
Набор файлов из которых после компиляции получается программа это
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
Состав компилятора g++
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
Перед тем, как приступать, давайте создадим исходный .cpp файл, с которым и будем работать в дальнейшем.
driver.cpp:
1) Препроцессинг
Самая первая стадия компиляции программы.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
Взглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
Мы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
Но на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Компиляция проекта проходит в два этапа. Сначала выполняется предварительная обработка проекта с помощью программы qmake . Этот инструмент Qt несёт ответственность за весь процесс компиляции проекта. Он читает содержание проектного файла и генерирует необходимые промежуточные файлы (дополнительные файлы с исходным кодом и make -файлы для компиляции). Это необходимо для того, чтобы превратить все особые расширения Qt , которые были использованы в программе, в код на языке C++ и использовать дополнительные настройки для проекта, описанные в pro-файле. После этого проект готов к обработке компилятором. Вторым этапом является непосредственно процесс компиляции. Все эти действия выполняются автоматически в среде Qt Creator .

После успешной компиляции мы получаем исполняемый файл программы. Откройте папку проекта. Она будет содержать исполняемый файл и все промежуточные файлы, сгенерированные в процессе.
Таким образом, процессом построения проекта руководит .pro - файл . При наличии исходных текстов программы и при отсутствии .pro -файла, его можно сгенерировать. Для этого из командной строки необходимо перейти в папку, которая содержит исходные тексты программы и вызвать qmake с параметром --project . Этим приёмом удобно воспользоваться, чтобы сгенерировать файл проекта и использовать оболочку QtCreator для работы над программой (даже для обычных программ на C++ без Qt ).
Раздел " Projects " (Проекты) содержит набор необходимых настроек для процесса компиляции и для настройки среды запуска проекта. Одной из таких настроек есть опция Shadow Build , которая позволяет включить режим при котором для промежуточных файлов, make -файлов и продуктов компиляции создаётся отдельная папка вне папки с исходным кодом проекта (настройки размещения для неё — в поле Build directory ). Это позволяет построить и хранить одновременно несколько вариантов построенного проекта для различных инструментариев. Также это сохраняет папку с исходным кодом от засорения файлами, созданными в процессе построения проекта. При выключенном Shadow build промежуточные файлы и папка с построенной программой сохраняются в папке, которая содержит файл проекта.
Конечно, созданные промежуточные файлы не являются непосредственной частью проекта. Они были сгенерированы, и будут перезаписываться при необходимости во время компиляции . Поэтому не стоит добавлять их к pro -файлу или делать любые изменения в них. Также не стоит их добавлять в систему контроля версий, если её используют при разработке.
Иногда сгенерированные файлы вместе с объектными и make -файлами бывает необходимо удалить. Это необходимо делать перед тем как заархивировать проект для сохранения, поскольку сгенерированные файлы занимают довольно много места на диске по сравнению с объёмом исходного кода. Порой могут возникать проблемы с компиляцией, когда после значительных изменений в структуре программы промежуточные файлы не были достаточно хорошо заново сгенерированы. В таких случаях возникает необходимость очистить проект. Для этого выберите в главном меню Build->Clean Project (Сборка->Очистить проект). Это позволит удалить сгенерированные файлы, кроме скомпилированного исполняемого файла и make -файлов.
Для того, чтобы очистить проект полностью, необходимо изменить некоторые настройки. Откройте раздел Projects (Проекты) и в разделе C lean Steps (Этапы очистки) нажмите кнопку Details (Подробнее) и измените параметр Make arguments (Аргументы make) с clean на distclean (рис. 12.2).

Снова очистите проект — все сгенерованные файлы, включительно с исполняемым файлом и make -файлами, будут удалены.
Мы то и дело повторяем слово "Проект". В первой лекции мы говорили, что проект - это набор связанных файлов различного типа, из которых, в конце концов, после компиляции, получается программа.
Из каких же файлов состоит проект?
Выберите команду Главного меню "Сервис -> Параметры", и в ветке "Окружение" перейдите на раздел "Файловые фильтры". Вы увидите 6 основных типов файлов, которые могут встречаться в проекте:
- Модуль Lazarus (*.pas;*.pp)
- Проект Lazarus (*.lpi)
- Форма Lazarus или Delphi (*.lfm;*.dfm)
- Пакет Lazarus (*.lpk)
- Исходный код проекта Lazarus (*.lpr)
- Иной файл Lazarus (*.inc;*.lrs;*.lpl)
Если мы перейдем в папку с нашим проектом, то увидим, что он состоит из восьми файлов:
- project1.exe (Исполняемый файл программы).
- project1.ico (Файл с "иконкой" проекта - изображением в виде лапы гепарда, которое появляется в верхнем левом углу окна программы).
- project1.lpi (Информационный файл проекта). Если вы желаете открыть данный проект в Lazarus, то запускать нужно именно этот, информационный файл.
- project1.lpr (Исходный файл проекта). Запуск этого файла также приведет к запуску Lazarus с загрузкой данного проекта.
- project1.lps (Конфигурация проекта в виде xml-кода)
- project1.res (Файл ресурсов, используемых в проекте)
- unit1.lfm (Файл формы модуля. В нем в текстовом виде отображены настройки всех компонентов, используемых в модуле. Редактировать этот файл в ручную настоятельно не рекомендуется, для редактирования этих данных нужно использовать Редактор форм).
- unit1.pas (Исходный код модуля на языке Object Pascal).
Файлы с именем project1 - это файлы всего проекта в целом, файлы с именем unit1 - это файлы модуля.
Модуль> - это отдельная единица исходного кода, выполненная в виде файла с расширением *.pas. Совокупность таких единиц составляет программу.
Когда мы создаем окно, то для него создается два файла: модуль - файл *.pas с исходным кодом, и файл *.lfm, в котором содержатся настройки используемых на форме компонентов. Текст модуля мы можем видеть в Редакторе кода. Однако модуль не всегда имеет окно, это может быть и просто текстовый файл с исходным кодом. О модулях и их разделах мы поговорим подробней в одной из следующих лекций. В нашем проекте всего один модуль , но вообще их может быть сколько угодно. И каждый модуль будет представлен этой парой файлов.
Кроме того, в папке проекта находится папка lib, в которой располагаются подключаемые к проекту данные и информация о компиляции. Если же вы изменяли проект, и сохраняли эти изменения, то появится также папка backup, в которой будут храниться резервные копии старых вариантов проекта.
Нередко программист добавляет в проект и свои типы файлов. Например, в проекте можно использовать базу данных, какой-нибудь текстовый файл или ini-файл для сохранения пользовательских настроек. Разумно располагать эти файлы также в папке с проектом.
Теперь пару советов по поводу наименования проекта и модулей. Проект следует называть так, как мы хотим, чтобы называлась наша программа . Например, проекту из первой лекции было бы уместней дать имя "Hello" вместо нейтрального "project1".
Модули же нужно называть, исходя из их значения. Всегда в проекте есть главный модуль. В наших проектах пока что было по одному окну. Модуль , созданный для этого окна, и будет главным. В учебной литературе есть множество рекомендаций, как обозначать модули, остановимся на одной из них. Давайте договоримся в будущем главный модуль называть Main (англ. main - главный), а другим модулям давать смысловые названия, например, Options, Editor и т.п. Форму этого модуля (точнее, свойство Name формы) будем называть также, но с приставкой f-, обозначающей форму. То есть, fMain , fOptions , fEditor и так далее. Закрепим этот материал на практике.
В запросе вместо имени проекта project1 укажите новое имя Hello, не забывайте, что мы договорились сохранять проекты в папки с именем по номеру лекции, и номеру проекта в ней. В нашем примере это будет
C:\Education\02-02\
Как только вы нажмете кнопку "Сохранить", выйдет запрос на сохранение главного модуля. Форму мы назвали fMain, значит, модулю дадим название просто Main. В Lazarus строчные и заглавные буквы не различаются, однако для удобочитаемости кода лучше приучиться использовать заглавные буквы, чтобы выделять названия. Например, FileEdit, SaveAll и т.п.
В свойстве Caption формы впишем слово "Приветствие" (разумеется, без кавычек), это будет более понятным заголовком для окна. Не забывайте после ввода новых значений свойств в Инспекторе объектов нажимать , чтобы изменения вступили в силу. Теперь установим на форму компонент TLabel (метку), который позволит выводить на форме текст. Компонент находится на вкладке Standard:
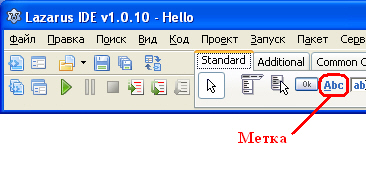
Подсказка: если подвести указатель мыши к компоненту и какое то время не нажимать кнопку, выйдет всплывающая подсказка с именем компонента.
Щелкните мышкой по метке, затем по форме, в верхней части окна. Поскольку метка у нас одна, то можно оставить ей имя (свойство Name ) по умолчанию - Label1 . А вот в свойстве Caption метки напишите:
Как вас зовут?
Ниже метки поместите компонент TEdit - редактируемое текстовое поле , в котором пользователь сможет написать что-то:

У этого компонента свойство Name также оставим по умолчанию - Edit1 . Как вы можете заметить, у этого компонента свойства Caption нет, зато появилось свойство Text - именно тут и содержится текст, отображенный в поле . По умолчанию, он совпадает с именем компонента. Просто очистим это свойство, удалив из него старый текст (не забывайте про ).
Еще ниже установим кнопку TButton. Оставим ее имя по умолчанию, а в свойстве Caption напишем
Изменим положение и размеры компонентов и самой формы так, чтобы форма приняла примерно такой вид:

Теперь запрограммируем нажатие кнопки. Щелкните по ней дважды, чтобы сгенерировалось событие, и автоматически открылся Редактор кода. В месте, где мигает курсор , впишем следующий код:
Редактор кода должен выглядеть так:
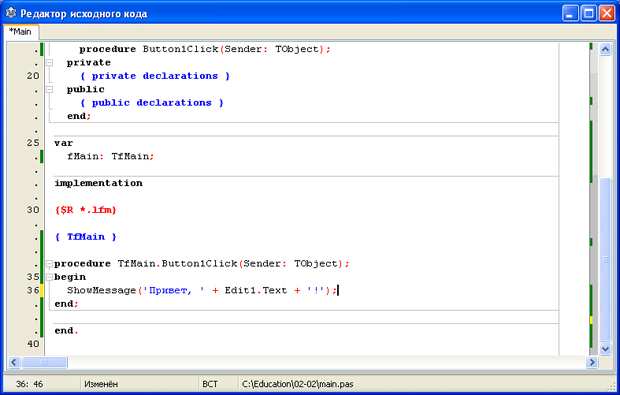
Сохраните проект и запустите его. Когда программа загрузится, впишите в окне Edit1 свое имя и нажмите кнопку "Выполнить". Вы должны получить примерно такой результат:

Вы можете сколько угодно раз менять имя в текстовом поле и снова нажимать кнопку "Выполнить", получая приветствие уже с другим текстом. У нас получилась настоящая интерактивная программа , то есть, программа , взаимодействующая с пользователем.
В дальнейших лекциях мы не будем так подробно останавливаться на том, как сохранять проект или модуль , ограничиваясь кратким
Как мы разобрались в предыдущей лекции, процесс компиляции и исполнения приложений . NET отличается от процесса исполнения традиционных ( native ) приложений. При компиляции приложения . NET на выходе получается бинарный файл , который содержит команды на языке MSIL , а не инструкции для центрального процессора. Этот факт отличает процесс функционирования приложений . NET . Фактически, приложения . NET компилируются в два этапа:

Для чего необходима подобная двухэтапная компиляция приложения? Те, кто разрабатывал на языках низкого уровня знают, что разработка программного кода имеет специфику при разработке для каждой платформы. Это означает, что разработка приложения для 32- и 64-разрядной платформы может иметь существенные различия. При этом при игнорировании особенностей разработки под конкретную платформу могут быть как некритические последствия (например, в виде снижения производительности), так и критические (например, неработоспособность приложения). В связи с этим зачастую можно видеть два типа пакетов распространения приложения (32- и 64-разрядных). Более того, для более эффективной работы приложения нередко требуется оптимизация его кода. Все эти задачи имеют непростую природу и могут отнимать у разработчика приложения много времени. Разработчик в этом случае должен тратить свое время не на улучшение логики программы, а заботиться об инфраструктурных задачах. Однако, несмотря на всю сложность этого процесса, существуют алгоритмы, которые способны выполнить большую часть работы по оптимизации кода под конкретную платформу без участия человека. Именно этой идеологии придерживается платформа . NET Framework.
При запуске кода на языке IL происходит его преобразование в машинный код. При этом весь процесс преобразования происходит в той среде, где приложение должно быть запущено (на компьютере конечного пользователя, где исполняется приложение ). Этот факт позволяет оптимизировать конечный машинный код, который получается в процессе преобразования, для той платформы, в рамках которой он будет исполняться. Также при таком подходе нет необходимости иметь две различных сборки для разных сред (32- и 64-разрядных) – конечный машинный код будет получен с учетом специфики платформы. Поскольку преобразование " MSIL – машинный код" требует определенного времени, среда исполнения записывает полученный машинный код в системных папках и при последующем запуске приложения, которое запускалось ранее, используется уже готовый код. Общий процесс компиляции выглядит следующим образом.

Механизм, который занимается преобразованием кода MSIL в машинный код, называется компилятором JIT (" just-in-time "). Этот компилятор преобразует код MSIL в машинный код "на лету". Это позволяет сделать процесс запуска приложений более "прозрачным". При запуске исполняемого файла . NET компилятор автоматически определяет, была ли эта сборка скомпилирована.
Поскольку процесс получения машинного кода является трудоемкой задачей, компилятор JIT работает " по запросу". Дело в том, что JIT - компилятор не пытается получить машинный код для всей сборки в момент запуска приложения – машинный код получается только для той части сборки, которая должна быть исполнена в данный момент. Получение машинного кода для остальных частей сборки происходит в момент запуска этих частей на исполнение .
Несмотря на то, что подобный способ позволяет более гибко подойти к разработке и распространению приложения, он обладает недостатком – для запуска приложения требуется несколько больше времени, нежели для запуска традиционного приложения. Это вытекает из того, что приложению требуется время на получение машинного кода. Этот недостаток компенсируется тем, что при запуске приложение компилируется в машинный код не полностью, а только те части, которые исполняются; также после первого запуска приложения оно будет скомпилировано и время на компиляцию больше не потребуется.
В случае, когда необходимо выполнить предкомпиляцию приложения до его запуска (для предотвращения ситуации компиляции приложения "на лету"), можно воспользоваться утилитой NGen ( native image generator ), которая поставляется в составе . NET Framework. Утилита NGen использует аналогичные методы компиляции приложения, что и компилятор JIT . Однако, от компилятора JIT эту утилиту отличает три аспекта:
- преобразование кода MSIL в машинный код производится перед выполнением приложения, а не в момент исполнения;
- преобразовываются сразу вся сборка, а не отдельные методы;
- полученный машинный код сохраняется в кэше образа машинного кода в виде файла на жестком диске.
Утилита NGen является консольным приложением и запускается из командной строки. Она позволяет сделать несколько различных действий:
- скомпилировать сборку и установить ее в кэш сборок (ключ install );
- удалить сборку из кэша сборок (ключ uninstall );
- обновить сборку в кэше сборок (ключ update );
- отобразить состояние процесса компиляции (ключ display );
- управлять очередью выполнения компиляции (ключ queue ).
Общий процесс компиляции приложений . NET представлен на следующей схеме.

Как видно, процесс компиляции приложений . NET – сложный и многогранный процесс. Однако, этот процесс придает гибкость и универсальность приложениям . NET , а встроенные механизмы оптимизации кода позволяют получить более эффективный исполняемый код .
Краткие итоги
Все приложения . NET поставляются в виде скомпилированного кода MSIL . Весь процесс компиляции приложения . NET состоит из двух этапов – преобразования исходного кода программы в код на языке MSIL и преобразование кода MSIL в машинный код. Такой процесс позволяет абстрагироваться от платформы исполнения, а также оптимизировать машинный код под конкретную платформу. Преобразование кода MSIL в машинный код происходит в момент запуска программы JIT -компилятором, а результат сохраняется в специальном кэше. Поэтому первый запуск . NET приложения может осуществляться с небольшой задержкой. Однако, этого можно избежать, если использовать утилиту NGen.

Исполняемые файлы Windows
Сам по себе полученный исполняемый файл можно описать как набор служебных данных — заголовков и полезных данных — секций . Общую структуру файла очень здорово описал хабровчанин здесь. Труд был создан еще в далеком 2015 году, но не потерял своей актуальности. Для полноты картины, которую придется изучать под микроскопом, приведу общий и сокращенный вид того самого исполняемого файла:

Представленный выше файл является шаблоном, который должны создавать компиляторы, если необходимо запускать приложение. Стоит сказать, что такую структуру в операционной системе используют все исполняемые файлы, перечислим наиболее часто встречаемые их типы:
sys — файлы драйверов
exe — файлы приложений
dll — расшариваемые библиотеки и драйвера
cpl — апплеты, которые могут использоваться для расширения функционала приложений в Windows. Для примера можно набрать WIN+R и вести control.cpl появится интерфейс для настройки системы.
Но как операционная система понимает, к какому типу файлов в итоге отнести, то что отдает пользователь или зовет приложение? Ответ очень прост, в структуре PE файла существует ряд полей, которые могут быть использованы для того чтобы определить что делать с файлом. Вот некоторые из них:
Characteristics его описание можно найти тут
Subsystem , его описание так же можно обнаружить по ссылке выше
Так как файл PE — это бинарный формат, поэтому нам придется прибегнуть к использованию софта, умеющего его разбирать. Для скрина будем использовать Explorer Suite.



В современном мире все подобные подходы реализуются так называемыми протекторами и некоторыми пакерами. Попробуем реализовать такой обфускатор и поищем возможные варианты запаковывания результирующего файла.
Способы защиты приложений
Для защиты алгоритма приложений можно разделить на несколько подходов, причем каждый из них можно развивать до совершенства. Различают несколько видов защиты:
запутывание кода путем изменения имен функций — понять алгоритм из чтения такого исходника проблематично, но возможно
запутывание кода путем добавления мусорных конструкций. Добавленные конструкции занимают процессорное время, но никак не влияют на конечный результат
запутывание алгоритма бесконечными безусловными и условными прыжками - серьезно запутывает задачу отладки
У этих подходов есть общий термин — обфускация.
шифрование частей исполняемого файла или самых важных с точки зрения алгоритма частей приложения
упаковка частей исполняемого файла или самых важных с точки зрения алгоритма частей
Отличие последних двух пунктов заключается в том, что при шифровании основная задача не дать прочесть зашифрованные данные и без знания ключа алгоритма ничего нельзя выполнить, а в случае упаковки основная задача алгоритма уменьшение размера данных.
Эти подходы можно объединить. Попробуем создать приложение, которое позволит использовать хотя бы один способ зашиты — переименование методов.
Mono.cecil
Для использования библиотеки можно загрузить NuGet пакет, для этого достаточно прописать Mono.Cecil в поиске и установить пакет для использования в проекте.
Для преобразований будем использовать простую программу:
Приложение для выполнения обфускации может выглядеть так:
Смотрим, что получилось через dnspy: слева исходный вид, справа пропатченная версия:

Приложения, как и ожидалось, работают одинаково, однако стоит упомянуть, что для корректного запуска такого приложения лучше пользоваться Release версией, там нет отладочных вставок, которые могут аварийно завершать исправленный файл.
Исправление названий коснулось только функций, которые были созданы программистом, при желании можно включить и стандартные имена. Продолжить изменение можно переключившись на названия переменных. Таким образом можно минимально усложнить восстановление алгоритма приложения.
Читайте также: