
Nvidia process and module monitoring driver что это
Здравствуйте, установила Nvidia Geforce Experience, и появилось много разных служб. скажите что они означают и какие можно отключить? чтобы зря не грузили процессор..
- Nvidia Display Driver Service
- Nvidia LocalSystem Container
- Nvidia NetworkService Container
- Nvidia Stereoscoic 3D Driver Srvice
- Nvidia Wireless Controller Service
Спасибо за ответы. Остановила и перевела в ручной режим службы Display Driver Service, NetworkService Container и Stereoscoic 3D Driver Srvice. Не могу понять что такое LocalSystem Container? и Wireless Controller Service? подскажите, пожалуйста, кто знает.
да. наверно так и надо было сделать. но уже установила Nvidia Geforce Experience..можно же остановить службы некоторые, которыми точно пользоваться не буду. Если подскажите какие, буду благодарна.)
Homo habilis Оракул (65660) я думаю, Nvidia Stereoscoic 3D Driver Srvice и Nvidia Wireless Controller Service можно остановить. про остальные не могу точно сказать, там возможно есть зависимости у служб.
Процессор может и не загружают, а вот "Container" постоянно пишет логи. Лишний раз насилует жесткий диск (или SSD, у кого что).
Stereoscoic 3D Driver Srvice - остановила и перевела в ручной режим. Не подскажите про эти две службы, что они означают - LocalSystem Container? и Wireless Controller Service?
Доцент Искусственный Интеллект (140058) wireless - судя по названию, служба беспроводной сети (вай фая).
Я установил Nvidia Geforce Experience, посмотрел что это и сколько его и как он работает и снес его к черту.
подскажите пожалуйста, если знаете что за службы, какие точно можно отключить? как поняла, не всеми вообще пользоваться то надо. Не хочется загружать процессор не совсем нужным.
ж-ж-ж Оракул (57041) Зачем тебе эта программа на постоянной основе? Скачала её,проверила обновления на драйвера, обновила, если нужно, и потом сноси её!
В К Мыслитель, не подскажите все таки что же это за службы nvidia LocalSystem Container? и Wireless Controller Service? ничего не могу про них найти.
Nvidia Display Driver Service - Следит за драйвером видеокарты, делает отчёты - можно отключить.
NVidia Experience - оптимизирует быстродействие, нужна для открытия панели управления Nvidia - можно отключить.
NVIDIA Streamer Service - Обеспечивает работу сервиса по стримингу игрового процесса - Можно отключить
NVIDIA Update Service Daemon - сканирует сайт NVidia на предмет новых версий драйверов - Можно отключить.
NVIDIA Network Service - устанавливается с компонентом GeForce Experience. При отключении этой службы появляется ошибка о невозможности подключения к серверу NVIDIA и небольшая задержка в запуске самого приложения. Также отключаются функции авто обновления, уведомления об обновлениях и обновления оптимальных настроек для игр.
NVIDIA GeForce Experience Backend - программа, оптимизации установленных в системе игр и подбора для них из своей базы оптимальных настроек, делает настолько часто, что перезагружает ЦП, удаляется вручную \NVIDIA Corporation\Update Core, с последующей чисткой реестра… к примеру Reg Organizer
NVIDIA Wireless Controller Service - если вы не используете функцию Shadow Play, то можно отключить и NvStreamKms
NVIDIA Stereoscoic 3D Driver Srvice - это программное обеспечение очков с активными LCD вставками и встроенной электроникой для работы в паре с LCD-экранами с частотой развертки 120Гц
P.S. Зачем Вам нужны эти шаманские танцы ?))
Скачиваем официальный видеодрайвер с сайта производителя и разархивируем его. Оставляем только папку Display.Driver.
Перед установкой нового драйвера воспользуйтесь Display Driver Uninstaller бесплатной утилитой предназначенной для полного удаления из системы остатков драйверов видеокарт от AMD, NVIDIA, Intel.
В диспетчере устройств ручками устанавливаем видеоадаптер, выбрав поиск и установка драйверов вручную, указав ранее созданную папу.
P.S.S В BIOSе опция SLI Mode отвечает за использование режима SLI. Режим SLI можно…. если нужно…. включить вопреки желанию драйверов.. через модификацию системного реестра… но, это уже другая история))
Здарвсчвуйте г. Корчагин! Вы знаете я бы хотела ещё у Вас узнать как мне закрыть порт 65000 TCP devil 1.03 stacheldracht? Оттуда лезут трояны и вроде действуют на видеокарту. Компьютер бесконца самопроизвольно перезапускается, выдаёт ошибку.
Сергей Корчагин Знаток (483) Здравствуйте, NVIDIA Streamer Service прослушивает порт, это не вирус ) можете не беспокоиться, просто отключите эту служб, (пытается вести потоковое вещание игр, что может перегружать вашу видеокарту, при обновлении драйверов процесс отключения службы нужно повторить)
Понаписал ты мути, прям как знающий
NVIDIA Network Service - устанавливается и без GeForce Experience
Что вот это за чушь?: "NVidia Experience - оптимизирует быстродействие, нужна для открытия панели управления"
Вам полностью разжую), для информации, не сокращённый вариант:
GeForce Experience - это приложение-компаньон для вашей видеокарты. Приложение своевременно обновляет драйверы вашей видеокарты, автоматически оптимизирует игровые настройки вашего ПК и предлагает самый простой способ записи вашего геймплея или его потоковой передачи в Twitch.
ОТКРЫВАЕТ ПАНЕЛЬ УПРАВЛЕНИЯ, или Вы можете запустить чем то другим?)))
Панель управления: является частью пользовательского интерфейса. Она позволяет выполнять основные действия по настройке системы, такие, как добавление и настройка устройств, установка и деинсталляция программ, включение специальных возможностей.
З. Ы. иногда лучше молчать чем говорить
Юрий Знаток (275) у меня блин нвидиа карты с 2000 года и ты мне собрался что то там разжёвывать? откуда ты скопировал данный текст? я повторю - прошил у 1070й биос, поставил дрова, только видеодрайвера и физикс, ничего больше из комплекта установки. и появилась ошибка NVIDIA Network Service после загрузки винды. бл*** не надо мне объяснять что такое GeForce Experience.он не установлен, но NVIDIA Network Service присутствует. драйвер чистил DDU в безопасном режиме винды
Достаточно отключить автоповторы игровых моментов, внутреигровом меню, настроить как надо производительность видеокарты через панель управления, под свою систему и прочие примочки от Expirience. И все встанет на свои места. А трогать службы производителя и насильно их вырубать, не есть правильно.

Process Monitor (сокращенно Procmon.exe или Procmon64.exe) - очень популярная утилита, которая имеет огромное количество различных функций и очень помогает в процессе использования ОС Windows, но при ее запуске, может появляться вот такая вот ошибка:
Unable to load process monitor device driver
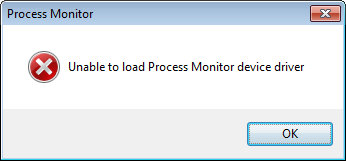
Если в этот момент посмотреть в просмотр событий, то увидим вот такую вот ошибку:
Средство проверки целостности кода обнаружило, что хэш образа файла недопустим. Файл может быть поврежден после его несанкционированного изменения, или недопустимый хэш может указывать на потенциальную ошибку дискового устройства.
Имя файла: \Device\HarddiskVolume2\Windows\System32\drivers\PROCMON24.SYS
Code integrity determined that the image hash of a file is not valid. The file could be corrupt due to unauthorized modification or the invalid hash could indicate a potential disk device error
Filename: \Device\HarddiskVolume2\Windows\System32\drivers\PROCMON24.SYS
Исправляем ошибку
После того, как мы скачали Windows6.1-KB3033929-x64.msu, необходимо его запустить и дождаться окончания установки.
После окончания установки не забываем нажать кнопку "Перезагрузить сейчас"
Чтобы ошибка перестала выскакивать ОБЯЗАТЕЛЬНО необходимо перезагрузить компьютер после установки данного обновления.
После перезагрузки Process Monitor должен запускаться нормально, а ошибка исчезнуть.

Возможно ни для кого не секрет, что последние пакеты драйверов от nVidia содержат комплекс телеметрии.
Понимая, что разработчик желает получать данные об использовании своего продукта, оптимизировать и улучшать программную составляющую, многие не желают быть бесплатными тестерами, более того — без спроса.
На картинке выше приводится способ отключения телеметрии «из коробки», надо отдать должное — производитель засунул эту опцию в довольно неожиданное место, и надо ещё больше отдать должное — работает она не до конца.
Ниже будет рассмотрено, как полностью отключить телеметрию в драйверах nVidia последних версий.
- Display.Driver — Основной драйвер видеоадаптера
- Display.NView — nView — управление рабочим пространством на одном или нескольких мониторах
- Display.Optimus — NVIDIA Optimus — оптимизирует графическую производительность ноутбука в зависимости от нагрузки
- HDAudio — Драйвера «NVIDIA High Definition Audio»
- NVI2 — Тело установщика
- PhysX — PhysX
Несмотря на то, что после проведения подобных чисток драйвера устанавливаются, мне такой способ не нравится, поскольку никто не гарантирует, что не нарушаются связи компонентов, а тем более — всё будет работать со следующей версией инсталлятора.
На Гитхабе существует даже проект некого Нейта Шоффнера для решения задачи, который отключает службу телеметрии и задачи, но при этом не отключает эту настройку в самом системном приложении, что в моём случае несколько раз выдавало ошибку при связи со службой. Неудивительно, что автор предлагает держать своё творение в фоне и регулярной проверкой на включение телеметрии — мы глушим мешающие процессы и добавляем для этого ещё один (epic!).
Мной предлагается простейшее решение проблемы в виде командного скрипта, который отключает службы, задачи, а также настройку в системном приложении nVidia.
schtasks /Change /TN "NvTmMon_" /Disable
schtasks /Change /TN "NvTmRep_" /Disable
schtasks /Change /TN "NvTmRepOnLogon_" /Disable
sc config NvTelemetryContainer start= disabled
reg add "HKCU\Software\NVIDIA Corporation\NVControlPanel2\Client" /v "OptInOrOutPreference" /t REG_DWORD /d 0 /f
Приведённый скрипт следует запускать от имени администратора один раз сразу после установки новой версии пакета драйверов nVidia. Скрипт ничего не удаляет из системы, все изменения обратимы, но с другой стороны не меняются без участия пользователя.
Для тех, кто не любит скрипты, но любит exe-файлы — исполняемый файл, выполняющий ту же задачу. Ссылка удалена по причине, что некоторые пользователи усмотрели в ней вирус. Предлагаю самостоятельно собрать exe из скрипта, это несложно.
Перед тем, как начать основное повествование, я бы хотел уточнить несколько моментов. Статья направлена в первую очередь на обладателей ноутбуков с технологией Nvidia Optimus, желающих установить себе GNU/Linux(далее Linux). Материал направлен на то, чтобы вышеуказанная ЦА ознакомилась с возможными решениями вопроса и на то, чтобы облегчить и ускорить ею его решение. Кроме того, статья не в последнюю очередь является мотивирующей, и направлена на понимание людьми одной простой истины: в Linux, как и в жизни, всегда найдётся обходной путь, и если Вы сдадитесь, лучше(в большинстве случаев) не станет.
— Латинская поговорка
Предисловие
До поры до времени я был обычным линуксоидом. Тестил разные дистрибутивы, потихоньку узнавал новое. Просто потому, что мне было интересно. Как правило, «знания» ограничивались Ubuntu и её форками, а также Fedora и ещё парой «user-friendly» дистрибутивов. Но, как гласит ещё одна латинская поговорка, omnia fluunt, omnia mutantur, то есть все течёт, всё меняется, и понятно, что так не могло продолжаться вечно.
Всё хорошо начиналось
Следует отметить, что у меня было не очень большое раздолье для экспериментов: относительно слабый ПК, который еле-еле тянул GNOME 3, и медленный интернет, который сильно усложнял общую ситуацию. Но тогда большего для мальчика 12 лет и не нужно было. В конце концов мне надоело экспериментировать, я установил Windows 10 и на несколько лет забыл о Linux.
Время шло, и где-то через 2 года я понял, что пришло время обновить мой замшелый кусок железа ПК, и начал копить деньги. Что-то выручил с продаж своих вещей, что-то дарили, более половины суммы накинули родители, пришлось даже принести в жертву продать свой Xbox(!) потешить своё ЧСВ повысить skill'ы в Linux. На этот раз решил попытаться установить Arch. Слышал, что у него очень хорошая документация. И начал.
Прелесть документации Arch
Установка прошла быстро и относительно безболезненно. Опять же, благодаря документации. После установки системы и DE в лице KDE Plasma, я попробовал подключить ноутбук к своему внешнему монитору, поскольку у монитора диагональ 24' а у дисплея ноутбука только 15,6'. Ничего не произошло, на монитор сигнал не поступил. Как всегда, я начал гуглить. И после 30 мин поисков я обнаружил, что проблема связана с технологией Nvidia Optimus.
Немного о Nvidia Optimus
Nvidia — хорошая компания. За свою 25-летнюю историю они реализовали немало относительно хороших решений. Nvidia Optimus — одно из таких. Сабж представляет собой гибридную технологию для обеспечения корректной работы двух видеокарт(как правило, мощной графики Nvidia и встроенной Intel) на ноутбуках. Если она работает в Windows правильно настроена, она помогает сберечь электроэнергию и ресурсы ноутбука. Всё это отлично, но что натолкнуло меня на написание сего опуса, так это то, что эта распрекраснейшая технология в Linux по словам разработчиков работает только частично, а по моим её настройка требует много, много нервов, времени и сил.
Прелесть документации Arch(продолжение)
После того, как я узнал об истинном корне проблемы, я поначалу обрадовался что определил «где собака зарыта»(HDMI-выход был только у карты Nvidia), и первым моим шагом было чтение официальной документации Arch. Суть её заключалась в том, чтобы при помощи редактирования xorg.conf и .xinitrc заставить X использовать только карту Nvidia. После выполнения указанных шагов и перезагрузки… появился черный экран. В документации говорилось, что в таком случае необходимо проверить, нет ли в .xinitrc амперсандов, а если их нет, использовать «Альтернативную конфигурацию», которая заставляла X использовать только карту Intel. Это меня не устроило, поскольку карта Intel уже использовалась по умолчанию и этот вариант мне не подходил. Также были варианты для различных DM. Они также не подошли, так как ни один из них по разным причинам не мог запустить X-сервер.
Описывать каждый из них отдельно было бы очень длинным и бессмысленным занятием.
Qui quaerit, reperit
Это выражение в переводе с латинского обозначает «Кто ищет, находит». Я не зря поместил его в начало, поскольку как по мне это выражение станет идеальной моралью для этой статьи.
Я был в отчаянии. Два дня я тщетно пытался найти решение, рыскал по зарубежным форумам(только по ним, поскольку на православном ЛОРе ответ был таков: Вы никак не запустите X через Nvidia. Это невозможно, смиритесь). Но всё-таки, пасмурным утром третьего дня поисков я наткнулся на тред(ссылка в подвале) на девелоперском форуме Nvidia, в котором было расписано, как Nvidia Optimus имплементируется в Arch на ноутбуках Dell. Я сразу же понял — я спасён! Выполнив шаги, я перезапустился и… черный экран. Безусловно, я расстроился, но тут я вспомнил: я же не прописал в .xinitrc строки для запуска DE. Прописав exec startkde, я снова перезапустился и всё заработало. X запустился через Nvidia. Долгих четыре дня ушло у меня на установку и настройку Arch, и всё же я это сделал!
Разбор полётов
Теперь давайте разберем инструкцию из вышеуказанного треда. Начнём:
Сперва необходимо включить поддержку KMS(Kernel Mode Setting, метод настройки разрешения непосредственно в ядре), добавив в параметры ядра(файл /etc/default/grub) в строку GRUB_CMDLINE_LINUX_DEFAULT= параметр
Затем создаём скрипт для DM(менеджера входа). Рассмотрим вариант с LightDM. Создаём скрипт /etc/lightdm/display_setup.sh со следующим содержанием:
Этим скриптом мы указываем поставщика и устанавливаем максимально возможное разрешение экрана.
Сделаем созданный скрипт исполняемым:
Заставим LightDM выполнять вышеуказанный скрипт при запуске. Сперва отредактируем /etc/lightdm/lightdm.conf:
Инструкцию для SDDM можете посмотреть в уже упомянутом мною треде, ссылки в подвале.
Теперь нам необходимо обновить микрокод ЦП(больше о микрокоде по ссылкам в подвале):
После обновления микрокода установим ворох пакетов от Nvidia:
Примечание: Некоторые из пакетов могут быть недоступны. В таком случае устанавливайте всё по отдельности. Пакеты, которые будут недоступны, пропускайте.
Включим демон nvidia.persistenced, отвечающий за персистентность(больше о ней читайте по ссылке в подвале) работы драйвера Nvidia:
Автоматически сконфигурируем GRUB:
Создадим загрузочный RAM-диск:
Если не вписали, впишем
После перезагрузки ноутбука логинимся под своей учетной записью и наслаждаемся миром Arch.
О Bumblebee и PRIME
Возможно, Вы заметили, что я ничего не сказал о «костылях», которые направлены на обеспечение корректной работы Nvidia Optimus в Linux: Bumblebee и PRIME.
Кроме того, завести карту Nvidia у меня вышло лишь с проприетарным драйвером, Nouveau не работал(поэтому статья и называется «Благословите Nouveau».
Что касается лично моего опыта работы с ними, то он мал и плачевен: оба костыля в упор не видели мою видеокарту Nvidia. Если Вам они интересны, в подвале вы найдете ссылки на материалы по ним.
Послесловие
Если вы прочли всю статью, то вы герой (ну, или модератор).
При написании статьи я старался разбавлять её для Вас относительно смешными шутками, чтобы как-то оправдать отсутствие картинок в ней. Надеюсь, что вы достигли дзена после прочтения.
Последние выходные я потратил на освоение программирования CUDA и SIMT. Это плодотворно проведённое время закончилось почти 700-кратным ускорением моего «рейтрейсера на визитке» [1] — с 101 секунд до 150 мс.
Такой приятный опыт стал хорошим предлогом для дальнейшего изучения темы и эволюции архитектуры Nvidia. Благодаря огромному объёму документации, опубликованному за долгие годы «зелёной» командой, мне удалось вернуться назад во времени и вкратце пройтись по удивительной эволюции её потоковых мультипроцессоров.
В этой статье мы рассмотрим:
Тупик
Вплоть до 2006 года архитектура GPU компании NVidia коррелировала с логическими этапами API рендеринга [2] . GeForce 7900 GTX, управлявшаяся кристаллом G71, состояла из трёх частей, занимавшихся обработкой вершин (8 блоков), генерацией фрагментов (24 блоков), и объединением фрагментов (16 блоков).
Кристалл G71. Обратите внимание на оптимизацию Z-Cull, отбрасывающую фрагмент, не прошедший бы Z-тест.
Эта корреляция заставила проектировщиков угадывать расположение «узких места» конвейера для правильной балансировки каждого из слоёв. С появлением в DirectX 10 ещё одного этапа — геометрического шейдера, инженеры Nvidia столкнулись со сложной задачей балансировки кристалла без знания того, насколько активно будет использоваться этот этап. Настало время для перемен.
Tesla
Nvidia решила проблему роста сложности при помощи «объединённой» архитектуры Tesla, выпущенной в 2006 году.
В кристалле G80 больше не было различий между слоями. Благодаря возможности выполнения вершинного, фрагментного и геометрического «ядра», потоковый мультипроцессор (Stream Multiprocessor, SM) заменил все существовавшие ранее блоки. Уравновешивание нагрузки выполнялось автоматически, благодаря замене выполняемого каждым SM «ядра» в зависимости от требований конвейера.
«Фактически, мы выбросили всю шейдерную архитектуру NV30/NV40 и с нуля создали новую, с новой общей архитектурой универсальных процессоров (SIMT), в которой также были введены новые методологии проектирования процессоров».
Больше не имеющие возможности выполнять инструкции SIMD «блоки шейдеров» превратились в «ядра», способные выполнять по одной целочисленной инструкции или по одной инструкции с float32 за такт. SM получает потоки в группах по 32 потока, называемых warp. В идеале все потоки одного warp выполняют одновременно одну и ту же инструкцию, только для разных данных (отсюда и название SIMT). Многопотоковый блок инструкций (Multi-threaded Instruction Unit, MT) занимается включением/отключением потоков в warp-е в случае, если их указатель инструкций (Instruction Pointer, IP) сходится/отклоняется.
Два блока SFU помогают выполнять сложные математические вычисления, например, обратный квадратный корень, sin, cos, exp и rcp. Эти блоки также способны выполнять по одной инструкции за такт, но поскольку их только два, скорость выполнения warp-а делится на четыре. Аппаратная поддержка float64 отсутствует, вычисления выполняются программно, что сильно влияет на скорость выполнения.
SM реализует свой максимальный потенциал, когда способен скрывать задержки памяти благодаря постоянному наличию диспетчеризируемых warp-ов, но также когда поток в warp-е не отклоняется (управляющая логика удерживает его на одном пути выполнения инструкций). Состояния потоков хранятся в 4-килобайтных файлах регистров (Register File, RF). Потоки, занимающие слишком большое пространство в стеке, снижают количество возможных потоков, которые могут выполняться одновременно, понижая при этом производительность.
Кристаллом-флагманом поколения Tesla был 90-нанометровый G80, представленный в GeForce 8800 GTX. Два SM объединены в кластер обработки текстур (Texture Processor Cluster, TPC) вместе с текстурным блоком (Texture Unit) и кешем Tex L1. Обещалось, что G80 с 8 TPC и 128 ядрами генерирует 345,6 гигафлопс [3] . Карта 8800 GTX была в своё время чрезвычайно популярна, она получила замечательные отзывы и полюбилась тем, кто мог себе её позволить. Она оказалась таким превосходным продуктом, что спустя тринадцать месяцев после выпуска оставалась одним из самых быстрых GPU на рынке.
G80, установленный в 8800 GTX. Render Output Units (ROP) занимаются выполнением сглаживания.
Вместе с Tesla компания Nvidia представила язык программирования C для Compute Unified Device Architecture (CUDA) — надмножество языка C99. Это понравилось энтузиастам GPGPU, приветствовавшим альтернативу обмана GPU при помощи текстур и шейдеров GLSL.
Хотя в этом разделе я в основном рассказываю о SM, это была только одна половина системы. В SM необходимо передавать инструкции и данные, хранящиеся в памяти GPU. Чтобы избежать простоев, GPU не пытаются минимизировать переходы в память при помощи больших кешей и прогнозирования, как это делают CPU. GPU пользуются задержкой, насыщая шину памяти для удовлетворения потребностей ввода-вывода тысяч потоков. Для этого кристалл (например, G80) реализует высокую пропускную способность памяти при помощи шести двусторонних шин памяти DRAM.
GPU пользуются задержками памяти, в то время как CPU скрывают их при помощи огромного кеша и логике прогнозирования.
Fermi
Tesla была рискованным ходом, оказавшимся очень успешным. Она была настолько успешной, что стала фундаментом для GPU компании NVidia на следующие два десятка лет.
«Хотя с тех пор мы, конечно же, внесли серьёзные архитектурные изменения (Fermi была серьёзным изменением архитектуры системы, а Maxwell стал ещё одним крупным изменением в проектировании процессоров), фундаментальная архитектура, представленная нами в G80, и сегодня осталась такой же [Pascal]».
В 2010 году Nvidia выпустила GF100, основанный на совершенно новой архитектуре Fermi. Внутренности её последнего чипа подробно описаны в технической документации Fermi [4] .
Модель выполнения по-прежнему основана на warp-ах из 32 потоков, диспетчеризируемых в SM. NVidia удалось удвоить/учетверить все показатели только благодаря 40-нанометровому техпроцессу. Благодаря двум массивам из 16 ядер CUDA, SM теперь мог одновременно диспетчеризировать два полу-warp-а (по 16 потоков). При том, что каждое ядро выполняло по одной инструкции за такт, SM по сути был способен исключать по одной инструкции warp за такт (в четыре раза больше, чем у SM архитектуры Tesla).
Количество SFU также увеличилось, однако не так сильно — мощность всего лишь удвоилась. Можно прийти к выводу, что инструкции такого типа использовались не очень активно.
Присутствует полуаппаратная поддержка float64, при которой комбинируются операции, выполняемые двумя ядрами CUDA. Благодаря 32-битном АЛУ (в Tesla оно было 24-битным) GF100 может выполнять целочисленное умножение за один такт, а из-за перехода от IEEE 754-1985 к IEEE 754-2008 имеет повышенную точность при работе с конвейером float32 при помощи Fused Multiply-Add (FMA) (более точного, чем используемое в Tesla MAD).
С точки зрения программирования, объединённая система памяти Fermi позволила дополнить CUDA C такими возможностями C++, как объект, виртуальные методы и исключения.
Благодаря тому, что текстурные блоки стали теперь SM, от концепции TPC отказались. Она была заменена кластерами Graphics Processor Clusters (GPC), имеющими по четыре SM. И последнее — SM теперь одарён Polymorph Engine, занимающимся получением вершин, преобразованием окна обзора и тесселяцией. Карта-флагман GeForce GTX 480 на основе GF100 рекламировалась, как содержащая 512 ядер и способная обеспечить 1 345 гигафлопс [5] .
GF100, установленный в GeForce GTX 480. Обратите внимание на шесть контроллеров памяти, обслуживающих GPC.
Kepler
В 2012 году Nvidia выпустила архитектуру Kepler, названную в честь астролога, наиболее известного открытием законов движения планет. Как обычно, взглянуть внутрь нам позволила техническая документация GK104 [6] .
В Kepler компания Nvidia значительно улучшила энергоэффективность кристалла, снизив тактовую частоту и объединив частоту ядер с частотой карты (ранее их частота различалась вдвое).
Такие изменения должны были привести к снижению производительности. Однако благодаря вдвое уменьшившемуся техпроцессу (28 нанометров) и замене аппаратного диспетчера на программный, Nvidia смогла не только разместить на чипе больше SM, но и улучшить их конструкцию.
Next Generation Streaming Multiprocessor (SMX) — это монстр, почти все показатели которого были удвоены или утроены.
Благодаря четырём диспетчерам warp-ов, способным на обработку целого warp-а за один такт (Fermi мог обрабатывать только половину warp-а), SMX теперь содержал 196 ядер. Каждый диспетчер имел двойную диспетчеризацию, позволявшую выполнять вторую инструкцию в warp-е, если она была независима от текущей исполняемой инструкции. Двойная диспетчеризация была не всегда возможна, потому что один столбец из 32 ядер был общим для двух операций диспетчеризации.
Такая схема усложнила логику диспетчеризации (к этому мы ещё вернёмся), но благодаря выполнению до шести инструкций warp-ов за такт SMX обеспечивал удвоенную производительность по сравнению с SM архитектуры Fermi.
Заявлялось, что флагманская NVIDIA GeForce GTX 680 с кристаллом GK104 и восемью SMX имеет 1536 ядер, достигающими 3 250 гигафлопс [7] . Элементы кристалла стали настолько запутанными, что мне пришлось убрать со схемы все подписи.
GK104, установленный в GeForce GTX 680.
Обратите внимание на полностью переделанные подсистемы памяти, работающие с захватывающей дух частотой 6 ГГц. Они позволили снизить количество контроллеров памяти с шести до четырёх.
Maxwell
В 2014 году Nvidia выпустила GPU десятого поколения под названием Maxwell. Как говорится в технической документации GM107 [8] , девизом первого поколения архитектуры стали «Максимальная энергоэффективность и чрезвычайная производительность на каждый потреблённый ватт». Карты позиционировались для «ограниченных в мощности сред, таких как ноутбуки и PC с малым форм-фактором (small form factor, SFF)».
Важнейшим решением стал отказ от структуры Kepler с количеством ядер CUDA в SM, не являющимся степенью двойки: некоторые ядра стали общими и вернулись в работе в режиме половины warp-ов. Впервые за всю историю архитектуры SMM имел меньше ядер, чем его предшественник: «всего» 128 ядер.
Согласование количества ядер и размера warp-ов улучшило сегментацию кристалла, что привело к экономии площади и энергии.
Один SMM 2014 года имел столько же ядер (128), сколько вся карта GTX 8800 в 2006 году.
Второе поколение Maxwell (описанное в технической документации GM200 [9] ) значительно повысило производительность, сохранив при этом энергоэффективность первого поколения.
Техпроцесс оставался на уровне 28 нанометров, поэтому инженеры Nvidia не могли для повышения производительности прибегнуть к простой миниатюризации. Однако уменьшение количества ядер SMM снизило их размер, благодаря чему на кристалле удалось разместить больше SMM. По сравнению с Kepler, второе поколение Maxwell удвоило количество SMM, при этом всего на 25% увеличив площадь кристалла.
В списке усовершенствований также можно найти упрощённую логику диспетчеризации, позволившую снизить количество избыточных повторных вычислений диспетчеризации и задержку вычислений, что обеспечило повышение оптимальности использования warp-ов. Также на 15% была увеличена частота памяти.
Изучение структурной схемы Maxwell GM200 уже начинает напрягать глаза. Но мы всё равно внимательно его исследуем. Флагманская карта NVIDIA GeForce GTX 980 Ti с кристаллом GM200 и 24 SMM обещала 3072 ядер и 6 060 гигафлопс [10] .
GM200, установленный в GeForce GTX 980 Ti.
Pascal
В 2016 году Nvidia представила Pascal. Техническая документация GP104 [11] оставляет ощущение дежавю, потому что Pascal SM выглядит точно так же, как Maxwell SMM. Отсутствие изменений SM не привело к стагнации производительности, потому что 16-нанометровый техпроцесс позволил разместить больше SM и снова удвоить количество гигафлопс.
Среди других серьёзных улучшений была система памяти, основанная на совершенно новой GDDR5X. 256-битный интерфейс памяти благодаря восьми контроллерам памяти обеспечивал скорости передачи в 10 гигафлопс, увеличив на 43% пропускную способность памяти и снизив время простоя warp-ов.
Флагман NVIDIA GeForce GTX 1080 Ti с кристаллом GP102 и 28 TSM обещал 3584 ядер и 11 340 гигафлопс [12] .
GP104, установленный в GeForce GTX 1080.
Turing
Выпуском в 2018 году Turing компания Nvidia произвела свой «крупнейший за десять лет архитектурный шаг вперёд» [13] . В «Turing SM» появились не только специализированные ядра Tensor с искусственным интеллектом, но и ядра для трассировки лучей (rautracing, RT). Такая фрагментированная структура напоминает мне многослойную архитектуру, существовавшую до Tesla, и это ещё раз доказывает, что история любит повторения.
Кроме новых ядер, в Turing появилось три важные особенности. Во-первых, ядро CUDA теперь стало суперскалярным, что позволяет параллельно выполнять инструкции с целыми числами и с числами с плавающей запятой. Если вы застали 1996 год, то это может напомнить вам об «инновационной» архитектуре Pentium компании Intel.
Во-вторых, новая подсистема памяти на GDDR6X, поддерживаемая 16 контроллерами, способна теперь обеспечивать 14 гигафлопс.
В-третьих, потоки теперь не имеют общих указателей инструкций (IP) в warp-е. Благодаря появившейся в Volta диспетчеризации Independent Thread Scheduling, каждый поток имеет собственный IP. В результате этого SM способны гибче настраивать диспетчеризацию потоков в warp-е без необходимости как можно более быстрого их схождения.
Флагманская карта NVIDIA GeForce GTX 2080 Ti с кристаллом TU102 и 68 TSM имеет 4352 и достигает 13 45 гигафлопс [14] . Я не стал рисовать структурную схему, потому что она выглядела бы как размытое зелёное пятно.
Что ждёт нас дальше
По слухам, следующая архитектура под кодовым названием Ampere будет объявлена в 2020 году. Так как Intel доказала на примере Ice Lake, что по-прежнему существует потенциал миниатюризации при помощи 7-нанометрового техпроцесса, почти нет сомнения в том, что Nvidia использует его для дальнейшего уменьшения SM и удвоения производительности.
Интересно будет посмотреть, как Nvidia продолжит эволюцию идеи кристаллов, имеющих три типа ядер, выполняющих разные задачи. Увидим ли мы кристаллы, целиком состояние из Tensor-ядер или RT-ядер? Любопытно.
Читайте также: