
Как в 1с включить режим mtom
Начиная с версии технологической платформы 8.3.9 средства для работы с двоичными данными претерпели существенные изменения. В этой статье я постараюсь рассказать как о старых, так и о новых инструментах для работы с двоичными данными. При написании статьи использовалась версия технологической платформы 8.3.12
Общая информация
Если раньше, до версии технологической платформы 8.3.9, мы располагали только объектом ДвоичныеДанные, то к настоящему времени у нас имеется целый набор объектов, которые серьезно расширяют наши возможности по манипуляциям с двоичными данными. Рассмотрим все эти объекты чуточку подробнее.
Двоичные данные
Экземпляры объекта ДвоичныеДанные содержат двоичные данные, которые считываются из файла. При это объект ДвоичныеДанные является достаточно многофункциональным — мы можем:
- читать двоичные данные из файла и записывать их в файл;
- передавать их между клиентом и сервером при помощи временного хранилища;
- передавать и получать их по сети;
- хранить их базе данных в реквизитах вида ХранилищеЗначения;
- превратить двоичные данные в объект вида Картинка (при определенных условиях конечно);
- хранить двоичные данные в макетах;
- шифровать и расшифровывать, подписывать и проверять подписи;
Наверняка я что-то пропустил, но главное должно быть понятно — несмотря на значительное развитие средств работы с двоичными данными, объект ДвоичныеДанные остается ключевым.
Потоки
Это группа объектов назначение которых заключается в работе с потоками данных.
Поток — этот объект представляет собой поток данных из которого можно читать и/или записывать в него данные. Данный объект не имеет конструктора, а получить экземпляр объекта можно при помощи различных методов других объектов.
ФайловыйПоток — специализированный вариант объекта Поток, предназначенный для работы с данными находящимися в файлах на диске.
ПотокВПамяти — специализированный вариант объекта Поток, предназначенный для работы с данными находящимися в оперативной памяти.
МенеджерФайловыхПотоков — этот объект предоставляет типовые методы для работы с файлами (открытие и создание). Создать экземпляр этого объекта нельзя — имеется объект глобального контекста ФайловыеПотоки который и предоставляет доступ к методам менеджера.
Чтение и запись
ЧтениеДанных — этот объект предназначен для чтения различных типов данных из различных источников (потоки, файлы, двоичные данные).
РезультатЧтенияДанных — этот объект содержит описание результата чтения данных из потока. Объект не имеет конструктора, получить экземпляр объекта можно при помощи методов других объектов.
БуферДвоичныхДанных — этот объект представляет собой коллекцию байтов фиксированного размера, имеется возможность произвольного доступа и изменения по месту.
ЗаписьДанных — этот объект предназначен для записи различных типов данных в приемник.
Практическая часть
Итак, у нас достаточно много различных объектов, которые, в свою очередь, имеют много разных свойств и методов. Разобраться во всем этом более подробно помогут практические примеры, к ним и перейдем.
Многие объекты — ДвоичныеДанные, Поток, ФайловыйПоток, ПотокВПамяти, ЧтениеДанных, ЗаписьДанных, РезультатЧтенияДанных имеют пары синхронных и асинхронных методов, например: Записать — НачатьЗапись, Закрыть — НачатьЗакрытие. Асинхронные методы нужны для обеспечения возможности одинаковой работы и в тонком клиенте, и в веб-клиенте.
Подробнее про синхронные и асинхронные методы можно прочесть в этой статье.
Двоичные данные
Ниже приведены примеры основных операций с объектом ДвоичныеДанные.
1. Вы опытный программист, и в данный момент времени перед Вами стоит задача интегрировать 1С с внешними программами посредством вызова внешних веб-сервисов, и эта задача возникает у Вас периодически, каждый раз при этом Вы дублируете код - этот модуль придёт Вам на помощь, вызывайте любые операции любых веб-сервисов из кода в две строчки.
2. Вы только учитесь программировать или Вы опытный программист 1С, но у Вас абсолютно нет опыта работы с веб-сервисами и понятием XDTO в 1С - модуль поможет Вам в тестовом режиме использования понять на практике определенные нюансы работы с XDTO объектами в 1С , на примере с тестовыми внешними веб-сервисами (можете использовать в учебных целях общедоступный веб-сервис для работы с погодой ).
Конечно же, практика в виде чтения чужого кода с отладчиком хороша и полезна, не заменит никакую документацию, но для начала, если Вы не знакомы с веб-сервисами, но хотите понять всю суть работы с внешними веб-сервисами из 1С и публикации веб-сервисов 1С для внешнего использования, для начала советую прочитать статью о ИТС, затем серию публикаций автора Evil Beaver под названием XDTO - это просто . По Вашему желанию можно поискать любую другую информацию на просторах интернета, всё зависит от Вашего настроя. Но давайте вернёмся к сути данной публикации.
Принцип работы данного модуля
Когда у меня встала задача интеграции 1С с внешними источниками, я сразу понял, что код нужно разделить на несколько уровней абстракции.
Общий модуль (1-ый уровень абстракции), который обслуживает определенный внешний веб-сервис, предоставляет такие функции как : получить структуру параметров определенной операции на данном веб-сервисе, выполнить определенную операцию на определенном веб-сервисе, который по мере необходимости обращается к 2-ому общему модулю (2-ой уровень абстракции), который уже на более низком уровне предоставляет все необходимые операции для работы с веб-сервисами.
Более подробно схематично:

От теории к практике
Как это работает в коде:
Платформа 8.3, управляемые формы.

Платформа 8.2, обычные формы.

Под капотом при получении параметров:

Под капотом при выполнении метода:

Как видно по последнему скрину, имеется возможность указать имя реквизита, который идентифицирует успешное выполнение, также модуль имеет функционал для создания анонимных типов, причем на любом уровне вложенности. Есть возможность передавать реквизит булевого типа - "Отказ", в случае, если веб-сервис вызывается при записи объектной сущности.
Так как статья ориентирована на программистов, так или иначе умеющих читать код 1С и делать логические выводы, я не буду слишком сильно углубляться в обьяснение принципов работы данного модуля.
Файлы во вложении:
1. Тестовые конфигурации с интегрированными тестовыми внешними веб-сервисами:
1.1. на платформе 8.2, с режимом запуска обычное приложение.
1.2. на платформе 8.3, с режимом запуска управляемое приложение.
1.3 Соответствующие обработки на обычных и управляемых формах, для вызова и тестирования интегрированных веб-сервисов.
2. Текстовые файлы содержащие код технического общего модуля и шаблон обслуживающего веб-сервис общего модуля.
3. Текстовый файл, описывающий необходимые действия для интеграции данного модуля.
Средства работы с двоичными данными
Необходимо просканировать каталог с файлами, выбрать файлы с расширением ".jpg" или ".jpg" и для каждого такого файла собрать информацию об изображении. Если при анализе выяснится, что файл не соответствует формату JPEG, то такой файл следует пропустить.
Информация, которая нас интересует:
- Ширина изображения в пикселах,
- Высота изображения в пикселах,
- Глубина цвета (количество битов на один пиксел).
Краткое описание формата JPEG
Кратко опишем некоторые детали формата, существенные для решения нашей задачи. За более подробным описанием формата JPEG можно обратиться к соответствующим источникам:
Файл JPEG содержит последовательность маркеров , каждый из которых начинается с байта 0xFF, свидетельствующего о начале маркера, и байта-идентификатора. Некоторые маркеры состоят только из этой пары байтов, другие же содержат дополнительные данные, состоящие из двухбайтового поля с длиной информационной части маркера (включая длину этого поля, но за вычетом двух байтов начала маркера, то есть 0xFF и идентификатора) и собственно данных. Такая структура файла позволяет быстро отыскать маркер с необходимыми данными (например, с длиной строки, числом строк и числом цветовых компонентов сжатого изображения).
Решение
Создадим функцию, которая будет сканировать файл, определять его формат и выделять нужную нам информацию.
Важно, что для корректного разбора маркеры необходимо читать последовательно, один за другим, т.к. байты, совпадающие с маркером могут быть в содержимом фрагментов.
Теперь, когда мы написали основную функцию для анализа JPEG-файла, напишем вспомогательную функцию - ПрочитатьМаркер , которая читает очередной маркер и возвращает информацию о нем:
- РазмерСекции : размер секции, начало которой отмечает маркер
- ЭтоОписаниеИзображения : признак того, что секция, отмеченная маркером, содержит нужную нам информацию об изображении.
И, наконец, соберем всё вместе и напишем функцию, которая будет анализировать все файлы в заданной папке и выдавать полученную информацию в виде таблицы.
Вы можете скачать приложенную конфигурацию прямо сейчас
Постановка задачи
Ответ от сервиса будет иметь следующий вид:
В качестве обработчика для метода создаем в модуле сервиса функцию ДляВсех_Get :
Создаем новую общую форму. На форму добавляем реквизиты типа Строка:
Далее добавляем элементы управления:
Создаем обработчик команды:
Вся работа по запросу сервиса и отображению результата выполняется в серверной функции ВыполнитьЗапрос :
Сервисы REST на основе JSON популярны, но когда дело доходит до интеграции корпоративных сервисов, SOAP все еще широко используется. В недавнем проекте мне пришлось написать микросервис на основе весенней загрузки, который был своего рода шлюзом для стороннего веб-сервиса на основе SOAP, построенного на Microsoft WCF . При вызове микросервис собирал некоторые данные из других микросервисов, загружал документ PDF из системы хранения и передавал данные и PDF в службу SOAP за один вызов SOAP. Когда первая реализация была закончена и развернута, я проверил журналы доступа: вау, размер запроса был огромным для некоторых запросов. Хорошо, размер PDF-файлов варьировался от нескольких килобайт до нескольких мегабайт, но запрос, казалось, был намного больше. Это потому, что SOAP использует Base64 кодировать двоичный контент. И Base64 кодирует 6 битов на символ, значит 3 байта кодируются в 4 символа. Это на 33% больше контента, чем необработанных данных. Для небольшого контента это не проблема, но если вам нужно передать 4 МБ вместо 3 МБ … это проблема. Вот пример простого SOAP-запроса с двоичным содержимым. Содержание всего 30 байтов, которые закодированы в 40 символов (XML был отформатирован для удобства чтения):
Как видите, часть, содержащая двоичные данные, содержит только 30 байтов, не более. Но наверняка есть некоторые издержки для составных метаданных, которые вы должны заплатить. Как правило, MTOM имеет смысл только для контента> 1 кБ. Если вы посмотрите на элемент содержимого, вы заметите элемент xop:
В то время как MTOM описывает абстрактную функцию оптимизации передачи в SOAP, конкретная реализация, использующая мультипартии MIME, хранится в отдельной спецификации: XOP , XML-двоичная оптимизированная упаковка. Тем самым он может использоваться независимо от SOAP для любого двоичного содержимого в документах XML. Поэтому вы часто найдете формулировку MTOM / XOP.
Пример приложения
Чтобы дать вам пример, с которым можно поиграться, я подготовил простой SOAP-сервер и клиент на github, реализованный с использованием Spring Boot. Они построены с помощью STS , но вы можете создавать и запускать их с помощью простой Java; просто проверьте файл Readme. Клонируйте репозиторий и переключитесь на ветку base64 , он обеспечивает начальную настройку с двумя весенними проектами mtom-server и mtom-client . Просто запустите сервер и клиент, как описано в файле Readme. Клиент запрашивает размер документа для загрузки. Если вы введете размер, клиент сгенерирует документ такого размера (содержащий некоторые случайные двоичные данные) и загрузит его на сервер. И клиент, и сервер также отслеживают запрос и ответ, так что вы можете проверить их.
Вывод клиентской консоли:
Вывод консоли сервера:
Таким образом, мы имеем только операции storeDocument с a document в storeDocumentRequest и логическое в storeDocumentResponse . document Сама содержит некоторые метаданные , как name и author , и — наконец — двоичный код content .
Использование MTOM
Чтобы использовать MTOM, мы должны применить некоторые изменения в нашем примере. (Вы можете выполнить эти шаги на своем примере или напрямую проверить готовое решение в филиале mtom ). Сначала давайте включим MTOM на клиенте, который просто включает его на маршаллере JAXB:
По сути, это то же самое, что и на сервере. Но мы также должны сказать Spring, чтобы использовать этого маршаллера для конечных точек:
Также мы должны добавить поддержку множественных компонентов, предоставив соответствующий многочастный преобразователь:
Вот и все, если вы запустите его, вы получите следующий вывод на клиентской консоли:
MTOM и потоковое
Если вы посмотрите на классы Java, сгенерированные из модели, вы увидите, что двоичное содержимое хранится в байтовом массиве:
Когда вы имеете дело с большими двоичными данными, это проблема, поскольку полные данные должны храниться в памяти. OutOfMemoryException Ждет вас. Решением этой проблемы является потоковая передача: вместо того, чтобы хранить данные в памяти, вы предоставляете данные в потоке, соответственно. читать данные из потока. Это вполне естественно, поскольку большинство хранилищ данных, например, файловая система, база данных и т. Д., Предоставляют потоковые интерфейсы. Даже если спецификация MTOM не говорит ни слова о потоковой передаче, спецификация XOP говорит, что — даже если это не является обязательным — большинство реализаций предоставляют возможность потоковой передачи данных. Давайте сделаем это сейчас в нашем примере. Опять же, вы можете выполнить шаги и преобразовать приложение MTOM в потоковую передачу или оформить заказ master ветка проекта. Мастер предоставляет финальную версию для вас. Сначала нам нужен способ обеспечить потоковый интерфейс в наших классах Java. Способ сделать это — немного изменить схему. Просто добавьте атрибут xmime:expectedContentTypes="application/octet-stream" к элементу контента:
Теперь JAXB использует DataHandler вместо byte[] поля содержимое:
DataHandler основан на потоках, поэтому вы можете использовать Input- и OutputStreams для передачи данных. Это то, что мы делаем; вместо того, чтобы сначала читать наш контент в байтовый массив, мы напрямую передаем наш поток ввода в DataHandler на клиенте:
Теперь у нас есть это? Давайте попробуем … святой чихуахуа, теперь сервер стонет . Но это должно сработать прямо сейчас. Это ошибка в реализации SAAJ, см. SAAJ-31 . Как вы можете прочитать там, мы должны установить переключатель, чтобы заставить SAAJ использовать mimepull, поэтому мы делаем это:
Теперь это работает … действительно. Попробуйте это с 1.000.000.000 байтов (трассировка SOAP отключена в master, так что не беспокойтесь). Это займет некоторое время, так как наши случайные данные InputStream генерируют каждый байт:
MTOM и потоковая передача в WCF
Это было легко, а? Да, WCF обрабатывает все эти мелкие мелочи для вас.
Заключение
MTOM позволяет эффективно передавать большие двоичные данные, и даже позволяет потоковую передачу во избежание проблем с памятью. Да, есть и другие механизмы потокового вещания; но если вы хотите, чтобы ваш SOAP-сервис взаимодействовал с другими, то стандарт MTOM — ваш выбор.
Смущенный? Вы не будете после этого эпизода мыла!
Диктор Soap, комедия конца 70-х, которую я любил смотреть 🙂
Отладка — это неотъемлемая этап разработки прикладного решения. Умение эффективно использовать имеющиеся инструменты существенно снижает временные затраты на разработку и повышает ее качество. В этой статье я попробую рассказать о том, какие инструменты для отладки предоставляет нам система «1С:Предприятие».
Кроме этого отмечу, что эта статья входит в небольшую серию статей об отладке в 1С:
Имеющиеся в наличии инструменты отладки собраны в меню — «Отладка» можно вызвать соответствующими горячими клавишами или из меню «Отладка».
Точки останова
Точка останова — это некая точка в программном модуле, на которой выполнение модуля приостанавливается и управление перехватывает отладчик. Точку останова можно установить с любой строке модуля и в любой момент работы с отладчиком. Место установки точки останова отмечается соответствующим знаком, для разных видов точек останова используются разные обозначения:

Виды точек останова
Работе с точками останова посвящена секция меню «Отладка»:
- Точка останова (F9) — устанавливает/удаляет точку останова в строке на которой стоит курсор;
- Точка останова с условием — устанавливает точку останова и открывает окно для ввода условия — логического выражения, повторное использование команды в этой же строке откроет окно для редактирования условия. Останов в указанной точке будет выполнен только если условие истинно;
- Включить/отключить точку останова (Ctrl+Shift+F9) — включает/отключает точку останова;
- Удалить все точки останова — удаляет все точки останова во всех модулях;
- Отключить все точки останова — отключает все точки останова во всех модулях;
- Список точек останова (Alt+F9) — открывает окно для просмотра и управления точками останова, о нем ниже.
Кроме этого пункт меню «Отладка» — «Остановка по ошибке…» также можно отнести к работе с точками останова, так как эта команда позволяет останавливать выполнение кода при возникновении ошибки и переходит к строке которая вызвала ошибку.
Команда «Список точек останова» (Alt+F9) открывает окно для просмотра и управления точками останова:
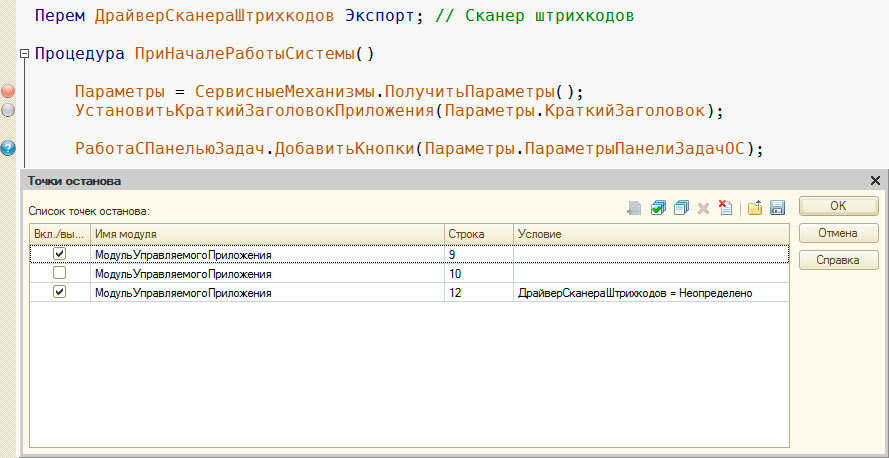
Окно «Точки останова»
В окне показаны все точки останова во всех модулях, их расположение (модуль и номер строки) и условие (если есть). Имеется возможность включить/отключить/удалить точки останова, перейти к месту установки точек останова, сохранить и загрузить список точек останова.
Пошаговое выполнение
После того как сработает какая-либо точка останова и управление перейдет к отладчику обычно следует пошаговое выполнение кода модуля. Для пошагового выполнения в меню «Отладка» (и на панели отладки) имеется соответствующая группа команд — они появляются в момент подключения первого из предметов отладки.

Команды пошагового выполнения
В режиме пошаговой отладки исполнение кода приостанавливается после каждой команды и ждет инструкций от отладчика. А инструкции бывают следующими:
- Шагнуть в (F11) — если следующая команда это процедура/функция, то начинается пошаговая отладка этой функции, иначе отладчик просто переходит к следующей команде;
- Шагнуть через (F10) — если следующая команда это процедура/функция, то она полностью выполняется (не пошагово) и отладчик переходит к следующей команде;
- Шагнуть из (Shift+F11) — прерывает пошаговое выполнение процедуры/функции и останавливается на первом операторе после выхода из нее;
- Идти до курсора (Shift+F10) — выполняются все операторы до строки на которой стоит курсор;
- Текущая строка — перемещает курсор в ту строку, на которой остановился отладчик;
- Продолжить отладку (F5) — прерывает пошаговую отладку и продолжает свободное исполнение модуля.
Управление отладкой
Управление отладкой осуществляется при помощи соответствующих команд меню «Отладка»:
- Перезапустить (Ctrl+Shift+F5) — прекращает выполнение конфигурации и производить повторный запуск в режиме «1С:Предприятия»;
- Завершить (Shift+F5) — прекращает выполнение модуля и завершает работу текущего предмета отладки;
- Остановить — останавливает выполнение модуля на текущем операторе и позволяет начать отладку со следующей исполняемой строки.
- Остановка по ошибке — открывает окно настройки остановки по ошибке:
Окна, табло и стек вызова
Далее рассмотрим команды которые открывают окно «Выражение», «Локальные переменные», «Табло» и «Стек вызова»:

Окна, табло и стек вызова
Окно «Выражение» (Shift+F9)
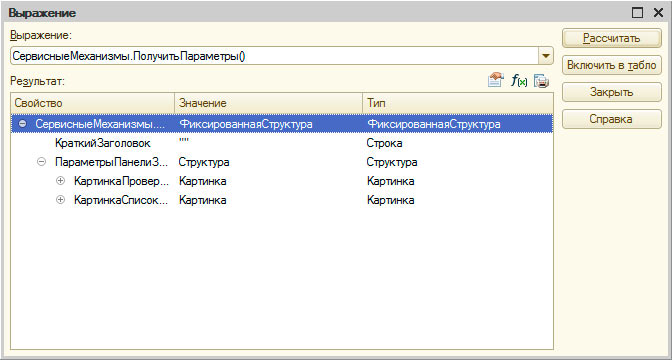
Окно «Выражение»
Позволяет рассчитать выражение на встроенном языке. Следует отметить, что выражения выполняются в реальной системе и об этом нельзя забывать, если, к примеру, рассчитываемое выражение создает некий объект данных, то этот объект будет создан в реальной системе.
Табло (Ctrl+Alt+W)
Специальное окно, которое состоит из четырех страниц (переключение из контекстного меню) и отображает результаты вычисления переменных, арифметических выражений и выражений с использованием встроенного языка.
Окно «Локальные переменные»
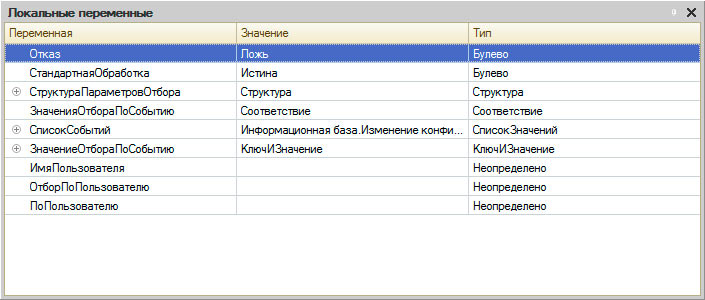
Окно «Локальные переменные»
Специальное окно, которое во время отладки показывает список локальных переменных текущего метода. Редактировать таблицу переменных нельзя.
Изменение значения переменной
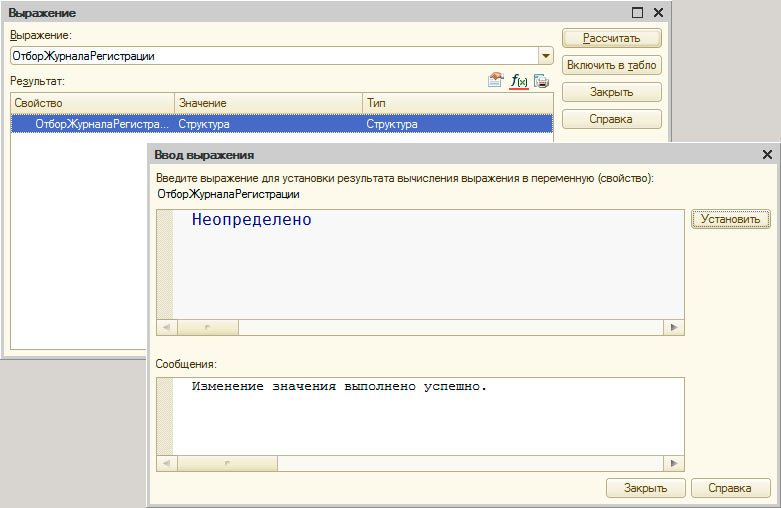
Изменение значения переменной
Когда управление находится у отладчика имеется возможность изменять значения переменных и свойства объектов (доступные для записи). Доступ к этой функции можно получить из окна выражений (подчеркнутая кнопка на рисунке выше), а также из контекстного меню в окне локальных переменных и в табло (такой же значок как и в окне выражений).
Откроется специальное окно (как на рисунке выше). В верхней части можно ввести новое значение для переменной — константное значение любого типа или выражение, корректное с точки зрения встроенного языка.
Пользоваться функцией нужно с осторожностью — необдуманное изменение значений переменных может привести к записи в базу данных совершенно неправильных значений.
Стек вызова
Показывает последовательность вызовов процедур и функций, которая привела к отлаживаемой в данный момент строке кода. Колонки таблицы содержат название метода, номер строки модуля и предмет отладки.
Замер производительности
Замер производительности позволяет оценить скорость работы всей конфигурации или ее части. Измеряется скорость выполнения и частота использования конкретных участков кода, а также прочая дополнительная информация о которой ниже.
Полученная информация позволяет, например, выбрать наиболее оптимальный (по быстродействию) вариант решения какой-либо задачи или отыскать «узкие», в плане быстродействия, места конфигурации. При этом нужно учитывать, что какие-либо сравнения скорости выполнения нужно проводить в одинаковых условиях.
Включить режим замера производительности можно соответствующей командой из меню «Отладка»:
![]()
Команда «Замер производительности»
Включить режим замера производительности можно как до запуска отладки, так и во время. Повторный использование команды прекратит замер и выведет окно с результатами. Включение и выключение замера производительности действует на все подключенные ко отладчику предметы отладки.
Результаты замера
Результаты замера производительности отображаются в виде таблицы со следующими столбцами:
- Модуль — название модуля;
- Номер строки — номер строки;
- Строка — участок кода;
- Кол. — количество вызовов данного участка кода за все время замера;
- Врем. — суммарное время выполнения (в секундах) данного участка кода за все время замера;
- %(Врем.) — процент суммарного времени выполнения данного участка кода к общему времени замера (общее время замера — это суммарное время выполнения кода конфигурации);
- Клиент — отметка участков кода выполняющихся на клиенте;
- Сервер — отметка участков кода выполняющихся на сервере;
- Обр. сервер — отметка участков кода в которых происходит вызов сервера.
Таблица с результатами замера производительности может выглядеть, например, так:
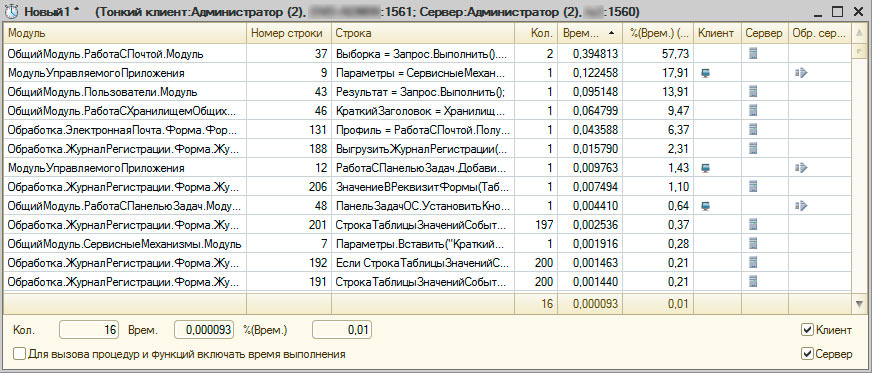
Результаты замера производительности
Если в строке вызывается процедура/функция то система может показывать время выполнения строки как с учетом времени выполнения вызываемой процедуры/функции и без учета этого времени. Флажок «Для вызова процедур и функций включать время выполнения» служит для выбора способа подсчета времени выполнения строки.
Результаты можно отсортировать по любой из колонок. Если выделить несколько строк, то сумма квантитативных данных (Кол., Врем., %(Врем.)) отобразится в нижней части окна. Кроме этого результаты можно сохранить в файл с расширением *.pff (этот файл, в последствии, можно открыть в любом конфигураторе).
Имитация задержек при вызове сервера
Механизм имитации задержек при вызове сервера позволяет имитировать работу прикладного решения в условиях существенных временных задержек при взаимодействии с сервером — при вызове сервера, а также при отправке данных на сервер и получении данных с сервера.
Включить механизм можно в конфигураторе (меню «Сервис»->»Параметры», вкладка «Запуск 1С:Предприятия»), специальным ключом командной строки, а также в режиме 1С:Предприятие (меню «Сервис»->»Параметры»):
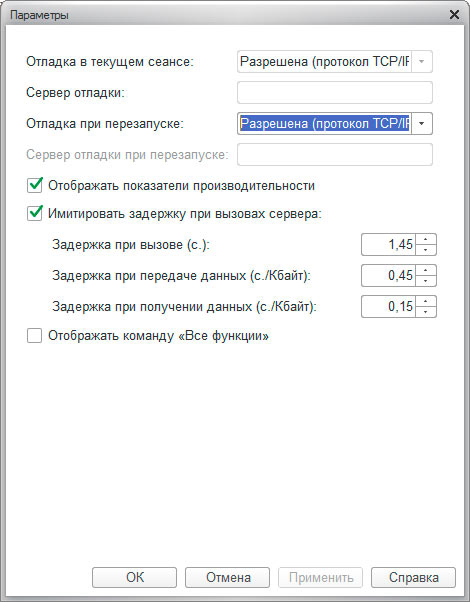
Включение механизма имитации задержек
На этом все, надеюсь, что эта статья была Вам полезна. Также напомню про другие статьи серии об отладке в 1С, ссылки на них можно найти в начале этой статьи.
Если Вы нашли ошибку или неточность, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
(оценок: 3, средняя оценка: 5,00 из 5)
Читайте также: