
Метод брандона в excel
Пусть игра задана матрицей A размерности m x n. Каждое разыгрывание игры в чистых стратегиях будет далее называться партией. Метод Брауна-Робинсон — это итеративная процедура построения последовательности пар смешанных стратегий игроков, сходящейся к решению матричной игры.
В 1-ой партии оба игрока выбирают произвольную чистую стратегию. Пусть сыграно k партий, причем выбор стратегии в каждой партии запоминается. В (k + 1)-ой партии каждый игрок выбирает ту чистую стратегию, которая максимизирует его ожидаемый выигрыш, если противник играет в соответствии с эмпирическим вероятностным распределением, сформировавшимся за k партий. Оценивается интервал для цены игры и, если он достаточно мал, процесс останавливается. Полученные при этом вероятностные распределения определяют смешанные стратегии игроков.
- Этот метод ориентирован на произвольную игру G(m×n).
- Не требует условия aij>0.
- Легко реализуем программными методами.
Недостатки метода Брауна: скорость сходимости метода быстро уменьшается с ростом размерности матрицы игры.
Рассмотрим метод на примере игры G(3×3).
| Ai \ Bj | B1 | B2 | B3 |
| A1 | 7 | 2 | 9 |
| A2 | 2 | 9 | 0 |
| A3 | 9 | 0 | 11 |
Строится следующая матрица:
| k | i | B1 | B2 | B3 | j | A1 | A2 | A3 | Vmin | Vmax | V * |
| 1 | 3 | 9 | 0 | 11 | 2 | 2 | 9 | 0 | 0 | 9 | 4.5 |
| 2 | 2 | 11 | 9 | 11 | 2 | 4 | 18 | 0 | 4.5 | 9 | 6.75 |
| 3 | 2 | 13 | 18 | 11 | 3 | 13 | 18 | 11 | 3.67 | 6 | 4.84 |
| 4 | 2 | 13 | 18 | 11 | 3 | 22 | 18 | 22 | … | … | … |
| 5 | … | … | … | … | … | … | … | … | … | … | … |
| … | … | … | … | … | … | … | … | … | … | … | … |
k – номер партии.
i – номер стратегии, выбираемой игроком A.
j – номер стратегии, выбираемой игроком В.
Bi – накопленный игроком А выигрыш за k партий, при условии, что в данной партии B выбирает стратегию Bi.
Аj – накопленный игроком В проигрыш за k партий, при условии, что в данной партии A выбирает стратегию Аj.
Vmin – нижняя оценка игры = min (накопленный выигрыш)/k.
Vmax – верхняя оценка игры = max (накопленный проигрыш)/k.
Доказано, что
V * =(Vmin+Vmix)/2, V * à V при k à ¥ и
Ni - сколько раз выбирается Аi стратегия.
Nj - сколько раз выбирается Bj стратегия.
Итерационный процесс метода Брауна-Робинсон не является, вообще говоря, монотонным. Кроме того, скорость сходимости метода быстро уменьшается с ростом размерности матрицы игры. Однако он обладает одним неоспоримым преимуществом, которое заключается в исключительной простоте программирования метода.
1 Голубев ВО Литвинова ТЕ Реализация алгоритма построения статистической модели объекта по методу Брандона Постановка задачи Статистические модели создают на основании имеющихся экспериментальных данных снятых на действующем объекте Задачу формулируют следующим образом: по данной выборке объема т е по заданному числу опытов построить модель и оценить адекватность ее реальному объекту В общем случае современный технологический процесс представляется в виде многомерного объекта блок-схема которого приведена на рис На объект действуют вектор входных параметров составляющие которого и вектор Z управления составляющие которого z z Выходные параметры =l+k X p составляют вектор выходных параметров Y Общий вид статистической модели многомерного технологического объекта можно записать в виде системы алгебраических уравнений или в векторной форме : F F p Fp ; Y FX где X Y векторы входных и выходных параметров объекта В системе параметры управления учтены как входные параметры l l z k l Построение статистической модели одномерного технологического объекта На практике часто возникает необходимость создания моделей для одномерного технологического объекта Блок-схема такого объекта представлена на рис а модель описывается уравнением 3: 3 Процесс построения статистических моделей состоит из нескольких этапов Mth Desge
2 Z Z Z k Технологический Технологический процесс процесс X X X l Y Y p а Рис Блок-схема технологических процессов б Определение тесноты связи между переменными О наличии или отсутствии связи между двумя переменными качественно можно судить по виду поля корреляции [] а количественно по величине выборочного коэффициента корреляции определяемого по формуле 4 где и средние значения: число опытов; и дисперсии Для вычисления удобно использовать: 5 Коэффициент корреляции по абсолютной величине не превышает единицы: Чем ближе абсолютное значение коэффициента к единице тем сильнее линейная связь между величинами Следует отметить что коэффициент корреляции одинаково отмечает долю случайности и криволинейность связи между х и у Зависимость х и у может быть близкой к функциональной но существенно нелинейной; коэффициент корреляции при этом будет значительно меньше единицы Объективное определение тесноты связи может быть проведено в результате совместного анализа качественной и количественной оценок Mth Desge
3 Выбор вида зависимости Для определения вида зависимости 3 следует построить эмпирическую линию регрессии рис 3 Для это весь диапазон изменения х на поле корреляции разбивается на k равных интервалов х Все точки попавшие в j-й интервал j относят к его середине j Для этого определяв частные средние j j для каждого интервала: j j 6 где j число точек в интервале j причем j j объем выборки Y Y j X н X X j X В X Рис 3 Построение эмпирической линии регрессии Затем последовательно соединяют точки j j отрезками прямой Полученная ломаная называемся эмпирической линией регрессии у по х По виду эмпирической линии регрессии можно подобрать уравнение регрессии = < На практике чаще всего используют уравнение регрессии в виде: прямой ; экспоненты e ; параболы ; полинома -й степени и другие Уравнение регрессии в общем случае может быть записано как 7 где расчетное значение функции у; j коэффициенты зависимости; х значение аргумента Mth Desge 3 j
4 Mth Desge 4 Определение параметров зависимости Задачу определения параметров уравнения регрессии 7 решают обычно с использованием метода наименьших квадратов МНК [5 7] Согласно методу наилучшими значениями параметров будут те при которых сумма квадратов отклонений расчетных величин от экспериментальных будет наименьшей т е 8 Условием минимума функции является равенство нулю ее частных производных по всем аргументам: 9 В теории метода система 9 называется нормальной системой: для нее число уравнений равно числу неизвестных Для рассматриваемой функции Ф 8 условием минимума будет После преобразований нормальная система принимает вид а Решение системы алгебраических уравнений а позволит определить значения коэффициентов для конкретного вида зависимости Полученную зависимость называют уравнением регрессии Выражения для определения коэффициентов уравнений регрессии для зависимостей часто встречающихся в практике при создании статистических моделей могут быть получены по методу наименьших квадратов путем решения системы а В случае программной реализации когда вид уравнения регрессии заранее не известен вместо метода наименьших квадратов могут быть использованы э Ф / ; ; / ; / Ф Ф Ф
5 методы условной оптимизации в частности метод штрафных функций [6] Проверка адекватности уравнения регрессии Адекватность уравнения проверяют по критерию Фишера: F / ост в где ост остаточная дисперсия определяющая разброс экспериментальных данных относительно уравнения регрессии; величину случайной ошибки в дисперсия воспроизводимости определяющая ост Значение вычисляют по формуле [7]: ост где число степеней свободы определяемое как разность количества опытных точек и числа параметров а а оцененных по этим же точкам Значение дисперсии воспроизводимости находят на стадии предварительного анализа экспериментальных данных [5] Для этого используют зависимость в 3 где число степеней свободы знаменателя Определив расчетное значение критерия Фишера по формуле сравнивают его с табличным F т Если F т больше F для выбранных уровня значимости и чисел степеней свободы и то уравнение регрессии адекватно Математическая модель в виде уравнения регрессии может быть использована для практических целей для расчета решения задач оптимизации управления и т п Если F т меньше F то уравнение неадекватно В этом случае нужно выбрать другой вид зависимости между величинами х и у и построить новую модель В случае отсутствия данных для определения воспроизводимости процесса при определении адекватности модели на практике используют оценки адекватности корреляционное отношение и среднюю относительную ошибку : э э ; 4 Mth Desge 5
6 где у э экспериментальное расчетное и среднее значения выходного параметра соответственно 337 Построение статистической модели многомерного технологического объекта Для построения модели многомерного технологического объекта рис в настоящее время существуют несколько методов Можно использовать метод множественной корреляции метод группового учета аргументов [] метод главных компонент [] метод Брандона и др Однозначно отдать предпочтение одному из методов нельзя поскольку каждый из них связан с особенностями конкретного технологического объекта В работе для построения статистической модели использован метод Брандона Сущность метода заключается в следующем Предполагается что функция F е или в более удобной форме: э э в системе является произведением функций от входных параметров т где расчетное значение -o выходного параметра; средняя величина экспериментальных значений -го выходного параметра; количество опытов в исходной выборке При использовании метода Брандона большое значение имеет порядок следования функций в уравнении 5 Чем больше влияние оказывает фактор на выходной параметр тем меньшим должен быть его порядковый номер в указанном уравнении Поэтому задача построения модели разбивается на несколько этапов Ранжирование влияющих факторов Оценить степень влияния k-го фактора на выходной параметр можно по величине частного коэффициента множественной корреляции [3]: k k / k k 5 6 D D k D kk j э 7 Mth Desge 6
7 где величина частного коэффициента корреляции учитывающая влияние k- го фактора на выходной параметр у при условии что влияние всех прочих факторов исключено; D определитель матрицы построенной из парных коэффициентов корреляции Матрица имеет вид D k определитель матрицы с вычеркнутыми первой строкой и k-м столбцом; D D kk определитель матрицы с вычеркнутыми первой и k-й строками и k-ми столбцами соответственно k / R 3 4 При переходе от парных коэффициентов корреляции к частным может существенно измениться не только величина коэффициента корреляции но и знак Порядок расположения влияющих факторов в уравнении 5 определяют в соответствии с убыванием величины частных коэффициентов корреляции Следует иметь в виду что коэффициент корреляции чисто статистический показатель и не содержит предположения что изучаемые величины находятся в причинно-следственной связи Подобные предположения должны проверяться экспериментально Выбор вида зависимости и построение статистической модели 8 3 В уравнении 5 каждая из функций принимается либо линейной либо нелинейной степенной показательной экспоненциальной и т д Прежде чем определять вид первой зависимости следует представить исходные экспериментальные значения выходного параметра в каждом опыте э в безразмерной форме у эj : э j эj / где средняя величина выходного параметра Таким образом исходными данными для поиска первой зависимости будут нормированные значения вектора выходных параметров и опытные значения первого влияющего фактора Поиск зависимости где расчетные значения осуществляется по той же методике что и при построении модели одномерного технологического объекта 4 6 Mth Desge 7
8 Выбрав зависимость определяют остаточный показатель для каждого наблюдения: / э э Предполагая что э не зависит от х а зависит от х х выбирают зависимость от второго фактора Исходные данные для поиска остаточный показатель э и опытные значения второго фактора Получив расчетную зависимость находят остаточный показатель э для каждого-наблюдения: / э э Выполнив аналогичные действия для каждого k-го влияющего фактора получают регрессионную зависимость для рассмотренного выходного параметра Порядок расположения факторов для этой зависимости определен на этапе ранжирования и отличается от порядка в общем уравнении 5 Совокупность зависимостей по каждому выходному параметру представляет собой статистическую модель многомерного технологического объекта Порядок синтеза статистической модели объекта с использованием ЭВМ Использование ЭВМ в диалоговом режиме значительно ускоряет процесс синтеза модели по методу Брандона Построение модели происходит в несколько этапов Ранжирование влияющих факторов: а определение коэффициентов парной корреляции; б построение исходной матрицы D для определения частных коэффициентов корреляции; в вычисление значений частных коэффициентов; г анализ результатов проверка причинно-следственных связей; ранжирование факторов Выбор зависимостей выходных параметров от влияющих факторов: а получение одной или нескольких гипотез о виде расчетной зависимости; б идентификация параметров каждой расчетной зависимости методом МНК и определение оценок адекватности; в анализ результатов дискриминация гипотез окончательный выбор зависимости; г проверка адекватности модели Компьютерная реализация изложенного алгоритма синтеза статистической модели объекта методом Брандона выполнена в среде Mtlb 7 4 релиз Интерфейс программы «Bdo_Alze» в порядке выполнения расчета изображен на рис 3 8 Листинг программы приведен в Приложении э Mth Desge 8
9 Программа дает возможность осуществлять контроль над ходом расчета на всех его стадиях Результаты автоматического ранжирования факторов по результатам компьютерного расчета могут быть приняты либо изменены по желанию пользователя Предусмотрена возможность исключения из рассмотрения факторов оказывающих незначимое влияние на функцию отклика решение принимается исследователем В стандартном пакете зависимостей содержится наиболее распространенных функций коэффициенты которых рассчитываются по аналитическим выражениям полученным при дифференцировании исходного выражения Пользователь имеет возможность дополнить пакет собственными функциями чем удобно пользоваться в тех случаях когда тип зависимости известен заранее а задача состоит только в определении коэффициентов уравнения регрессии В этом случае расчет выполняется с использованием оптимизационного модуля системы Mtlb предоставляющего расширенные возможности поиска решения Затраты времени на составление модели не превышают мин Рис 3 Загрузка экспериментальных данных из файла Mth Desge 9
10 Рис 4 Составление матрицы корреляционных отношений Рис 5 Расчет коэффициентов частной корреляции параметров Mth Desge
11 Рис 6 Выбор вида зависимости и расчет коэффициентов частных регрессий Рис 7 Демонстрация точности совпадения экспериментальных и расчетных значений функции Mth Desge
12 Рис 8 Вывод результатов расчета во фрейм Mth Desge
13 БИБЛИОГРАФИЧЕСКИЙ СПИСОК Ахназарова СЛ Кафаров ВВ Методы оптимизации эксперимента в химической технологии М: Высш шк с Дубров АМ Обработка статистических данных методом главных компонент М: Статистика с 3 Закгрейм АЮ Введение в моделирование химико-технологических процессов М: Химия с 4 Кафаров ВВ Методы кибернетики в химии и химической технологии М: Химия с 5 Львовский ГН Статистические методы построения эмпирических формул М: Высш шк 98 4 с 6 Пантелеев АВ Летова ТА Методы оптимизации в примерах и задачах учебное пособие М: Высшая школа 544 с 7 Стьюпер Э Брюггер У Джурс П Машинный анализ связи химической структуры и биологической активности М: Мир 98 3 с Mth Desge 3
Очень часто в инженерной практике (например, при статистическом анализе экспериментальной информации, при построении математических моделей и алгоритмизации объектов автоматизации, при оптимизации проектируемых конструкций и т.п.) требуется аналитически отобразить полученную табличную зависимость между исследуемыми зависимыми величинами.
Похожие темы научных работ по математике , автор научной работы — Поляков Б. Н.
Some features of approximation of functions of two variables in algorithm «METHOD BRANDON»
The brief description of algorithm of approximation of functions of many variables by means of multiplicate function, components which are consistently by means of a method, offered by D.B. Brandon is given. Some features are considered and the sound recommendations on application of a method of the least squares at transformation of coordinates are given.
Текст научной работы на тему «Некоторые особенности аппроксимации функций двух переменных в алгоритме «Метод Брандона»»
Некоторые особенности аппроксимации функций двух переменных в алгоритме «МЕТОД БРАНДОНА»
Очень часто в инженерной практике (например, при статистическом анализе экспериментальной информации, при построении математических моделей и алгоритмизации объектов автоматизации, при оптимизации проектируемых конструкций и т.п.) требуется аналитически отобразить полученную табличную зависимость между исследуемыми зависимыми величинами.
Существует много различных методов аппроксимации функции, заданной таблично, которые описаны достаточно обширно в специальной математической литературе. Многообразие методов аппроксимации объясняется различными требованиями к точности приближающей функции: минимум среднеквад-ратической оценки, минимум максимума модуля невязки, точное (с заданной погрешностью) совпадение в интерполирующих узлах и т. д.
Рассмотрим1 один метод аппроксимации функции, значения которой получены в результате каких-либо измерений и, следовательно, обладают некоторым разбросом, т. е. аппроксимирующая функция должна в среднем хорошо отображать данную экспериментальную зависимость. В этом случае точность аппроксимации будет считаться достаточной, если исследователя удовлетворит величина полученной среднеквад-ратической ошибки.
Пусть m — число независимых переменных. Для m > 1 аппроксимирующая функция ищется в виде:
у = fi( Xi) f2 (Х2). fm (xm
при помощи метода последовательного определения функций f, предложенного
Д. Б. Брандоном (D. B. Brandon [1]). Суть метода следующая.
Рассматривается совокупность значений зависимой переменной у и значений одной из независимых переменныхx1. Из принятого заранее класса функций выбирается такая, которая наилучшим образом — в смысле минимума среднеквадратической ошибки — приближает видимую зависимость между у и x1. Обозначив эту функцию через f1, получим вспомогательную
переменную Y1 =— сит от x1 f1( x1'
которая уже не зави-
Y1 = f 2 ( x2 ). fm (xm
На следующем этапе находится функция, приближающая видимую зависимость между У1 иx2, и т.д. Класс функций, из которых выбирается наилучшая, определяется исходя из поставленных задач, т. е. составляется из тех функций, которые соответствуют природе изучаемых зависимостей.
Следовательно, метод сводится к многократному нахождению зависимостей между двумя переменными, которые определяем методом наименьших квадратов, так как он наиболее удобен из-за простоты вычислений, хорошо аппроксимирует и усредняет разброс значений зависимой переменной. Коэффициенты приближающей функции
1 Исследование выполнено совместно с инженером-математиком Ф.М. Карлинской и кандидатом технических наук Ю.Д. Макаровым.
на /-м этапе //■ (х) должны удовлетворять условию:
ходятся из системы линейных алгебраических уравнений:
Вычисления получаются несложными, когда // линейны относительно отыскиваемых коэффициентов, которые в этом случае будут являться решениями линейной системы алгебраических уравнений. Поэтому для упрощения выкладок в вышеупомянутую совокупность функций должны входить такие, которые либо линейны относительно коэффициентов, либо путем преобразования переменных приводятся к линейным (рис. 1). Данные функции наиболее пригодны для отображения зависимостей, часто встречающихся во многих прикладных разделах теории и практики горячей прокатки, теории электропривода и автома Например, функция у = ахЬ заменой и = £пу, и = £пх приводится к линейному уравнению и = а' + Ь'у, где а' = £ па, Ь' = Ь. Коэффициенты а' и Ь' на-
где Р = £(и - а'- Ь'у)2.
Полученные коэффициенты дают минимум среднеквадратической ошибки в логарифмических координатах, но, по всей видимости, не дают минимум величины 52 в координатах 0ху. Возникает вопрос:нельзя ли каким-то образом изменить систему (4) путем введения веса в уравнение (3), чтобы ее решение давало меньшую величину среднеквадратической ошибки.
П.В. Мелентьев [2] предлагает изменить систему (4), исходя из следующих предположений.
Пусть преобразование зависимой переменной у происходит при помощи функ-
9. у=а + Ьх + сх2 + с1х3
10 .у=а + Ьх+сх2 + бхЪ + Л*4
Рис. 1. Графики и аналитические зависимости принятой совокупности функций
ции ф, т.е. предлагается переход к переменной и = фу) (замена независимых переменных, очевидно, не влияет на величину среднеквадратической ошибки). Тогда если и =ф(у 1), и2 =ф(У1 +Ду) = ф(у2), то
Ü2 - u = ф(У2) - ф(У1) И ф(y)Ду,
т. е. у2 -у1 = Ду ф(У2) ф(yi) Следовательно, Ф (У)
(У2 - У1)2 = Т^ [ф(У2) -ф(yi)]2. (6)
Из соотношения (6) следует, что величину
можно принять в качестве веса для сис-
темы (4). Но Мелентьев систему берет с весом , что либо является ошибкой, либо Ф( У)
это специально введенная величина, определенная экспериментальными исследованиями, о чем автор не упоминает.
Рассмотрим два примера аппроксимации функции при помощи метода наименьших квадратов (I), метода с весом (II)
и метода с весом-(III).
Аппроксимация известных экспериментальных данных [3] производится при помощи функции y = axb, для получения линейной системы осуществляем преобразование ф(y) = tny. Среднеквад-ратические отклонения соответственно каждому методу равны: Sj = 1,40, Sп = 0,67 и Sш = 0,52, т. е.
наилучший результат дает метод III с весом
Аппроксимирующая функция— y = aebx. Функция преобразования та же, что и в примере 1.
В этом примере метод III с весом —1— также дает
лучший результат: Sх = 1,51, S„ = 0,62 и Sш = 0,58.
Также был просчитан ряд примеров, где ни метод II, ни метод III не улучшают результат метода наименьших квадратов. Это происходит тогда, когда приближенное равенство (5) дает очень большую ошибку.
По опыту обработки многочисленных примеров имеются основания сделать вывод о том, что чаще всего оба метода II и III
дают лучшее приближение чем метод I, хотя § разница в величине S во многих случаях не- § существенна. Видимо, коэффициенты, найденные по системе линейных уравнений ^ в преобразованных координатах с весом
лучше минимизируют среднеквадрати-
ческую ошибку, приближая ее к минимальной величине в истинных координатах.
Алгоритм, реализующий метод Брандона [3], на каждом этапе при аппроксимации парной зависимости может использовать все три метода, если это требуется, и после счета исследователь сам выбирает нужную ему кривую.
Кроме того, в алгоритме в функции, где это необходимо, вводятся дополнительные параметры i и к, сдвигающие кривые по осям координат. Например, приближение производится не функцией у = axb, а функцией у = a(x + k)b - i.
На основе алгоритма были разработаны компьютерные программы для различных ЭВМ и за более чем 30-летний период исследовательской и конструкторской деятельности были просчитаны многочисленные примеры (например, см. [3]), которые показали, что метод Брандона дает вполне приемлемую точность аппроксимации.
Таким образом, при помощи рассмотренного алгоритма строится первое приближение отыскиваемой криволинейной зависимости — аппроксимирующая функция вида (1), но, используя основные положения разработанного алгоритма, можно путем многократного повторения предложенного метода получить следующие приближения, а вместе с тем и более точную аппроксимирующую функцию.
1. Brandon D.B. Developing mathematical models for computer control // Instrument Societу of America (ISA) Journal. 1959. V. 6. № 7. P. 70-73.
2. Мелентьев П.В. Приближенные вычисления. М.: Физматгиз, 1962.
3. Поляков Б.Н. Статистические методы в алгоритмах и примерах (из практики прокатного производства): Учебное пособие. СПб.: Реноме, 2007.
Особенности использовании метода Брандона в задаче построения модели. Определение величины частного коэффициента множественной корреляции. Использование параметров статистической модели для расчета абсорберов и для построения системы теплообмена.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 27.05.2012 |
| Размер файла | 221,6 K |
Соглашение об использовании материалов сайта
Просим использовать работы, опубликованные на сайте, исключительно в личных целях. Публикация материалов на других сайтах запрещена.
Данная работа (и все другие) доступна для скачивания совершенно бесплатно. Мысленно можете поблагодарить ее автора и коллектив сайта.
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Подобные документы
Анализ матрицы коэффициентов парной корреляции. Выбор факторных признаков для построения двухфакторной регрессионной модели. Оценка параметров регрессии по методу наименьших квадратов. Нахождение определителей матриц. Применение инструмента Регрессия.
контрольная работа [1,0 M], добавлен 13.01.2013
Подбор параметров линейной функции. Вычисление значения функции в заданных промежуточных точках с использованием математических пакетов. Исследование математической модели решения задачи. Составление программы для вычисления коэффициента корреляции.
курсовая работа [2,3 M], добавлен 21.10.2014
Разработка математической модели системы. Моделирование работы конвейера сборочного цеха в течении 8 часов. Определение вероятности пропуска секции. Расчет количества скомплектованных изделий за 8 часов. Исследование системы на имитационной модели.
контрольная работа [98,3 K], добавлен 24.09.2014
Присвоение значений параметров передаточных функций разомкнутой и замкнутой САР в виде полиномов и типовых динамических звеньев разомкнутой системы. Разработка математической модели электротехнической системы в символьном и символьно-цифровом виде.
практическая работа [456,4 K], добавлен 05.12.2009
Общая характеристика системы массового обслуживания, исходные данные для ее создания. Особенности построения алгоритма имитационной модели задачи о поступлении заявок (клиентов) в канал (парикмахерскую). Описание функционирования математической модели.
курсовая работа [154,1 K], добавлен 19.05.2011
Идентификация объектов методом наименьших квадратов. Анализ коэффициентов парной, частной и множественной корреляции. Построение линейной модели и модели с распределенными параметрами. Итерационный численный метод нахождения корня (нуля) заданной функции.
курсовая работа [893,3 K], добавлен 20.03.2014
Исследование метода математического моделирования чрезвычайной ситуации. Модели макрокинетики трансформации веществ и потоков энергии. Имитационное моделирование. Процесс построения математической модели. Структура моделирования происшествий в техносфере.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню Сервис/Надстройки .
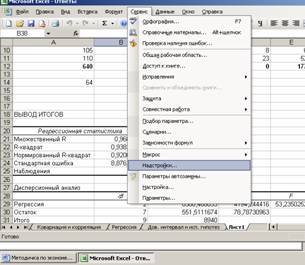
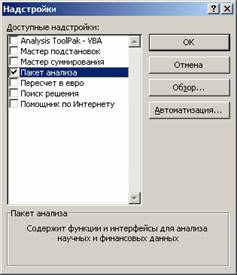
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel , нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:

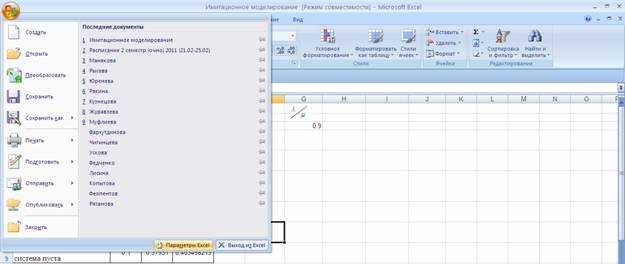
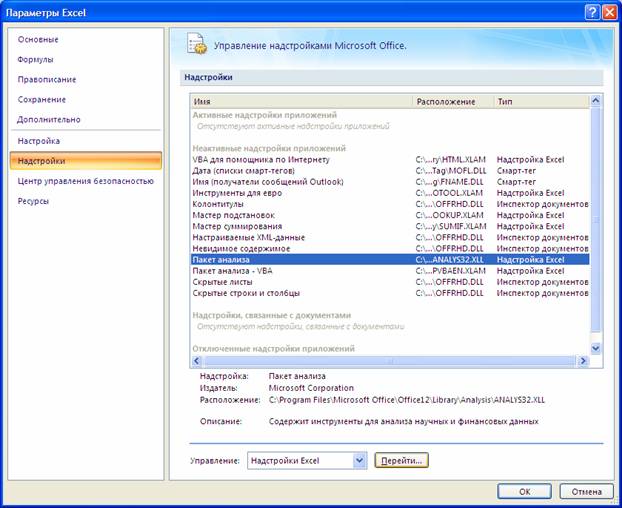
Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа , нажать кнопку Перейти и в следующем окне включить пакет анализа.
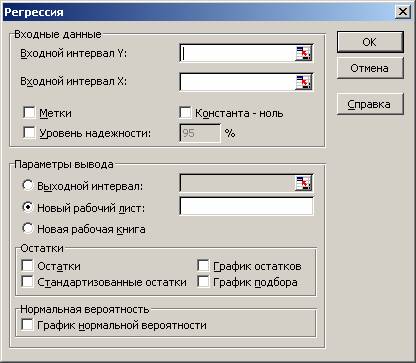
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия . (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия ) Появится диалоговое окно, которое нужно заполнить:
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R -квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения - это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R 2 = 0 (нет линейной зависимости), иначе принимается гипотеза R 2 ≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a0 , стандартной ошибки Sb0 и t -статистики tb0.
P-значение - это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП( t -статистика; n-m-1). Если P -значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% - это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2. xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Алгоритм работы
Вводим заданные значения xi и y , затем выбираем пункт меню Сервис/Анализ данных/Регрессия. Далее указываем интервалы значений xи y, включаем режим Метки, оставляем уровень надежность по умолчанию, указываем выходной интервал и включаем вывод остатков:
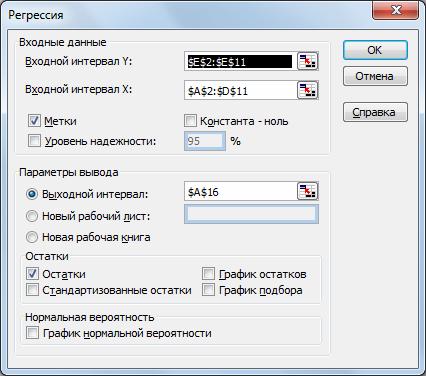
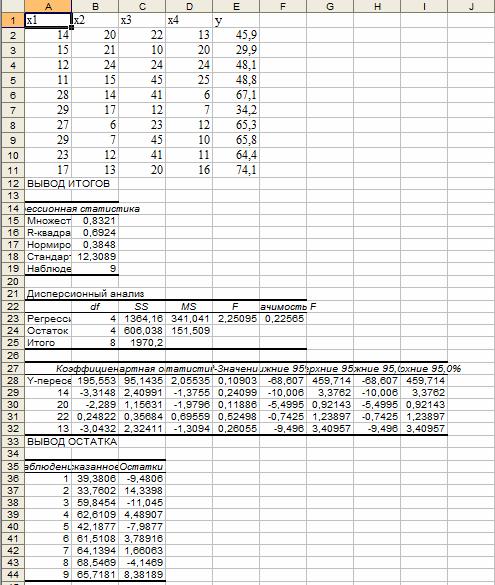
а) Коэффициенты уравнения соответствуют данным столбца Коэффициенты (следующий за столбцомY-пересечения) (блок Дисперсионный анализ).
б) Стандартная ошибка регрессии соответствует значению Стандартная ошибка блока Регрессионная статистика.
Стандартные ошибки коэффициентов соответствуют значениям столбца Стандартная ошибка блока Дисперсионный анализ.
в) Доверительные интервалы соответствуют интервалам Нижние %, Верхние %.
г) Статистическая значимость коэффициентов уравнения соответствует столбцу t -статистика. Граничная точка t(α; n-m-1) вычисляется с помощью функции СТЬЮДРАСПОБР(0,05;n-m-1) . Если i -ое значение P-значения меньше a, то i -ый коэффициент статистически значим и влияет на результативный признак.
д) Коэффициент детерминации R-квадрат в блоке Регрессионная статистика. Скорректированный (нормированный) коэффициент детерминации R2n. Это означает, что модель объясняет R2n*100% общего разброса значений результативного признака с учетом поправки на число степеней свободы.
Проверка гипотезы о статистической значимости коэффициента детерминации:
Проводим правостороннюю проверку. Граничная точка Fα;n-m-1 определяется с помощью функции FРАСПОБР(α;m;n-m-1) .
Статистика F (определяется из блока Дисперсионный анализ).
Если F> Fα;n-m-1, то гипотеза отвергается H0 и принимает гипотеза H1 на уровне значимости α%.
Этот вывод подтверждает число из столбца Значимость F, которое должно быть меньше значения a.
- Среднее значение: СРЗНАЧ(диапазон)
- Квадратическое отклонение: КВАДРОТКЛ(диапазон)
- Дисперсия: ДИСП(диапазон)
- Дисперсия для генеральной совокупности: ДИСПР(диапазон)
- Среднеквадратическое отклонение: СТАНДОТКЛОН(диапазон)
- Уравнение регрессии y = b1x1+b2x2+. bnxn+b0: ЛИНЕЙН(диапазон Y;диапазон X;1;1) .
- Выделите блок ячеек размером (n+1) столбцов и 5 строк.
Методические пояснения. 1. Для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические»), обратите внимание, что эта функция является функцией массива, поэтому ее использование подразумевает выполнение следующих шагов:
1) В свободном месте рабочего листа выделите область ячеек размером 5 строк и 2 столбца для вывода результатов;
2) В Мастере функций (категория «Статистические») выберите функцию ЛИНЕЙН .
3) Заполните поля аргументов функции:
Известные_значения_y — адреса ячеек, содержащих значения признака ;
Известные_значения_x — адреса ячеек, содержащих значения фактора ;
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
4) После того, как будут заполнены все аргументы функции, нажмите комбинацию клавиш ++ .
Результаты расчета параметров регрессионной модели будут выведены в виде следующей таблицы:
Значение коэффициента b | Значение коэффициента a |
Стандартная ошибка mb коэффициента b | Стандартная ошибка ma коэффициента a |
Коэффициент детерминации R 2 | Стандартное отклонение остатков Sост |
Значение F-статистики | Число степеней свободы, равное n-2 |
Регрессионная сумма квадратов | Остаточная сумма квадратов |
2. Табличные значения распределения Стьюдента определите с помощью функции СТЬЮДРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы — число степеней свободы, для парной линейной регрессии равно n-2, где n — число наблюдений.
3. Табличное значение распределения Фишера определите с помощью функции FРАСПОБР. Аргументы этой функции:
Вероятность — уровень значимости α (можно принять равным 0,05, т.е. 5%);
Степени_свободы1 — число степеней свободы числителя, для парной регрессии равно 1 (т.к. один фактор);
Степени_свободы2 — число степеней свободы знаменателя, для парной регрессии равно n-2, где n — число наблюдений.
4. Коэффициент корреляции вычислите с помощью функции КОРРЕЛ. Аргументы функции:
Массив 1ш и Массив 2 — адреса ячеек, в которых содержатся значения величин, для которых вычисляется коэффициент корреляции.
5. Для вычисления (X T X) -1
1) Построите матрицу .
2) Постройте транспонированную к ней матрицу X T . Для построения матрицы X T необходимо воспользоваться функцией ТРАНСП (категория Ссылки и массивы).
3) матрицу X T необходимо умножить на матрицу X;
Произведение матриц вычисляется с помощью функции МУМНОЖ, аргументами которой являются перемножаемые матрицы. Перемножаемые матрицы должны удовлетворять условию соответствия размеров: матрица размера mxn может быть умножена справа на матрицу размера nxk, в результате получится матрица размера mxk.
В случае множественной регрессии с тремя факторами матрица X будет иметь размер nx4, матрица X T — размер 4xn, а их произведение X T X — размер 4x4.
Функция МУМНОЖ является функцией массива! Поэтому перед использованием функции МУМНОЖ необходимо выделить область размером mxk, в которой будет выведен результат, затем вставить функцию МУМНОЖ, указав ее аргументы. После этого в левой верхней ячейке выделенной области появится первый элемент результирующей матрицы. Для вывода всей матрицы нажмите комбинацию клавиш ++ .
4) найти обратную матрицу (X T X) -1 ;
Обратную матрицу (X T X) -1 вычислите с помощью функции МОБР . Функция МОБР также является функцией массива и ее использование аналогично функции МУМНОЖ: сначала необходимо выделить область ячеек, в которой будет получена обратная матрица, вставить функцию МОБР, затем ++ .
6. Коэффициенты множественной линейной регрессии вычисляются с помощью функции ЛИНЕЙН . Для того чтобы использовать эту функцию для вычисления параметров множественной регрессии необходимо
1) Сначала выделить на рабочем листе область размером 5x(k+1), где k — число объясняющих переменных.
2) Затем заполнить поля аргументов этой функции, которые имеют тот же смысл, что и в случае парной регрессии:
Известные_значения_y — адреса ячеек, содержащих значения признака y;
Известные_значения_x — адреса ячеек, содержащих значения всех объясняющих переменных.
Обратите внимание: выборочные значения факторов должны располагаться рядом друг с другом (в смежной области), причем предполагается, что в первом столбце (строке) содержатся значения первой объясняющей переменной, во втором столбце — второй и т.д.
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
Читайте также: