20=85 дней.
Ровно как здесь нельзя ускорить процесс еще больше, заставив больше сценаристов писать по половине серии (потому что при этом растет сложность стыковки кусков сюжета, которые написаны разными людьми, потому им придется переписываться, теряя время), так и пытаясь запустить на кластере условную игру, придется просадить кучу времени на медленное общение узлов между собой по сети.
Чтобы всё "летало" в реальном времени в игре, вам нужен один мощный компьютер с многоядерным процессором, мощной видеокартой и быстрой шиной, которая всех их объединяет. А собрать кластер из сотни древних ноутов на медленном Ethernet и получить производительность в сто раз больше в играх - это фантастика из дурацких фильмов про хакеров.
Нагрузка на сервер — это важный показатель использования серверного оборудования. Хит – это запрос клиента к серверу для получения информации. Нагрузка сервера определяется как отношение количества клиентских запросов (хитов) ко времени, выражается в хитах в секунду. Согласно исследованиям Microsoft в 2010 году высоконагруженным сервером можно считать сервер с нагрузкой 100-150 хитов в секунду.
В литературе встречаются такие понятия как HPC-система, высоконагруженная система, высоконагруженный кластер, Highload-система, суперкомпьютер, которые порой используются как синонимы. Мы будем понимать сайт с нагрузкой не менее 150 хитов в секунду.
Кластер – это группа компьютеров, которые работают вместе и составляют единый унифицированный вычислительный ресурс. Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются Linux и BSD.
Чтобы понять каким образом задачи, выполняемые кластером, распределяются по его узлам необходимо дать определение масштабироемости. Масштабируемость — способность системы справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов. Система называется масштабируемой, если она способна увеличивать производительность пропорционально дополнительным ресурсам. Масштабируемость можно оценить через отношение прироста производительности системы к приросту используемых ресурсов. Чем ближе это отношение к единице, тем лучше. Также под масштабируемостью понимается возможность наращивания дополнительных ресурсов без структурных изменений центрального узла системы. Масштабирование архитектуры высоконагруженной системы может быть горизонтальным и вертикальным. Вертикальное масштабирование заключается в увеличении производительности системы за счёт увеличения мощности сервера. Главный недостаток вертикального масштабирования в том, что оно ограничено определённым пределом. Параметры железа нельзя увеличивать бесконечно. Однако на самом деле вертикальная компонента присутствует практически всегда, а универсального горизонтального масштабирования как такового не существует. Горизонтальное масштабирование заключается в увеличении производительности системы за счёт подключения дополнительных серверов. Именно горизонтальное масштабирование является сейчас фактически стандартом. Известен также такой термин, как диагональное масштабирование. Оно подразумевает одновременное использование двух подходов.
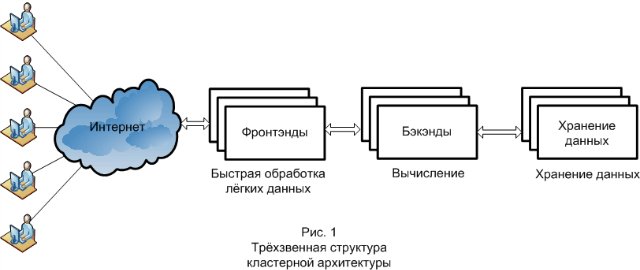
И наконец, необходимо определить основной принцип, использующийся при построении любой кластерной архитектуры. Это — трёхзвенная структура системы (рис. 1). Три звена – это фронтэнд, бэкэнд и хранилище данных. Каждое звено выполняет свои функции, отвечает за различные стадии в обработке запросов и по-разному масштабируется. Первоначально запрос приходит на фронтэнд. Фронтэнды отвечают, как правило, за отдачу статических файлов, первичную обработку запроса и передачу его дальше. Второе звено, куда приходит запрос, уже предварительно обработанный фронтэндом — это бэкэнд. Бэкэнд занимается вычислениями. На стороне бэкэнда, как правило, реализуется бизнес-логика проекта. Следующий слой, который вступает в дело обработки запроса – это хранилище данных, которые обрабатываются бэкэндом. Это может быть база данных или файловая система.
Обзор программно-аппаратных средств для построения кластерной HPC-системы
При построении кластера встаёт задача как распределять нагрузку между серверами. Для этого используется балансировка нагрузки, которая кроме самого распределения выполняет ещё ряд других задач, например: повышение отказоустойчивости (при выходе из строя одного из серверов система будет продолжать работать) и защита от некоторых типов атак (например SYN-flood).
Балансировка фронтэндов и их защита
Масштабирование бэкэндов
Масштабирование СУБД
И наконец, в описании программных средств, использующихся при создании кластерных HPC-систем необходимо упомянуть средства масштабирования хранилищ данных. В качестве хранилищ данных для веба используются базы данных общего назначения, самые распространённые из них это MySQL и PostgreSQL.
Основной техникой масштабирования СУБД является шардинг, вернее корректнее было бы назвать шардинг не масштабированием, а разбиением данных по машинам. Суть метода в том, что при увеличении количества данных происходит добавление новых шард — серверов, которые добавляются при заполнении имеющихся шард до некоего лимита.
При масштабировании СУБД на помощь приходит техника репликации. Репликация — это средство связи между серверами баз данных. С помощью репликации можно перенести данные с одного сервера на другой либо продублировать данные на двух серверах. Репликация используется в технике масштабирования «виртуальных шард» — при помощи репликации данные разносятся так, чтобы каждый бэкэнд-сервер работал со своим виртуальным шардом, информация о том где физически находится искомый шард хранится в таблице соотвестствия. Также техника репликации в методе масштабировании, основаном на особенностях запросов к базе данных: редкие операции обновления и частые запросы на чтение. Каждый бэкэнд-сервер работает со своим сервером базы данных, они называются SLAVE, на этих серверах происходят операции чтения из таблицы (функция SELECT). Если же осуществляется запись в таблицу (функции INSERT и UPDATE) то запрос поступает на сервер MASTER и оттуда реплицируется на все сервера.
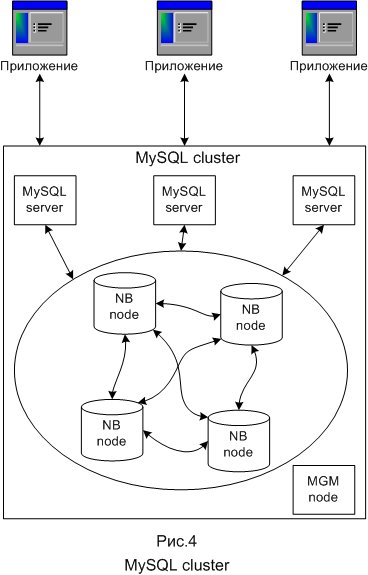
В MySQL используются разные системы хранения данных. Чащё всего это MyISAM и InnoDB. Существует также система хранения NDB, которая используется в специальном средстве масштабирования MySQL под названием MySQL cluster. Кластерная часть MySQL Cluster в настоящее время конфигурируется независимо от серверов MySQL. В MySQL Cluster каждая часть кластера именуется node (узел), при этом ноды на самом деле являются процессами. Может иметься любое число нод на одном компьютере. В минимальной конфигурации кластера MySQL будет по крайней мере три ноды: управляющая (MGM node) – её роль: управлять другими нодами внутри MySQL Cluster, типа обеспечения данных конфигурации, старта и остановки узлов, выполнение резервного копирования и т.д.; нода базы данных (DB node) — управляет и сохраняет базу данных непосредственно, имеется столько DB-узлов, сколько имеется фрагментов для репликаций, например, с двумя репликациями по два фрагмента каждая, надо четыре DB-узла; клиентская нода (API) — узел пользователя, который обратится к кластеру, в случае кластера MySQL, узел пользователя традиционный сервер MySQL, который использует тип хранения NDB Cluster, допуская доступ к кластеризуемым таблицам.
Распределённые вычисления как альтернативное решение
Порой, вместо построения собственной высоконагруженной системы на основе кластерной архитектуры, клиенту проще и выгоднее воспользоваться интернет-сервисами распределённых вычислений. Распределённые вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединённых в параллельную вычислительную систему. История распределённых вычислений ведёт своё начало с 1999 года, когда первокурсник Северо-восточного Университета США Шон Фэннинг написал систему обмена MP3 файлами между пользователями. Этот проект получил название Napster. По примеру Napster развился целый класс P2P (или пиринговых) сетей нового, децентрализованного типа, P2P-файлообмен состоит в том, что пользователь загружает файлы не с сервера, а с компьютеров других пользователей файлообменной сети, IP-адреса которых он получает со специализированного сервера, называемого трекером или хабом. Загрузка файлов происходит одновременно со всех пиров (участников пиринговой сети) и сопровождается одновременной отдачей, таким образом пиринговая сеть представляет собой некое распределённое файловое хранилище.
Технология распределённых вычислений развивалась, и принципы P2P стали использоваться не только для создания распределённых файловых хранилищ, появились распределённые базы данных, потоки, процессоры.
Грид-вычисления (grid — решётка, сеть) — это форма распределённых вычислений, в которой «виртуальный суперкомпьютер» представлен в виде кластеров, соединённых с помощью сети, работающих вместе для выполнения огромного количества заданий. Грид — это система, которая координирует распределённые ресурсы посредством стандартных, открытых, универсальных протоколов и интерфейсов для обеспечения нетривиального качества обслуживания. Основной идеей, заложенной в концепции грид-вычислений, является централизованное удалённое предоставление ресурсов, необходимых для решения различного рода вычислительных задач. Пользователь может запустить любую задачу с любого компьютера на вычисление, ресурсы для этого вычисления должны быть автоматически предоставлены на удалённых высокопроизводительных серверах, независимо от типа задачи. Распределение ресурсов, в котором заинтересованы разработчики грид, это не обмен файлами, а прямой доступ к компьютерам, программному обеспечению, данным и другим ресурсам, которые требуются для совместного решения задач и стратегий управления ресурсами. Выделяют следующие уровни архитектуры грид: базовый (содержит различные ресурсы, такие как компьютеры, устройства хранения, сети, сенсоры и др.); связывающий (определяет коммуникационные протоколы и протоколы аутентификации); ресурсный (реализует протоколы взаимодействия с ресурсами РВС и их управления); коллективный (управление каталогами ресурсов, диагностика, мониторинг); прикладной (инструментарий для работы с грид и пользовательские приложения).
Программа тестировалась под Windows 7, 8, 10. Если под Windows 8 будут проблемы, то можно запустить в режиме совместимости с Windows 7. Если у Вас другая ОС, например MacOS, то программу можно запустить через виртуальную машину.
Для пользователей MacOS и Parallels:
Для работы в программе на виртуальной Windows - необходимо сохранять проекты в каталог, который доступен только одной операционной системе(Windows). При сохранении в общедоступный каталог - Parallels не дает программе забрать файл в монопольный доступ.
Какой срок лицензии у приобретаемой программы?
Для работы программы нужны xml лимиты, где мне их взять?
Если у Вас есть сайты, добавленные в Яндекс-вебмастер, то в интерфейсе https://xml.yandex.ru/ Вам уже выделено определённое количество лимитов. Если же сайтов нет, то Вы можете зарегистрироваться на сайте XMLRiver , в разделе "покупка запросов" скопировать адрес для совершения запроса и вставить его в программу, при этом 1000 лимитов будут Вам стоить всего от 10 до 20 рублей.
У меня в семантическом ядре 1000 запросов, сколько мне нужно лимитов для кластеризации?
Вам нужно 1000 лимитов, столько же, сколько и запросов. На один запрос израсходуется один лимит.
Если я поменяю компьютер, мне выдадут новую лицензию?
Новую лицензию можно получить в личном кабинете.
У меня не устанавливается программа, выдаёт ошибку
Программа установки по какой-то причине не может получить доступ к необходимым каталогам.
Одной из причин может быть отсутствие прав у текущего пользователя. Поэтому можно порекомендовать запустить программу под администратором.
Еще вероятная причина - блокировка программы антивирусом либо фаерволом. Отключите антивирус при установке.
Если у Вас Windows10, инструкция по отключению встроенного брандмауэра.
Если у Вас avast, вот цитата с официального форума:
"Скорее всего проблемы у ваших пользователей как раз из-за установок по умолчанию. Как раз по умолчанию Аваст автоматически помещает неизвестные приложения в "песочницу".
Если они используют бесплатный Avast Free, то посоветуйте вашим пользователям:
1. Открыть главное окно Аваста и перейти на вкладку Дополнительная защита
2. На вкладке перейти в раздел AutoSanbox
3. Открыть настройки AutoSandbox, нажав кнопку Настройки (она там единственная)
4. В появившемся окне настроек изменить поле Режим AutoSandbox на Спрашивать
5. Сохранить новые настройки, нажав кнопку ОК и закрыть главное окно Аваста
В режиме Спрашивать при запуске неизвестных или сомнительных программ Аваст откроет окно, в котором он спросит как ему поступить. Если программа известна пользователю и он доверяет её источнику, то ему надо только выбрать из списка режим обычного открытия и не забыть отметить галочку запомнить это действие. "
Могу ли я порекомендовать добавить свою функцию в программу?
Да, предлагайте и голосуйте за уже предложенные идеи здесь, всё будет внедрятся в порядке важности для большинства пользователей.
Мне нужна вторая программа на рабочий или домашний компьютер/ноутбук
На вторую и последующие лицензии программы продусмотрена скидка 20%!
Для её получения введите промо-код kasecond в форму покупки KeyAssort.
Вопросы по кластеризации
Кластеризация - это автоматическая группировка поисковых запросов на основании выдачи поисковых систем. Процесс кластеризации происходит так - для каждого запроса собирается определённое количество URL из поисковой системы. Потом фразы между собой сравниваются на предмет совпадения общих URL. Фразы, у которых есть общий набор URL, объединяются в группы.
Что такое сила группировки?
Сила группировки - это минимальное количество общих URL у фраз, которые должны совпасть для объединения запросов в группы.
Что такое hard, middle и soft виды кластеризации и чем они отличаются?
При Soft кластеризации запросы сравниваются на предмет общих url у всех запросов в группе. Например, у запроса А есть общий набор url с запросом Б, у запроса Б есть общий набор url с запросом В. При этом запросы А и В будут объединены в одну группу, не смотря на то, что они могут не иметь общего набора url.
При Middle-кластеризации для объединения запросов в группы берется один основной запрос, а все остальные сравниваются с ним по количеству общих URL-ов в собранных данных. Если количество общих URL-ов превышает порог или равен ему - запрос добавляют в группу.
При Hard-кластеризации запросы объединяются в группу, только если есть общий для всех запросов набор URL, который показывается по всем этим запросам в топ-10.
Soft-кластеризация дает самые большие группы - высокую полноту и низкую точность. Hard-кластеризация показывает высокую точность группировки и низкую полноту. В middle кластеризации полнота и точность максимально уравновешены.
Что такое миграция запросов?
Если в процессе кластеризации определённый запрос попал в группу с минимально допустимым совпадением по количеству url (сила кластеризации), но в процессе дальнейшей кластеризации обнаружилось, что у этого запроса более сильная связь с другой группой, то он мигрирует.
Например, была выставлена сила кластеризации 3. Запросы А и Б были объединены, т.к. между ними 3 общих url. Но дальше в процессе кластеризации обнаружилось, что у запроса Б 7 общих url с запросом В, при этом запросы А и В не схожи. Если включена миграция, то запрос Б будет перемещён в группу к запросу B. Если же миграция выключена, запрос Б останется с запросом А.
Почему не все ключевые фразы объединились?
Ключевые фразы не объединяются, когда у них не находится общих URL с другими фразами в вашем семантическом ядре.
Что делать с фразами, которые не объединились?
Если вы найдёте в несгруппированных фразах такие, которые, на ваш взгляд можно объединить с другими фразами или группами, объединяйте. Возможно, по этому запросу низкое качество выдачи поисковых систем и фразы не сгруппировались по этой причине.
Под другие ценные фразы, которые вы не объединили вручную, можно выделить отдельные страницы.
Как увеличить количество объединённых фраз?
Есть несколько способов, два самых действенных:
1. Собрать бо́льшее, чем топ 10, количество url для каждой фразы;
2. Понизить силу группировки.
Читайте также: