
Количество ошибок в программе
Отладка программы – это процесс поиска и устранения ошибок. Часть ошибок формального характера, связанных с нарушением правил записи конструкций языка или отсутствием необходимых описаний, обнаруживает транслятор, производя синтаксический анализ текста программы. Транслятор выявляет ошибки и сообщает о них, указывая их тип и место в программе. Такие ошибки называются ошибками времени трансляции или синтаксическими ошибками.
Ошибочные ситуации могут возникнуть и при выполнении программы, например, деление на нуль или извлечение корня квадратного из отрицательного числа. Такие ошибки называются ошибками времени выполнения.
Программа, не имеющая ошибок трансляции и выполнения, может и не дать верных результатов из-за логических ошибок в алгоритме, т. е. алгоритмических или семантических ошибок. Ошибки подобного рода могут возникнуть на любом этапе разработки программы: постановки задачи, разработке математической модели или алгоритма. Необходим действенный контроль над процессом вычислений, позволяющий предотвращать или своевременно обнаруживать ошибки подобного рода. Для этого используются как качественный анализ задачи, основанный на различного рода интуитивных соображениях и правдоподобных рассуждениях, так и контрольный просчет или тестирование программы.
Тестирование программы – это выполнение программы на наборах исходных данных (тестах), для которых известны результаты, полученные другим методом. Система тестов подбирается таким образом, чтобы
а) проверить все возможные режимы работы программы;
б) по возможности, локализовать ошибку.
При тестировании программы простой и действенный метод дополнительного контроля над ходом её выполнения – получение контрольных точек, т. е. контрольный вывод промежуточных результатов.
Для проверки правильности работы программы иногда полезно также выполнить проверку выполнения условий задачи (например, для алгебраического уравнения найденные корни подставляются в исходное уравнение и проверяются расхождения левой и правой частей).
33. ВИДЫ ОШИБОК В ПРОГРАММАХ
Об ошибках в программе сигнализируют некорректная работоспособность программы либо ее полное невыполнение. В наше время для обозначения ошибки в программе используют термин «Баг» (с англ. Bug-жук).
Есть несколько типов ошибок:
1) Логическая ошибка. Это, пожалуй, наиболее серьезная из всех ошибок. Когда написанная программа на любом языке компилирует и работает правильно, но выдает неправильный вывод, недостаток заключается в логике основного программирования. Это ошибка, которая была унаследована от недостатка в базовом алгоритме. Сама логика, на которой базируется вся программа, является ущербной. Чтобы найти решение такой ошибки нужно фундаментальное изменение алгоритма. Вам нужно начать копать в алгоритмическом уровне, чтобы сузить область поиска такой ошибки. (пример: задача программы вывести сумму двух чисел а и b.
varc,a,b:integer;
2) Синтаксическая ошибка.Каждый компьютерный язык, такой как C, Java, Perl и Python имеет специфический синтаксис, в котором будет написан код. Когда программист не придерживаться "грамматики" спецификациями компьютерного языка, возникнет ошибка синтаксиса. Такого рода ошибки легко устраняются на этапе компиляции.
3) Ошибка компиляции.Компиляция это процесс, в котором программа, написанная на языке высокого уровня, преобразуется в машиночитаемую форму. Многие виды ошибок могут происходить на этом этапе, в том числе и синтаксические ошибки. Иногда, синтаксис исходного кода может быть безупречным, но ошибка компиляции все же может произойти. Это может быть связано с проблемами в самом компиляторе. Эти ошибки исправляются на стадии разработки.

vara:array[1..5] of integer;
6) Ошибки ресурса. Ошибка ресурса возникает, когда значение переменной переполняет максимально допустимое значение. Переполнение буфера, использование неинициализированной переменной, нарушение прав доступа и переполнение стека - примеры некоторых распространенных ошибок.
vara:integer;
7) Ошибка взаимодействия. Они могут возникнуть в связи с несоответствием программного обеспечения с аппаратным интерфейсом или интерфейсом прикладного программирования. В случае веб-приложений, ошибка интерфейса может быть результатом неправильного использования веб-протоколов
Синтаксические ошибки – это ошибки в записи конструкций языка программирования (чисел, переменных, функций, выражений, операторов, меток, подпрограмм).
Семантические ошибки – это ошибки, связанные с неправильным содержанием действий и использованием недопустимых значений величин.
Данная модель требует тестирование программы двумя специалистами (или группами специалистов). Зато не требует внесение в программу искусственных ошибок. Итак, пусть программу тестируют независимо друг от друга две группы специалистов. Предположим, что в программе содержится N ошибок. Пусть первая группа нашла N1 ошибок, а вторая — N2. Часть ошибок обнаружена обеими группами. Пусть таких ошибок N12.

Эффективность работы групп оценим через процент обнаруженных ими ошибок:
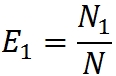
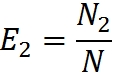
Обаружение всех ошибок считаем равновероятным (что, на мой взгляд, уменьшает доверие к этой модели, как и в случае с миллсовой). Тогда, в силу равновероятности нахождения любой из ошибок, любое случайным образом выбранное подмножество из N можно рассматривать как аппроксимацию всего множества N. Это значит, что если первая группа обнаружила 10% всех ошибок, она должна обнаружить примерно 10% из любого случайным образом выбранного подмножества.
В качестве такого случайным образом выбранного подмножества возьмём множество ошибок, найденных второй группой. Доля всех ошибок, найденных первой группой, равна N1/N. Доля ошибок, найденных первой группой среди тех ошибок, которые были найденны второй группой, равна N12/N2. Согласно такому рассуждению, эти две величины должны быть равны:
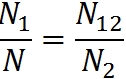
Отсюда количество ошибок в программе:

Количество нанайденных ошибок равно (N-N1-N2+N12).
Например, пусть первая группа нашла 8 ошибок, вторая 9. Обеими группами были найдены 3 ошибки. Тогда количество ошибок в программе N=(8*9/3)=24. Из них уже найденно (8+9-3)=14. Следовательно осталось найти 10 штук.
Исторический опыт
Данная модель появилась в процессе работы над OS/360 компанией IBM. Была использованна следущая формула для оценки числа ошибок: N=2*ИМ+23*МИМ. Здесь
N — полное число исправлений изза ошибок,
ИМ — количество исправляемых модулей,
МИМ — число многократно исправляемых модулей.
Многократно исправляемыми модулями считались модули, которые потребовали 10 или более исправлений. ИМ оценивалось как 90% новых модулей и 15% старых. МИМ — как 15% новых и 6% старых. При подстановке таких оценок в формулу получаем вид:
Nиспр=2*(0.9*Nнов. мод.+0.15*Nстар. мод.)+23*(0.15*Nнов. мод.+0.06*Nстар. мод.)
Таким образом, если в системе 140 модулей, а в процесее обновления предстоит добавить ещё 20, то количество ошибок, которое при этом будет обнаружено, оценивается следующим образом:
2*(0.9*20+0.15*140)+21*(0.15*20+0.06*140) = 2*(18+21)+23*(3+8.4) = 78+262.2 = 340.2
Стоит иметь в виду, что такая модель разрабатывалась для конкретной системы. Не факт, что её можно напрямую применять в других случаях.
При написании статьи была использована методичка «Тестирование и отладка для «чайников» и не только для них» (М.А. Плаксин)
Сколько ошибок в программе? Это вопрос, который волнует каждого программиста. Особую актуальность придает ему принцип кучкования ошибок, согласно которому нахождение в некотором модуле ошибки увеличивает вероятность того, что в этом модуле есть и другие ошибки. Точного ответа на вопрос о количестве ошибок в программе очень часто дать невозможно, а вот построить некоторую оценку — можно. Для этого существуют несколько статических моделей. Рассмотрим одну из них: Модель Миллса.
В 1972 г. суперпрограммист фирмы IBM Харлан Миллс предложил следущий способ оценки количества ошибок в программе. Пусть у нас есть программа. Предположим, что в ней N ошибок. Назовем их естественными. Внесем в нее дополнительно M искусственных ошибок. Проведём тестирование программы. Пусть в ходе тестирования было обнаружено n естественных ошибок и m искусственных. Предположим, что вероятность обнаружения для естественных и искусственных ошибок одинакова. Тогда выполняется соотношение:
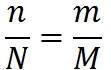
Мы нашли один и тот же процент естественных и искусственных ошибок. Отсюда количество ошибок в программе:

Количество необнаруженных ошибок равно (N-n).
Например, пусть в программу внесено 20 искусственных ошибок, в ходе тестирования было обнаружено 12 искусственных и 7 естественных ошибок. Получим следущую оценку количества ошибок в программе:

Количество необнаруженных ошибок равно (N-n) = 12 — 7 = 5.
Легко заметить, что в описанном выше способе Миллса есть один существенный недостаток. Если мы найдем 100% искусственных ошибок, это будут означать, что и естественных ошибок мы нашли 100%. Но чем меньше мы внесем искусственных ошибок, тем больше вероятность того, что мы найдём их все. Внесем единственную исскуственную ошибку, найдем ее, и на этом основании объявим, что нашли все естесственные ошибки! Для решение такой проблемы Миллс добавил вторую часть модели, предназначенную для проверки гипотезы о величине N:
Предположим, что в программе N естественных ошибок. Внесём в неё M искусственных ошибок. Будем тестировать программу до тех пор, пока не найдем все искусственные ошибки. Пусть к этому моменту найдено n естественных ошибок. На основании этих чисел вычислим величину C:
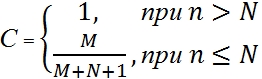
Величина C выражает меру доверия к модели. Это вероятность того, что модель будет правильно отклонять ложное предположение. Например, пусть мы считаем, что естественных ошибок в программе нет (N=0). Внесем в программу 4 искусственные ошибки. Будем тестировать программу, пока не обнаружим все искусственные ошибки. Пусть при это мы не обнаружим ни одной естественной ошибки. В этом случае мера доверия нашему предположению (об отсутствии ошибок в программе) будет равна 80% (4 / (4+0+1)). Для того чтобы довести ее до 90% количество искусственных ошибок придется поднять до 9. Следущие 5% уверенности в отсутствии естественных ошибок обойдутся нам в 10 дополнительных искусственных ошибок. M придется довести до 19.
Если мы предположим, что в программе не более 3-х естественных ошибок (N=3), внесем в нее 6 искусственных (M=6), найдем все искусственные и одну, две или три (но не больше!) естественных, то мера доверия к модели будет 60% (6 / (6+3+1)).
Значения функции С для различных значений N и M, в процентах:
Таблица 1 — с шагом 1;
Таблица 2 — с шагом 5;
Из формул для вычисления меры доверия легко получить формулу для вычисления количества искусственных ошибок, которые необходимо внести в программу для получения нужной уверенности в полученной оценке:

Количество исскуственных ошибок, которые необходимо внести в программу, для достижения нужной меры доверия, для различных значений N:
Таблица 3 — с шагом 1;
Таблица 4 — с шагом 5;
Модель Миллса достаточно проста. Ее слабое место — предположение о равновероятности нахождения ошибок. Чтобы это предположение оправдалось, процедура внесения искусственных ошибок должна обладать определенной степенью «интеллекта». Ещё одно слабое место — это требование второй части миллсовой модели отыскать непременно все искусственные ошибки. А этого может не произойти долго, может быть, и никогда.
Значительная часть усилий и времени, затрачиваем на реализацию большинства программ для ЭВМ, приходится на их отладку, т. е. выявление и устранение ошибок типа “лишних и недостающих элементов”, внесенных в начальный период написания программы. Следовательно, любое обоснованное представление о числе первоначальных ошибок, ожидаемых в данной программе, даст важную оценку для практики. Предлагаемая метрика предсказывает число первоначальных ошибок (до отладки и тестирования) и не может служить доказательством правильности (корректности) программы, даже если ее значение равно нулю.
Время, требуемое на разработку программы, характеризуется числом элементарных мысленных различений Е. Следовательно, число моментов, в которые можно сделать ошибочное различение, также определяется значением Е или связанным с ним значением объема программы V. По утверждениям психолога Джорджа Миллера (закон “7±2”) мозг человека может в своей “сверхбыстрой” памяти обрабатывать пять “объектов” одновременно (т. е. получать из них результат). Представив эту способность мозга как Екрит, получим ее программное значение.
Пусть каждый объект так же, как и результат, соответствует единице уникальных операндов в потенциальном языке, т. е. h2* = 6. С помощью равенств h1* = 2 и
Далее из уравнения (4.8) имеем
а из табл. 6 получаем для английского языка l= 2,16. Тогда для описания программы на уровне английского языка приходим к следующему выводу
Екрит = (24) 3 * (2,16) 2 = 3000 (4.13)
Определим теперь Ео как среднее число элементарных различений между возможными ошибками в программировании, а В — как число переданных ошибок в программе. Можно ожидать, что
но при этом не будет учтено какая-либо избыточность в создаваемой программе.
Однако уровень программы L, собственно, и является мерой такой избыточности. Заметим, что только в потенциальном языке, на котором любая программа может быть выражена в виде вызова процедуры, не повторяются ни операторы, ни операнды. Для такого потенциального языка L = 1. Для всех же остальных языков L уменьшается с увеличением избыточности.
Следовательно, вместо уравнения (4.14) реальнее ожидать, что
По правилам алгебры произведение L ´ Е можно заменить на V, что даст:
Если теперь приравнять Eo из уравнений (4.14) значению Екрит, найденному по уравнению (4.13), то получим соотношение
C другой стороны, подставив в (4.17) выражение для V из (4.10), получим
B= (V * ) 2 / (3000*l) (4.18)
Из выражения (4.18) следует, что поскольку для определения потенциального объема необходимо только знание числа независимых входных и выходных параметров программы, задаваемого в техническом задании на ее разработку, то после выбора языка программирования потенциальное количество ошибок можно оценить до написания программы.
Полный спектр компьютерных услуг!
Внимание!


Decker
![]()

Просмотр профиля
Продолжение к посту модель Миллса.
Парная оценка
Данная модель требует тестирование программы двумя специалистами (или группами специалистов). Зато не требует внесение в программу искусственных ошибок. Итак, пусть программу тестируют независимо друг от друга две группы специалистов. Предположим, что в программе содержится N ошибок. Пусть первая группа нашла N1 ошибок, а вторая — N2. Часть ошибок обнаружена обеими группами. Пусть таких ошибок N12.
Эффективность работы групп оценим через процент обнаруженных ими ошибок:
Обаружение всех ошибок считаем равновероятным (что, на мой взгляд, уменьшает доверие к этой модели, как и в случае с миллсовой). Тогда, в силу равновероятности нахождения любой из ошибок, любое случайным образом выбранное подмножество из N можно рассматривать как аппроксимацию всего множества N. Это значит, что если первая группа обнаружила 10% всех ошибок, она должна обнаружить примерно 10% из любого случайным образом выбранного подмножества.
В качестве такого случайным образом выбранного подмножества возьмём множество ошибок, найденных второй группой. Доля всех ошибок, найденных первой группой, равна N1/N. Доля ошибок, найденных первой группой среди тех ошибок, которые были найденны второй группой, равна N12/N2. Согласно такому рассуждению, эти две величины должны быть равны:
Отсюда количество ошибок в программе:
Количество нанайденных ошибок равно (N-N1-N2+N12).
Например, пусть первая группа нашла 8 ошибок, вторая 9. Обеими группами были найдены 3 ошибки. Тогда количество ошибок в программе N=(8*9/3)=24. Из них уже найденно (8+9-3)=14. Следовательно осталось найти 10 штук.
Исторический опыт
Данная модель появилась в процессе работы над OS/360 компанией IBM. Была использованна следущая формула для оценки числа ошибок: N=2*ИМ+23*МИМ. Здесь
N — полное число исправлений изза ошибок,
ИМ — количество исправляемых модулей,
МИМ — число многократно исправляемых модулей.
Многократно исправляемыми модулями считались модули, которые потребовали 10 или более исправлений. ИМ оценивалось как 90% новых модулей и 15% старых. МИМ — как 15% новых и 6% старых. При подстановке таких оценок в формулу получаем вид:
Таким образом, если в системе 140 модулей, а в процесее обновления предстоит добавить ещё 20, то количество ошибок, которое при этом будет обнаружено, оценивается следующим образом:
2*(0.9*20+0.15*140)+21*(0.15*20+0.06*140) = 2*(18+21)+23*(3+8.4) = 78+262.2 = 340.2
Стоит иметь в виду, что такая модель разрабатывалась для конкретной системы. Не факт, что её можно напрямую применять в других случаях.
Читайте также: