
Мониторинг доступности сервера 1с
На нашем сайте профессионалы делятся своим опытом и разработками. Вы получаете доступ к уникальному и самому полному хранилищу материалов для 1С, состоящему из более 30 000 отчетов, обработок, видео и т.д.
Рейтинг: 150
Изначально хотел написать серьезную статью о том как искал способ решения, как пробовал варианты и т.д.
Но пришел к тому что это будет не интересно.
Поэтому просто опишу кейс.
- Мониторить что служба 1С запущена и работает (не просто что rphost крутится, а именно работает)
- Мониторить количество сеансов
- Мониторить количество компьютеров/пользователей
- Мониторить уснувшие/зависшие сеансы
Решение:
1 этап - собственно получаем нужные нам данные.
Создаем регламентное задание в любой информационной базе.
Если все находятся на поддержке, то можно создать пустую или добавить регламентное задание в расширение.
Регламентное запускаем раз в минуту.
Я настроил чтобы во время обслуживания базы - регламентное не запускалось и не мешало обновлению или выгрузке
В регламентном задании собираем нужные нам показатели.
Мой пример такого сбора:
2 этап - отправляем полученные данные zabbix
Из полученных данных формируем файл и отправляем его zabbix серверу через zabbix sender.
Формат строк файла: .
Пример моего кода:
Поясняю: zabbix со всеми вспомогательными файлами находится в папке "C:/zabbix/".
Если у вас другая папка, то указываем ее.
3 этап - сохраняем и анализируем полученные данные в zabbix
Тут все относительно просто для тех кто работал с zabbix.
Создаем элементы данных с именами из файла и нужные нам тригеры.
Единственный нюанс: элементы данных должны иметь тип "zabbix траппер".
Суть этого типа в том что не zabbix запрашивает данные, а данные ему отправляются через zabbix_sender.
Для простоты я прикрепил свой шаблон.
В шаблоне помимо описанных элементов еще есть:
- стандартное отслеживание состояния службы сервера 1С 8.3
- тригер на доступность службы (с 8 утра до 12 ночи)
- тригер на отсутствие ответа от 1с больше 2х минут (с 8 утра до 12 ночи)
- тригер на долгий запрос к БД (Захвачено СУБД из консоли больше 300с.) (с 8 утра до 12 ночи)
- пара элементарных графиков (сессии и активность).
Концовка
Такие решения обычно бывают индивидуальными и точки мониторинга и контроля у каждого могут быть своими.
Также способы этого контроля бывают разные.
Описанное решение вышло из моего опыта постепенного улучшения и анализа возникающих проблем.
Поэтому я не претендую на лучшее и оптимальное решение.
Это лишь мой кейс.
Но я буду рад улучшить его, если будут предложения и идеи)))
Специалист по информационным системам в компании «Камин-Софт» Алексей Федотов выступил на митапе Инфостарта, посвященном работе 1С и Linux. Алексей поделился с коллегами, как контролировать работу 1С на Linux с помощью Zabbix.
История проекта
Попробую рассказать, как приглядывать за 1С, которая работает на Linux.

Картинка – аллегория на то, с чего все начиналось:
Проект мониторинга начался в 2014 году, когда меня пригласили разворачивать площадку на базе технологии 1С:Фреш. Мы тогда поднимали гибридную площадку, где присутствовали сервера как на Windows, так и на Linux – из-за того, что на тот момент агент сервиса 1С:Фреш не работал на Linux.
Таким образом была поднята площадка, но, поскольку я был привлеченным со стороны специалистом, в мои задачи не входило ее сопровождение – я должен был только развернуть и настроить компоненты системы.
Но я понимал, что работу этих компонентов нужно мониторить. При этом я не понимал, какие метрики вытаскивать.
Но на тот момент работы были завершены, и с развитием проекта мониторинга 1С на Linux возникла пауза.
Второй этап развития проекта мониторинга. Преимущества решения

Возврат к теме мониторинга произошел в 2018 году. Я начал с того, что провел обзор: какие свободно распространяемые готовые инструменты мониторинга есть.
Но, поскольку я ничем не впечатлился, было решено продолжить начинание 2014 года «с чистого листа».
Чем отличается проект, который я затеял, от найденных аналогов? На слайде вы видите основные вехи.
Первое – он свободно распространяется. Его можно брать и использовать, допиливая как вам угодно.
Проект – кроссплатформенный, можно использовать для мониторинга серверов 1С на Linux и Windows.
Получение данных минимальным набором «инструментов» сводится к тому, что не хотелось изначально ставить дополнительные инструменты, добавлять точки входа в 1С – хотелось обойтись тем, что установлено на сервере 1С из коробки.
При этом минимальный уровень участия пользователя в настройках мониторинга. Пользователь, проставив необходимые шаблоны в Zabbix и скрипты на сервер 1С, и назначив роли на узлы наблюдения, получит данные, не вникая в тонкости.
Исключение необходимости сбора больших объемов технологического журнала для расследования возникающих инцидентов, так как по методикам и по статьям, которые имеются в общем доступе, рассказывают о том, как собирают большие объемы технологического журнала, запихивают его в разные базы или просто скриптами анализируют за длительное время. А тут хотелось инструмента, который будет сохранять только тот объем технологического журнала, который необходим для расследования.
И еще один момент – это модульный принцип. Изначально, когда это делалось в 2014 году, сбор всех метрик был реализован в одном скрипте, который пытался выгребать данные из RAS. Вернувшись в эту тему в 2018 году, я немного переосмыслил этот процесс и принял решение разбить какие-то вещи по функциональности. Те, кто читали мои статьи на Инфостарте, могли заметить, что в названии скриптов присутствовали названия процессов сервера 1С:Предприятия. Сейчас опять произошло переосмысление, и скрипты поменяли свое название на роли серверов.
Давайте посмотрим, что предоставляют эти модули, какие метрики можно собирать с из помощью.
Модуль Сервер лицензирования (программные лицензии)
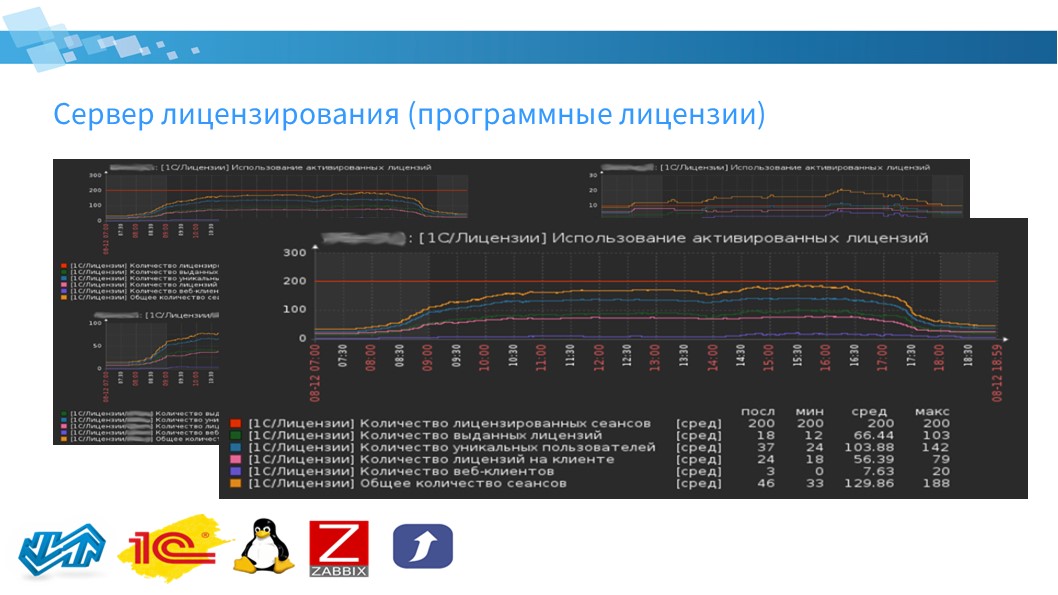
Есть модуль, который отвечает за мониторинг сервера лицензирования. Его основное назначение – сбор данных по утилизации программных пользовательских лицензий 1С, активированных на сервере лицензирования. В данном случае под сервером лицензирования понимается как выделенный сервер, так и сервис лицензирования, если он установлен на общем сервере.
На заднем плане слайда я поместил комплексный экран, который отображает утилизацию лицензий в целом по серверу лицензирования, и есть разбивка по кластерам. Если сервер лицензирования у вас участвует в нескольких кластерах, вы можете получать данные в разрезе кластеров по утилизации лицензий.
общее количество сеансов;
количество лицензированных сеансов – на сколько сеансов у вас установлено лицензий;
количество выданных лицензий – сколько из этих установленных лицензий выдано сервером;
количество уникальных пользователей;
количество лицензий на клиенте – это те лицензии, которые клиентское приложение получило у себя локально;
и количество веб-клиентов.
Модуль Рабочий сервер
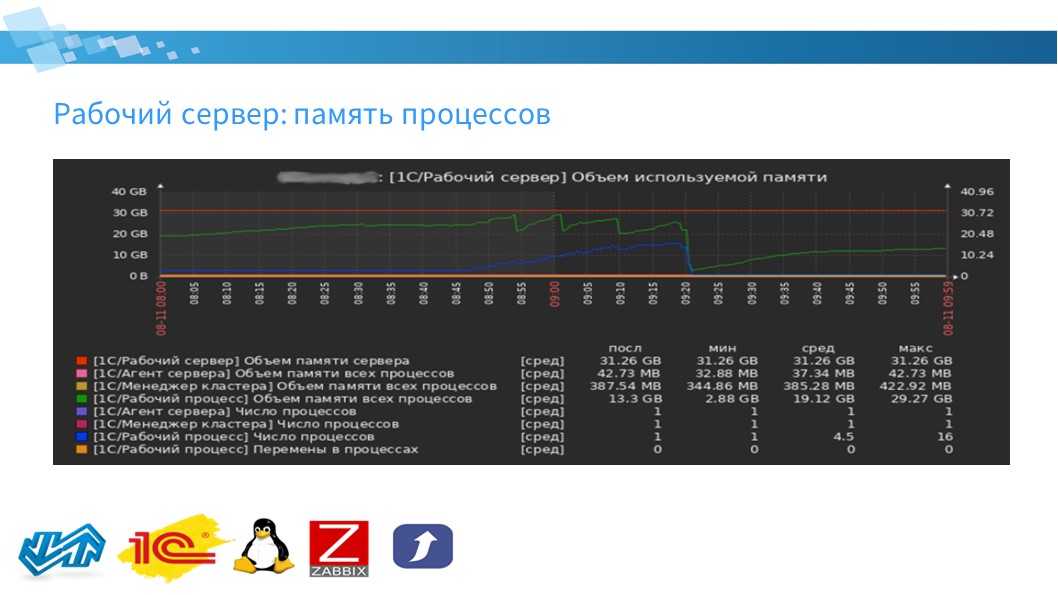
Следующий модуль – модуль рабочего сервера.
Здесь есть показатели:
по количеству процессов сервера:
для Агента сервера (ragent);
для Менеджера кластера (rmngr);
для Рабочего процесса (rphost);
и общее число процессов.
по суммарному объему занимаемой ими памяти:
для Агента сервера;
для Менеджера кластера;
для Рабочего процесса;
и общий объем памяти сервера.
также фиксируется количество перемен в рабочих процессах, что позволяет Zabbix фиксировать частые перезапуски рабочих процессов.
На слайде я привел график с реального боевого сервера – здесь можно увидеть рост количества рабочих процессов. Произошел инцидент, и произошло увеличение рабочих процессов, сопровождающееся резким замедлением работы пользователей.
Zabbix позволяет оперативно реагировать на эти ситуации, не дожидаясь звонков пользователей – предпринимать решения до того, как пользователи начали названивать на линию поддержки.
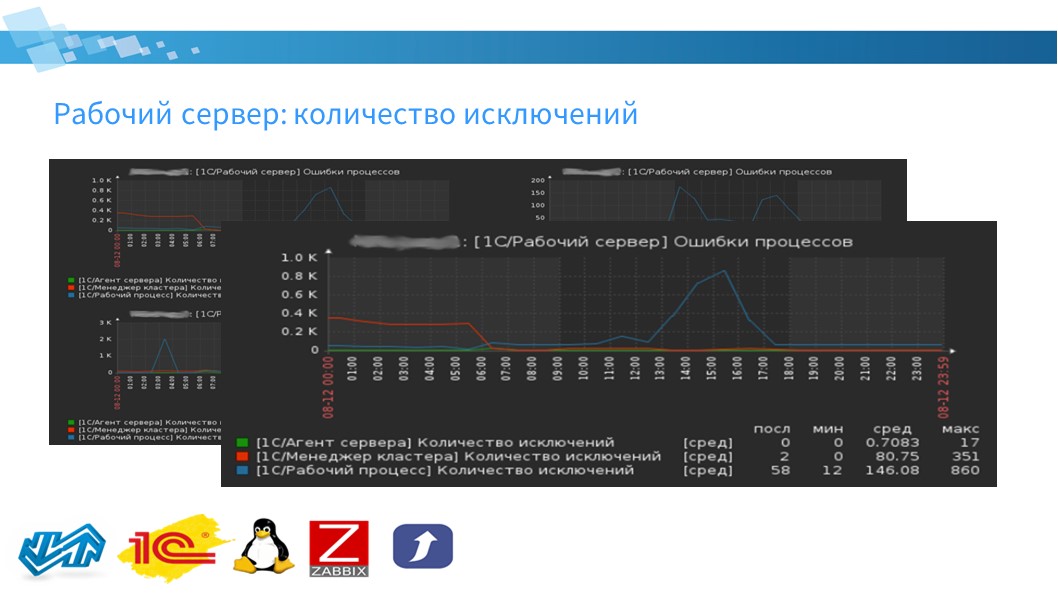
Есть показатели, которые собираются по техжурналу – это количество ошибок/исключений процессов сервера 1С.
Эти показатели собираются один раз в час – можно сделать комплексные экраны по рабочим серверам, которые будут показывать графики количества ошибок.
Здесь на картинке собран комплексный экран с нескольких серверов, который вам в динамике показывает, как меняется количество ошибок по разным процессам.
И, соответственно, можно какую-то аналитику проводить по логам – что происходило в эти моменты.
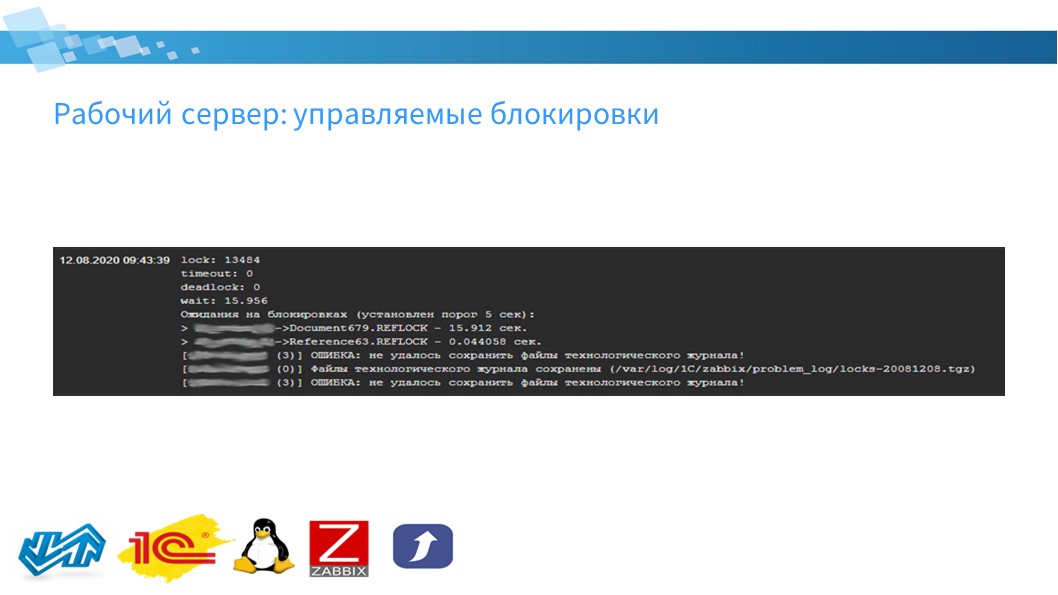
Еще один момент по рабочим серверам – мониторинг управляемых блокировок.
Анализируется технологический журнал раз в час и выдается информация о том, были ли:
ожидания на управляемых блокировках.
Если ожидания были – выдает информацию, на каких измерениях были эти ожидания, и в какой величине.
Если было превышение установленного порога ожидания на блокировках, либо если возникали таймауты, взаимоблокировки – техжурнал сохраняется в каталог. Вы можете видеть, что на сервере файлы технологического журнала сохранены в такой-то каталог.
Причем, файлы технологического журнала сохраняются на всех серверах, входящих в кластер – были ситуации, когда виновник блокировки оказывается не на том сервере, где произошла ошибка. Например, если возник таймаут. В данном случае, функциональность позволяет сохранять технологический журнал по всем рабочим серверам кластера.
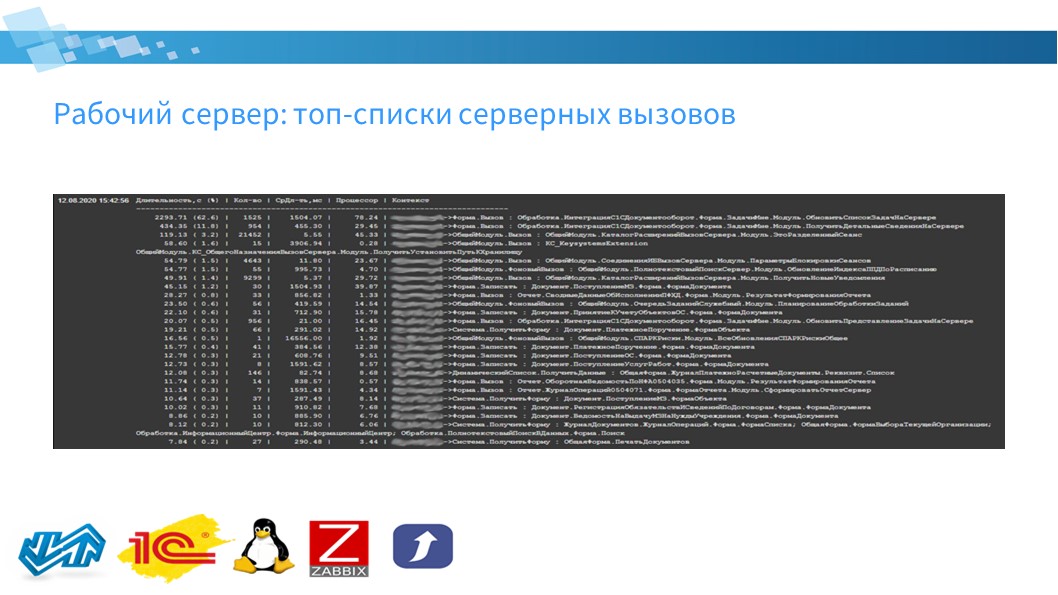
Так же собираются топ-списки серверных вызовов – анализируется технологический журнал за час.
Длину топ-списков можно настроить: по умолчанию – 25. И сохранить информацию о самых затратных серверных вызовах в Zabbix:
на слайде приведен топ по суммарной длительности вызовов;
есть топ по суммарному процессорному времени;
топ максимальной памяти за вызов;
топ «ленивых» вызовов, у которых процессорное время сильно меньше времени вызова;
топ по средней длительности.
На слайде видно, что есть сама суммарная длительность и процентное соотношение – сколько времени от общего количества суммарного времени вызовов по этому серверу и по этой базе этот вызов занимал.
Модуль Центральный сервер
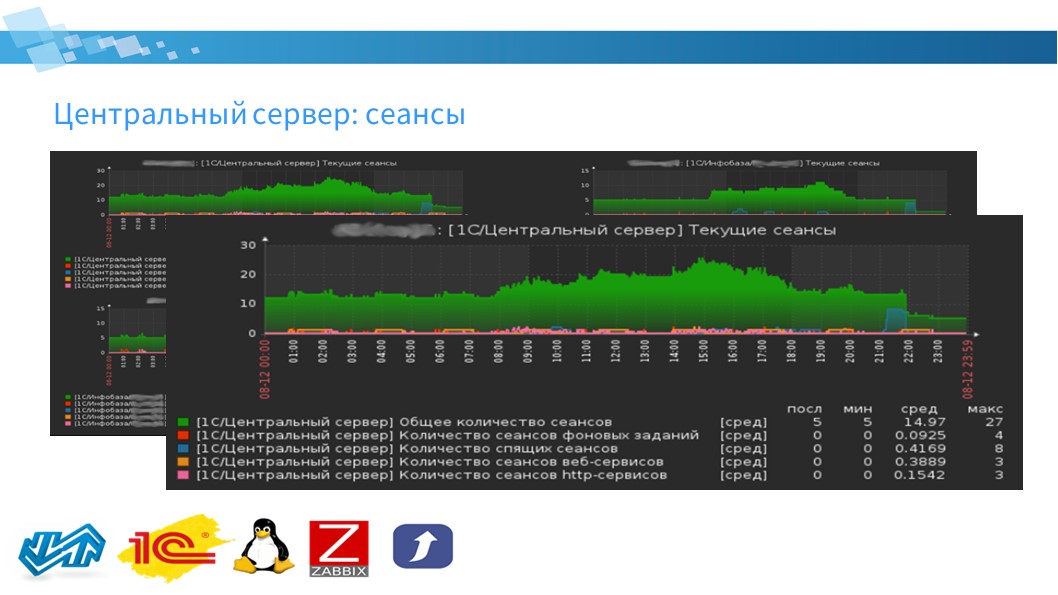
Следующий модуль – центральный сервер. На нем можно мониторить сеансы.
Чем сеансы они отличаются от лицензий? Немного разные контексты.
В сеансах мы можем увидеть:
общее количество сеансов;
количество сеансов фоновых заданий;
количество спящих сеансов;
Zabbix позволяет собирать эту информацию как в контексте кластеров, так и в контексте информационных баз.
Можно собрать комплексный экран, на котором отобразить информацию по центральному серверу в целом и по информационным базам, если у вас несколько информационных баз в кластере. Или, если у вас несколько кластеров управляемых центральным сервером, можно включить автоматическое обнаружение кластеров и получать аналогичную информацию в данном разрезе.
Это – то, что касается модулей, на которые разделена функциональность решения.
Планы по развитию

Всю информацию по планам на дальнейшее развитие я стараюсь выкладывать в задачах на GitHub.
Основные моменты, на которых стоит акцент:
Развитие функциональности в части автоматизации процедуры развертывания на большое количество серверов.
Увеличение количества собираемых показателей, в частности, один из интересующих моментов – проверка доступности информационной базы через веб-сервис.
Список топ-исключений/ошибок, возникающих в рабочих процессах. Чтобы, посмотрев на графике количества ошибок, которые у вас в процессах возникают, можно было параллельно бегло посмотреть, что за это ошибки.
Исправление выявленных ошибок, которые находятся в процессе эксплуатации.
Оптимизация самих скриптов, которые получают данные, чтобы сократить время их работы и уменьшить нагрузку на прикладные серверы 1С. Те, кто сталкивался с системами мониторинга, знают об «эффекте наблюдателя», когда у вас инструмент, собирающий данные на наблюдаемом объекте, отъедает значительную долю производительности вашего прикладного сервера, чего не очень хотелось бы.
Это был краткий рассказ о том, что я хотел представить вашему вниманию, обозначив то, что умеет этот инструмент. Подробнее с ним можно ознакомиться на GitHub.
Вопросы
Скрипты написаны на bash. Это был сознательный выбор. И некоторые моменты – платформозависимые. Сбор данных по оперативной памяти и по количеству процессов выполняется на основе данных операционной системы. Не на основе данных, которые возвращает RAS. Моей целью было – отойти от RAS, как от основного источника данных. Не могу сказать, что скрипты сложные. Можно на GitHub их посмотреть и допилить под свои нужды.
Мониторятся ли каким-то образом аппаратные лицензии и есть ли какой-то гибридный мониторинг аппаратных и программных лицензий 1С?
В данном контексте – нет. Аппаратный мониторинг же завязан на сервер лицензирования HASP Licence Manager. Здесь именно мониторинг процессов 1С:Предприятия – то, что можно получить из 1С:Предприятия. История аппаратных лицензий пребывает в стороне. Там получается отдельный инструмент лицензирования. Поэтому данной функциональности нет в контексте этого шаблона.
Еще вопрос про разбор технологического журнала в продакте. Если работает большое число пользователей, технологический журнал при настройке определенных событий будет занимать достаточно много места – там будет много строк. Какая скорость обработки техжурнала – если собирать данные по тем же блокировкам и таймаутам, например.
В тех проектах, которые у нас есть, где в базе работают 500-600 пользователей, технологический журнал по блокировкам, по серверным вызовам за час анализируется меньше 3 секунд, которые выделяет на таймаут стандартный Zabbix-агент . Хотя бывают ситуации, когда скрипт не успевает отработать за три секунды. Здесь решением может быть либо увеличение таймаута Zabbix-агента, либо переход на другой метод сбора (zabbix trapper). Это у нас уже будет не сервер Zabbix опрашивать сервер 1С, а сервер приложений 1С выполнять анализ технологического журнала и отправлять результаты Zabbix-серверу. На тех проектах, на которых у нас внедрен данный инструмент, там анализ ТЖ успевает отрабатывать за отведенный интервал времени. Может быть, на более крупных проектах, где в одной базе работает большее количество пользователей, больше нагрузка, там могут быть с этим какие-то трудности, и тогда придется немного перестраивать схему сбора данных.
Можно ли как-то настроить систему предупреждений, если большое количество ошибок идут в контексте одной формы или с одной строчки кода?
Сейчас настраивается по количеству ошибок на процесс. Есть пороговое значение количества ошибок на один процесс. Мы задали порог – 100 ошибок на процесс. И если этот порог будет превышен, он сигнализирует, что количество ошибок слишком велико, чтобы заглянуть в Zabbix или в технологический журнал, посмотреть, что это за ошибки. Такой гибкой настройки, чтобы конкретно контекст разбирать – такого нет. И, мне кажется, это не требуется на наших проектах так, чтобы привязываться к конкретному контексту. Если такая нужда будет, я думаю, что это вполне легко реализуемо.
Просто это часто встречаемая ситуация, когда какое-то фоновое задание падает вследствие вызова регламентного задания. И ошибки с этого задания начинают копиться, но ты о них не узнаешь, пока не заглянешь в журнал регистрации или в тех. журнал или пользователи не скажут об этом. Если это можно будет гибко настроить в скриптах – будет замечательно.
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "1С и Linux". Больше статей можно прочитать здесь.
Изначально хотел написать серьезную статью о том как искал способ решения, как пробовал варианты и т.д.
Но пришел к тому что это будет не интересно.
Поэтому просто опишу кейс.
- Мониторить что служба 1С запущена и работает (не просто что rphost крутится, а именно работает)
- Мониторить количество сеансов
- Мониторить количество компьютеров/пользователей
- Мониторить уснувшие/зависшие сеансы
Решение:
1 этап - собственно получаем нужные нам данные.
Создаем регламентное задание в любой информационной базе.
Если все находятся на поддержке, то можно создать пустую или добавить регламентное задание в расширение.
Регламентное запускаем раз в минуту.
Я настроил чтобы во время обслуживания базы - регламентное не запускалось и не мешало обновлению или выгрузке
В регламентном задании собираем нужные нам показатели.
Мой пример такого сбора:
2 этап - отправляем полученные данные zabbix
Из полученных данных формируем файл и отправляем его zabbix серверу через zabbix sender.
Формат строк файла: .
Пример моего кода:
Поясняю: zabbix со всеми вспомогательными файлами находится в папке "C:/zabbix/".
Если у вас другая папка, то указываем ее.
3 этап - сохраняем и анализируем полученные данные в zabbix
Тут все относительно просто для тех кто работал с zabbix.
Создаем элементы данных с именами из файла и нужные нам тригеры.
Единственный нюанс: элементы данных должны иметь тип "zabbix траппер".
Суть этого типа в том что не zabbix запрашивает данные, а данные ему отправляются через zabbix_sender.
Для простоты я прикрепил свой шаблон.
В шаблоне помимо описанных элементов еще есть:
- стандартное отслеживание состояния службы сервера 1С 8.3
- тригер на доступность службы (с 8 утра до 12 ночи)
- тригер на отсутствие ответа от 1с больше 2х минут (с 8 утра до 12 ночи)
- тригер на долгий запрос к БД (Захвачено СУБД из консоли больше 300с.) (с 8 утра до 12 ночи)
- пара элементарных графиков (сессии и активность).
Концовка
Такие решения обычно бывают индивидуальными и точки мониторинга и контроля у каждого могут быть своими.
Также способы этого контроля бывают разные.
Описанное решение вышло из моего опыта постепенного улучшения и анализа возникающих проблем.
Поэтому я не претендую на лучшее и оптимальное решение.
Это лишь мой кейс.
Но я буду рад улучшить его, если будут предложения и идеи)))
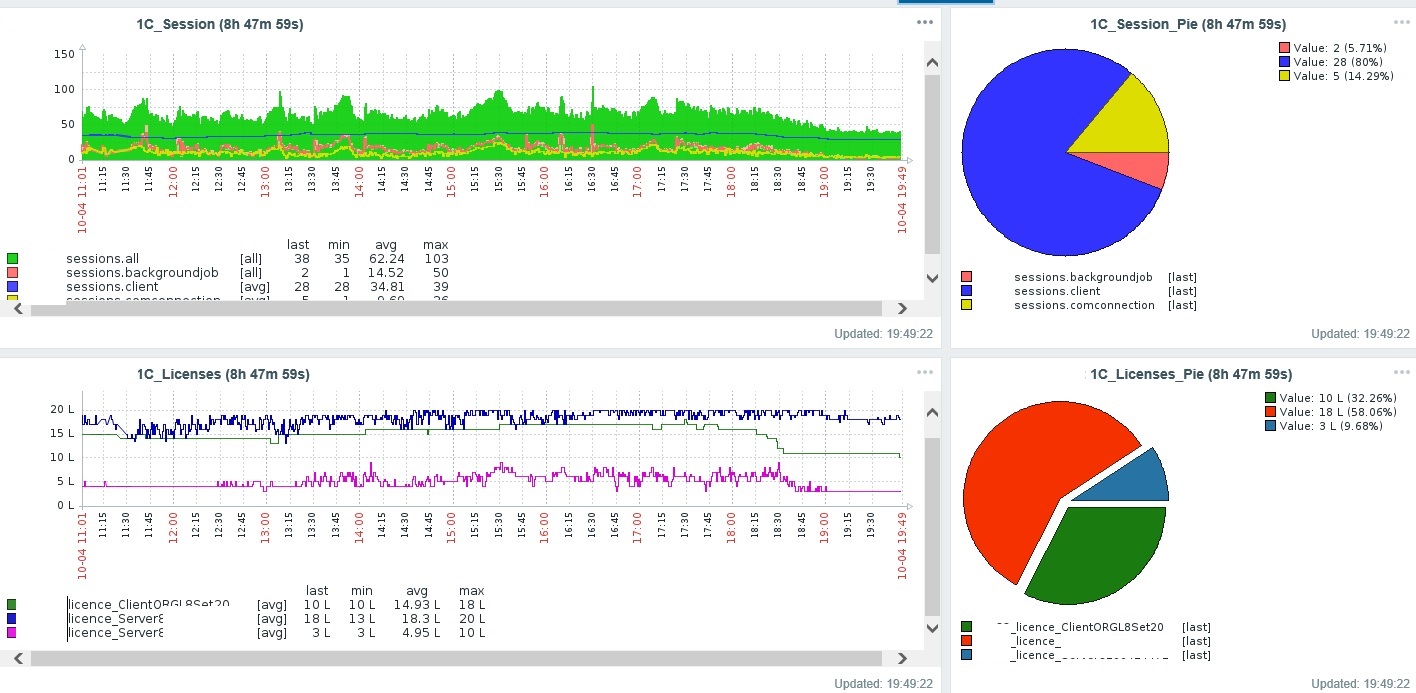
- показатели количества сессий 1С: все сессии, только клиентские сессии, только jobs, только com connections.
- показатели количества использованных лицензий, в разрезе каждой лицензии. Зачем: у нас ограниченное количество лицензий и проходиться контролировать количество входящих com connections. Мониторинг показателей с Apllication сервера 1С лучше вешать на отдельную БД, что-то типа MonitoringDB, в ней надо создать пользователя Zabbix, у которого будет указано Windows аутентификация типа \\Net_NT\ServerOneS$ .
- показатели очередей импорта/экспорта объектов. Зачем: наши системы 1С получают в день от 500 тысяч до 1 млн. событий извне и порой в очередях 1С может скапливаться десятки тысяч событий, соответственно срабатывание Trigger'a на определенном пороге для нас сигнал, что возникла проблема.
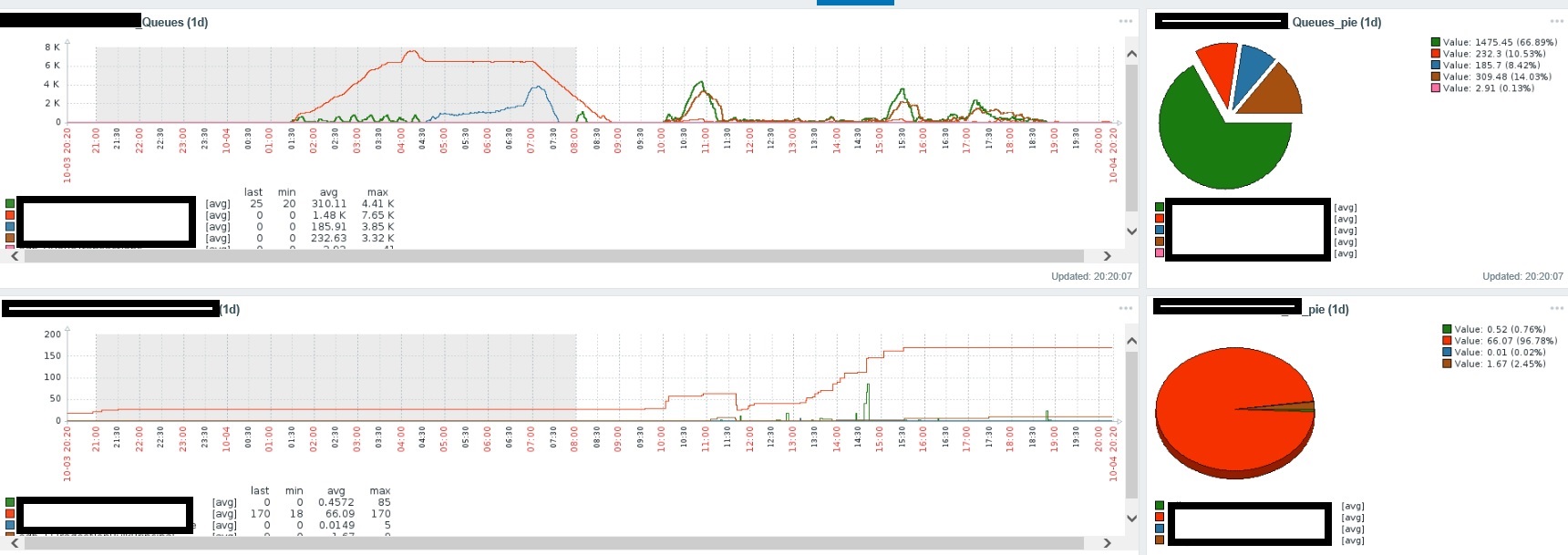
- показатели работы Apllication и sql серверов, которые собираются с помощью типовых шаблонов самого Zabbix.

Как настроить сбор данных через REST интерфейс:
2. На стороне Zabbix настраиваем нужное количество Items и необходимые Triggers.
Примеры кода 1С приложены в обработке к статье, код протестирован на платформе 1С 8.3.10.2669.
Шаг 2. Создание Items в Zabbix.
Заходим в Configuration - All hosts - Host - Item - Create Item.
Самое главное корректно заполнить поле Key с помощью шаблона Поиск строки на веб-странице: web.page.regexp[хост,,,,,] .
В моем примере в поле Key надо положить строку: web.page.regexp[serverOneS,"MonitoringDB/hs/1CMonitoring/GetLicensesData/serverOneS/licenceClientORGL8Set20",80,"licence_ClientORGL8Set20:(9+)",,\1]
Разберем формат строки:
- хост - serverOneS - сервер 1С, на котором поднят IIS;
- путь - MonitoringDB/hs/1CMonitoring/GetLicensesData- путь к http сервису + serverOneS/licenceClientORGL8Set20- параметры передаваемые в http сервис.
- регулярное выражение - "licence_ClientORGL8Set20:(8+)" - шаблон строки, который разбирается Zabbix. В скобках указан шаблон извлечения числа и если Zabbix сможет эту часть преобразовать в число, то это и будет value для Item.
- вывод - по этому параметру, к сожалению, не нашел внятного описания, поэтому поставил аналогично примерам найденным на форумах.
Остальные параметры Item заполняем аналогично скриншоту ниже:

Проверяем в Latest Data, что Zabbix собирает данные.
В та ком случае, надо проверить через отладчик, что Zabbix цепляет http сервис и возвращает ему правильную строку. Если все-таки отладчик покажет, что строка возврата верная, то скорее всего запрос внутри 1С отрабатывает, более 20 секунд и этом случае Zabbix считает, что ответа нет и выдает ошибку " Value "" of type "string" is not suitable for value type "Numeric (unsigned)" ".
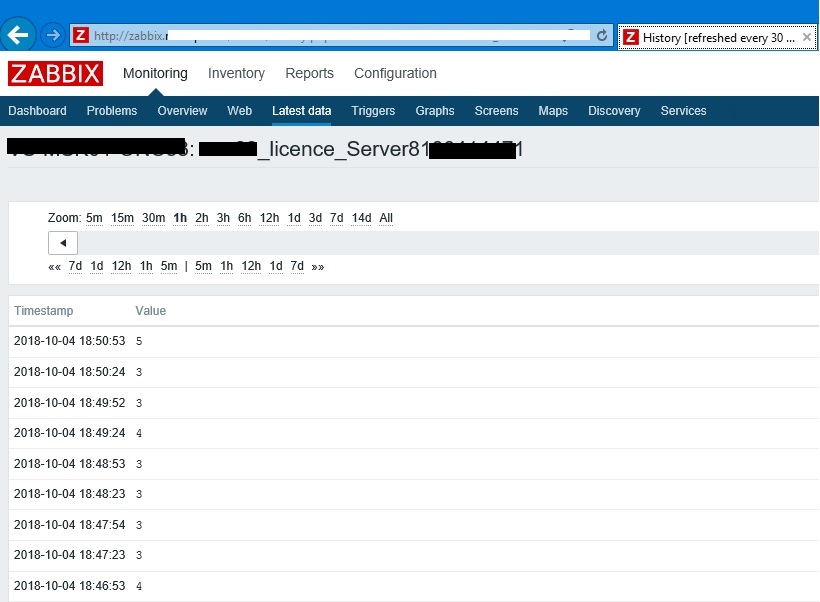
Сбор данных по определенным показателям через Zabbix sender:
- На стороне Zabbix настроить Item с типом Zabbix trapper.
- На стороне 1С необходимо вставить вызов Windows команды, которая будет отравлять значение по нужному Item в Zabbix.
Для чего можно использовать именно такой способ сбора данных: с помощью регламентных заданий каждые 30 минут отрабатывает реконсиляция между 1С и сторонней системой по входящим объектам, которая показывает количество расхождений по объектам и как результат в Zabbix отравляется количество брейков.
Мы не храним внутри 1С количество брэйков, поэтому второй способ не подходит, а видеть сколько у нас брэйков на графике надо, чтобы нужный момент отчитаться бизнесу.
Шаг 1. Настройка Item с типом Zabbix trapper
Заходим в Configuration - All hosts - Host - Item - Create Item.
Необходимо заполнить поля Name и Key названием показателя. В поле Type выбрать Zabbix trapper, поле Type of information = Numeric(unsigned).
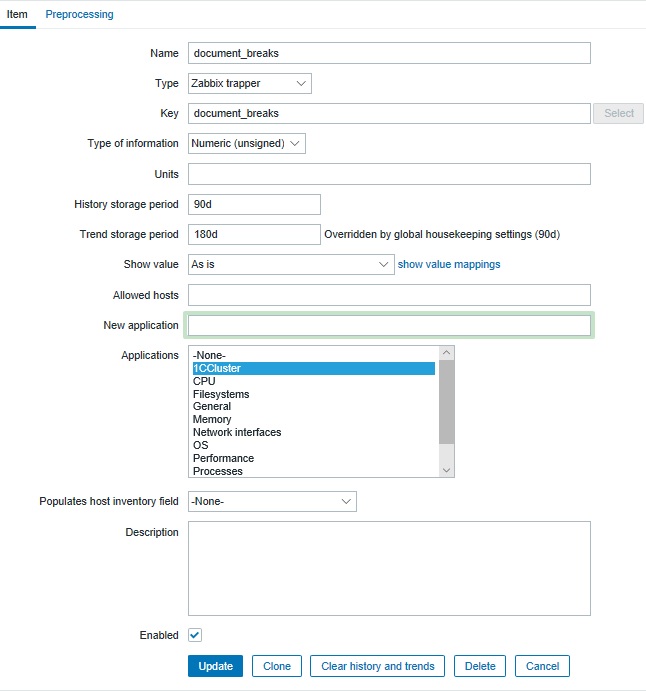
Шаг 2. Вызов Windows команды внутри регламентного задания
Добавить в конце регламентного задания подобный код:
После настройки Items и получения данных из 1С, настраиваем Graphs и Dashboards и наслаждаемся :-).
P.S. Zabbix отлично собирает данные, но возможности в настройках Dashboards у него не большие, гораздо лучше и красивее в этом плане Grafana, у которой в качестве источника можно указать Items из Zabbix'а:
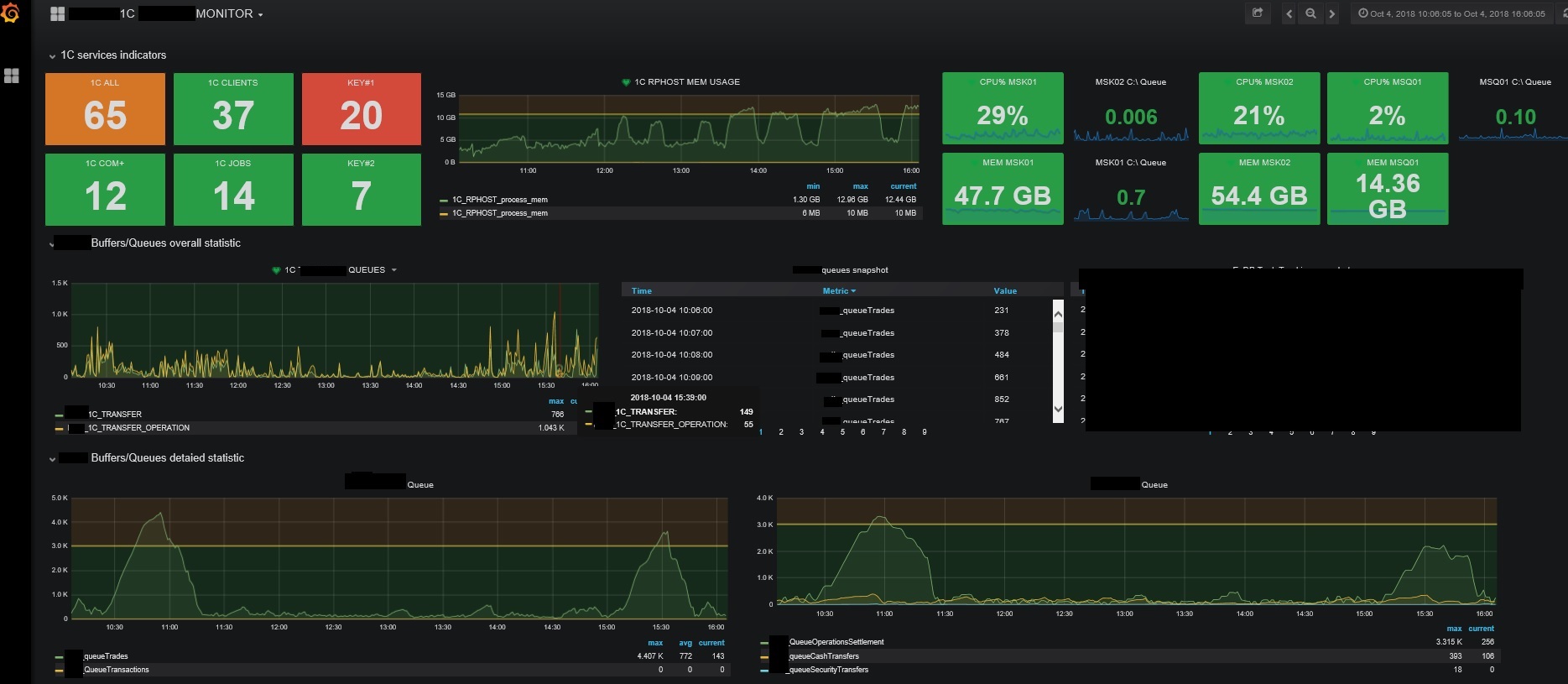
P.S.P.S. Данный способ мониторинг довольно прост, но чтобы разобраться с ним я потратил немало времени на поиск информации, поэтому статья написана, не только с целью поделиться своим опытом, но и узнать опыт коллег. Всем удачи.
Специальные предложения









(1) Если вы не знаете зачем мониторить сервер 1С, то это вам не нужно. А когда у вас 500+ пользователей в онлайне, и падает сервак за 10 мультов, то звонок от буха идет не вам, а сразу директору.
(4) Меня всегда смешили люди, которые считают себя умнее других. Вообще вопрос был не к вам, и вопрос был не в том нужно или нет. Я знаю для чего нужен Заббикс и т.д. я хотел подробнее познакомиться с опытом коллег. Это всегда бывает полезно сколько бы человек не работал в ИТ.
В следующий раз вообще не пишите комментарии, чем писать такое.
да смешили люди, которые считают себя умнее других. Вообще вопрос был не к вам, и вопрос был не в том нужно или нет. Я знаю для чего нужен Заббикс и т.д. я хотел подробнее познакомиться с опытом коллег. Это всегда бывает полезно сколько бы человек не работал в ИТ.
В следующий раз вообще не пишите комментарии, чем писать такое.
Честно говоря, меня тоже вводит в некоторое замешательство Ваш вопрос, но давайте я поделюсь опытом своего предприятия.
У нас тоже построены дашбоарды графаны на основании данных заббикса. Мы создали дашбоард в разрезе каждой базы куда выведены ключевые показатели производительности наших серверов (1С + MS SQL).
Общие MS SQL + 1C.
За ключевые счетчики мы посчитали: Нагрузка ЦП, Очередь ЦП, % использования РАМ, Очередь диска, время обращение к диску, нагруженность сети, наличие свободного места на диске, доступность сервера, время отклика. Если речь о СУБД, то в счетчики в разрезе всех дисков (С, tempDB, Диск с базой).
Только для 1С:
Наличие установленной блокировки входа в базу, наличие установленной блокировки для регламентных заданий в базу, текущий потребляемый объем памяти в разрезе рп хостов. Так же прикручена логика если вдруг какой то из счетчиков выйдет из зеленой зоны сразу же запуститься скрипт на powershell который выведет топ 5 пользователей в консоли отсортированных по колонке захвачено СУБД.
Только для СУБД:
Процент попадания в буферный кэш, время жизни страницы в буфере, количество латчей, статистика ожиданий. + данные регламентных заданий на СУБД, были ли они выполнено успешно.
Данные из СХД:
Счетчик загруженности операциями IO с СХД.
p.s: не обращайте внимание на отсутствие значений, сейчас в работе у нас модернизация нашего текущего железа, в связи с чем мы тестируем разные СХД от вендеров, а в графане подвязан счетчик от другого Луна.
Ниже прикладываю скрины как выглядит мой дашбоард, ну и подобный дашбоард у меня в разрезе каждой базы.
Ну а на вопрос "Конкретно на примерах из жизни что это дает в части отслеживания проблем и скорости их устранения?" я бы ответил, что это дает очень удобную визуализацию, что именно является узким горлышком в момент появлении проблемы с производительностью баз данных + отправка СМС ответственным лицам с информацией о том, что просели ключевые счетчики, подключись посмотри.
Ну и так же такой момент, что в графану мы выводим только ключевые счетчики, есть куча других счетчиков которые собирает заббикс к которым точно так же прикручены алармы. Недавно прикрутили новый alarm который отслеживает размер ldf файла, который по неизвестным мне причинам не очищался после инкриментального бэкапа, а в конечном итоге вырос до огромных размеров.
Очень долго хотел написать статью, но не хватало времени. Нигде (в том числе на Хабре) не нашёл такой простой альтернативы munin, как описанная в этой статье.

Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.

Munin
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
Выполняем команды:
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Альтернативы munin для мониторинга нескольких серверов
- количество метрик не меньше чем у munin (у него их около 30 базовых графиков и ещё около 200 плагинов в комплекте)
- возможность написания собственных плагинов на bash (у меня было два таких плагина)
- иметь небольшие требования к серверу
- возможность вывода метрик с разных серверов на одном графике без правки конфигов
- уведомления на почту, в slack и telegram
- Time Series Database более мощную чем RRDtool
- простая установка
- ничего лишнего
- бесплатно и с открытым исходным кодом
Cacti
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.

Ganglia
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
Collectd
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.

Graphite
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.

Zabbix
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.

Nagios
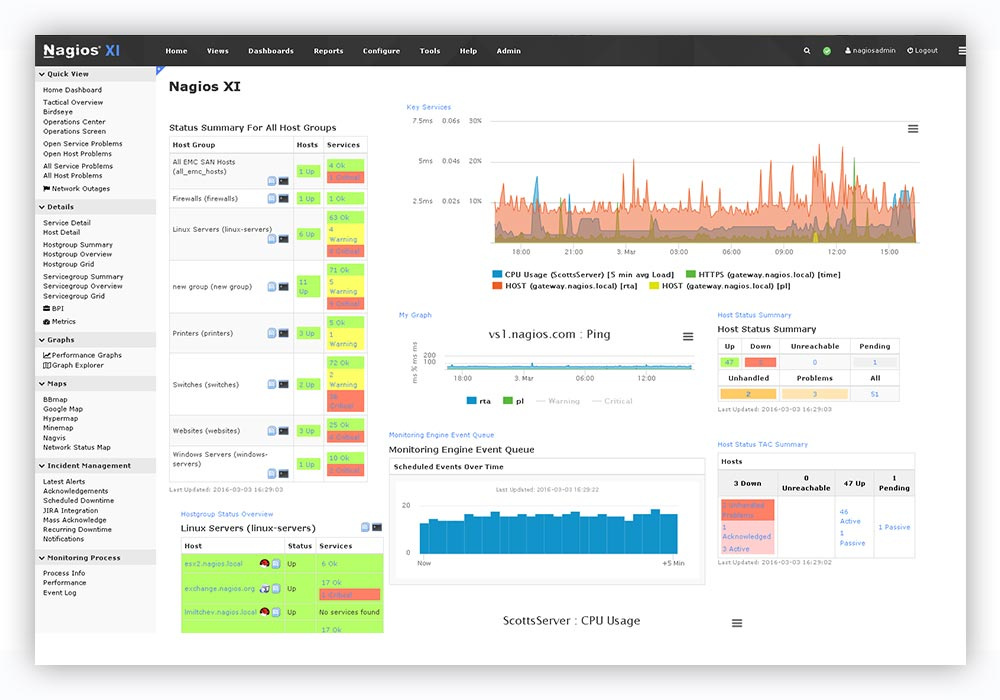
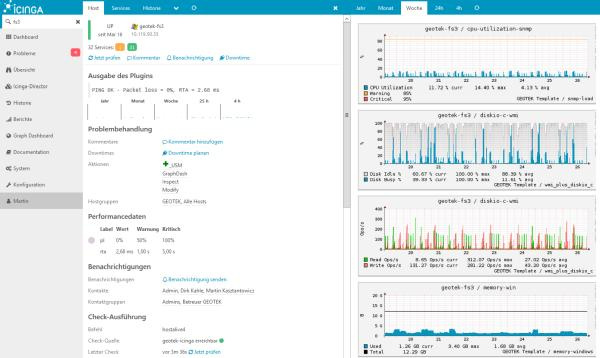
Icinga
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Небольшое отступление
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Netdata
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.

Prometheus
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.

InfluxData (TICK Stack)
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.

Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
Выбираем лучшее
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
Telegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
Акцент на безопасность
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Update: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
1) сначала посмотрел на сравнение систем мониторинга на английской википедии
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.

Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl
P.S.: если я опустил какие-то моменты в описании настройки-установки, то пишите в комментариях и я обновлю статью. Опечатки — в личку.
P.P.S.: конечно этого никто не услышит (исходя из предыдущего опыта написания статей), но я всё равно должен попробовать: не задавайте вопросы в личку на хабре, вк, фб и т.д., а пишите комментарии здесь.
P.P.P.S.: размер статьи и потраченное на неё время сильно выбились из начального «бюджета», надеюсь, что результаты этой работы будут для кого-то полезны.
Читайте также: