
Как выбрать представление данных xslt в word
This guide covers how you can use XSL transformations to generate advanced Word reports.
This guide contains:
Why use XSL transformations?
Starting in Word 2003, Word documents are built using XML in what Microsoft calls the WordprocessingML.
Unfortunately, this is not such good news as one would think. The WordprocessingML language is quite complex and it takes some getting used to. You check out the Overview of WordprocessingML in MSDN.
On the bright side, there are plenty of tools out there to work with XML documents. We are going to make use of one of such tools: XSL transformations (XSLT).
An XSLT document is itself an XML document that contains rules on how to transform an input XML into an output document (you can read more on the XSLT Wikipedia page).
In this case we are going to convert an input XML containing the information stored in your Dradis repository into an output document in the WordprocessingML format.
Introduction to WordprocessingML
Unfortunately WordprocessingML is a huge topic. The bare minimum WordprocessingML document is:
If you copy and paste the above text into a file and have Word installed, Windows will detect this XML (because of the mso-application declaration) and will launch Word if you double-click it.
In the example you can see some of the elements we will have to deal with when creating the template:
- w:p represents a paragraph
- w:r represents a text run, a contiguous set of WordprocessingML components with a consistent set of properties
- w:t represents a text
Other common items you will have to work with are tables, table rows and table cells ( w:tbl , w:tr , and w:tc respectively).
To get familiar with the other elements you will need to review the Overview of WordprocessingML and sharpen your Google skills.
Unfortunately Word is not going to keep your XML as clear and simple as our example. Try opening the file in Word, adding a second line to the document and saving it again. We have gone from 280 bytes to a 10KB of document!
This is because Word starts including styling information, additional namespaces and a plethora of other bits and pieces. Thankfully, we will be able to ignore most of it.
Introduction to XSLT
Say we have a very simple XML:
And a simple XSLT document:
The above transformation will create a Word document with a new paragraph containing the Title field for every Note in the source XML:
If you want to verify this by yourself, create the dradis_source.xml and simple.xslt files in a temporary folder and fire the Ruby interpreter (install the Nokogiri gem first if it is not installed):
Creating the template
Now that we have a basic understanding of the inner workings of the WordprocessingML and XSLT technologies we can start working on our Dradis Pro template.
Open Word and create a new document. You can also start from your existing reporting template but we are going to keep things simple in this guide. A very basic report skeleton could look like this:

We could save this document as XML and start working on it, but we are going to make our life easier by adding some placeholders:

Now we are ready to convert this into an XSL transformation. Save the document (File > Save As) as Word 2003 XML Document. Mine is about 25 KB.
Converting the template into an XSL transformation
The first thing we need to do with our document to convert it into an XSLT is to replace the Word document preamble with an XSLT preamble. Lets create a copy of the document and rename it to template.xslt .
Open it in a text-editor and replace the Word preamble:
With the XSLT preamble:
And then go all the way down to the bottom and close the XSLT tags:
So now officially your template.xslt is a well-formed XSLT document. It does not do anything interesting, but it is a start.
Adding content to the template
Now comes the tricky part. We need to navigate through the source of the XSLT document to locate the placeholders we created for our fields.
For instance, the first one is going to be the phTitle placeholder in the first cell of the table. Using your editor's search function look for phTitle. Mine is in line 12, column 21689 but your mileage may vary.
Because we know this is a table cell, we know that our placeholder is going to be locate within a set of w:tc tags. After finding them and indenting the code around them we have:
There is a lot in the markup for that table cell. Thankfully you can ignore most of it. For instance, w:tcPr contains cell properties, all the wsp attributes can be ignored or deleted, w:pPr are paragraph properties, etc.
One interesting thing to note is the w:proofErr block. This has been added by word because our placeholder (phTitle) is not a valid English word. For our purposes we can ignore it but lets just say that if your placeholder had been Title you would not see this w:proofErr element.
The next thing we need to do is to replace our placeholder text with an XSLT xsl:value-of tag that extracts the field from the source (note that I have also removed the w:proofErr element):
We need to repeat this (tedious) process for the other cells in the row.
Once that is done, we need to ensure that a new row is created for each note in our Dradis Pro source XML. We do this by enclosing the w:tr element within an XSLT xsl:for-each tag (I have removed the wsp attributes in the w:tr tag):
The code above will ensure that a new table row (i.e. a new @w:tr@ element) will be created for each Dradis note.
Now we need to repeat the same process for the Technical Details section of our report. It is going to be a bit trickier this time because the fields are not enclosed by table cells or table rows but in essence this is what we have to do:
- Locate the placeholder
- Replace the placeholder with a xsl:value-of XSLT element
- Repeat for every field
- Enclose the block in a xsl:for-each XSLT element
Using the editor's search function, search again for phTitle. Once you find it, walk backwards to the previous paragraph (an empty one) and the one before (containing the Detailed Findings header). See the snippet below (superfluous wsp attributes have been removed) where I have already replaced the phTitle with an xsl:value-of :
The process of going through the rest of the fields is straightforward. And once we have identified all the paragraphs that compose the block we want to repeat for each issue, we just need to enclose it in a xsl:for-each element:
We are all done here. Lets wrap this up.
Providing the content and obtaining final result
That's it for now. We just need to copy the template across and use it. Follow the instructions on the Report Templates page of the Administration guide.
Once the template is uploaded into Dradis, you can generate a report through the Export menu.
Follow the instructions on the Generate your report page of the Working with Projects guide.
Wrapping up
As you can see, XSL transformations are a powerful and versatile technology. They are not for the faint of heart though.
This guide only scratches the surface but there is much more that can be done with XSLT (think images, charts, the xsl:choose element, etc.). There are plenty of resources out there to help you with WordprocessingML and XSLT. It will take some time but it will be worth it.
However, if you currently do not have the time to fully investigate this on your own, the Dradis team has years of experience and can help you create a custom template.
Contact our support team if you'd like to learn more about our report template conversion service.
Платформы WPF и Silverlight используют язык разметки XAML для описания элементов пользовательского интерфейса, шаблонов и стилей. Если вы разрабатываете одновременно под разные XAML платформы, то естественно, возникает желание иметь общие файлы разметки для этих платформ.
Разметка в WPF и Silverlight очень схожа, но имеются досадные отличия, которые сильно осложняют ее шаринг. В нашей компании эта проблема была решена несколько лет назад в виде внутреннего инструмента, который называется WPF2SL.
WPF2SL слишком специфичен, чтобы быть полезным широкой публике, поэтому мы не планируем его публиковать. В этой статье я расскажу об особенностях XSLT преобразований применительно к разметке XAML и о некоторых сложностях и особенностях, с которыми мы столкнулись.
Проект WPF2SL стартовал 4 года назад, когда мы решили создать линейки компонентов для платформ WPF и Silverlight. WPF контролы у нас были готовы раньше, поэтому возникла идея сделать шаринг разметки между платформами. В то время разрыв между разметкой WPF и Silverlight был больше, чем сейчас, потому что в Silverlight 3 не было implicit styles, markup extensions и были сильно ограничены байндинги.
Кстати, некоторые наши конкуренты пошли по другому пути. У них были сначала готовы Silverlight контролы и их линейка WPF контролов получена из априори урезанной платформы, поэтому они до сих пор в полной мере не используют всех возможностей WPF платформы.
Начнем с создания System.Xml.Xsl.XslCompiledTransform. Тут всё, как написано в MSDN. Однако следует помнить, что загрузка XSLT файла методом XslCompiledTransform.Load занимает много времени, потому что в этот момент в памяти будет создана временная сборка для конечного автомата, который описан в XSLT файле.
В одной из ранних версий WPF2SL на каждый входной XAML файл производилась полная инициализация с вызовом XslCompiledTransform.Load. Это сильно замедляло работу утилиты. В XslCompiledTransform загружается XSLT файл, содержащий описания преобразований для узлов и атрибутов исходного дерева. Преобразования в XSLT файле упорядочены по возрастанию приоритета. Правило с самым низким приоритетом — первое. Это копирующее правило.
Если для узла или атрибута не найдется более приоритетного правила, от будет скопирован.
Отсутствие DynamicResource в Silverlight
Если просто заменить DynamicResource на StaticResource, полученная разметка будет содержать много ошибок, связанных с неверным следованием ресурсов, потому что StaticResource требует, чтобы ресурс был объявлен до его использования. Решением стало ручное упорядочивание ресурсов внутри файла. XSLT шаблон для замены DynamicResource на StaticResource выглядит так.
Проблема усложняется, когда имеются ссылки на ресурсы, объявленные в другом файле. Эту часть проблемы не удалось решить XSLT преобразованиями. Для этого у нас есть отдельный этап пост-обработки, про который надо писать отдельную статью.
Вырезание узлов и атрибутов которые отсутствуют в Silverlight
Так как WPF разметка значительно богаче Silverlight разметки, нам придется вырезать узлы и атрибуты из XAML дерева. Это очень просто делается в XSLT.
Пример вырезания атрибута:
Пример вырезания поддерева:
Особенности преобразования ключей ресурсов
И в WPF, и в Silvelight в разметке XAML можно задать ResourceDictionary, в котором будут храниться ресурсы. Ресурсы доступны по ключу. В WPF ключом может быть любой объект, а в SL ключ должен быть обязательно строковый.
Для унификации, конечно можно ввести в WPF ограничение, чтобы ключом была только строка, но нам нравится строгая типизация, которая достижима именно на объектных ключах. В WPF возможно написать вот так
Где FloatingContainerThemeKey — это специальный дженерик объект, унаследованный от System.Windows.ResourceKey. Дженерик принимает параметром тип Enum, который описывает возможные названия ключей.

За счет этого в WPF сложнее ошибиться в названии ключа в объявлении ресурса или в ссылке на ресурс.
Вернемся к преобразованию XAML. В Silverlight объектных ключей нет, поэтому
преобразуется в строчку
XML namespaces
Многие схожие элементы в WPF и Silverlight находятся в разных xml неймспейсах. Это различие породило вот такие шаблоны.
Когда мы поняли, что таких шаблонов придется сделать очень много, мы создали своего наследника стандартного класса XmlTextWriter, у которого перегружен метод WriteString.
Этого наследника можно отдать в метод XslCompiledTransform.Transfrom(reader, writer) в качестве второго параметра. Перегруженый WriteString в соответствии с таблицей замен подменяет неймспейс при записи.
Интеграция в процесс компиляции
WPF2SL — это консольное приложение. В наших SL проектах на Pre-build event прописан вызов WPF2SL с соответствующими параметрами.
Но тут не всё так просто, как кажется. Практически у всех сейчас машины с многоядерными процессорами, на которых msbuild делает одновременную сборку сразу для нескольких проектов. WPF2SL в процессе работы создавала временные файлы в Temp. Поскольку их названия совпадали, возникал конфликт доступа. Проблема была решена добавлением ID процесса к названию файла.
Диагностика проблем в XSLT преобразовании
К сожалению, удобного средства диагностики XSLT преобразований нет (по крайней мере, автору о них не известно). Когда какие-то из XSLT преобразований работают не так, как ожидается, самый действенный способ — итеративная модификация XSLT с анализом результатов. Если результат преобразования сильно отличается от ожидаемого, смело помещайте в коментарий половину XSLT файла; если всё еще не понятно, еще половину и так далее. Этот способ получил у нас название: «метод половинного комента».
Описанный способ является универсальным для всех декларативных языков, в том числе и для XAML. Если не понятно, какой из шаблонов сформировал неверную строчку в выходном файле, можно временно в шаблон вписать строчку, которая позволит однозначно его идентифицировать.
Выводы
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
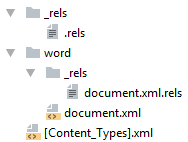
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
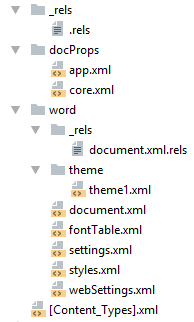
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
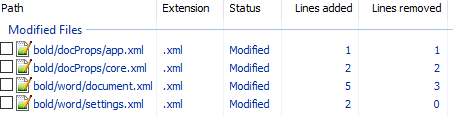
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
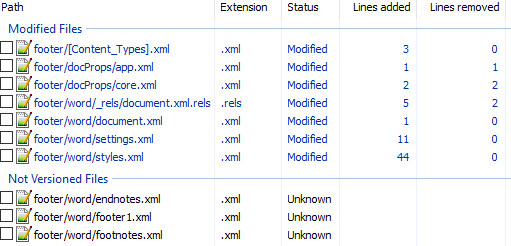
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег надо добавить
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег добавляем тег или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег добавить тег или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега может быть 3 тега — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Стандарт Extensible Stylesheet Language Transformation (XSLT) указывает определение языка для преобразований данных XML. XSLT используется для преобразования XML-документов в XHTML-документы или в другие XML-документы. В этой статье показано, как использовать XSLT с Microsoft Office Project XML-файлами обмена данными 2007 г. для фильтрации и отображения сведений о проекте. (Содержимое этой статьи было предоставлено Джессикой Бриттон, корпорация Майкрософт.)
Сведения о сохранении проектов в виде Project XML-файлов обмена данными см. в материалах Saving and Opening Projects in XML Format.
Таблица стилей XSLT — это XML-документ, состоящий из сочетания разметки XHTML, правил шаблона XSLT и отчетов XPath, которые работают вместе.
Разметка XHTML определяет среду отображения, в которой представлены XML-данные.
Правила шаблона XSLT предоставляют инструкции по преобразованию элемента XML источника определенным образом.
В заявлениях XPath определяются определенные элементы в документе XML.
Если элемент XML соответствует шаблону XPath, вызывается связанное правило шаблона XSLT. Преобразованные данные затем отображаются в рамках отображения, заданной разметка XHTML.
Дополнительные сведения о правилах шаблона XSLT и утверждениях XPath см. в ссылке в конце этой статьи.
Отображение Project с помощью преобразований XSLT
Процедура 1. Чтобы создать таблицу стилей XSLT:
Создайте XSLT-файл для таблицы стилей. Если вы работаете в Microsoft Visual Studio 2005 г., вы можете использовать шаблон XSLT File (в Visual Studio нажмите кнопку Файл, указать на Новый , а затем нажмите файл . Этот шаблон предварительно заселяется кодом XML, показанным в следующем примере. Если вы работаете в другом тексте или редакторе XML, скопируйте XML-шаблон и вклейте его в XSLT-файл.
Удалите следующий комментарий по коду XML. Здесь вы пишете XSLT-код.
Создайте код XSLT. Код XSLT, показанный в этом примере, делает следующее:
Отображает текстовое значение имени ребенка элемента Project в загонах.
Проверяет ребенка сводки каждого элемента Задачи, чтобы узнать, является ли значение 0 (false).
Тестирует критическое дитя каждого элемента Задачи, чтобы узнать, является ли значение 1 (true).
Отображает данные для критически важных задач, которые не являются сводными задачами в жирный шрифт.
Отображает данные для некритических задач, которые не являются сводными задачами.
Сортировка сведений о ресурсах в алфавитном порядке по текстовому значению имени каждого элемента Ресурса.
Тестирует переоправдаемого ребенка каждого элемента Ресурса, чтобы узнать, является ли значение 1 (true).
Отображает отсортченные данные ресурсов только для перенаваляемых ресурсов.
Сохраните файл в качестве ProjectTransform.xslt.
После создания таблицы стилей XSLT необходимо связать Project XML-файл с ней, добавив инструкции по обработке. В процедуре 2 показано, как связать файл ProjectTransform.xslt, созданный в процедуре 1, с любым Project XML-файлом.
Процедура 2. Чтобы изменить Project XML-файл, используйте таблицу стилей XSLT:
Откройте файл Project XML в Visual Studio или в другом тексте или редакторе XML.
Вставьте следующую строку кода после объявления XML, которая является первой строкой в Project XML-файле.
Удалите объявление пространства имен XML из Project, который является корневым элементом Project XML-файла. Если вы не удалите объявление пространства имен, встроенное в элемент Project, XPath не будет соответствовать элементам в XML Project XML-файле.
После выполнения этапов 2 и 3 первые три строки XML Project XML-файла должны выглядеть следующим примером кода.
Сохраните Project XML-файл.
Рекомендуется сохранить файл с помощью имени файла, которое отличается от исходного имени XML Project XML, так как изменения, внесенные в шаге 3, отсоедят XML-файл Project от схемы Project XML-обмена данными.
Просмотр преобразованного Project XML-файла. Преобразование XSLT можно выполнить в Visual Studio, задав свойство Stylesheet XML Project xML-файла ProjectTransform.xslt, а затем выбрав show XSLT Output из меню XML.
Вы также можете открыть Project XML-файл в Internet Explorer 7, Microsoft Office Word 2007 или любом другом приложении, которое поддерживает XSLT.
На рисунке 1 показан преобразованный выход Project XML-файла в Word 2007. Когда вы открываете Project XML-файл, по умолчанию отображается только представление данных. Чтобы просмотреть преобразованный выход, необходимо выбрать представление данных ProjectTransform.xslt в области документов XML.
Редактор XML позволяет связать таблицу стилей XSLT с XML-документом, выполнить преобразование и просмотреть вывод. Результат XSLT-преобразования отображается в новом окне документа.
Свойство Вывод определяет имя выходного файла. Если свойство Вывод пустое, файл с указанным именем создается во временном каталоге. Расширение файла определяется на основе элемента xsl:output в таблице стилей. Это может быть XML, TXT или HTM.
Если свойство Вывод определяет имя файла с расширением HTM или HTML, вывод XSLT открывается для предварительного просмотра с помощью браузера. Файлы с другими расширениями открываются редактором по умолчанию, которые выбирает среда Visual Studio. Например, если файл имеет расширение XML, то в Visual Studio используется редактор XML.
Выполнение преобразования XSLT из XML-файла
Откройте XML-документ в редакторе XML.
Свяжите таблицу стилей XSLT с XML-документом.
Добавьте в XML-документ инструкцию по обработке xml-stylesheet . Например, добавьте в пролог документа следующую строку: .
Добавьте таблицу стилей XSLT с помощью окна Свойства. Открыв файл XML в редакторе, щелкните правой кнопкой мыши в любом месте редактора и выберите Свойства. В окне Свойства щелкните поле Таблица стилей и нажмите кнопку обзора (. ). Выберите таблицу стилей XSLT, а затем нажмите Открыть.
В строке меню щелкните XML > Запустить XSLT без отладки. Либо нажмите клавиши CTRL+ALT+F5.
Результат XSLT-преобразования отображается в новом окне документа.
Если с XML-документом не связана ни одна таблица стилей, появится диалоговое окно с предложением указать таблицу стилей, которую нужно использовать.
Выполнение преобразования XSLT из таблицы стилей XSLT
Откройте таблицу стилей XSLT в редакторе XML.
Укажите XML-документ в поле Ввод в окне Свойства документа.
XML-документ является входным документом для преобразования. Если документ не указан при запуске преобразования XSLT, появится диалоговое окно Открытие файла, и можно будет указать документ.
В строке меню щелкните XML > Запустить XSLT без отладки. Либо нажмите клавиши CTRL+ALT+F5.
Результат XSLT-преобразования отображается в новом окне документа.
Задание имени выходного файла
У имени выходного файла может быть расширение XML или XS. Откройте окно Свойства и укажите имя файла в поле Вывод.
Читайте также: