Какие типы памяти доступны для программиста при разработке программ
В традиционных языках программирования, таких как Си , Фортран, Паскаль , существуют три вида памяти: статическая, стековая и динамическая . Конечно, с физической точки зрения никаких различных видов памяти нет: оперативная память - это массив байтов, каждый байт имеет адрес , начиная с нуля. Когда говорится о видах памяти, имеются в виду способы организации работы с ней, включая выделение и освобождение памяти , а также методы доступа.
Статическая память
Статическая память выделяется еще до начала работы программы, на стадии компиляции и сборки. Статические переменные имеют фиксированный адрес, известный до запуска программы и не изменяющийся в процессе ее работы. Статические переменные создаются и инициализируются до входа в функцию main , с которой начинается выполнение программы.
Существует два типа статических переменных:
- глобальные переменные - это переменные, определенные вне функций, в описании которых отсутствует слово static . Обычно описания глобальных переменных, включающие слово extern , выносятся в заголовочные файлы (h-файлы). Слово extern означает, что переменная описывается, но не создается в данной точке программы. Определения глобальных переменных, т.е. описания без слова extern , помещаются в файлы реализации (c-файлы или cpp-файлы). Пример: глобальная переменная maxind описывается дважды:
- в h-файле с помощью строки
- Статическую переменную можно описать и внутри функции, хотя обычно так никто не делает. Переменная размещается не в стеке, а в статической памяти, т.е. ее нельзя использовать при рекурсии, а ее значение сохраняется между различными входами в функцию. Область видимости такой переменной ограничена телом функции, в которой она определена. В остальном она подобна статической или глобальной переменной. Заметим, что ключевое слово static в языке Си используется для двух различных целей:
- как указание типа памяти: переменная располагается в статической памяти, а не в стеке;
- как способ ограничить область видимости переменной рамками одного файла (в случае описания переменной вне функции).
Стековая, или локальная, память
Локальные, или стековые, переменные - это переменные, описанные внутри функции. Память для таких переменных выделяется в аппаратном стеке, см. раздел 2.3.2. Память выделяется в момент входа в функцию или блок и освобождается в момент выхода из функции или блока. При этом захват и освобождение памяти происходят практически мгновенно, т.к. компьютер только изменяет регистр, содержащий адрес вершины стека.
Локальные переменные можно использовать при рекурсии, поскольку при повторном входе в функцию в стеке создается новый набор локальных переменных, а предыдущий набор не разрушается. По этой же причине локальные переменные безопасны при использовании нитей в параллельном программировании (см. раздел 2.6.2). Программисты называют такое свойство функции реентерабельностью, от англ. re-enter able - возможность повторного входа. Это очень важное качество с точки зрения надежности и безопасности программы! Программа, работающая со статическими переменными, этим свойством не обладает, поэтому для защиты статических переменных приходится использовать механизмы синхронизации (см. 2.6.2), а логика программы резко усложняется. Всегда следует избегать использования глобальных и статических переменных, если можно обойтись локальными.
Недостатки локальных переменных являются продолжением их достоинств. Локальные переменные создаются при входе в функцию и исчезают после выхода из нее, поэтому их нельзя использовать в качестве данных, разделяемых между несколькими функциями. К тому же, размер аппаратного стека не бесконечен, стек может в один прекрасный момент переполниться (например, при глубокой рекурсии), что приведет к катастрофическому завершению программы. Поэтому локальные переменные не должны иметь большого размера. В частности, нельзя использовать большие массивы в качестве локальных переменных.
Динамическая память, или куча
Помимо статической и стековой памяти, существует еще практически неограниченный ресурс памяти, которая называется динамическая, или куча ( heap ). Программа может захватывать участки динамической памяти нужного размера. После использования ранее захваченный участок динамической памяти следует освободить.
Под динамическую память отводится пространство виртуальной памяти процесса между статической памятью и стеком. (Механизм виртуальной памяти был рассмотрен в разделе 2.6.) Обычно стек располагается в старших адресах виртуальной памяти и растет в сторону уменьшения адресов (см. раздел 2.3). Программа и константные данные размещаются в младших адресах, выше располагаются статические переменные. Пространство выше статических переменных и ниже стека занимает динамическая память:
Память — одна из самых сложных тем в информатике, но понимание устройства памяти компьютера позволяет разрабатывать более эффективные программы, а для более низкоуровневого программирования, например, при разработке ОС, это понимание и вовсе является обязательным.
В этой статье будет рассмотрена модель памяти с высокоуровневой точки зрения — виды памяти, аллокаторы, сборщик мусора.
Виды памяти
Существует 3 типа памяти: статический, автоматический и динамический.
Статический — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего времени выполнения программы. Во многих языках для размещения объекта в статической памяти достаточно задекларировать его в глобальной области видимости.
Автоматический, также известный как «размещение на стеке», — самый основной, автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове функции и освобождает память при выходе из неё.
Стек, как структура данных, работает по принципу LIFO («последним пришёл — первым ушёл»). Другими словами, добавлять и удалять значения в стеке можно только с одной и той же стороны.
Автоматическая память работает именно на основе стека, чтобы вызванная из любой части программы функция не затёрла уже используемую автоматическую память, а добавила свои данные в конец стека, увеличивая его размер. При завершении этой функции её данные будут удалены с конца стека, уменьшая его размер. Длина стека останется той же, что и до вызова функции, а у вызывающей функции указатель на конец стека будет указывать на тот же адрес.
Проще всего это понять из примера на С++:
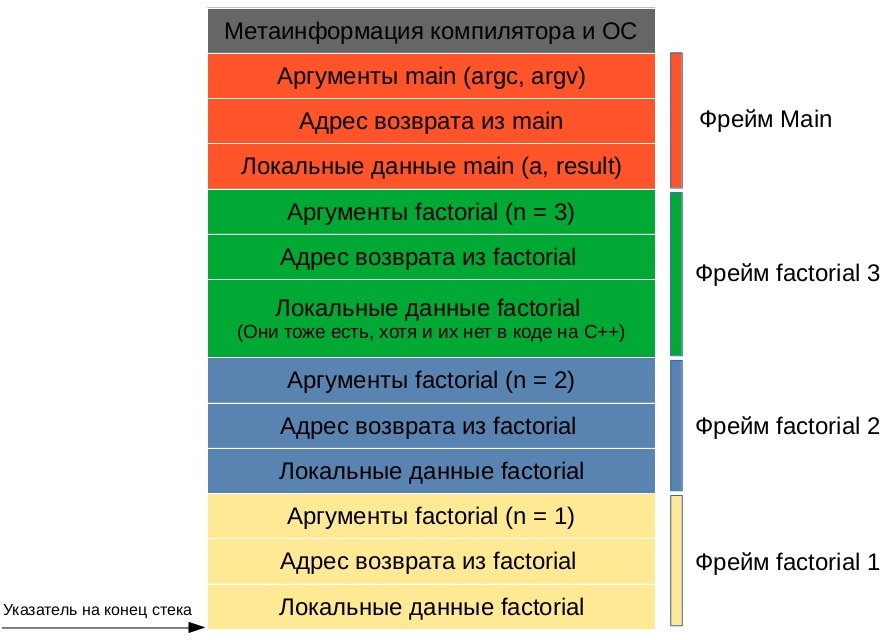
Стек при вызове последней рекурсивной функции будет выглядеть следующим образом:
![]()
Детали реализации автоматической памяти могут быть разными в зависимости от конкретной платформы. Например, кому очищать из стека метаинформацию функции и её аргументы: вызывающей функции или вызываемой? Как передавать результат: через стек или, что намного быстрее, через регистры процессора (память, расположенную прямо на кристалле процессора. В этой статье не рассматривается, т. к. в языках программирования высокого уровня зачастую нет прямого доступа к регистрам процессора). На все эти вопросы отвечает конкретная реализация calling convention — описание технических особенностей вызова подпрограмм, определяющее способы передачи параметров/результата функции и способы вызова/возврата из функции.
Таким образом, когда одна функция вызывает другую, последняя всегда в курсе, где ей взять свои аргументы: на конце стека. Но откуда ей знать, где конец стека? В процессоре для этого есть специальный регистр, хранящий указатель на конец стека. В большинстве случаев стек расположен ближе к концу виртуальной памяти и растёт в сторону начала.
Размер автоматической памяти, а он тоже фиксированный, определяется линковщиком (обычно — 1 мегабайт), максимальный размер зависит от конкретной системы и настроек компилятора/линковщика.
Если приложение выйдет за максимум автоматической памяти, его там может ждать Page Fault (сигнал SIGSEGV в POSIX-совместимых системах: Mac OS X, Linux, BSD и т. д.) — ошибка сегментации, приводящая к аварийному завершению программы.
Динамическая — выделение памяти из ОС по требованию приложения.
Автоматическая и статическая память выделяются единоразово перед запуском программы. При их нехватке, либо если модель LIFO не совсем подходит, используется динамическая память.
Приложение при необходимости может запросить у ОС дополнительную память через аллокатор или напрямую через системный вызов. Пример использования динамической памяти с помощью аллокатора ниже на примере языка Си.
После выделения памяти в распоряжение программы поступает указатель на начало выделенной памяти, который, в свою очередь, тоже должен где-то храниться: в статической, автоматической или также в динамической памяти. Для возвращения памяти обратно в аллокатор необходим только сам указатель. Попытка использования уже очищенной памяти может привести к завершению программы с сигналом SIGSEGV.
Языки сверхвысокого уровня используют динамическую память как основную: создают все или почти все объекты в динамической памяти, а на стеке или в статической памяти держат указатели на эти объекты.
Максимальный размер динамической памяти зависит от многих факторов: среди них ОС, процессор, аппаратная архитектура в целом, не говоря уже о самом очевидном — максимальном размере ОЗУ у конкретного устройства. Например x86_64 процессоры используют только 48 бит для адресации виртуальной памяти, что позволяет использовать до 256 ТБ памяти. В следующей статье про более низкоуровневую архитектуру памяти будет объяснено, почему не все 64 бита.
Аллокатор
У динамической памяти есть две явные проблемы. Во-первых, любое выделение/освобождение памяти в ОС — системный вызов, замедляющий работу программы. Решением этой проблемы является аллокатор.
Аллокатор — это часть программы, которая запрашивает память большими кусками напрямую у ОС через системные вызовы (в POSIX-совместимых ОС это mmap для выделения памяти и unmap — для освобождения), затем по частям отдаёт эту память приложению (в Си это могут быть функции malloc() / free() ). Такой подход увеличивает производительность, но может вызвать фрагментацию памяти при длительной работе программы.
malloc() / free() и mmap / unmap — это не одно и то же. Первый является простейшим аллокатором в libc , второй является системным вызовом. В большинстве языков можно использовать только аллокатор по умолчанию, но в языках с более низкоуровневой моделью памяти можно использовать и другие аллокаторы.
Например, boost::pool аллокаторы, созданные для оптимальной работы с контейнерами ( boost::pool_allocator для линейных ( std::vector ), boost::fast_pool_allocator для нелинейных ( std::map, std::list )). Или аллокатор jemalloc, оптимизированный для решения проблем фрагментации и утилизации ресурсов CPU в многопоточных программах. Более подробно о jemalloc можно узнать из доклада с конференции C++ Russia 2018.
Способы контроля динамической памяти
Из-за сложности программ очень трудно определить, когда необходимо освобождать память в ОС, и это вторая явная проблема динамической памяти. Если забыть вызвать munmap() или free() , то произойдет следующая ситуация: приложению память уже не нужна, но ОС всё ещё будет считать, что эта память используется программой. Эту проблему называют «утечкой памяти». Существуют несколько способов автоматического или полуавтоматического решения этой проблемы:
RAII (Получение ресурса есть инициализация) — в ООП — организация получения доступа к ресурсу в конструкторе, а освобождения — в деструкторе соответствующего класса. Достаточно реализовать управление памятью в конструкторах и деструкторах, а компилятор вызовет их автоматически. Например, немного урезанный класс String из статьи про Move-семантику. Выделяем память в конструкторе, очищаем в деструкторе:
Умные указатели на основе RAII — указатели, автоматически владеющие динамической памятью, то есть автоматически освобождающие её, когда она больше не нужна. Умные указатели инкапсулируют только управление памятью объекта, но не сам объект, как, например, происходит в String, который инкапсулирует объект целиком. Примеры умных указателей ниже.
std::unique_ptr — класс уникального указателя, является единственным владельцем памяти и очищает её в своём деструкторе. Поэтому объекты класса std::unique_ptr не могут иметь копий, но могут быть перемещены. Подробнее о семантике перемещения в этой статье.
std::shared_ptr — класс общего указателя, использующий атомарный счётчик ссылок для подсчёта количества владельцев памяти. В конструкторе счётчик инкрементируется, в деструкторе — декрементируется. Как только счётчик становится равным нулю, память освобождается.
Но у std::shared_ptr есть проблема, например, когда объект A ссылается на объект B, а объект B ссылается на объект A. В таком случае у обоих объектов счётчик ссылок никогда не будет меньше 1 и произойдёт утечка памяти. Решений у этой проблемы два. Использование std::weak_ptr , который ссылается на объект, но без счётчика ссылок, и не может быть разыменован без предварительной конвертации в std::shared_ptr . Вторым решением этой проблемы является сборщик мусора.
Сборка мусора — одна из форм автоматического управления динамической памятью, которая помечает все доступные из стека или статической памяти динамически выделенные объекты. Объекты, до которых нельзя добраться через цепочку указателей, начиная с автоматической или статической памяти, т. е. не помеченные сборщиком мусора, очищаются.
Умные указатели и RAII используются в основном в относительно низкоуровневых языках, например, С++ или Swift. В более высокоуровневых языках обычно используется сборщик мусора (Java), хотя может применяться комбинация умного указателя и сборщика мусора (Python).
У каждого способа управления динамической памятью есть свои плюсы и минусы. В основном приходится жертвовать производительностью программы ради скорости и простоты разработки, либо наоборот: высокая производительность, но и высокая требовательность к программистам, из-за чего вероятность ошибиться при разработке программы выше и медленней сам процесс.
В IT-сфере огромное количество информации, и с каждым днём становится только больше. Чтобы ориентироваться в этом объёме данных, нужно иметь хорошую память, ведь даже чтобы поискать что-то в интернете, нужно помнить о том, что это что-то существует. Как улучшить свою память, чтобы идти в ногу со временем? Узнаем у экспертов.
Это может показаться странным, но программисту сейчас нет нужды запоминать множество вещей — IT настолько быстро развивающаяся индустрия, что то, что вы запомнили сегодня, может оказаться морально устаревшим уже к концу этого года. Особенно ярко это проявляется в мире фронтенд-разработки.
Куда более полезным для современного разработчика является умение быстро находить нужную информацию и грамотно формулировать поисковые запросы, а также способность выбирать из огромного потока информации только нужную и достоверную часть. Как развить эти навыки? На мой взгляд, они могут прийти только с опытом, есть лишь несколько небольших советов:
- Прежде чем искать ответ на свой вопрос, проговорите его, убедитесь, что он максимально лаконичен и полностью отражает суть вашей проблемы.
- Если вы хотите найти что-то в документации, то определитесь, к какой категории относится ваша проблема, чтобы не терять времени на блуждание по разным разделам.
- Ну и самое главное: когда копируете код со StackOverflow, копируйте из ответа, а не из вопроса.
Действительно важная информация, которую нужно помнить разработчику, всегда очень абстрактна и описывает не конкретные реализации, а основные концепции. Этой информации не так много, и запомнить её может каждый без особых усилий, а всякие мелочи вы всё равно забудете через пару недель после того, как перестанете с ними работать. Можно, конечно, упражнения разные поделать, их в сети описано бесчисленное множество, осталось только найти и выбрать, но зачем?
Программирование как сфера деятельности — это прекрасный образец каждодневной тренировки памяти. Помнить синтаксис и алгоритмы — ежедневная рутина, которая перерастает в механическую память, когда мозг не включается, а «руки помнят». Естественно, это происходит не за один день и даже не за неделю, этот механический опыт передаётся тщательными тренировками и практическими заданиями.
Поэтому, по моему мнению, для программиста забыть синтаксис, операторы, способы объявления функций и т. д. — это как для строителя забыть, как пользоваться молотком.
Для профилактики некоторые упражнения для памяти всё-таки лучше попрактиковать: в моём случае это посмотреть мельком на телефон и вспомнить, сколько там было времени; также по ходу движения запоминать номерные знаки автомобилей — чем больше, тем лучше; вспомнить, что было вчера — тоже отличный вариант!
Память это, конечно, очень важно, и прекрасно помнить всё, но на случай тотального забытья всегда есть Google!
Хотелось бы сразу предостеречь начинающих программистов от зубрёжки. В отличие от языков, на которых мы разговариваем, в языках программирования очень мало исключений из правил, а количество ключевых слов и конструкций редко превышает сотню. Более того, при написании программ, если вы, конечно, не собираетесь работать в блокноте, всегда можно воспользоваться современными редакторами кода и IDE, которые анализируют код, делают подсказки, отмечают ваши ошибки, тем самым ускоряя разработку.
Но существуют вещи в программировании, которые действительно необходимо выучить по двум причинам. Во-первых, чтобы успешно пройти собеседование, продемонстрировав свои навыки, а во-вторых, просто для того, чтобы не тратить своё время на поиск одной и той же информации. К таким вещам относятся, например, основные алгоритмы и шаблоны (паттерны) проектирования, а также синтаксис и основные функции языка программирования, на котором вы собираетесь писать основную часть времени.
Как же лучше всего выучить эти вещи? Просто вызубрить, не вникая в суть? Вряд ли. Можно либо найти в интернете тренировки для памяти и выполнять упражнения «запомни ряд слов и повтори», «запомни цифры и повтори», либо учить стихи. Да, это бесспорно пойдёт вам и вашему мозгу на пользу, но сделает ли это из вас великого программиста? Скорее всего, нет. А вот что действительно может помочь, так это постоянная практика. Если вы будете каждый день хотя бы по паре часов писать код на своём любимом языке программирования (или на том, с которым вы хотите работать в дальнейшем) и не просто бездумно копировать код с таких сайтов, как StackOverflow, а именно писать, понимая, что делает каждый символ вашего кода, то очень скоро вы поймаете себя на мысли, что пишете по памяти, и вам не приходится каждую конструкцию подсматривать в учебнике/документации.
Кроме того, могу посоветовать «сохранять себе в копилку» интересные конструкции и фрагменты кода для того, чтобы в будущем не писать повторно тот же алгоритм, а подсмотреть у себя же. Такие кусочки принято называть сниппетами кода, от английского snippet — отрывок, фрагмент. Существуют и бесплатные сервисы для хранения таких кусочков кода, например GitHub Gist.
Подводя итог, хочу порекомендовать не заучивать всё подряд, а в первую очередь понимать, что вы пишете и почему ваш код работает именно так, а не иначе. Достаточно выучить самые основные и наиболее часто используемые вещи, и, скорее всего, они сами быстро запомнятся. Остальное важно уметь быстро найти в учебнике или в документации.
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
- загружать свой собственный байт-код для выполнения;
- хранить значения переменных и структуры данных, которые используются в процессе работы;
- загружать внешние модули, которые необходимы программе для выполнения задач.
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
- благодаря упомянутому принципу, стек позволяет очень быстро выполнять операции с данными — все манипуляции производятся с «верхней книгой в стопке». Книга добавляется в самый верх, если нужно сохранить данные, либо берётся сверху, если данные требуется прочитать;
- существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции;
- в стековой памяти хранится стек вызовов — информация о ходе выполнения цепочек вызовов функций в виде стековых кадров. Каждый стековый кадр это набор блоков данных, в которых хранится информация, необходимая для работы функции на определённом шаге — её локальные переменные и аргументы, с которыми её вызывали. Например, каждый раз, когда функция объявляет новую переменную, она добавляет её в верхний блок стека. Затем, когда функция завершает свою работу, очищаются все блоки памяти в стеке, которые функция использовала — иными словами, очищаются все блоки ее стекового кадра;
- каждый поток многопоточного приложения имеет доступ к своему собственному стеку;
- управление стековой памятью простое и прямолинейное; оно выполняется операционной системой;
- в стеке обычно хранятся данные вроде локальных переменных и указателей;
- при работе со стеком есть вероятность получать ошибки переполнения стека (stack overflow), так как максимальный его размер строго ограничен. Например, ошибка при составлении граничного условия в рекурсивной функции совершенно точно приведёт к переполнению стека;
- в большинстве языков существует ограничение на размер значений, которые можно сохранить в стек;
Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформатеКуча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
- операции на куче производятся несколько медленнее, чем на стеке, так как требуют дополнительного этапа для поиска данных;
- в куче хранятся данные динамических размеров, например, список, в который можно добавлять произвольное количество элементов;
- куча общая для всех потоков приложения;
- вследствие динамической природы, куча нетривиальна в управлении и с ней возникает большинство всех проблем и ошибок, связанных с памятью. Способы решения этих проблем предоставляются языками программирования;
- типичные структуры данных, которые хранятся в куче — это глобальные переменные (они должны быть доступны для разных потоков приложения, а куча как раз общая для всех потоков), ссылочные типы, такие как строки или ассоциативные массивы, а так же другие сложные структуры данных;
- при работе с кучей можно получить ошибки выхода за пределы памяти (out of memory), если приложение пытается использовать больше памяти, чем ему доступно;
- размер значений, которые могут храниться в куче, ограничен лишь общим объёмом памяти, который был выделен операционной системой для программы.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
Владение
![]()
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.Читайте так же другие части серии:
Ссылки
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
За вычитку перевода отдельное спасибо Александру Максимовскому и Катерине Шибаковой
Большинство современных микроконтроллеров имеют Гарвардскую архитектуру и содержат 3 вида памяти:
- память программ FLASH;
- оперативная память (ОЗУ) SRAM (Static RAM);
- энергонезависимая память данных EEPROM.
Адресные пространства указанных видов памяти, как правило, разделены. Способы адресации и доступа к этим областям памяти также различны. Такая структура позволяет центральному процессору работать одновременно как с памятью программ, так и с памятью данных, что существенно увеличивает производительность. Каждая из областей памяти данных (SRAM и EEPROM) также расположена в своем адресном пространстве.
Память программ
Память программ представляет собой электрически стираемое ППЗУ (FLASH) и может поддерживать команды с разрядностью больше 8 бит. В некоторых микроконтроллерах память программ разделена на 2 секции:
- секцию загрузчика (Boot Program);
- секцию прикладных программ (Application Program).
Память программ чаще всего является электрически перепрограммируемой, количество циклов перезаписи превышает 10 тысяч.
Большинство микроконтроллеров поддерживают внутрисхемное программирование , т. е. загрузку программы в микроконтроллер можно осуществлять после монтажа на плату посредством специального разъема программирования.
Для адресации памяти программ используется счетчик команд (Program Counter – PC).
В памяти программ также находится вектор сброса — в момент подачи питания микроконтроллер начинает выполнение программы с этого адреса, и здесь размещается команда перехода к началу исполняемой программы. Кроме того, память программ содержит таблицу векторов прерываний. При возникновении прерывания после сохранения в стеке текущего значения счетчика команд происходит выполнение команды, расположенной по адресу соответствующего вектора. Поэтому по данным адресам располагаются команды перехода к подпрограммам обработки прерываний.
Положение вектора сброса и таблицы векторов прерываний может быть перенесено из секции прикладных программ в секцию загрузчика.В некоторых случаях память программ может использоваться не только для хранения кода программы, но и для хранения различных констант.
Оперативная память
Оперативная память, как правило, содержит 3 области:
- регистры общего назначения;
- служебные регистры;
- память для хранения данных.
Регистры общего назначения (РОН) находятся в непосредственной близости к АЛУ. Однако в микроконтроллерах некоторых фирм (в частности, PIC фирмы Microchip) имеется только один рабочий регистр, играющий роль одного из операндов в командах.
Применение набора регистров общего назначения в сочетании с конвейерной обработкой позволяет АЛУ выполнять одну операцию (извлечение операндов из набора регистров, выполнение команды и запись результата обратно в регистр) за один такт.Служебные регистры имеют свои имя, адрес и назначение. Они предназначены для конфигурации и обслуживания периферийных узлов микроконтроллера. Краткая характеристика служебных регистров должна быть приведена в руководстве по использованию микроконтроллера (Data Sheet).
Среди служебных регистров есть, как правило, один регистр, используемый наиболее часто в процессе выполнения программ. Это регистр состояния. Он содержит набор флагов, показывающих текущее состояние микроконтроллера. Большинство флагов автоматически устанавливаются в «1» или сбрасываются в «0» при наступлении определенных событий (в соответствии с результатом выполнения команд). Все биты этого регистра доступны как для чтения, так и для записи. Эта информация анализируется при выполнении условных переходов. При возникновении прерываний содержимое регистра состояния необходимо сохранять программно (чаще всего это является «заботой» компилятора).Остальная часть оперативной памяти предназначена для хранения пользовательских данных.
Энергонезависимая память данных
Энергонезависимая память данных (EEPROM) организована таким образом, что содержимое каждого байта отдельно может быть считано или записано. Количество циклов перезаписи энергонезависимой памяти превышает 100 тысяч. Энергонезависимая память предназначена для хранения настроек и конфигурации программы, то есть тех данных, которые должны сохраняться при пропадании питания.
Чтение и запись данных в EEPROM, как правило, осуществляется посредством использования соответствующих регистров из области служебных регистров SRAM. Как правило, это:
Читайте также: