
Множественная регрессия в excel пример с решением
Данный способ применяется, в основном, в экономическом моделировании и прогнозировании. Его цель – пронаблюдать и выявить зависимости между двумя показателями.
Основными типами нелинейных регрессий являются:
- полиномиальные (квадратичная, кубическая);
- гиперболическая;
- степенная;
- показательная;
- логарифмическая.
Также могут применяться различные комбинации. Например, для аналитики временных рядов в банковской сфере, страховании, демографических исследованиях используют кривую Гомпцера, которая является разновидностью логарифмической регрессии.
В прогнозировании с помощью нелинейных регрессий главное выяснить коэффициент корреляции, который покажет нам есть ли тесная взаимосвязь меду двумя параметрами или нет. Как правило, если коэффициент корреляции близок к 1, значит связь есть, и прогноз будет довольно точен. Ещё одним важным элементом нелинейных регрессий является средняя относительная ошибка ( А ), если она находится в промежутке
На этом, пожалуй, теоретический блок мы закончим и перейдём к практическим вычислениям.
У нас имеется таблица продаж автомобилей за промежуток 15 лет (обозначим его X), количество шагов измерений будет аргумент n, также имеется выручка за эти периоды (обозначим её Y), нам нужно спрогнозировать какова будет выручка в дальнейшем. Построим следующую таблицу:
Для исследования нам потребуется решить уравнение (зависимости Y от X): y=ax2+bx+c+e. Это парная квадратичная регрессия. Применим в этом случае метод наименьших квадратов, для выяснения неизвестных аргументов — a, b, c. Он приведёт к системе алгебраических уравнений вида:
Для решения этой системы воспользуемся, к примеру, методом Крамера. Видим, что входящие в систему суммы являются коэффициентами при неизвестных. Для их вычисления добавим в таблицу несколько столбцов (D,E,F,G,H) и подпишем соответственно смыслу вычислений — в столбце D возведём x в квадрат, в E в куб, в F в 4 степень, в G перемножим показатели x и y, в H возведём x в квадрат и перемножим с y.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню Сервис/Надстройки .
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel , нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:

Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа , нажать кнопку Перейти и в следующем окне включить пакет анализа.
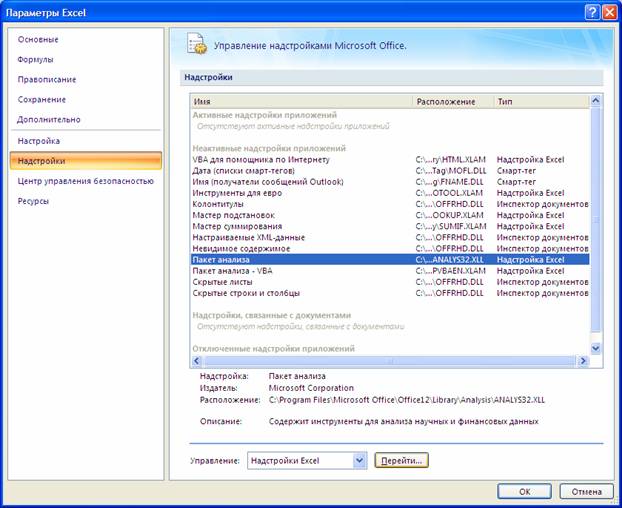
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия . (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия ) Появится диалоговое окно, которое нужно заполнить:
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R -квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения - это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R 2 = 0 (нет линейной зависимости), иначе принимается гипотеза R 2 ≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a0 , стандартной ошибки Sb0 и t -статистики tb0.
P-значение - это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП( t -статистика; n-m-1). Если P -значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% - это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2. xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Алгоритм работы
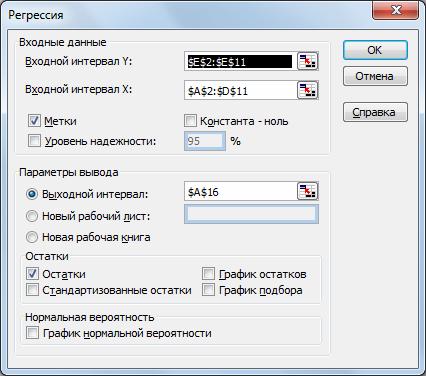
Вводим заданные значения xi и y , затем выбираем пункт меню Сервис/Анализ данных/Регрессия. Далее указываем интервалы значений xи y, включаем режим Метки, оставляем уровень надежность по умолчанию, указываем выходной интервал и включаем вывод остатков:
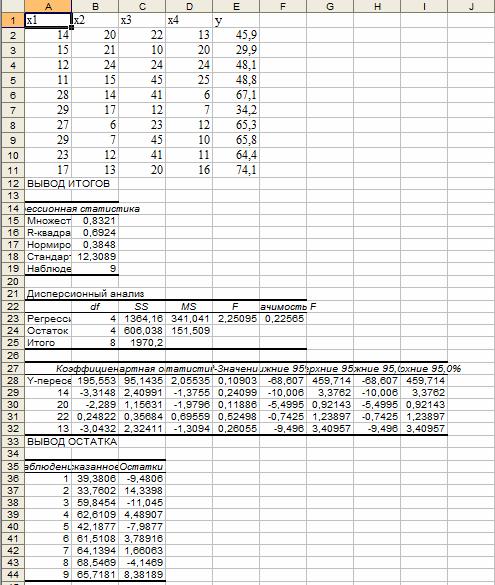
а) Коэффициенты уравнения соответствуют данным столбца Коэффициенты (следующий за столбцомY-пересечения) (блок Дисперсионный анализ).
б) Стандартная ошибка регрессии соответствует значению Стандартная ошибка блока Регрессионная статистика.
Стандартные ошибки коэффициентов соответствуют значениям столбца Стандартная ошибка блока Дисперсионный анализ.
в) Доверительные интервалы соответствуют интервалам Нижние %, Верхние %.
г) Статистическая значимость коэффициентов уравнения соответствует столбцу t -статистика. Граничная точка t(α; n-m-1) вычисляется с помощью функции СТЬЮДРАСПОБР(0,05;n-m-1) . Если i -ое значение P-значения меньше a, то i -ый коэффициент статистически значим и влияет на результативный признак.
д) Коэффициент детерминации R-квадрат в блоке Регрессионная статистика. Скорректированный (нормированный) коэффициент детерминации R2n. Это означает, что модель объясняет R2n*100% общего разброса значений результативного признака с учетом поправки на число степеней свободы.
Проверка гипотезы о статистической значимости коэффициента детерминации:
Проводим правостороннюю проверку. Граничная точка Fα;n-m-1 определяется с помощью функции FРАСПОБР(α;m;n-m-1) .
Статистика F (определяется из блока Дисперсионный анализ).
Если F> Fα;n-m-1, то гипотеза отвергается H0 и принимает гипотеза H1 на уровне значимости α%.
Этот вывод подтверждает число из столбца Значимость F, которое должно быть меньше значения a.
- Среднее значение: СРЗНАЧ(диапазон)
- Квадратическое отклонение: КВАДРОТКЛ(диапазон)
- Дисперсия: ДИСП(диапазон)
- Дисперсия для генеральной совокупности: ДИСПР(диапазон)
- Среднеквадратическое отклонение: СТАНДОТКЛОН(диапазон)
- Уравнение регрессии y = b1x1+b2x2+. bnxn+b0: ЛИНЕЙН(диапазон Y;диапазон X;1;1) .
- Выделите блок ячеек размером (n+1) столбцов и 5 строк.
Методические пояснения. 1. Для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические»), обратите внимание, что эта функция является функцией массива, поэтому ее использование подразумевает выполнение следующих шагов:
1) В свободном месте рабочего листа выделите область ячеек размером 5 строк и 2 столбца для вывода результатов;
2) В Мастере функций (категория «Статистические») выберите функцию ЛИНЕЙН .
3) Заполните поля аргументов функции:
Известные_значения_y — адреса ячеек, содержащих значения признака ;
Известные_значения_x — адреса ячеек, содержащих значения фактора ;
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
4) После того, как будут заполнены все аргументы функции, нажмите комбинацию клавиш ++ .
Результаты расчета параметров регрессионной модели будут выведены в виде следующей таблицы:
Значение коэффициента b | Значение коэффициента a |
Стандартная ошибка mb коэффициента b | Стандартная ошибка ma коэффициента a |
Коэффициент детерминации R 2 | Стандартное отклонение остатков Sост |
Значение F-статистики | Число степеней свободы, равное n-2 |
Регрессионная сумма квадратов | Остаточная сумма квадратов |
2. Табличные значения распределения Стьюдента определите с помощью функции СТЬЮДРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы — число степеней свободы, для парной линейной регрессии равно n-2, где n — число наблюдений.
3. Табличное значение распределения Фишера определите с помощью функции FРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы1 — число степеней свободы числителя, для парной регрессии равно 1 (т.к. один фактор);
Степени_свободы2 — число степеней свободы знаменателя, для парной регрессии равно n-2, где n — число наблюдений.
4. Коэффициент корреляции вычислите с помощью функции КОРРЕЛ. Аргументы функции:
Массив 1ш и Массив 2 — адреса ячеек, в которых содержатся значения величин, для которых вычисляется коэффициент корреляции.
5. Для вычисления (X T X) -1
1) Построите матрицу .
2) Постройте транспонированную к ней матрицу X T . Для построения матрицы X T необходимо воспользоваться функцией ТРАНСП (категория Ссылки и массивы).
3) матрицу X T необходимо умножить на матрицу X;
Произведение матриц вычисляется с помощью функции МУМНОЖ, аргументами которой являются перемножаемые матрицы. Перемножаемые матрицы должны удовлетворять условию соответствия размеров: матрица размера mxn может быть умножена справа на матрицу размера nxk, в результате получится матрица размера mxk.
В случае множественной регрессии с тремя факторами матрица X будет иметь размер nx4, матрица X T — размер 4xn, а их произведение X T X — размер 4x4.
Функция МУМНОЖ является функцией массива! Поэтому перед использованием функции МУМНОЖ необходимо выделить область размером mxk, в которой будет выведен результат, затем вставить функцию МУМНОЖ, указав ее аргументы. После этого в левой верхней ячейке выделенной области появится первый элемент результирующей матрицы. Для вывода всей матрицы нажмите комбинацию клавиш ++ .
4) найти обратную матрицу (X T X) -1 ;
Обратную матрицу (X T X) -1 вычислите с помощью функции МОБР . Функция МОБР также является функцией массива и ее использование аналогично функции МУМНОЖ: сначала необходимо выделить область ячеек, в которой будет получена обратная матрица, вставить функцию МОБР, затем ++ .
6. Коэффициенты множественной линейной регрессии вычисляются с помощью функции ЛИНЕЙН . Для того чтобы использовать эту функцию для вычисления параметров множественной регрессии необходимо
1) Сначала выделить на рабочем листе область размером 5x(k+1), где k — число объясняющих переменных.
2) Затем заполнить поля аргументов этой функции, которые имеют тот же смысл, что и в случае парной регрессии:
Известные_значения_y — адреса ячеек, содержащих значения признака y;
Известные_значения_x — адреса ячеек, содержащих значения всех объясняющих переменных.
Обратите внимание: выборочные значения факторов должны располагаться рядом друг с другом (в смежной области), причем предполагается, что в первом столбце (строке) содержатся значения первой объясняющей переменной, во втором столбце — второй и т.д.
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
Суть регрессионного анализа : построение математической модели и определение ее статистической надежности.
Вид множественной линейной модели регрессионного анализа: Y = b0 + b1xi1 + . + bjxij + . + bkxik + ei где ei - случайные ошибки наблюдения, независимые между собой, имеют нулевую среднюю и дисперсию s.
Назначение множественной регрессии : анализ связи между несколькими независимыми переменными и зависимой переменной.
Экономический смысл параметров множественной регрессии
Коэффициент множественной регрессии bj показывает, на какую величину в среднем изменится результативный признак Y, если переменную Xj увеличить на единицу измерения, т. е. является нормативным коэффициентом.
Матричная запись множественной линейной модели регрессионного анализа: Y = Xb + e где Y - случайный вектор - столбец размерности (n x 1) наблюдаемых значений результативного признака (y1, y2. yn);
X - матрица размерности [n x (k+1)] наблюдаемых значений аргументов;
b - вектор - столбец размерности [(k+1) x 1] неизвестных, подлежащих оценке параметров (коэффициентов регрессии) модели;
e - случайный вектор - столбец размерности (n x 1) ошибок наблюдений (остатков).
На практике рекомендуется, чтобы n превышало k не менее, чем в три раза.
- получить наилучшие оценки неизвестных параметров b0, b1. bk;
- проверить статистические гипотезы о параметрах модели;
- проверить, достаточно ли хорошо модель согласуется со статистическими данными (адекватность модели данным наблюдений).
- выбор формы связи (уравнения регрессии);
- определение параметров выбранного уравнения;
- анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
- Множественная регрессия с одной переменной
- Множественная регрессия с двумя переменными
- Множественная регрессия с тремя переменными
Пример решения нахождения модели множественной регрессии
Модель множественной регрессии вида Y = b 0 +b 1 X 1 + b 2 X 2 ;
1) Найтинеизвестные b 0 , b 1 ,b 2 можно, решим систему трехлинейных уравнений с тремя неизвестными b 0 ,b 1 ,b 2 :
Для решения системы можете воспользоваться решение системы методом Крамера
2) Или использовав формулы
Для этого строим таблицу вида:
| Y | x 1 | x 2 | (y-y ср ) 2 | (x 1 -x 1ср ) 2 | (x 2 -x 2ср ) 2 | (y-y ср )(x 1 -x 1ср ) | (y-y ср )(x 2 -x 2ср ) | (x 1 -x 1ср )(x 2 -x 2ср ) |
Выборочные дисперсии эмпирических коэффициентов множественной регрессии можно определить следующим образом:
Здесь z' jj - j-тый диагональный элемент матрицы Z -1 =(X T X) -1 .
где m - количество объясняющихпеременных модели.
В частности, для уравнения множественной регрессии Y = b 0 + b 1 X 1 + b 2 X 2 с двумя объясняющими переменными используются следующие формулы:
или
.
Здесьr 12 - выборочный коэффициент корреляции между объясняющимипеременными X 1 и X 2 ; Sb j - стандартная ошибкакоэффициента регрессии; S - стандартная ошибка множественной регрессии (несмещенная оценка).
По аналогии с парной регрессией после определения точечных оценокb j коэффициентов β j (j=1,2,…,m) теоретического уравнения множественной регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов.
Доверительный интервал, накрывающий с надежностью (1- α ) неизвестное значение параметра β j, определяется как
Матричный способ решения
Множественная регрессия в Excel
Чтобы найти параметры множественной регресии средствами Excel, используется функция ЛИНЕЙН(Y;X;0;1),
где Y - массив для значений Y
где X - массив для значений X (указывается как единый массив для всех значений Хi)
Проверка статистической значимости коэффициентов уравнения множественной регрессии
Как и в случае множественной регрессии, статистическая значимость коэффициентовмножественной регрессии с m объясняющими переменными проверяется на основе t-статистики:
имеющей в данном случае распределение Стьюдента с числом степеней свободы v = n- m-1. При требуемом уровне значимости наблюдаемое значение t-статистики сравнивается с критической точной распределения Стьюдента.
В случае, если , то статистическая значимость соответствующего коэффициента множественной регрессии подтверждается. Это означает, что фактор Xj линейно связан с зависимой переменной Y. Если же установлен факт незначимости коэффициента bj, то рекомендуется исключить из уравнения переменную Xj. Это не приведет к существенной потере качества модели, но сделает ее более конкретной.
Проверка общего качества уравнения множественной регрессии
Для этой цели, как и в случае множественной регрессии, используется коэффициентдетерминации R 2 :
Справедливо соотношение 0Для множественной регрессии коэффициент детерминации является неубывающей функциейчисла объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R 2 , так как каждая последующая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной.
Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы, т.е. вводится так называемый скорректированный (исправленный) коэффициент детерминации:
Соотношение может быть представлено вследующем виде:
для m>1. С ростом значения m скорректированный коэффициент детерминации растет медленнее, чем обычный.Очевидно, что только при R 2 = 1. может принимать отрицательные значения.
Доказано, что увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.
Рекомендуется после проверки общего качества уравнения регрессии провести анализ его статистической значимости. Для этого используется F-статистика:
Показатели F и R2 равны или не равен нулю одновременно. Если F=0, то R 2 =0, следовательно, величина Y линейно не зависит от X1,X2,…,Xm..Расчетное значение F сравнивается с критическим Fкр. Fкр, исходя из требуемого уровня значимости α и чисел степеней свободы v1 = m и v2 = n - m - 1, определяется на основе распределения Фишера. Если F>Fкр, то R 2 статистически значим.
Проверка выполнимости предпосылок МНК множественной регрессии. Статистика Дарбина-Уотсона для множественной регрессии
Статистическая значимость коэффициентов множественной регрессии и близкое к единице значение коэффициента детерминации R 2 не гарантируют высокое качество уравнения множественной регрессии. Поэтому следующим этапом проверки качества уравнения множественной регрессии является проверка выполнимости предпосылок МНК. Причины и последствия невыполнимости этих предпосылок, методы корректировки регрессионных моделей будут рассмотрены в последующих главах. В данном параграфе рассмотрим популярную в регрессионном анализе статистику Дарбина-Уотсона.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой.
При этом проверяется некоррелированность соседних величин e i ,i=1,2,…n..
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона:
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n и количества объясняющих переменных m.
Автоматический расчет
Полностью произвести подобный расчет можно автоматически, используя популярный сервис Множественная регрессия (с оформлением в Word)
Частные коэффициенты корреляции при множественной регрессии
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции, т.е. последовательно беруться пары yx1,yx2. , x1x2, x1x3 и так далее и для каждой пары находится коэффициент корреляции
Вычисления в MS Excel. Матрицу парных коэффициентов корреляции переменных можно рассчитать, используя инструмент анализа данных Корреляция. Для этого:
1) Выполнить команду Сервис / Анализ данных / Корреляция.
2) Указать диапозон данных;
Проверка общего качества уравнения множественной регрессии
Для этой цели, как и в случае множественной регрессии, используется коэффициентдетерминации R 2 :
Справедливо соотношение 0 < =R 2 < = 1. Чем ближе этот коэффициент к единице, тем больше уравнение множественной регрессии объясняет поведение Y.
Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R 2 , так как каждая последующая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведениезависимой переменной.
Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы, т.е. вводится так называемый скорректированный (исправленный) коэффициент детерминации:
Соотношение может быть представлено в следующем виде:
для m>1. С ростом значения m скорректированный коэффициент детерминации растет медленнее, чем обычный.Очевидно, что только при R 2 = 1. может принимать отрицательные значения.
Доказано, что увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.
Рекомендуется после проверки общего качества уравнения регрессии провести анализ его статистической значимости. Для этого используется F-статистика:
Показатели F и R 2 равны или не равен нулю одновременно. Если F=0, то R 2 =0, следовательно, величина Y линейно не зависит от X 1 ,X 2 ,…,X m .Расчетное значение F сравнивается с критическим Fкр. Fкр, исходя из требуемого уровня значимости α и чисел степеней свободы v 1 = m и v 2 = n - m - 1, определяется на основе распределения Фишера. Если F > Fкр, то R 2 статистически значим.

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».





Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.

- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».



С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Важную роль при исследовании взаимосвязей между статистическими выборками кроме корреляционного и дисперсионного анализа играет регрессионный анализ. Регрессия позволяет проанализировать воздействие на какую-либо зависимую переменную одной или более независимых переменных и позволяет установить аналитическую форму (модель) этой зависимости в виде аппроксимирующего полинома.
Если рассматривается зависимость между одной зависимой переменной Y и несколькими независимыми то речь идет о множественной линейной регрессии. В этом случае уравнение регрессии имеет вид:
где a1, a2, …, an - коэффициенты при независимых переменных, которые нужно вычислить (коэффициенты регрессии), a0 –константа.
При построении регрессионной модели важнейшими моментами являются оценка ее адекватности (эффективности) и значимости, на основании которых можно судить о возможности применения в практике полученной модели.
Мерой оценки адекватности регрессионной модели является коэффициент детерминации R2 (R-квадрат), который определяет, с какой степенью точности полученное уравнение регрессии аппроксимирует исходные данные.
6. Если нужно получить график нормальной вероятности, то установить флажок График нормальной вероятности (Normal Probability Plots) .
7. В выходном диапазоне после выполнения вычислений отображаются результаты дисперсионного анализа, коэффициенты регрессии, стандартная погрешность вычисления Y, среднеквадратичные отклонения, количество наблюдений, стандартные погрешности для коэффициентов.
Значения коэффициентов регрессии размещаются в столбце Коэффициенты:
• Y- пересечение a0;
• X1 - a1;
• X1 – a2 и т.д.
В столбце Р – Значение содержится оценка достоверности отличия соответствующих коэффициентов от нуля. Если P > 0,05, то коэффициент можно считать нулевым. Это означает, что соответствующая независимая переменная практически не влияет на зависимую переменную.
Значение R – квадрат определяет, с какой степенью точности регрессионное уравнение будет аппроксимировать экспериментальные данные. Если R – квадрат > 0,95, то точность аппроксимации высокая. При 0,8< R – квадрат < 0,95 аппроксимация удовлетворительная. В случае, когда R – квадрат
Кроме инструмента Регрессия в MS Excel для получения параметров уравнения регрессии есть функция ЛИНЕЙН и функция ТЕНДЕНЦИЯ для получения значения Y в требуемых точках.
Пример 1 . Имеются статистические данные о затратах, связанных с рекламой по телевидению, с рекламой в интернет и объеме реализации продукции в рублях, приведенные в таблице.
Требуется найти регрессионные коэффициенты для независимых переменных Расходы на рекламу по телевидению и Расходы на рекламу в интернет на объем реализации продукции и построить уравнение регрессии.
Читайте также: