
Программа для голосового управления компьютером
Алиса, Siri, Маруся - это далеко не весь список проектов в области голосовых помощников. С каждым днем проектов становится больше, а функционал шире и кажется настал тот момент, когда всерьез можно подумать о переводе компьютера на голосовое управление.
В рамках данного цикла статей я разберу создание голосового ассистента, работающего локально на вашем компьютере и имеющего широкий функционал, начиная с "запусти музыку" и заканчивая "создай новый проект в PyCharm".
Распознавание речи
Такая популярная тема не могла остаться без огромного количества статей, но с появлением API Яндекса и Google большое количество статей начинается и заканчивается так:
Это имеет место быть, но у меня натура пытливая, да и опыт в машинном обучении у меня имеется, так почему бы не сделать распознавание самому? Потому что это огромная гора, потратив на подъем на нее кучу времени ты лишь осознаешь, что вершина очень далеко.
"И что не так с import speech_recognition?" спросили меня, когда я вывел первую версию статьи на суд людской.
Конфиденциальность - Яндекс и Google могут упорно заявлять, что наши данные никуда не утекут и не будут нигде использоваться, но готовы ли вы поставить свою карьеру на это их заявление? Вот и система безопасности любой крупной компании тоже не готова, так что при работе с гос. контрактами или при доступе к секретности использование такого решения будет запрещено.
Языки - Давно вы говорили на керекском? Думаю, что вы даже не слышали как звучит этот язык, все потому, что носителей этого языка всего 2 человека в России. А теперь представим, что один из них захочет себе "Джарвиса". Конечно это крайний случай, но открытые API не всегда справляются с заявленными языками, что говорить о других?
Интернет - Недавно заезжал в прекрасное место около Рязани - птички, да поля бескрайние. Так вдохновляет! Но Алиса не оценила отсутствие интернета. Такая любовь к городской жизни объяснима, хоть детище Яндекса и может распознать голос любого человека, говорящего на русском языке, но развернуть такую махину на компьютере (Сбер недавно заявлял о Нейросети на 23 млрд параметров), а тем более на своем смартфоне задача невыполнимая.
Определившись со значимостью, начнем по порядку.
Звук - это волна
Компьютер не дружит с волнами, но обожает цифры.
Возьмем какое-то время t (шаг дискретизации), например 1 секунда. И начнем через каждое время t записывать уровень шума на микрофоне (точки на графике ниже). После чего возьмем число A = 256. Это число будет характеризовать во сколько бит мы хотим записать точку.
- Уровень максимального шума (УМШ) - максимальное значение, которое может выдать микрофон
- Уровень тишины (УТ) - значение, которое выдает микрофон при тишине
Тогда УМШ после записи должен быть равен (А-1), то есть 255, а УТ = 0
Отсюда, число ШК = (УМШ - УТ) / А
ШК - шаг квантования
Теперь каждое t секунд мы будем брать значение с микрофона, делить его на ШК и полученное число записывать в файл. Записанный файл назовем "Запись 1.wav" и попробуем послушать. Ничего осознанного там мы не услышим, так как мы взяли очень большой шаг дискретизации (t). Здесь появляется еще одна характеристика записи - частота дискретизации.
Из физики помним, что:
Возьмем часто используемую частоту 44 кГц, и теперь голос на записи начал звучать. Сохраним запись в папочке Data, чтобы удобнее было с ней работать.
Мы записали 5 секунд с частотой дискретизации 44 кГц и получили 200 000 чисел. Как можно заставить компьютер понять, что там сказано?
Так как звук это волна, значит, то что мы записали есть сумма колебаний разных частот, а как доказано до меня, именно в частоте скрыта информация передаваемая звуком. Здесь то мы и приходим к преобразованию Фурье (FT), а точнее его модификации Быстрое преобразование Фурье (FFT).
После преобразования Фурье мы получаем набор частот, характеризующий нашу дорожку.
На этом этапе мы можем сделать отсеивание информации. Так как мы слышим в диапазоне от 20 Гц до 20 кГц, все что выше этого диапазона нас не интересует. Мы же используем речь, чтобы общаться друг с другом, а значит кодированная информация должна лежать в слышимом диапазоне.
Мы хотим посимвольно распознавать речь, ведь это даст нам более гибкий инструмент. Для этого используем "окна". Возьмем первые n наносекунд и сделаем для них преобразование Фурье. Потом следующие n и так далее. Теперь у нас есть данные, основываясь на которых мы можем попробовать предсказать, какой символ из нашего словаря произносится в каждом "окне".
Также мы не знаем, когда именно сказана буква. Может произойти так, что она попадет на стык "окон", что разобьет букву на два "окна" и затруднит ее распознавание. Тогда хочется взять "окно" с данными из предыдущего "окна", тем самым делая нахлест.
Проведя преобразование Фурье для всех "окон", мы получим спектрограмму .
Теперь мы можем работать с ней как с картинкой и применить алгоритмы, помогающие компьютерам видеть собак или объезжать препятствия, но такой подход говорит о том, что нейронная сеть будет просто прогнозировать вероятность соответствия преобразования Фурье символу из словаря. В сказанных словах еще есть иногда и смысл, чтобы его могла использовать наша нейронная сеть используем LSTM слой.
Чтобы не расширять статью, здесь не буду рассказывать, что такое нейронная сеть.
Вот на этом канале можно послушать про основы.
Когда мы говорим о нейронных сетях, то возникает такое представление:

Да, это крутая визуализация простой нейросети. Но когда мы хотим работать со смыслом текста, то нам нужен контекст, а следовательно, нейросеть должна помнить, что было до этого. Для такой памяти разработали рекуррентные нейронные сети (RNN).

Хоть и избитая, зато понятная
RNN слой имеет, как и обычный слой, вход X и выход Y, но при этом еще есть вход h(t-1) и выход h. Когда нейронная сеть такого типа просчитывает себя, она формирует массив Y, который идет не только на выход слоя, но и на вход следующему просчету сети.

Пример:
Хотим перевести "Привет" на английский язык.
Первый проход сети:
x = "п" в категориальном представлении x.shape = (1, 34)
h(t-1) = нулевой вектор h(t-1).shape = (1, 22)
y = w * (h & x), здесь x и h дополняют друг друга (h & x).shape = (1, 56), w.shape = (1, 56)
Второй проход сети:
x = "р" в категориальном представлении x.shape = (1, 34)
h(t-1) = y из прошлого прохода h(t-1).shape = (1, 22)
y = w * (h & x), здесь x и h дополняют друг друга (h & x).shape = (1, 56), w.shape = (1, 56)
Словарь
"В категориальном представлении", давайте теперь разберемся с тем, что я имел ввиду.
Как с волнами - компьютер, так и машинное обучение с буквами не очень дружит. Следовательно, нам нужно превратить буквы в цифры. Самое простое, что можно придумать, это пронумеровать символы, получив словарь:
В данном режиме на выходе нейронной сети мы будем получать одно число от 0 до 37, которое не будет иметь правильного смысла. Например, если нейронная сеть будет думать между "а" и "я", то в ответе она вообще выдаст какое-нибудь "п". Чтобы этого не произошло, давайте попросим нейросеть выдавать нам вероятность того или иного символа на этом месте. Чтобы это реализовать наш словарь должен иметь такой вид:
"а": [1, 0, 0, 0 . ],
"б": [0, 1, 0, 0 . ],
"в": [0, 0, 1, 0 . ],
"г": [0, 0, 0, 1 . ]
.
" ": [. 0, 0, 0, 1]
>
Здесь каждый символ закодирован массивом из нулей, где на месте порядкового номера стоит 1. Получив такой словарь, мы можем перейти к подготовке данных для обучения.
Данные
Теперь перейдем к одному из самых интересных вопросов: "Где взять данные?".
Вообще есть два варианта:
Со "скачать" все просто, например для начального обучения я использовал этот датасет (Habr/Git)
Преобразование данных, с которым я столкнулся в этой статье, принимает на вход WAV файлы, так что преобразуем OPUS в WAV:
На данный момент обучение проходило на модулях:
Теперь наш манифест имеет такой вид:

Если внимательно пройтись по данной таблице, то можно найти огрехи по типу "ааа", "яя", но они встречаются так редко, что лень искать я даже не смог быстро найти для иллюстрации.
Создать же свой датасет тоже не очень сложно, если вас не интересуют конечно объемы Open STT. Чуть позже я выпущу статью о том, как быстро справился с этой задачей с помощью Telegram и 150 строк кода.
В общих словах вам нужно взять текст, разбить его на фразы, а после озвучить эти фразы, записав 1000 WAV файлов (у меня это получилось примерно 1,5 часа данных). В своих экспериментах я взял для озвучивания "Преступление и наказание", но в ходе озвучки понял, что там попадаются слова, которые в повседневной жизни не встречаются (Спасибо, Кэп), что немного обесценивает знание контекста, к которому мы стремились выбирая LSTM. Так что, думаю, третьим шагом обучения будут заготовленные команды по типу:
Алиса, как погодка?
Алиса, посмотри в Яндексе.
Открой первую ссылку
CTC loss
Ну вот мы и дошли к самому главным вопросам:
Как провести обучение без сложной разметки?
Как понять, что "орвлыарлов" не похожа на "Привет, как дела?", и как оценить степень похожести?
В 2006 году вышла статья Алекса Грейвса «Connectionist temporal classification», которая рассказывает как это можно сделать и доказывает это математикой. Так как математика точная наука и не любит приблизительных пересказов, я оставлю ее за скобками своей статьи.
Общий смысл подхода сводится к тому, чтобы подсчитать вероятность каждого символа в каждом "окне", после чего преобразовать это в строку выбрав более вероятные символы (" " - тоже символ), а дальше подсчитать расстояние Левенштейна выдав его метрикой похожести.
Модель
Результат
Тут не все так однозначно, с одной стороны:


Такой результат я получил при обучении на своем компьютере через 2 дня обучения.
Планы
Тут наткнулся на идею поверх прикрутить лингвистическую модель, которая бы удаляла огрехи по типу отсутствия пробелов между словами.
Также скоро закончу кастомный датасет и отполирую им мелкие дефекты.
Выбрать файлы, на которых нейронка спотыкается, и проанализировать. Есть два варианта:
файл дефектный - решение: удаляем его из датасета, благо Open STT огромный
нейронка мало с ним работала - решение: добавляем его в кастомный датасет
Управление голосом – одна из важнейших функций умных устройств. Она позволяет людям с ограниченными возможностями здоровья полноценно пользоваться гаджетами, да и для обычных пользователей голосовой ассистент становится помощником в решении повседневных задач. В этой связи важно разобраться, как настроить голосовое управление компьютером на базе Windows 10 на русском. И, в первую очередь, нужно заняться выбором ПО.
ПО для голосовых команд
Голосовое управление выполняется при помощи программного обеспечения. В этом отношении у пользователя есть широкий выбор приложений, которые будут способны осуществить задуманное. Ниже рассмотрим лучшие программы.

Typle
Одно из самых щадящих, с точки зрения потребления ресурсов ПК, приложение, поддерживающее массу полезных функций. Так, с помощью голоса владелец компьютера может запускать софт, открывать документы и взаимодействовать с программами, работающими в онлайне. Typle поддерживает русский язык, а для первичной настройки требуется:
- Запустить приложение.
- Нажать на кнопку «Добавить пользователя».

- Задать входные данные.
- Нажать кнопку «Добавить команды» и зарегистрировать необходимые действия.

К минусам Typle стоит отнести тот факт, что программа не имеет предустановленных команд и рассматривается исключительно в качестве средства выполнения действий голосом, но никак не в качестве полноценного ассистента.

Speaker
Еще одна простая программа, в возможностях которой легко сориентируется даже новичок. Приложение работает по схожему с Typle принципу. После первого запуска владельцу компьютера нужно зарегистрировать пользователя, а также команды для выполнения тех или иных действий, будь то запуск программ или открытие конкретной странице в браузере. По аналогии с Typle, приложение Speaker нельзя назвать полноценным голосовым помощником.

Laitis
В отличие от двух предыдущих, эта программа распространяется как на платной, так и на бесплатной основе. Во втором случае пользователю доступен ограниченный функционал, а в работе приложения неминуемо будут встречаться баги. В то же время Laitis справляется с поставленными задачами, предлагая зарегистрировать неограниченное число команд. Но, опять же, Laitis – не голосовой ассистент, а софт для обработки пользовательских команд, произнесенных голосом. Поэтому не стоит рассчитывать на то, что с вами будет общаться виртуальный помощник.

«Горыныч»
Разработка российских программистов, отличающаяся возможностью работать и онлайн, и офлайн. При регистрации пользователь заносит всю необходимую информацию, после чего «Горыныч» начинает распознавать голосовые команды. Из минусов важно отметить непродуманный интерфейс и общий проигрыш в оформлении, если сравнивать «Горыныча» с конкурентами.
Speechka
Это тоже отечественная разработка, но Speechka во многом базируется на технологии Google Voice Search. Функции нельзя назвать сверхинновационными: запуск приложений, открытие документов и поиск информации в сети (разумеется, через Google). Как и в случае с ранее рассмотренными программами, пользователю придется самостоятельно регистрировать команды, но зато с их распознаванием не должно возникнуть серьезных проблем.

«Алиса»
Куда более серьезный и проработанный софт, представляющий собой полноценного голосового ассистента. В «Алисе» уже запрограммированы основные команды, благодаря чему владельцу компьютера не придется долго копаться в настройках. Одновременно с этим предлагаются следующие интересные фишки:


- интеграция с онлайн-сервисами, включая Госуслуги;
- моментальный поиск информации в сети.

«Алиса» идеально распознает русскую речь и крайне редко допускает ошибки. Однако данное приложение не является оптимальным средством управления компьютером. Она не интегрирована в Windows 10 по умолчанию, в связи с чем пользователю приходится регистрировать команды или, как они здесь называются, «Навыки». Только после этого «Алиса» сможет осуществлять манипуляции с данными в оффлайне.
Cortana для Windows 10
Последним на очереди идет стандартный голосовой ассистент для компьютеров на базе Windows 10. Cortana рассматривается нами в последнюю очередь только из-за того, что она не поддерживает русский язык (во всяком случае пока). Поэтому пользоваться «Кортаной» могут лишь те, кто обладает разговорными навыками других языков.
На заметку. Cortana поддерживает английский, немецкий, французский, китайский, итальянский, испанский и японский языки.
Но у «Кортаны» есть несколько преимуществ, заставляющих рассматривать ее в качестве основного средства голосового управления. Во-первых, это стандартный инструмент, не требующий скачивания дополнительного софта и оплаты подписки. Во-вторых, Cortana – полноценный ассистент. Наконец, «Кортана» интегрирована в систему, что позволяет рассчитывать на управление любыми процессами компьютера.

Как использовать распознавание речи в Windows 10
Процесс взаимодействия голосом с компьютером напрямую зависит от того, какой софт выбрал пользователь для управления. Если это простая утилита вроде «Горыныча» или Typle, то владельцу придется регистрировать команды. Только затем его запросы, произнесенные на русском языке, будут обрабатываться, а софт начнет осуществлять те или иные манипуляции.
«Алиса» – совершенно другой пример. Здесь пользователь получает в свое распоряжение виртуальную ассистентку, готовую вести диалог без предварительного ввода команд. Достаточно задать интересующий вопрос – и помощница сразу же даст на него ответ.
И, конечно же, отдельно стоит рассматривать Cortana. Это оптимальный вариант ассистента и средства для настройки голосового управления, если вы пользуетесь компьютером на базе Windows 10. Но и здесь есть свои недостатки, которые затрагивают русскоязычных пользователей.
Также, вне зависимости от выбранного софта, необходимо дать разрешение на работу микрофона и осуществление операций в фоне. В противном случае программа, будь то Typle или «Алиса», не будет распознавать человеческую речь.
Большинство людей говорит быстрее, чем набирает текст на компьютере. В итоге это может привести к неприятностям, так как из-за скорости мысли человек нередко забывает о том, что хотел сообщить. Однако с помощью голосовых помощников для ввода текста в Windows 10 на русском языке удается избежать подобных ситуаций. Такие программы ускоряют передачу информации и облегчают жизнь пользователей.
Что можно сделать с помощью голосового ввода текста
Данная функция реализуется с помощью отдельной программы, которая автоматически переводит произнесенные слова в письменный текст.

Эта технология позволяет:
- переводить аудиофайлы (точнее, слова) в текст;
- увеличить скорость переноса информации в компьютер (человек говорит быстрее, чем печатает);
- набирать текст людям с ограниченными возможностями.
Windows 10 не поддерживает данную функцию. Для реализации технологии голосового текста потребуется установка сторонних приложений.
Для использования такой функции потребуется микрофон. Причем тип аппарата в данном случае не играет роли.

Проверка и настройка микрофона
Прежде чем приступать к использованию функции голосового ввода текста, необходимо проверить работоспособность микрофона. Для этого нужно:
- Нажать кнопкой мыши на значок динамика, расположенный в правом нижнем углу экрана.
- Открыть «Записывающие устройства».

- Выбрать микрофон. Если этого значка нет, то нужно кликнуть правой кнопкой мыши по свободному полю и отметить пункты «Показывать отсоединенные устройства» и «Показывать отключенные устройства». Затем в новом окне следует выбрать микрофон.

- Сказать в микрофон любые слова, чтобы проверить работоспособность устройства.

При необходимости можно внести изменения в стандартные настройки микрофона, включив подавление шума и другие параметры. Количество опций в данном случае определяется возможностями установленной звуковой карты.
Программы для голосового ввода
Сторонние программы упрощают перевод фраз, сказанных человеком, в написанный текст.
Dictate для MS Office
Dictate – это функция, встроенная в пакет MS Office. Чтобы воспользоваться данным инструментом, нужно:
- Запустить Word и сочетанием клавиш «Win» и «H» активировать функцию.
- Зайти в «Параметры» программы и включить функцию.
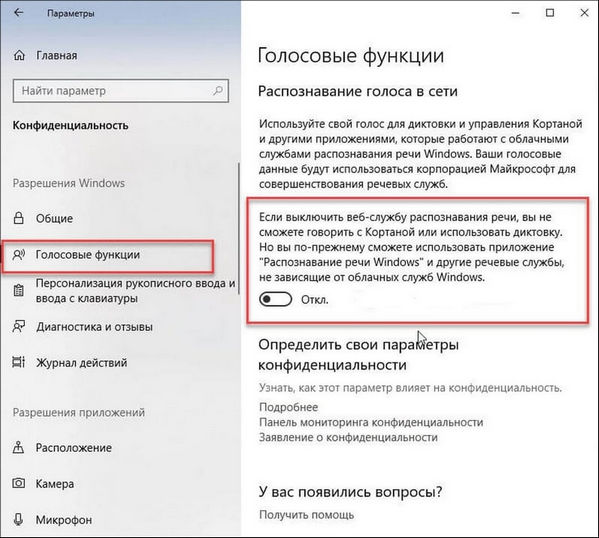
Данная утилита плохо воспринимает русскую речь. Поэтому Dictate используется для перевода небольших фрагментов текста. Также рекомендуется произносить фразы медленно, постоянно делая паузы.
MSpeech
Эта программа отличается простым интерфейсом и поддерживает 50 языков, включая русский. Для перевода речи в текст с помощью MSpeech нужно:
- Включить программу и в настройках установить основной и дополнительный языки распознавания.

- Выбрать (при необходимости) горячие клавиши для быстрого запуска отдельных функций.
- Выбрать перечень программ, в которые будет передаваться текст.

Для работы с MSpeech необходим постоянный доступ в интернет.
Speechpad

Чтобы узнать возможность Speechpad, утилиту можно интегрировать в браузер. Для этого нужно установить соответствующее расширение. После инсталляции необходимо в настройках Speechpad выбрать основной язык, на котором будет зачитываться текст.

Эта платная программа отличается от предыдущих расширенным функционалом. В частности, Voco автоматически расставляет знаки препинания согласно правилам русского языка. Также программа проверяет орфографию, используя встроенные словари.

Веб-сервисы и приложения
Такие сервисы удобны тем, что позволяют переводить голос в напечатанный текст без установки программ на компьютер. При работе с каждым приложением необходимо давать разрешение на использование встроенного (подключенного) микрофона.
Google Docs
Google Docs – это онлайн-редактор, который по функциональности не уступает MS Word. Для начитывания текста с помощью этого сервиса нужно:
- Открыть Google Docs под собственным аккаунтом.


- Открыть меню «Инструменты» и выбрать опцию перевода голоса в текст.
- Задать основной язык.

После завершения манипуляций на экране появится значок микрофона, нажав на который можно активировать данную функцию.
Speechpad
Этот сервис работает только с браузером Google Chrome. Чтобы перевести голос в текст, нужно перейти на официальный сайт Speechpad и на главной странице найти окно редактора. Далее достаточно нажать на «Включить запись». После этого можно наговаривать нужный текст.
Speechpad отличается расширенным функционалом. Сервис удобен тем, что при помощи голоса пользователи могут расставлять знаки препинания и переносить курсор на новую строчку.

VoiceNote
Этот сервис также работает только с браузером Google Chrome. Чтобы запустить VoiceNote, нужно:
- Открыть окно с текстовым редактором.
- Нажать на значок в виде земного шара и установить язык для диктовки.
- Нажать на значок микрофона.
Как и в случае со Speechpad, VoiceNote расставляет знаки препинания с помощью соответствующих голосовых команд.

TalkTyper
Этот онлайн-редактор не уступает Google Docs. TalkTyper поддерживает 37 языков, включая русский. Но, как и предыдущие сервисы, данный работает только с Google Chrome.
Принцип ввода текста в TalkTyper не отличается от ранее приведенных. Для начала работы необходимо задать основной язык, на котором планирует говорить пользователь. После этого необходимо нажать на значок микрофона и начать диктовку. Постановка знаков препинания и перенос строк также доступны с помощью голосовых команд.
Результат диктовки остается во встроенном редакторе. Этот текст можно скопировать и перенести в другие программы.

Voice Notepad
Этот сервис, работающий только с Google Chrome, поддерживает 120 языков. Но по набору функций Voice Notepad сопоставим с другими подобными приложениями.
Данный сервис поддерживает расстановку знаков препинания и перенос строки за счет голосовых команд. Готовый текст необходимо скопировать в другую программу.
Причина, почему такие сервисы работают только с Chrome, обусловлена особенностью используемой лицензии. Последняя распространяется на технологию распознавания речи, которую разработала компания Google.

Этот бесплатный онлайн-сервис поддерживает более 60 языков. Для пользователей смартфонов Android разработчики создали отдельное приложение Speechertexter. Программа и онлайн-сервис поддерживают следующие функции:
- счетчик слов, которые распознал алгоритм;
- редактирование текста (выделение, выравнивание, смена шрифта и другое);
- списки;
- ночной режим.
В приложении Speechertexter предусматривается несколько голосовых команд (вынесены в отдельную вкладку «Custom»), при помощи которых редактор автоматически расставляет знаки препинания. Пользователи могут расширить этот список, внеся соответствующие изменения в настройки. Готовый текст сохраняется в виде файла с расширением .txt или .docs.
Если вас интересует, как помочь обездвиженному человеку управлять компьютером для общения с внешним миром – вам сюда. Если вам интересно, какое отношение к этому имеют мел-частотные кепстральные коэффициенты и нейронные сети – вам тоже сюда.
Часть I. Программа для управления компьютером при помощи голоса
Ко мне обратился человек с просьбой написать программу, которая позволила бы управлять компьютерной мышью при помощи голоса. Тогда я и представить себе не мог, что, практически полностью парализованный человек, который даже не может сам повернуть голову, а может лишь разговаривать, способен развить бурную деятельность, помогая себе и другим жить активной жизнью, получать новые знания и навыки, работать и зарабатывать, общаться с другими людьми по всему свету, участвовать в конкурсе социальных проектов.
Позволю себе привести здесь пару ссылок на сайты, автором и/или идейным вдохновителем которых является этот человек – Александр Макарчук из города Борисов, Беларусь:
Это одному мне режет глаз?
Программа была сделана в 2005-2009 годах и хорошо работала на Windows XP. В более свежих версиях Windows программа может зависнуть, что неприемлемо для человека, который не может встать со стула и её перезапустить. Поэтому программу нужно было переделать.
Исходных текстов нет, есть только отдельные публикации, приоткрывающие технологии, на которых она основана (MFCC, MLP – читайте об этом во второй части).
По образу и подобию была написана новая программа (месяца за три).
Собственно, посмотреть, как она работает, можно здесь:
Никаких особенных действий для установки программы выполнять не надо, просто щёлкаете на ней, да запускаете. Единственное, в некоторых случаях требуется, чтобы она была запущена от имени администратора (например, при работе с виртуальной клавиатурой “Comfort Keys Pro”):

Пожалуй, стоит упомянуть здесь и о других вещах, которые я ранее делал для того, чтобы можно было управлять компьютером без рук.
Если у вас есть возможность поворачивать голову, то хорошей альтернативой eViacam может послужить гироскоп, крепящийся к голове. Вы получите быстрое и точное позиционирование курсора и независимость от освещения.
Если вы можете двигать только зрачками глаз, то можно использовать трекер направления взгляда и программу к нему (могут быть сложности, если вы носите очки).
Часть II. Как это устроено?
Из опубликованных материалов о программе «Vocal Joystick» было известно, что работает она следующим образом:
- Нарезка звукового потока на кадры по 25 миллисекунд с перехлёстом по 10 миллисекунд
- Получение 13 кепстральных коэффициентов (MFCC) для каждого кадра
- Проверка того, что произносится один из 6 запомненных звуков (4 гласных и 2 согласных) при помощи многослойного персептрона (MLP)
- Воплощение найденных звуков в движение/щелчки мыши
Последняя задача просто реализуется при помощи функции SendInput.
Наибольший же интерес, мне кажется, представляют вторая и третья задачи. Итак.
Задача №2. Получение 13 кепстральных коэффициентов
Если кто не в теме – основная проблема узнавания звуков компьютером заключается в следующем: трудно сравнить два звука, так как две непохожие по очертанию звуковые волны могут звучать похоже с точки зрения человеческого восприятия.
И среди тех, кто занимается распознаванием речи, идёт поиск «философского камня» — набора признаков, которые бы однозначно классифицировали звуковую волну.
Из тех признаков, что доступны широкой публике и описаны в учебниках, наибольшее распространение получили так называемые мел-частотные кепстральные коэффициенты (MFCC).
Но человек устроен так, что он склонен использовать то, что ему лучше знакомо. И тем, кто занимался речевыми сигналами, пришло в голову использовать уже готовое компактное представление сигнала в виде MFCC. Оказалось, что, в общем, работает. (Один мой знакомый, специалист по вентиляционным системам, когда я его спросил, как бы сделать дачную беседку, предложил использовать вентиляционные короба. Просто потому, что их он знал лучше других строительных материалов).
Являются ли MFCC хорошим классификатором для звуков? Я бы не сказал. Один и тот же звук, произнесённый мною в разные микрофоны, попадает в разные области пространства MFCC-коэффициентов, а идеальный классификатор нарисовал бы их рядом. Поэтому, в частности, при смене микрофона вы должны заново обучать программу.
Это всего лишь одна из проекций 13-мерного пространства MFCC в 3-мерное, но и на ней видно, что я имею в виду – красные, фиолетовые и синие точки получены от разных микрофонов: (Plantronix, встроенный массив микрофонов, Jabra), но звук произносился один.
Однако, поскольку ничего лучшего я предложить не могу, также воспользуюсь стандартной методикой – вычислением MFCC-коэффициентов.
Чтобы не ошибиться в реализации, в первых версиях программы в качестве основы был использован код из хорошо известной программы CMU Sphinx, точнее, её реализации на языке C, именующейся pocketsphinx, разработанной в Университете Карнеги-Меллона (мир с ними обоими! (с) Хоттабыч).
Исходные коды pocketsphinx открыты, да вот незадача – если вы их используете, то должны в своей программе (как в исходниках, так и в исполняемом модуле) прописать текст, содержащий, в том числе, следующее:
Мне это показалось неприемлемым, и пришлось код переписать. Это сказалось на быстродействии программы (в лучшую сторону, кстати, хотя «читабельность» кода несколько пострадала). Во многом благодаря использованию библиотек “Intel Performance Primitives”, но и сам кое-что оптимизировал, вроде MEL-фильтра. Тем не менее, проверка на тестовых данных показала, что получаемые MFCC-коэффициенты полностью аналогичны тем, что получаются при помощи, например, утилиты sphinx_fe.
В программах sphinxbase вычисление MFCC-коэффициентов производится следующими шагами:
| Шаг | Функция sphinxbase | Суть операции |
|---|---|---|
| 1 | fe_pre_emphasis | Из текущего отсчёта вычитается большая часть предыдущего отсчета (например, 0.97 от его значения). Примитивный фильтр, отбрасывающий нижние частоты. |
| 2 | fe_hamming_window | Окно Хемминга – вносит затухание в начале и конце кадра |
| 3 | fe_fft_real | Быстрое преобразование Фурье |
| 4 | fe_spec2magnitude | Из обычного спектра получаем спектр мощности, теряя фазу |
| 5 | fe_mel_spec | Группируем частоты спектра [например, 256 штук] в 40 кучек, используя MEL-шкалу и весовые коэффициенты |
| 6 | fe_mel_cep | Берём логарифм и применяем DCT2-преобразование к 40 значениям из предыдущего шага. Оставляем первые 13 значений результата. Есть несколько вариантов DCT2 (HTK, legacy, классический), отличающихся константой, на которую мы делим полученные коэффициенты, и особой константой для нулевого коэффициента. Можно выбрать любой вариант, сути это не изменит. |
В эти шаги ещё вклиниваются функции, которые позволяют отделить сигнал от шума и от тишины, типа fe_track_snr, fe_vad_hangover, но нам они не нужны, и отвлекаться на них не будем.
Были выполнены следующие замены для шагов по получению MFCC-коэффициентов:
| Шаг | Функция sphinxbase | Переделка |
|---|---|---|
| 1 | fe_pre_emphasis | cas_pre_emphasis (через frame[i] -= frame[i — 1] * pre_emphasis_alpha;) |
| 2 | fe_hamming_window | for(i=0;i |
| 3 | fe_fft_real | ippsDFTFwd_RToCCS_32f |
| 4 | fe_spec2magnitude | for(i=0;i buf_ipp[i]=buf_ipp[i*2]*buf_ipp[i*2]+buf_ipp[i*2+1]*buf_ipp[i*2+1]; |
| 5 | fe_mel_spec | cas_mel_spec (через предрасчитанную таблицу) |
| 6 | fe_mel_cep | CS_mel_cep (через логарифм + ippsDCTFwd_32f_I) |
Что же дальше? У нас есть вектор 13-мерного пространства. Как определить, к какому звуку он относится?
Задача №3. Проверка того, что произносится один из 6 запомненных звуков
В программе-оригинале «Vocal Joystick» для классификации использовался многослойный персептрон (MLP) – нейронная сеть без новомодных наворотов.
Давайте посмотрим, насколько оправдано применение нейронной сети здесь.
Вспомним, что делают нейроны в искусственных нейронных сетях.
Если у нейрона N входов, то нейрон делит N-мерное пространство пополам. Рубит гиперплоскостью наотмашь. При этом в одной половине пространства он срабатывает (выдаёт положительный ответ), а в другой – не срабатывает.
Давайте посмотрим на [практически] самый простой вариант – нейрон с двумя входами. Он, естественно, будет делить пополам двумерное пространство.
Пусть на вход подаются значения X1 и X2, которые нейрон умножает на весовые коэффициенты W1 и W2, и добавляет свободный член C.

Итого, на выходе нейрона (обозначим его за Y) получаем:
(опустим пока тонкости про сигмоидальные функции)
Считаем, что нейрон срабатывает, когда Y>0. Прямая, заданная уравнением 0=X1*W1+X2*W2+C как раз и делит пространство на часть, где Y>0, и часть, где Y
Проиллюстрируем сказанное конкретными числами.
Пусть W1=1, W2=1, C=-5;

Теперь посмотрим, как нам организовать нейронную сеть, которая бы срабатывала на некоторой области пространства, условно говоря – пятне, и не срабатывала во всех остальных местах.
Из рисунка видно, что для того, чтобы очертить область в двумерном пространстве, нам потребуется по меньшей мере 3 прямых, то есть 3 связанных с ними нейрона.

Эти три нейрона мы объединим вместе при помощи ещё одного слоя, получив многослойную нейронную сеть (MLP).


А если нам нужно, чтобы нейронная сеть срабатывала в двух областях пространства, то потребуется ещё минимум три нейрона (4,5,6 на рисунках):

И тут уж без третьего слоя не обойтись:
А третий слой – это уже почти Deep Learning…

Теперь обратимся за помощью к ещё одному примеру. Пусть наша нейронная сеть должна выдавать положительный ответ на красных точках, и отрицательный – на синих точках.

Если бы меня попросили отрезать прямыми красное от синего, то я бы сделал это как-то так:

Но нейронная сеть априори не знает, сколько прямых (нейронов) ей понадобится. Этот параметр надо задать перед обучением сети. И делает это человек на основе… интуиции или проб и ошибок.
Если мы выберем слишком мало нейронов в первом слое (три, например), то можем получить вот такую нарезку, которая будет давать много ошибок (ошибочная область заштрихована):

Но даже если число нейронов достаточно, в результате тренировки сеть может «не сойтись», то есть достигнуть некоторого стабильного состояния, далёкого от оптимального, когда процент ошибок будет высок. Как вот здесь, верхняя перекладина улеглась на два горба и никуда с них не уйдёт. А под ней большая область, порождающая ошибки:

Снова, возможность таких случаев зависит от начальных условий обучения и последовательности обучения, то есть от случайных факторов:
— Что ты думаешь, доедет то колесо, если б случилось, в Москву или не доедет?
— А ты как думаешь, сойдётся ента нейронная сеть или не сойдётся?
Есть ещё один неприятный момент, связанный с нейронными сетями. Их «забывчивость».
Если начать скармливать сети только синие точки, и перестать скармливать красные, то она может спокойно отхватить себе кусок красной области, переместив туда свои границы:

Если у нейронных сетей столько недостатков, и человек может провести границы гораздо эффективнее нейронной сети, зачем же их тогда вообще использовать?
А есть одна маленькая, но очень существенная деталь.
Я очень хорошо могу отделить красное сердечко от синего фона отрезками прямых в двумерном пространстве.
Я неплохо смогу отделить плоскостями статую Венеры от окружающего её трёхмерного пространства.
Но в четырёхмерном пространстве я не смогу ничего, извините. А в 13-мерном — тем более.
А вот для нейронной сети размерность пространства препятствием не является. Я посмеивался над ней в пространствах малой размерности, но стоило выйти за пределы обыденного, как она меня легко уделала.
Тем не менее вопрос пока открыт – насколько оправдано применение нейронной сети в данной конкретной задаче, учитывая перечисленные выше недостатки нейронных сетей.
Забудем на секунду, что наши MFCC-коэффициенты находятся в 13-мерном пространстве, и представим, что они двумерные, то есть точки на плоскости. Как в этом случае можно было бы отделить один звук от другого?
Пусть MFCC-точки звука 1 имеют среднеквадратическое отклонение R1, что [грубо] означает, что точки, не слишком далеко отклоняющиеся от среднего, наиболее характерные точки, находятся внутри круга с радиусом R1. Точно так же точки, которым мы доверяем у звука 2 находятся внутри круга с радиусом R2.

Внимание, вопрос: где провести прямую, которая лучше всего отделяла бы звук 1 от звука 2?
Напрашивается ответ: посередине между границами кругов. Возражения есть? Возражений нет.
Исправление: В программе эта граница делит отрезок, соединяющий центры кругов в соотношении R1:R2, так правильнее.

Далее, представим, что звука три. В этом случае проведём границы между каждой парой звуков.

И, наконец, не забудем, что где-то в пространстве есть точка, которая является представлением полной тишины в MFCC-пространстве. Нет, это не 13 нулей, как могло бы показаться. Это одна точка, у которой не может быть среднеквадратического отклонения. И прямые, которыми мы отрежем её от наших трёх звуков, можно провести прямо по границам окружностей:

На рисунке ниже каждому звуку соответствует кусок пространства своего цвета, и мы можем всегда сказать, к какому звуку относится та или иная точка пространства (или не относится ни к какому):

Ну, хорошо, а теперь вспомним, что пространство 13-мерное, и то, что было хорошо рисовать на бумаге, теперь оказывается тем, что не укладывается в человеческом мозгу.
Так, да не так. К счастью, в пространстве любой размерности остаются такие понятия, как точка, прямая, [гипер]плоскость, [гипер]сфера.
Мы повторяем все те же действия и в 13-мерном пространстве: находим дисперсию, определяем радиусы [гипер]сфер, соединяем их центры прямой, рубим её [гипер]плоскостью в точке, равно отдалённой от границ [гипер]сфер.
Никакая нейронная сеть не сможет более правильно отделить один звук от другого.
Здесь, правда, следует сделать оговорку. Всё это справедливо, если информация о звуке – это облако точек, отклоняющихся от среднего одинаково во всех направлениях, то есть хорошо вписывающееся в гиперсферу. Если бы это облако было фигурой сложной формы, например, 13-мерной изогнутой сосиской, то все приведённые выше рассуждения были бы не верны. И возможно, при правильном обучении, нейронная сеть смогла бы показать здесь свои сильные стороны.
Но я бы не рисковал. А применил бы, например, наборы нормальных распределений (GMM), (что, кстати и сделано в CMU Sphinx). Всегда приятнее, когда ты понимаешь, какой конкретно алгоритм привёл к получению результата. А не как в нейронной сети: Оракул, на основе своего многочасового варения бульона из данных для тренировки, повелевает вам принять решение, что запрашиваемый звук – это звук №3. (Меня особенно напрягает, когда нейронной сети пытаются доверить управление автомобилем. Как потом в нестандартной ситуации понять, из-за чего машина повернула влево, а не вправо? Всемогущий Нейрон повелел?).
Но наборы нормальных распределений – это уже отдельная большая тема, которая выходит за рамки этой статьи.
Надеюсь, что статья была полезной, и/или заставила ваши мозговые извилины поскрипеть.
Для людей с ограниченными возможностями, а также просто для сибаритов, разработчики ОС создали голосовое управление компьютером. Оно позволяет пользователю вводить информацию при помощи голоса. После проговаривания определенных слов устройство начинает распознавание речи - преобразование звукового сигнала в цифровую информацию. После того, как введенная информация будет корректно распознана – программа переходит к заданному алгоритму действия – выполняет функцию, которая прикреплена к той или иной команде.

Все достаточно просто. Не всегда речь распознается корректно, поэтому для решения сложных задач по управлению операционной системой программа голосового управления компьютером интенсивно не используется. Она применяется для выполнения основных функций: открытия и закрытия файлов, локального и сетевого поиска и пр.
История развития голосового управления
- Первая система распознавания голоса Audrey была создана в 50-х годах ХХ века. Она расшифровывала лишь цифры, проговоренные одним голосом.
- В 1962 г была создана первая система распознавания слов. Она расшифровывала 15 англоязычных слов.
- С развитием компьютеров в 1990 г была разработана программа Dragon Dictate. Она распознавала до 100 слов в минуту, но отличалась высокой ценой.
- В начале 2000-х годов в iPhone появилось приложение для распознавания речи Google Voice Search. В 2010 году была добавлена система поиска в Android.
- Siri была включена в программное обеспечение Phone 4S в начале октября 2011 г;
- в 2014 г была представлена Cortana - голосовая помощница для Windows.

Возможности Cortana и голосового ввода на сегодняшний день
«Кортана» - это виртуальный помощник в операционной системе Windows. Сервис помогает пользователю в планировании дел, напоминает о них.
При определенном запросе сервис поможет собрать конкретную информацию, создать четкую структуру и преподнести ее пользователю в максимально возможно обработанном виде.
Интересно, что сразу при включении виртуальный помощник собирает всю информацию о введенных запросах, личных данных, пытаясь максимально адаптироваться под каждого отдельного пользователя.
Голосовое управление компьютером Windows 7 посредством использования виртуального помощника невозможно – он интегрирован только в десятую версию. Но, как ни жаль, разработчики не удосужились выпустить русскоязычную версию.
Главную роль отыгрывает поиск, который в 10-ке можно открыть через «Пуск». Эта функция определяет практически любые запросы. Если вхождение не распознано – можно ввести соответствующую команду во всплывающее окно и программа голосового управления компьютером считает текстовую информацию.
Неприятный момент – сбор всех данных, введенных через клавиатуру, и их отправка в «Майкрософт».
Сторонние программы
Typle
После выполнения установки переходим к следующему шагу – создаем учетную запись. Здесь необходимо придумать ключевую фразу, после чего прозвучит уведомление об активации.
Дальше нужно будет придумать и создать голосовые команды, независимо от их предназначения. Команда «собака» может запускать приложение или выполнять совсем другое действие.
Просто нужно создать голосовую команду и закрепить ее за определенным действием. Подойдет только для выполнения базовых операций – открытия файлов, папок и пр. Функционал ограничен.
Speaker
Здесь функционал более широкий, нежели в Typle.
Голосовое управление компьютером Windows 10 предоставляет пользователю возможность открывать и закрывать файлы, делать снимки состояния экрана, выключать ПК.
Распознавание речи происходит довольно долго, свыше 3-4 секунд. Это обусловлено тем, что сначала речь преобразуется в текст, а команды распознаются компьютером уже с текстовой информации.
Laitis

Это бесплатная программа, которая позволяет как управлять ПК, так и диктовать текст. После установки необходимо зарегистрироваться и дальше можно пользоваться в свое удовольствие.
Интересна функция автозамены при наборе текста. Вы можете сказать «Кавычки» и в тексте появится соответствующий символ.
Возможности управления голосом через Яндекс.строку
Появилась возможность выполнять голосовое управление компьютером при помощи приложения Яндекс.строка.

Посредством использования этого приложения можно выполнять локальный или сетевой поиск информации и файлов, перезагрузить или выключить компьютер. Присутствует функция открытия программ и сайтов.
Чтобы воспользоваться программой, необходимо сначала скачать и установить ее.
Но при установке стоит убрать галочки напротив пунктов, где производитель софта предлагает установить браузер, поменять его настройки. В противном случае установка займет больше время и в браузере изменится конфигурация.
В конечном итоге строка размещается около кнопки «Пуск». Скажите «Слушай Яндекс» и откроется окно.
Проговорите запрос.
После паузы в браузере откроется строка поиска. Занимательно управлять поиском таким образом.
В целом, голосовое управление компьютером пока не развито, так как рисуется нам в воображении. Но и те функции, что имеются на сегодняшний день, уже впечатляют и существенно помогают перейти на новый уровень пользования ПК.
Читайте также: