
Как выгрузить таблицу из sql в excel
Мало пользователей, да и начинающих программистов, которые знают о возможности Excel подключаться к внешним источникам, и в частности к SQL серверу, для загрузки данных из этих источников. Эта возможность достаточно полезна, поэтому сегодня мы займемся ее рассмотрением.
Функционал Excel получения данных из внешних источников значительно упростит выгрузку данных с SQL сервера, так как Вам не придется просить об этом программиста, к тому же данные попадают сразу в Excel. Для этого достаточно один раз настроить подключение и в случае необходимости получать данные в Excel из любых таблиц и представлений Views, из базы настроенной в источнике, естественно таких источников может быть много, например, если у Вас несколько баз данных.
Задача для получения данных в Excel
И для того чтобы более понятно рассмотреть данную возможность, мы это будем делать как обычно на примере. Другими словами допустим, что нам надо выгрузить данные, одной таблицы, из базы SQL сервера, средствами Excel, т.е. без помощи вспомогательных инструментов, таких как Management Studio SQL сервера.
Примечание! Все действия мы будем делать, используя Excel 2010. SQL сервер у нас будет MS Sql 2008.
И для начала разберем исходные данные, допустим, есть база test, а в ней таблица test_table, данные которой нам нужно получить, для примера будут следующими:
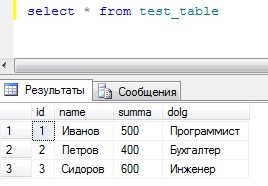
Эти данные располагаются в таблице test_table базы test, их я получил с помощью простого SQL запроса select, который я выполнил в окне запросов Management Studio. И если Вы программист SQL сервера, то Вы можете выгрузить эти данные в Excel путем простого копирования (данные не большие), или используя средство импорта и экспорта MS Sql 2008. Но сейчас речь идет о том, чтобы простые пользователи могли выгружать эти данные.
Заметка! Если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server.
Настройка Excel для получения данных с SQL сервера
Настройка, делается достаточно просто, но требует определенных навыков и консультации администратора SQL сервера. Вы, конечно, можете попросить программиста настроить Excel на работу или сделать это сами, просто спросив пару пунктов, а каких мы сейчас узнаем.
И первое что нам нужно сделать, это конечно открыть Excel 2010. Затем перейти на вкладку «Данные» и нажать на кнопку «Из других источников» и выбрать «С сервера SQL Server»
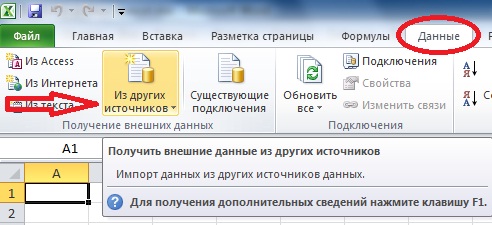
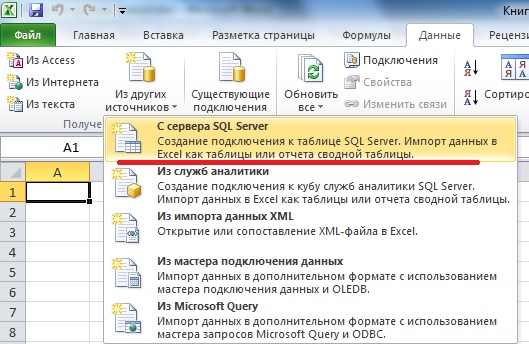
Затем у Вас откроется окно «Мастер подключения данных» в котором Вам необходимо, указать на каком сервере располагается база данных и вариант проверки подлинности. Вот именно это Вам придется узнать у администратора баз данных, а если Вы и есть администратор, то заполняйте поля и жмите «Далее».
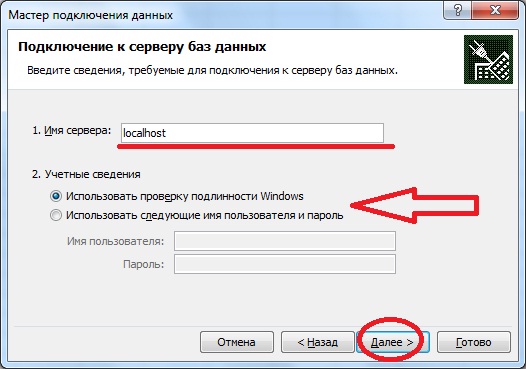
- Имя сервера – это адрес Вашего сервера, здесь можно указывать как ip адрес так и DNS имя, в моем случае сервер расположен на этом же компьютере поэтому я и указал localhost;
- Учетные данные – т.е. это логин и пароль подключения к серверу, здесь возможно два варианта, первый это когда в сети Вашей организации развернута Active directory (Служба каталогов или домен), то в этом случае можно указать, что использовать те данные, под которыми Вы загрузили компьютер, т.е. доступы доменной учетки, и в этом случае никаких паролей здесь вводить не надо, единственное замечание что и на MSSql сервере должна стоять такая настройка по проверки подлинности. У меня именно так и настроено, поэтому я и выбрал этот пункт. А второй вариант, это когда администратор сам заводит учетные данные на SQL сервере и выдает их Вам, и в этом случае он должен их Вам предоставить.
Далее необходимо выбрать базу, к которой подключаться, в нашем примере это база test. Также это подключение можно настроить сразу на работу с определенной таблицей или представлением, список таблиц и представлений у Вас будет отображен, давайте мы сделаем именно так и настроем подключение сразу на нашу таблицу test_table. Если Вы не хотите этого, а хотите чтобы Вы подключались к базе и потом выбирали нужную таблицу, то не ставьте галочку напротив пункта «Подключаться к определенной таблице», а как я уже сказал, мы поставим эту галочку и жмем «Далее».
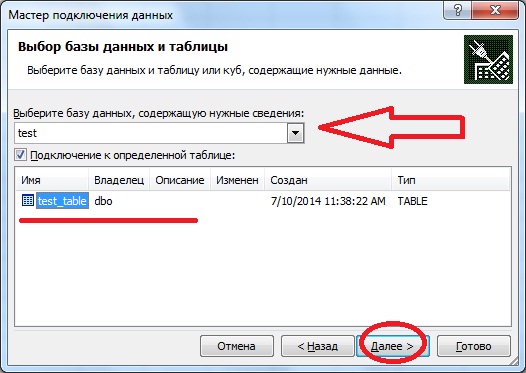
В следующем окне нам предложат задать имя файла подключения, название и описание, я например, написал вот так:

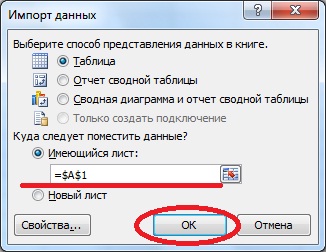
После того как Вы нажмете «Готово» у Вас откроется окно импорта этих данных, где можно указать в какие ячейки копировать данные, я например, по стандарту выгружу данные, начиная с первой ячейки, и жмем «ОК»:
В итоге у меня загрузятся из базы вот такие данные:
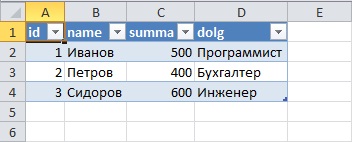
Т.е. в точности как в базе. Теперь когда, например, изменились данные в этой таблице, и Вы хотите выгрузить их повторно Вам не нужно повторять все заново, достаточно в excel перейти на вкладку «Данные» нажать кнопку «Существующие подключения» и выбрать соответствующее, т.е. то которое Вы только что создали.
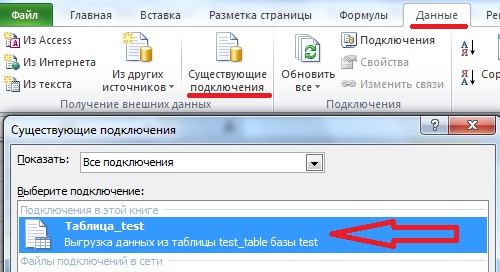
Вот собственно и все, как мне кажется все достаточно просто.
Таким способом получать данные в Excel из базы SQL сервера очень удобно и главное быстро, надеюсь, Вам пригодятся эти знания полученные в сегодняшнем уроке. Удачи!
В этой статье приводится информация о подключении, которую вы должны предоставить, и необходимые настройки подключения для импорта данных из Excel и экспорта данных в Excel с помощью SQL Server Integration Services (SSIS).
В следующих разделах содержится вся информация, которая потребуется для успешной работы с приложением Excel из служб SSIS, а также для понимания и устранения распространенных проблем:
Средства, которые можно использовать.
Файлы, которые вам потребуются.
Сведения о подключении, которые необходимо предоставить, и параметры, которые необходимо настроить для загрузки данных в/из Excel с использованием SSIS.
-
в качестве источника данных.
- Укажите имя файла Excel и путь к нему.
- Выберите версию Excel.
- Укажите, содержит ли первая строка имена столбцов.
- Укажите лист или диапазон, который содержит данные.
Известные проблемы и ограничения.
- Проблемы с типами данных.
- Проблемы с импортом.
- Проблемы с экспортом.
Средства, которые можно использовать
Вы можете импортировать и экспортировать данные в Excel с использованием SSIS при помощи любого из следующих инструментов.
SQL Server Integration Services (SSIS) . Создайте пакет SSIS, настроив для него Excel в качестве источника или назначения с помощью диспетчера подключений Excel. (В этой статье не рассматривается создание пакетов SSIS.)
Получение файлов, необходимых для подключения к Excel
Прежде чем импортировать или экспортировать данные в Excel с использованием SSIS, вам может потребоваться скачать компоненты подключения для Excel, если они еще не установлены. По умолчанию компоненты подключений для Excel не устанавливаются.
Используйте таблицу из статьи Не удалось использовать интерфейсы Access ODBC, OLEDB или DAO за пределами Office Click-to-Run, чтобы понять, нужны ли дополнительные компоненты для вашей среды.
Примечание. Системные драйверы Office поддерживаются только в определенных случаях, конкретные руководства см. в статье Рекомендации по автоматизации Office на стороне сервера.
Назначение Excel в качестве источника данных
Сначала необходимо указать, что вам требуется установить подключение к Excel.
В службах SSIS
В службах SSIS создайте диспетчер соединений Excel для подключения к файлу источника или назначения Excel. Создать диспетчер соединений можно несколькими способами:
Щелкните правой кнопкой в области Диспетчеры соединений и выберите команду Создать соединение. В диалоговом окне Добавление диспетчера соединений со службами SSIS выберите EXCEL и затем Добавить.
В меню Службы SSIS выберите Создать соединение. В диалоговом окне Добавление диспетчера соединений со службами SSIS выберите EXCEL и затем Добавить.
Диспетчер соединений необходимо создавать в то время, как вы настраиваете источник Excel или назначение Excel на странице Диспетчер соединений в редакторе источника Excel или в редакторе назначения Excel.
В мастере импорта и экспорта SQL Server
В мастере импорта и экспорта на странице Выбор источника данных или Выбор назначения выберите Microsoft Excel в списке Источник данных.
Если вы не видите Excel в списке источников данных, убедитесь, что используется 32-разрядная версия мастера. Компоненты подключений для Excel обычно представляют собой 32-разрядные файлы и не отображаются в 64-разрядной версии мастера.
Файл Excel и путь к нему
В первую очередь необходимо предоставить имя файла Excel и путь к нему. Это можно сделать в редакторе диспетчера соединений Excel в пакете служб SSIS либо на странице Выбор источника данных или Выбор назначения в мастере импорта и экспорта.
Введите имя файла и путь к нему в следующем формате:
Для файла на локальном компьютере: C:\TestData.xlsx.
Для файла в общей сетевой папке: \\Sales\Data\TestData.xlsx.
Также можно нажать кнопку Обзор и выбрать электронную таблицу в диалоговом окне Открыть.
Подключить защищенный паролем файл Excel нельзя.
Версия Excel
Далее следует предоставить сведения о версии файла Excel. Это можно сделать в редакторе диспетчера соединений Excel в пакете служб SSIS либо на странице Выбор источника данных или Выбор назначения в мастере импорта и экспорта.
Выберите версию Microsoft Excel, в которой был создан файл, или другую совместимую версию. Например, если вам не удалось установить компоненты подключений для версии 2016, вы можете установить компоненты для версии 2010 и выбрать в этом списке вариант Microsoft Excel 2007-2010.
Если у вас установлены старые версии компонентов подключений, вы не сможете выбрать более новые версии Excel в этом списке. Список Версия Excel содержит все версии Excel, поддерживаемые службами SSIS. Наличие элементов в этом списке не означает, что необходимые компоненты подключений были установлены. Например, вариант Microsoft Excel 2016 будет присутствовать в этом списке даже в том случае, если у вас не установлены компоненты подключений для версии 2016.
Первая строка содержит имена столбцов
Если вы импортируете данные из Excel, далее необходимо указать, содержит ли первая строка данных имена столбцов. Это можно сделать в редакторе диспетчера соединений Excel в пакете служб SSIS или на странице Выбор источника данных в мастере импорта и экспорта.
- Если этот параметр отключен, поскольку в данных источника отсутствуют имена столбцов, мастер будет использовать в качестве заголовков столбцов значения F1, F2 и т. д.
- Если данные содержат имена столбцов, но этот параметр отключен, мастер импортирует строку имен столбцов как первую строку данных.
- Если данные не содержат имена столбцов, но этот параметр включен, мастер использует первую строку данных источника как имена столбцов. В этом случае первая строка в данных источника не включается в сами данные.
Если вы экспортируете данные из Excel и включили этот параметр, первая строка экспортированных данных будет включать имена столбцов.
Листы и диапазоны
В качестве источника или назначения для данных можно использовать три типа объектов Excel: лист, именованный диапазон или неименованный диапазон ячеек, который задается с помощью адреса.
Лист Чтобы указать лист, добавьте в конец имени листа символ $ и окружите строку разделителями, например [Листt1$] . Также можно выполнить поиск имени, заканчивающегося символом $ , в списке существующих таблиц и представлений.
Именованный диапазон Чтобы указать именованный диапазон, используйте имя диапазона, например Мой_диапазон. Также можно выполнить поиск имени, не заканчивающегося символом $ , в списке существующих таблиц и представлений.
Неименованный диапазон Чтобы указать диапазон ячеек, которым не были заданы имена, добавьте символ $ после имени листа, добавьте спецификацию диапазона и окружите строку разделителями, например [Лист1$A1:B4] .
Чтобы выбрать или указать тип объекта Excel, который вы хотите использовать в качестве источника или назначения для данных, выполните одно из следующих действий:
В службах SSIS
В службах SSIS на странице Диспетчер соединений в редакторе источника Excel или редакторе назначения Excel выполните одно из следующих действий:
Чтобы использовать лист или именованный диапазон, выберите Таблица или представление в разделе Режим доступа к данным. Затем выберите лист или именованный диапазон в списке Имя листа Excel.
Чтобы использовать неименованный диапазон, который задается по адресу, выберите Команда SQL в разделе Режим доступа к данным. Затем в поле Текст команды SQL введите запрос, аналогичный представленному ниже примеру:
В мастере импорта и экспорта SQL Server
В мастере импорта и экспорта выполните одно из следующих действий:
При импорте из Excel выполните одно из следующих действий:
Чтобы использовать лист или именованный диапазон, на странице Выбор копирования таблицы или запроса выберите Скопировать данные из одной или нескольких таблиц или представлений. Затем на странице Выбор исходных таблиц и представлений в столбце Источник укажите исходные листы и именованные диапазоны.
Чтобы использовать неименованный диапазон, который задается по адресу, на странице Выбор копирования таблицы или запроса выберите Написать запрос, указывающий данные для передачи. Затем на странице Определение исходного запроса введите запрос, аналогичный показанному ниже:
При экспорте в Excel выполните одно из следующих действий:
Чтобы использовать лист или именованный диапазон, на странице Выбор исходных таблиц и представлений в столбце Назначение выберите целевые листы и именованные диапазоны.
Чтобы использовать неименованный диапазон, который задается по адресу, на странице Выбор исходных таблиц и представлений в столбце Назначение укажите диапазон в следующем формате без использования разделителей: Sheet1$A1:B5 . Мастер автоматически добавит разделители.
После выбора или ввода объектов Excel для импорта или экспорта вы также можете выполнить следующие действия на странице Выбор исходных таблиц и представлений мастера:
Проверить сопоставления столбцов между источником и назначением, выбрав команду Изменить сопоставления.
Выполнить предварительный просмотр данных, чтобы убедиться в правильности выбора, с помощью команды Предварительный просмотр.
Проблемы с типами данных
Типы данных
Драйвер Excel распознает только ограниченный набор типов данных. Например, все числовые столбцы воспринимаются как тип double (DT_R8), а все строковые столбцы (кроме столбцов типа memo) воспринимаются как строки в Юникоде длиной 255 символов (DT_WSTR). Службы SSIS сопоставляют типы данных Excel следующим образом:
Числовой — с плавающей запятой двойной точности (DT_R8)
Денежный — денежный (DT_CY)
Логический — логический (DT_BOOL)
Дата и время — datetime (DT_DATE)
Строковый — строка в Юникоде длиной в 255 символов (DT_WSTR)
Memo — текстовый поток в Юникоде (DT_NTEXT)
Преобразования типов данных и длины по умолчанию
В службах SSIS неявное преобразование типов данных не выполняется. В результате, возможно, потребуется использовать преобразование "Производный столбец" или "Преобразование данных" для явного преобразования данных Excel до их загрузки в назначение, отличное от Excel, либо для преобразования данных из источника, отличного от Excel, до их загрузки в назначение Excel.
Ниже приведены некоторые примеры преобразований, которые могут потребоваться:
Преобразование между строковыми столбцами Excel в Юникоде и строковыми столбцами в формате с конкретными кодовыми страницами, отличными от Юникода.
Преобразование между строковыми столбцами Excel длиной в 255 символов и строковыми столбцами другой длины.
Преобразование между числовыми столбцами Excel с плавающей запятой двойной точности и числовыми столбцами других типов.
Если вы используете мастер импорта и экспорта и вам требуется выполнить некоторые из этих преобразований данных, мастер выполнит настройку необходимых преобразований автоматически. В результате, даже если вам требуется использовать пакет служб SSIS, часто бывает полезно создать первичный пакет с помощью мастера импорта и экспорта. В таком случае мастер создаст и настроит диспетчеры соединений, источники, преобразования и назначения автоматически.
Проблемы с импортом
Пустые строки
Если в качестве источника указан лист или диапазон, драйвер считывает непрерывный блок ячеек, начиная с первой непустой ячейки в верхнем левом углу листа или диапазона. В результате данные могут начинаться не со строки 1, однако в данных источника не должны присутствовать пустые строки. Например, пустые строки не допускаются между заголовками столбцов и строками данных, а также после названия в верхней части листа.
Если над данными располагаются пустые строки, вы не сможете выполнить их запрос в качестве листа. В Excel необходимо выбрать диапазон данных, присвоить ему имя и выполнить запрос к именованному диапазону, а не к листу.
Отсутствующие значения
Драйвер Excel считывает определенное количество строк (по умолчанию 8 строк) в указанном источнике для определения типа данных каждого столбца. Если столбец содержит смешанные типы данных, особенно если числовые данные смешаны с текстовыми данными, драйвер принимает решение в пользу того типа данных, которого больше, и возвращает значения NULL в ячейки, содержащие данные другого типа. (В случае равенства преимущество получает числовой тип.) Большинство параметров форматирования ячеек в листе Excel не затрагивает это определение типа данных.
Можно изменить поведение драйвера Excel, указав режим импорта для импорта всех значений в виде текста. Чтобы указать режим импорта, добавьте IMEX=1 к значению расширенных свойств в строке соединения диспетчера соединений с Excel в окне "Свойства".
Усеченный текст
Когда драйвер определяет, что столбец Excel содержит текстовые данные, он выбирает тип данных (строковый или memo) на основании самого длинного значения. Если драйвер не обнаруживает значений длиннее 255 символов в выбираемых строках, он считает, что столбец является строковым с длиной 255 символов, а не столбцом типа memo. Поэтому значения длиннее 255 символов могут быть усечены.
Чтобы импортировать данные из столбца типа memo без усечения, можно воспользоваться любым из двух способов:
Убедитесь, что столбец типа memo как минимум в одной из выбранных строк содержит значение длиной более 255 символов.
Увеличьте число строк в выборке драйвера, чтобы включить такую строку. Чтобы увеличить количество строк, включаемых в выборку, достаточно увеличить значение TypeGuessRows в следующем разделе реестра:
Проблемы с экспортом
Создание нового файла назначения
В службах SSIS
Создайте диспетчер соединений Excel с именем создаваемого файла Excel и путем к нему. Затем в редакторе назначения Excel в разделе Имя листа Excel выберите Создать, чтобы создать лист назначения. В этот момент службы SSIS создают новый файл Excel с указанным листом.
В мастере импорта и экспорта SQL Server
На странице Выбор назначения нажмите кнопку Обзор. В диалоговом окне Открыть перейдите в папку, в которой требуется создать новый файл Excel, укажите имя этого файла и выберите Открыть.
Экспорт в достаточно большой диапазон
Экспорт длинных текстовых значений
Чтобы успешно сохранять в столбцы Excel строки, имеющие длину более 255 символов, драйвер должен распознать тип данных целевого столбца как memo , а не как string.
- Если в существующей целевой таблице уже содержатся строки данных, то в столбце типа memo в первых нескольких строках, которые проверит драйвер, должен содержаться, по крайней мере, один экземпляр значения, имеющего длину более 255 символов.
См. также
Дополнительные сведения о компонентах и процедурах, описываемых в этой статье, см. в следующих статьях:
В Службы Master Data ServicesНадстройка для Excelдля работы с данными необходимо сначала экспортировать их из репозитория MDS.
Если перед загрузкой набора данных нужно отфильтровать его, см. раздел Фильтрация данных перед их экспортом (надстройка MDS для Excel).
Предварительные требования
Для выполнения этой процедуры:
- Необходимо иметь разрешение на доступ к функциональной области Обозреватель .
Экспорт данных из MDS в Excel
Откройте Excel и на вкладке Основные данные установите соединение с репозиторием MDS. Дополнительные сведения см. в разделе Соединение с репозиторием MDS (надстройка MDS для Excel).
На панели Обозреватель основных данных выберите модель и версию. Заполняется список сущностей.
Если панель Обозреватель основных данных не видна, в группе Соединение и загрузка нажмите Показать обозреватель.
Если панель Обозреватель основных данных отключена, то причина этого заключается в том, что существующий лист уже содержит данные, управляемые MDS. Чтобы включить эту панель, откройте новый лист.
В области Обозреватель основных данных в списке сущностей дважды щелкните сущность, которую нужно загрузить.
В Excel загружается только первый миллион элементов. Чтобы отфильтровать список перед загрузкой, на ленте в группе Подключение и загрузка нажмите кнопку Фильтр.
В столбцах, которые являются ограниченными списками (атрибутами на основе домена), по умолчанию загружаются только первые 25 000 значений. Это число можно изменить в свойстве MaximumDbaEntitySize в файле excelusersettings.config, расположенном на компьютере, на котором установлена программа Excel. Этот файл расположен в каталоге C:\Users\\AppData\Local\Microsoft\Microsoft SQL Server\130\MasterDataServices\.
Если количество значений для атрибута на основе домена превышает настройку свойства MaximumDbEntitySize, список значений не загружается.
Если при загрузке разделенных текстом данных с помощью надстройки для Microsoft Excel в 32-разрядную версию Excel свойствам Число ячеек для загрузки и Число ячеек для публикации присвоено максимальное значение 1000, возникнет ошибка нехватки памяти. Для использования максимальных значений свойств Число ячеек для загрузки и Число ячеек для публикации необходимо использовать 64-разрядную версию Excel.
Небольшое предисловие. Имеется база данных MS SQL, в которой содержится определённая таблица, её нужно загрузить в Excel.
Зачем использовать такую модель? Базы данных SQL могут быть объёмом гораздо больше чем файлы Excel и работают гораздо быстрее, а Excel используется как инструмент тонкой настройки загруженной таблицы.
Задача проста, но есть несколько моментов: необходимо знать, как называется инстанс (экземпляр) где находится база данных, естественно, нужно знать учётные данные, нужно знать название таблицы. Что ж, приступим.
Я предпочитаю в таких случаях использовать Microsoft Management Studio, для поиска основных данных. Найти ярлык можно в меню Пуск.

В консоли MS SQL есть несколько полей:
Server Type - можно выбрать тип подключения (в этом случаем остаётся Database Engine);
- Analysis Services - сервисы аналитики;
- Reporting Services - сервисы отчётов;
- Integration Services - сервисы интеграции (встраивания).
Далее следует имя сервера (его можно задать на этапе установки).
Тип аутентификации - WIndows Authentication или SQL Server Authentication, эти пункты позволяют выбрать тип проверки пользователя. Windows - можно войти под логином и паролем для операционной системы, SQL Server - под специальной учётной записью sa и заданным для неё паролем.
Оставим первый вариант - он проще (но запомните - только для тестов!). Хорошим тоном считается смешанная аутентификация и смена пароля для учётки sa на случай непредвиденных ситуаций.
Видно, что имя сервера - BLACKPRINCE, логин axiro. Пароль не скажу:) Осталось нажать кнопку "Connect" и зайти в базу данных.

Поди цифрой 1 - список баз данных, под 2 - тестовая база с именем Test, под 3 - запущенный SQL Server Agent - он должен быть запущен иначе база данных может быть не видна для других программ, если на нем стоит крест - щёлкнуть правой кнопкой мышки и выбрать "Start".
Исходные данные есть, теперь необходимо создать таблицу с данными. Это можно сделать через графический интерфейс, но лучше воспользоваться запросом - "New Query".

Откроется окно запроса.

Все запросы будут производиться на языке Transact SQL. У него очень много общего с синтаксисом SQL, но есть и много отличий.
Создаём базу данных
Если необходимо создать новую базу данных, например, магазины (SHOPS), синтаксис будет следующий:
CREATE DATABASE SHOPS
Обязательно после написания запроса нажать "Execute" или F5! В противном случае запрос не будет выполнен.

Под цифрой 1 - "Execute", под 2 - текст запроса, под 3 - результат выполнения. Если в процессе выполнения будут выявлены ошибки, они незамедлительно будут показаны. Пока всё идёт по плану.
Создаём таблицу
Если необходимо выполнить запрос к определённой базе данных - щёлкаем правой кнопкой на неё и выбираем "New query".

В окне запроса введём текст запроса. Цель - создать таблицу с четырьмя столбцами: номер магазина, название магазина, выручка магазина, менеджер. Лучше все столбцы называть по английски (хотя бы на первоначальном этапе).
CREATE TABLE dbo.Shops
(ShopID int PRIMARY KEY NOT NULL,
ShopName varchar(25) NOT NULL,
Revenue money NULL,
Manager text NULL)
GO

Нажать "Execute". Таблица создалась. Проверить можно раскрыв дерево базы данных и раскрыть группу "Tables".

Цель достигнута. В запросе также были упомянуты типы данных (varchar(25), money, text, PRIMARY KEY). Соответственно - varchar это длина текста, в скобках указано, что длина названия магазина может быть до 25 символов включительно, money - тип данных, представляющий денежные (валютные) значения, text - обычный текст, PRIMARY KEY - ограничение, позволяющее однозначно идентифицировать каждую запись в таблице SQL. Также есть атрибут NULL и NOT NULL - позволяет значениям принимать нулевое значение или не принимать (может в поле стоять ноль или не может).
Добавим в таблицу одну строчку (пока). Открываем окно нового запроса базе данных и добавляем запрос.
INSERT INTO dbo.Shops VALUES ( '1', 'Ручеёк', '120000', 'Петров В.И.')

Добавилась одна строка.
Импорт данных SQL в Excel
Со стороны Excel действий будет гораздо меньше. Переходим на вкладку "Данные", нажимаем кнопку "Получение внешних данных", "Из других источников", "С сервера SQL Server".

Как было написано выше, нужно указать имя сервера SQL - BLACKPRINCE, и выбрать проверку подлинности - Windows. Нажать "Далее".

В следующем окне выберем базу данных SHOPS и отметим галкой таблицу Shops. Если нужно выбрать несколько таблиц - отметить галкой соответствующую настройку. Нажать "Далее".

В следующем окне Excel предложит сохранить файл для подключения к базе данных с настройками. Нажать "Готово".

Теперь можно выбрать расположение загруженной таблицы и указать необходимые настройки. Я пока указывать их не буду, просто нажму "ОК". Таблица будет размещена в ячейку A1.

Цель достигнута! Таблица из базы данных перекочевала в Excel и теперь над ней можно совершать привычные действия.
В следующих уроках мы поговорим о более сложных манипуляциях с запросами к базам данных .
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Состав колонок будет следующим:

В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
Для тестирования добавим spring-boot-starter-test
И еще нам нужен сам драйвер для подключения к БД
Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List с помощью простого метода:
А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "< ? = call message_ref(?, ?) >", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
В итоге наш метод генерации имеет следующий вид:
4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
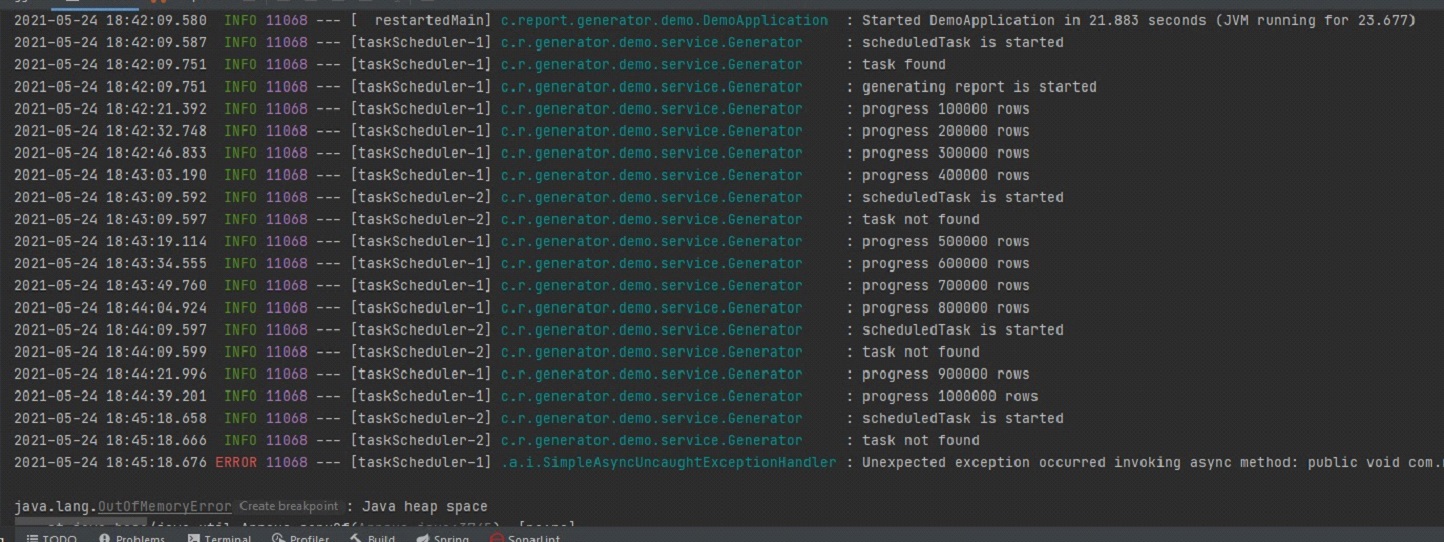
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.
Читайте также: