
Коллизия в 1с это
Кто-то считает, что это очевидные вещи, другие скажут, что скучная и ненужная теория. Тем не менее на собеседованиях периодически можно услышать подобные вопросы. Мое мнение: о том, о чем ниже пойдет речь, нужно знать всем, кому приходится брать в руки «обжимку» 8P8C (этот разъем обычно ошибочно называют RJ-45). На академическую глубину не претендую, воздержусь от формул и таблиц, так же за бортом оставим линейное кодирование. Речь пойдет в основном о медных проводах, не об оптике, т.к. они шире распространены в быту.
Технология Ethernet описывает сразу два нижних уровня модели OSI. Физический и канальный. Дальше будем говорить только о физическом, т.е. о том, как передаются биты между двумя соседними устройствами.
Технология Ethernet — часть богатого наследия исследовательского центра Xerox PARC. Ранние версии Ethernet использовали в качестве среды передачи коаксиальный кабель, но со временем он был полностью вытеснен оптоволокном и витой парой. Однако важно понимать, что применение коаксиального кабеля во многом определило принципы работы Ethernet. Дело в том, что коаксиальный кабель — разделяемая среда передачи. Важная особенность разделяемой среды: ее могут использовать одновременно несколько интерфейсов, но передавать в каждый момент времени должен только один. С помощью коаксиального кабеля можно соединит не только 2 компьютера между собой, но и более двух, без применения активного оборудования. Такая топология называется шина. Однако если хотябы два узла на одной шине начнут одновременно передавать информацию, то их сигналы наложатся друг на друга и приемники других узлов ничего не разберут. Такая ситуация называется коллизией, а часть сети, узлы в которой конкурируют за общую среду передачи — доменом коллизий. Для того чтоб распознать коллизию, передающий узел постоянно наблюдает за сигналов в среде и если собственный передаваемый сигнал отличается от наблюдаемого — фиксируется коллизия. В этом случае все узлы перестают передавать и возобновляют передачу через случайный промежуток времени.
Диаметр коллизионного домена и минимальный размер кадра
Таким образом чем больше потенциальный размер сегмента сети, тем больше накладных расходов уходит на передачу порций данных маленького размера. Разработчикам технологии Ethernet пришлось искать золотую середину между двумя этими параметрами, и минимальным размером кадра была установлена величина 64 байта.
Витая пара и дуплексный режим рабты

Витая пара в качестве среды передачи отличается от коаксиального кабеля тем, что может соединять только два узла и использует разделенные среды для передачи информации в разных направлениях. Одна пара используется для передачи (1,2 контакты, как правило оранжевый и бело-оранжевый провода) и одна пара для приема (3,6 контакты, как правило зеленый и бело-зеленый провода). На активном сетевом оборудовании наоборот. Не трудно заметить, что пропущена центральная пара контактов: 4, 5. Эту пару специально оставили свободной, если в ту же розетку вставить RJ11, то он займет как раз свободные контакты. Таким образом можно использовать один кабели и одну розетку, для LAN и, например, телефона. Пары в кабеле выбраны таким образом, чтоб свести к минимуму взаимное влияние сигналов друг на друга и улучшить качество связи. Провода одной пару свиты между собой для того, чтоб влияние внешних помех на оба провода в паре было примерно одинаковым.
Для соединения двух однотипных устройств, к примеру двух компьютеров, используется так называемый кроссовер-кабель(crossover), в котором одна пара соединяет контакты 1,2 одной стороны и 3,6 другой, а вторая наоборот: 3,6 контакты одной стороны и 1,2 другой. Это нужно для того, чтоб соединить приемник с передатчиком, если использовать прямой кабель, то получится приемник-приемник, передатчик-передатчик. Хотя сейчас это имеет значение только если работать с каким-то архаичным оборудованием, т.к. почти всё современное оборудование поддерживает Auto-MDIX — технология позволяющая интерфейсу автоматически определять на какой паре прием, а на какой передача.
Возникает вопрос: откуда берется ограничение на длину сегмента у Ethernet по витой паре, если нет разделяемой среды? Всё дело в том, первые сети построенные на витой паре использовали концентраторы. Концентратор (иначе говоря многовходовый повторитель) — устройство имеющее несколько портов Ethernet и транслирующее полученный пакет во все порты кроме того, с которого этот пакет пришел. Таким образом если концентратор начинал принимать сигналы сразу с двух портов, то он не знал, что транслировать в остальные порты, это была коллизия. То же касалось и первых Ethernet-сетей использующих оптику (10Base-FL).
Зачем же тогда использовать 4х-парный кабель, если из 4х пар используются только две? Резонный вопрос, и вот несколько причин для того, чтобы делать это:
- 4х-парный кабель механически более надежен чем 2х-парный.
- 4х-парный кабель не придется менять при переходе на Gigabit Ethernet или 100BaseT4, использующие уже все 4 пары
- Если перебита одна пара, можно вместо нее использовать свободную и не перекладывать кабель
- Возможность использовать технологию Power over ethernet
Не смотря на это на практике часто используют 2х-парный кабель, подключают сразу 2 компьютера по одному 4х-парному, либо используют свободные пары для подключения телефона.
Gigabit Ethernet
В отличии от своих предшественников Gigabit Ethernet всегда использует для передачи одновременно все 4 пары. Причем сразу в двух направлениях. Кроме того информация кодируется не двумя уровнями как обычно (0 и 1), а четырьмя (00,01,10,11). Т.е. уровень напряжения в каждый конкретный момент кодирует не один, а сразу два бита. Это сделано для того, чтоб снизить частоту модуляции с 250 МГц до 125 МГц. Кроме того добавлен пятый уровень, для создания избыточности кода. Он делает возможной коррекцию ошибок на приеме. Такой вид кодирования называется пятиуровневым импульсно-амплитудным кодированием (PAM-5). Кроме того, для того, чтоб использовать все пары одновременно для приема и передачи сетевой адаптер вычитает из общего сигнала собственный переданный сигнал, чтоб получить сигнал переданный другой стороной. Таким образом реализуется полнодуплексный режим по одному каналу.
Дальше — больше
10 Gigabit Ethernet уже во всю используется провайдерами, но в SOHO сегменте не применяется, т.к. судя по всему там вполне хватает Gigabit Ethernet. 10GBE качестве среды распространения использует одно- и многомодовое волокно, с или без уплотнением по длине волны, медные кабели с разъемом InfiniBand а так же витую пару в стандарте 10GBASE-T или IEEE 802.3an-2006.
40-гигабитный Ethernet (или 40GbE) и 100-гигабитный Ethernet (или 100GbE). Разработка этих стандартов была закончена в июле 2010 года. В настоящий момент ведущие производители сетевого оборудования, такие как Cisco, Juniper Networks и Huawei уже заняты разработкой и выпуском первых маршрутизаторов поддерживающих эти технологии.
В заключении стоит упомянуть о перспективной технологии Terabit Ethernet. Боб Меткалф, создатель предположил, что технология будет разработана к 2015 году, и так же сказал:
Чтобы реализовать Ethernet 1 ТБит/с, необходимо преодолеть множество ограничений, включая 1550-нанометровые лазеры и модуляцию с частотой 15 ГГц. Для будущей сети нужны новые схемы модуляции, а также новое оптоволокно, новые лазеры, в общем, все новое
UPD: Спасибо хабраюзеру Nickel3000, что подсказал, про то что разъем, который я всю жизнь называл RJ45 на самом деле 8P8C.
UPD2:: Спасибо пользователю Wott, что объяснил, почему используются контакты 1,2,3 и 6.
Отказ от использования механизма планов обмена в РИБ не означает отказа от необходимости решать проблему выявления и разрешения коллизий. Данная статья предлагает рассмотреть один из вариантов решения этой проблемы.
Реализация подобного варианта обмена данными рассмотрена в моей статье " DaJet Exchange: обмен данными с 1С (часть 1) ".
Так же, как и РИБД 1С, альтернативная реализация должна предусматривать выявление коллизий и их разрешение.
Первым делом необходимо сформулировать практически целесообразные требования к системе обмена данными по типу РИБД, имеющей топологию "звезда".
Требования к асинхронному обмену данными:
Правила разрешения коллизий:
1. Root node always wins!
Центральный узел всегда имеет наивысший приоритет своих изменений по отношению к изменениям любого периферийного узла.
Все узлы должны получить и принять изменения центрального узла.
2. Leaf node may be allowed to make changes.
До тех пор пока центральный узел не сделал изменений, любой периферийный узел может предложить свои изменения.
Центральный узел и заинтересованные периферийные узлы должны получить и принять предложенные инициирующим периферийным узлом изменения.
3. First leaf node wins!
Первый периферийный узел, предложенное изменение которого было зафиксировано в центральном узле, имеет приоритет по отношению к изменениям, одновременно сделанным в других периферийных узлах.
Другие узлы должны получить и принять такое изменение.
Следствия из правил разрешения коллизий:
Для реализации правил разрешения коллизий используется адаптированная к вышеуказанным требованиям методика синхронизации потоков при помощи мьютексов.
Жизненный цикл использования мьютекса завершается в статусе вышедшего из употребления мьютекса (obsolete mutex).
Таким образом можно выделить следующие состояния данных РИБ:
1. Синхронизированное состояние данных - данные во всех узлах идентичны.
4. Получение, изменение и синхронизация данных в периферийном узле.
5. Новое синхронизированное состояние.
Для того, чтобы было понятнее как работает всё вышесказанное, ниже будут приведены схемы изменения состояния РИБ в зависимости от происходящих в системе событий. Работа алгоритма основана на том, что для каждого объекта конфигурации, участвующего в обмене данными РИБ, создаётся дополнительная таблица метаданных обмена. Данная таблица по сути своей расширяет основную таблицу объекта дополнительными полями для хранения информации о мьютексах.
Механизмы обмена данными «1С:Предприятия» позволяют организовывать обмен информацией, хранимой в базе данных, с другими программными системами. К механизмам обмена данными могут быть отнесены:
- Планы обмена,
- XML-сериализация,
- Средства чтения и записи документов XML.
Что такое план обмена
Для того чтобы существовала возможность обмена какими-либо данными с кем-либо, необходимо некоторым образом идентифицировать тех, с кем мы будем обмениваться, и для каждого из них описать перечень обмена. Обе эти задачи позволяет решать объект конфигурации «План обмена». Подобно тому, как элементами данных справочника являются элементы справочника, элементами данных плана обмена являются узлы плана обмена.
Каждый узел идентифицирует участника обмена по данному плану обмена. Кроме этого, в каждом плане обмена всегда существует один предопределенный узел, идентифицирующий данную информационную базу.
В обмене данными могут участвовать:
- объекты базы данных: элементы справочников, документы и т. д.,
- необъектные данные: наборы записей регистров, последовательностей, константы,
- специальный объект встроенного языка – УдалениеОбъекта .
Для упрощения изложения в дальнейшем будем называть эти элементы информационных структур объектами обмена. Разработчик имеет возможность определить состав каждого плана обмена, указав объекты конфигурации, данные которых должны участвовать в обмене по данному плану. При описании состава данных плана обмена разработчик имеет возможность указать для каждого типа объектов признак Авторегистрация . Этот признак определяет, каким образом план обмена будет отслеживать изменения данных.
Возможность отслеживать изменения данных реализована в плане обмена за счет использования механизма регистрации изменений. Работа этого механизма базируется на том, что каждый из объектов обмена имеет свойство ОбменДанными , с помощью которого можно указать, для каких узлов необходимо производить регистрацию изменений этого объекта. Любые изменения объекта обмена сводятся в конечном итоге к записи или удалению объекта обмена.
Так вот, признак Авторегистрация , устанавливаемый при указании состава данных плана обмена, позволяет указать, что параметры обмена данными будут формироваться каждый раз самим механизмом регистрации изменений на основании информации, содержащейся в плане обмена. После автоматического заполнения параметров обмена разработчик имеет возможность внести изменения в сформированные таким образом параметры. Кроме этого, существует возможность отключить авторегистрацию изменений, и тогда параметры обмена данными нужно будет формировать полностью средствами встроенного языка.
Итак, при записи и удалении объектов обмена план обмена формирует записи регистрации изменений. Записи регистрации изменений хранятся в таблицах регистрации изменений, причем для каждого объекта обмена ведется своя таблица. При изменении объекта обмена в таблице регистрации изменений создается столько записей, сколько узлов-получателей указано в параметрах обмена данными у объекта обмена. Каждая запись при этом будет хранить ссылку на свой узел-получатель.
Добавление плана обмена
Раскроем ветвь «Общие» дерева объектов конфигурации и добавим новый объект конфигурации План обмена с именем Филиалы , представление объекта – Филиал . На закладке «Данные» создадим реквизит плана обмена Главный , имеющий тип Булево .
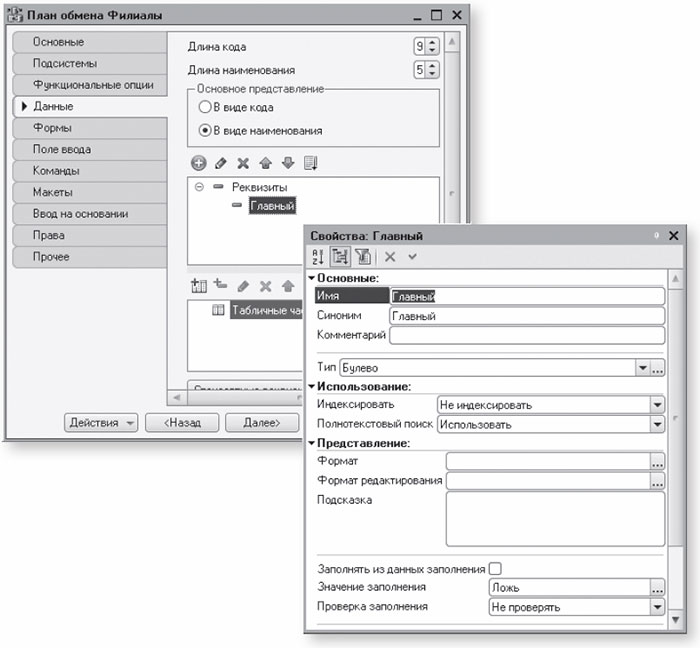
Этот реквизит понадобится нам для того, чтобы разрешать коллизии при обмене данными. Под коллизией понимается ситуация, когда один и тот же объект обмена данными был изменен одновременно в двух узлах. В этом случае мы будем анализировать значение реквизита Главный и принимать изменения только в том случае, если они сделаны в главном узле. В случае коллизии изменения, произведенные не в главном узле, мы будем отвергать.
Теперь определим состав объектов, участвующих в обмене. Для этого на закладке «Основные» нажмем кнопку «Состав».

Создадим основную форму узла и добавим обработчик события формы ПриСозданииНаСервере . Этот обработчик понадобится нам для того, чтобы запретить установку реквизита Главный для предопределенного узла, соответствующего данной информационной базе.
Затем создадим основную форму списка плана обмена, чтобы описать в ней некоторые действия по регистрации нового узла обмена.
Суть этих действий будет заключаться в том, что при регистрации нового узла обмена мы должны будем сформировать для него все необходимые записи регистрации изменений для всех объектов конфигурации, входящих в данный план обмена. Это будет своего рода начальная синхронизация узла обмена всеми данными обмена.
Для этого на закладке «Команды» создадим команду ЗарегистрироватьИзменения .
Кнопка «Зарегистрировать изменения» должна быть доступна только в случае, если текущий узел не является предопределенным для данной информационной базы, иначе регистрация изменений невозможна. Чтобы обеспечить такое поведение кнопки, создадим в модуле формы списка функцию, выполняющуюся на сервере без контекста и возвращающую истину, если переданный в функцию узел является предопределенным.
Затем в окне элементов формы выделим элемент Список , вызовем его палитру свойств и создадим обработчик события ПриАктивизацииСтроки .
Процедуры обмена данными
Для инициализации обмена данными мы используем обработку. Добавим новый объект конфигурации Обработка с именем ОбменДанными . На закладке Формы создадим основную форму обработки. В окне редактора форм на закладке «Команды» создадим команду формы ВыполнитьОбмен .
Процедуры записи и чтения данных
Сами процедуры записи и чтения данных обмена мы разместим в модуле объекта План обмена Филиалы .
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу посвятить запуску нового потока курса «Алгоритмы для разработчиков».

Введение
Хеш-таблицы (HashMap) наравне с динамическими массивами являются самыми популярными структурами данных, применяемыми в production'е. Очень часто можно услышать вопросы на собеседованиях касаемо их предназначения, особенностей их внутреннего устройства, а также связанных с ними алгоритмов. Данная структура данных является классической и встречается не только в Java, но и во многих других языках программирования.
Постановка задачи
Давайте зададимся целью создать структуру данных, которая позволяет:
- contains(Element element) проверять, находится в ней некоторый элемент или нет, за О(1)
- add(Element element) добавлять элемент за О(1)
- delete(Element element) удалять элемент за О(1)
Массив
Попробуем сделать эти операции поверх массива, который является самой простой структурой данных. Договоримся, что будем считать ячейку пустой, если в ней содержится null.
Проверка наличия
Необходимо сделать линейный поиск по массиву, ведь элемент потенциально может находиться в любой ячейке. Асимптотически это можно осуществить за O(n), где n — размер массива.
Добавление
Если нам надо добавить элемент абы куда, то вначале мы должны найти пустую ячейку, а затем записать в нее элемент. Таким образом, мы опять осуществим линейный поиск и получим асимптотику O(n).
Удаление
Чтобы удалить элемент, его нужно сначала найти, а затем в найденную ячейку записать null. Опять линейный поиск приводит нас к O(n).
Простейшее хеш-множество
Обратите внимание, что при каждой операции, мы сначала искали индекс нужной ячейки, а затем осуществляли операцию, и именно поиск портит нам асимптотику! Если бы мы научились получать данный индекс за O(1), то исходная задача была бы решена.
Давайте теперь заменим линейный поиск на следующий алгоритм: будем вычислять значение некоторой фунции — хеш-функции, ставящей в соответствие объекту класса некоторое целое число. После этого будем сопоставлять полученное целое число индексу ячейки массива (это достаточно легко сделать, например, взяв остаток от деления этого числа на размер массива). Если хеш-функция написана так, что она считается за O(1) (а она так обычно и написана), то мы получили самую простейшую реализацию хеш-множества. Ячейка массива в терминах хеш-множества может называться bucket'ом.
Проблемы простейшей реализации хеш-множества
Как бы ни была написана хеш-функция, число ячеек массива всегда ограничено, тогда как множество элементов, которые мы хотим хранить в структуре данных, неограничено. Ведь мы бы не стали заморачиваться со структурой данных, если бы была потребность в сохранении всего лишь десяти заранее известных элементов, верно? Такое положение дел приводит к неизбежным коллизиям. Под коллизией понимается ситуация, когда при добавлении разных объектов мы попадаем в одну и ту же ячейку массива.
Для разрешения коллизий придумано 2 метода: метод цепочек и метод открытой адресации.
Метод цепочек
Метод цепочек является наиболее простым методом разрешения коллизий. В ячейке массива мы будем хранить не элементы, а связанный список данных элементов. Потому как добавление в начало списка (а нам все равно в какую часть списка добавлять элемент) обладает асимптотикой О(1), мы не испортим общую асимптотику, и она останется равной О(1).
У данной реализации есть проблема: если списки будут очень сильно вырастать (в качестве крайнего случая можно рассмотреть хеш-функцию, которая возвращает константу для любого объекта), то мы получим асимптотику O(m), где m — число элементов во множестве, если размер массива фиксирован. Для избежания таких неприятностей вводится понятие коэффициент заполнения (он может быть равен, например, 1.5). Если при добавлении элемента оказывается, что доля числа элементов, находящихся в структуре данных по отношению к размеру массива, превосходит коэффициент заполнения, то происходит следующее: выделяется новый массив, размер которого превосходит размер старого массива (например в 2 раза), и структура данных перестраивается на новом массиве.
Данный метод разрешения коллизий и применяется в Java, а структура данных называется HashSet.
Метод открытой адресации
В данном методе в ячейках хранятся сами элементы, а в случае коллизии происходит последовательность проб, то есть мы начинаем по некоторому алгоритму перебирать ячейки в надежде найти свободную. Это можно делать разными алгоритмами (линейная / квадратичная последовательности проб, двойное хеширование), каждый из которых обладает своими проблемами (например, возникновение первичных или вторичных кластеров).
От хеш-множества к хеш-таблице (HashMap)
Давайте создадим структуру данных, которая позволяет так же быстро, как и хеш-множество (то есть за O(1)), добавлять, удалять, искать элементы, но уже по некоторому ключу.
Воспользуемся той же структурой данных, что у хеш-множества, но хранить будем не элементы, а пары элементов.
Таким образом, вставка (put(Key key, Value value)) будет осуществляться так: мы посчитаем ячейку массива по объекту типа Key, получим номер bucket'а. Пройдемся по списку в bucket'е, сравнивая ключ с ключом в хранимых парах. Если нашли такой же ключ — просто вытесняем старое значение, если не нашли — добавляем пару.
Как осуществляется получение элемента по ключу? Да по похожему принципу: получаем bucket по ключу, проходимся по парам и возвращаем значение в паре, ключ в которой равен ключу в запросе, если такая пара есть, и null в противном случае.
Данная структура данных и называется хеш-таблицей.
Типичные вопросы на собеседовании
Q: Как устроены HashSet и HashMap? Как осуществляются основные операциии в данных коллекциях? Как применяются методы equals() и hashCode()?
A: Ответы на данные вопросы можно найти выше.
Q: Каков контракт на equals() и hashCode()? Чем он обусловлен?
A: Если объекты равны, то у них должны быть равны hashCode. Таким образом, hashCode должен определяться по подможноству полей, учавствующих в equals. Нарушение данного контракта может приводить к весьма интересным эффектам. Если объекты равны, но hashCode у них разный, то вы можете не достать значение, соответствующее ключу, по которому вы только что добавили объект в HashSet или в HashMap.
Вывод
На собеседованиях очень любят задавать различные кейсы, связанные с этими структурами данных. При этом решение любого из них может быть выведено из понимания принципов их работы без всякой «зубрежки».
На этом все. Если вы дочитали материал до конца, приглашаю на бесплатный урок по теме «Секреты динамического программирования» в рамках урока мой коллега — Евгений Волосатов покажет как решить олимпиадную задачу используя идеи динамического программирования.
Механизм РИБ — механизм распределенных информационных баз - это когда у вас есть главная база и подчиненная(ые). Главная база может быть только одна, подчиненных может быть много. Каждая подчиненная база может иметь свои подчиненные базы, для которых она будет главной.
Вот посмотрим на картинку из первой ссылки по запросу в Яндексе:
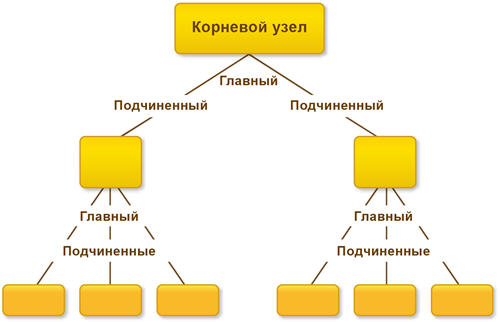
РИБ используется для обмена данными. Причем не только теми данными, с которыми работает пользователь, но и данными изменения конфигурации. То есть РИБ позволяет передавать изменения конфигурации. Но изменить конфигурацию можно только в главной базе!
Визуализируем:
У нас большая компания и много филиалов. Есть доработанная УНФ, которую мы гордо называем УБФ(Управление Большой Фирмой). Но мы решили, что хватит терпеть то, что все филиалы имеют доступ к документам всех филиалов и каждому филиалу решили сделать отдельную базу, которую синхронизировать с нашей основной базой для передачи данных. Что ж, можно. Сделали.
И внезапно мы решили изменить картинку, которая появляется при входе в базу, захотели поместить туда логотип нашей фирмы, а почему бы и нет?
Как запилить картинку во все базы всех филиалов? Ну при текущем варианте, что у всех филиалов отдельная база, только руками. Руками специалистов, которые умеют заходить в конфигуратор и знают что нужно там нажать.
А вот если бы мы сделали подчиненные базы для филиалов, то есть использовали РИБ, то и данными бы обменивались, как при обычной синхронизации, и картинка бы сама добавилась во все "базы-дочки". Однако, в конфигуратор зайти бы все-таки пришлось, но только чтобы нажать кнопочку "Обновить конфигурацию базы данных", вот картинка:

Как создать подчиненную базу, на пальцах:
я буду использовать Управление торговлей, редакция 11 (11.4.13.275), но способ, в целом, одинаковый во всех типовых конфигурациях.
1) Сначала проделаем шаги, как при настройке обычной синхронизации:

2) . поставим галочку, нажмем.


4) тут ознакомимся с описанием. Я выберу обычную настройку, но если бы мы следовали примеру выше, то нужно было бы выбрать "с фильтром" и там одним кликом выбрать нужный филиал.


6) Указываем префикс - он будет подставляться к номерам документов, чтобы можно было отличить документы дочки и основной базы.


7) в общем случае, тут ничего не надо нажимать, кроме "Записать и закрыть".

8) А вот теперь создаем нашу новую подчиненную базу:

9) указываем место, куда ее покладем.




10) Зайдем в нашу новую подчиненную базу и закончим настройки синхронизации(синхронизация уже создалась, так как использовали РИБ, но нужно указать каталог для обмена выбрав "Настройки подключения")

(обратите внимание на верхний левый угол окна программы, там название базы, он отличается от предыдущих, так как это "дочка")
Кстати, в новой базе все пользователи будут выключены, пароли сброшены, нужно включить руками:

В общем-то ВСЕ.
Подчиненная база создана!
Теперь, когда наши программисты что-нибудь улучшат, эти улучшения прилетят в подчиненные базы сами.
Вот что-то изменили в основной базе:

нам нужно перенести изменения в базы-дочки.
Для этого запускаем главную базу в режиме 1С:Предприятие, то есть в пользовательском интерфейсе, заходим в настройки синхронизации, жмем выделенную кнопку:

После того, как синхронизация закончится, заходим в базу дочку и так же жмем "Синхронизировать", база загрузит данные и напишет:


После нажатия на Далее база закроется и начнет устанавливать обновления.

Когда обновы установятся, база начнет запускаться и сообщит нам следующее:

Это означает, что не обновлена конфигурация базы данных. Та самая маленькая кнопка в конфигураторе и это именно та причина, почему придется ОДИН раз зайти в конфигуратор. Что ж, зайдем в конфигуратор базы-дочки и нажмем эту кнопку, заодно вообще посмотрим что-да-как там, мы ж там еще не были.
Откроем конфигурацию и вот что увидим
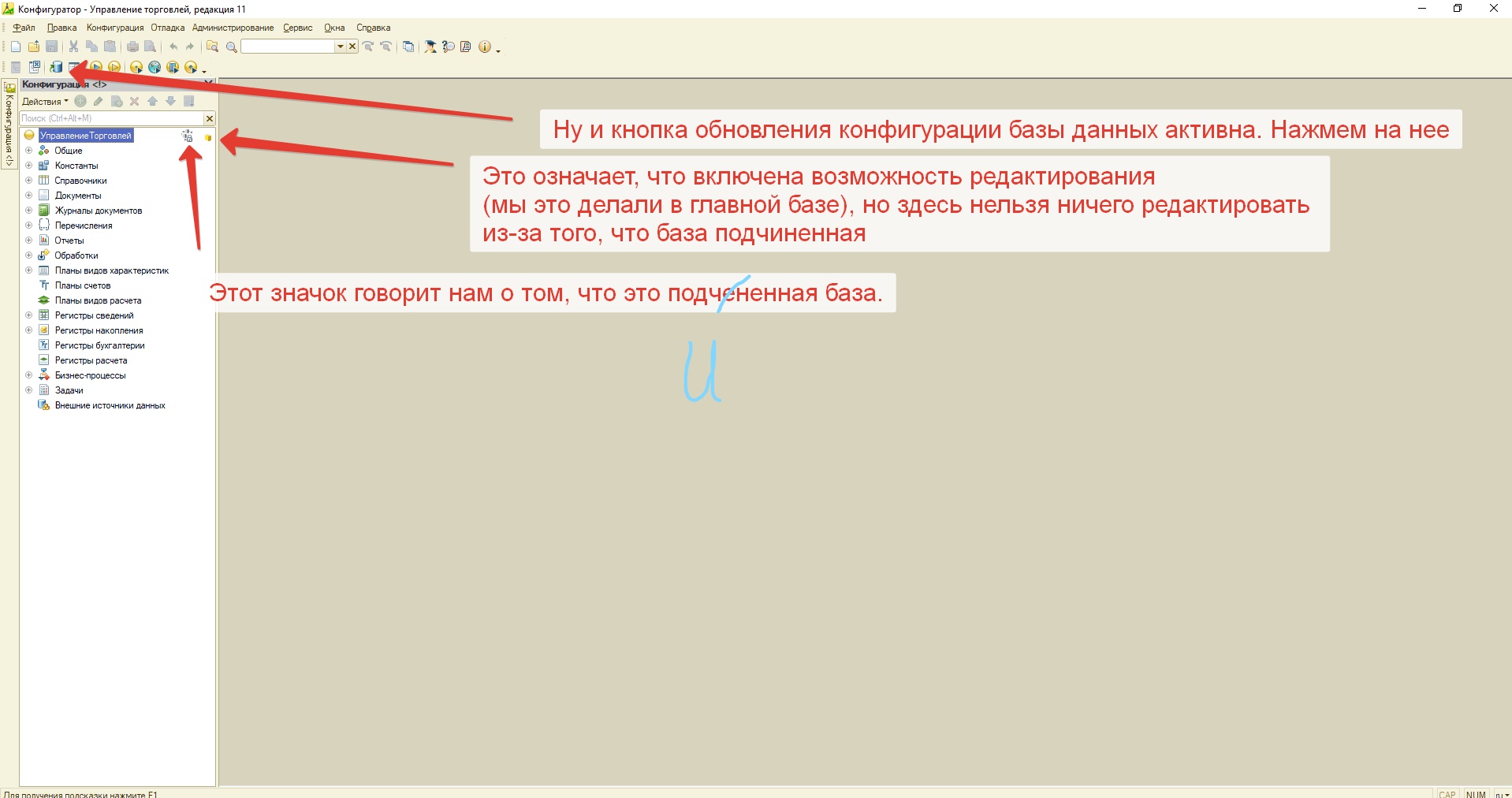
Нажмем на "Обновить конфигурацию базы данных".
Увидим список изменений, которые прилетели с обновлениями:

И вот эти обновления появились в подчиненной базе.

Теперь необходимо запустить базу в пользовательском режиме, чтобы выполнились обработчики обновления.
Несколько правил:
1) Все узлы, кроме одного, должны иметь по одному главному узлу и один узел не будет иметь главного узла - это корневой узел.
2) Конфигурация может быть изменена только в узле, не имеющем главного узла (то есть в корневом).
3) Изменения конфигурации будут передаваться от главного к подчиненным узлам.
4) Разрешение коллизий так же будет производиться исходя из отношений "главный - подчиненный" - если изменения сделаны одновременно и в главном и в подчиненном узлах, то приняты будут изменения главного узла.
5) Сделать подчиненный узел в распределенной базе можно разными способами, но создание начального образа является рекомендуемым.
А теперь то, ради чего все писалось.
Как подчиненную базу сделать обычной(нормальной, отдельной, как хотите).
Я опишу только тот способ, которым пользуюсь. Это моя шпаргалка. Но он не единственный.
1) Заходим в свойства ярлыка запуска окна 1С:Предприятие:

2) В поле "Объект" дописываем:
DESIGNER /F"Путь до базы" /N"Имя Пользователя в базе" /P"Пароль пользователя" /ResetMasterNode
В итоге у меня получится:
"C:\Program Files\1cv8\common\1cestart.exe" DESIGNER /F"C:\Users\79119\Desktop\РИБ" /N"" /P"" /ResetMasterNode
Читайте также: