
Настройка postgresql для 1с
Приветствую тебя, мой юный 1С-ник. Ты, как и я, не любишь 1С и стараешься как можно быстрее и качественнее отвязаться от задач, связанных с этим продуктом, чтобы больше никогда к ним не возвращаться? Настроил — и забыл, это наш подход!
1С тормозит. Корову можно кормить топовыми процессорами, SSD и немеряным количеством оперативки, но гепардом она всё равно не станет. Этому есть несколько причин:
- Транзакционная модель, от этого в финансах не уйти. Транзакция сидит на транзакции и транзакцией погоняет. Опять же, транзакции подразумевают блокировки, пока блокировка не будет снята, объект не станет доступным другим пользователям.
- Доступность среды разработки. Куча разработчиков сидят, что-то там программируют. Бесконечные циклы, утечки памяти, перерасход ресурсов, кривые руки и непонимание того, что они делают. Ладно бы это делалось централизованно, но сколько 1С серверов, столько и разработчиков. Одну и ту же задачу можно решить разными способами, зачастую решение задачи оказывается не самым оптимальным. В итоге мы слышим: "Это железо тормозит!" "Это база тормозит!"
- Временные таблицы. Весь 1С построен на временных таблицах. На каждый чих создаётся временная таблица, с которой проводятся операции, на них даже индексы строятся. И если БД не может правильно обрабатывать временные таблицы, то успеха не будет. Table Scan — не самая быстрая операция.
- Неправильные настройки сервера БД. Кривые настройки — такой же результат.
Сегодня будем настраивать PostgreSQL 11.9 на сервере Windows Server 2019.
Что лучше: MSSQL или PostgreSQL?
Сложно сказать. С одной стороны, крутые исследователи заявляют о том, что правильно настроенный PostgreSQL выигрывает у MSSQL:
И тут я такой: "А если поднять у MSSQL tempdb в RAM диск?" И снова становится непонятно. Но понятно одно, MSSQL стоит денег, а PostgreSQL бесплатный.
Итак, тестовый стенд (или правильнее сказать, реальный?):
- Сервер, виртуальный, операционная система Windows Server 2019 Standard, триальная.
- CPU: 16 ядер
- ОЗУ: 64 ГБ
- Диск SSD, отдельный для БД.
- Размер базы: 50 Гб
- 1С 8.3 и PostgreSQL 11.9-1.1C вместе на одном сервере
- 50 аккаунтов пользователей 1С в настоящее время
По хорошему, мух следует отделять от котлет. И разносить 1С и БД на разные серверы. Однако, на практике, часто бывает иначе. Сервер имеется один, на нём размещают и базу и сервер 1С. И это не просто предположение, вчера привезли новый сервер и поставили задачу: установить Windows, MSSQL и 1С. Всё на одну машину. Но это немного другая история, не связанная с текущей.
Как разделить ресурсы между 1С и PostgreSQL?
Следовательно, для настроек PostgreSQL я исхожу из цифр:
- CPU: 16 ядер
- ОЗУ: 48 ГБ
- Диск: SSD
- Количество пользователей 1С: 100 (с расчётом на будущее)
Полезные ссылки
Настройка PostgreSQL 11.9
Основной файл настроек PostgreSQL — postgresql.conf . Приступим.
Максимальное количество одновременных подключений к БД. Я просто установил в два раза больше, чем текущее количество 1С пользователей. К базе ещё подключается пользователь для мониторинга и администраторы. Если будет не хватать, то можно потом изменить параметры.
Память
Количество памяти, выделенное для кэша страниц. Рекомендуется от 1/8 до 1/4 RAM. Вычисляю: 48 Гб / 4 = 12 Гб.
Лимит памяти для внутренних обслуживающих задач. Рекомендуется 1/4 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Кэш файловой системы. Планировщик исходя из этого параметра принимает решение об использовании больших индексов (IndexScan), и это хорошо. Рекомендуется RAM - shared_buffers. Вычисляю: 48 Гб - 12 Гб = 36 Гб.
Лимит памяти для обработки одного запроса. При превышении этого объёма сервер начинает использовать временные файлы на диске. Рекомендуется от 1/32 до 1/16 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Буфер под временные объекты, например, для временных таблиц. Рекомендуется 1/20 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Процессор
Максимальное число фоновых процессов. Зависит от количества выделенных для PostgreSQL ядер CPU. По калькулятору.
Задаёт максимальное число рабочих процессов, которое система сможет поддерживать для параллельных запросов. Рекомендуют равным max_worker_processes, однако в этом случае какой-то "толстый" запрос может сожрать все потоки и другим не достанется. Использую половину процессоров.
Задаёт максимальное число рабочих процессов, которые могут запускаться одним узлом Gather илиGather Merge. Не более max_parallel_workers, задал по максимуму.
Задаёт максимальное число рабочих процессов, которые могут запускаться одной служебной командой. По калькулятору.
Задаёт максимальное число файлов, которые могут быть одновременно открыты каждым процессом. Значение по умолчанию — 1000 файлов.
Задаёт максимальное число процессов автоочистки (не считая процесс, запускающий автоочистку), которые могут выполняться одновременно. Чем больше запросов записи, тем больше процессов. Если база только для чтения, то достаточно одного процесса.
Если параметр fsync включён, то при выполнении операции COMMIT данные сразу переписываются из кэша операционной системы на диск, тем самым гарантируется целостность данных при возможном аппаратном сбое. При этом снижается производительность операций записи на диск, поскольку при этом не используются возможности отложенной записи данных операционной системы. Данный параметр можно отключать только при наличие аппаратного RAID контроллера с кэшем в режиме write-back и батарейкой для гарантированной записи данных при отключении питания.
Задаёт допустимое число параллельных операций ввода/вывода, которое говорит PostgreSQL о том, сколько операций ввода/вывода могут быть выполнены одновременно. Для магнитных носителей хорошим начальным значением этого параметра будет число отдельных дисков, составляющих массив RAID 0 или RAID 1, в котором размещена база данных. Для RAID 5 следует исключить один диск (как диск с чётностью). У меня один диск, поэтому у меня данный параметр закомментирован.
Метод, который используется для принудительной записи данных на диск. Возможные значения:
- open_datasync – запись данных методом open() с параметром O_DSYNC,
- fdatasync – вызов метода fdatasync() после каждого commit,
- fsync_writethrough – вызывать fsync() после каждого commit игнорирую паралельные процессы,
- fsync – вызов fsync() после каждого commit,
- open_sync – запись данных методом open() с параметром O_SYNC.
Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL. Для Windows рекомендуется open_datasync. Для Linux — fdatasync.
В версии PostgreSQL 11.9 не используется, поэтому у меня данный параметр закомментирован. Данный параметр определяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. В зависимости от объема данных установите этот параметр в диапазоне от 12 до 256 сегментов и, если в логе появляются предупреждения (warning) о том, что контрольные точки происходят слишком часто, постепенно увеличивайте его. Можно установить в 32 (если у вас PostgreSQL поддерживает этот параметр) и дальше смотреть предупреждения в логе.
Часть интервала контрольной точки. Рекомендуется максимальное значение 0.9.
PostgreSQL сначала пишет в буферы, а затем эти буферы сбрасываются в WAL файлы на диск. По молчанию 16MB.
Минимальный размер WAL файла. Установил чуть больше, чем предложил калькулятор.
Максимальный размер WAL файла. Рекомендуется от 2 * min_wal_size до 4 * min_wal_size.
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем gwriter_lru_maxpages.
Параметры, управляющие интенсивностью записи фонового процесса записи.
Отключаем синхронизацию с диском в момент коммита. Есть риск потери последних нескольких транзакций, но гарантируется целостность базы данных. Значительно увеличивает производительность.
Пауза в микросекундах перед собственно выполнением сохранения WAL.
Минимальное число одновременно открытых транзакций, при котором будет добавляться задержка commit_delay.
Оптимизатор запросов
Количество записей, просматриваемых при сборе статистики по таблицам. Рекомендуется для 1С от 1000 до 10000. Я поставил 300, если будут зависания, параметр можно увеличить.
Задаёт максимальное число элементов в списке FROM, до которого планировщик будет объединять вложенные запросы с внешним запросом. При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). Рекомендуется 1, но сложные запросы с большим количеством соединений и источников данных станут надолго зависать. Поэтому ставлю чуть меньше значения по умолчанию — 6.
Задаёт приблизительную стоимость последовательного чтения одной страницы с диска. Для NVMe дисков рекомендуется 0.1. Для HDD 1.5 - 2.0. Для SSD 1.1 - 1.3. Можно посмотреть характеристики ваших дисков.
Задаёт приблизительную стоимость случайного чтения одной страницы с диска. Рекомендуется ставить чуть больше чем seq_page_cost.
Задаёт приблизительную стоимость обработки оператора или функции при выполнении запроса. Рекомендуется 0.00025.
Типы таблиц, для которых выполняется немедленный анализ:
- all (все),
- persistent (постоянные),
- temporary (временные),
- none (никакие).
При возникновении проблем с производительностью выполнения регламентных операций можно включить сбор статистики для всех таблиц: all.
Минимальное число изменений строк, после которого может начаться немедленный анализ.
Процент от размера таблицы, при котором начинается немедленный анализ.
Минимальный интервал времени между вызовами ANALYZE для отдельной таблицы (в миллисекундах).
online_analyze использует для временных таблиц системную статистику по умолчанию.
plantuner будет обнулять число страниц/кортежей в таблице, которая не содержит никаких блоков в файле.
Отключает использование планов соединения с вложенными циклами.
Отключает использование планов соединения слиянием.
Сбор статистики
Включает сбор статистики активности в базе данных. Этот параметр по умолчанию включён, так как собранная информация требуется автоочистке.
Разрешить использовать символ "\" для экранирования.
Не выдавать предупреждение об использовании символа "\" для экранирования.
shared_preload_libraries = 'online_analyze, plantuner'
Библиотеки, которые будут загружаться при запуске сервера.
Анализ статистики временных таблиц.
PostgreSQL
Этот параметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции.
Шифрование. Если сеть защищена, то отключаем. Если 1С и PostgreSQL находятся на одном сервере — тем более отключаем.
Прошёл месяц
Сначала были какие-то ошибки в логах postgresql, но они были связаны с процессом разработки. Месяц — полёт нормальный.
Если вам понравилась статья, то ставьте 👍🏻 каналу.
Пишите комментарии, задавайте вопросы, подписывайтесь.
Под «Окнами» «Слона» водили… Когда файловая БД 1С вырастает и начинает тормозить, встает вопрос по переводу базы на SQL, безусловно, лидеры и самые используемые при настройке SQL баз на 1С это ПО Microsoft SQL Server и PostgerSQL, (прочие IBM DB2 и Oracle Datebase), но жирный плюс в сторону PostgerSQL, что она условно бесплатная, в отличие от цены на MSSQL.
PostgerSQL заточен под Linux и в своей среде он будет работать лучше и быстрее (как рыба в воде), но есть и адаптированный под Windows, требующий чуть больших настроек для оптимизации, чем просто "далее-далее-далее" в MSSQL. Хотя на небольших БД на первых этапах хватает и стандартной настройки задаваемой при установке.
Тесты о работе и производительности на разных системах разных продуктов MS SQL, PostgerSQL, под Linux, Windows легко можно найти в интернете, тут же мы рассмотрим простую установку и базовую настройку для работы 1С 8 на PostgerSQL 11.5 под Windows Server 2008 R2.
Постановка задачи:
1С Предприятие 8.3.16.1063, 1С БД Бухгалтерия 3.0.75.58 – размер файла ~15 Гб.
Сервер: i5-9400, ОЗУ DDR4 16 Гб, SSD 256, ОС Windows Server 2008R2 x64
Установка и настройка PostgreSQL:
1. Подготовка:
Перед установкой и настройкой рекомендуется отключить протокол IPv6, иначе это может затруднить дальнейшую настройку.

Также необходимо установить Microsoft Visual C++ 2015 (на сайте 1С он идет в комплекте)

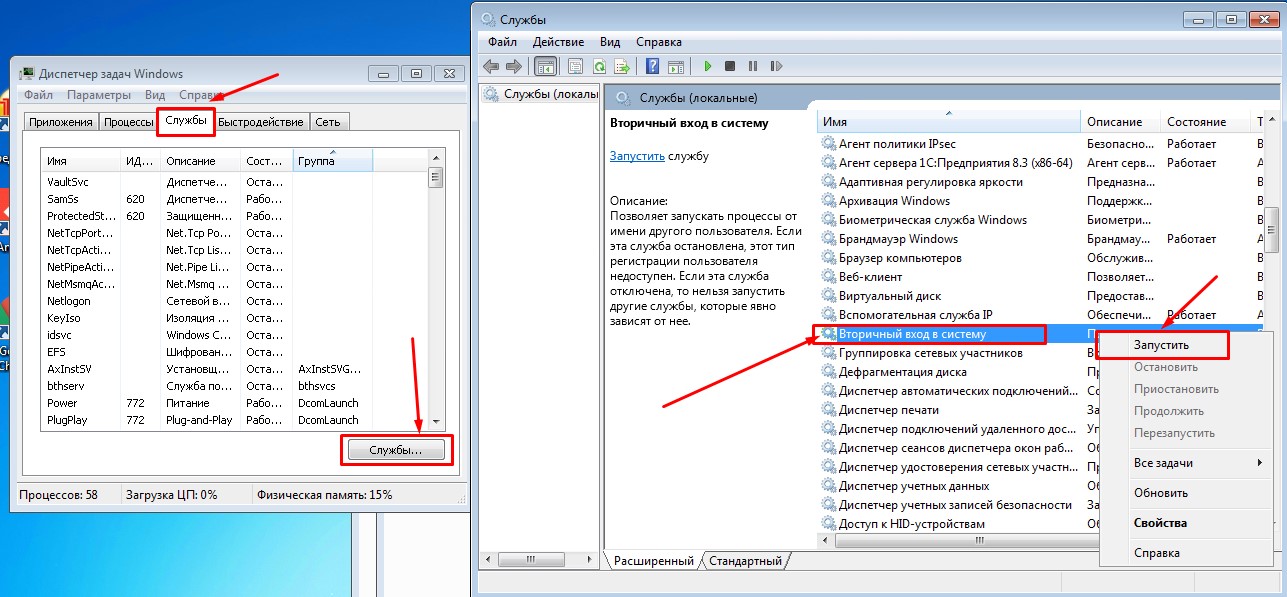
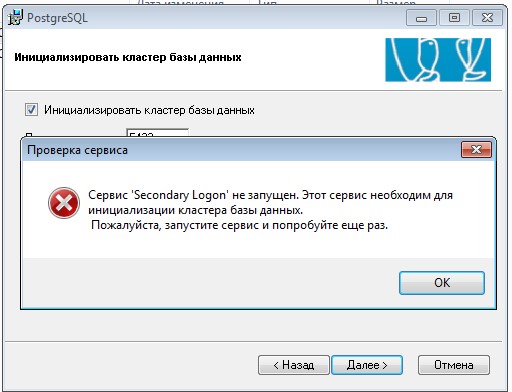
Также заранее рекомендуется включить службу "Вторичный вход в систему", иначе при установке будет ошибка.
2. Процесс установки
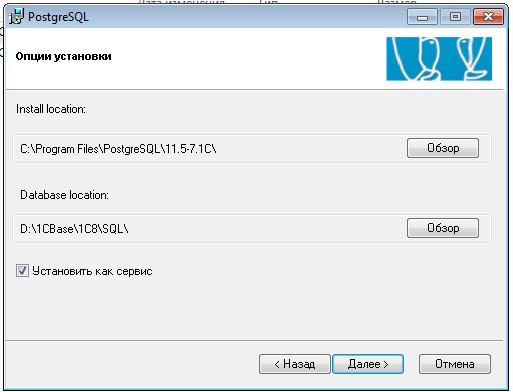
Далее указываем путь установки программы (его не меняем) и путь, где будут располагаться БД (его рекомендуется сменить, чтобы БД хранились не на системном диске)
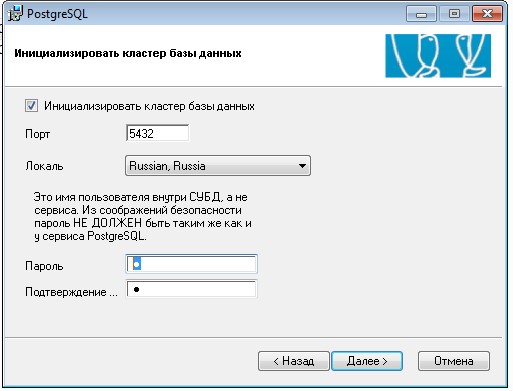
Если вы не запустили службу "Вторичный вход в систему" то у вас будет ошибка, ее можно включить на этапе установки и продолжить:

После установки запускаем консоль администратора "Пуск-PostgreSQL 11.5-7.1C(x64)-pgAdmin 4"
На этом установка PostgreSQL закончена.
3. Установка 1С сервера:
Запуститься помощник установки системы «1С:Предприятия». На первой странице жмем «Далее».
На следующей странице необходимо выбрать те компоненты, которые будут устанавливаться, нам требуются компоненты:
- Сервер 1С:Предприятия — компоненты сервера «1С:Предприятия»
- Администрирование сервера 1С:Предприятия 8 — дополнительные компоненты для администрирования кластера серверов «1С:Предприятия»
Сделав выбор жмем «Далее».

Если сервер «1С:Предприятия» устанавливается как служба Windows рекомендуется сразу создать отдельного пользователя, из под которого будет запускаться служба "Агент сервера 1С Предприятия", либо можно выбрать существующего пользователя для запуска сервера. Для создание нового пользователя необходимо:
- Выбираем флаг «Установить сервер 1С:Предприятие как сервис Windows (рекомендуется)»;
- Выбираем «Создать пользователя USR1CV8» и задаем его пароль (пароль должен отвечать политики паролей Windows).
Также пользователю обязательно следует дать необходимые права на каталог служебных файлов сервера (по умолчанию C:\Program Files\1cv8\srvinfo для 64-х разрядного и C:\Program Files (x86)\1cv8\srvinfo для 32-х разрядного сервера). Созданный автоматически пользователь USR1CV8 будет обладать всеми перечисленными правами.
Заполнив соответствующие параметры, жмем «Далее».

Далее идет установка всех необходимых файлов и служб. После чего следует убедиться что появилась и запущена соответствующая служба.

На этом установка Сервера 1С Предприятия закончена.
4. Создание 1С БД для PostgreSQL
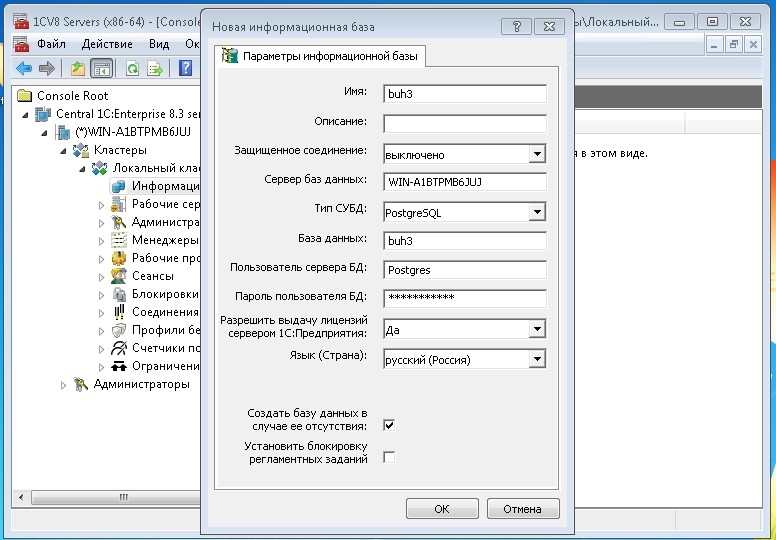
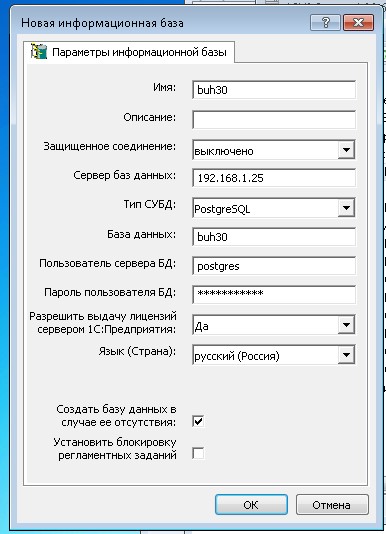
После установки 1С Сервера запускаем "Администрирование серверов 1С Предприятия x86-64", переходим в список "Информационные базы" и создаем новую БД. Заполняем основные поля:
- Имя - имя БД на сервере 1с
- Сервер баз данные - имя сервера где будет располагаться БД 1С SQL
- Тип СУБД - выбор на какой платформе у вас будет работать ваша база (MSSQL, PostgeSQL, IBM DB2, Oracle DateBase)
- База данных - имя базы которое будет создано в SQL
- Пользователь и пароль БД - пользователь в SQL
- Создавать базу данных в случае ее отсутствия - Создает БД в SQL если ее нет.
Если вы не отключили протокол IPv6 то у вас при создании будет ошибка:
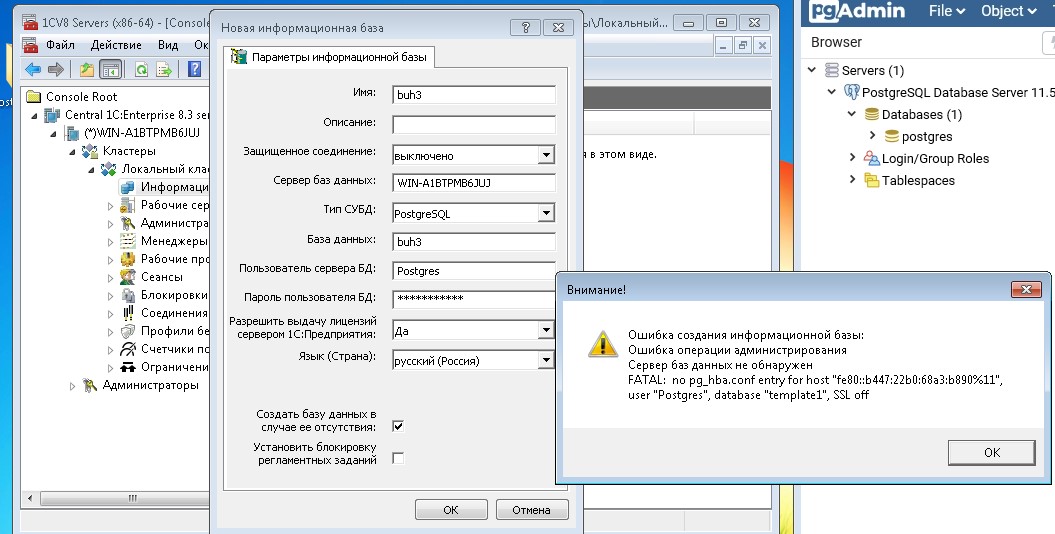
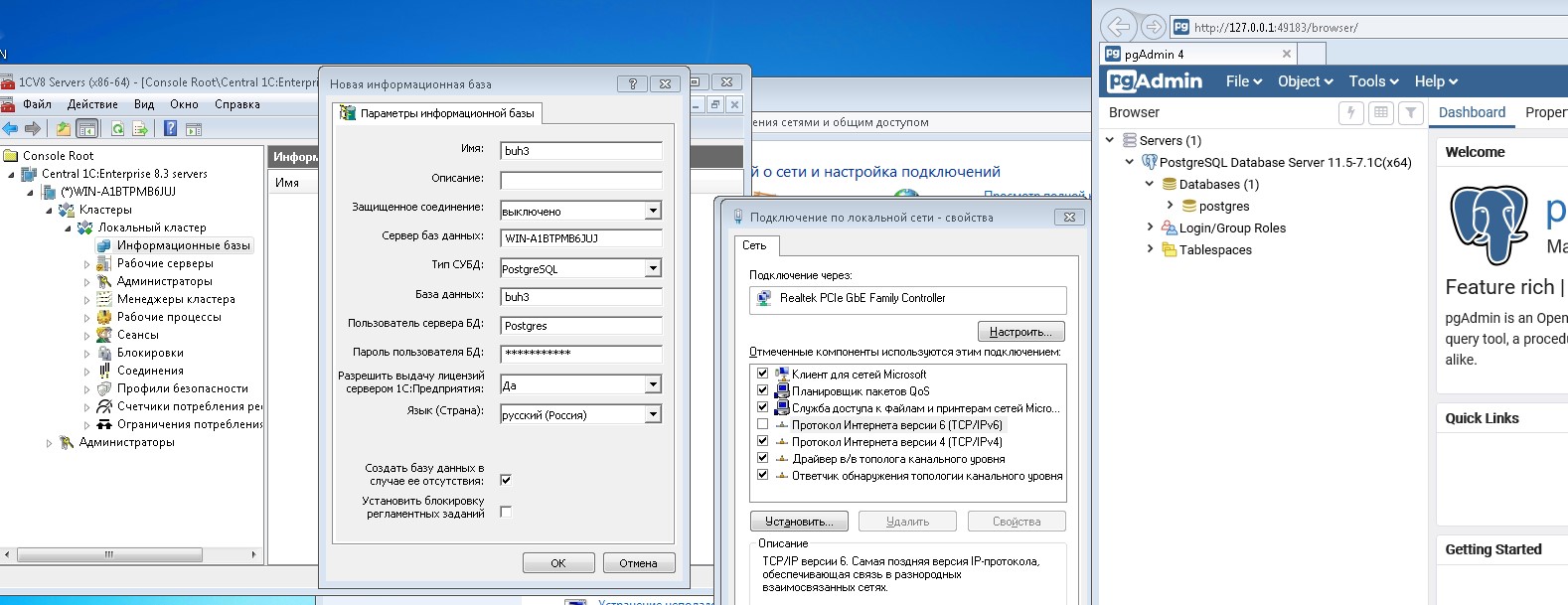
можно отключить протокол IPv6 и продолжить создание, либо можно указать IP адрес сервера без отключение протокол IPv6:
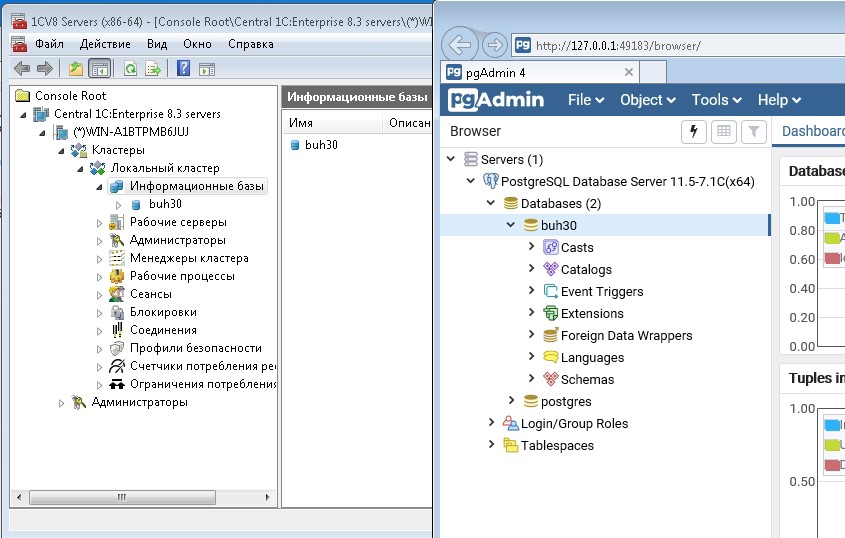
Все на этом этапе БД готова, в принципе ее можно подключать загружать в SQL и работать. Но рекомендуется сделать настройку самого Postgre сервера для оптимизации и более стабильной работы базы 1С на PostgreSQL. Делается это в 1 файле расположенном в каталоге с базами (путь который вы указывали при установке для баз по умолчанию C:\Program Files\PostgreSQL\11.5-7.1C\data). Файл postgresql.conf
5. Настройка PostgreSQL под 1С 8
ВАЖНО. Перед любыми изменения в этом файле обязательно сделайте его копию, в противном случаем если какой то параметр указан не верно у вас не запустится служба PostgreeSQL:
Перед тем как вносить изменения в файл postgresql.conf необходимо остановить службу

Изменение параметров в postgresql.conf:
Вся документация по настройке так же есть на сайте 1С (its.1c.ru) а разделе "Методическая поддержка для разработчиков и администраторов 1С:Предприятия 8"
После чего запускаем службу PostgreSQL и можно работать.
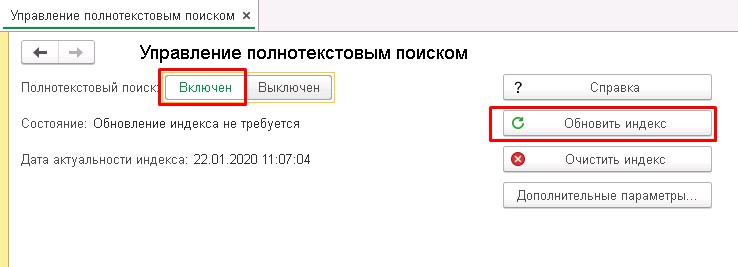
Так же иногда по какой то причине после загрузки в PostgreSQL в базе отключается "Полнотекстовый поиск", поэтому после настройки рекомендуется проверить и включить если выключено и обновить индексы (все функции-стандартные-управление полнотекстовым поиском).
Во вложении дистрибутив postgresql_11.5_7.1C_x64 с сайта 1С и файл настроек postgresql.conf.
Начнем с того, что дистрибутив PostgreSQL нужно брать ИТС-ный, ибо че-то там не так, если качать с официальных страниц СУБД.
*Буду стараться делать так, сначала будет идти скриншот, ниже описание.
У меня на руках postgresql-9.1.2-1.1C(x64) так что нажимаю на установщике .exe

Ничегошеньки не менял, ибо логи установки, которые предлагают мне сохранить в текущей директории, мне не нужны, и русский язык СУБД меня устраивал.

И здесь оставил все по умолчанию, ибо сам не знаю толком, какая опция и за что отвечает, все и так заработает без проблем.

Здесь зададим пользователю postgres, под которым будет запускаться СУБД (если данного пользователя нет в системе, он будет автоматически создан) пароль, сложный, сложный, все остальные параметры заполнились самостоятельно и трогать их не вижу смысла.

Как видим из описания о пользователе, postgres пользователю также нужно задать пароль, что и сделаем.
Кодировку лучше изменить на UTF-8, почему? А я не знаю, уже и забыл преимущества данной кодировки, умные люди в комментариях опишут, почему лучше та или иная кодировка
Поддерживать подсоединения с любых IP, а не только с localhost – означает, мол, будет возможность подключаться к серверу извне в локальной сети

Уведомление смиренно прочитали и запомнили, что нужно и куда нужно зайти после установки, продолжаем .

Тут как бы все понятно, жмем WIN+R вводим services.msc находим службу «Вторичный вход в систему» и запускаем ее + ставим автозапуск службы, далее опять повторяем нажатие «Далее», где видим

Это что-то такое мудрёное, что для нашей задачи навряд ли понадобится, пропускаем смело, оставляем все как есть

Какие там модули, мы устанавливать без модулей еще не научились, поэтому что было по умолчанию, то и оставляем.
Ждем окончания установки.

Нам эти фишки ни к чему, снимаем галку, жмем «Завершить»
Управление СУБД осуществляется утилитой pgAdmin III, которую можно найти в списке программ Пуск, но имейте в виду, что нужно ее обновить, ибо после запуска pgAdmin III и последующего подключения к БД получаем картинку

Приступим к установке 1С сервера
У меня мега 1C_8.3.7.1633 версия, так что поехали

Здесь ничего нового, устанавливаем компоненты сервера и, чтобы администрировать им, устанавливаем компоненты администрирования

Здесь я только ввел пароль для пользователя postgres, который будет являться администратором для нашего кластера серверов
Всякие там драйвера защиты и т.д., при установке я не устанавливал, ибо не наш случай, у нас задача ознакомительная.
- ! Для управление кластером серверов 1С используем Администрирование серверов 1С Предприятия
- ! Для управления СУБД используем pgAdmin III
Давайте теперь попробуем создать новую, пустую базу данных посредством программы запуска информационных баз 1С - 1cestart.exe

Кластер серверов 1С Предприятие = 192.168.1.111 это айпишник компьютера, на котором установлен сервера 1С, в нашем случаи это наш основной пк
Имя информационной базы в кластере = пишем, что хотим, если БД с таким именем не будет, создастся автоматически
Защищенное соединение = не трогаем, пока без этого обойдемся
Тип СУБ = коль установили Postgresql, тогда и выбираем данную СУБД из списка
Сервер базы данных = айпишний, тот же айпишник компьютера, на котором установлена СУБД
Имя базы данных = как назовем, так и будет называться наша БД в списке СУБД
Пользователь базы данных = да, наш пользователь из СУБД, помните, это postgres
Пароль пользователя = пароль выше упомянутого пользователя
Создать базу данных в случаи ее отсутствия = Да, ставим галку
Все иные параметры типа Язык и ниже галка о блокировке заданий не изменяем, не нужно пока это, если вы читаете данный текст.
Результат на экран

А теперь попробуем по локальной сети подключиться к нашей базе данных.



А это ничто иное, как блокировка портов брандмауэром, а именно 1541, 1560 портов, который нужно разрешить

И получаем запущенный сеанс

А теперь продемонстрирую удаленное подключение, из интернета к нашей базе
Предварительно, настраиваем на сервере 1С форвардинг портов на роутере, типа

Соответственно, напомню, эти же порты должны быть открыты брандмауэром
Далее, на удаленном компьютере (назовем его клиент), открываем файл hosts, что находится по пути в проводнике %WinDir%\System32\Drivers\Etc и добавляем запись
77.121.199.91 ws
Где циферки - это айпи адрес внешний нашего сервера, а буковки это название нашего сервера, к которому подключаемся

А также на клиенте нужно открыть файл nethasp.ini, который находится по пути C:\Program Files (x86)\1cv8\conf, найти параметр NH_SERVER_ADDR, который нужно разкомментировать + вместо вписать внешний айпишник нашего сервера, в итоге вышло

А далее, на том же удаленном компьютере добавляем запись для подключения к информационной базе, указываем наш алиас, который задали в файле hosts + порт кластера серверов ну и наименование нашей БД с кластера

Приветствую тебя, мой юный 1С-ник. Ты, как и я, не любишь 1С и стараешься как можно быстрее и качественнее отвязаться от задач, связанных с этим продуктом, чтобы больше никогда к ним не возвращаться? Настроил — и забыл, это наш подход!
1С тормозит. Корову можно кормить топовыми процессорами, SSD и немеряным количеством оперативки, но гепардом она всё равно не станет. Этому есть несколько причин:
- Транзакционная модель, от этого в финансах не уйти. Транзакция сидит на транзакции и транзакцией погоняет. Опять же, транзакции подразумевают блокировки, пока блокировка не будет снята, объект не станет доступным другим пользователям.
- Доступность среды разработки. Куча разработчиков сидят, что-то там программируют. Бесконечные циклы, утечки памяти, перерасход ресурсов, кривые руки и непонимание того, что они делают. Ладно бы это делалось централизованно, но сколько 1С серверов, столько и разработчиков. Одну и ту же задачу можно решить разными способами, зачастую решение задачи оказывается не самым оптимальным. В итоге мы слышим: "Это железо тормозит!" "Это база тормозит!"
- Временные таблицы. Весь 1С построен на временных таблицах. На каждый чих создаётся временная таблица, с которой проводятся операции, на них даже индексы строятся. И если БД не может правильно обрабатывать временные таблицы, то успеха не будет. Table Scan — не самая быстрая операция.
- Неправильные настройки сервера БД. Кривые настройки — такой же результат.
Сегодня будем настраивать PostgreSQL 11.9 на сервере Windows Server 2019.
Что лучше: MSSQL или PostgreSQL?
Сложно сказать. С одной стороны, крутые исследователи заявляют о том, что правильно настроенный PostgreSQL выигрывает у MSSQL:
И тут я такой: "А если поднять у MSSQL tempdb в RAM диск?" И снова становится непонятно. Но понятно одно, MSSQL стоит денег, а PostgreSQL бесплатный.
Итак, тестовый стенд (или правильнее сказать, реальный?):
- Сервер, виртуальный, операционная система Windows Server 2019 Standard, триальная.
- CPU: 16 ядер
- ОЗУ: 64 ГБ
- Диск SSD, отдельный для БД.
- Размер базы: 50 Гб
- 1С 8.3 и PostgreSQL 11.9-1.1C вместе на одном сервере
- 50 аккаунтов пользователей 1С в настоящее время
По хорошему, мух следует отделять от котлет. И разносить 1С и БД на разные серверы. Однако, на практике, часто бывает иначе. Сервер имеется один, на нём размещают и базу и сервер 1С. И это не просто предположение, вчера привезли новый сервер и поставили задачу: установить Windows, MSSQL и 1С. Всё на одну машину. Но это немного другая история, не связанная с текущей.
Как разделить ресурсы между 1С и PostgreSQL?
Следовательно, для настроек PostgreSQL я исхожу из цифр:
- CPU: 16 ядер
- ОЗУ: 48 ГБ
- Диск: SSD
- Количество пользователей 1С: 100 (с расчётом на будущее)
Далее RAM — это 48 Гб, которые выделены для PostgreSQL.
Полезные ссылки
Настройка PostgreSQL 11.9
Основной файл настроек PostgreSQL — postgresql.conf. Приступим.
Максимальное количество одновременных подключений к БД. Я просто установил в два раза больше, чем текущее количество 1С пользователей. К базе ещё подключается пользователь для мониторинга и администраторы. Если будет не хватать, то можно потом изменить параметры.
Память
Количество памяти, выделенное для кэша страниц. Рекомендуется от 1/8 до 1/4 RAM. Вычисляю: 48 Гб / 4 = 12 Гб.
Лимит памяти для внутренних обслуживающих задач. Рекомендуется 1/4 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Кэш файловой системы. Планировщик исходя из этого параметра принимает решение об использовании больших индексов (IndexScan), и это хорошо. Рекомендуется RAM - shared_buffers. Вычисляю: 48 Гб - 12 Гб = 36 Гб.
Лимит памяти для обработки одного запроса. При превышении этого объёма сервер начинает использовать временные файлы на диске. Рекомендуется от 1/32 до 1/16 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Буфер под временные объекты, например, для временных таблиц. Рекомендуется 1/20 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Процессор
Максимальное число фоновых процессов. Зависит от количества выделенных для PostgreSQL ядер CPU. По калькулятору.
Задаёт максимальное число рабочих процессов, которое система сможет поддерживать для параллельных запросов. Рекомендуют равным max_worker_processes, однако в этом случае какой-то "толстый" запрос может сожрать все потоки и другим не достанется. Использую половину процессоров.
Задаёт максимальное число рабочих процессов, которые могут запускаться одним узлом Gather илиGather Merge. Не более max_parallel_workers, задал по максимуму.
Задаёт максимальное число рабочих процессов, которые могут запускаться одной служебной командой. По калькулятору.
Задаёт максимальное число файлов, которые могут быть одновременно открыты каждым процессом. Значение по умолчанию — 1000 файлов.
Задаёт максимальное число процессов автоочистки (не считая процесс, запускающий автоочистку), которые могут выполняться одновременно. Чем больше запросов записи, тем больше процессов. Если база только для чтения, то достаточно одного процесса.
Если параметр fsync включён, то при выполнении операции COMMIT данные сразу переписываются из кэша операционной системы на диск, тем самым гарантируется целостность данных при возможном аппаратном сбое. При этом снижается производительность операций записи на диск, поскольку при этом не используются возможности отложенной записи данных операционной системы. Данный параметр можно отключать только при наличие аппаратного RAID контроллера с кэшем в режиме write-back и батарейкой для гарантированной записи данных при отключении питания.
Задаёт допустимое число параллельных операций ввода/вывода, которое говорит PostgreSQL о том, сколько операций ввода/вывода могут быть выполнены одновременно. Для магнитных носителей хорошим начальным значением этого параметра будет число отдельных дисков, составляющих массив RAID 0 или RAID 1, в котором размещена база данных. Для RAID 5 следует исключить один диск (как диск с чётностью). У меня один диск, поэтому у меня данный параметр закомментирован.
Метод, который используется для принудительной записи данных на диск. Возможные значения:
- open_datasync – запись данных методом open() с параметром O_DSYNC,
- fdatasync – вызов метода fdatasync() после каждого commit,
- fsync_writethrough – вызывать fsync() после каждого commit игнорирую паралельные процессы,
- fsync – вызов fsync() после каждого commit,
- open_sync – запись данных методом open() с параметром O_SYNC.
Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL. Для Windows рекомендуется open_datasync. Для Linux — fdatasync.
В версии PostgreSQL 11.9 не используется, поэтому у меня данный параметр закомментирован. Данный параметр определяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. В зависимости от объема данных установите этот параметр в диапазоне от 12 до 256 сегментов и, если в логе появляются предупреждения (warning) о том, что контрольные точки происходят слишком часто, постепенно увеличивайте его. Можно установить в 32 (если у вас PostgreSQL поддерживает этот параметр) и дальше смотреть предупреждения в логе.
Часть интервала контрольной точки. Рекомендуется максимальное значение 0.9.
PostgreSQL сначала пишет в буферы, а затем эти буферы сбрасываются в WAL файлы на диск. По молчанию 16MB.
Минимальный размер WAL файла. Установил чуть больше, чем предложил калькулятор.
Максимальный размер WAL файла. Рекомендуется от 2 * min_wal_size до 4 * min_wal_size.
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем gwriter_lru_maxpages.
Параметры, управляющие интенсивностью записи фонового процесса записи.
Отключаем синхронизацию с диском в момент коммита. Есть риск потери последних нескольких транзакций, но гарантируется целостность базы данных. Значительно увеличивает производительность.
Пауза в микросекундах перед собственно выполнением сохранения WAL.
Минимальное число одновременно открытых транзакций, при котором будет добавляться задержка commit_delay.
Оптимизатор запросов
Количество записей, просматриваемых при сборе статистики по таблицам. Рекомендуется для 1С от 1000 до 10000. Я поставил 300, если будут зависания, параметр можно увеличить.
Задаёт максимальное число элементов в списке FROM, до которого планировщик будет объединять вложенные запросы с внешним запросом. При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). Рекомендуется 1, но сложные запросы с большим количеством соединений и источников данных станут надолго зависать. Поэтому ставлю чуть меньше значения по умолчанию — 6.
Задаёт приблизительную стоимость последовательного чтения одной страницы с диска. Для NVMe дисков рекомендуется 0.1. Для HDD 1.5 - 2.0. Для SSD 1.1 - 1.3. Можно посмотреть характеристики ваших дисков.
Задаёт приблизительную стоимость случайного чтения одной страницы с диска. Рекомендуется ставить чуть больше чем seq_page_cost.
Задаёт приблизительную стоимость обработки оператора или функции при выполнении запроса. Рекомендуется 0.00025.
Типы таблиц, для которых выполняется немедленный анализ:
- all (все),
- persistent (постоянные),
- temporary (временные),
- none (никакие).
При возникновении проблем с производительностью выполнения регламентных операций можно включить сбор статистики для всех таблиц: all.
Минимальное число изменений строк, после которого может начаться немедленный анализ.
Процент от размера таблицы, при котором начинается немедленный анализ.
Минимальный интервал времени между вызовами ANALYZE для отдельной таблицы (в миллисекундах).
online_analyze использует для временных таблиц системную статистику по умолчанию.
plantuner будет обнулять число страниц/кортежей в таблице, которая не содержит никаких блоков в файле.
Отключает использование планов соединения с вложенными циклами.
Отключает использование планов соединения слиянием.
Сбор статистики
Включает сбор статистики активности в базе данных. Этот параметр по умолчанию включён, так как собранная информация требуется автоочистке.
Разрешить использовать символ "\" для экранирования.
Не выдавать предупреждение об использовании символа "\" для экранирования.
Библиотеки, которые будут загружаться при запуске сервера.
Анализ статистики временных таблиц.
PostgreSQL
Этот параметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции.
Шифрование. Если сеть защищена, то отключаем. Если 1С и PostgreSQL находятся на одном сервере — тем более отключаем.
Прошёл месяц
Сначала были какие-то ошибки в логах postgresql, но они были связаны с процессом разработки. Месяц — полёт нормальный.

Вопросу, какая же СУБД - Postgresql или MS SQL для 1С является наиболее оптимальной, посвящено множество статей. В этой статье мы рассмотрим шаги оптимизации обоих. Каждая СУБД вендора имеет как собственные рекомендации по настройке, так и рекомендации фирмы 1С. Следует отметить, что в зависимости от оборудования, конфигурации серверов и количества пользователей, задающих разную нагрузку, детали процесса оптимизации СУБД под 1С и реализации рекомендаций могут меняться.
Настройка PostgreSQL под 1С
Опыт эксплуатации баз 1С на PostgreSQL показал, что наибольшей производительности и оптимальной работы 1С и PostgreSQL удалось добиться на linux, поэтому желательно использовать именно ее. Но вне зависимости от операционной системы, важно помнить, что настройки, указанные по умолчанию при установке PostgreSQL, предназначены только для запуска сервера СУБД. Ни о какой промышленной эксплуатации речи идти не может! Следующим шагом после запуска станет оптимизация PostgreSQL под 1С:
Установка параметра shared_buffers в RAM/4 является рекомендацией по умолчанию, но пример Sql Server говорит о том, что чем больше памяти ему выделяется, тем лучше его производительность (при отключенном сбросе страниц в файл подкачки). То есть, чем больше страниц данных располагаются в оперативной памяти, тем меньше обращений к диску. Возникает вопрос: почему такой маленький кэш? Ответ прост: если shared_buffers большой, то часть неиспользуемых страниц свопируется на диск. Но как отследить момент, когда сброс прекратится, и показатель параметра будет оптимальным? Для достижения и выхода на оптимальный показатель shared_buffers, его значение необходимо поднимать на продуктиве ежедневно (по возможности) с определенным шагом прироста и смотреть, в какой момент начнется сброс страниц на диск (увеличится своп).
- Помимо этого, на «большой параметр» негативно влияет работа с множеством мелких страниц, которые по умолчанию имеют размер 8Кб. Работа с ними увеличивает накладные расходы. Что можно с этим сделать для оптимизации под 1С? В версии postgreSQL 9.4 появился параметр huge_pages, который можно включить, но только в Linux. По умолчанию включаются огромные страницы с размером по умолчанию 2048 kB. Дополнительно поддержку данных страниц необходимо включить в ОС. Таким образом, оптимизировав структуру хранения, можно выйти на больший показатель shared_buffers.
- work_mem = RAM/32..64 или 32MB..128MB Задает объем памяти для каждой сессии, который будет использоваться для внутренних операций сортировки, объединения и пр., прежде чем будут задействованы временные файлы. При превышении этого объема, сервер будет использовать временные файлы на диске, что может существенно снизить скорость обработки запросов. Данный параметр используется при выполнении операторов: ORDER BY, DISTINCT, соединения слиянием и пр.
- Посчитать дополнительно данный параметр можно следующим образом: (Общая память shared_buffers – память на другие программы) / число активных соединений. Это значение можно уменьшать, следя за количеством создаваемых временных файлов. Такую статистику по размеру и количеству временных файлов можно получить из системного представления pg_stat_database.
- effective_cache_size = RAM - shared_buffers основная задача этого параметра подсказать оптимизатору запроса, какой способ получения данных выбрать: полный просмотр или сканирование по индексу. Чем выше значение параметра, тем больше вероятность использования сканирования по индексу. При этом сервер не учитывает, что данные при выполнении запроса могут оставаться в памяти, и следующему запросу не надо их поднимать с диска.
Установка PostgreSQL
Установка 1С на PostgreSQL под Windows – достаточно простой процесс. При запуске установочного пакета необходимо указать кодировку UTF-8. По сути, это единственный интересный нюанс и еще какая-то настройка PostgreSQL для 1С 8.3 из-под Windows не потребуется. Установка и настройка PostgreSQL для 1С на ОС linux может вызвать ряд затруднений. Для их преодоления в качестве примера рассмотрим запуск работы (используя дистрибутивы ведущего российского вендора PostgreSQL-Pro и компании 1С) PostgreSQL на сервере Ubuntu 16.04 х64
Установка дистрибутивов 1С для СУБД PostgreSQL
1.Скачиваем указанную позицию дистрибутива СУБД PostgreSQL:
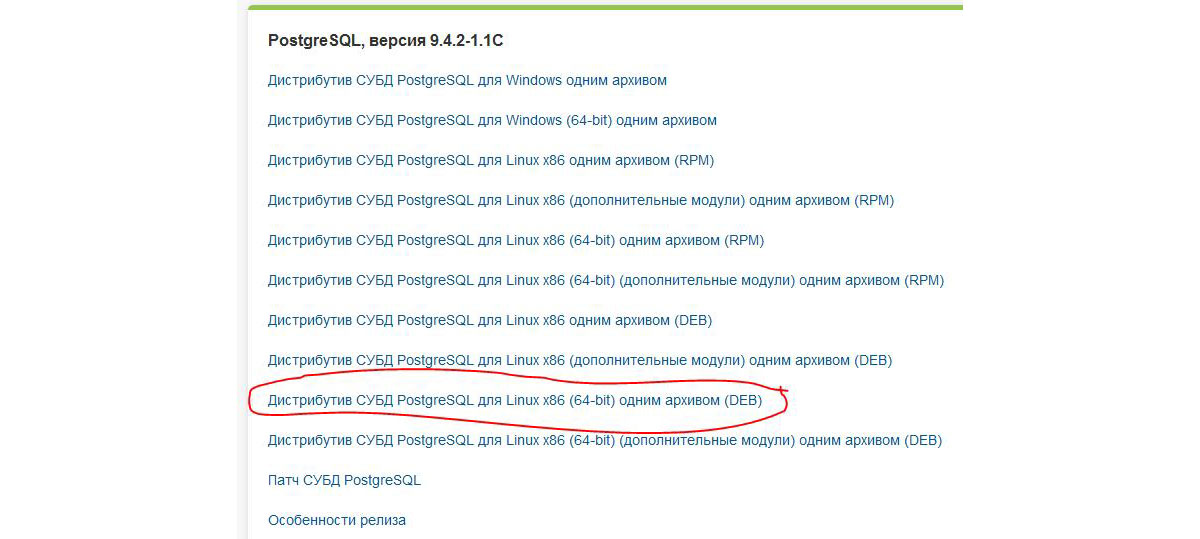
Рис.1 Оптимизация СУБД под 1С
2.Выкладываем PostgreSQL на сервер;
3.Распаковать установщик СУБД PostgreSQL можно командой:
4.Перед установкой дистрибутива СУБД PostgreSQL проверим наличие в системе необходимой локали (по умолчанию ru_RU.UTF-8):
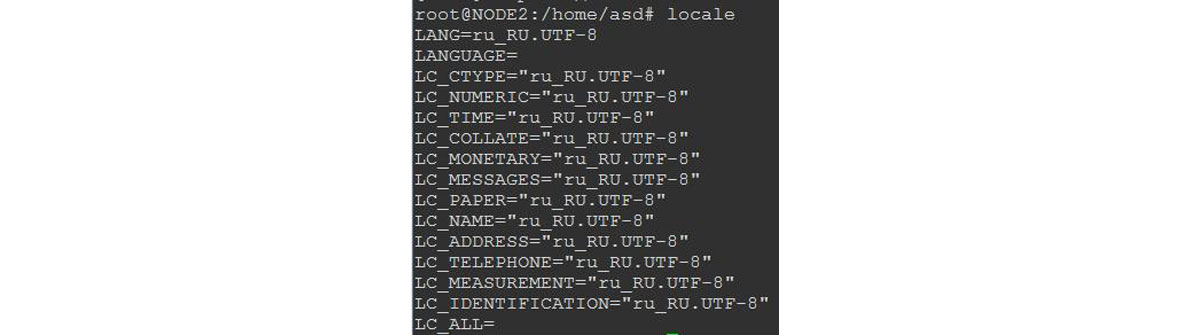
Рис.2 Оптимизация СУБД под 1С
5.Если система, с которой будет работать PostgreSQL, ставилась с языком отличным от русского, необходимо создать новые локали:
6.Если необходимая локаль все же имеется, устанавливаем ее по умолчанию:
7.После перезагрузки, установим необходимые пакеты для нашей версии PostgreSQL:
8.Версия PostgreSQL пакета 9.4.2-1.1C связана с пакетом libicu версии libicu48. В репозитории нужной версии уже нет, ее можно скачать;
9.Скачиваем и помещаем в каталог, где хранятся скачанные файлы для PostgreSQL;
10.Перейдя в каталог с файлами PostgreSQL, производим установку, последовательно набирая следующие команды:
Читайте также: