
Как выглядит для программы основная память
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Аппаратное управление памятью
Большинство компьютеров используют большое количество различных запоминающих устройств, таких как: ПЗУ, ОЗУ, жесткие диски, магнитные носители и т.д. Все они представляют собой виды памяти, которые доступны через разные интерфейсы. Два основных интерфейса — это прямая адресация процессором и файловые системы. Прямая адресация подразумевает, что адрес ячейки с данными может быть аргументом инструкций процессора.
Режимы работы процессора x86:
- реальный — прямой доступ к памяти по физическому адресу
- защищенный — использование виртуальной памяти и колец процессора для разграничения доступа к ней
Виртуальная память — это подход к управлению памятью компьютером, который скрывает физическую память (в различных формах, таких как: оперативная память, ПЗУ или жесткие диски) за единым интерфейсом, позволяя создавать программы, которые работают с ними как с единым непрерывным массивом памяти с произвольным доступом.
- поддержка изоляции процессов и защиты памяти путём создания своего собственного виртуального адресного пространства для каждого процесса
- поддержка изоляции области ядра от кода пользовательского режима
- поддержка памяти только для чтения и с запретом на исполненение
- поддержка выгрузки не используемых участков памяти в область подкачки на диске (свопинг)
- поддержка отображённых в память файлов, в том числе загрузочных модулей
- поддержка разделяемой между процессами памяти, в том числе с копированием-при-записи для экономии физических страниц

Виды адресов памяти:
- физический - адрес аппаратной ячейки памяти
- логический - виртуальный адрес, которым оперирует приложение

Кроме того, этот дополнительный уровень позволяет через тот же самый интерфейс обращения к данным по адресу в памяти реализовать другие функции, такие как обращение к данным в файле (через механизм mmap ) и т.д. Наконец, он позволяет обеспечить более гибкое, эффективное и безопасное управление памятью компьютера, чем при использовании физической памяти напрямую.
На аппаратном уровне виртуальная память, как правило, поддерживается специальным устройством — Модулем управления памятью.
Страничная организация памяти
Страничная память — способ организации виртуальной памяти, при котором единицей отображения виртуальных адресов на физические является регион постоянного размера — страница.

При использовании страничной модели вся виртуальная память делится на N страниц таким образом, что часть виртуального адреса интерпретируется как номер страницы, а часть — как смещение внутри страницы. Вся физическая память также разделяется на блоки такого же размера — фреймы. Таким образом в один фрейм может быть загружена одна страница. Свопинг — это выгрузка страницы из памяти на диск (или другой носитель большего объема), который используется тогда, когда все фреймы заняты. При этом под свопинг попадают страницы памяти неактивных на данный момент процессов.


Размер страницы и количество страниц зависит от того, какая часть адреса выделяется на номер страницы, а какая на смещение. К примеру, если в 32-разрядной системе разбить адрес на две равные половины, то количество страниц будет составлять 2^16, т.е. 65536, и размер страницы в байтах будет таким же, т.е. 64 КБ. Если уменьшить количество страниц до 2^12, то в системе будет 4096 страницы по 1МБ, а если увеличить до 2^20, то 1 миллион страниц по 4КБ. Чем больше в системе страниц, тем больше занимает в памяти таблица страниц, соответственно работа процессора с ней замедляется. А поскольку каждое обращение к памяти требует обращения к таблице страниц для трансляции виртуального адреса, такое замедление очень нежелательно. С другой стороны, чем меньше страниц и, соотвественно, чем они больше по объему — тем больше потери памяти, вызванные внутренней фрагментацией страниц, поскольку страница является единицей выделения памяти. В этом заключается диллема оптимизации страничной памяти. Она особенно актуальна при переходе к 64-разрядным архитектурам.
Для оптимизации страничной памяти используются следующие подходы:
- специальный кеш — TLB (translation lookaside buffer) — в котором хранится очень небольшое число (порядка 64) наиболее часто используемых адресов страниц (основные страницы, к которым постоянно обращается ОС)
- многоуровневая (2, 3 уровня) таблица страниц — в этом случае виртуальный адрес разбивается не на 2, а на 3 (4. ) части. Последняя часть остается смещением внутри страницы, а каждая из остальных задает номер страницы в таблице страниц 1-го, 2-го и т.д. уровней. В этой схеме для трансляции адресов нужно выполнить не 1 обращение к таблице страниц, а 2 и более. С другой стороны, это позволяет свопить таблицы страниц 2-го и т.д. уровней, и подгружать в память только те таблицы, которые нужны текущему процессу в текущий момент времени или же даже кешировать их. А каждая из таблиц отдельного уровня имеет существенно меньший размер, чем имела бы одна таблица, если бы уровень был один

- инвертированная таблица страниц — в ней столько записей, сколько в системе фреймов, а не страниц, и индексом является номер фрейма: а число фреймов в 64- и более разрядных архитектурах существенно меньше теоретически возможного числа страниц. Проблема такого подхода — долгий поиск виртуального адреса. Она решается с помощью таких механизмов как: хеш-таблицы или кластерные таблицы страниц
Сегментная организация памяти
Сегментная организация виртуальной памяти реализует следующий механизм: вся память делиться на сегменты фиксированной или произвольной длины, каждый из которых характеризуется своим начальным адресом — базой или селектором. Виртуальный адрес в такой системе состоит из 2-х компонент: базы сегмента, к которому мы хотим обратиться, и смещения внутри сегмента. Физический адрес вычисляется по формуле:

Историческая модель сегментации в архитектуре х86
В архитектуре х86 сегментная модель памяти была впервые реализована на 16-разрядных процессорах 8086. Используя только 16 разрядов для адреса давало возможность адресовать только 2^16 байт, т.е. 64КБ памяти. В то же время стандартный размер физической памяти для этих процессоров был 1МБ. Для того, чтобы иметь возможность работать со всем доступным объемом памяти и была использована сегментная модель. В ней у процессора было выделено 4 специализированных регистра CS (сегмент кода), SS (сегмент стека), DS (сегмент данных), ES (расширенный сегмент) для хранения базы текущего сегмента (для кода, стека и данных программы).
Физический адрес в такой системе расчитывался по формуле:
Это приводило к возможности адресовать большие адреса, чем 1МБ — т.н. Gate A20.
Плоская модель сегментации
32-разрядный процессор 80386 мог адресовать 2^32 байт памяти, т.е. 4ГБ, что более чем перекрывало доступные на тот момент размеры физической памяти, поэтому изначальная причина для использования сегментной организации памяти отпала.
Однако, помимо особого способа адресации сегментная модель также предоставляет механизм защиты памяти через кольца безопасности процессора: для каждого сегмента в таблице сегментов задается значение допустимого уровня привилегий (DPL), а при обращении к сегменту передается уровень привилегий текущей программы (запрошенный уровень привилегий, RPL) и, если RPL > DPL доступ к памяти запрещен. Таким образом обеспечивается защита сегментов памяти ядра ОС, которые имеют DPL = 0 . Также в таблице сегментов задаються другие атрибуты сегментов, такие как возможность записи в память, возможность исполнения кода из нее и т.д.
Таблица сегментов каждого процесса находится в памяти, а ее начальный адрес загружается в регистр LDTR процессора. В регистре GDTR процессора хранится указатель на глобальную таблицу сегментов.
В современных процессорах x86 используется "Плоская модель сегментации", в которой база всех сегментов выставлена в нулевой адрес.

Виртуальная память в архитектуре x86

Системные вызовы для взаимодействия с подсистемой виртуальной памяти:
- brk , sbrk - для увеличения сегмента памяти, выделенного для данных программы
- mmap , mremap , munmap - для отображения файла или устройства в память
- mprotect - изменение прав доступа к областям памяти процесса
Пример выделение памяти процессу:

Алгоритмы выделения памяти
Эффективное выделение памяти предполагает быстрое (за 1 или несколько операций) нахождение свободного участка памяти нужного размера.
Способы учета свободных участков:
- битовая карта (bitmap) — каждому блоку памяти (например, странице) ставится в соответствие 1 бит, который имеет значение занят/свободен
- связный список — каждому непрерывному набору блоков памяти одного типа (занят/свободен) ставится в соответствеи 1 запись в связном списке блоков, в которой указывается начало и размер участка
- использование нескольких связных списков для участков разных размеров — см. алгоритм Buddy allocation
Кеш — это компонент компьютерной системы, который прозрачно хранит данные так, чтобы последующие запросы к ним могли быть удовлетворены быстрее. Наличие кеша подразумевает также наличие запоминающего устройства (гораздо) большего размера, в которых данные хранятся изначально. Запросы на получение данных из этого устройства прозрачно проходят через кеш в том смысле, что если этих данных нет в кеше, то они запрашиваются из основного устройства и параллельно записываются в кеш. Соответственно, при последующем обращении данные могут быть извлечены уже из кеша. За счет намного меньшего размера кеш может быть сделан намного быстрее и в этом основная цель его существования.
По принципу записи данных в кеш выделяют:
- сквозной (write-through) — данные записываются синхронно и в кеш, и непосредственно в запоминающее устрйоство
- с обратной записью (write-back, write-behind) — данные записываются в кещ и иногда синхронизируются с запоминающим устройством
По принципу хранения данных выделяют:
- полностью ассоциативные
- множественно-ассоциативные
- прямого соответствия


Алгоритмы замещения записей в кеше
Поскольку любой кеш всегда меньше запоминающего устройства, всегда возникает необходимость для записи новых данных в кеш удалять из него ранее записанные. Эффективное удаление данных из кеша подразумевает удаление наименее востребованных данных. В общем случае нельзя сказать, какие данные являются наименее востребованными, поэтому для этого используются эвристики. Например, можно удалять данные, к которым происходило наименьшее число обращений с момента их загрузки в кеш (least frequently used, LFU) или же данные, к которым обращались наименее недавно (least recently used, LRU), или же комбинация этих двух подходов (LRFU).
Кроме того, аппаратные ограничения по реализации кеша часто требуют минимальных расходов на учет служебной информации о ячейках, которой является также и использование данных в них. Наиболее простым способом учета обращений является установка 1 бита: было обращение или не было. В таком случае для удаления из кеша может использоваться алгоритм часы (или второго шанса), который по кругу проходит по всем ячейками, и выгружает ячейку, если у нее бит равен 0, а если 1 — сбрасывает его в 0.
Более сложным вариантом является использование аппаратного счетчика для каждой ячейки. Если этот счетчик фиксирует число обращений к ячейке, то это простой вариант алгоритма LFU. Он обладает следующими недостатками:
- может произойти переполнение счетчика (а он, как правило, имеет очень небольшую разрядность) — в результате будет утрачена вся информация об обращениях к ячейке
- данные, к которым производилось множество обращений в прошлом, будут иметь высокое значение счетчика даже если за последнее время к ним не было обращений
Для решения этих проблем используется механизм старения, который предполагает периодический сдвиг вправо одновременно счетчиков для всех ячеек. В этом случае их значения будут уменьшаться (в 2 раза), сохраняя пропорцию между собой. Это можно считать вариантом алгоритм LRFU.
Управление памятью – одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере – включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.


Это не значит, что ядро использует так много физической памяти – просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов:
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым – пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты – всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:

Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам – адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент отображения в память и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало места, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса – это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры – достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack(), которая, в свою очередь, вызывает acct_stack_growth(), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться – подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека – единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент отображения в память. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap() в Linux или CreateFileMapping() / MapViewOfFile() в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc(), библиотека C создаст такую анонимное отображение вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt().)
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk(). Управление кучей – дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

И вот мы добрались до самой нижней части схемы – BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers , то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10 , то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватное отображение в память (private memory mapping) – а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:

Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированного в память, есть своя область в сегменте mmap, а у динамических библиотек – дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump – вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье – это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему:
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Как известно программист, когда пишет программы работает не с физическим адресом, а только с логическим. И то если он программирует на ассемблере. В том же Си ячейки памяти от программиста уже скрыты указателями, для его же удобства, но если грубо говорить указатель это другое представление логического адреса памяти, а в Java и указателей нет, совсем плохой язык. Однако грамотному программисту не помешают знания о том как организована память хотя бы на общем уровне. Меня вообще очень огорчают программисты, которые не знают как работает машина, обычно это программисты Java и прочие php-парни, с квалификацией ниже плинтуса.
Так ладно, хватит о печальном, переходим к делу.
Рассмотрим адресное пространство программного режима 32 битного процессора (для 64 бит все по аналогии)
Адресное пространство этого режима будет состоять из 2^32 ячеек памяти пронумерованных от 0 и до 2^32-1.
Программист работает с этой памятью, если ему нужно определить переменную, он просто говорит ячейка памяти с адресом таким-то будет содержать такой-то тип данных, при этом сам програмист может и не знать какой номер у этой ячейки он просто напишет что-то вроде:
int data = 10;
компьютер поймет это так: нужно взять какую-то ячейку с номером стопицот и поместить в нее цело число 10. При том про адрес ячейки 18894 вы и не узнаете, он от вас будет скрыт.
Все бы хорошо, но возникает вопрос, а как компьютер ищет эту ячейку памяти, ведь память у нас может быть разная:
3 уровень кэша
2 уровень кэша
1 уровень кэша
основная память
жесткий диск
Это все разные памяти, но компьютер легко находит в какой из них лежит наша переменная int data.
Этот вопрос решается операционной системой совместно с процессором.
Вся дальнейшая статья будет посвящена разбору этого метода.
Архитектура х86 поддерживает стек.
Стек это непрерывная область оперативной памяти организованная по принципу стопки тарелок, вы не можете брать тарелки из середины стопки, можете только брать верхнюю и класть тарелку вы тоже можете только на верх стопки.
В процессоре для работы со стеком организованны специальные машинные коды, ассемблерные мнемоники которых выглядят так:
push operand
помещает операнд в стек
pop operand
изымает из вершины стека значение и помещает его в свой операнд
Стек в памяти растет сверху вниз, это значит что при добавлении значения в него адрес вершины стека уменьшается, а когда вы извлекаете из него, то адрес вершины стека увеличивается.
Теперь кратко рассмотрим что такое регистры.
Это ячейки памяти в самом процессоре. Это самый быстрый и самый дорогой тип памяти, когда процессор совершает какие-то операции со значением или с памятью, он берет эти значения непосредственно из регистров.
В процессоре есть несколько наборов логик, каждая из которых имеет свои машинные коды и свои наборы регистров.
Basic program registers (Основные программные регистры) Эти регистры используются всеми программами с их помощью выполняется обработка целочисленных данных.
Floating Point Unit registers (FPU) Эти регистры работают с данными представленными в формате с плавающей точкой.
Еще есть MMX и XMM registers эти регистры используются тогда, когда вам надо выполнить одну инструкцию над большим количеством операндов.
Рассмотрим подробнее основные программные регистры. К ним относятся восемь 32 битных регистров общего назначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP
Для того чтобы поместить в регистр данные, или для того чтобы изъять из регистра в ячейку памяти данные используется команда mov:
mov eax, 10
загружает число 10 в регистр eax.
mov data, ebx
копирует число, содержащееся в регистре ebx в ячейку памяти data.
Регистр ESP содержит адрес вершины стека.
Кроме регистров общего назначения, к основным программным регистрам относят шесть 16битных сегментных регистров: CS, DS, SS, ES, FS, GS, EFLAGS, EIP
EFLAGS показывает биты, так называемые флаги, которые отражают состояние процессора или характеризуют ход выполнения предыдущих команд.
В регистре EIP содержится адрес следующей команды, которая будет выполнятся процессором.
Я не буду расписывать регистры FPU, так как они нам не понадобятся. Итак наше небольшое отступление про регистры и стек закончилось переходим обратно к организации памяти.
Как вы помните целью статьи является рассказ про преобразование логической памяти в физическую, на самом деле есть еще промежуточный этап и полная цепочка выглядит так:
Логический адрес --> Линейный (виртуальный)--> Физический

Все линейное адресное пространство разбито на сегменты. Адресное пространство каждого процесса имеет по крайней мере три сегмента:
Сегмент кода. (содержит команды из нашей программы, которые будут исполнятся.)
Сегмент данных. (Содержит данные, то бишь переменные)
Сегмент стека, про который я писал выше.
Линейный адрес вычисляется по формуле:
линейный адрес=Базовый адрес сегмента(на картинке это начало сегмента) + смещение
Сегмент кода
Базовый адрес сегмента кода берется из регистра CS. Значение смещения для сегмента кода берется из регистра EIP, в котором хранится адрес инструкции, после исполнения которой, значение EIP увеличивается на размер этой команды. Если команда занимает 4 байта, то значение EIP увеличивается на 4 байта и будет указывать уже на следующую инструкцию. Все это делается автоматически без участия программиста.
Сегментов кода может быть несколько в нашей памяти. В нашем случае он один.
Сегмент данных
Данные загружаются в регистры DS, ES, FS, GS
Это значит что сегментов данных может быть до 4х. На нашей картинке он один.
Смещение внутри сегмента данных задается как операнд команды. По дефолту используется сегмент на который указывает регистр DS. Для того чтобы войти в другой сегмент надо это непосредственно указать в команде префикса замены сегмента.
Сегмент стека
Используемый сегмент стека задается значением регистра SS.
Смещение внутри этого сегмента представлено регистром ESP, который указывает на вершину стека, как вы помните.
Сегменты в памяти могут друг друга перекрывать, мало того базовый адрес всех сегментов может совпадать например в нуле. Такой вырожденный случай называется линейным представлением памяти. В современных системах, память как правило так организована.
Теперь рассмотрим определение базовых адресов сегмента, я писал что они содержаться в регистрах SS, DS, CS, но это не совсем так, в них содержится некий 16 битный селектор, который указывает на некий дескриптор сегментов, в котором уже хранится необходимый адрес.
Так выглядит селектор, в тринадцати его битах содержится индекс дескриптора в таблице дескрипторов. Не хитро посчитать будет что 2^13 = 8192 это максимальное количество дескрипторов в таблице.
Вообще дескрипторных таблиц бывает два вида GDT и LDT Первая называется глобальная таблица дескрипторов, она в системе всегда только одна, ее начальный адрес, точнее адрес ее нулевого дескриптора хранится в 48 битном системном регистре GDTR. И с момента старта системы не меняется и в свопе не принимает участия.
А вот значения дескрипторов могут меняться. Если в селекторе бит TI равен нулю, тогда процессор просто идет в GDT ищет по индексу нужный дескриптор с помощью которого осуществляет доступ к этому сегменту.
Пока все просто было, но если TI равен 1 тогда это означает что использоваться будет LDT. Таблиц этих много, но использоваться в данный момент будет та селектор которой загружен в системный регистр LDTR, который в отличии от GDTR может меняться.
Индекс селектора указывает на дескриптор, который указывает уже не на базовый адрес сегмента, а на память в котором хранится локальная таблица дескрипторов, точнее ее нулевой элемент. Ну а дальше все так же как и с GDT. Таким образом во время работы локальные таблицы могут создаваться и уничтожаться по мере необходимости. LDT не могут содержать дескрипторы на другие LDT.
Итак мы знаем как процессор добирается до дескриптора, а что содержится в этом дескрипторе посмотрим на картинке:
Дескрипторы состоит из 8 байт.
Биты с 15-39 и 56-63 содержат линейный базовый адрес описываемым данным дескриптором сегмента. Напомню нашу формулу для нахождения линейного адреса:
линейный адрес = базовый адрес + смещение
[база; база+предел)
В зависимости от 55 G-бита(гранулярити), предел может измеряться в байтах при нулевом значении бита и тогда максимальный предел составит 1 мб, или в значении 1, предел измеряется страницами, каждая из которых равна 4кб. и максимальный размер такого сегмента будет 4Гб.
Для сегмента стека предел будет в интервале:
(база+предел; вершина]
Кстати интересно почему база и предел так рвано располагаются в дескрипторе. Дело в том что процессоры х86 развивались эволюционно и во времена 286х дескрипторы были по 8 бит всего, при этом старшие 2 байта были зарезервированы, ну а в последующих моделях процессоров с увеличением разрядности дескрипторы тоже выросли, но для сохранения обратной совместимости пришлось оставить структуру как есть.
Значение адреса «вершина» зависит от 54го D бита, если он равен 0, тогда вершина равна 0xFFF(64кб-1), если D бит равен 1, тогда вершина равна 0xFFFFFFFF (4Гб-1)
С 41-43 бит кодируется тип сегмента.
000 — сегмент данных, только считывание
001 — сегмент данных, считывание и запись
010 — сегмент стека, только считывание
011 — сегмент стека, считывание и запись
100 — сегмент кода, только выполнение
101- сегмент кода, считывание и выполнение
110 — подчиненный сегмент кода, только выполнение
111 — подчиненный сегмент кода, только выполнение и считывание
44 S бит если равен 1 тогда дескриптор описывает реальный сегмент оперативной памяти, иначе значение S бита равно 0.
Самым важным битом является 47-й P бит присутствия. Если бит равен 1 значит, что сегмент или локальная таблица дескрипторов загружена в оперативку, если этот бит равен 0, тогда это означает что данного сегмента в оперативке нет, он находится на жестком диске, случается прерывание, особый случай работы процессора запускается обработчик особого случая, который загружает нужный сегмент с жесткого диска в память, если P бит равен 0, тогда все поля дескриптора теряют смысл, и становятся свободными для сохранения в них служебной информации. После завершения работы обработчика, P бит устанавливается в значение 1, и производится повторное обращение к дескриптору, сегмент которого находится уже в памяти.
На этом заканчивается преобразование логического адреса в линейный, и я думаю на этом стоит прерваться. В следующий раз я расскажу вторую часть преобразования из линейного в физический.
А так же думаю стоит немного поговорить о передачи аргументов функции, и о размещении переменных в памяти, чтобы была какая-то связь с реальностью, потому размещение переменных в памяти это уже непосредственно, то с чем вам приходится сталкиваться в работе, а не просто какие-то теоретические измышления для системного программиста. Но без понимания, как устроена память невозможно понять как эти самые переменные хранятся в памяти.
В общем надеюсь было интересно и до новых встреч.
Память — одна из самых сложных тем в информатике, но понимание устройства памяти компьютера позволяет разрабатывать более эффективные программы, а для более низкоуровневого программирования, например, при разработке ОС, это понимание и вовсе является обязательным.
В этой статье будет рассмотрена модель памяти с высокоуровневой точки зрения — виды памяти, аллокаторы, сборщик мусора.
Виды памяти
Существует 3 типа памяти: статический, автоматический и динамический.
Статический — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего времени выполнения программы. Во многих языках для размещения объекта в статической памяти достаточно задекларировать его в глобальной области видимости.
Автоматический, также известный как «размещение на стеке», — самый основной, автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове функции и освобождает память при выходе из неё.
Стек, как структура данных, работает по принципу LIFO («последним пришёл — первым ушёл»). Другими словами, добавлять и удалять значения в стеке можно только с одной и той же стороны.
Автоматическая память работает именно на основе стека, чтобы вызванная из любой части программы функция не затёрла уже используемую автоматическую память, а добавила свои данные в конец стека, увеличивая его размер. При завершении этой функции её данные будут удалены с конца стека, уменьшая его размер. Длина стека останется той же, что и до вызова функции, а у вызывающей функции указатель на конец стека будет указывать на тот же адрес.
Проще всего это понять из примера на С++:
Стек при вызове последней рекурсивной функции будет выглядеть следующим образом:
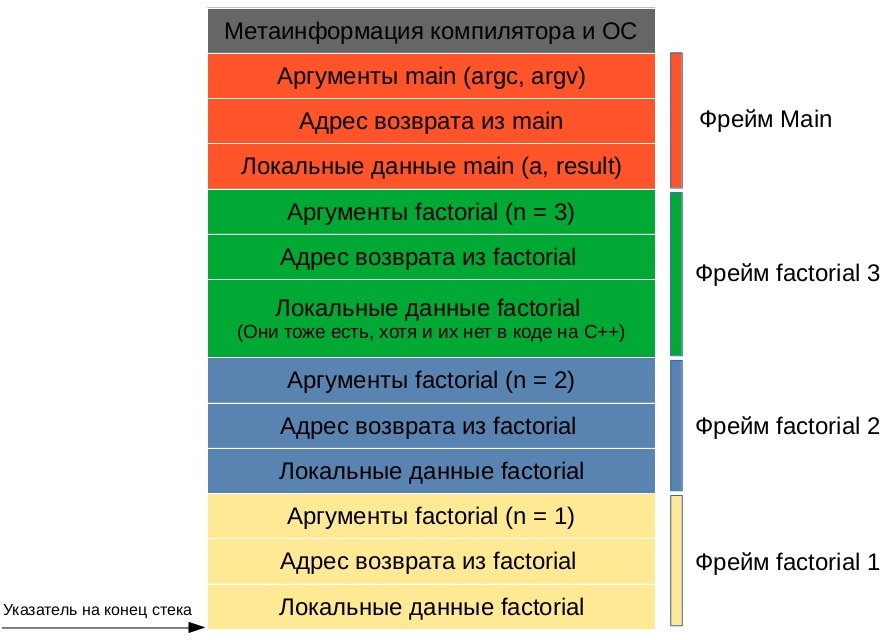
Детали реализации автоматической памяти могут быть разными в зависимости от конкретной платформы. Например, кому очищать из стека метаинформацию функции и её аргументы: вызывающей функции или вызываемой? Как передавать результат: через стек или, что намного быстрее, через регистры процессора (память, расположенную прямо на кристалле процессора. В этой статье не рассматривается, т. к. в языках программирования высокого уровня зачастую нет прямого доступа к регистрам процессора). На все эти вопросы отвечает конкретная реализация calling convention — описание технических особенностей вызова подпрограмм, определяющее способы передачи параметров/результата функции и способы вызова/возврата из функции.
Таким образом, когда одна функция вызывает другую, последняя всегда в курсе, где ей взять свои аргументы: на конце стека. Но откуда ей знать, где конец стека? В процессоре для этого есть специальный регистр, хранящий указатель на конец стека. В большинстве случаев стек расположен ближе к концу виртуальной памяти и растёт в сторону начала.
Размер автоматической памяти, а он тоже фиксированный, определяется линковщиком (обычно — 1 мегабайт), максимальный размер зависит от конкретной системы и настроек компилятора/линковщика.
Если приложение выйдет за максимум автоматической памяти, его там может ждать Page Fault (сигнал SIGSEGV в POSIX-совместимых системах: Mac OS X, Linux, BSD и т. д.) — ошибка сегментации, приводящая к аварийному завершению программы.
Динамическая — выделение памяти из ОС по требованию приложения.
Автоматическая и статическая память выделяются единоразово перед запуском программы. При их нехватке, либо если модель LIFO не совсем подходит, используется динамическая память.
Приложение при необходимости может запросить у ОС дополнительную память через аллокатор или напрямую через системный вызов. Пример использования динамической памяти с помощью аллокатора ниже на примере языка Си.
После выделения памяти в распоряжение программы поступает указатель на начало выделенной памяти, который, в свою очередь, тоже должен где-то храниться: в статической, автоматической или также в динамической памяти. Для возвращения памяти обратно в аллокатор необходим только сам указатель. Попытка использования уже очищенной памяти может привести к завершению программы с сигналом SIGSEGV.
Языки сверхвысокого уровня используют динамическую память как основную: создают все или почти все объекты в динамической памяти, а на стеке или в статической памяти держат указатели на эти объекты.
Максимальный размер динамической памяти зависит от многих факторов: среди них ОС, процессор, аппаратная архитектура в целом, не говоря уже о самом очевидном — максимальном размере ОЗУ у конкретного устройства. Например x86_64 процессоры используют только 48 бит для адресации виртуальной памяти, что позволяет использовать до 256 ТБ памяти. В следующей статье про более низкоуровневую архитектуру памяти будет объяснено, почему не все 64 бита.
Аллокатор
У динамической памяти есть две явные проблемы. Во-первых, любое выделение/освобождение памяти в ОС — системный вызов, замедляющий работу программы. Решением этой проблемы является аллокатор.
Аллокатор — это часть программы, которая запрашивает память большими кусками напрямую у ОС через системные вызовы (в POSIX-совместимых ОС это mmap для выделения памяти и unmap — для освобождения), затем по частям отдаёт эту память приложению (в Си это могут быть функции malloc() / free() ). Такой подход увеличивает производительность, но может вызвать фрагментацию памяти при длительной работе программы.
malloc() / free() и mmap / unmap — это не одно и то же. Первый является простейшим аллокатором в libc , второй является системным вызовом. В большинстве языков можно использовать только аллокатор по умолчанию, но в языках с более низкоуровневой моделью памяти можно использовать и другие аллокаторы.
Например, boost::pool аллокаторы, созданные для оптимальной работы с контейнерами ( boost::pool_allocator для линейных ( std::vector ), boost::fast_pool_allocator для нелинейных ( std::map, std::list )). Или аллокатор jemalloc, оптимизированный для решения проблем фрагментации и утилизации ресурсов CPU в многопоточных программах. Более подробно о jemalloc можно узнать из доклада с конференции C++ Russia 2018.
Способы контроля динамической памяти
Из-за сложности программ очень трудно определить, когда необходимо освобождать память в ОС, и это вторая явная проблема динамической памяти. Если забыть вызвать munmap() или free() , то произойдет следующая ситуация: приложению память уже не нужна, но ОС всё ещё будет считать, что эта память используется программой. Эту проблему называют «утечкой памяти». Существуют несколько способов автоматического или полуавтоматического решения этой проблемы:
RAII (Получение ресурса есть инициализация) — в ООП — организация получения доступа к ресурсу в конструкторе, а освобождения — в деструкторе соответствующего класса. Достаточно реализовать управление памятью в конструкторах и деструкторах, а компилятор вызовет их автоматически. Например, немного урезанный класс String из статьи про Move-семантику. Выделяем память в конструкторе, очищаем в деструкторе:
Умные указатели на основе RAII — указатели, автоматически владеющие динамической памятью, то есть автоматически освобождающие её, когда она больше не нужна. Умные указатели инкапсулируют только управление памятью объекта, но не сам объект, как, например, происходит в String, который инкапсулирует объект целиком. Примеры умных указателей ниже.
std::unique_ptr — класс уникального указателя, является единственным владельцем памяти и очищает её в своём деструкторе. Поэтому объекты класса std::unique_ptr не могут иметь копий, но могут быть перемещены. Подробнее о семантике перемещения в этой статье.
std::shared_ptr — класс общего указателя, использующий атомарный счётчик ссылок для подсчёта количества владельцев памяти. В конструкторе счётчик инкрементируется, в деструкторе — декрементируется. Как только счётчик становится равным нулю, память освобождается.
Но у std::shared_ptr есть проблема, например, когда объект A ссылается на объект B, а объект B ссылается на объект A. В таком случае у обоих объектов счётчик ссылок никогда не будет меньше 1 и произойдёт утечка памяти. Решений у этой проблемы два. Использование std::weak_ptr , который ссылается на объект, но без счётчика ссылок, и не может быть разыменован без предварительной конвертации в std::shared_ptr . Вторым решением этой проблемы является сборщик мусора.
Сборка мусора — одна из форм автоматического управления динамической памятью, которая помечает все доступные из стека или статической памяти динамически выделенные объекты. Объекты, до которых нельзя добраться через цепочку указателей, начиная с автоматической или статической памяти, т. е. не помеченные сборщиком мусора, очищаются.
Умные указатели и RAII используются в основном в относительно низкоуровневых языках, например, С++ или Swift. В более высокоуровневых языках обычно используется сборщик мусора (Java), хотя может применяться комбинация умного указателя и сборщика мусора (Python).
У каждого способа управления динамической памятью есть свои плюсы и минусы. В основном приходится жертвовать производительностью программы ради скорости и простоты разработки, либо наоборот: высокая производительность, но и высокая требовательность к программистам, из-за чего вероятность ошибиться при разработке программы выше и медленней сам процесс.
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Кеш, оперативная память, стек и куча, выделение и освобождение памяти

Линейное представление памяти
| Адрес | Значение (1 байт) |
|---|---|
| 0x0000 | . |
| . | . |
| 0x1000 | 1 |
| 0x1001 | 2 |
| 0x1002 | 3 |
| 0x1003 | 4 |
| . | . |
| 0xffffffffff | . |
C-cast использовать в С++ нельзя! Как надо приводить типы в С++ и надо ли вообще будет в другой лекции
| Знаковые | Беззнаковые |
|---|---|
| char | unsigned char |
| short | unsigned short |
| int | unsigned или unsigned int |
| long | unsigned long |
Стандарт не регламентирует размер типов
| Размер, бит | Тип |
|---|---|
| 8 | int8_t, int_fast8_t, int_least8_t |
| 16 | int16_t, int_fast16_t, int_least16_t |
| 32 | int32_t, int_fast32_t, int_least32_t |
| 64 | int64_t, int_fast64_t, int_least64_t |
Беззнаковая (unsigned) версия - добавление префикса u
Память разбита на сегменты:
- кода (CS)
- данных (DS)
- стека (SS)
Регистр сегмента (CS, DS, SS) указывают на дескриптор.
Для инструкций и стека на смещение в сегменте указывает регистр:
Линейный адрес - это сумма базового адреса сегмента и смещения.

Segment limit (20 bit) - размер сегмента, 55-й бит G определяет гранулярность размера:
- байты, если 0
- страницы, если 1 (размер страницы обычно 4Кб)
- 000 - сегмент данных, только чтение
- 001 - сегмент данных, чтение и запись
- 010 - сегмент стека, только чтение
- 011 - сегмент стека, чтение и запись
- 100 - сегмент кода, только выполнение
- 101- сегмент кода, чтение и выполнение


Кроме задержки (latency) есть понятие пропускной способности (throughput, bandwidth). В случае чтения из RAM - 10-50 Gb/sec
Выводы из таблицы
- Стараться укладывать данные в кеш
- Минимизировать скачки по памяти
- В условиях основной веткой делать ветку которая выполняется с большей вероятностью

Классы управления памятью и областью видимости в C++
Характеризуются тремя понятиями:
Продолжительность хранения данных в памяти
Части кода из которых можно получить доступ к данным
Если к данным можно обратиться из другой единицы трансляции — связывание внешнее (external), иначе связывание внутреннее (internal)
| Время жизни | Область видимости | Связывание |
|---|---|---|
| Автоматическое (блок) | Блок | Отсутствует |
Статический без связывания
| Время жизни | Область видимости | Связывание |
|---|---|---|
| Статическое | Блок | Отсутствует |
Инициализируется при первом обращении
Статический с внутренним связыванием
| Время жизни | Область видимости | Связывание |
|---|---|---|
| Статическое | Файл | Внутреннее |
Инициализируется до входа в main
Статический с внешним связыванием
| Время жизни | Область видимости | Связывание |
|---|---|---|
| Статическое | Файл | Внешнее |
Выделение памяти на стеке очень быстрая, но стек не резиновый
Память в куче выделяют new и malloc, есть сторонние менеджеры памяти.

- new то же, что и malloc, только дополнительно вызывает конструкторы
- Внутри malloc есть буфер, если в буфере есть место, ваш вызов может выполниться быстро
- Если памяти в буфере нет, будет запрошена память у ОС (sbrk, VirtualAlloc) - это дорого
- ОС выделяет память страницами от 4Кб, а может быть и все 2Мб
- Стандартные аллокаторы универсальные, то есть должны быть потокобезопасны, быть одинаково эффективны для блоков разной длины, и 10 байт и 100Мб. Плата за универсальность - быстродействие
Глобальная память (data segment)
Если не удастся разместить блок глобальной памяти, то программа даже не запустится
Значение в квадратных скобках должно быть известно на этапе компиляции, увы
Фактически - это вычисление смещения:
Массив - непрерывный блок байт в памяти, sizeof(data) вернет размер массива в байтах (не элементах!). Размер массива в элементах можно вычислить: sizeof(data) / sizeof(data[0])
Измеряем скорость работы (benchmark)
- Измерений должно быть много
- Одному прогону верить нельзя
- Компилятор оптимизирует, надо ему мешать
- Перед тестами надо греться
Пример "вредной" оптимизации
Не даем компилятору оптимизировать
Написать свой аллокатор со стратегией линейного выделения памяти со следующим интерфейсом:
При вызове makeAllocator аллоцируется указанный размер, после чего при вызове alloc возвращает указатель на блок запрошенного размера или nullptr, если места недостаточно. После вызова reset аллокатор позволяет использовать свою память снова.
Читайте также: