Признак в 1с это
Во-первых, в подавляющем большинстве книг, интернет-ресурсов и уроков по Data Science нюансы, изъяны разных типов нормализации данных и их причины либо не рассматриваются вообще, либо упоминаются лишь мельком и без раскрытия сути.
Во-вторых, имеет место «слепое» использование, например, стандартизации для наборов с большим количеством признаков — “чтобы для всех одинаково”. Особенно у новичков (сам был таким же). На первый взгляд ничего страшного. Но при детальном рассмотрении может выясниться, что какие-то признаки были неосознанно поставлены в привилегированное положение и стали влиять на результат значительно сильнее, чем должны.
И, в-третьих, мне всегда хотелось получить универсальный метод учитывающий проблемные места.
Повторение — мать учения
Нормализация — это преобразование данных к неким безразмерным единицам. Иногда — в рамках заданного диапазона, например, [0..1] или [-1..1]. Иногда — с какими-то заданным свойством, как, например, стандартным отклонением равным 1.
Ключевая цель нормализации — приведение различных данных в самых разных единицах измерения и диапазонах значений к единому виду, который позволит сравнивать их между собой или использовать для расчёта схожести объектов. На практике это необходимо, например, для кластеризации и в некоторых алгоритмах машинного обучения.
Аналитически любая нормализация сводится к формуле
где — текущее значение,
— величина смещения значений,
— величина интервала, который будет преобразован к “единице”
По сути всё сводится к тому, что исходный набор значений сперва смещается, а потом масштабируется.
Минимакс (MinMax). Цель — преобразовать исходный набор в диапазон [0..1]. Для него:
= , минимальное значение исходных данных.
= — , т.е. за “единичный” интервал берется исходный диапазон значений.
Стандартизация. Цель — преобразовать исходный набор в новый со средним значением равным 0 и стандартным отклонением равным 1.
= , среднее значение исходных данных.
— равен стандартному отклонению исходного набора.
Для других методов всё аналогично, но со своими особенностями.
В большинстве методов кластеризации или, например, классификации методом ближайших соседей необходимо рассчитывать меру “близости” между различными объектами. Чаще всего в этой роли выступают различные вариации евклидового расстояния.
Представим, что у Вас есть какой-то набор данных с несколькими признаками. Признаки отличаются и по типу распределения, и по диапазону. Чтобы можно было с ними работать, сравнивать, их нужно нормализовать. Причём так, чтобы ни у какого из них не было преимуществ перед другими. По крайней мере, по умолчанию — любые такие предпочтения Вы должны задавать сами и осознанно. Не должно быть ситуации, когда алгоритм втайне от Вас сделал, например, цвет глаз менее важным, чем размер ушей*
* нужно сделать небольшое примечание — здесь речь идёт не о важности признака для, например, результата классификации (это определяется на основе самих данных при обучении модели), а о том, чтобы до начала обучения все признаки были равны по своему возможному влиянию.
Итого, главное условие правильной нормализации — все признаки должны быть равны в возможностях своего влияния.
Шаг 1 — определяем смещение
Чаще всего данные центрируют — т.е. определяют, значение, которое станет новым 0 и “сдвигают” данные относительно него.
Что лучше взять за центр? Некоего «типичного представителя» Ваших данных. Так при использовании стандартизации используется среднее арифметическое значение.
Здесь проявляется проблема № 1 — различные типы распределений не позволяют применять к ним методы, созданные для нормального распределения.
Если Вы спросите любого специалиста по статистике, какое значение лучше всего показывает “типичного представителя” совокупности, то он скажет, что это — медиана, а не среднее арифметическое. Последнее хорошо работает только в случае нормального распределения и совпадает с медианой (алгоритм стандартизации вообще оптимален именно для нормального распределения). А у Вас распределения разных признаков могут (и скорее всего будут) кардинально разные.
Вот, например, различия между медианой и средним арифметическим значением для экспоненциального распределения.

А вот так выглядят эти различия при добавлении выброса:

В отличии от среднего значения медиана практически не чувствительна к выбросам и асимметрии распределения. Поэтому её оптимально использовать как “нулевое” значение при центрировании.
В случае, когда нужно не центрировать, а вписать в заданный диапазон, смещением является минимальное значение данных. К этому вернёмся чуть позже.
Шаг 2 — масштабируем
Мы определили нужные величины смещения для всех признаков. Теперь нужно сделать признаки сравнимыми между собой.
Степень возможного влияния признаков определяется величиной их диапазонов после масштабирования. Если оба признака распределены в одинаковых интервалах, например, [-1..1], то и влиять они могут одинаково. Если же изначально один из признаков лежит в диапазоне [-1..1], а второй — в [-1..100], то очевидно, что изменения второго могут оказывать существенно большее влияние. А значит он будет в привилегированном положении по сравнению с первым.
Стандартное отклонение
Вернёмся к примеру стандартизации. В её случае новый диапазон определяется величиной стандартного отклонения. Чем оно меньше, тем диапазон станет “шире”.
Посмотрим на гипотетические распределения различных признаков с одинаковыми начальными диапазонами (так будет нагляднее):

Для второго признака (бимодальное распределение) стандартное отклонение будет больше, чем у первого.

А это значит, что у второго признака новый диапазон после масштабирования (стандартизации) будет “уже”, и его влияние будет меньше по сравнению с первым.

Итог — стандартное отклонение не удовлетворяет начальным требованиям по одинаковому влиянию признаков (величине интервала). Даже не говоря о том, что и наличие выбросов может исказить “истинную” величину стандартного отклонения.
Межквартильный интервал
Другим часто используемым кандидатом является разница между 75-м и 25-м процентилями данных — межквартильный интервал. Т.е. интервал, в котором находятся “центральные” 50% данных набора. Эта величина уже устойчива к выбросам и не зависит от “нормальности” распределения наличия/отсутствия асимметрии.
Но и у неё есть свой серьезный недостаток — если у распределения признака есть значимый “хвост”, то после нормализации с использованием межквартильного интервала он добавит “значимости” этому признаку в сравнении с остальными.
Проблема № 2 — большие “хвосты” распределений признаков.
Пример — два признака с нормальным и экспоненциальным распределениями. Интервалы значений одинаковы

После нормализации с использованием межквартильного интервала (для наглядности оба интервала смещены к минимальным значениям равным нулю).

В итоге интервал у признака с экспоненциальным распределением из-за большого “хвоста” стал больше. А, следовательно, и сам признак стал “влиятельнее”.
Размах значений
Очевидным решением проблемы межквартильного интервала выглядит просто взять размах значений признака. Т.е. разницу между максимальным и минимальным значениями. В этом случае все новые диапазоны будут одинаковыми — равными 1.
И здесь максимально проявляется, наверное, самая частая проблема в подготовке данных, проблема № 3 — выбросы. Присутствие одного или нескольких аномальных (существенно удалённых) значений за пределами диапазона основных элементов набора может ощутимо повлиять на его среднее арифметическое значение и фиктивно увеличить его размах.
Это, пожалуй, самый наглядный пример из всех. К уже использовавшемуся выше набору из 2-х признаков добавим немного выбросов для одного признака

После нормализации по размаху

Наличие выброса, который вдвое увеличил размах признака, привело к такому же уменьшению значимого интервала его значений после нормализации. Следовательно влияние этого признака уменьшилось.
Работаем с выбросами
Решением проблемы влияния выбросов при использовании размаха является его замена на интервал, в котором будут располагаться “не-выбросы”. И дальше — масштабировать по этому интервалу.
Искать и удалять выбросы вручную — неблагодарное дело, особенно когда количество признаков ощутимо велико. А иногда выбросы и вовсе нельзя удалять, поскольку это приведёт к потере информации об исследуемых объектах. Вдруг, это не ошибка в данных, а некое аномальное явление, которое нужно зафиксировать на будущее, а не отбрасывать без изучения? Такая ситуация может возникнуть при кластеризации.
Пожалуй, самым массово применяемым методом автоматического определения выбросов является межквартильный метод. Его суть заключается в том, что выбросами “назначаются” данные, которые более чем в 1,5 межквартильных диапазонах (IQR) ниже первого квартиля или выше третьего квартиля.*
* — в некоторых случаях (очень большие выборки и др.) вместо 1,5 используют значение 3 — для определения только экстремальных выбросов.
Схематично метод изображен на рисунке снизу.

Вроде бы все отлично — наконец-то есть инструмент, и можно приступать к работе.
Но и здесь есть своя ложка дёгтя. В случае наличия длинных хвостов (как, например, при экспоненциальном распределении) слишком много данных попадают в такие “выбросы” — иногда достигая значений более 7%. Избирательное использование других коэффициентов (3 * IQR) опять приводит к необходимости ручного вмешательства — не для каждого признака есть такая необходимость. Их потребуется по отдельности изучать и подбирать коэффициенты. Т.е. универсальный инструмент опять не получается.
Ещё одной существенной проблемой является то, что этот метод симметричный. Полученный “интервал доверия” (1,5 * IQR) одинаков как для малых, так и для больших значений признака. Если распределение не симметричное, то многие аномалии-выбросы с “короткой” стороны просто будут скрыты этим интервалом.

Скорректированный интервал
Красивое решение этих проблем предложили Миа Хаберт и Елена Вандервирен (Mia Hubert and Ellen Vandervieren) в 2007 г. в статье “An Adjusted Boxplot for Skewed Distributions”.
Их идея заключается в вычислении границ “интервал доверия” с учетом асимметрии распределения, но чтобы для симметричного случая он был равен всё тому же 1,5 * IQR.
Для определения некоего “коэффициента асимметрии” они использовали функцию medcouple (MC), которая определяется так:


Поиск подходящей формулы для определения границ “интервала доверия” производился с целью сделать долю, приходящуюся на выбросы, не превышающей такую же, как у нормального распределения и 1,5 * IQR — приблизительно 0,7%
В конечном итоге они получили такой результат:


Более подробно про этот метод и его эффективность лучше прочитать в самой статье. Найти ее по названию не составляет труда.
Универсальный инструмент
Теперь, объединяя все найденные плюсы и учитывая проблемы, мы получаем оптимальное решение:
- Центрирование, если оно требуется, производить по медиане.
- Масштабировать набор данных по величине скорректированного интервала.
- (Опционально) — если центрирование не требуется, то смещать масштабированные данные так, чтобы границы скорректированного интервала приходились на [0..1]
Назовем его методом… скорректированного интервала — по названию статьи Mia Hubert и Ellen Vandervieren
Теперь сравним результаты обычных методов с новым. Для примера возьмем уже использовавшиеся выше три распределения с добавлением выбросов.

Сравнивать новый инструмент будем с методами стандартизации, робастной нормализации (межквартильный интервал) и минимакса (MinMax — с помощью размаха).
Ситуация № 1 — данные необходимо центрировать. Это используется в кластеризации и многих методах машинного обучения. Особенно, когда необходимо определять меру “близости” объектов.

Робастная нормализация (по межквартильному интервалу):


Преимущество использования метода скорректированного интервала в том, что каждый из признаков равен по своему возможному влиянию — величина интервала, за пределами которого находятся выбросы, одинакова у каждого из них.
Ситуация № 2 — данные необходимо вписать в заданный интервал. Обычно это [0..1]. Это используется, например, при подготовке данных для входов нейронной сети.
MinMax (по размаху):


В этом случае метод скорректированного интервала вписал в нужный диапазон только значения без выбросов. Значения-выбросы, выходящие за границы этого диапазона, в зависимости от постановки задачи можно удалить или принудительно приравнять ближайшей границе нужного диапазона — т.е. 0 или 1.
То, что только “нормальные” данные попадают в единичный диапазон [0..1], а выбросы не удаляются, но пропорционально выносятся за его пределы — это крайне полезное свойство, которое сильно поможет при кластеризации объектов со смешанными признаками, как числовыми, так и категорийными. Подробно об этом я напишу в другой статье.
Напоследок, для возможности пощупать руками этот метод, Вы можете попробовать демонстрационный класс AdjustedScaler из моей библиотеки AdjDataTools.
Он не оптимизирован под работу с очень большим объемом данных и работает только с pandas DataFrame, но для пробы, экспериментов или даже заготовки под что-то более серьезное вполне подойдет. Пробуйте.
с ошибками расчета среднего заработка;
сменой данных карт для выплаты пособий;
прочими причинами, которые могут возникнуть в процессе оформления реестра прямых выплат ФСС.
Реестр прямых выплат ФСС включает в себя документы «Больничный лист» и «Сведения для реестра прямых выплат».
Предположим, у нас есть сотрудник, реестр прямых выплат ФСС по больничному листу уже сдан и принят в ФСС.
Позднее мы узнаем, что средний заработок в переданном нами реестре рассчитан неправильно. Скажем, был выбран не тот период для расчета или не введена справка о доходах за прошлые периоды.
После нажатия на данную строку, создастся документ-исправление текущего больничного листа. После этого первичный больничный лист будет не доступен для редактирования.
После внесения корректировок в больничный лист, нам нужно сформировать новый реестр прямых выплат ФСС. Признак корректировки данных в реестре присваивается в документе «Сведения для реестра прямых выплат».
Найти документ «Сведения для реестра прямых выплат» мы можем через меню Отчетность, справки - Передача в ФСС сведений о пособиях.
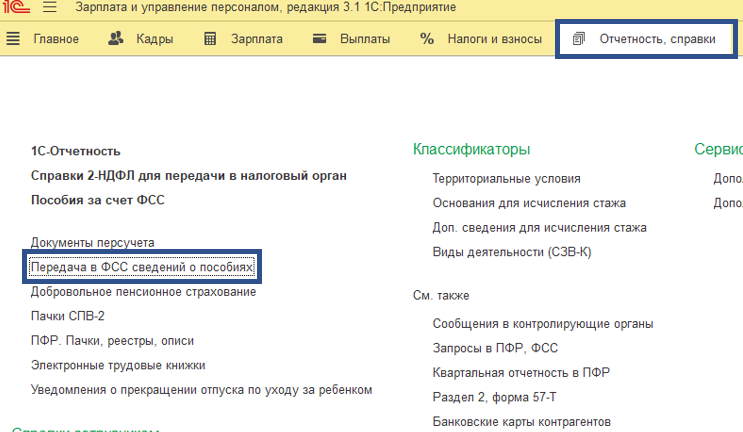
В дубликате заявления заходим во вкладку расчет пособия. Ставим отметку Перерасчет по причине и выбираем причину перерасчета из выпадающего списка. Указываем исправленный средний заработок сотрудника для расчета пособия ФСС.
Создаем новый реестр прямых выплат ФСС и заполняем по сотруднику исправленным больничным листом и документом «Сведения для реестра прямых выплат» с признаком Перерасчет по причине. Реестр отправляем. Он будет принят ФСС как корректирующий.
Так как планируется переход на выплату пособий по беременности и родам исключительно на карты платежной системы МИР, данный способ актуален и при смене способа выплаты пособия. В случае смены платежной карты, так же создаем дублирующий документ «Сведения для реестра прямых выплат». Указываем перерасчет по причине иное и выбираем новые платежные реквизиты для выплаты пособия.
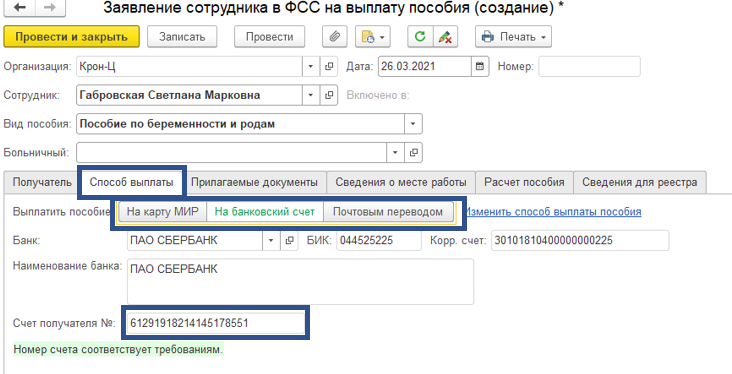
Заполняем новый реестр прямых выплат ФСС с документом сведения для реестра прямых выплат с признаком Перерасчет по причине и новыми платежными реквизитами и отправляем в ФСС.
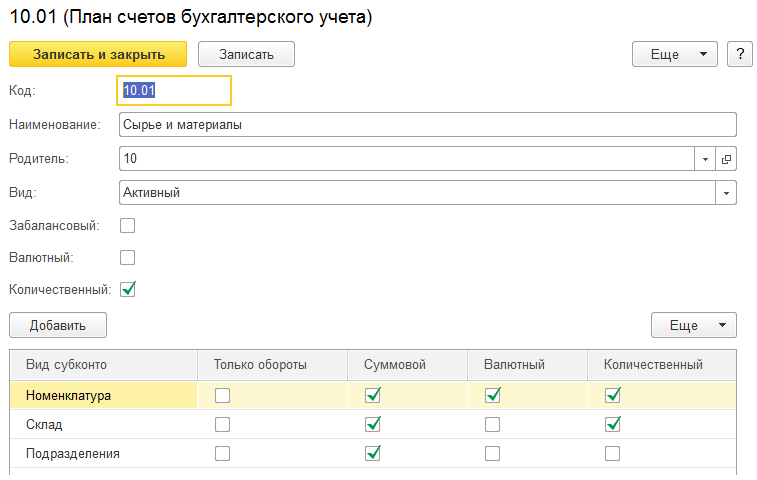
Вот мы и добрались до регистров бухгалтерии платформы 1С:Предприятие 8.x. Ранее мы говорили о регистрах накопления и регистрах сведений, подробно рассматривали их устройство и принцип работы с ними со стороны платформы. В этом плане, регистры бухгалтерии интереснее и сложнее, т.к. имеют большее количество настроек, а сама специфика бухгалтерского учета усложняет их структуру хранения в базе данных, а также SQL-запросы платформы для получения этих данных.
В этой серии статей мы рассмотрим общую информацию о регистре бухгалтерии, его структуре хранения в базе данных в зависимости от настроек, построение SQL-запросов платформы при использовании различных виртуальных таблиц, влияние плана счетов на настройки регистра, а также другие особенности, связанные с итогами и прочими моментами.
В первой части, которая сейчас открыта перед Вами, мы рассмотрим внутреннее устройство регистра бухгалтерии при часто используемой структуре.
Назначение
Регистры бухгалтерии очень похожи на регистры накопления: они также могут иметь произвольный набор измерений, в разрезе которых накапливаются показатели, а также дополнительные реквизиты, в которых хранится произвольная информация о записях.
Любой регистр бухгалтерии обязательно должен быть связан с одним из планов счетов, который своими настройками влияет на хранение итогов (об этом подробнее мы поговорим в следующих статьях). На структуру хранения записей регистра бухгалтерии в основном влияют как сама структура регистра (измерения, ресурсы, реквизиты) и его настройки (включена ли корреспонденция, разделение итогов и др.), так и настройки используемых счетов (признаки учета счетов и субконто, вид счета и т.д.).
Регистры бухгалтерии - это
Опишем каждую из настроек:
- Настройки регистра
- План счетов - указание на объект метаданных "План счетов", который используется регистром бухгалтерии.
- Корреспонденция - флаг, указывающий используется ли корреспонденция счетов при создании записей в регистре. Регистр бухгалтерии может работать в двух режимах:
- С корреспонденцией - в этом случае используется механизм двойной записи, когда каждая запись регистра содержит поля "СчетДт" (счет дебета) и "СчетКт" (счет кредита).
- Без корреспонденции - в этом случае механизм двойной записи использоваться не будет. В каждой записи будет использоваться только одно измерение для указания счета - "Счет"
- Организация - ссылка на справочник "Организации". Не используется признак учета, т.е. измерение будет использоваться для всех записей. Установлена настройка "Балансовый", которая определяет поддержку двойной записи для этого измерения и, соответственно, схождение баланса для него. Другими словами регистр бухгалтерии в нашем случае сконфигурирован таким образом, чтобы баланс можно было сводить в разрезе организации.
- Валюта - ссылка на справочник "Валюты". Измерение ссылается на признак учета "Валютный". Это означает, что измерение будет использоваться только в том случае, если у счета установлен признак учета "Валютный".
- Сумма - балансовый показатель, используемый для всех счетов. Признак учета субконто "Суммовой" указывает ведется ли учет по этому ресурсу для указанных в счете субконто. Подробнее об этом еще поговорим и рассмотрим работы этой настройки на примерах.
- ВалютнаяСумма - не балансовый ресурс, используемый только для счетов с признаком учета "Валютный", а также используемый только для тех субконто, у которых признак учета субконто "Валютный" установлен в Истина.
- Количество - также, как и ресурс "ВалютнаяСумма", не является балансовым. Используется только для счетов с признаком учета "Количественный", а также только для тех субконто, у которых в Истина установлен признак учета субконто "Количественный".
- Содержание - реквизит с типом "Строка" (макс. длина 150) для хранения справочной информации записей регистра.
Как мы видим, на заполнение полей регистра бухгалтерии в основном влияют счета учета. В зависимости от признаков учета счета и субконто определяется какие измерения и ресурсы используются для записи, как должны хранится итоги по счетам и субконто, а также прочие настройки.
![]()
Для новичков все эти настройки кажутся запутанными. Мы не будем подробно рассказывать о назначении каждой из настроек регистра и плана счетов. О каждой настройке с прикладной точки зрения Вы можете узнать на ИТС и здесь. Также в последующих статьях мы подробнее остановимся на каждой настройке и проанализируем ее влияние на структуру таблиц регистра и работы платформы 1С:Предприятие с ними.
Таблицы регистра
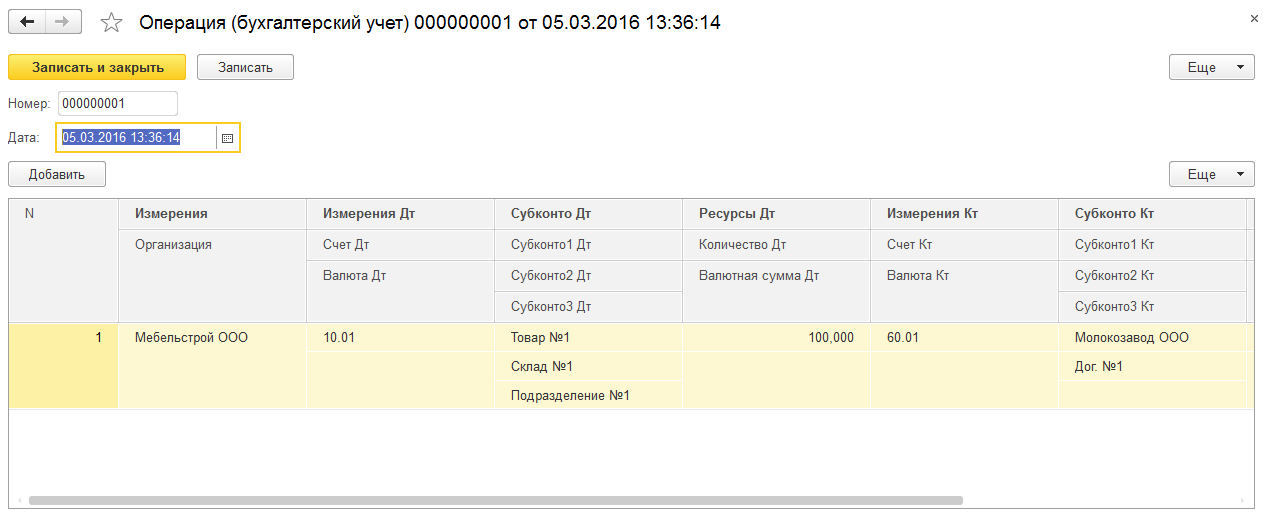
В нашем примере используется регистр бухгалтерии с поддержкой корреспонденции и с максимальным количеством субконто - 3. Для измерений используются как признаки учета счетов, так и признаки учета субконто. В итоге платформа создала следующую структуру таблиц:
1. Основная таблица (_AccRg[внутренний номер]) - основная таблица регистра, в которой хранятся данные аналогично той структуре регистра, которая задана в конфигураторе (измерения + ресурсы + реквизиты). В нашем примере она выглядит следующим образом:
![]()
Заметим, что значения доп. аналитики, а именно субконто, не хранятся в основной таблице регистра. Для их хранения используется отдельная таблица, которая содержит все поля регистра, включая стандартные (период, регистратор, номер записи). Также присутствует поле "Активность" типа булево, которое влияет на то, будет ли запись влиять на таблицы итогов (если Истина, то запись учитывается в таблицах итогов).
2. Значения субконто (_AccRgED[внутренний номер]) - таблица создается, если для плана счетов регистра бухгалтерии используются субконто. Она нужна для хранения значений субконто записей основной таблицы регистра. В нашем примере таблица имеет следующую структуру:
![]()
Поле "Вид движения" может содержать два значения: 0 - дебет, 1 - кредит. Вид субконто в большинстве случаев содержит ссылку на элемент плана вида характеристик, задающий виды субконто. Значение субконто хранится по правилам, аналогично тому типу данных, который нужно сохранить. В нашем случае это ссылочный тип (подробнее о значениях каждого поля в этом случае Вы можете прочитать в одной из предыдущих статей).
3. Таблицы итогов. К таблицам итогов регистра накопления относят:
![]()
Из названия уже понятно, что в таблице хранятся итоги остатков по счетам, по периодам и в разрезе измерений регистра бухгалтерии. Для каждого ресурса хранится оборот по дебету и кредиту, а также общий оборот. При использовании разделения итогов для регистра используется служебное поле "Разделитель", чтобы повысить параллельность работы пользователей. Принцип работы разделения итогов аналогично его использованию в регистрах накопления, поэтому подробней останавливаться не будем.
![]()
Таблица оборотов хранит обороты между счетами в разрезе балансовых измерений регистра. Как и в таблице остатков, хранятся обороты по дебету и кредиту для ресурсов регистра и имеются служебные поля для механизма разделения итогов.
Таблицы итогов субконто (или итоги по счетам с субконто) (_AccRgAT[количество субконто][внутренний номер])
Таблицы итогов субконто хранят итоги по субконто для счетов в разрезе измерений регистра бухгалтерии. В таблицах хранятся обороты по ресурсам регистра (по дебету и кредиту). Таблицы также содержат поля для механизма разделения итогов.
Главной особенностью хранения итогов по субконто является использование нескольких таблиц для этих целей. В нашем примере у плана счетов, который используется регистром бухгалтерии, максимальное количество субконто - 3. В этом случае платформа создает три таблицы итогов, где хранит итоги по 1 субконто, по 2 субконто и по 3 субконто.
![]()
В последующих статьях мы подробней проанализируем работу платформы с итогами и на примере проанализируем изменение данных в таблицах. Также будет рассмотрен вопрос влияния количества субконто на производительность бухгалтерских регистров.
4. Настройки хранения итогов (_AccRgOpt[внутренний номер]) - таблицы с настройками итогов регистра бухгалтерии. Имеют следующую структуру:
В таблице настроек хранения итогов сохраняются данные, по которым платформа определяет как именно будут рассчитываться итоги для данного регистра, использовать ли текущие итоги и другие настройки. Подробнее мы о них еще поговорим.
Примечание: аналогичная таблица есть и у регистров накопления. Когда мы рассматривали эту тему ранее (еще на платформе 8.2), таких настроек как макс. и мин. хранимый период итогов не было. Это нововведение платформы 8.3. На примере регистра бухгалтерии мы проанализируем работу этих настроек, который будет актуальным и для регистров накопления.
Таким образом, мы рассмотрели общую информацию о структуре таблиц регистра бухгалтерии. В некотором плане его внутреннее устройство схоже с регистром накопления, за исключением таблиц дополнительной аналитики - субконто, а также таблиц итогов для них.
Вместо заключения
Платформа 1С внутри содержит множество интересных механизмов, решений и много другого. Речь идет не только о стороне базы данных, но и особенностях работы сервера приложений, клиентской части, взаимодействия с веб-сервером и так далее. В этой и предыдущих статьях мы лишь немного приоткрыли внутреннюю структуру базы данных
Если есть интерес к подобным темам или другие вопросы – пишите в комментариях. Вы сами задаете темы будущих публикаций!
Сегодня мы коснулись общего назначение и структуры таблиц регистра бухгалтерии. В будущих статьях поднимем такие темы как:
2-НДФЛ с признаком 2 — это отчетный документ специальной формы. Для его оформления требуется особая причина: из выплаченного физлицу дохода не смогли удержать налог. Разъясним, как указанный в справке признак связан с отчетным сроком, и оценим масштабы материальных потерь работодателя, представившего справки с разными признаками без учета особого отчетного срока.
Выбираем признак для 2-НДФЛ
Форма 2-НДФЛ с 2019 года обновилась, но по-прежнему проставление в ней признака — обязательное условие.
Для отражения признака предусмотрено отдельное поле в заглавной части 2-НДФЛ.
Правила для выбора признака в справке 2-НДФЛ в 2019 году показано на рисунке:
![Какой признак — 1 или 2 — нужно ставить в справке 2-НДФЛ]()
У организации в отчетном году может не возникнуть обстоятельств, при которых НДФЛ невозможно удержать из выданных доходов. Тогда в отчетном комплекте справок 2-НДФЛ с признаком 2 не будет.
Готовьтесь к расходам, если справка с признаком 2 запоздала
- единожды в год;
- в разные отчетные даты: с признаком 1 — не позднее 1 апреля, а с признаком 2 — до 1 марта.
Пример
По итогам завершившегося года бухгалтер ПАО «ТехноСтройКом» 27 марта представила в ИФНС полный комплект справок 2-НДФЛ. Всего было оформлено и передано контролерам 1360 справок. Из них 347 справок 2-НДФЛ с признаком 2.
ПАО «ТехноСтройКом» был начислен штраф 69 400 руб. (347 × 200 руб.) — в такую сумму налоговое законодательство оценивает факт опоздания с 347 документами, имеющими статус обязательной налоговой отчетности. Остальные справки (с признаком 1) попали в инспекцию вовремя, поэтому в определении штрафной суммы не участвуют.
200 руб. — размер материального наказания за каждую опоздавшую справку (п. 1 ст. 126 НК РФ). От 300 до 500 руб. придется заплатить в казну руководству (ст. 15.6 КоАП РФ).
Что поможет отчитаться по 2-НДФЛ вовремя и без ошибок
Чтобы организации не нести материальные потери из-за штрафов, следует грамотно организовать учетный процесс по всем физлицам, которым в течение отчетного года выплачиваются доходы.
Важно также ориентироваться в ситуациях, когда налог действительно невозможно удержать. К примеру, физлицу выдан подарок, а денежных выплат ему не производили.
Если все возможностиу налогового агента имелись, но удержание и перечисление налога не произошли из-за плохо организованного учетного процесса или недостаточной исполнительской дисциплины бухгалтерии, избежать штрафа не получится.
Не забывайте и о том, что подача справки 2-НДФЛ с признаком 2 требует от работодателя выполнения еще одной обязанности: нужно сообщить о невозможности удержания налога не только в налоговый орган, но и самому физлицу — получателю дохода (п. 5 ст. 226 НК РФ).
Признак 1 проставьте в тех справках 2-НДФЛ, которые содержат сведения о выплаченных физлицам доходах и перечисленном в бюджет налоге. Если же налог с выданных сумм удержать не удалось, справку 2-НДФЛ нужно представить с признаком 2.
📝 Клиенту срочно потребовалась копия информационной базы. Файловая « Зарплата и управление персоналом ». Кажется, все просто — скопируй каталог, переименуй, добавь новую базу в список и работай.
Важный момент в этом — установка признака « Это копия ИБ », когда 1С блокирует работу со всеми внешними ресурсами (синхронизация данных, отправка почты и т. п.), выполняемую по расписанию.
Где предлагается выбор — «ИБ перемещена» или «Это копия ИБ». В нашем случае этого не случилось.
📌 Как определяется факт перемещения базы
- В первую очередь, по изменению типа расположения ИБ : с файлового на клиент-серверный и наоборот. Если тип сменился, то база считается перемещенной.
- Далее, если тип не изменился, сравнивается строка соединения ИБ . Если строка соединения не изменилась, то проверка прекращается.
- Если строка изменилась, следующая проверка зависит от типа расположения базы :
- В файловой ИБ факт перемещения определяется по служебному файлу DoNotCopy.txt , автоматически создаваемому программой. Внутри файла находится идентификатор ИБ.
Если файл отсутствует или идентификатор в файле отличается от идентификатора в базе, то информационная база считается перемещенной.
- В клиент-серверном варианте — по изменению имени ИБ или имени компьютера (сервера).
📌 Как принудительно поставить признак копии
- Закройте 1С.
- Откройте каталог с информационной базой, удалите или переименуйте файл DoNotCopy.txt.
- Откройте 1С — при повторном входе программа предложит на выбор: разрешить или заблокировать работу с внешними ресурсами .
- Выберите «Это копия информационной базы».
✅ Появится слово [КОПИЯ] в заголовке программы — значит, вы все сделали правильно.
База готова для тестирования, обучения или просто, чтобы проверить данные за предыдущий период.
⚡ Подписывайтесь на канал или задавайте вопрос на сайте — постараемся помочь всеми техническими силами. Безопасной и производительной работы в Windows и 1С.
Читайте также: